Лекция
Привет, сегодня поговорим про анализ текстовой информации, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое анализ текстовой информации, text mining, интеллектуальный анализ текстов, иат , настоятельно рекомендую прочитать все из категории Интеллектуальный анализ данных.
Формулируются задачи анализа текстов (этапы анализа текстов, предсредним обработка текста, задачи Text Mining). Рассматриваются этапы анализа
текстов, такие как извлечение ключевых понятий из текста (общее описание процесса
извлечения понятий из текста, стадия локального анализа, стадия интеграции и вывода понятий), классификация текстовых документов (описание задач классификационной ции текстов, методы классификации текстовых документов), методы кластеризации текстовых документов (наведение текстовых документов, иерархические методы кластеризации текстов, бинарные методы кластеризации текстов), анотирование текстов (выполнение аннотирования текстов, методы извлечения фрагментов для аннотации). Сравниваются различные средства анализа текстовой информации (средства Oracle - Oracle Text, средства от IBM - Intelligent Miner for Text, заства SAS Institute - Text Miner, средства Мега-компьютер Интеллидженс -TextAnalyst).
интеллектуальный анализ текстов ( иат , англ. text mining) — направление в искусственном интеллекте, целью которого является получение информации из коллекций текстовых документов, основываясь на применении эффективных в практическом плане методов машинного обучения и обработки естественного языка. Название «интеллектуальный анализ текстов» перекликается с понятием «интеллектуальный анализ данных» (ИАД, англ. data mining), что выражает схожесть их целей, подходов к переработке информации и сфер применения; разница проявляется лишь в конечных методах, а также в том, что ИАД имеет дело с хранилищами и базами данных, а не электронными библиотеками и корпусами текстов.
Интеллектуальный анализ текста , также называемый интеллектуальным анализом текстовых данных , похож на текстовую аналитику , - это процесс получения высококачественной информации из текста . Он включает «обнаружение компьютером новой, ранее неизвестной информации путем автоматического извлечения информации из различных письменных ресурсов». Письменные ресурсы могут включать веб-сайты , книги , электронные письма , обзоры и статьи. Качественная информация обычно получается путем разработки шаблонов и тенденций с помощью таких средств, как статистическое изучение шаблонов.. Согласно Hotho et al. (2005) мы можем различать три разных точки зрения интеллектуального анализа текста : извлечение информации , интеллектуальный анализ данных и процесс KDD (обнаружение знаний в базах данных). Интеллектуальный анализ текста обычно включает в себя процесс структурирования входного текста (обычно анализ с добавлением некоторых производных лингвистических функций и удаление других с последующей вставкой в базу данных ), получение шаблонов в структурированных данных и, наконец оценка и интерпретация результатов. «Высокое качество» в интеллектуальном анализе текста обычно относится к некоторому сочетанию актуальности и новизны., и интерес. Задачи горнодобывающих Типичный текста включают текст категоризацию , наслоение текста , концепцию / извлечение сущности, производство гранулированных таксономии, анализ настроений , документ обобщению и моделирование отношения сущностей ( т.е. , изучение отношений между названными лицами ).
Анализ текста включает в себя поиск информации , лексический анализ для изучения частотного распределения слов, распознавание образов , маркировку / аннотацию , извлечение информации , методы интеллектуального анализа данных , включая анализ связей и ассоциаций, визуализацию и прогнозную аналитику . Общая цель, по сути, - превратить текст в данные для анализа с помощью обработки естественного языка (NLP), различных типов алгоритмов и аналитических методов. Важным этапом этого процесса является интерпретация собранной информации.
Типичное приложение - сканировать набор документов, написанных на естественном языке, и либо моделировать набор документов для целей прогнозной классификации, либо заполнять базу данных или поисковый индекс извлеченной информацией. Документ является основным элементом в то время , начиная с добычей текста. Здесь мы определяем документ как блок текстовых данных, который обычно существует во многих типах коллекций.
ПЛАН
1.Задача анализа текстов (этапы анализа текстов, предварительная обработка текста, задачи Text Mining)
2.Извлечение ключевых понятий из текста (общее описание процесса понятий из текста, стадия локального анализа, стадия интеграции и выводу понятий).
3.Классификация текстовых документов (описание задачи классификации текстов, методы классификации текстовых документов).
4 Методы кластеризации текстовых документов (представление текстовых доментов, иерархические методы кластеризации текстов, бинарные методы кластери-
зации текстов).
5.Задача аннотирования текстов (выполнение аннотирования текстов, методыдобывания фрагментов для аннотации).
6.Средства анализа текстовой информации (сре Oracle - Oracle Text, сре от IBM - Intelligent Miner for Text, сре SAS Institute - Text Miner, сре Мега-компьютер Интелидженс - Text Analyst).
Анализ структурированной информации, хранящейся в базах данных, требует предварительной обработки: проектирования БД, ввод информации по определенным правилам, размещение ее в специальных структурах (например, реляционных таблицах) и т. п. Таким образом, непосредственно для анализа этой информации и получения из нее новых знаний необходимо затратить дополнительные усилия. При этом они не всегда связаны с анализом и не обязательно приводят к желаемому результату. Из-за этого КПД анализа структурированной информации снижается. Кроме того, не все виды данных можно структурировать без потери полезной информации. Например, текстовые документы практически невозможно преобразовать в табличное представление без потери семантики текста и отношений между сущностями. По этой причине такие документы хранятся в БД без преобразований, как текстовые поля (BLOB-поля). В то же время в тексте скрыто огромное количество информации, но ее неструктурированность не позволяет использовать алгоритмы Data Mining. Решением этой проблемы занимаются методы анализа неструктурированного текста. В западной литературе такой анализ называют Text Mining.
Методы анализа в неструктурированных текстах лежат на стыке нескольких областей: Data Mining, обработка естественных языков, поиск информации, извлечение информации и управление знаниями.
В работе [41] по аналогии с термином Data Mining (см. гл. 4) дано следующее определение:
Обнаружение знаний в тексте — это нетривиальный процесс обнаружения действительно новых, потенциально полезных и понятных шаблонов в неструктурированных текстовых данных.
Как видно, от определения Data Mining оно отличается только новым понятием "неструктурированные текстовые данные". Под такими знаниями понимается набор документов, представляющих собой логически объединенный текст без каких-либо ограничений на его структуру. Примерами таких документов являются: Web-страницы, электронная почта, нормативные документы и т. п. В общем случае такие документы могут быть сложными и большими и включать в себя не только текст, но и графическую информацию. Документы, использующие язык расширяемой разметки XML (eXtensible Markup Language), стандартный язык обобщенной разметки SGML (Standard Generalised Markup Language) и другие подобные соглашения по структуре формирования текста, принято называть полуструктурированными документами. Они также могут быть обработаны методами Text Mining.
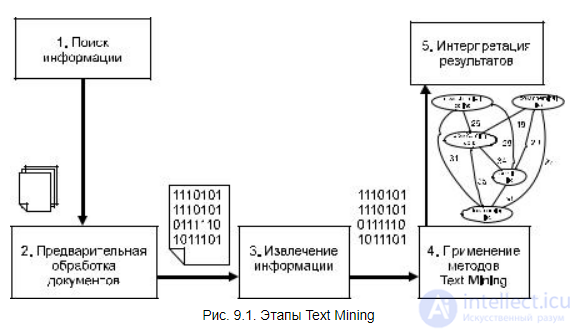
Рис. 9.1. Этапы Text Mining
Процесс анализа текстовых документов можно представить как последовательность нескольких шагов (рис. 9.1).
1.Поиск информации. На первом шаге необходимо идентифицировать, какие документы должны быть подвергнуты анализу, и обеспечить их доступность. Как правило, пользователи могут определить набор анализируемых документов самостоятельно — вручную, но при большом количестве документов необходимо использовать варианты автоматизированного отбора по заданным критериям.
2.Предварительная обработка документов. На этом шаге выполняются простейшие, но необходимые преобразования с документами для представления их в виде, с которым работают методы Text Mining. Целью таких преобразований является удаление лишних слов и придание тексту более строгой формы. Подробнее методы предварительной обработки будут описаны в разд. 9.1.2.
3.Извлечение информации. Извлечение информации из выбранных документов предполагает выделение в них ключевых понятий, над которыми в дальнейшем будет выполняться анализ. Данный этап является очень важным и будет подробно описан в разд. 9.1.3.
4.Применение методов Text Mining. На данном шаге извлекаются шаблоны
и отношения, имеющиеся в текстах. Данный шаг является основным в процессе анализа текстов, и практические задачи, решаемые на этом шаге, описываются в разд. 9.1.4.
5.Интерпретация результатов. Последний шаг в процессе обнаружения знаний предполагает интерпретацию полученных результатов. Как правило, интерпретация заключается или в представлении результатов на естественном языке, или в их визуализации в графическом виде.
Визуализация также может быть использована как средство анализа текста. Для этого извлекаются ключевые понятия, которые и представляются в графическом виде. Такой подход помогает пользователю быстро идентифицировать главные темы и понятия, а также определить их важность.
Подзадачи - компоненты более широкой работы по аналитике текста - обычно включают:
Одной из главных проблем анализа текстов является большое количество слов в документе. Если каждое из этих слов подвергать анализу, то время поиска новых знаний резко возрастет и вряд ли будет удовлетворять требованиям пользователей. В то же время очевидно, что не все слова в тексте несут полезную информацию. Кроме того, в силу гибкости естественных языков формально различные слова (синонимы и т. п.) на самом деле означают одинаковые понятия. Таким образом, удаление неинформативных слов, а также приведение близких по смыслу слов к единой форме значительно сокращают время анализа текстов. Устранение описанных проблем выполняется на этапе предварительной обработки текста.
Обычно используют следующие приемы удаления неинформативных слов и повышения строгости текстов:
удаление стоп-слов. Стоп-словами называются слова, которые являются вспомогательными и несут мало информации о содержании документа. Обычно заранее составляются списки таких слов, и в процессе предварительной обработки они удаляются из текста. Типичным примером таких слов являются вспомогательные слова и артикли, например: "так как", "кроме того" и т. п.;
стемминг — морфологический поиск. Он заключается в преобразовании каждого слова к его нормальной форме. Нормальная форма исключает
клонение слова, множественную форму, особенности устной речи и т. п. Например, слова "сжатие" и "сжатый" должны быть преобразованы в нормальную форму слова "сжимать". Алгоритмы морфологического разбора учитывают языковые особенности и вследствие этого являются языковозависимыми алгоритмами;
N-граммы — это альтернатива морфологическому разбору и удалению стоп-слов. N-грамма — это часть строки, состоящая из N символов. Например, слово "дата" может быть представлено 3-граммой "_да", "дат", "ата", "та_" или 4-граммой "_дат", "дата", "ата_", где символ подчеркивания заменяет предшествующий или замыкающий слово пробел. По сравнению со стеммингом или удалением стоп-слов, N-граммы менее чувствительны к грамматическим и типографическим ошибкам. Кроме того, N-граммы не требуют лингвистического представления слов, что делает данный прием более независимым от языка. Однако N-граммы, позволяя сделать текст более строгим, не решают проблему уменьшения количества неинформативных слов;
приведение регистра. Этот прием заключается в преобразовании всех символов к верхнему или нижнему регистру. Например, все слова "текст", "Текст", "ТЕКСТ" приводятся к нижнему регистру "текст".
Наиболее эффективно совместное применение перечисленных методов.
В настоящее время в литературе описано много прикладных задач, решаемых с помощью анализа текстовых документов. Это и классические задачи Data Mining: классификация, кластеризация, и характерные только для текстовых документов задачи: автоматическое аннотирование, извлечение ключевых понятий и др.
Классификация (classification) — стандартная задача из области Data Mining. Ее целью является определение для каждого документа одной или нескольких заранее заданных категорий, к которым этот документ относится. Особенностью задачи классификации является предположение, что множество классифицируемых документов не содержит "мусора", т. е. каждый из документов соответствует какой-нибудь заданной категории.
Частным случаем задачи классификации является задача определения тематики документа [43].
Целью кластеризации (clustering) документов является автоматическое выявление групп семантически похожих документов среди заданного фиксированного множества. Отметим, что группы формируются только на основе попарной схожести описаний документов, и никакие характеристики этих групп не задаются заранее [43].
Автоматическое аннотирование (summarization) позволяет сократить текст, сохраняя его смысл. Решение этой задачи обычно регулируется пользователем при помощи определения количества извлекаемых предложений или процентом извлекаемого текста по отношению ко всему тексту. Результат включает в себя наиболее значимые предложения в тексте.
Первичной целью извлечения ключевых понятий (feature extraction) является идентификация фактов и отношений в тексте. В большинстве случаев такими понятиями являются имена существительные и нарицательные: имена и фамилии людей, названия организаций и др. Алгоритмы извлечения понятий могут использовать словари, чтобы идентифицировать некоторые термины и лингвистические шаблоны для определения других.
Навигация по тексту (text-base navigation) позволяет пользователям перемещаться по документам относительно тем и значимых терминов. Это выполняется за счет идентификации ключевых понятий и некоторых отношений между ними.
Анализ трендов позволяет идентифицировать тренды в наборах документов на какой-то период времени. Тренд может быть использован, например, для обнаружения изменений интересов компании от одного сегмента рынка к другому.
Поиск ассоциаций также является одной из основных задач Data Mining. Для ее решения в заданном наборе документов идентифицируются ассоциативные отношения между ключевыми понятиями.
Существует достаточно большое количество разновидностей перечисленных задач, а также методов их решения. Это еще раз подтверждает значимость анализа текстов. Далее в этой главе рассматриваются решения следующих задач: извлечение ключевых понятий, классификация, кластеризация и автоматическое аннотирование.
Ключевыми группами задач ИАТ являются:
Категоризация документов заключается в отнесении документов из коллекции к одной или нескольким группам (классам, кластерам) схожих между собой текстов (например, по теме или стилю). Категоризация может происходить при участии человека, так и без него. В первом случае, называемом классификацией документов, система ИАТ должна отнести тексты к уже определенным (удобным для него) классам. В терминах машинного обучения для этого необходимо произвести обучение с учителем, для чего пользователь должен предоставить системе ИАТ как множество классов, так и образцы документов, принадлежащих этим классам.
Второй случай категоризации называется кластеризацией документов. При этом система ИАТ должна сама определить множество кластеров, по которым могут быть распределены тексты, — в машинном обучении соответствующая задача называется обучением без учителя. В этом случае пользователь должен сообщить системе ИАТ количество кластеров, на которое ему хотелось бы разбить обрабатываемую коллекцию (подразумевается, что в алгоритм программы уже заложена процедура выбора признаков).
Извлечение ключевых понятий из текста может рассматриваться и как отдельный этап анализа текста, и как определенная прикладная задача. В первом случае извлеченные из текста факты используются для решения различных задач анализа: классификации, кластеризации и др. Большинство методов Data Mining, адаптированные для анализа текстов, работают именно с такими отдельными понятиями, рассматривая их в качестве атрибутов данных.
В задаче извлечения ключевых понятий из текста интерес представляют некоторые сущности, события и отношения. При этом извлеченные понятия анализируются и используются для вывода новых. В данном разделе и будет описано решение такой задачи. При этом часть процесса решения может быть использована для выделения ключевых понятий при решении других задач анализа текста.
Извлечение ключевых понятий из текстовых документов можно рассматривать как фильтрацию больших объемов текста. Этот процесс включает в себя отбор документов из коллекции и пометку определенных термов в тексте. Существуют различные подходы к извлечению информации из текста. Примером может служить определение частых наборов слов и объединение их в ключевые понятия. Для определения частых наборов используется алгоритм Apriori, описанный в разд. 6.3.
Другим подходом является идентификация фактов в текстах и извлечение их характеристик [48]. Фактами являются некоторые события или отношения. Идентификация производится с помощью наборов образцов. Образцы представляют собой возможные лингвистические варианты фактов.
Такой подход позволяет представить найденные ключевые понятия, представленные событиями и отношениями, в виде структур, которые в том числе можно хранить в базах данных.
Процесс извлечения ключевых понятий с помощью шаблонов разбивается на две стадии: локальный анализ и анализ понятий (рис. 9.2). На первой стадии из текстовых документов извлекаются отдельные факты с помощью лексического анализа. Вторая стадия заключается в интеграции извлеченных фактов и/или в выводе новых фактов. В конце наиболее характерные факты преобразовываются в нужную выходную форму.
Сложность извлечения фактов с помощью образцов связана с тем, что на практике их нельзя представить в виде простой последовательности слов. В большинстве систем обработки естественных языков вначале идентифицируются различные уровни компонентов и отношений, а затем на их основе строятся образцы. Этот процесс обычно начинается с лексического анализа (определения частей речи и характеристик слов и фраз посредством морфологического анализа и поиска по словарю) и распознавания имен (идентификации имен и других лексических структур, таких как даты, денежные выражения и т. п.). За этим следует синтаксический разбор, целью которого является выявление групп существительных, глаголов и, если возможно, дополнительных структур. Затем применяются предметно-ориентированные образцы для идентификации интересующих фактов.
На стадии интеграции найденные в документах факты исследуются и комбинируются. Это выполняется с учетом отношений, которые определяются ме-
стоимениями или описанием одинаковых событий. Также на этой стадии делаются выводы из ранее установленных фактов.
Как уже отмечалось ранее, извлечение фактов выполняется при помощи сопоставления текста с набором регулярных выражений (образцов). Если выражение сопоставляется с текстовыми сегментами, то такие сегменты помечаются метками. При необходимости этим сегментам приписываются дополнительные свойства. Образцы организуются в наборы. Метки, ассоциированные с одним набором, могут ссылаться на другие наборы.
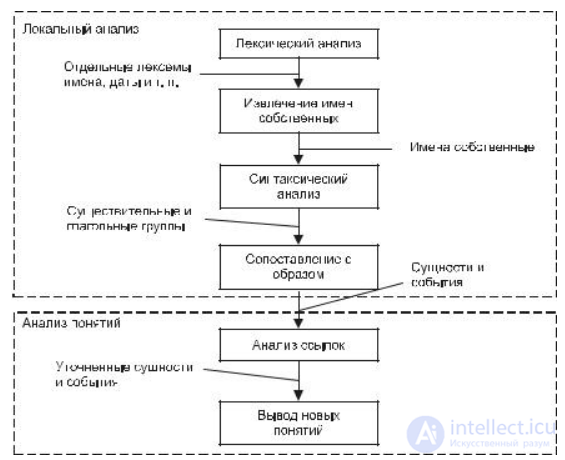
Рис. 9.2. Процесс извлечения ключевых понятий
Каждый образец имеет связанный с ним набор действий. Как правило, главное действие — это пометить текстовый сегмент новой меткой, но могут быть и другие действия. В каждый момент времени текстовому сегменту сопоставляется только один набор образцов. Каждый образец в наборе начинает сопоставляться с первого слова предложения. Если образец может быть сопоставлен более чем одному сегменту, то выбирается наиболее длинный сопоставленный сегмент. Если таких сегментов несколько, то выбирается первый. При сопоставлении выполняются действия, ассоциированные с этим образцом. Если не удалось сопоставить ни один образец, то сопоставление
повторяется, начиная со следующего слова в предложении. Если сегмент сопоставлен с образцом, то сопоставление повторяется, начиная со следующего слова после сегмента. Процесс продолжается до конца предложения.
Основной целью сопоставления с образцами является выделение в тексте сущностей, связей и событий. Все они могут быть преобразованы в некоторые структуры, которые могут анализироваться стандартными методами Data Mining.
Рассмотрим процесс выделения ключевых понятий на примере следующего текста:
Петр Сергеевич Иванов покинул должность вице-президента известной фабрики ООО "Анкор". Его заменил Иван Андреевич Сидоров.
На этапе лексического анализа текст делится на предложения и лексемы. Каждая лексема ищется в словаре для определения ее части речи и других свойств. Такой словарь готовится заранее экспертами в данной предметной области и должен включать, кроме специальных терминов, имена людей, названия городов, стран, префиксы компаний (такие как "ООО", "ЗАО", "АО" и т. п.) и др. В нашем примере на этом этапе должны быть идентифицированы следующие лексемы: "Петр", "Иван", "ООО". При этом "Петр" и "Иван" помечаются как имена, а "ООО" — как префикс фирмы.
На следующем этапе идентифицируются различные типы имен собственных и другие специальные формы, такие как даты, денежные выражения и т. п. Имена присутствуют в текстах различного вида. Определить их достаточно просто, но они являются важными ключевыми понятиями.
Имена идентифицируются с помощью образцов (регулярных выражений), которые строятся на основе частей речи, синтаксических и орфографических свойств (например, использование заглавных букв). Например, люди могут быть идентифицированы:
предшествующими званиями: "мистер", "сударь", "господин", "товарищ" и т. п. (например, мистер Смит, господин Иванов, товарищ Сталин
и т. д.);
распространенными именами: "Иван", "Петр", "Елена" и т. п. (например, Иван Сидоров, Елена Премудрая, Петр Сергеевич Иванов и т. д.);
предшествующими инициалами имени и отчества (например, И. И. Сидоров, Е. А. Иванова и т. д.).
Компании могут идентифицироваться с помощью лексем, обозначающих форму их организации "ООО", "ЗАО" и т. п.
В нашем примере можно идентифицировать три имени собственных:
Петр Сергеевич Иванов с типом "человек";
Иван Андреевич Сидоров с типом "человек";
ООО "Анкор" с типом "фирма".
Врезультате получим следующую структуру:
[имя собственное тип: человек Петр Сергеевич Иванов] покинул должность вице-президента известной фабрики [имя собственное тип: фирма ООО
"Анкор"]. Его заменил [имя собственное тип: человек Иван Андреевич Сидоров].
При идентификации имен собственных также важно распознавать и альтернативное их написание (другие формы тех же имен). Например, "Петр Сергеевич Иванов", "П. С. Иванов", "Петр Иванов", "господин Иванов" должны быть идентифицированы как одно и то же лицо. Такое сопоставление различных написаний имен собственных может помочь в идентификации свойств понятия. Например, по выражению "Елена работает с 9:00 до 20:00" невозможно понять, Елена является человеком или фирмой с названием "Елена" (однозначно это сложно определить даже человеку). Однако если в тексте также встречается альтернативное написание "ООО "Елена", то понятию "Елена" можно присвоить тип "фирма".
Идентификация некоторых аспектов синтаксических структур упрощает последующие фазы извлечения фактов. Об этом говорит сайт https://intellect.icu . С другой стороны, идентификация сложных синтаксических структур в предложении — трудная задача. В связи с этим различные методы анализа текста по-разному решают эту задачу. Некоторые из них опускают данный этап, а некоторые выполняют сложный разбор предложений. Однако большинство систем выполняют разбор последовательных фрагментов предложений. Они строят только такие структуры, которые могут быть точно определены или синтаксисом, или семантикой отдельного фрагмента предложения.
Примером такого подхода может служить построение структур для групп имен существительных (имя существительное плюс его модификации) и глагольных групп (глагол с его вспомогательными частями). Оба вида структур могут быть построены, используя только локальную синтаксическую информацию. Кроме того, этот подход позволяет строить большие структуры групп имен существительных (путем объединения нескольких групп), если имеется семантическая информация, подтверждающая корректность таких объединений. Все такие структуры строятся с использованием одних и тех же регулярных выражений.
Вначале помечаются все основные группы имен существительных меткой "сущ.". В нашем примере имеются следующие группы имен существитель-
ных: три имени собственных, местоимение и две больших группы. Далее помечаются глагольные группы меткой "гл.". В результате наш пример будет выглядеть следующим образом:
[сущ. сущность: е1 Петр Сергеевич Иванов] [гл.: покинул] [сущ. сущность: е2 должность вице-президента] [сущ. сущность: е3 известной фабрики] [[сущ. сущность: е4 ООО "Анкор"]. [сущ. сущность: е5 Его] [гл.: заменил] [сущ. сущность: е6 Иван Андреевич Сидоров].
С каждой группой можно связать дополнительные свойства. Для глагольных групп такими свойствами являются информация о времени (прошедшее, настоящее, будущее) и залоге (активный или пассивный), а также корневая форма глагола. Для групп имен существительных это информация о корневой форме главного слова (например, имени собственном) и его числительность (единственное или множественное число). Кроме того, для каждой группы имен существительных создается сущность. В нашем примере их шесть:
e1 — тип: человек, имя: "Петр Сергеевич Иванов";
e2 — тип: должность, значение: "вице-президент";
e3 — тип: фирма;
e4 — тип: фирма, имя: "ООО "Анкор";
e5 — тип: человек;
e6 — тип: человек, имя: "Иван Андреевич Сидоров".
Для укрупнения групп имен существительных используют наборы образцов, присоединяющие правые модификаторы. Эти образцы обычно объединяют две группы имен существительных и, возможно, промежуточные слова в большую группу и модифицируют сущность, ассоциированную с главным существительным, чтобы соединить информацию из модификатора.
В нашем примере можно выделить два важных образца:
Во втором образце "должность" представляет собой элемент, который сопоставляется с сущностью типа "должность" (в нашем примере это сущность е2), а элемент "фирма" сопоставляется c сущностью типа "фирма" (е3 и е4). Возможно использование некоторой иерархии семитических типов и сопоставление образцов с ее применением (например, "фирма" более общее понятие, чем "фабрика", поэтому сопоставление должно выполняться). В первом образце элемент "имя фирмы" определяет сущность типа "фирма", в которой главным словом является имя (е4); элемент "описание фирмы" определяет
группу типа "фирма", в котором главным словом является общее описание (е3). Эти образцы порождают следующие метки:
[сущ. сущность: е1 Петр Сергеевич Иванов] [гл: покинул] [сущ. сущность: е2 должность вице-президента известной фирмы ООО "Анкор"]. [сущ. сущность: е5 Его] [гл: заменил] [сущ. сущность: е6 Иван Андреевич Сидоров].
Таким образом, список сущностей обновится следующим образом:
e1 — тип: человек, имя: "Петр Сергеевич Иванов";
e2 — тип: должность, значение: "вице-президент" фирмы: е3;
e3 — тип: фирма, имя: "ООО "Анкор";
e5 — тип: человек;
e6 — тип: человек, имя: "Иван Андреевич Сидоров".
Для извлечения событий и отношений используются образцы, которые получаются за счет расширения образцов, описанных ранее. Например, событие преемственности должности извлекается с помощью следующих образцов:
человек покинул должность
и
человек заменяется человеком.
В примере элементы шаблона: "человек" и "должность" сопоставляются с группами имен существительных. А элементы "покинул" и "заменяется" сопоставляются с активными и пассивными глагольными группами соответственно. В результате в тексте выделяются две структуры событий на основе ранее созданных сущностей:
[событие: е7 Петр Сергеевич Иванов покинул должность вице-президента известной фирмы ООО "Анкор"]. [событие: е8 Его заменил Иван Андреевич
продолжение следует...
Часть 1 3 Анализ текстовой информации - Text Mining
Часть 2 3.Классификация текстовых документов (описание задачи классификации текстов, методы классификации текстовых
Часть 3 Средства от IBM — Intelligent Miner for Text1 - 3
К сожалению, в одной статье не просто дать все знания про анализ текстовой информации. Но я - старался. Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое анализ текстовой информации, text mining, интеллектуальный анализ текстов, иат и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Интеллектуальный анализ данных
Комментарии
Оставить комментарий
Интеллектуальный анализ данных
Термины: Интеллектуальный анализ данных