Лекция
Привет, Вы узнаете о том , что такое git, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое git, сис контроля версий , настоятельно рекомендую прочитать все из категории Разработка программного обеспечения и информационных систем.
Глава 1. Системы контроля версий.
1.1 Что это такое?
1.2 Накуа надо, и так все работает
1.3 Как работает внутри
1.4 А как работать
1.5 Работа в команде
1.6 Домашка
1.1 Что такое системы контроля версий?
Системы контроля версий - это программы которые позволяют отслеживать изменения вашего файла, и хранить их. При этом менять информацию в этом файле могут сразу несолько человек. Мы можем перейти в более ранним изменениям или наоборот к более поздним.
Вообще системы контроля версий 2-х типов:
a) Централизованные
б) Распределенные.
Централизованные.
Давайте поговорим о том, в чем разница.

В централизованных системах весь код хранит центральный сервер (бла-бла-бла). Доступ имеют все разработчики ПО. Минусы такого подхода, что у разработчика нет своего репозитория, а если сервак сломается, упадет, сгороит (нужное подчеркнуть). То ни у кого не останется полной рабочей версии ПО. Обмен происходит также, ка ки децентрализовванных.
В настоящее время уже не особо популярны, поэтому подробно останавливаться не будем, дабы не забивать голову. Кому интересно может погуглить инфы много, например: SVN
Децентрализованные
Вот тут уже гораздо интересней - остановимся подробней во второй части. Пока краткое описание, как работает.
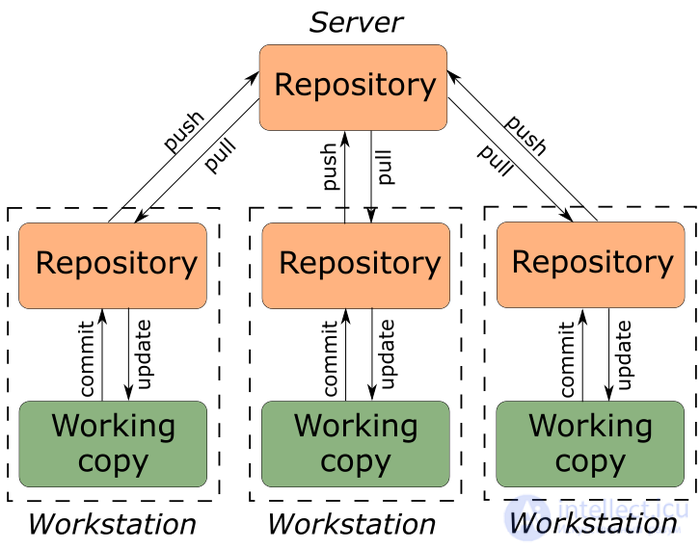
как видим у нас есть центральный репозиторий, и при этом у каждого разработчика есть свой, так что если что-то пойдет не так, мы быстро сможем восстановить актуальность состояния ПО.
Коротко рассмотрели, давайте подробней теперь на децентральзованных.
1.2 Накуа надо и как работает
Всем знакома ситуация:

----------------------------

Папки конечно могут называться по разному. Например: "правил дизайн" и т.д.
В папке "Изменения Васи" поменялся файл index.php и т.д.
можно решить таким способом данную проблему:
Вася пишет исправлял файл
...
...
и т.д.
Петя пишет исправлял файл
...
...
и т.д.
Так вот, представьте что у Вас работает над проектом так человек 20-ть, как быстро показать заказчику проект со всеми изменениями?
Правильно подумали, открывает файл и начинаем копировать файлы с изменениями в папку "Рабочая версия". Вам ничего не кажется странным? :) пишите в комменты что думаете о таком подходе.
И у нас вдруг возникает ситуация, что Вася и Петя редактировали один файл.
Что будем делать?
Если честно я хз, как решать подобное, но срок релиза отложился до решения проблемы.
По головке не погладят точно.
Вот тут и приходит на помощь наш репозиторий.
Буду рассматривать git, материалы приведенные мной это книга по git
link to book:
https://git-scm.com/book/ru/v1/
и так поехали.
Я не буду рассматривать установку на свой ПК сервера git
Некоторые моменты, я специально буду опускать, они простые и чаще всего находятся в материале, на которые я привожу ссылки. Они появятся в виде вопросов к концу главы или раздела.
И так мы уже знаем, что наш git - это СКВ.
Как же он устроен и почему на сегодня он лидер в данной области?
Неужели весь код хранится на сервере, каждый файлик.
Это и так и не так.
Во первых все изменения происходят у Вас локально. Т.е. сервер не знает, что вы там наделали. Инфа приходит есму после, того как Вы ее туда отправили.
Локально в момент добавления файла пищется информация о названии файла, что в нем есть (если только добавили), и далее заносится информация о изменениях (я бы назвал ее дельта изменений), кто и когда создал, ветка (позже расскажу) и комментарий.
Получается вот такая картина:
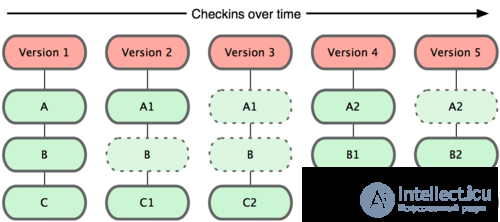
Давайте рассмотрим подробнее что тут отображено:
Version - история изменений (коммитов)
A, B, C - файлы.
Наверное у Вас возникли вопросы, че за **но одни пунктиром, другие нет.
Так в этом и заключается версионность. Сам git не сохраняет полный файл к себе каждый раз, когда вы сохраняете состояние. Он сохраняет только изменения, измененных файлов. Если файл не менялся, то будет просто (условно) сказано (фактически ссылка на файл), файл без изменений.
Получается, что мы можем видеть что конкретно в какой строке поменялось в файле.
Удалилось или добавилось. При этом достаточно компактно.
На сим давайте закончим. Основа задана, далее по линку. А мы поедем дальше.
Самое важное.
Состояния файлов в гит. Это действительно важно, без этого не понять как работает система контроля версий.
и так, есть три состояния:
а) подготовленный - будет включен в репозиторий при commit
б) измененный - изменили файл
в) зафиксированный - зафиксировали, значит отправили с локальный репозиторий (помните где он да?)
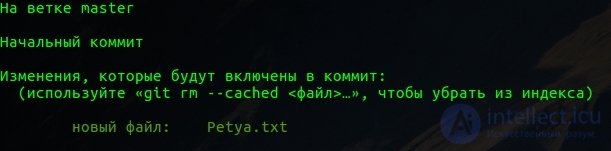
Как видно у нас есть файл Petya.txt. Git видит его и сообщает нам о том, что данный файл не добавлен у нас в отслеживание изменений. сейчас у файла нет ни одного из трех состояний.
Их называют не отслеживаемые файлы. Ну само вытекает как бы из этого.

Теперь добавим файл в отслеживание.
(Команды пока я опускаю, мы к ним еще придем.)
Теперь у нас файл принял состояние №1 - подготовленный, т.е. когда мы сохраним данные локально в репозиторий, он будет включен в продукт для изменений. При этом изменения уже начали отслеживаться.

Теперь файл зафиксировали в нашем локальном репозитории. Состояние №3, при отправке на сервер от будет отправлен.
А теперь давайте сделаем состояние №2. Напишем внутри файла строку:
Petya the Best. Как видно на картинке ниже git отметил наш файл как измененный
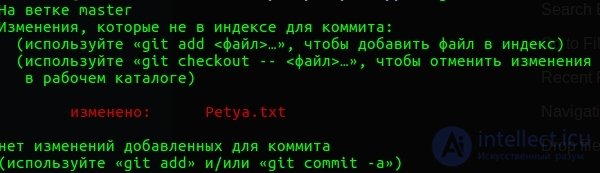
Фухххх....... Ну что же. Передохните пол часика, пусть материал уляжется. И продолжим. Статья получается огромной.
----------------------------------------------------------------------------------------------
Отдохнули, налили чай. Едем дальше.
И так, что надо сделать, чтобы начать работу.
Далее и на протяжении почти всех постов я буду использовать git для работы, пожалуйста отнеситесь серьезно к этому посту.
Для начала давайте поставим необходимые программы для работы.
Linux: ссылка на мануал по установке
Windows: http://msysgit.github.com/
Для тех кто использует Windows, разработчики git написали:
"Пожалуйста, используйте Git только из командой оболочки, входящей в состав msysGit, потому что так вы сможете запускать сложные команды, приведенные в примерах в настоящей книге. Командная оболочка Windows использует иной синтаксис, из-за чего примеры в ней могут работать некорректно."
После того, как установили приложение приступим уже к практической части.
Когда учили автора статьи использовать технологии командной разработки у нас было 2 дня теории и 4 дня практики, нам дали целый сервер на 20-ть человек и мы делали с ним все что хотели в рамках заданий. Именно поэтому я стараюсь сделать упор именно на практически часть в рамках всего курса. Ну если можно так сказать (:
Фактически у нас есть два способа создать репозиторий. Рассмотрим.
1. Склонировать готовый, (допустим на работе уже давно создано)
2. Создать новый локально.
И так способ 1-й.
Идем на bitbucket.org (github и др.)
регистрируемся, там есть кнопка создать репозиторий, (останавливаться не буду, в сети полно материалов как это сделать).
на ПК создаем каталог в котором будет находится копия нашего ПО, склонированного с сервера. Пишем команду:
git clone https://bitbucket.org/bla-bla-lba (в созданном репозитории на bitbucket уже есть ссылка на проект).
Мы должны в нашей папке увидеть проект, название папки = название проекта.

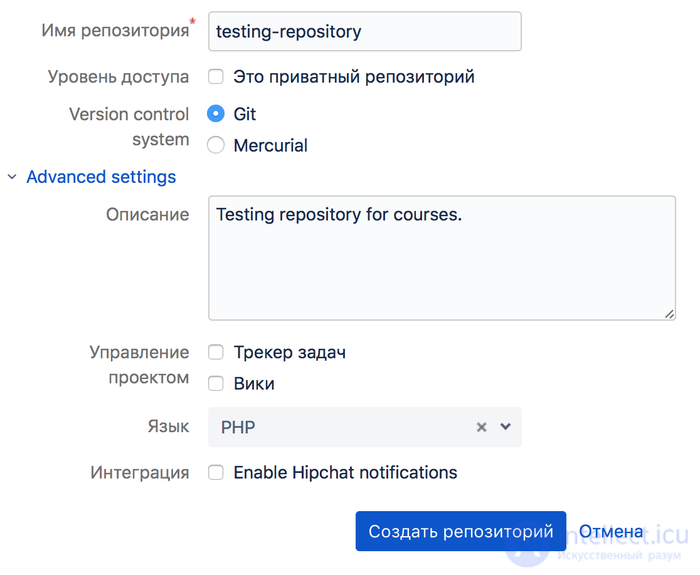
Жмем создать. Все наш репозиторий на bitbucket создан.
Можем приступать к работе. Внизу на странице у нас две ссылки:
У меня уже есть проект
Я начинаю полностью с нуля
Сейчас мы выберем, я начинаю проект с нуля:
git clone https://nibbler-ws@bitbucket.org/nibbler-ws/testing-repository.git
получаем ссылку на клонирование нашего проекта к себе на ПК.
Я советовал бы всем кто начинает программировать или кто уже умеет, пользоваться консолью.
Теперь открываем консоль и понеслась.
1. Выбираем папку куда будем клонировать наш пустой (пока) репозиторий.
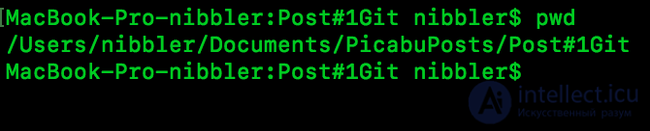
Собственно моя папка куда мы будем производить сие действие.
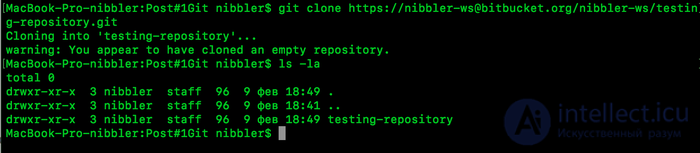
Оп, наш репозиторий готов. Теперь у нас есть два репозитория, один на нашем сервер, второй на нашем ПК.
И так репозиторий готов, приступим к работе с файлами. Правда для начала давайте пробежимся коротко по GUI приложениям для git:
GitKraken - на мой взгляд просто красивый :) Эта сволоч платная, но красивая.
Есть и free-план
В остальном можно обойтись консолью, так как я работаю в основном на Ubuntu/Mac то клиентов могу назвать еще пару, но можно просто погуглить.
Ладно передохнули, начнем. Создаем файл в нашей папке Petya.txt

touch и прочие мной используемые команды ищите пожалуйста в интернете, они просты, а Вы сразу подучите консоль.
и так мы сделали клон репозитория ранее, перешли в папку, создали файл Petya.txt и попросили git показать статус (назовем это так). В данном случае git говорит нам, что видит наш файл, но он его не отслеживает. Что это значит, а это значит что ничего, что мы там напишем не попадет на наш сервер. Давайте попробуем зафиксировать наши изменения.
Нам сказали, что парень какого? У тебя нихрена не добавлено, давай работай. И показал, что есть файлы которые просто не отслеживает. Снова :) Мы всегда будем их видеть.
Ну давайте скажем следить ему за файлом.

Странно, но нам ничего не сказали. Об этом говорит сайт https://intellect.icu . Конечно зачем :) мы уже просто и так добавили файл
Но если сейчас запросить статус увидим, такую картину:
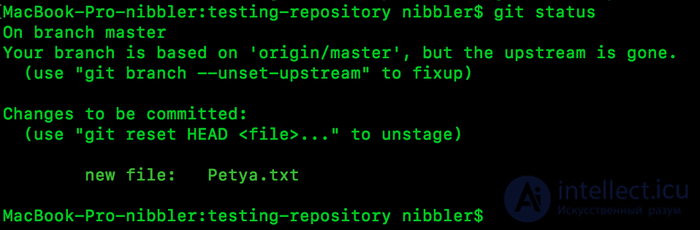
Ага мы получили искомое состояние, файл отслеживается. Отлично. Теперь хочу внести ясность.
То что файл отслеживается, не означает, что все абсолютно все изменения Вы можете вернуть. Вот нифига подобного :) вы можете вернуть только изменения, которые были зафиксированы в состоянии вашего репозитория. Наглядно это выглядит так:
А: ( Строка ХАХАХ ) фиксируем изменения | ( Строка ХАХАХ ) -> ( Строка ХАХАХ2 ) -> ( Строка ХАХАХ123 ) -> ( Строка ХАХАХ Кхе-Кхе ) фиксируем изменения.
В конечном итоге у нас будут в репозитории файл в двух состояний:
А: ( Строка ХАХАХ ) -> ( Строка ХАХАХ Кхе-Кхе ).
Надеюсь это понятно. Едем дальше. Сделаем первый коммит теперь (фиксация изменений).

нам сообщили, что наш файл зафиксирован. 1 файл изменен, строк добавилось 0, удалено 0.
и хэш. Клево правда :)
Посмотрим лог (история фиксаций):
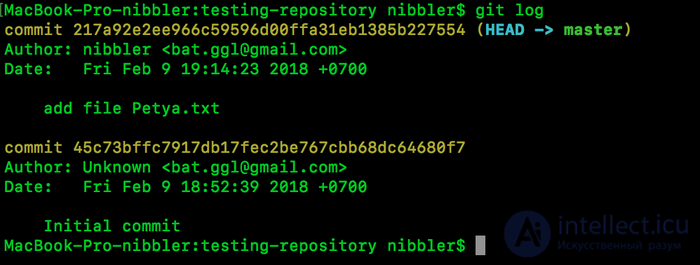
Отлично, давайте разберем, что у нас получилось:
commit - хэш коммита, для чего он буду рассказывать позже.
автор - собственно кто создал коммит.
Дата
И список файлов, которые были изменены.
теперь отправим наши изменения на сервер. Мы помним уже, что наш файл был добавлен и зафиксирован, теперь чтобы все разработчики его увидели нам надо сделать push (или отправить на наш сервер).
Для этого делаем git push.

У меня остался последний блок который я могу добавить :) мать его да у меня статья не влезла полностью первая, надо что-то думать :)
Читая Ваши комментарии и просматривая ссылки наткнулся на такой комментарий от пикабушника.
"Вот ты пишешь, что твои посты в горячем нахер не нужны. B я только на 30 лекции на тебя наткнулся." Пруф по ссылке
Я вот даже не знаю, просить как-то неудобно Вас. А люди мучаются :(
ПЫ.СЫ. вторая часть тоже готова уже, просто все не влезло. Скоро надеюсь смогу публиковать двумя частями. Завтра тогда домашка блин.
По роду своей деятельности я нередко становлюсь свидетелем «священных войн» между коллегами-программистами на тему, какую же систему контроля версий выбрать для того или иного проекта. Роль системы контроля версий особо остро ощущается в случаях разработки и поддержки проектов с длинной историей. Вариантов инструментов много, но я хочу сконцентрироваться на двух, на мой взгляд, наиболее перспективных: Mercurial и Git. Далее попробуем рассмотреть возможности обеих систем с позиции их внутреннего устройства.
Немного истории
Толчком к созданию обеих систем, как Mercurial, так Git, послужило одно событие 2005 года. Все дело было в том, что в упомянутом 2005 году ядро системы Linux потеряло возможность бесплатного использования системы контроля версий BitKeeper. После пользования BitKeeper в течение трех лет разработчики ядра привыкли к его распределенному рабочему процессу. Автоматизированная работа с патчами сильно упрощала процесс учета и слияния изменений, а наличие истории за продолжительный период времени позволяло проводить регрессию.
Другой немаловажной частью процесса разработки ядра Linux стала иерархическая организация разработчиков. В вершине иерархии стоял Диктатор и много Лейтенантов, отвечавших за отдельные подсистемы ядра. Каждый Лейтенант принимал или отклонял отдельные изменения в пределах своей подсистемы. Линус, в свою очередь, затягивал их изменения и публиковал их в официальном хранилище ядра Linux. Любой инструмент, вышедший на замену BitKeeper, должен был реализовывать такой процесс.
Третьим критичным требованием к будущей системе была скорость работы с большим количеством изменений и файлов. Ядро Linux — это очень большой проект, принимающий тысячи отдельных изменений от тысяч различных людей.
Среди множества инструментов подходящего не нашлось. Практически одновременно Мэт Макол (Matt Mackall) и Линус Торвальдс (Linus Torvalds) выпускают свои системы контроля версий: Mercurial и Git соответственно. В основу обеих систем легли идеи появившегося двумя годами ранее проекта Monotone.
Cходство
Обе системы контроля версий имеют ряд общих черт:
Отличия
Несмотря на общность идей и высокоуровневого функционала, реализации систем на низком уровне в значительной степени отличны.
Хранение истории
И Git, и Mercurial идентифицируют версии файлов по их контрольной сумме. Контрольные суммы отдельных файлов объединяются в манифесты. В Git манифесты называются деревьями, в которых одни деревья могут указывать на другие. Манифесты непосредственно связаны с ревизиями/фиксациями.
Mercurial для улучшения производительности пользуется специальным механизмом хранения Revlog. Каждому файлу, помещенному в хранилище, сопоставляется два других: индекс и файл с данными. Файлы с данными содержат слепки и дельта-слепки, которые создаются только когда количество отдельных изменений файла превышает некоторое пороговое значение. Индекс служит инструментом эффективного доступа к файлу с данными. Дельты, полученные в результате изменения файлов под контролем версий, добавляются только в файлы с данными. Для того, чтобы правки из разных мест файла объединить в одну ревизию, используется индекс. Ревизии отдельных файлов складываются манифесты, а из манифестов — фиксации. Этот метод зарекомендовал себя весьма эффективным в деле создания, поиска и вычисления различий в файлах. Также к достоинствам метода можно отнести компактность по отношению к месту на диске и достаточно эффективный протокол передачи изменений по сети.
В основе модели хранения Git лежат большие объектные бинарные файлы (BLOB). Каждая новая ревизия файла — это полная копия файла, чем достигается быстрое сохранение ревизий. Копии файлов сжимаются, но, все равно, имеют место большие объемы дублирования. Разработчики Git применили методы упаковки данных для снижения требований к объему хранилища. По существу они создали нечто похожее на Revlog для указанного момента времени. Полученные в результате упаковки пакеты отличаются от Revlog’а, но преследуют ту же цель — сохранить данные, эффективно расходуя дисковое пространство. В виду того, что Git сохраняет слепки файлов, а не инкремент, фиксации могут легко создаваться и уничтожаться. Если при анализе требуется посмотреть разницу между двумя различными фиксациями, то в Git разность (diff) вычисляется динамически.
Ветвление
Ветвление — очень важная часть систем управления конфигураций, т.к. оно позволяет проводить параллельную разработку новой функциональности, сохраняя стабильность старой. Поддержка ветвления присутствует как в Git, так и в Mercurial. Отличия формата хранения истории нашли свое отражение и в реализации ветвления. Для Mercurial ветка — это некая отметка, которая прикрепляется к фиксации навсегда. Эта отметка глобальна и уникальна. Любой человек, затягивающий изменения из удаленного хранилища, увидит все ветки в своем хранилище и все фиксации в каждой из них. Для Mercurial ветки — это публичное место разработки вне основного ствола. Имена веток публикуются среди всех участников, поэтому в качестве имен обычно используют устойчивые во времени номера версий.
Ветки Git, по сути, являются лишь указателями на фиксации. В разных клонах хранилища ветки с одинаковыми названиями могут указывать на разные фиксации. Ветки в Git могут удаляться и передаваться по отдельности (каждая уникально идентифицируется по локальному имени в хранилище-источнике).
Практические аспекты использования
Различия в реализациях Git и Mercurial можно проиллюстрировать на примерах.
Mercurial позволяет легко фиксировать изменения, проталкивать и вытягивать их с поддержкой всей предыдущей истории. Git не заботится о поддержке всей предыдущей истории, он только фиксирует изменения и создает указатели на них. Для Git не имеет значения предыдущая история и на что раньше ссылались указатели, важно то, что актуально в текущий момент. Существует даже инструмент, гарантирующий сохранность локальной истории при вытягивании изменений из внешнего хранилища — fast-forward merge. Если этот механизм включен, то Git будет сообщать об изменениях, которые не могут быть улажены без продвижения по истории вперед. Данные ошибки можно не принимать во внимание, если поступившие изменения ожидались.
При выполнении отката фиксации или затягивания со слиянием Git просто меняет указатель ветки на предыдущую фиксацию. В действительности в любой момент времени, когда требуется откатиться в некоторое предыдущее состояние, Git ищет в логе соответствующую контрольную сумму и сообщает какая фиксация ей соответствует. Как только что-то зафиксируется в Git, то всегда можно к этому состоянию вернуться. Для Mercurial существуют случаи, когда невозможно полностью вернуться в исходное состояние. Т.к. Mercurial для решения какой-либо проблемы создает фиксацию, то в некоторых случаях затруднительно переместиться назад с учетом свежего изменения.
Для решения различных проблем в Mercurial существуют расширения. Каждое расширение решает свои проблемы хорошо, если существует само по себе. Существует даже некоторые расширения, обеспечивающие сходную функциональность, но разными способами.
Для примера рассмотрим работу с отложенной историей. Допустим, нам необходимо записать изменения из рабочей копии без фиксации в хранилище. Git предлагает использовать stash. Stash — это фиксация или ветка, которые не сохраняются в обычном месте. Stash не показывается, когда выводится список веток, но всеми инструментами он трактуется как ветка. Если аналогичная функциональность требуется Mercurial, то можно использовать расширения attic или shelve. Оба этих расширения хранят «отложенную» историю в качестве файлов в хранилище, которые могут быть при необходимости зафиксированы. Каждое расширение решает проблему немного по-своему, поэтому имеет место несогласованность форматов.
Другой пример, команда git commit --amend. Если нужно изменить самую последнюю фиксацию, например, добавить что-нибудь забытое или изменить комментарий, то команда git commit --amend создаст полностью новый набор файловых объектов, деревьев и объектов фиксации. После этого обновляется указатель ветки. Если далее потребуется откатить изменения, то необходимо только вернуть указатель на предыдущую фиксацию командой git reset --hard HEAD@{1}. Чтобы повторить это в Mercurial потребуется откатить фиксацию, затем создать новую, далее импортируем содержимое последней фиксации при помощи расширения queue, дополняем ее и делаем новую фиксацию.
Следует заметить, что ни одно из перечисленных выше дополнений не использует возможности формата хранения Mercurial, и таким образом они существуют исключительно как самостоятельная надстройка над ним.
Выводы
В последнем разделе этой статьи хотел бы высказать собственное мнение по выбору системы контроля версий. И Mercurial, и Git хороши в своих сегментах.
Например, для целей ведения коммерческого программного проекта мне больше импонирует Mercurial.
Для хранения бинарных файлов, например, электронной библиотеки, Git подходит лучше. По сравнению с Mercurial он не ориентирован на расчет дельты файлов, что для бинарного содержимого не очень эффективно. Сами файлы меняются редко, а основные операции с ними — это перемещение и добавление. По моим собственным наблюдениям папка хранилища Git с историей моей библиотеки сопоставима по размерам с рабочей копией с окрестностью примерно 10%.
Источники знаний
 Для начала я хочу внести ясность в понятие коммерческой разработки и ее отличий от других моделей. В коммерческой разработке принято ставить конкретные цели и отслеживать этапы выполнения работы. Тогда как, например, в open source моделях разработки, обычно цели ставит перед собой отдельный разработчик, а этапность их исполнения и привязка к бизнес требованиям никого не интересует.
Для начала я хочу внести ясность в понятие коммерческой разработки и ее отличий от других моделей. В коммерческой разработке принято ставить конкретные цели и отслеживать этапы выполнения работы. Тогда как, например, в open source моделях разработки, обычно цели ставит перед собой отдельный разработчик, а этапность их исполнения и привязка к бизнес требованиям никого не интересует.
Зачем вообще нужна система контроля версий? Есть несколько причин:
— Обеспечить одновременную возможность работы коллектива над кодом;
— Сохранить лог всех изменений и версий для того чтобы при необходимости вернуть версию или часть кода, а также разобраться в проблеме на основе анализа изменений.
Главное отличие — «Its all in branches», как сформулировал однажды Felipe Contreras в своем блоге. В статье приведена масса аргументов, почему git технически лучше, чем mercurial, и большинство из этих аргументов бесспорны. Действительно, для программиста проекта open source на сегодняшний день git — лучший выбор.
Да и вообще, если спрашивать только программистов, в том числе на коммерческих проектах, выбор тоже будет преимущественно в пользу git. Видимо, процесс выбора системы контроля версий полностью отдается на откуп программистам, а они, конечно же, выберут самый технически совершенный инструмент на рынке, чем и является на сегодня git.
Но этот выбор может оказаться сомнительным, если взглянуть на него с точки зрения PM. А вот многие слабые места Mercurial оказываются, на поверку, его сильными сторонами.
Предлагаю рассмотреть следующие отличия git vs. mercurial в контексте их удобства для PM и коммерческого проекта в целом:
— невозможность удаления веток, коммитов, т.е. изменения истории репозитория;
— уровень сложности обучения;
— «тяжелые» ветки, в коммитах которых ветка привязана напрямую.
Отслеживаемость изменений
На всех наших проектах поддержка Traceability позволяет нам работать более эффективно. Если вернуться в начало статьи, то трассировка позволяет нам отслеживать:
— этапность изменений;
— привязку изменений к бизнес требованиям.
Как это реализовано на практике: связка с таском кодируется в названии ветки, например: 29277_pivot_table, 30249_summary_page, 30081_agroups, 28255_angularjs_todo. Мы работаем c теми самыми «тяжелыми» ветками, в которых ветка привязана к коммиту. В номере ветки кодируется номер задачи и краткое описание. Потом, если вдруг в hg annotate (аналог команды blame) мы попытаемся понять, кто изменил конкретную строку кода, нам не составит труда открыть трекинговую систему с номером таска. В таске, в свою очередь, перечислены (путем обычных comments) список всех изменений к данному таску.
И если вдруг заказчик задаст мне вопрос: «Кто выпилил важный баннер на первой странице с рекламой главного рекламодателя?» — я смогу четко ответить, указав ссылку на бизнес требование и таск, с ним связанный.
Полноценная трассировка невозможна в Git по нескольким причинам:
— Ветка может быть удалена. Git, как более мощный инструмент, позволяет удалять ветки и другие части лога из истории. То есть вполне может так оказаться, что останется только merge commit, в котором может быть указана только общая причина (например, «вливка версии 11 в master»).
— Возможно, вы обнаружите commit девелопера, но это еще не решение. В коммите может быть сказано: «Выпилил баннер». А почему так произошло — тайна покрытая мраком. Тут приходится делать упор на то, чтобы девелоперы обязательно ставили номер таска в commit msg. Регулярно наблюдаю эту картинку в командах, которые работают с git, и там же регулярно наблюдаю процентов 40-60% коммитов без метки таска.
Для того, чтобы хоть как-то решить эту проблему, в Jira стоит авто-отслеживание коммитов по номеру таска, совпадающих с названием проекта. Но этого оказывается недостаточно для 100% гарантии результата.
Сложность обучения и эксплуатации
Большинство людей, которые используют git, вообще не понимают, о чем я говорю. Ну да, они «уже» работают, в 90% случаев не вдаваясь в подробности, почему это так устроено. Некоторые имеют на бумажке «шпаргалку» в которой указаны наиболее часто используемые команды.
Я не могу себе отказать в удовольствии немного потроллить пользователей git, которые считают его синтаксис логичным и понятным.
1. Разделение типов репозиториев в git и команда clone
Начнем с первого шага, и здесь я сразу вижу некоторую неудобность git в рельной жизни. И в git, и в mercurial синтаксис команды clone одинаковый:
git clone <откуда> <куда>
hg clone <откуда> <куда>
Вроде все логично? Все, да не совсем. В Git, оказывается, есть разделение репозиториев на клоны для девелоперов (рабочие) и клоны для сервера (bare). Это сделано, видимо, в целях оптимизации, но в результате, чтобы обменяться кодом с соседом программистом, мне уже недостаточно будет просто написать hg push ssh://otheruser@othercomp, а потребуется создать bare репозиторий и организовать обмен кодом на его основе.
2. Работа с ветками
В Git придется выучить целый раздел описания того, как работать с локальными и удаленными ветками, как их клонировать, коммититься и т.п. Это, конечно, хорошо, если оно реально используется. Это суперфича важна для open source, когда можно локально играться на разных ветках и оправлять на оценку сообществу только те ветки, которые уже завершены и готовы к рассмотрению.
В коммерческой же модели разработки PM’у важно видеть объем и качество сделанной работы каждый день, а иногда и чаще. И, соответственно,удобно, чтобы все рабочие ветки заливались на сервер, что по умолчанию происходит в mercurial.
Я не хочу сказать, что работа с локальными/удаленными ветками — это плохо. Опционально я был бы не против такой фичи в mercurial. Но ее полезность в нашей ежедневной работе под большим сомнением.
Помимо того, данный функционал довольно сильно усложняет синтаксис вызова команд. Если в Mercurial все, что вам требуется знать, — это просто команды создания, перехода между ветками, то в git все намного сложнее. И хотя сложный функционал востребован редко, пользоваться им приходится всем. Примеры для сравнения:
| hg | git | комментарий |
| hg diff | git diff HEAD | показать текущие изменения |
| hg up branchname | git checkout -b branchname origin/branchname | перейти в ветку |
| hg push | git push git push origin master |
отправить изменения на сервер |
Мне поначалу было сложно понять, что за origin и почему надо указывать ветку.
С точки зрения простоты, Mercurial действительно незамысловат. Отправляет все локальные ветки по умолчанию на сервер, то же самое происходит в обратной ситуации.
Будьте внимательны с синтаксисом вызова git. Допустим, для удаления ветки в git используется не очень понятная конструкция типа git push origin :the_remote_branch. То есть мы отправляем «пусто» заменить ветку на сервере — в результате команды удаляется ветка на сервере.
С точки зрения менеджмента это опасная команда. Я бы такую запретил, если бы мог:) Или, как вариант, — бекапировать основной репозиторий время от времени.
В Mercurial ничего удалить нельзя (тривиальным способом). Для меня как для PM’а это плюс, для разработчика скорее минус.
Простота запоминания команд в Mercurial
Сравните:
| hg | git |
| hg in | git fetch && git log master..FETCH_HEAD |
| hg out | git fetch && git log FETCH_HEAD..master |
| hg purge | git clean -fd |
| hg revert -a | git reset --hard |
| hg addremove | git add .; git ls-files --deleted xargs git rm |
| hg glog | git log --graph --all --decorate |
Ну и закодированное git config по сравнению с обычным простым файлом .hg/hgrc
Все вышеуказанные плюсы в какой-то мере могут стать и минусами. Например, самая проблемная ситуация — не стоит добавлять огромные файлы в репозиторий. Один наш заказчик решил, что таким образом можно добавить media файлы, включая рекламные ролики, и размер репозитория резко вырос на размер видео, помноженный на два. Удалить их простым способом было невозможно, пришлось использовать ConvertExtension.
Второй минус — к хорошему привыкаешь быстро. Поработав немного с mercurial, возвращаться на git довольно сложно, так как приходится вспоминать зубодробительный синтаксис для простых вещей.
Третий минус — вы, как PM, скорее всего, не сможете переубедить свои программистов в необходимости перехода на Mercurial. Причина проста — они уже выучили один синтаксис, переучиваться не хотят. Тем более, на заведомо более слабую по фичам систему. Есть шанс, если стартовать новый проект.
Спор о том, что лучше, а что хуже, сильно зависит от контекста решаемых задач. Мой выбор на сегодня прост — для Open Source я пользуюсь в основном git, в коммерческих проектах — только Mercurial.
Хочу пожелать читателям правильно делать свой выбор.
Практически любой программный продукт – это труд не одного человека. Если проект начинал разрабатываться программистом-одиночкой, то однажды настанет момент, когда для его поддержки и дальнейшего развития понадобится целая команда разработчиков. В связи с этим встает вопрос о правильной и, главное, эффективной организации совместной разработки систем, а также контролем всего процесса разработки [12]. Появляется необходимость отслеживания всех манипуляций с файлами проекта и, при необходимости, возврат их до определенного состояния [10].
Системы, решающие эту проблему, были названы системами контроля версий (Version Control System, VCS). Под системой контроля версий понимается механизм сохранения промежуточных состояний кода разрабатываемого приложения [13]. Однако, с момента появления первых версий подобных систем прошло достаточно много времени, вместе с тем выросли и потребности: сейчас системы контроля версий позволяют вести совместную разработку, производить синхронизацию с сервером и многое другое.
Системы контроля версий актуальны не только в области разработки ПО. Например, всем известный Microsoft Office – офисный пакет приложений – также позволяет контролировать версии документа: с некоторым промежутком времени документ автоматически сохраняется, что позволяет в будущем вернутся к определенной версии. Это наиболее примитивная реализация системы контроля версий, однако для MS Office этого вполне достаточно.
Существует несколько различных систем контроля версий, которые отличаются принципами работы, областью их использования и концепциями в целом. Какие-то их них более популярны, какие-то – менее, однако каждая их них выполняет свою главную задачу – контролирует версии разрабатываемой системы.
Системы контроля версий делят на распределенные и централизованные. В централизованных системах есть единое хранилище кода, управляемое специальным сервером, который и выполняет большую часть функций по управлению версиями [7]. Однако при таком подходе есть и несколько серьезных недостатков. Наиболее очевидный — централизованный сервер является уязвимым местом всей системы. Если сервер выключается на час, то в течение часа разработчики не могут взаимодействовать, и никто не может сохранить новой версии своей работы [8].
Распределенные системы работают иначе: здесь не просто выгружается последняя версия файлов с сервера, а полностью копируется репозиторий. Это позволяет вести работу с системой вне зависимости от того, что происходит с самой системой.
Наиболее популярной системой контроля версий в данный момент является Git. Она была разработана Линусом Торвальдсом, создателем операционной системы с открытым исходным кодом Linux, в 2005 году. По сей день Git используется для управления разработкой ядра GNU/Linux, а также для множества других проектов.
Чтобы понять необходимость использования систем контроля версий, необходимо выяснить, что они контролируют, какие проблемы решают и насколько упрощают разработку.
Системы контроля версий позволяют отслеживать любые изменения в коде разрабатываемого приложения и фиксировать их как отдельную версию всего приложения. Это позволяет в любой момент времени откатится на любую из предыдущих версий приложения, отменить определенные изменения и просто отслеживать процесс разработки. Системы контроля версий хранят большие объемы информации о том, когда и какие изменения в коде были сделаны [11].
Контроль изменения файлов – базовая функциональность систем контроля версий, которая исходит из их названия. Современные системы контроля версий позволяют разрабатывать приложение в команде, а также производить синхронизацию всех изменений с репозиторием.
Как говорилось ранее, существует несколько различных систем контроля версий: SVN, Mercurial, Bazaar и др. Git имеет ряд преимуществ перед своими аналогами.
Во-первых, Git отличается принципом хранения информации об изменениях. Большинство других систем контроля версий, таких как Subversion, для хранения новых версий используют дельта-компрессию, т.е. система находит отличия новой версии от предыдущей и записывает только их, избегая дублирования данных [4]. Git же считает хранимые данные набором слепков небольшой файловой системы. При каждой операции фиксации изменений Git, по сути, сохраняет слепок того, как выглядят все файлы проекта на текущий момент. Это позволяет экономить память, а также дает возможность иметь на локальной машине всю историю изменений всего проекта, при этом не требуя доступа к репозиторию, что является важным аспектом использования систем контроля версий, и чего другие системы не предоставляют.
В-вторых, Git работает локально. Для совершения большинства операций необходимы только локальные ресурсы. Это позволяет добиться высокой скорости работы с Git: например, при просмотре изменений файла, Git не будет запрашивать какие-либо данные у сервера: все изменений хранятся на локальном компьютере и доступны в любой момент, а благодаря уникальным принципам хранения этих изменений Git занимает меньше памяти на жестком диске.
Git оперирует большим количеством команд, но для повседневной работы с ним достаточно всего нескольких. Рассмотрим их по порядку.
Git clone – команда клонирования удаленного репозитория на локальную машину.
Git add – команда добавления рабочей директории в индекс (staging area) для последующего коммита.
Git status позволяет узнать, в каком состоянии находятся файлы в рабочей директории: изменения, ожидание коммита и т.д.
Git commit фиксирует изменения файлов, добавленных в индекс с помощью git add. При этом, по сути, создается новая версия системы. Важно понимать, что файлы в Git могут находится в одном из трех состояний (рис 1).
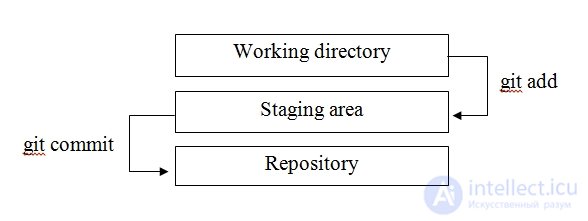
Рисунок 1. Состояние файлов в Git
Рабочий каталог (Working Directory) – это копия определенной версии проекта. Именно рабочий каталог копируется из репозитория при выполнении команды git clone.
Область подготовленных файлов (Staging area) – это файл, который хранит информацию о изменениях, которые войдут в следующий коммит.
Репозиторий (Repository) – место хранения зафиксированных измененй.
Git push отправляет зафиксированные изменения в главный репозиторий.
Git pull – наоборот, забирает с удаленного репозитория все новые изменения.
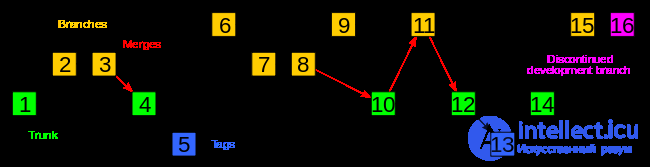
Git merge производит слияние изменений нескольких «веток» (branches). Ветки – это мощный инструмент в разработке. Чтобы понять всю его суть, представим ситуацию, когда есть задача по разработке некого функционала, которая займет довольно много времени. Однако, вместе с тем, на протяжении всего этого времени есть необходимость вносить другие, мелкие изменения в проект, но при этом не затрагивая все данные нового функционала. В таких ситуациях используют ветки: под разработку новых модулей создается новая ветвь, и вся разработка ведется в ней. Между ветвями можно переключаться, таким образом появляется несколько различных версий проекта, разработка которых может вестись параллельно. Ветки, как правило, создаются для отдельных фаз разработки проекта и для предрелизных версий, в которых ведется устранение ошибок [5].
При выполнении операции слияния ветвей Git сравнивает содержимое соответствующих фиксаций, затем объединяет состояния репозитория разных версий проекта, формируя новую версию [2].
Для распределенных систем контроля версий ветки разработки являются одной из основополагающих концепций – в большинстве случаев каждая копия хранилища версий является веткой разработки [3].
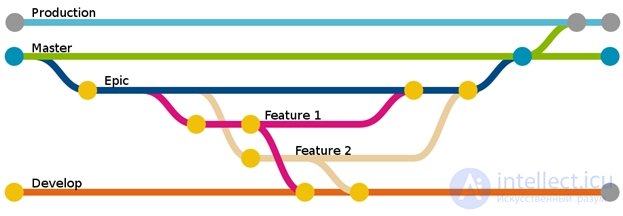
Рисунок 2. Ветвление и слияние веток в Git
Когда новые модули разработаны и протестированы, ветки сливаются: все изменения заносятся в главную ветку (master). При этом, конечно, могут возникать конфликты, в случае если один и тот же файл был одновременно изменен несколькими разработчиками. Обычно в таких случаях система не в состоянии самостоятельно обновить проект и требует вмешательства со стороны разработчика. [1]
Также, Git решает проблему обновления (деплоя, развертывания) на сервере, где система непосредственно работает (production). Для этого сервере так же устанавливается Git и обновляет данные из репозитория командой git pull. Для того, чтобы автоматизировать этот процесс, многие сервисы для хранения проектов, работающие с Git, предоставляют механизм веб-хуков (WebHooks). Работает это следующим образом: при любом изменении в репозитории отправляется HTTP-запрос на сервер приложения, где заранее настроенный скрипт запускает команду обновления данных с основного репозитория.
На базе Git создана социальная сеть для разработчиков под названием GitHub. Это не просто сервис хранения кода: участники сети могут участвовать в разработке любого открытого проекта, получать сообщениях об ошибках от участников сообщества и предлагать свои решения. GitHub предоставляет доступ к проектам как для группы разработчиков, так и для контролирующей группы. При этом зоны действия полномочий обеих групп не пересекаются [6].
Git – популярнейшая система контроля версий среди разработчиков. Такие корпорации, как Google, Microsoft и другие используют его для части своих проектов. Кроме того, для контроля версий популярнейшего движка для отображения веб страниц под названием Webkit, который используется в большинстве современных веб-браузеров, разработчики используют именно Git, а его исходные коды размещены на GitHub. Стоит сказать, что репозиторий Webkit – один из наиболее популярных по количеству коммитов на Github, количество которых достигло 180 тысяч.
Команды разработчиков, использующие Git, освобождены от большого количества проблем командной разработки проектов. Можно сказать, что Git решает большинство проблем еще до их появления, ускоряет и удешевляет процесс разработки [9]. Каждый разработчик изолированно работает над своей задачей, не мешая остальным. Git делает резервные копии проекта, позволяя вернуться в исходное состояние при возникновении ошибок, а деплой приложения становится задачей, решаемой всего несколькими git-командами. Все это экономит время разработчиков на выполнение рутинных (и не очень) операций, позволяя сосредоточиться непосредственно на разработке.
Git, по сравнению с другими системами контроля версий, сложнее в освоении, поэтому разработчики боятся начать им пользоваться. Однако, перейдя на него и поработав с ним некоторое время, приходит понимание того, что git – это не просто модная тенденция современной разработки информационных систем, а инструмент, позволяющий вести разработку правильно.
Выводы из данной статьи про git указывают на необходимость использования современных методов для оптимизации любых систем. Надеюсь, что теперь ты понял что такое git, сис контроля версий и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Разработка программного обеспечения и информационных систем
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

Комментарии