Лекция
Привет, Вы узнаете о том , что такое чистая архитектура и ddd, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое чистая архитектура и ddd , настоятельно рекомендую прочитать все из категории Разработка программного обеспечения и информационных систем.
При создании приложения самая простая часть - создать что-то, что работает. Построить что-то производительное, несмотря на обработку огромного количества данных, немного сложнее. Но самая большая проблема - создать приложение, которое можно было бы поддерживать в течение многих лет (10, 20, 100 лет).
Большинство компаний, в которых я работал, перестраивали свои приложения каждые 3-5 лет, а некоторые даже 2 года. Это влечет за собой чрезвычайно высокие затраты, оказывает большое влияние на то, насколько успешно приложение и, следовательно, на то, насколько успешна компания, помимо того, что разработчикам крайне неприятно работать с беспорядочной базой кода и заставляет их уходить из компании. Серьезная компания с долгосрочным видением не может позволить себе ничего из этого, ни финансовых потерь, ни потери времени, ни потери репутации, ни потери клиента, ни потери таланта.
Отражение архитектуры и предметной области в кодовой базе имеет основополагающее значение для удобства сопровождения приложения и, следовательно, имеет решающее значение для предотвращения всех этих неприятных проблем.
Чистая архитектура - это то, как я рационализирую набор принципов и практик, защищаемых разработчиками, гораздо более опытными, чем я, и как я организую базу кода, чтобы она отражала и сообщала архитектуру и предметную область проекта.
В своем предыдущем посте я рассказал о том, как объединяю все эти идеи, и представил некоторую инфографику и диаграммы UMLish, чтобы попытаться создать своего рода концептуальную карту того, как я это думаю.
Однако как мы на самом деле применим это на практике в нашей кодовой базе ?!
В этом посте я расскажу о том, как я отражаю архитектуру и предметную область проекта в коде, и предложу общую структуру, которая, как мне кажется, может помочь нам спланировать ремонтопригодность.
В последних двух сообщениях этой серии я объяснил две ментальные карты, которые я использую, чтобы помочь себе думать о коде и организовать базу кода, по крайней мере, в моей голове.
Первый состоит из серии концентрических слоев, которые в конце нарезаются, чтобы составить доменные модули приложения, компоненты. На этой диаграмме направление зависимости идет внутрь, что означает, что внешние слои знают о внутренних слоях, но не наоборот.
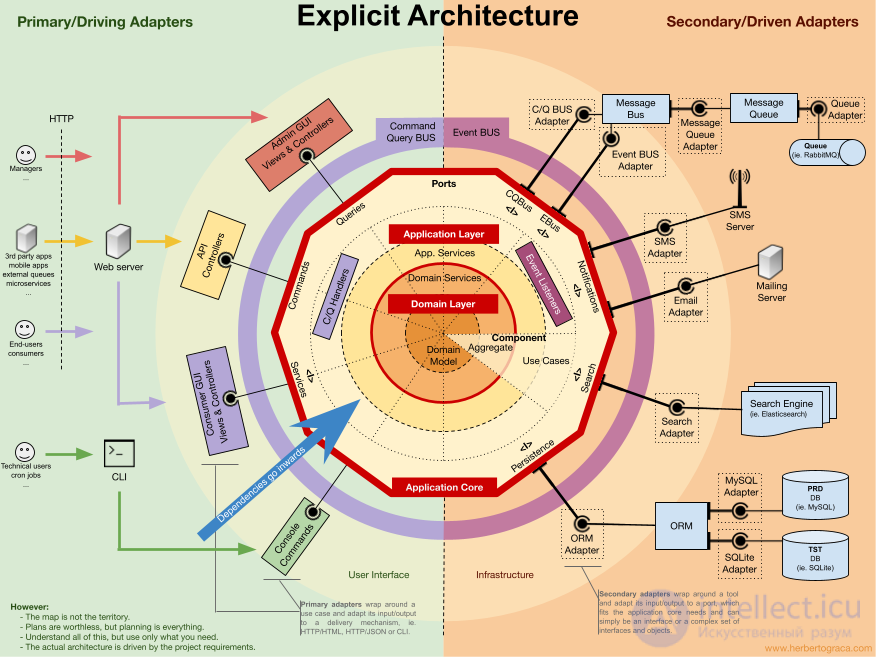
Второй - это набор горизонтальных уровней, где предыдущая диаграмма находится вверху, за ней следует код, совместно используемый компонентами (общее ядро), за которым следуют наши собственные расширения языков и, наконец, фактические языки программирования внизу. Здесь направление зависимостей идет вниз.
Использование архитектурно очевидного стиля кодирования означает, что наш стиль кодирования (стандарты кодирования, соглашения об именах классов, методов и переменных, структура кода и т. Д.) Каким-то образом связывает домен и архитектуру с тем, кто читает код. Есть две основные идеи о том, как достичь архитектурно очевидного стиля кодирования.
« […] Архитектурно очевидный стиль кодирования, который позволяет вам подсказывать читателям кода, чтобы они могли правильно сделать вывод о дизайне. ”
Джордж Фэрбенкс
Первый касается использования имен артефактов кода (классов, переменных, модулей,…) для передачи как предметной области, так и архитектурного значения. Итак, если у нас есть класс, который является репозиторием, имеющим дело с объектами счетов-фактур, мы должны назвать его как-то вроде `InvoiceRepository`, что сообщит нам, что он имеет дело с концепцией домена счета-фактуры и его архитектурная роль - роль репозитория. Это помогает нам знать и понимать, где он должен быть расположен, а также как и когда его использовать. Тем не менее, я думаю, что нам не нужно делать это с каждым артефактом кода в нашей кодовой базе, например, я считаю, что пост-исправление объекта с помощью Entity является избыточным и просто добавляет шум.
« […] Код должен отражать архитектуру. Другими словами, если я посмотрю на код, я смогу четко идентифицировать каждый из компонентов […] »
Саймон Браун
Второй - сделать поддомены чистыми как артефакты верхнего уровня нашей кодовой базы, как доменные модули, как компоненты.
Итак, первое должно быть ясным, и я не думаю, что он требует каких-либо дополнительных объяснений. Об этом говорит сайт https://intellect.icu . Однако второй вариант сложнее, так что давайте углубимся в него.
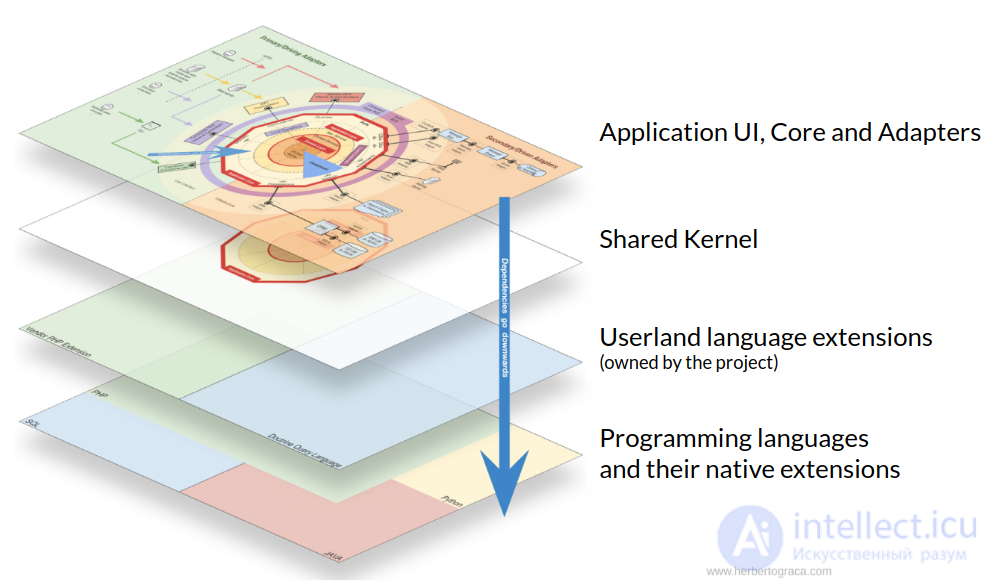
На моей первой диаграмме мы видели, что на самом высоком уровне масштабирования у нас есть 3 разных типа кода:
Итак, в корне нашей исходной папки мы можем отразить эти типы кода, создав 3 папки, по одной для каждого типа кода. Эти три папки будут представлять три пространства имен, и позже мы даже можем создать тест, чтобы убедиться, что и пользовательский интерфейс, и инфраструктура знают о ядре, но не наоборот, другими словами, мы можем проверить, идет ли направление зависимостей. внутренности.
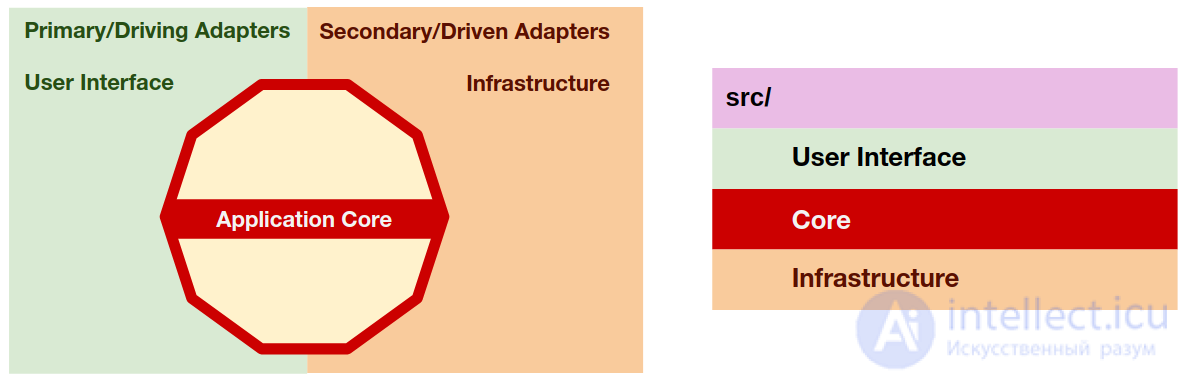
В корпоративном веб-приложении обычно есть несколько API, например REST API для клиентов, еще один для веб-хуков, используемых сторонними приложениями, возможно, устаревший SOAP API, который все еще нуждается в поддержке, или, может быть, GraphQL. API для нового мобильного приложения…
Для таких приложений также характерно наличие нескольких команд интерфейса командной строки, используемых заданиями Cron или операциями обслуживания по требованию.
И, конечно же, у него будет сам веб-сайт, которым пользуются обычные пользователи, но, возможно, еще один веб-сайт, используемый администраторами приложения.
Все это разные представления одного и того же приложения, все они представляют собой разные пользовательские интерфейсы приложения.
Таким образом, наше приложение может иметь несколько пользовательских интерфейсов, даже если некоторые из них используются только пользователями, не являющимися людьми (другие сторонние приложения). Давайте отразим это с помощью папок / пространств имен, чтобы разделить и изолировать несколько пользовательских интерфейсов.
В основном у нас есть 3 типа пользовательских интерфейсов, API, CLI и веб-сайты. Итак, давайте начнем с того, что сделаем это различие чистым внутри корневого пространства имен UserInterface , создав по одной папке для каждого из них.
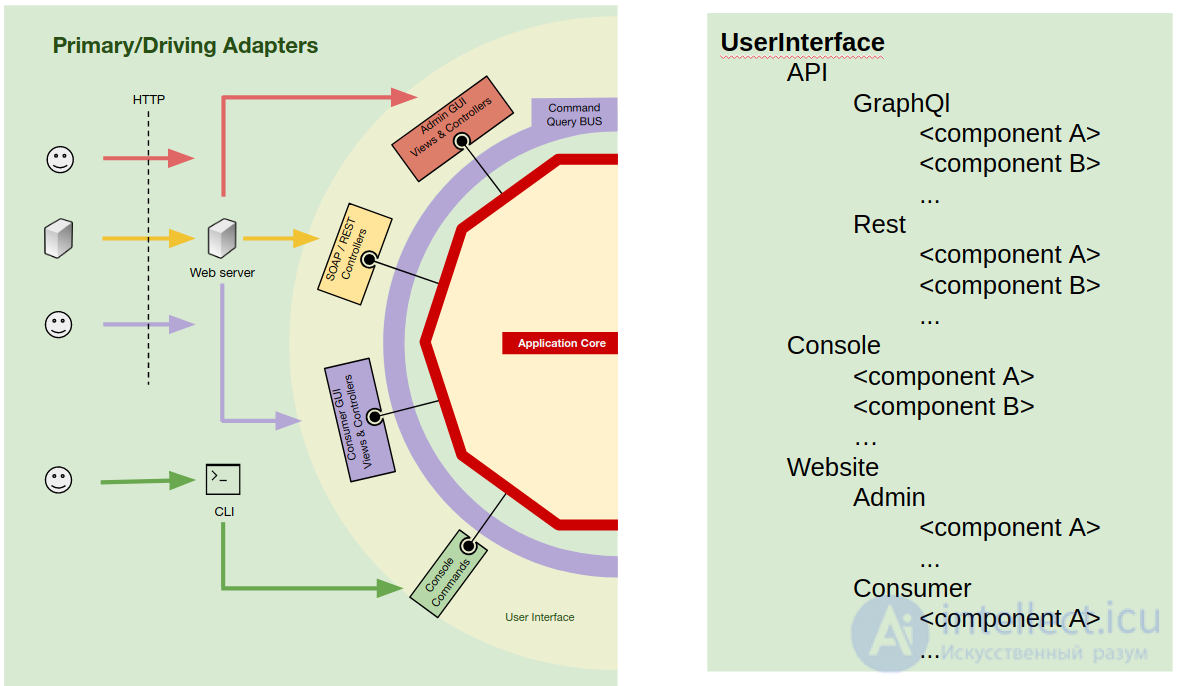
Затем мы углубляемся в пространство имен для каждого типа и, при необходимости, создаем пространство имен для каждого пользовательского интерфейса (возможно, для CLI нам это не нужно).
Подобно пользовательскому интерфейсу, наше приложение использует несколько инструментов (библиотеки и сторонние приложения), например ORM, очередь сообщений или провайдер SMS.
Более того, для каждого из этих инструментов может потребоваться несколько реализаций. Например, рассмотрим случай, когда компания расширяется в другую страну, и по соображениям ценообразования лучше использовать другого поставщика SMS в каждой стране: нам потребуются разные реализации адаптеров, использующие один и тот же порт, чтобы их можно было использовать взаимозаменяемо. Другой случай - это когда мы реорганизуем схему базы данных или даже переключаем механизм БД и нам нужно (или решаем) также переключиться на другой ORM: тогда у нас будет 2 адаптера ORM, подключенных к нашему приложению.
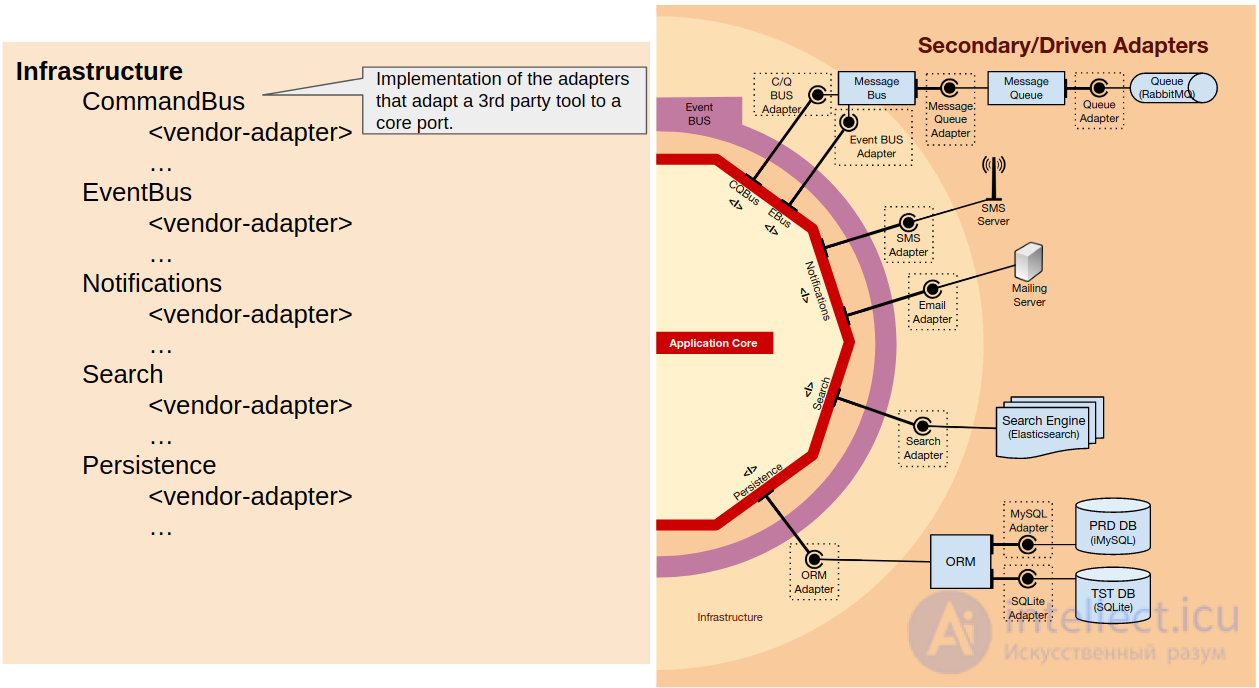
Итак, в пространстве имен инфраструктуры мы начинаем с создания пространства имен для каждого типа инструмента (ORM, MessageQueue, SmsClient), и внутри каждого из них мы создаем пространство имен для каждого из адаптеров поставщиков, которые мы используем (Doctrine, Propel, MessageBird, Twilio ,…).
В ядре, на самом высоком уровне масштабирования, у нас есть три типа кода: компоненты , общее ядро и порты . Итак, мы создаем папки / пространства имен для всех из них.
В пространстве имен Components мы создаем пространство имен для каждого компонента, и внутри каждого из них мы создаем пространство имен для уровня приложения и пространство имен для уровня домена. Внутри пространств имен Application и Domain мы начинаем с того, что просто выгружаем туда все классы, и по мере роста количества классов мы начинаем группировать их по мере необходимости (я считаю чрезмерным рвением создавать папку, чтобы поместить в нее только один класс, поэтому я предпочитаю это по мере необходимости).
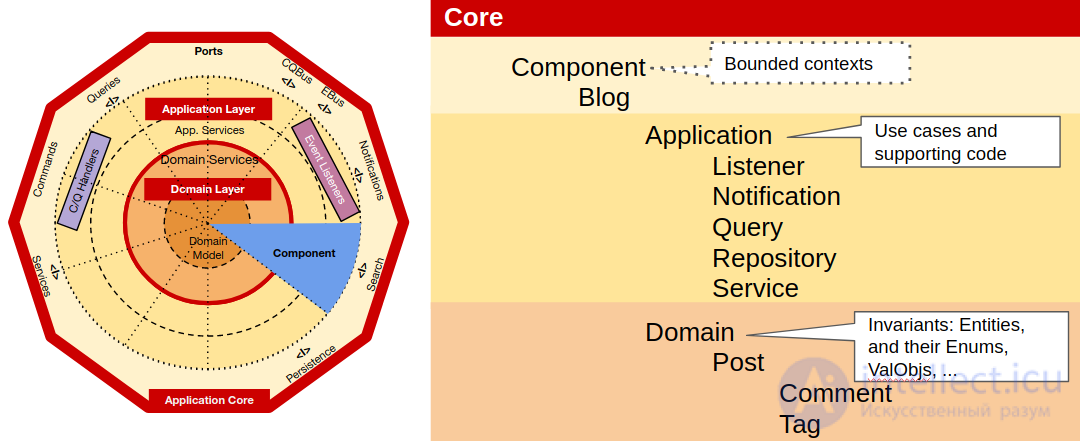
На этом этапе нам нужно решить, следует ли сгруппировать их по теме (счет-фактура, транзакция,…) или по технической роли (репозиторий, услуга, объект стоимости,…), но я чувствую, что независимо от выбора, на самом деле это не так. имеют большое влияние, потому что мы находимся на листьях организационного дерева, поэтому при необходимости легко внести изменения в этот последний фрагмент структуры без особого влияния на остальную часть кодовой базы.
Пространство имен Ports будет содержать пространство имен для каждого инструмента, используемого ядром, точно так же, как мы это сделали для инфраструктуры, где мы разместим код, который ядро будет использовать для использования базового инструмента.
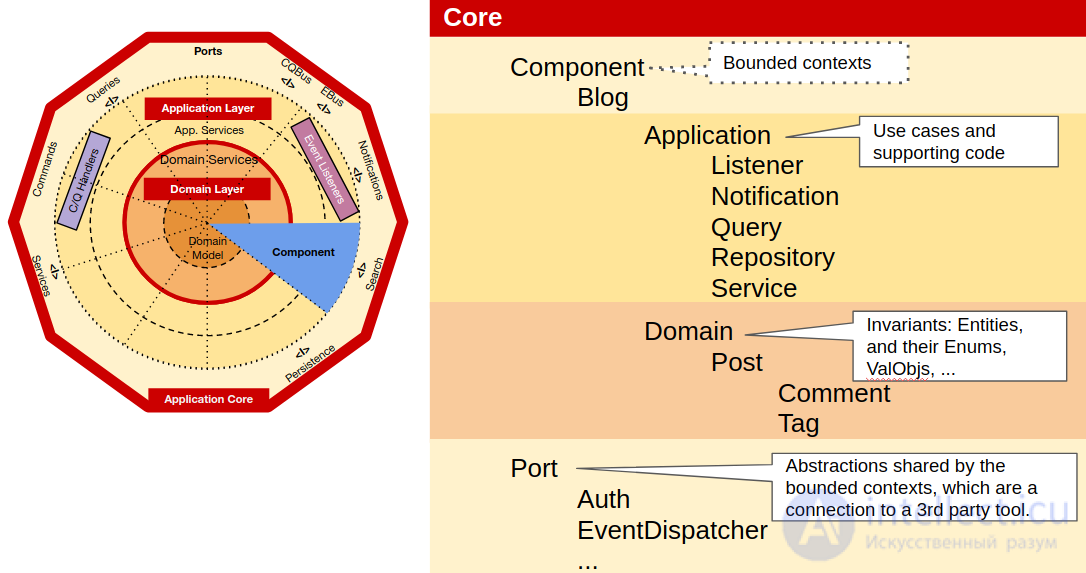
Этот код также будет использоваться адаптерами, роль которых заключается в переводе между портом и фактическим инструментом. В своей простейшей форме порт - это просто интерфейс, но во многих случаях ему также требуются объекты значений, DTO, службы, построители, объекты запросов или даже репозитории.
В Shared Kernel мы разместим код, который является общим для Компонентов. После экспериментов с различными внутренними структурами для общего ядра я не могу выбрать структуру, которая подходит для всех сценариев. Я считаю, что для некоторого кода имеет смысл разделить его по компонентам, как мы это делали в Core\Component(т. Е. Идентификаторы сущностей явно принадлежат одному компоненту), но в других случаях не так много (т. Е. События могут запускаться и прослушиваться несколькими компонентами, поэтому они никому не принадлежат). Может быть, лучше подойдет микс.
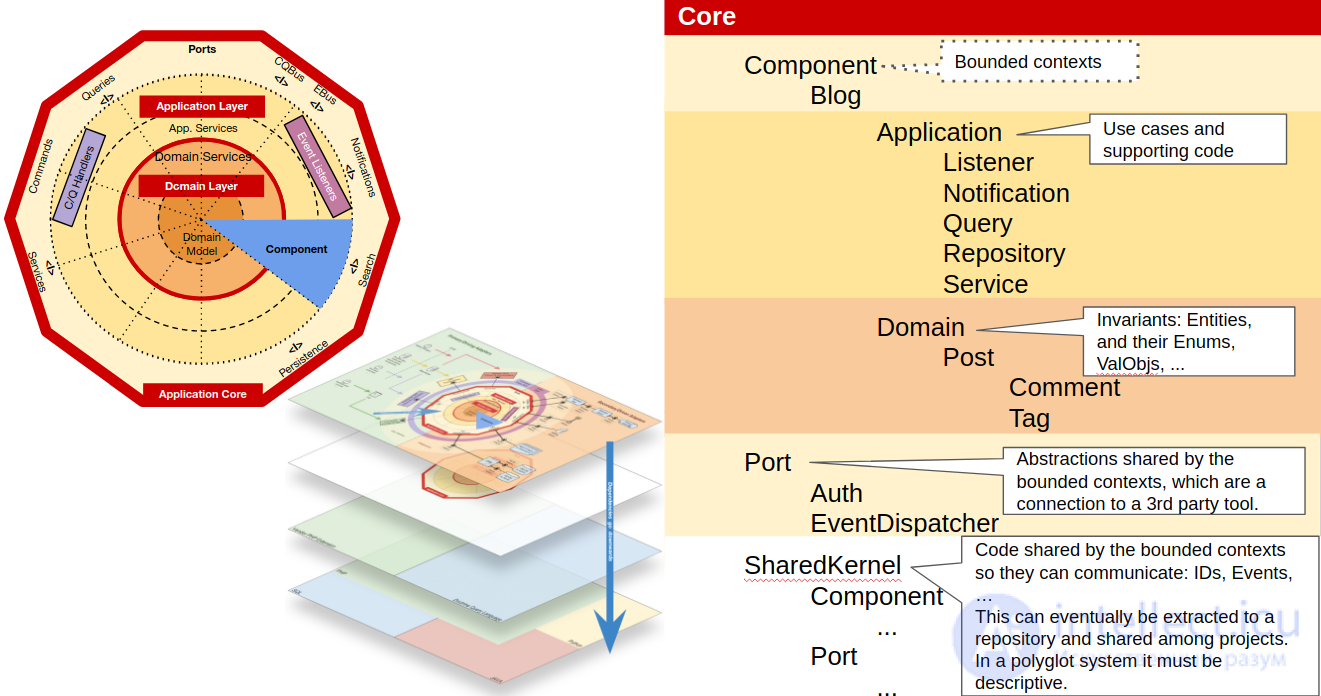
И последнее, но не менее важное: у нас есть собственные расширения языка. Как объяснялось в предыдущем посте этой серии, это код, который может быть частью языка, но по какой-то причине это не так. В случае PHP мы можем думать, например, о классе DateTime, основанном на классе, предоставляемом PHP, но с некоторыми дополнительными методами. Другим примером может быть класс UUID, который, хотя и не предоставляется PHP, по своей природе очень асептичен, не зависит от домена и, следовательно, может использоваться любым проектом независимо от домена.
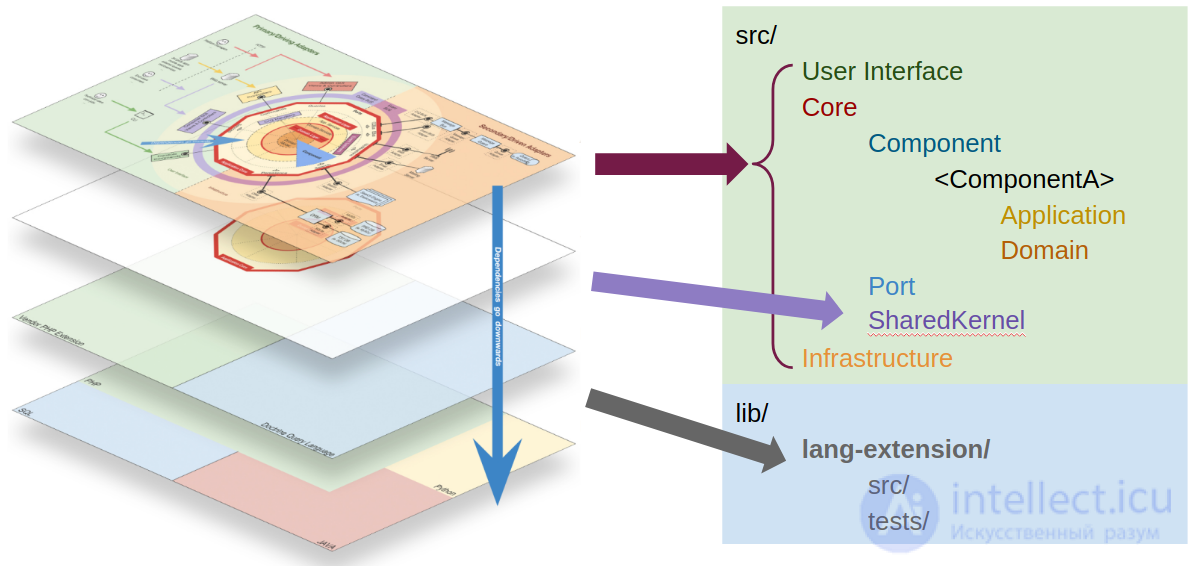
Этот код используется так, как если бы он был предоставлен самим языком, поэтому он должен быть полностью под нашим контролем. Однако это не означает, что мы не можем использовать сторонние библиотеки. Мы можем и должны использовать их, когда это имеет смысл, но они должны быть обернуты нашей собственной реализацией (чтобы мы могли легко переключать базовую стороннюю библиотеку), которая представляет собой код, который будет использоваться непосредственно в кодовой базе приложения. В конце концов, это может быть отдельный проект в собственном репозитории CVS и использоваться в нескольких проектах.
Все эти идеи и то, как мы решаем применять их на практике, требуют большого внимания, и их нелегко освоить. Даже если мы справимся со всем этим, в конце концов, мы всего лишь люди, поэтому мы будем делать ошибки, а наши коллеги будут делать ошибки, так оно и есть.
Точно так же, как мы делаем ошибки в коде и имеем набор тестов, чтобы предотвратить попадание этих ошибок в рабочую среду, мы должны сделать то же самое со структурой кодовой базы.
Для этого в мире PHP у нас есть небольшой инструмент под названием Deptrac (но я уверен, что аналогичные инструменты существуют и для других языков), созданный Sensiolabs. Мы настраиваем его с помощью файла yaml, где мы определяем имеющиеся у нас слои и допустимые зависимости между ними. Затем мы запускаем его через командную строку, что означает, что мы можем легко запустить его в CI, так же, как мы запускаем набор тестов в CI.
Мы даже можем создать диаграмму зависимостей, которая наглядно покажет нам зависимости, включая те, которые нарушают настроенный набор правил:
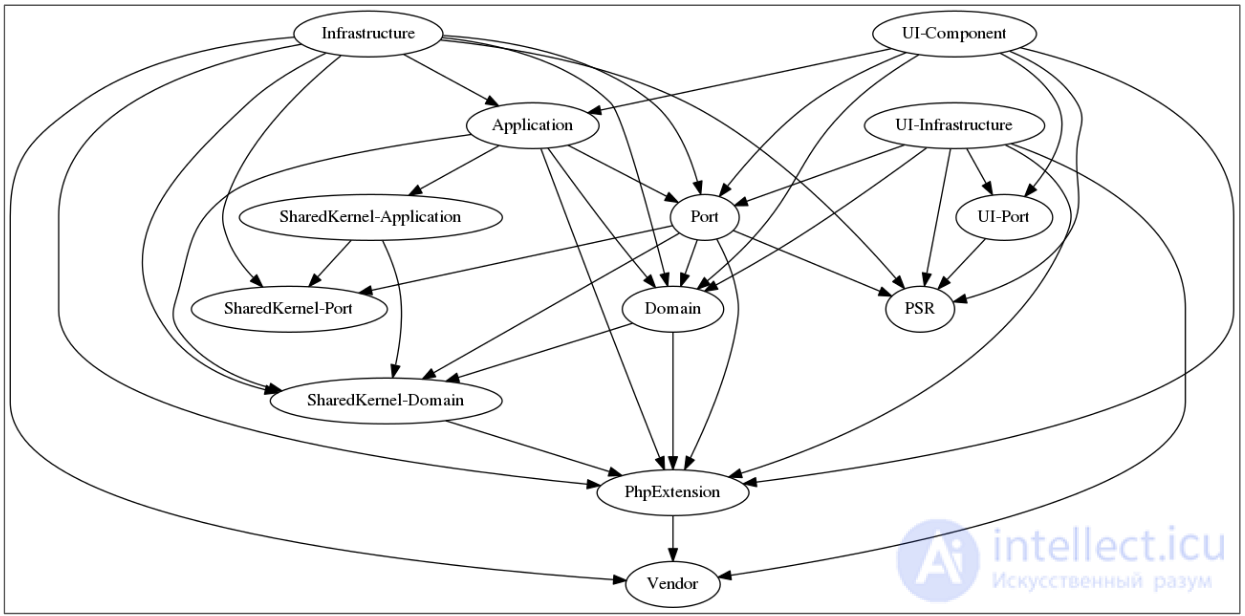
Приложение состоит из домена и технической структуры, архитектуры. Это реальные различия в приложении, а не используемые инструменты, библиотеки или механизмы доставки. Если мы хотим, чтобы приложение было обслуживаемым в течение длительного времени, оба из них должны быть явно указаны в кодовой базе, чтобы разработчики могли знать о нем, понимать его, соблюдать его и при необходимости дорабатывать.
Эта ясность поможет нам понять границы при написании кода, что, в свою очередь, поможет нам сохранить модульный дизайн приложения с высокой степенью согласованности и низкой связанностью.
Опять же, большинство этих идей и практик, о которых я говорил в своих предыдущих сообщениях, исходят от разработчиков, гораздо более опытных и опытных, чем я. Я подробно обсуждал их со многими своими коллегами из разных компаний, я экспериментировал с ними в кодовых базах корпоративных приложений, и они очень хорошо работали над проектами, в которых я принимал участие.
Тем не менее, я верю, что нет серебряных пуль , ни одного ботинка, подходящего всем , ни Святого Грааля .
Эти идеи и структуру, о которых я упоминаю в этом посте, следует рассматривать как общий шаблон, который можно использовать в большинстве корпоративных приложений, но при необходимости его следует без сожалений адаптировать. Нам всегда нужно оценивать контекст (проект, команду, бизнес,…) и делать все возможное, но я верю и надеюсь, что этот шаблон является хорошей отправной точкой или, по крайней мере, пищей для размышлений.
Исследование, описанное в статье про чистая архитектура и ddd, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое чистая архитектура и ddd и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Разработка программного обеспечения и информационных систем

Комментарии