Лекция
Привет, Вы узнаете о том , что такое чистая архитектура, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое чистая архитектура , настоятельно рекомендую прочитать все из категории Разработка программного обеспечения и информационных систем.
Сперва мы поговорим о том, что такое чистая архитектура вообще и познакомимся с такими понятиями как домен, юзкейс и слои приложения. Затем обсудим, как это применимо ко фронтенду и стоит ли вообще заморачиваться.
Далее мы спроектируем фронтенд магазина печенек по заветам чистой архитектуры. Этот магазин будет использовать React в качестве UI-фреймворка, чтобы показать, что такой подход к архитектуре применим к нему тоже. Потом с нуля реализуем один из пользовательских сценариев, чтобы понять, удобно ли это.
В коде будет немножко TypeScript, но только чтобы показать, как использовать типы и интерфейсы для описания сущностей. Все, что мы сегодня посмотрим, можно использовать и без TypeScript, разве что код будет не таким выразительным.
Мы сегодня почти не будем говорить об ООП, поэтому пост не должен вызывать резких приступов аллергии. Мы упомянем ООП лишь один раз в конце, но спроектировать приложение нам это не помешает.
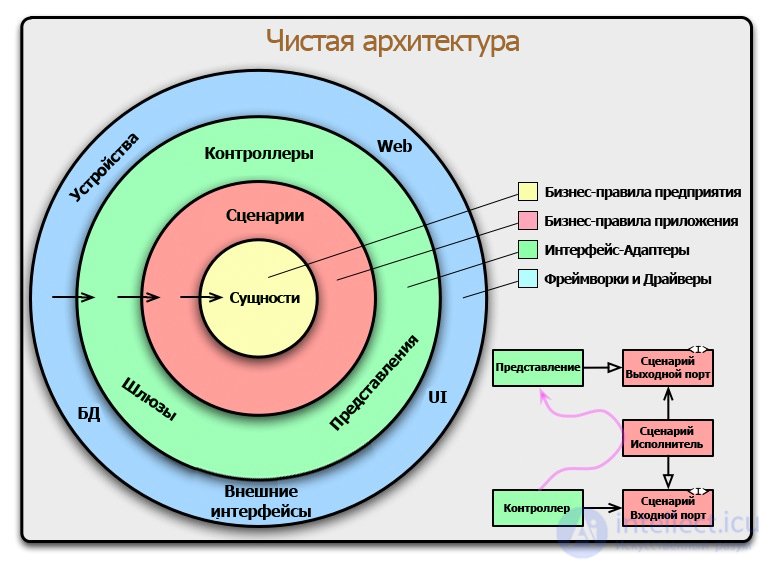
За последние несколько лет мы видели целый ряд идей относительно архитектуры систем. Каждая из них на выходе давала:
Диаграмма в начале этой статьи — попытка объединить все эти идеи в единую эффективную схему.
Концентрические круги на диаграмме представляют собой различные слои программного обеспечения. В общем случае, чем дальше вы идете, тем более общим становится уровень. Внешние круги — механика. Внутренние круги — политика.
Главным правилом, делающим эту архитектуру работающей является Правило Зависимостей. Это правило гласит, что зависимости в исходном коде могут указывать только во внутрь. Ничто из внутреннего круга не может знать что-либо о внешнем круге, ничто из внутреннего круга не может указывать на внешний круг. Это касается функций, классов, переменных и т.д.
Более того, структуры данных, используемых во внешнем круге не должны быть использованы во внутреннем круге, особенно если эти структуры генерируются фреймворком во внешнем круге. Мы не используем ничего из внешнего круга, чтобы могло повлиять на внутренний.
Сущности определяются бизнес-правилами предприятия. Сущность может быть объектом с методами или она может представлять собой набор структур данных и функций. Не имеет значения как долго сущность может быть использована в разных приложениях.
Если же вы пишете просто одиночное приложение, в этом случае сущностями являются бизнес-объекты этого приложения. Они инкапсулируют наиболее общие высокоуровневые правила. Наименее вероятно, что они изменятся при каких-либо внешних изменениях. Например, они не должны быть затронуты при изменении навигации по страницам или правил безопасности. Внешние изменения не должны влиять на слой сущностей.
В этом слое реализуется специфика бизнес-правил. Он инкапсулирует и реализует все случаи использования системы. Эти сценарии реализуют поток данных в и из слоя Cущностей для реализации бизнес-правил.
Мы не ожидаем изменения в этом слое, влияющих на Cущности. Мы также не ожидаем, что это слой может быть затронут внешними изменениями, таких как базы данных, пользовательским интерфейсом или фреймворком. Этот слой изолирован от таких проблем.
Мы, однако, ожидаем, что изменения в работе приложения повлияет на Cценарии. Если будут какие-либо изменения в поведении приложения, то они несомненно затронут код в данном слое.
Программное обеспечение в этом слое представляет собой набор адаптеров, которые преобразуют данные из формата наиболее удобным для Сценариев и Сущностей, в формат наиболее удобный для дальнейшего использования, например в БД. Именно это слой, например, будет полностью содержать архитектуру MVC. Модели являются скорее всего структурами данных, которые передаются от контроллеров к Сценариям, а затем обратно из Сценариев к Представлениям.
Точно так же, данные преобразуются, в этом слое, из формы наиболее удобным для Сценариев и Сущностей, в форму, наиболее удобной для постоянного хранения, например в базе данных. Код, находящийся внутри этого круга не должен знать что-либо о БД. Если БД — это SQL база данных, то любые SQL-инструкции не должны быть использованы на этом уровне.
Наружный слой обычно состоит из фреймворков, БД, UI и т.д. Как правило, в этом слое не пишется много кода, за исключением кода, который общается с внутренними кругами.
Это слой скопления деталей. Интернет — деталь, БД — деталь, мы держим эти штуки снаружи для уменьшения их влияния.
Нет, круги схематичны. Вы можете решить, что вам нужно больше, чем эти четыре. Нет правила, утверждающего, что вы должны всегда иметь только эти четыре. Тем не менее, Правило Зависимостей применяется всегда. Зависимости в исходном коде всегда указывают внутрь. По мере продвижения внутрь уровень абстракции возрастает. Внешний круг — уровень деталей. Внутренний круг является наиболее общим.
В нижней правой части диаграммы показан пример того, как мы пересекаем границы круга. Контроллеры и Представления взаимодействуют со Сценариями из следующего слоя. Обратите снимание на поток управления. Она начинается в Контроллере, движется через Сценарий, а затем завершает выполнение в Представлении. Обратите внимание на зависимости в исходном коде. Каждая из них указывает внутрь к Сценарию.
Обычно мы решаем это кажущееся противоречие с помощью Принципа Инверсии Зависимостей.
Например, предположим, что из Сценария нужно обратиться к Представлению. Однако, этот вызов обязан быть не прямым, чтобы не нарушать Правило Зависимостей — внутренний круг не знает ничего о внешнем. Таким образом Сценарий вызывает интерфейс (на схеме показан как Выходной Порт) во внутреннем круге, а Представление из внешнего круга реализует его.
Та же самая техника используется, чтобы пересечь все границы в архитектуре. Мы воспользуемся преимуществами динамического полиморфизма для создания зависимостей в исходном коде так, чтобы поток управления соответствовал Правилу Зависимостей.
Обычно данные, которые пересекают границы — это просто структуры данных. Вы можете использовать базовые структуры или, если хотите, Data Transfer Objects (DTO — один из шаблонов проектирования, используется для передачи данных между подсистемами приложения). Или данные могут быть просто аргументами вызова функций. Или вы можете упаковать его в хэш-таблицу или в объект. Важно, чтобы передаваемые структуры данных были изолированными при передаче через границы. Мы не хотим жульничать и передавать Сущность или строки БД. Мы не хотим, чтобы структуры данных имели какие-либо зависимости, нарушающие Правило Зависимостей.
Например, многие фреймворки (ORM) в ответ на запрос к БД возвращают данные в удобном формате. Мы могли бы назвать это RowStructure. Мы не хотим передавать эту структуру через границу. Это было бы нарушением Правила Зависимостей поскольку в этом случае внутренний круг получает информацию о внешнем круге.
Поэтому передача данных через границу всегда должна быть в формате удобном для внутреннего круга.
Designing is fundamentally about taking things apart... in such a way that they can be put back together. ...Separating things into things that can be composed that's what design is.
— Rich Hickey. Design Composition and Performance
Системный дизайн, говорит цитата в эпиграфе, — это разделение системы таким образом, чтобы ее можно было потом собрать снова. И главное — собрать легко, без лишних трудозатрат.
Я согласен: собирать домик из кубиков проще, чем разбивать большой валун на камешки. Но еще одной из целей грамотной архитектуры я считаю расширяемость системы. Требования к программе постоянно меняются. Мы хотим, чтобы программу было легко обновлять и дорабатывать под новые требования. Чистая архитектура может помочь этой цели достичь.
Чистая архитектура — это способ разделения ответственностей и частей функциональности по степени их близости к предметной области приложения.
Под предметной областью мы имеем в виду часть реального мира, которую моделируем программой. Это такие преобразования данных, которые отражают преобразования в реальном мире. Например, если мы обновили название товара, то замена старого имени на новое и есть доменное преобразование.
Чистую архитектуру часто называют трехслойной, потому что приложение в ней делится слои. В оригинальном посте о The Clean Architecture приводится диаграмма с выделенными слоями:
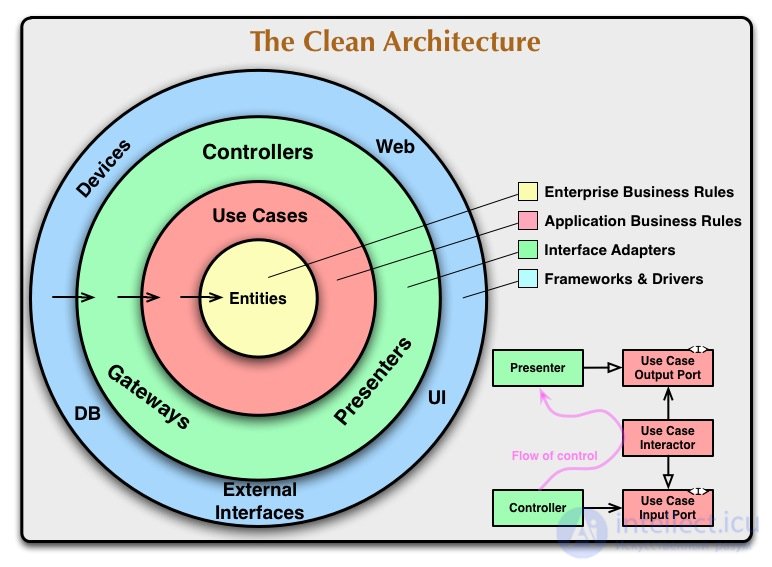
Диаграмма слоев по чистой архитектуре: в центре домен, вокруг него прикладной слой, и снаружи — слой адаптеров
В центре — доменный слой. Это те сущности и данные, которые описывают предметную область приложения, а также код для преобразования эти данных. Домен — это ядро, которое отличает одно приложение от другого.
О домене можно думать, как о том, что точно не поменяется, если мы будем переезжать с React на Angular, или если изменим какой-то пользовательский сценарий. В случае с магазином это товары, заказы, пользователи, корзина и функции для обновления их данных.
Структура данных доменных сущностей и суть их преобразований не зависит от внешних обстоятельств. Внешние обстоятельства запускают доменные преобразования, но не определяют, как они будут протекать.
Функции добавления товара в корзину неважно, как именно товар был добавлен: самим пользователем через кнопку «Купить» или автоматически по промо-коду. Она в обоих случаях будет принимать товар и возвращать обновленную корзину с добавленным товаром.
Вокруг домена расположен прикладной слой. В этом слое описываются юзкейсы — то есть пользовательские сценарии. Они отвечают за то, что происходит после возникновения какого-то события.
Например, сценарий «Положить товар в корзину» — это юзкейс. Он описывает действия, которые должны произойти после нажатия на кнопку. Это такой «оркестратор», который говорит:
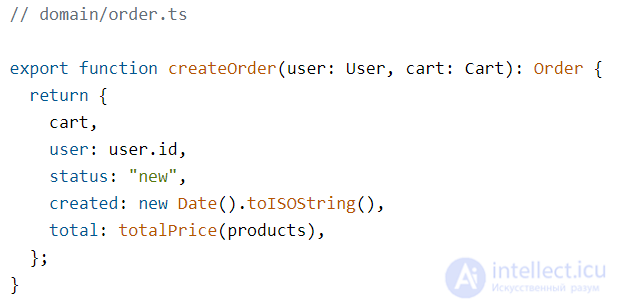
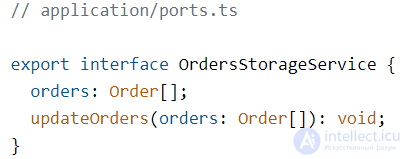
Также в прикладном слое находятся порты — спецификации того, как наше приложение хочет, чтобы с ним общался внешний мир. Обычно порт — это интерфейс, контракт на поведение.
Порты служат «буфером» между хотелками нашего приложения и реалиями внешнего мира. Входные порты (Input Ports) говорят, как приложение хочет, чтобы к нему обращались извне. Выходные порты (Output Ports) говорят, как приложение собирается общаться с внешним миром, чтобы тот был готов к этому.
Мы рассмотрим порты и их пользу более детально позже.
На самом внешнем слое находятся адаптеры ко внешним сервисам. Адаптеры нужны, чтобы превращать несовместимое API внешних сервисов в совместимое с хотелками нашего приложения.
Адаптеры — это отличный способ понизить зацепление между нашим кодом и кодом сторонних сервисов. Низкое зацепление уменьшает необходимость менять один модуль при изменении других.
Адаптеры часто делят на:
С управляющими адаптерами чаще всего взаимодействует пользователь. Например, обработка нажатия кнопки UI-фреймворком — это работа управляющего адаптера. Он работает с браузерным API (по сути сторонним сервисом) и преобразует событие в понятный нашему приложению сигнал.
Управляемые адаптеры взаимодействуют с инфраструктурой. Во фронтенде большая часть инфраструктуры — это бекенд-сервер, но иногда мы можем взаимодействовать и с какими-то другими сервисами напрямую, например, с поисковым движком.
Обратите внимание, чем дальше мы от центра — тем функциональность кода более «сервисная», тем дальше она от предметной области нашего приложения. Это будет важно позже, когда мы будем принимать решение, к какому слою отнести какой-либо модуль.
У трехслойной архитектуры есть правило зависимостей: только внешние слои могут зависеть от внутренних. Это значит, что:
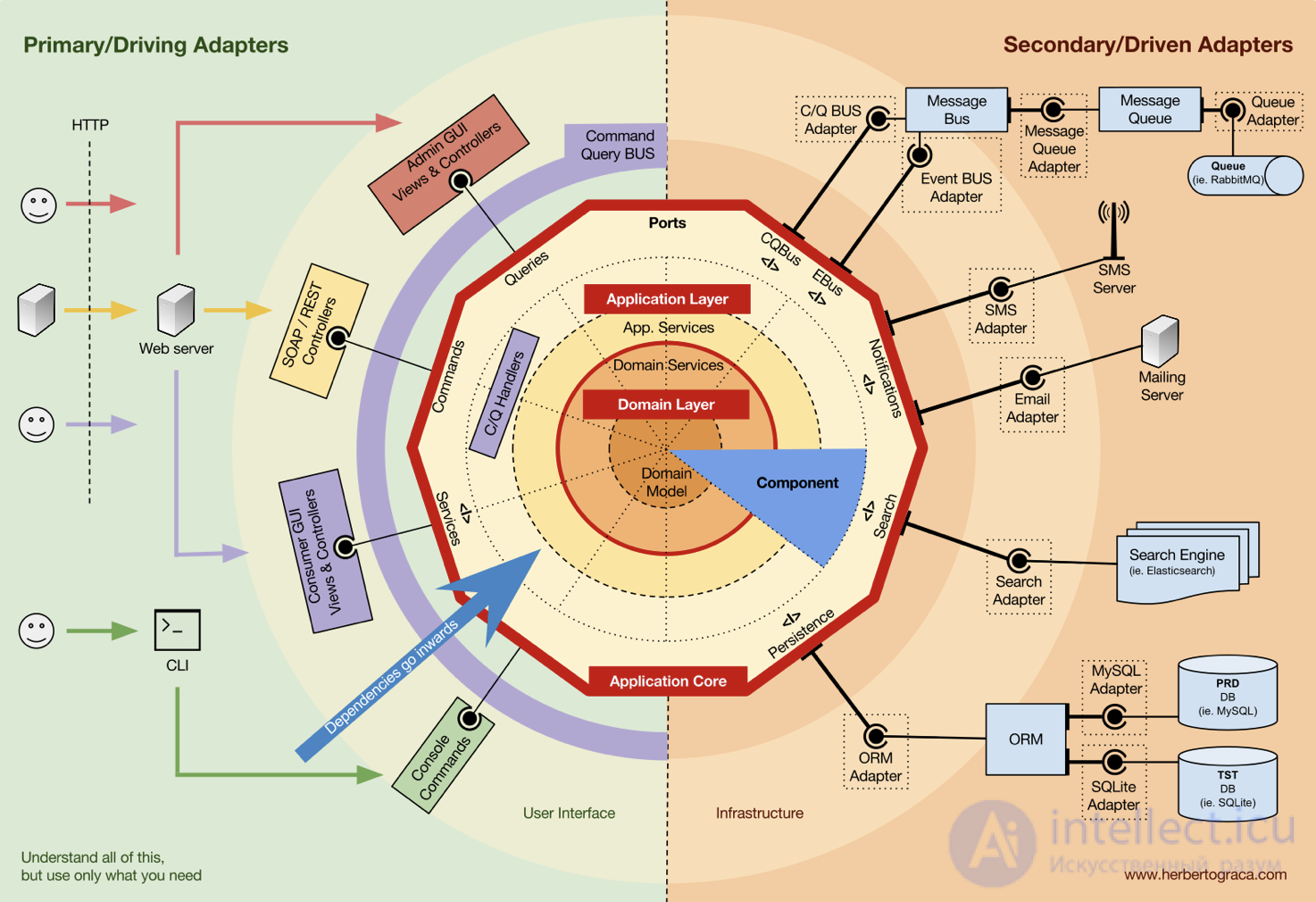
Внешние слои могут зависеть от внутренних, но не наоборот
Иногда этим правилом можно пренебречь, хотя лучше не злоупотреблять. Например, иногда бывает удобно в домене использовать какой-нибудь «полубиблиотечный» код, хотя по канонам там не должно быть никаких зависимостей. Об этом говорит сайт https://intellect.icu . Мы рассмотрим пример такого нарушения, когда доберемся до непосредственно кода, либо вы можете посмотреть описание репозитория, там я тоже немного об этом написал.
Беспорядочное направление зависимостей может приводить к сложному и запутанному коду. Например, нарушение правила зависимостей может приводить:
Теперь поговорим, что нам такое разделение кода дает. У него есть несколько преимуществ.
Вся главная функциональность приложения обособлена и собрана в одном месте — в домене. Функциональность в домене независима, а значит, ее проще тестировать. Чем меньше у модуля зависимостей, тем меньше нужно инфраструктуры для тестирования, меньше нужно моков и стабов.
Также обособленный домен проще проверять на соответствие ожиданиям бизнеса. Это помогает новым разработчикам быстрее сориентироваться с тем, что приложение должно делать. Кроме того, обособленный домен помогает быстрее искать ошибки и неточности «перевода» с языка бизнеса на язык программирования.
Сценарии приложения, юзкейсы описаны отдельно. Именно они диктуют, какие сторонние сервисы понадобятся. Мы подстраиваем внешний мир под свои нужды, а не наоборот — это дает больше свободы в выборе сторонних сервисов. Например, мы можем быстро поменять платежную систему, если нынешняя стала требовать слишком большую комиссию.
Также код юзкейсов получается плоским, тестируемым и расширяемым. Мы увидим это на примере позже.
Внешние сервисы становятся заменяемыми благодаря адаптерам. Пока мы не меняем интерфейс взаимодействия с приложением, нам не важно, какой именно внешний сервис будет реализовывать этот интерфейс.
Таким образом мы создаем барьер для распространения изменений: изменения в чужом коде не влияют напрямую на наш. Адаптеры также ограничивают и распространение ошибок во время работы приложения.
Архитектура — это в первую очередь инструмент. Как у любого инструмента у чистой архитектуры кроме выгод есть и издержки.
Главная издержка — это время. Оно понадобится не только на проектирование, но и на реализацию, потому что всегда проще вызвать сторонний сервис напрямую, чем писать адаптеры.
Продумывать взаимодействие всех модулей системы заранее тоже трудно, потому что мы можем не знать заранее всех требований и ограничений. При проектировании нужно держать в уме, как система может измениться, и оставлять пространство для расширения.
В целом каноническое воплощение чистой архитектуры — это не всегда удобно, а иногда даже вредно. Если проект небольшой, то полная реализация будет оверхедом, который увеличит порог входа для новичков.
Может понадобиться идти на компромиссы при проектировании, чтобы не выходить за рамки бюджета или срок. Я покажу на примере, что именно подразумеваю под подобными компромиссами.
Полная реализация чистой архитектуры может увеличить порог входа и выгнуть кривую обучения, потому что любой инструмент требует знания, как им пользоваться.
Если наоверинжинирить на старте проекта, то потом труднее будет онбордить новых разработчиков. Надо держать это в уме и следить за простотой кода.
Конкретно фронтендовая проблема в том, что чистая архитектура может увеличить количество кода в финальном бандле. Чем больше кода мы отдадим браузеру, тем больше ему скачивать, парсить и интерпретировать.
За количеством кода придется следить и принимать решения о том, где срезать углы:
Уменьшить количество времени и кода можно, если срезать углы и немного жертвовать каноничностью. Я вообще не фанат радикализма в подходах: если прагматичнее (выгоды > потенциальных издержек) нарушить правило, я его нарушу.
Так, можно подзабивать на некоторые аспекты чистой архитектуры до некоторого времени без видимых проблем. Минимальное необходимое же количество ресурсов, которое точно стоит уделять при проектировании — это две вещи.
Именно выделенный доменный слой помогает разобраться, что мы вообще проектируем и как оно должно работать. По выделенному домену новым разработчикам проще разбираться с сутью приложения, его сущностями и отношениями между ними.
Даже если мы пропустим остальные слои и нафигачим в продакшен лапше-код, работать и рефакторить все равно будет проще с выделенным, не размазанным по кодовой базе доменом. Другие слои можно добавлять по мере необходимости.
Второе правило, от которого не стоит отказываться — правило зависимостей, а точнее их направление. Внешние сервисы должны подстраиваться под нас и никогда наоборот.
Если вы чувствуете, что «дорабатываете напильником» свой код, чтобы он мог вызывать API поиска — что-то не так. Лучше напишите адаптер, пока проблема не пустила метастазы.
Теперь, когда мы поговорили о теории, можно приступить к практике. Давайте для примера спроектируем архитектуру магазина печенек.
Магазин будет продавать разные виды печенек, у которых может отличаться состав. Пользователи будут выбирать печеньки и заказывать их, а оплачивать заказы в стороннем платежном сервисе.
На главной будет витрина с печеньками, которые мы можем купить. Купить печеньки мы сможем, только если будем аутентифицированы. Кнопка входа будет нас перебрасывать на страницу логина, где мы сможем залогиниться.

Главная страница магазина
После удачного логина мы сможем положить какие-то печеньки к себе в корзину.
Корзина с выбранными печеньками
Когда мы накидали печенек в корзину, можем оформить заказ. После оплаты получаем новый заказ в списке и очищенную корзину.
Оформление заказа — будет тем самым сценарием, который мы реализуем вместе. Код остальных юзкейсов вы сможете подсмотреть в исходниках.
Чтобы начать проектировать, сперва определимся, какие сущности, сценарии и функциональность в широком смысле у нас вообще будут. Затем определимся с тем, какому слою они должны принадлежать.
Самое важное в приложении — это домен. Именно в нем будут находиться главные сущности приложения и преобразования их данных. Я предлагаю начинать проектировать именно с него, чтобы максимально точно отразить предметную область магазина в коде.
К домену можно отнести:
Функции преобразования в домене должны зависеть только от правил предметной области и ни от чего еще. Такими функциями будут, например:
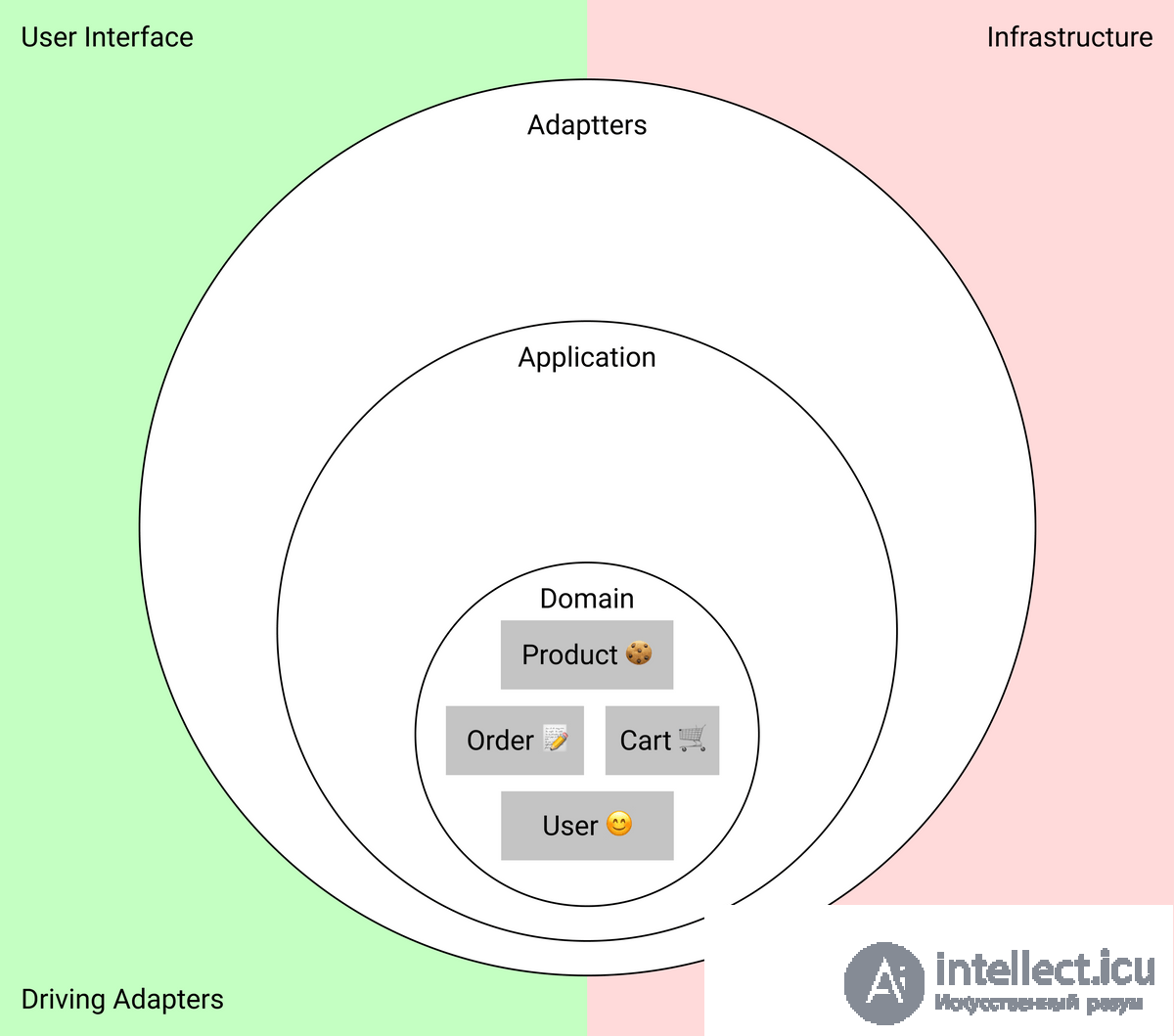
Диаграмма доменных сущностей во внутреннем слое
В прикладном слое находятся юзкейсы — пользовательские сценарии. У сценария всегда есть действующее лицо, обычно пользователь, действие и результат.
Мы, например, можем выделить:
Сценарии, как правило, описывают в понятиях предметной области. Например, сценарий «оформить заказ» на самом деле состоит из нескольких шагов:
Функция-юзкейс будет кодом, который описывает этот сценарий.
Также в прикладном слое находятся интерфейсы портов для общения с внешним миром.
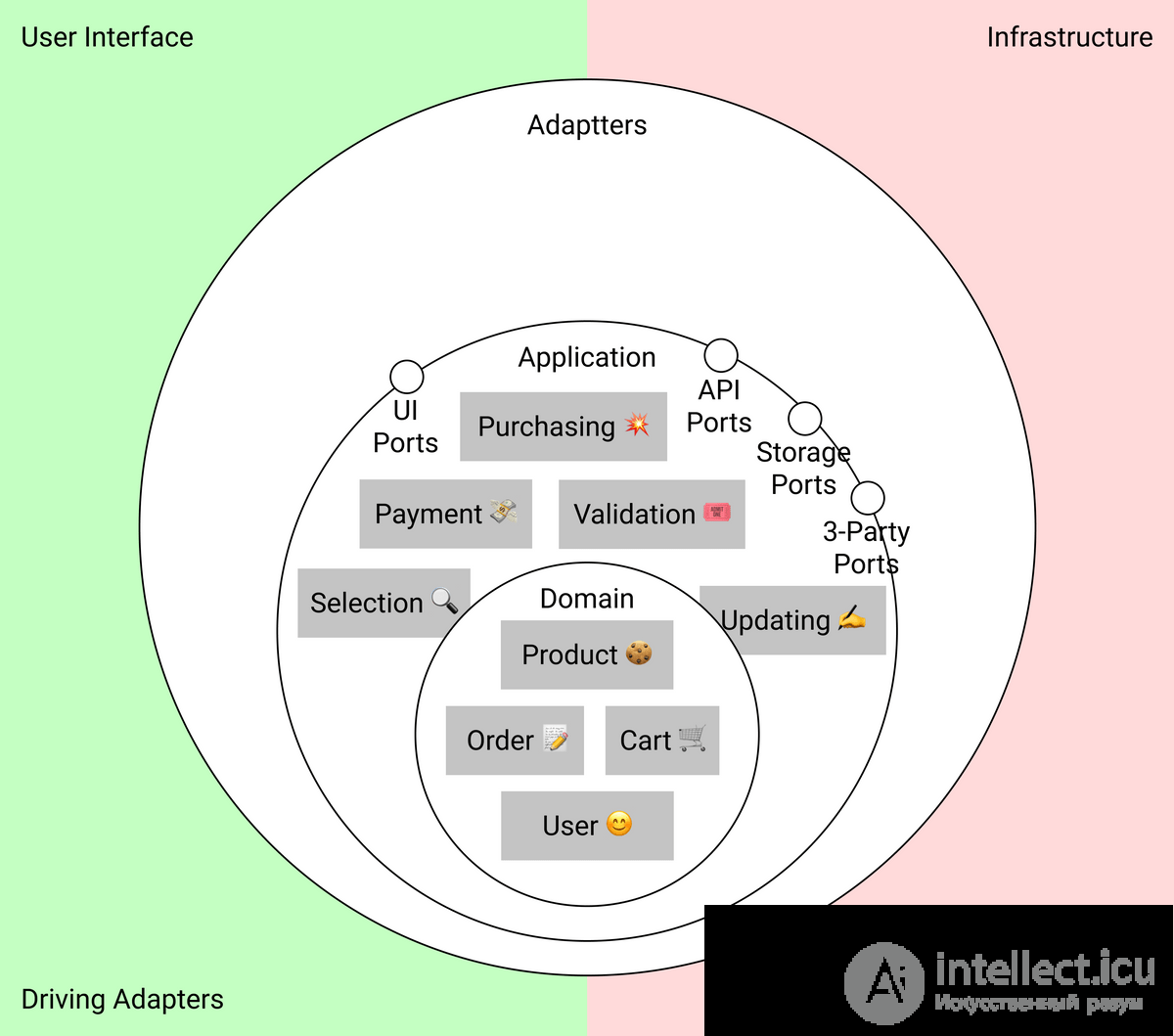
Диаграмма юзкейсов и портов в среднем слое
В слое адаптеров мы держим адаптеры ко внешним сервисам. Задача адаптеров — сделать несовместимое API сторонних сервисов совместимым с нашими хотелками.
Во фронтенде чаще всего это UI-фреймворк и модуль запросов к API-серверу. В нашем случае среди адаптеров мы выделим:
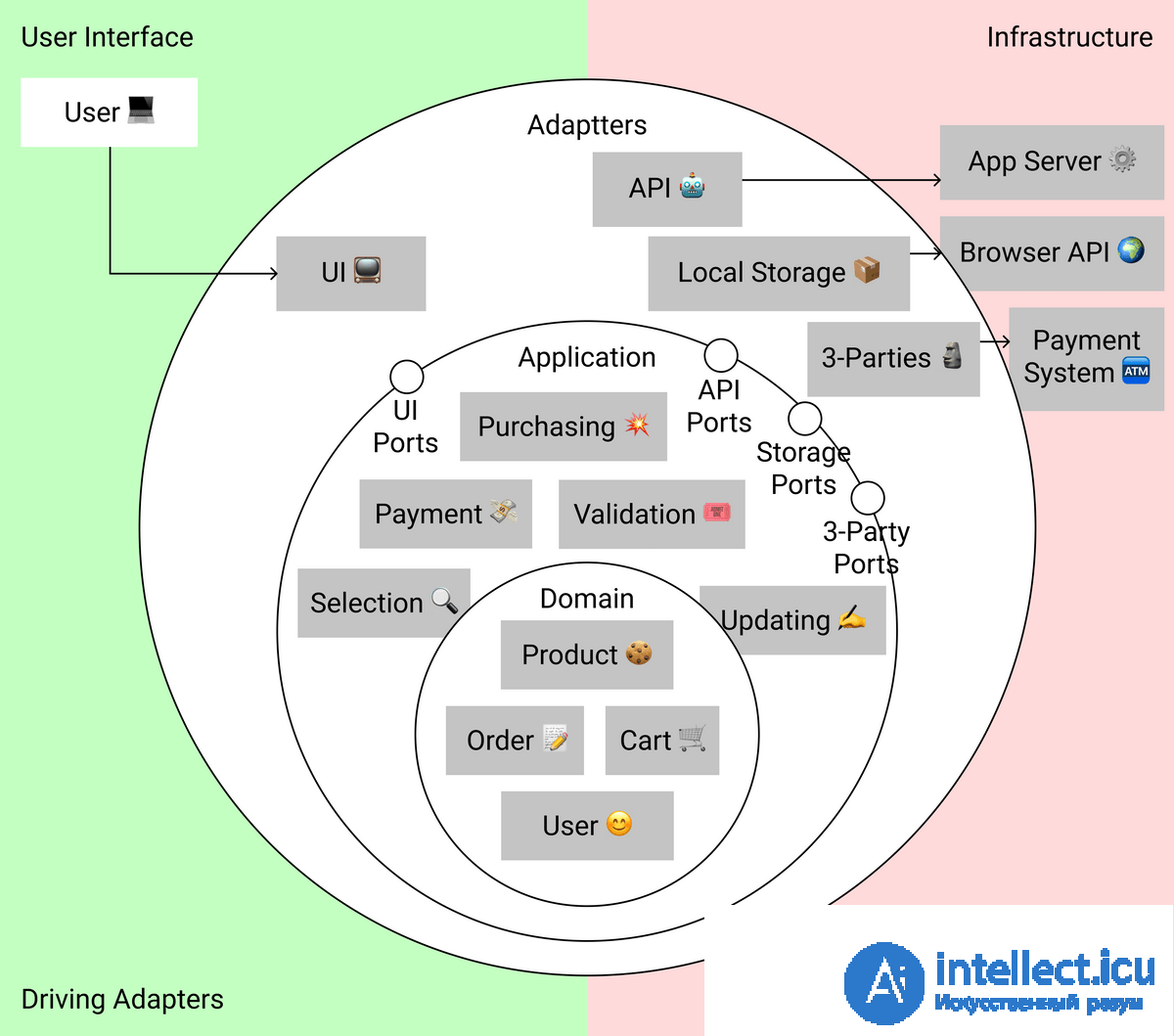
Диаграмма адаптеров с разделение на управляющие и управляемые
Заметьте, что чем более функциональность «сервисная», тем дальше она от центра диаграммы. Главная часть приложения находится в центре, именно домен содержит бизнес-логику и несет бизнесовую ценность, а все остальное — обслуживающий код.
Иногда бывает сложно сходу определиться, к какому слою отнести какой-то модуль или данные. Здесь может помочь небольшая (и неполная!) аналогия с MVC:
Идеи отличаются в деталях, но концептуально схожи, и для определения доменного и прикладного кода этой аналогией вполне можно пользоваться.
Когда мы определились с тем, какие сущности нам потребуется, можем приступить к определению того, как они себя ведут.
Чтобы не отвлекаться дальше, я сразу покажу структуру кода в проекте. Код для наглядности я делю по папкам-слоям.
Домен находится в domain/, прикладной слой — в application/, адаптеры — в services/. Об альтернативах такому разделению кода я расскажу в конце.
В домене у нас будет 4 модуля:
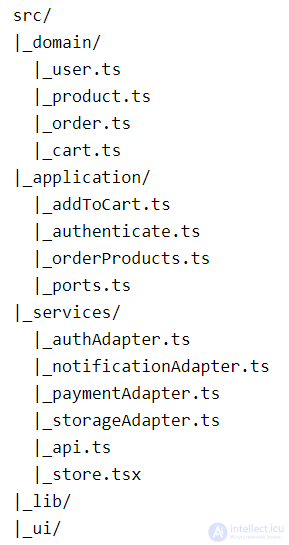
Главное действующее лицо — это пользователь. Мы будем хранить данные о пользователе в хранилище во время сессии. Эти данные мы хотим типизировать, поэтому создадим доменный тип пользователя.
Тип пользователя будет содержать идентификатор, имя, почту и списки предпочтений и аллергий.
Пользователи будут накидывать печеньки в корзину, добавим типы для корзины и товара. Товар будет содержать идентификатор, название, цену в копейках и список ингредиентов.
В корзине мы будем лишь держать список продуктов, которые пользователь положил в нее:
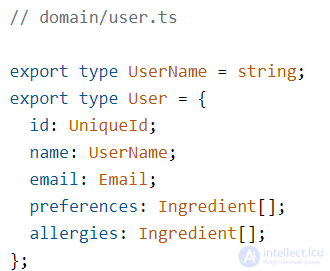
После успешной оплаты создается заказ с указанными печеньками, создадим сущность заказа.
Тип заказа будет содержать идентификатор пользователя, список заказанных продуктов, дата и время создания, статус и общую цену за весь заказ.
Польза проектирования типов сущностей в том, что уже сейчас мы можем проверить, насколько схема их отношений соответствует реальности:
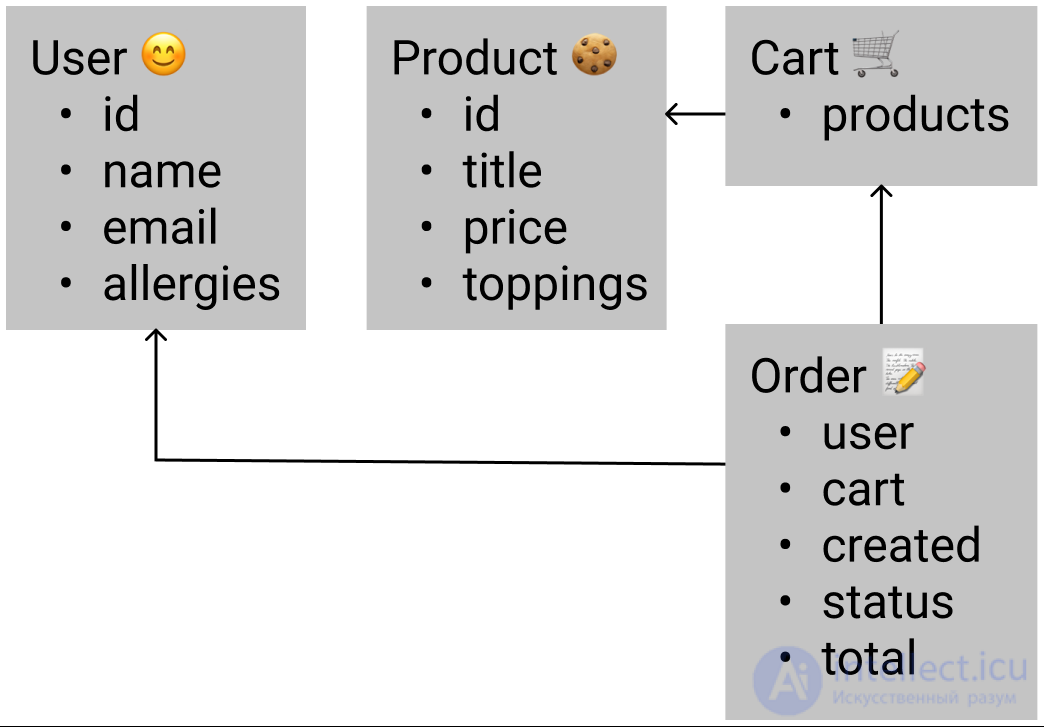
Диаграмма отношений сущностей
Мы можем убедиться, действительно ли главый актор — это пользователь, достаточно ли информации находится в заказе, нужно ли расширить какую-то сущность, будут ли проблемы с расширяемостью в будущем.
Также уже на этом этапе типы помогут подсветить ошибки с совместимостью сущностей друг с другом и направлением сигналов между ними.
Если все соответствует нашим ожиданиям, то мы можем приступать к проектированию доменных преобразований.
С данными, типы для которых мы только что спроектировали, будет происходить всякое. Мы будем добавлять товары в корзину, очищать ее, обновлять товары и имена пользователей и тому подобное. Для всех таких преобразований мы создадим отдельные функции.
Например, чтобы определить, есть ли у пользователя аллергия на какой-то ингредиент или предпочтение, мы можем написать функции hasAllergy и hasPreference:
Для добавления товаров в корзину и проверки, есть ли товар в корзине — функции addProduct и contains:
Еще нам понадобится подсчитывать общую цену списка товаров — напишем для этого функцию totalPrice. При желании мы можем добавить в эту функцию учет различных условий, типа промо-кодов или сезонных скидок.
Для того, чтобы пользователи могли оформлять заказы, мы добавим функцию createOrder. Она будет возвращать при вызове новый заказ, закрепленный за указанным пользователем.
Обратим внимание, что в каждой функции мы строим API так, чтобы нам было удобно преобразовывать данные. Мы принимаем аргумент и отдаем результат в том виде, в каком хочется и удобно.
На этапе проектирования домена внешних ограничений еще нет. Это позволяет отразить преобразования данных максимально близко к предметной области. А чем ближе преобразования к реальности, тем проще будет проверять работу.
Вы могли обратить внимание на некоторые типы, которые мы использовали при описании доменных типов. Например, Email, UniqueId или DateTimeString. Это тип-алиасы:
Обычно я использую тип-алиасы, чтобы избавиться от одержимости элементарными типами (primitive obsession).
Я использую не просто string, а DateTimeString, чтобы было понятнее, что именно за строка используется. Чем ближе тип к предметной области, тем проще будет разобраться с ошибками, когда они появятся.
Указанные типы находятся в файле shared-kernel.d.ts. Shared kernel — это такой код и данные, зависимость от которых не повышает зацепление (coupling) между модулями. Подробнее о понятии советую прочесть в “DDD, Hexagonal, Onion, Clean, CQRS, … How I put it all together”.
На практике shared kernel можно объяснить так. Мы используем сам TypeScript, используем его стандартную библиотеку типов, но не считаем это зависимостями. Все потому, что модули, которые его используют, могут ничего не знать друг о друге и оставаться расцепленными.
Не любой код можно отнести к shared kernel. Основное и самое главное ограничение — такой код должен быть совместимым с любой частью системы. Если часть приложения написана на TypeScript, а часть на другом языке, в shared kernel в может лежать только код, который может быть использован в обеих частях. Например, спецификации сущностей в формате JSON — подойдут, хелперы на TypeScript — уже нет.
В нашем случае все приложение написано на TypeScript, поэтому и тип-алиасы над встроенными типами тоже можно отнести к shared kernel. Такие доступные глобально типы не повышают зацепление между модулями и могут быть использованы в любой части приложения.
С доменом разобрались, можно приступить к прикладному слою. В этом слое находятся юзкейсы или пользовательские сценарии.
В коде юзкейсов мы описываем технические детали работы сценария. Что должно произойти с данными, после добавления товара в корзину или оформления заказа, — это юзкейс.
Юзкейсы предполагают взаимодействие с внешним миром, а значит — использование внешних сервисов. Взаимодействие со внешним миром — это сайд-эффекты. Мы знаем, что программировать и дебажить проще функции и системы без сайд-эффектов. Да и большая часть доменных функций у нас уже написана чистыми функциями. Чтобы подружить чистые преобразования и взаимодействие с «нечистым» миром, мы можем использовать прикладной слой как нечистый контекст.
Нечистый контекст для чистых преобразований — это такая организация кода, в которой:
На примере сценария «Положить товар в корзину» это бы выглядело так:
Получается такой «сендвич»: сайд-эффект, чистая функция, сайд-эффект. Главная логика отражена в преобразовании данных, а все общение с миром обособлено в императивной оболочке.

Функциональная архитектура: сайд-эффект, чистая функция, сайд-эффект
Нечистый контекст иногда называют функциональным ядром в императивной оболочке. Об этом в своем блоге писал Марк Зиманн. Мы будем использовать именно этот подход при написании функций юзкейсов.
Из всех сценариев приложения мы выберем и спроектируем сценарий оформления заказа. Он самый показательный, потому что асинхронный и дергает много сторонних сервисов. Напомню, что остальные сценарии и код всего приложения можно посмотреть на Гитхабе.
Подумаем, чего мы хотим добиться в интересующем юзкейсе. У пользователя есть корзина с печеньками, когда пользователь нажимает кнопку оформить заказ:
С точки зрения API и сигнатуры функции мы хотим передать пользователя и корзину аргументами, и чтобы функция сделала дальше все сама.
В идеале, конечно, юзкейс должен принимать не 2 отдельных аргумента, а команду, которая будет инкапсулировать все входные данные внутри себя. Но мы не хотим раздувать количество кода, поэтому оставим так.
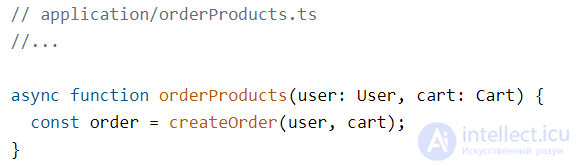
Рассмотрим поближе этапы юз-кейса: само создание заказа — это функция из домена. Все остальное — это внешние сервисы, которыми мы хотим воспользоваться.
Важно помнить, что именно внешние сервисы должны подстраиваться под наши нужды и не наоборот. Поэтому в прикладном слое мы опишем не только сам юзкейс, но еще и интерфейсы для этих внешних сервисов — порты.
Порты должны быть в первую очередь удобны нашему приложению. Если API внешних сервисов несовместимо с нашими хотелками, мы напишем адаптер.
Прикинем, какие именно сервисы нам понадобятся:

Необходимые сервисы для работы сценария
Обратите внимание, что сейчас мы говорим именно об интерфейсах этих сервисов, а не их реализации. На этом этапе нам важно описать требуемое поведение, потому что на это поведение мы будем рассчитывать в прикладном слое при описании сценария.
Как именно это поведение будет реализовано, нам пока не важно. Главное, чтобы реализация выполняла те гарантии, что описаны в интерфейсах. Это позволяет нам отложить решение о том, какие внешние сервисы использовать, до самого последнего момента — то есть делает код минимально зацепленным. Реализацией мы займемся позже.
Также обратите внимание, что интерфейсы мы делим по фичам. Все связанное с платежами — в одном модуле, связанное с хранилищем данных — в другом. Так будет проще следить за тем, чтобы функциональность разных сторонних сервисов не смешивалась. ISP во всей красе.
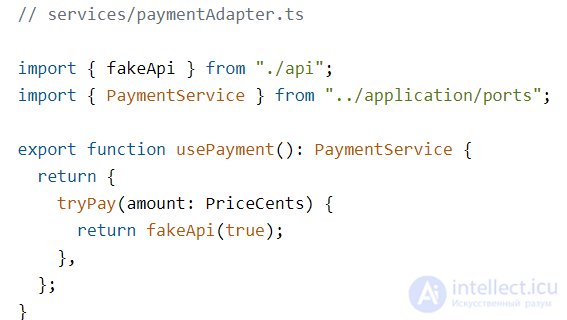
Магазин — это приложение-пример, поэтому платежная система будет предельно простой. У нее будет метод tryPay, который будет принимать количество денег, которое надо заплатить, а в ответ будет присылать подтверждение, что все нормально.
Ошибки обрабатывать не будем, потому что обработка ошибок — это тема для целого отдельного большого поста 😃
Да, обычно, оплату проводят на сервере, но это игрушечный пример, сделаем все на клиенте. Мы запросто могли бы вместо этого общаться с нашим API, а не с платежкой напрямую. Такое изменение, кстати, затронуло бы только этот юзкейс, остальной код остался бы нетронутым.
Если что-то при оплате пойдет не по плану, об этом надо сказать.
Пользователя уведомлять можно по-разному. Можно блочком в UI, можно письма слать, можно телефоном повибрировать (не надо, пожалуйста). В общем, сервису уведомлений бы тоже лучше быть абстрактным, чтобы сейчас не задумываться о реализации этих уведомлений.
Пусть принимает сообщение и как-то уведомляет пользователя:
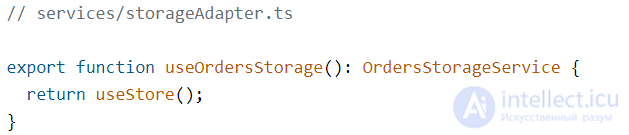
Сохранять новый заказ будем в локальном хранилище.
Этим хранилищем может быть что угодно: Redux, MobX, whatever-floats-your-boat-js. Хранилище может быть разделено на микро-сторы для разных сущностей или быть одним большим для всех данных приложения — сейчас это тоже не важно, потому что это детали реализации. Нам же важно спроектировать интерфейс.
Я люблю интерфейсы хранилищ делить на отдельные под каждую сущность. Отдельный интерфейс для хранилища данных о пользователе, отдельный — для корзины, отдельный — для хранилища заказов:
В примере здесь я привожу только интерфейс хранилища заказов, все остальные можно глянуть в исходниках.
Проверим, получится ли собрать сценарий, используя созданные интерфейсы и имеющуюся доменную функциональность. Как мы описывали ранее, сценарий будет состоять из следующих шагов:

Все шаги пользовательского сценария на схеме
Приступим к коду. Сперва объявим заглушки сервисов, которые собираемся использовать. TypeScript будет ругаться, что мы не реализовали интерфейсы в соответствующих переменных, но пока что это не важно.
Теперь мы можем использовать созданные заглушки, как будто это настоящие сервисы — обращаться к их полям, вызывать их методы. Это будет удобно при «переводе» сценария с языка предметной области на TypeScript.
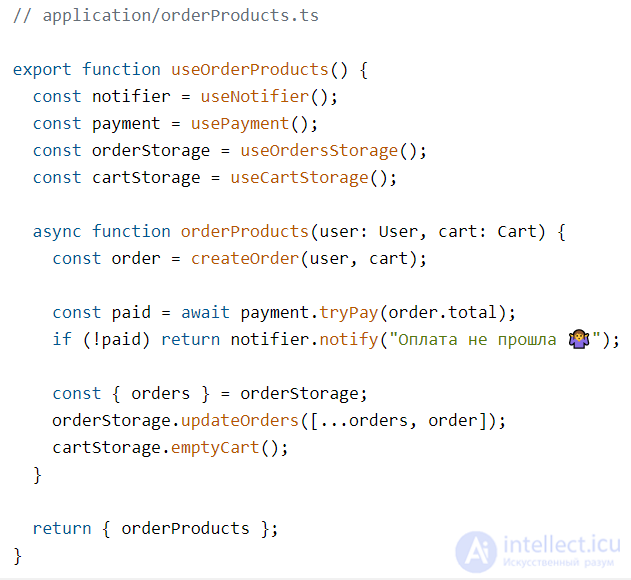
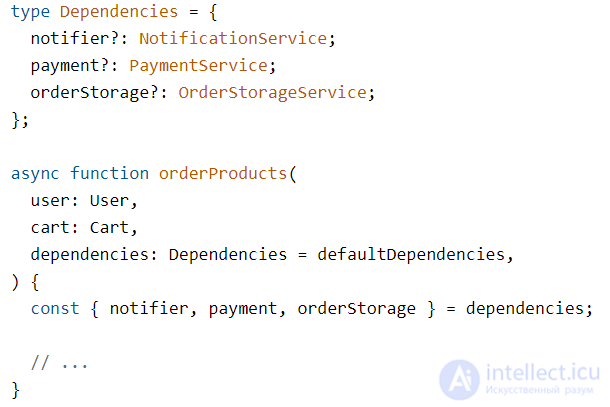
Создадим функцию-юзкейс orderProducts. Внутри первым делом создаем новый заказ:
Затем используем созданные заглушки, чтобы обратиться к нужным методам каждого сервиса. Здесь мы используем тот факт, что интерфейс — это гарантия, контракт на поведение. Это значит, что в будущем переменные-заглушки будут на самом деле выполнять те действия, на которые мы сейчас рассчитываем:
Обратим внимание, что юзкейс не вызывает сторонние сервисы напрямую. Он рассчитывает на поведение, описанное в интерфейсах, поэтому пока интерфейс остается тем же, нам не важно, какой модуль и как его реализовывает. Это делает модули заменяемыми.
Мы «перевели» сценарий на TypeScript. Теперь надо проверить, совпадает ли реальность с нашими хотелками из интерфейсов.
Обычно — нет, не совпадает. Поэтому мы подстраиваем внешний мир под свои нужды с помощью адаптеров.
Первый адаптер — это UI фреймворк или библиотека. Он связывает нативное браузерное API и приложение. В случае юзкейса создания заказа, это кнопка «Оформить заказ» и обработчик клика, который запустит функцию-юзкейс.
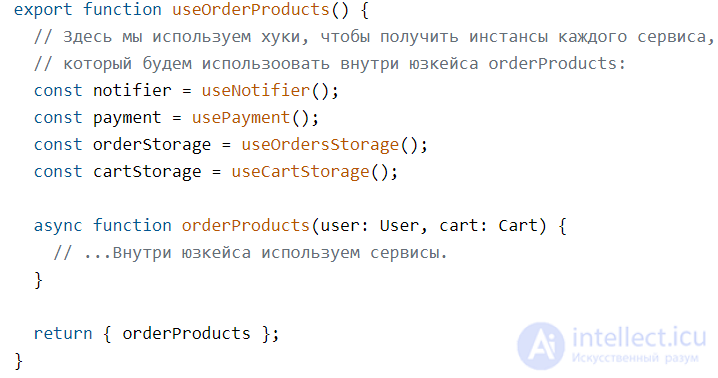
Сейчас модно писать на хуках, поэтому давайте предоставим юзкейс через хук. Внутри получим все сервисы, а как результат из хука вернем саму функцию юзкейса.
Мы, можно сказать, используем хуки, как «кустарное внедрение зависимостей». Сперва с помощью хуков useNotifier, usePayment, useOrdersStorage мы получаем инстансы сервисов, а затем используем замыкание функции useOrderProducts, чтобы они были доступны внутри функции orderProducts.
Важно отметить, что функция юзкейса все еще отделена от остального кода, что важно для тестирования. Мы вытащим ее полностью и сделаем ее еще более тестируемой в конце статьи, когда проведем ревью и рефакторинг.
Юзкейс использует интерфейс PaymentService. Напишем его реализацию.
Для оплаты воспользуемся фейковым API-заглушкой. Нас ничто не принуждает писать сервис сейчас, можно будет написать его позже, главное — реализовать указанное поведение:
Функция fakeApi — это таймаут, который срабатывает через 450 мс, имитируя задержку ответа от сервера. Возвращает он то, что мы передадим ему как аргумент.
Мы явно типизируем возвращаемое значение у usePayment. Так TypeScript проверит, что функция действительно возвращает объект, который содержит все объявленные в интерфейсе методы.
Пусть уведомления будут простым алертом. Так как код расцеплен, не будет проблем переписать и этот сервис позже.
Пусть хранилищем будет React.Context и хуки потому что я ленивый. Создадим контекст, передадим в провайдер значение и экспортнем провайдер и доступ к стору через хуки.
Хук для доступа ко хранилищу напишем отдельно под каждую фичу. Так мы не нарушим ISP, а сторы, как минимум в терминах интерфейсов, будут атомарными.
Также такой подход даст нам возможность настроить дополнительные оптимизации под каждый стор: селекторы, мемоизации и прочее.
Давайте теперь проверим, как будет происходить общение пользователя с приложением во время созданного сценария. На диаграмме покажем какие данные будут поступать, откуда и куда идти.

Диаграмма потоков данных сценария
Пользователь взаимодействует с UI-слоем, который может обращаться к приложению только посредством портов. То есть мы можем поменять UI, если захотим.
Сценарии обрабатываются в прикладном слое, который говорит, как именно с ним могут взаимодействовать внешние сервисы, которые могут понадобиться. Вся главная логика и данные находятся в домене.
Все внешние сервисы спрятаны в инфраструктуре и подчиняются нашим спецификациям. Если нужно будет поменять сервис отправки сообщений, единственное, что нужно будет поправить в коде — это адаптер для нового сервиса.
Такая схема делает код заменяемым, тестируемым и расширяемым под меняющиеся требования.
В целом, для старта и начального понимания чистой архитектуры прочитанного уже достаточно. Но мне хочется обратить внимание на вещи, которые я упростил, чтобы облегчить повествование. Этот раздел необязательный, но даст расширенное понимание того, как выглядит код, устроенный по чистой архитектуре, «без срезанных углов».
Я бы выделил несколько вещей, которые режут глаза и которые можно улучшить.
Вы могли заметить, что я использую число для описания цены. Это не очень хорошая практика.
Число указывает лишь количество, но не указывает валюту, а цена без валюты смысла не имеет. По-хорошему, цену стоит сделать объектом с двумя полями: значением и валютой.
Это решит проблему с хранением валюты и сэкономит много сил и нервов при изменении или добавлении валют в магазине. Я не использовал этот тип в примерах, чтобы не усложнять их. В реальном же коде цена была бы похожа на этот тип.
Отдельно стоит сказать о значении цены. Я всегда держу количество денег в самой маленькой доли валюты, которая находится в обращении. Например, для рубля — это копейки, для доллара — центы.
Такое отображение цены позволяет не задумываться о делении и дробных значениях. С деньгами это особенно важно, если мы хотим избежать проблем с плавающей точкой и дробными ценами.
Код можно компоновать и располагать в папках не «по слоям», а «по фичам». Одна «фича» будет куском пирога со схемы ниже. Такое разделение даже предпочтительнее, потому что позволяет деплоить отдельно именно фичи, а это часто бывает полезно.
Компонент — это кусок гексагонального пирога
О том, как делить код на подобные компоненты, советую прочесть в “DDD, Hexagonal, Onion, Clean, CQRS, … How I put it all together” — там объясняется и польза, и издержки деления. А еще советую посмотреть на Feature Sliced, который концептуально очень похож на компонентное деление кода, но проще для понимания.
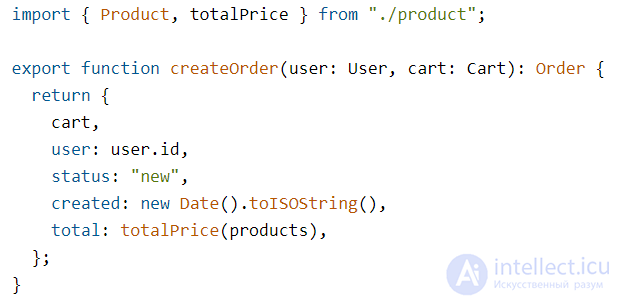
Если мы заговорили о делении на компоненты, стоит упомянуть и кросс-компонентное использование кода. Вспомним функцию создания заказа:
Эта функция использует totalPrice из «другого компонента» — продукта. Само по себе такое использование — это нормально, но если мы хотим делить код на независимые фичи, то обращаться напрямую к функциональности другой фичи будет нельзя.
Способы обойти это ограничение также можно подсмотреть в “DDD, Hexagonal, Onion, Clean, CQRS, … How I put it all together” и Feature Sliced.
Для shared kernel я использовал тип-алиасы. Они хороши тем, что ими просто оперировать: достаточно создать новый тип и сослаться например, на строку. Но их минус в том, что в TypeScript нет механизма следить за их использованием и энфорсить его.
Кажется, что это не проблема: ну использует кто-то string вместо DateTimeString — что с того? код же соберется.
Проблема именно в том, что код соберется, хотя использован более широкий тип (умными словами ослаблено предусловие). Это в первую очередь делает код более хрупким, потому что позволяет использовать любые строки, а не только строки специального качества, что может привести к ошибкам.
Ну а во вторую очередь это сбивает с толку при чтении, потому что создает два источника правды. Непонятно, действительно там нужно использовать только дату или можно в принципе любые строки.
Есть способ заставить TypeScript понимать, что мы хотим конкретный тип — использовать брендирование, branded types. Брендирование дает возможность следить за тем, как именно типы используются, но делает код чуть более сложным.
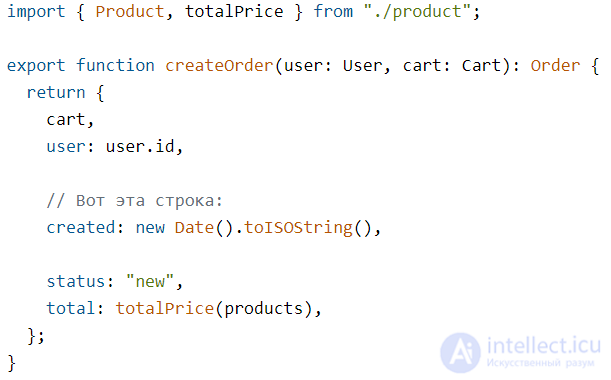
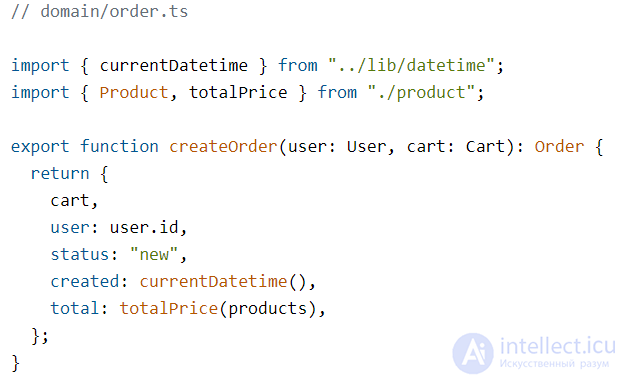
Следующий момент, который режет глаз — это создание даты в домене в функции createOrder:
Есть подозрение, что new Date().toISOString() будет довольно часто повторяться в проекте и хочется вынести это в «хелпер»:
...А потом использовать в домене:
Но мы тут же вспомним, что в домене зависеть ни от чего нельзя — как же быть? По-хорошему, createOrder должна принимать данные для заказа в уже готовом виде, дату можно передать последним аргументом:
Это же позволяет не нарушать правило зависимостей в случаях, когда создание даты зависит от библиотек. Если дату мы создаем «снаружи» доменной функции, то скорее всего эта дата будет создана внутри юзкейса и передана как аргумент:
Таким образом домен останется независимым, и к тому же его будет проще тестировать.
В примерах я решил не заострять на этом внимание по двум причинам: это бы отвлекало от сути, и я не вижу ничего плохого в том, чтобы зависеть от собственного хелпера, который использует только возможности языка. Такие хелперы можно даже отнести в shared kernel проекта, потому что они лишь уменьшают дублирование кода.
А вот что в создании даты внутри функции createOrder было действительно не очень хорошо — это сайд-эффект. Проблема сайд-эффектов в том, что они делают систему менее предсказуемой, чем хотелось бы. Справляться с этим помогают чистые преобразования в домене, то есть такие, которые не производят сайд-эффектов.
Создание даты — это сайд-эффект, потому что в разное время результат вызова Date.now() разный. Чистая же функция при одинаковых аргументах всегда возвращает одинаковый результат.
Я пришел к выводу, что домен лучше держать настолько чистым, насколько это возможно. Так его проще тестировать, проще переносить и обновлять, проще читать. Сайд-эффекты резко увеличивают когнитивную нагрузку при отладке, а домен — это совсем не то место, где стоит держать сложный и запутанный код.
В этом маленьком примере Order включает в себя корзину, потому что корзина представляет только список продуктов:
Это может не подойти, если в корзине будут дополнительные свойства, которые к заказу никак не относятся. В таких случаях лучше использовать проекции данных или промежуточные DTO.
Как вариант, можно использовать сущность «Списка продуктов»:
В юзкейсе тоже есть что обсудить. Сейчас функцию orderProducts сложно протестировать в отрыве от React — это плохо. В идеале его должно быть можно протестировать минимальным количеством усилий.
Проблема текущей реализации в хуке, который предоставляет доступ к юзкейсу в UI:
В каноническом исполнении функция юзкейса была бы вынесена за пределы хука, а сервисы были бы переданы юзкейсу через последний аргумент или с помощью DI:
Хук в этом случае превратился бы в адаптер:
Тогда код хука можно было бы отнести к адаптерам, а в прикладном слое остался бы только юзкейс. Функцию orderProducts можно будет протестировать, передав в качестве зависимостей моки необходимых сервисов.
Подробнее о том, как писать тесты для таких случаев и как рефакторить код, чтобы его былоо удобнее тестировать, я рассказывал в воркшопе по тестированию React-приложений. Предупреждаю, он длинный, но посмотреть стоит 😃
Там же в прикладном слое мы сейчас «внедряем» сервисы руками:
Но вообще это может быть автоматизировано и сделано через внедрение зависимостей. Мы уже рассмотрели простейший вариант «внедрения» через последний аргумент, но можно пойти дальше и настроить автоматическое внедрение.
Конкретно в этом приложении, я посчитал, что настраивать DI особо смысла нет. Это бы отвлекало от сути и переусложнило код. Да и в случае с React и хуками мы можем использовать их, как «контейнер», который возвращает реализацию указанного интерфейса. Да, это ручная работа, но зато не увеличивает порог входа и быстрее считывается новичками.
Пример из поста рафинированный и намеренно простой. Понятно, что жизнь куда удивительнее и запутаннее, чем этот пример. Поэтому хочется рассказать и о распространенных проблемах, которые могут возникнуть при работе по чистой архитектуре.
Самая главная проблема — это предметная область, о которой нам не достает знаний. Представьте, что в магазине есть товар, товар по акции и списанный товар. Как правильно описать эти сущности?
Должна ли быть «базовая» сущность, которую будут расширять? Как именно расширять эту сущность? Должны ли быть дополнительные поля? Надо ли делать эти сущности взаимоисключающими? Как должны себя вести юзкейсы, если вместо простого товара там будет другой? Надо ли сразу уменьшать дублирование?
Вопросов может быть слишком много, а ответов может не быть, потому что никто из команды и стейкхолдеров не знает, как себя должна на самом деле вести система. Если есть только предположения, то придется принимать решение, находясь в параличе анализа, что очень трудно.
Конкретные решения зависят от конкретной ситуации, я могу лишь порекомендовать несколько общих штук.
Не используйте наследование, даже если оно называется «расширением», даже если кажется, что интерфейс действителньо наследуется, даже если кажется, что «ну тут же явно иерархия». Просто подождите.
Копипаста в коде не всегда зло, это инструмент. Сделайте две почти одинаковые сущности, посмотрите, как они себя ведут в реальности, понаблюдайте за ними. В какой-то момент вы заметите, что они либо стали очень разными, либо они действительно отличаются лишь одним полем. Смержить две похожие сущности в одну — проще, чем обмазывать код условиями проверки под каждый возможный вариант.
Если все же приходится что-то расширять...
Помните о ковариантности, контравариантности и инвариантности, чтобы случайно не придумать себе больше работы, чем следовало бы.
Используйте аналогию с блоками и модификаторами из БЭМ при выборе между разными сущностями и расширениями. Мне очень помогает определить, отдельная передо мной сущность или «модификатор-расширение», если я думаю о ней в контексте БЭМ.
Вторая большая проблема — это связанные друг с другом пользовательские сценарии, когда событие из одного сценария запускает другой.
Единственный способ бороться с этим, который я знаю и который помогает мне, — это дробить сценарии на более мелкие, атомарные. Пусть они даже называются не «пользовательскими», но зато их будет проще скомпоновать.
Вообще, проблема таких сценариев, — это следствие другой большой проблемы в программировании, композиции сущностей. О том, что делать, чтобы эффективно компоновать сущности, написано уже много и даже есть целый раздел математики. Мы туда далеко заходить не будем, это тема для отдельного поста.
В этом посте я законспектировал и немного расширил свой доклад о чистой архитектуре во фронтенде.
Это не золотой эталон, а скорее компиляция опыта работы в разных проектах, парадигмах и языках. Мне это кажется удобной схемой, которая позволяет расцепить код и сделать независимые слои, модули, сервисы, которые не только можно разворачивать и паблишить отдельно, но и переносить из проекта в проект, если понадобится.
Мы не затрагивали ООП, так как архитектура и ООП вещи ортогональные. Да, архитектура говорит о композиции сущностей, но она не диктует что именно должно быть юнитом композиции: объект или функция. Работать с этой схемой можно в разных парадигмах, что мы и посмотрели в примерах.
Про ООП я только скажу, что недавно писал пост о том, как использовать чистую архитектуру вместе с ООП. Если вас заинтересовала тема архитектуры и у вас нет аллергии на ООП, то тоже советую посмотреть. В посте мы пишем генератор картинок деревьев на канвасе.
Чтобы посмотреть, как именно можно совмещать этот подход с остальными крутыми штуками типа нарезки по фичам, гексагональной архитектуры, CQS и прочим, советую посмотреть на DDD, Hexagonal, Onion, Clean, CQRS, … How I put it all together и весь цикл статей из этого блога. Очень толково, кратко и по делу.
Исследование, описанное в статье про чистая архитектура, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое чистая архитектура и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Разработка программного обеспечения и информационных систем
























Комментарии
Оставить комментарий
Разработка программного обеспечения и информационных систем
Термины: Разработка программного обеспечения и информационных систем