Лекция
Привет, мой друг, тебе интересно узнать все про анализ текста, тогда с вдохновением прочти до конца. Для того чтобы лучше понимать что такое анализ текста, обработка текста при извлечении информации, интеллектуальный анализ текстов, иат, text mining , настоятельно рекомендую прочитать все из категории Моделирование мыслительных процессов на естественном языке и Символьное моделирование.
Задача извлечения информации заключается в обработке текста на естественном языке с целью извлечения заданных элементов. На входе системы извлечения информации –– слабоструктурированный или неструктурированный текст на естественном языке; на выходе –– заполненные структуры данных (экзофреймы), позволяющие проводить дальнейшую автоматическую или ручную обработку информации. Извлечение информации можно рассматривать как особый вид аннотирования текстов, когда в роли аннотации выступает специфическая структура данных.
интеллектуальный анализ текстов ( иат , англ. text mining) — направление в искусственном интеллекте, целью которого является получение информации из коллекций текстовых документов, основываясь на применении эффективных в практическом плане методов машинного обучения и обработки естественного языка. Название «интеллектуальный анализ текстов» перекликается с понятием «интеллектуальный анализ данных» (ИАД, англ. data mining), что выражает схожесть их целей, подходов к переработке информации и сфер применения; разница проявляется лишь в конечных методах, а также в том, что ИАД имеет дело с хранилищами и базами данных, а не электронными библиотеками и корпусами текстов.
Текст как феномен – явление весьма многогранное, разнообразное и многоаспектное. В связи с этим нет да и, пожалуй, не может существовать единого его понимания и определения. Термин «текст» фигурирует в трудах различных ученых для обозначения феноменов не только «разнопорядковых» (от отдельного высказывания до речевого потока), но подчас и различной «природы» (от процесса и результата речемыслительной деятельности до сугубо языкового, особым образом обработанного и структурированного произведения, выраженного исключительно вербальными средствами) (см., например, [3; 1; 15]).
Информация, извлеченная из текста, хранится в экзофрейме, который представляет собой набор целевых слотов. Целевой слот может содержать информацию об объектах (например, персоналии, организации, продукты), отношениях или событиях, их атрибутах, также возможна привязка к фрагменту текста, на основании которого получена данная информация.
Релевантная информация должна быть определена абсолютно точно для того, чтобы автоматическая система извлечения информации показывала хорошие результаты. Хорошей постановкой задачи можно считать такую, для которой согласованность результатов выделения информации вручную для нескольких экспертов предметной области (inter-annotator agreement) будет высокой (более 90%). Если же ключевая информация скрыта или настолько плохо определена.
Для качественной работы автоматической системы в конкретной предметной области ей необходимо обладать значительными знаниями в этой области. Каждая предметная область предполагает извлечение данных различного характера, свой специфический профессиональный словарь и стиль написания текста.
Каждая конкретная задача извлечения данных из текста предусматривает слоты разных видов: для событий, персоналий, организаций, дат и т. д. Целевой фрейм и правила извлечения информацииописывают условия, при которых создается экзофрейм и способ заполнения его слотов.
Рассмотрим типичное применение системы извлечения информации. Задается массив текстов, в каждом из которых потенциально присутствует описание некоторого объекта или события предметной области. Например, это может быть подборка новостей, в которых может встречаться информация о появлении новых товаров на рынке. Другой пример –– набор домашних страниц сотрудников какой-либо организации. Помимо этого задано определение целевой информации (можно рассматривать его как список вопросов, относящихся к предметной области). Для каждого текста из массива на основании определения целевой информации требуется выделить ответы на вопросы в виде фрагмента текста. Для подборки новостей целью может быть обнаружение названия товара, названия фирмы-производителя и даты появления товара на рынке; для домашних страниц––обнаружение имени владельца страницы, его домашнего адреса и подразделения, в котором он работает.
На всех этапах обработки текста на естественном языке присутствует неопределенность, которая разрешается разными средствами. Большую проблему представляет построение словарей, тезаурусов, онтологий. Эта работа по большей части выполняется вручную. Попытки автоматизации данной работы проводились с использованием статистических методов и методов машинного обучения. На настоящий момент, по-видимому, нет свободно доступных исследований, описывающих всестороннее решение этой проблемы.
Применение методов машинного обучения может упростить настройку и разработку систем извлечения информации и облегчить переключение всей системы на новую предметную область. Рассмотрим уровни анализа текста в целом, а затем возможность и эффективность использования применения машинного обучения для контекстного снятия омонимии, синтаксического анализа, определения семантических классов, построения правил извлечения информации и объединения частичных результатов.
Системы извлечения информации используют во многом сходные методы. Обратимся к типичной последовательности обработки текста в задачах извлечения информации. Сразу будем отмечать этапы обработки, для которых было бы полезно использовать машинное обучение. К ним относятся, в первую очередь, те этапы, которые требуют тонкой настройки в конкретных приложениях.
Исходный текст подвергается графематическому анализу; происходит выделение слов и предложений. На следующих этапах происходит обнаружение составных слов, которые должны рассматриваться как одно (с точки зрения морфологического анализатора). Графематический анализ обычно не требует настройки, зависящей от предметной области, поскольку реализация общего алгоритма графематического анализа подходит для большинства реальных приложений.
Морфологический анализ обычно работает на уровне отдельных слов (возможно, составных) и возвращает морфологические атрибуты данного слова. В случае, когда атрибуты не могут быть установлены однозначно, возвращается несколько возможных вариантов морфологического анализа. Использование методов машинного обучения для морфологического анализа не принесет пользы, так как существует множество высококачественных словарных и бессловарных решений этой задачи, которые могут применяться в широком спектре приложений.
Результаты морфологического анализа используются при микрои макросинтаксическом анализе. Микросинтаксический анализ осуществляет построение ограниченного набора синтаксических связей (например, выделение именных групп). Задача макросинтаксического анализа состоит в выделении в предложении крупных синтаксических единиц––фрагментов––и в установлении иерархии на множестве этих фрагментов. Разбиение на микро- и макросинтаксический анализ условно, оно отображает тот факт, что для большинства задач извлечения информации достаточно поверхностного (микросинтаксического анализа).
Эксперименты показывают, что лингвистический анализатор, обладающий богатыми выразительными возможностями, дает больше ошибок из-за того, что почти каждый уровень анализа представляет собой задачу, которая не имеет строгого, а тем более формализуемого, решения. В наибольшей мере это относится к синтаксическому анализу. Поэтому в предметной области, где достаточно простого синтаксического анализа, мощный анализатор будет лишь вносить нежелательный шум, а производительность будет падать. В то же время существуют предметные области, в которых для извлечения информации требуются развитые возможности представления лингвистической информации. В таких предметных областях примитивный анализатор не сможет предоставить необходимых для извлечения целевой информации лингвистических атрибутов. Настройка выполняется вручную, поэтому данный этап анализа выиграл бы от применения машинного обучения.
Поскольку у каждого слова после выполнения морфологического анализа может присутствовать несколько омонимичных словоформ, то для улучшения качества синтаксического анализа и повышения его производительности можно использовать алгоритмы устранения омонимии, которые сокращают количество вариантов морфологического анализа. Часто задача снятия омонимии решается при помощи наборов правил, составление которых очень трудоемко, поскольку практически применимые наборы оказываются довольно крупными.
Кроме того, для каждой предметной области набор правил приходится модифицировать. Снятие омонимии –– еще одна область анализа текста, которая может быть улучшена при помощи машинного обучения.
В дальнейшем происходит выделение семантических классов (составных типов). При выделении составных типов осуществляется пометка фрагментов текста, которые позже (например, при применении правил) рассматриваются как единое целое (например, даты, имена, должности). Выделение семантических классов осуществляется на основе тезаурусов или правил, подобных правилам извлечения информации. Оба варианта представляют интерес с точки зрения методов машинного обучения. Первый, к сожалению, практически невозможно автоматизировать, а второй мы рассмотрим ниже. Затем осуществляется применение правил извлечения информации к тексту. При выполнении условий и ограничений, описанных в правилах, выполняется функциональная часть правил. Функциональная часть позволяет строить целевые структуры данных или сохранять дополнительную информацию, которая будет использована на последующих этапах. Чаще всего правила группируются по фазам: правила последующих фаз имеют доступ к информации, порожденной правилами предыдущих. Построение и тестирование наборов правил извлечения информации, особенно для сложной предметной области –– трудоемкая задача, для которой предлагается ряд удовлетворительных решений с применением машинного обучения.
Целевые фреймы могут быть подвергнуты дополнительной обработке с целью повышения качества работы системы. Для этого используются средства разрешения кореферентности и объединения частичных результатов.
При разрешении кореферентности в целевых фреймах особым образом помечаются объекты, которые описываются разными фрагментами текста, но указывают на одну сущность реального мира. Исследования показывают, что нет общего решения проблемы кореферентности, однако существуют общие подходы, которые приемлемо работают во множестве предметных областей, но требуют настройки при переходе от одной области к другой, следовательно здесь также потенциально может быть использовано машинное обучение.
Объединение частичных результатов заключается в поиске частично заполненных целевых фреймов и принятии решения о возможности объединения результатов. В случае, когда объединение возможно, из нескольких целевых фреймов собирается один, обладающий более полной информацией, чем каждый из исходных. Объединение частичных результатов не имеет общего решения, как и ряд перечисленных выше проблем, а требует настройки на предметную область. Особенность этого этапа заключается в том, что есть ряд подходов, реализующих алгоритмы из области машинного обучения и близкие к ним (часто статистические), но помимо настройки параметров алгоритма, требуется выбор алгоритма для каждой предметной области и его творческая «доводка» для решения конкретной задачи. Алгоритмы построения правил объединения частичных результатов часто сходны с алгоритмами построения правил извлечения информации.
Качество морфологического анализа можно повысить при помощи контекстного анализа. Это позволит в большинстве случаев избавиться от морфологической омонимии. Модуль контекстного анализа можно настраивать на произвольную предметную область. Для этого необходимо обучающей программе модуля предоставить множество текстов –– документов целевой предметной области. На этом множестве обучающая программа выделит наиболее характерный контекст для значимых с точки зрения омонимии слов и будет использовать его в дальнейшем для разрешения омонимической неоднозначности.
Контекстный анализ, по-видимому, не решит всех проблем омонимии для русского языка. Например, в русском языке у многих существительных совпадает написание в винительном и именительном падежах (при этом возможный контекст лексемы практически не изменяется); то же касается имен собственных. Об этом говорит сайт https://intellect.icu . Но существует множество случаев, когда контекстный анализ отсеет нерелевантные омонимы. Зарубежные аналоги показывают высокую точность работы морфологических процессоров при использовании технологии, основанной на скрытых Марковских моделях и правилах специального вида. Существуют реализации как для супервизорного обучения, так и для обучения «без учителя».
Для использования машинного обучения при синтаксическом анализе требуется тщательная разметка больших объемов текстов, поэтому супервизорное обучение применять неперспективно.
Эксперименты по настройке синтаксического анализатора с применением машинного обучения «без учителя», показывают, что синтаксическая структура естественного языка слишком выразительна и сложна, чтобы можно было эффективно строить его модель, не располагая размеченными текстами.
Если говорить о практической стороне, то для реализации синтаксического анализа с использованием машинного обучения «без учителя» самым эффективным подходом представляется статистическое обучение, когда выделение синтаксических структур производится без использования лингвистических знаний. Вместо этого можно подсчитывать частоты совместной встречаемости слов. Подобный подход (для русского языка) был исследован в, но и там значительное место занимают жестко заложенные в систему формально-грамматические правила. Тем не менее, очень значимым для качества работы системы будет адаптивный синтаксический анализ. В зависимости от задач, которые мы хотим решать, не всегда рационально использовать всю мощность синтаксического анализатора. Иногда бывает достаточно разобрать лишь те характеристики предложения, которые нам требуются с прикладной точки зрения и имеют меньшую вероятность ошибки при разборе. Тогда работу синтаксического анализатора можно будет модифицировать в соответствии с прикладными целями (в том числе и средствами машинного обучения).
Важным свойством для системы извлечения информации является ее способность определять семантические классы фрагментов текста. Набор семантических классов может включать в себя разные составляющие –– от примитивных вариантов (например, определение дат) до выделения именованных сущностей и определения их класса (например, «Организация», «Персона», «Должность»). Это позволит при задании правил извлечения информации оперировать не отдельными словами и их взаимосвязями, а сущностями, характерными для предметной области.
Машинное обучение в этом контексте, скорее всего, возможно только в супервизорном варианте, поскольку применение кластеризации на множестве семантических классов приведет к результатам, с трудом воспринимаемыми человеком.
Не следует путать с Data Mining. Извлечение информации (англ. information extraction) — это задача автоматического извлечения (построения) структурированных данных из неструктурированных или слабоструктурированных машиночитаемых документов.
Извлечение информации является разновидностью информационного поиска, связанного с обработкой текста на естественном языке. Примером извлечения информации может быть поиск деловых визитов — формально это записывается так: НанеслиВизит(Компания-Кто, Компания-Кому, ДатаВизита), — из новостных лент, таких как: «Вчера, 1 апреля 2007 года, представители корпорации Пепелац Интернэшнл посетили офис компании Гравицап Продакшнз». Главная цель такого преобразования — возможность анализа изначально «хаотичной» информации с помощью стандартных методов обработки данных. Более узкой целью может служить, например, задача выявить логические закономерности в описанных в тексте событиях.
В современных информационных технологиях роль такой процедуры, как извлечение информации, все больше возрастает — из-за стремительного увеличения количества неструктурированной (без метаданных) информации, в частности, в Интернете. Эта информация может быть сделана более структурированной посредством преобразования в реляционную форму или добавлением XML разметки. При мониторинге новостных лент с помощью интеллектуальных агентов как раз и потребуются методы извлечения информации и преобразования ее в такую форму, с которой будет удобнее работать позже.
Типичная задача извлечения информации: просканировать набор документов, написанных на естественном языке, и наполнить базу данных выделенной полезной информацией. Современные подходы извлечения информации используют методы обработки естественного языка, направленные лишь на очень ограниченный набор тем (вопросов, проблем) — часто только на одну тему.
Тексты на естественном языке могут потребовать некоего предварительного преобразования на язык (например, RDF — Resource Description Framework), понятный для компьютера.
Типичные подзадачи извлечения информации:
Распознавание именованных элементов (сущностей), например: имен людей, названий организаций, географических названий, событий, временны́х и денежных обозначений и пр.
Разрешение анафоры и кореференций : поиск связей, относящихся к одному и тому же объекту. Типичный случай таких ссылок — местоименная анафора.
Выделение терминологии: нахождение для данного текста ключевых слов и словосочетаний (коллокаций).
Автореферирование: выделение из текста смысловой, эмотивной, оценочной и пр. информации. Бывает генеративным и декларативным.
Ключевыми группами задач Интеллектуального анализа текста являются:
Категоризация документов заключается в отнесении документов из коллекции к одной или нескольким группам (классам, кластерам) схожих между собой текстов (например, по теме или стилю). Категоризация может происходить при участии человека, так и без него. В первом случае, называемом классификацией документов, система ИАТ должна отнести тексты к уже определенным (удобным для него) классам. В терминах машинного обучения для этого необходимо произвести обучение с учителем, для чего пользователь должен предоставить системе ИАТ как множество классов, так и образцы документов, принадлежащих этим классам.
Второй случай категоризации называется кластеризацией документов. При этом система ИАТ должна сама определить множество кластеров, по которым могут быть распределены тексты, — в машинном обучении соответствующая задача называется обучением без учителя. В этом случае пользователь должен сообщить системе ИАТ количество кластеров, на которое ему хотелось бы разбить обрабатываемую коллекцию (подразумевается, что в алгоритм программы уже заложена процедура выбора признаков).
В рамках той научной парадигмы, которая сложилась в последнее время и неотъемлемой составляющей которой является психолингвистика, текст рассматривается в первую очередь как продукт речемыслительной деятельности. Вместе с тем сегодня уже абсолютно очевидно и мало у кого вызывает неприятие туверждение,
что текст как таковой (или его часть, фрагмент) может быть выражен и невербальными средствами. Во многих исследованиях текст рассматривается именно как
«креолизованный» продукт, выраженный как вербальными, так и невербальными – паралингвистическими, визуальными и т. д. – средствами. Сегодня уже даже самые «стойкие» лингвисты не отмахиваются от того факта, что при непосредственной коммуникации до 80% информации коммуниканты получают по невербальным каналам, и соглашаются с тем, что невозможно изучать речь, не учитывая экстралингвистических факторов, на нее влияющих. Другими словами, анализировать речевое поведение, игнорируя общий контекст поведения коммуникативного, не принимая во внимание включенность речевой деятельности в общий круг других деятельностей (а это один из постулатов психологии и психолингвистики), не учитывая ситуацию, в которой осуществляется общение, и факторы, влияющие на процессы порождения и восприятия речевого произведения, не рассматривая языковое (лингвокультурное) сознание коммуникантов, сегодня не представляется оправданным, целесообразным и корректным.
«Парадокс текста» – его вербально-невербальная природа – объясняется тем, что из всего спектра средств выражения некоторого смысла (понимаемого в данном
случае с позиций психологии) автор выбирает не только вербальные, но и невербальные (паралингвистические) средства (например, мимику, жесты и т. д.; об этом
много писали, к примеру, Е. А. Земская , Г. В. Колшанский и другие исследователи). Такой невербальный компонент коммуникации оказывается особо ктуальным в наши дни: вспомним, например, недавно появившиеся типы текста – от электронных писем и интернет-текстов до текстов современных теленовостей и клипов (см., напр., ). Но это – тема отдельного разговора. Говоря о комплексном психолингвистическом анализе текста (как одном из возможных подходов), следует иметь в виду, что практически все невербальные компоненты коммуникации и уж тем более все «немые реплики» могут быть вербализованы. Например, «вопросительный» взгляд на собеседника и кивок головы в ответ возможно «перевести» на язык слов: «Ну что? / Ну как? – Хорошо. / Ладно». И таких примеров из непосредственной коммуникации можно привести немало. Если говорить метафорически, то текст можно представить как готовую картинку, «снимок» (своего рода «чистый» пример такого подхода – это понимание текста И. Р. Гальпериным и его последователями: текст рассматривается как готовый, законченный продукт, подвергшийся определенной обработке [3; 17]). Дискурс, если продолжать нашу метафору, – это процесс и то, что его окружает. Таким образом,
можно сказать, что текст – это то, что получилось, когда «художник» (автор / авторы текста) отложил кисть или карандаш. Это может быть рисунок, мгновенный набросок или сложное полотно. Но работа над продуктом завершена, и то, что получилось, начинает жить своей жизнью. Дискурс – это не только и не столько то, что выходит из-под руки автора, но и все наброски на полях, и все зарисовки, и черновики, и сам процесс работы, и мастерская, и сам художник (автор). Безусловно, при восприятии текста (а текст живет именно в момент своего порождения и восприятия его реципиентом / реципиентами) принципиально важными оказываются все аспекты, актуальные для дискурса, все параметры последнего. И это вполне объяснимо, поскольку текст – неотъемлемый «элемент» дискурса. Мы же говорим более четко и категорично: для нас текст есть основная единица дискурса. Дискурс и текст невозможны вне процесса коммуникации (об этом говорили
и писали многие исследователи [12; 14; 17]; то, что текст является единицей коммуникации особо и многократно подчеркивали психолингвисты [2; 4; 14]; однако оговоримся сразу, что для нас коммуникация – это не только процесс непосредственного общения: она может быть «рассеяна», «дистанцирована» во времени и пространстве). Коммуникация осуществляется с целью передачи / получения / обмена информацией, с целью некоторого определенного воздействия на реципиента (что из этого первично, что вторично – вопрос отдельный, не будем на нем останавливаться, поскольку в данном случае это для нас не принципиально). Коммуникация есть процесс и, как всякий процесс, поддается членению. Основной единицей коммуникации, с нашей точки зрения, является коммуникативный акт (КА). Компонентами КА являются ситуация и дискурс, основной единицей последнего является текст (см., напр., ).
Цель подобного анализа – понять, получилось ли у коммуникантов совместная (речевая) деятельность, и показать это на конкретном материале.
Параметры текста, которые подвергаются анализу и вносятся нами в таблицу:
Итак, мы считаем текст основной единицей дискурса. Текст может иметь структуру более простую или более сложную. Минимальной «текстовой» единицей
является микротекст, который характеризуется, в частности, одной предикацией, одной микротемой, одним микроконцептом при порождении (ср. с идеей
Н. И. Жинкина о том, что «во всяком тексте, если он относительно закончен и последователен, высказана одна основная мысль, один тезис, одно положение» [5: 250]. Микротексты могут складываться в единицы более сложной структуры - макротексты; ср.: «Наиболее важной чертой текста, отличающей его от всех других языковых образований, является наличие в тексте смысловой суперструктуры [10: 6] (выделено нами. – В.К.); а также: «Текст есть сложная коммуникативная единица наиболее высокого порядка <…> некая система смысловых единиц разной степени сложности и значимости (с точки зрения достижения целей названной деятельности), функционально (т. е. для данной конкретной цели / целей) объединенных в единую семантико-смысловую структуру общей концепцией (замыслом)» [4: 135]. Макротексты могут иметь в своем составе энное количество микротекстов и, как показывают наши наблюдения, могут также складываться в тексты более «высокого» уровня. В таком случае мы говорим о макротекстах первого уровня, второго уровня и т. д. Своеобразной «вершиной» такой иерархической пирамиды текстов является макротекст самого «высокого» уровня или, если коммуникантам удалось в процессе общения
создать единый текст, макротекст «глобальный». Подобный взгляд соотносим с пониманием текста в психолингвистике, которая рассматривает текст как «форму выражения иерархии смыслообразований разной степени сложности и значимости»
[18: 114-115].
Приведем пример такого строения макротекста (отметим в скобках, что данный текст является далеко не самым сложным по своей структуре). Заметим, что, на
наш взгляд, данный текст являет собой яркую иллюстрацию положения о том, что
«глобальные цели говорящего регулируют расчленение деятельности на ряд подчиненных действий и обеспечивают необходимые отношения типа предпосылка / следствие между ними» [13: 18].
разговор у книжного лотка;
один из коммуникантов увидел некую книгу
А 1 – Слушай, я ведь ее уже давно искала...
2 Сколько стоит?
2’ ... [Берет книгу и, увидев цену, присвистывает]
3 Слушай, у тебя есть деньги?
Б 4 – Есть.
А 5 – Можно стрельнуть?
Б 6 – Сколько тебе?
А 7 – Ну, полтинник.
Б 8 – Держи...
8’ Точно хватит?
А 9 – Да, конечно. Мерси.
9’ Завтра верну.
Б 10 [Ничего не говоря, машет рукой]
А 11 – Ну, наконец-то!.. Сбудется мечта идиота!
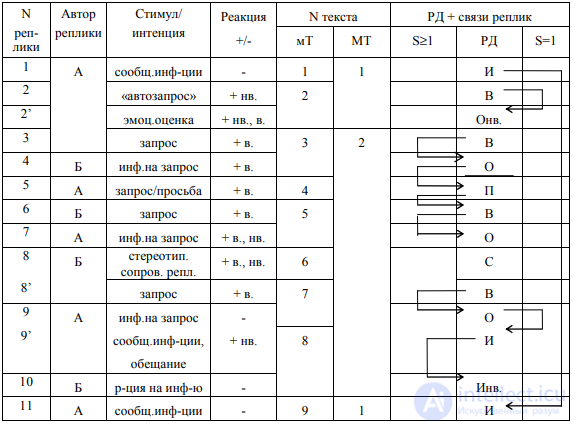
В данном случае мы обозначили коммуникантов и проставили номера реплик, чтобы при анализе не повторять сами реплики, но называть только их номер. При
этом в трех случаях мы использовали знак «штрих» (2 – 2’, 8 – 8’ и 9 – 9’), чтобы показать, что имеет место одна реплика, но начало ее «закрывает» предшествующий микротекст, а конец ее «открывает» последующий.
Две реплики: вторая часть реплики (2) – (2’) и (10) – выражены невербальными средствами, но легко понимаются и при желании могут быть вербализованы.
Стимулом большинства реплик является предшествующая реплика партнера по коммуникации.
В анализируемой ситуации конситуация остается практически неизменной в процессе коммуникативного акта, параметр времени в данном случае также оказывается релевантным, т. к. реплики следуют одна за другой, практически не прерываясь паузами. Итак, представим нашу таблицу в несколько редуцированном виде (см. табл. 1).
Таким образом, из приведенной таблицы видно, что границы текста (даже если речь идет о микротексте) далеко не всегда совпадают с границами реплик. При этом
не только несколько реплик могут входить в один текст (что достаточно очевидно), но и в пределах одной реплики может проходить «межа» между текстами (реплики 8–8’ и 9–9’, внутри которых проходит граница между микротекстами 6–7 и 7–8, соответственно).
Далее, в представленную нами таблицу 1 мы не включили графу «логикосмыловые блоки (ЛСБ)», поскольку в данном случае этот параметр также оказался
неревантным. ЛСБ, с нашей точки зрения, есть фрагмент коммуникации, тесно связанный с конситуацией и, следовательно, с ее изменениями, принципиально важными для протекания коммуникации3 (каковых в рассматриваемом коммуникативном акте не наблюдается). ЛСБ определяется логикой ситуации и смысловыми связями как ситуации в целом, так и, следовательно, в порождаемом речемыслительном продукте (тексте), поскольку включает в себя коммуникативные – в самом широком смысле (т. е. не только речевые) действия. Как и в случае с соотношением «текст – реплики», между границами ЛСБ и границами текстов нет жесткого соответствия: один ЛСБ может содержать несколько текстов (как микро-, так и макро-), внутри ЛСБ может проходить граница между текстами и т. д.
Таблица 14
.
Что касается структуры анализируемого текста, с точки зрения аранжировки макротекстов, то она может быть представлена следующим образом (см. сх.1):
Схема 1. Структура анализируемого текста.

Предлагаемая методика позволяет определить психолингвистические характеристики анализируемого текста:
Помимо этого, наш анализ позволяет определить коммуникативное поведение участников коммуникации.
Психолингвистическими характеристиками приведенного текста являются:
В заключение отметим, что наши исследования показывают, что при наличии единого мотива, единой установки на осуществление совместной деятельности и при
осуществлении таковой коммуникантам удается «создать» единый текст. Если отсутствует единый мотив, но есть установка на осуществление совместной деятельности, текст может получиться. Однако при наличии единого мотива, но при отсутствии указанной установки и совместной деятельности о порождении коммуникантами единого текста (с какой бы ни было сложной или простой структурой) речь не идет.
Таким образом, если взглянуть на эту ситуацию с другой стороны, то можно сделать вывод о том, что если мы не имеем единого текста, как результата речемыслительной деятельности участников коммуникации, то это отсутствие значимо: у коммуникантов не было установки на совместную деятельность (единый мотив к осуществлению деятельности может также отсутствовать) или же участники коммуникации не смогли (в силу каких-либо причин) осуществить таковую.
В последнее время анализ текста привлекает все больше внимания в различных областях, таких как безопасность, коммерция, наука.
Многие пакеты анализа текста, такие как Aerotext и Attensity, нацелены на рынок приложений безопасности, в частности на анализ источников простого текста, например новостных сайтов.
Исследования и разработки подразделений крупных компаний, таких как IBM, Apple и Microsoft, исследуют технологии анализа текста с целью будущей автоматизации процессов анализа и извлечения данных.
1 Соотношение таких феноменов, как текст, логико-смысловой блок, коммуникативный акт, оговаривается нами особо в настоящей статье.
2 Мы не считаем текст языковым образованием, однако идея об обязательном наличии в тексте смысловой суперструктры нам достаточно близка. О том, что текст не представляет собой «текстему» как лингвистическую единицу и является единицей не языка, но речи, «элементом» системы коммуникации – см., например, [11; 14; 2].
3 ЛСБ некоторым (непрямым – sic!) образом соотносится с функционально-семантическим представлением (ФСП), который «отражает акт референтной привязки содержания текста к целевому (иллокутивному) акту», «отражает взаимодействие содержательной стороны текста с его функциональным
выражением» [16: 11]. Общим для данных феноменов (ФСП и ЛСБ) является «акт референтной привязки», однако мы говорим о некотором иллокутивном акте, но о фрагменте дискурса в его связи с ситуацией.
4 Сокращения, принятые в таблице: мТ – микротекст; МТ – макротекст; РД – речевое действие; в. – вербальная (реакция); нв. – невербальная; И – информация; О – ответ; В – вопрос; П – просьба; С – стереотип; сообщ.инф-ции – сообщение информации; эмоц.оценка – эмоциональная реакция-оценка на ситуацию; инф.на запрос – сообщение информации на запрос; стереотип. сопров. репл. – стереотипная реплика, сопровождающая невербальное действие; р-ция на инф-ю – реакция на информацию.
Если я не полностью рассказал про анализ текста? Напиши в комментариях Надеюсь, что теперь ты понял что такое анализ текста, обработка текста при извлечении информации, интеллектуальный анализ текстов, иат, text mining и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Моделирование мыслительных процессов на естественном языке и Символьное моделирование
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.
Комментарии
Оставить комментарий
Моделирование мыслительных процессов на естественном языке и Символьное моделирование
Термины: Моделирование мыслительных процессов на естественном языке и Символьное моделирование