Лекция
Привет, Вы узнаете о том , что такое конвейерная архитектура, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое конвейерная архитектура , настоятельно рекомендую прочитать все из категории Разработка программного обеспечения и информационных систем.
конвейерная архитектура — это способ построения программы, при котором данные проходят через цепочку независимых обработчиков.
Ее часто называют:
Главная идея:
Входные данные → шаг 1 → шаг 2 → шаг 3 → результат
Каждый шаг делает одну конкретную операцию и передает результат дальше.

Представьте заводской конвейер:
Сырье → Очистка → Обработка → Проверка качества → Упаковка
В программировании похожая схема:
Сырые данные → Очистка → Преобразование → Проверка → Сохранение
Например, импорт пользователей из CSV:
CSV-файл ↓ Прочитать файл ↓ Распарсить CSV ↓ Очистить пробелы ↓ Нормализовать email ↓ Проверить обязательные поля ↓ Сохранить в базу
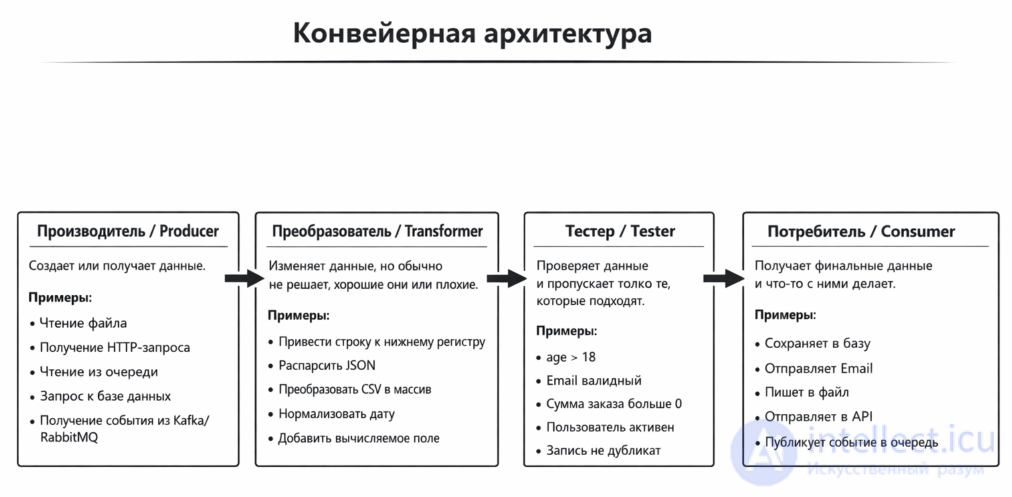
Обычно в такой архитектуре выделяют несколько ролей.
Создает или получает данные.
Примеры:
- читает файл - принимает HTTP-запрос - получает сообщение из очереди - читает данные из базы - получает данные из внешнего API
Пример:
ReadCsvFile
Изменяет данные.
Примеры:
- trim строк - приведение email к нижнему регистру - преобразование JSON в массив - нормализация номера телефона - добавление вычисляемого поля
Пример:
NormalizeEmail
Проверяет данные и решает, проходят они дальше или нет.
Примеры:
- email валидный? - поле name заполнено? - age больше 18? - запись не является дубликатом?
Пример:
ValidateEmail
Получает финальный результат и что-то с ним делает.
Примеры:
- сохраняет в базу - отправляет email - пишет лог - отправляет данные в очередь - возвращает HTTP-ответ
Пример:
SaveToDatabase
Но это не жесткое правило.
Можно иметь много преобразователей:
Producer → Transformer → Transformer → Transformer → Consumer
Можно иметь много проверок:
Producer → Tester → Tester → Tester → Consumer
Можно вообще сделать pipeline только из середины:
Normalize → Validate → Format
Пример случая когда несколько Producer, иногда pipeline собирает данные из нескольких источников:

Но это уже не простой линейный pipeline, а разветвленный pipeline / pipeline graph.
Пример случая когда несколько Consumer Например после обработки данных можно:

Последовательно Или параллельно
Допустим, у нас есть массив пользователей:
$users = [
['name' => ' Ivan ', 'email' => ' IVAN@EXAMPLE.COM '],
['name' => '', 'email' => 'wrong-email'],
['name' => ' Anna ', 'email' => ' ANNA@EXAMPLE.COM '],
];
Создадим несколько фильтров.
interface PipelineStep
{
public function handle(array $items): array;
}
class TrimFields implements PipelineStep
{
public function handle(array $items): array
{
return array_map(function ($item) {
$item['name'] = trim($item['name']);
$item['email'] = trim($item['email']);
return $item;
}, $items);
}
}
class NormalizeEmail implements PipelineStep
{
public function handle(array $items): array
{
return array_map(function ($item) {
$item['email'] = strtolower($item['email']);
return $item;
}, $items);
}
}
class ValidateUsers implements PipelineStep
{
public function handle(array $items): array
{
return array_filter($items, function ($item) {
return $item['name'] !== ''
&& filter_var($item['email'], FILTER_VALIDATE_EMAIL);
});
}
}
class Pipeline
{
private array $steps;
public function __construct(array $steps)
{
$this->steps = $steps;
}
public function run(array $input): array
{
$data = $input;
foreach ($this->steps as $step) {
$data = $step->handle($data);
}
return $data;
}
}
$pipeline = new Pipeline([
new TrimFields(),
new NormalizeEmail(),
new ValidateUsers(),
]);
$result = $pipeline->run($users);
print_r($result);
Результат будет примерно такой:
[
['name' => 'Ivan', 'email' => 'ivan@example.com'],
['name' => 'Anna', 'email' => 'anna@example.com'],
]
Пользователь с пустым именем и неправильным email был отфильтрован.
const producer = () => [1, 2, 3, 4, 5];
const transformer = (items) => items.map(x => x * 2);
const tester = (items) => items.filter(x => x > 5);
const consumer = (items) => {
console.log(items);
};
const data = producer();
const transformed = transformer(data);
const tested = tester(transformed);
consumer(tested);
Результат:
[6, 8, 10]
То есть поток выглядит так:
Producer → Transformer → Tester → Consumer
Конвейер можно описывать не только кодом, но и конфигурацией.
Например:
pipeline: - TrimFields - NormalizeEmail - ValidateUsers - SaveUsersToDatabase
А код будет читать конфиг и запускать нужные классы.
Такой подход удобен, когда нужно часто менять порядок шагов без изменения основного кода.
В конвейерной архитектуре ошибки можно обрабатывать разными способами.
ReadFile → ParseCsv → Normalize → Save
↑
ошибка
Если CSV поврежден, дальше идти нельзя.
try {
$result = $pipeline->run($input);
} catch (Throwable $e) {
echo "Pipeline failed: " . $e->getMessage();
}
Иногда pipeline должен падать сразу.
Например:
- нет обязательного конфига - неверный API key - нет подключения к базе - нарушена структура входных данных
Это называется fail fast.
То есть система не пытается «как-нибудь продолжить», а сразу сообщает:
Pipeline cannot continue
Например, одна строка CSV плохая, но остальные нормальные.
1000 строк → 980 обработано → 20 ошибок сохранено в отчет
Valid data → SaveToDatabase Invalid data → ErrorReport
Такой подход часто используют в импортах, ETL и очередях.
Если ошибка временная:
Можно попробовать повторить шаг несколько раз.
В системах с очередями, например RabbitMQ, Kafka, AWS SQS, ошибочные сообщения часто отправляют в Dead Letter Queue.
То есть сообщение не удаляется навсегда, а переносится в специальную очередь ошибок.
Это нужно, чтобы потом можно было:
- посмотреть причину ошибки- исправить данные- повторно запустить обработку- найти баг в кодеВ реальной архитектуре часто задают стратегию обработки ошибки для каждого шага.
Например:
pipeline:
- step: CsvParser
on_error: stop
- step: UserNormalizer
on_error: skip_item
- step: EmailValidator
on_error: send_to_error_channel
- step: DatabaseSaver
on_error: retry_then_stop
То есть:
CsvParser упал → остановить pipeline
UserNormalizer упал на одной строке → пропустить строку
EmailValidator нашел ошибку → отправить в список ошибок
DatabaseSaver упал → повторить 3 раза, потом остановить
В конвейерной архитектуре обработка ошибок обычно строится по одному из вариантов:
1. Остановить весь pipeline 2. Пропустить ошибочный элемент 3. Отправить ошибку в отдельный error channel 4. Повторить шаг несколько раз 5. Отправить сообщение в Dead Letter Queue 6. Вернуть объект Result вместо исключения 7. Обработать ошибку централизованно в PipelineRunner
Самый практичный вариант:
Критические ошибки → остановить pipeline. Ошибки отдельных записей → отправить в error channel. Временные ошибки → retry. Неисправимые сообщения → dead letter queue.
То есть конвейерная архитектура не требует одного универсального способа. В ней обычно заранее задают политику обработки ошибок для каждого фильтра.
Она встречается очень часто.
В Laravel, Express.js, Symfony и других фреймворках запрос проходит через цепочку middleware:
Request ↓ CheckMaintenanceMode ↓ StartSession ↓ Authenticate ↓ CheckPermissions ↓ Controller ↓ Response
Это тоже похоже на pipeline.
Commit ↓ Install dependencies ↓ Run tests ↓ Build application ↓ Deploy
Каждый шаг получает результат предыдущего и либо продолжает выполнение, либо останавливает процесс.
Original image ↓ Resize ↓ Compress ↓ Add watermark ↓ Save
Каждый шаг отвечает за одну задачу.
Каждый фильтр можно тестировать отдельно.
Можно легко добавить новый шаг:
NormalizePhone
И получить:
TrimFields → NormalizeEmail → NormalizePhone → ValidateUsers
Один фильтр можно использовать в разных конвейерах.
Например:
NormalizeEmail
может использоваться и в регистрации пользователя, и в импорте CSV, и в обновлении профиля.
Можно менять порядок шагов через конфиг:
pipeline: - TrimFields - NormalizeEmail - ValidateUsers
Если шагов очень много, трудно понять, где именно данные изменились.
Step1 → Step2 → Step3 → Step4 → Step5 → Step6 → Step7...
Решение:
Если каждый шаг создает новые объекты или копирует большие массивы, может быть просадка по производительности.
Если логика сильно ветвится:
если A → B → C если D → E → F если G → H → I
то простой линейный pipeline может стать неудобным.
Тогда лучше использовать:
- workflow engine - state machine - event-driven architecture - orchestration service
Если сделать слишком много маленьких шагов, код может стать раздробленным.
Плохо:
Иногда лучше объединить близкие операции:
Конвейерная архитектура похожа на Chain of Responsibility, но есть отличие.
Каждый шаг обычно обрабатывает данные и передает дальше.
A → B → C → D
Каждый обработчик может решить: обработать запрос или передать дальше.
A не обработал → B не обработал → C обработал → стоп
Пример Chain of Responsibility:
Support Level 1 → Support Level 2 → Support Level 3
Пример Pipeline:
Parse → Normalize → Validate → Save
Конвейерная архитектура хорошо подходит, когда:
Примеры хороших задач:
Лучше не использовать простой pipeline, если:
Например, для сложного жизненного цикла заказа может быть лучше:
State Machine
А для взаимодействия многих сервисов:
Saga / Orchestration / Event-driven architecture
В Laravel есть встроенный Pipeline.
Идея примерно такая:
use Illuminate\Pipeline\Pipeline;
$result = app(Pipeline::class)
->send($userData)
->through([
TrimFields::class,
NormalizeEmail::class,
ValidateUser::class,
])
->thenReturn();
Каждый класс может иметь метод handle:
class NormalizeEmail
{
public function handle(array $data, Closure $next)
{
$data['email'] = strtolower(trim($data['email']));
return $next($data);
}
}
Это уже готовый пример конвейерного подхода в реальном фреймворке.
Конвейерная архитектура — это подход, где данные проходят через последовательность независимых шагов.
Источник данных → обработка → проверка → результат
Самое важное:
Очень коротко:
Pipeline = данные идут по цепочке обработчиков.
Каждый обработчик что-то делает и передает результат дальше.
Исследование, описанное в статье про конвейерная архитектура, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое конвейерная архитектура и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Разработка программного обеспечения и информационных систем

Комментарии