Лекция
Это окончание невероятной информации про анализ текстовой информации.
...
среди которых можно выделить три группы:
Все описанные средства могут использоваться совместно, что поддерживается языком запросов в сочетании с традиционным синтаксисом SQL и PL/SQL для поиска документов. Oracle Text предоставляет возможность работать с современными реляционными СУБД в контексте сложного многоцелевого поиска и анализа текстовых данных.
Возможности обработки текстовой информации на русском языке в Oracle Text достаточно ограничены. Для решения этой проблемы компанией "Га- рант-Парк-Интернет" был разработан модуль Russian Context Optimizer (RCO), предназначенный для совместного использования с InterMedia Text (или Oracle Text). Помимо поддержки русскоязычной морфологии, RCO включает в себя средства нечеткого поиска, тематического анализа и реферирования документов.
Продукт фирмы IBM Intelligent Miner for Text представляет собой набор отдельных утилит, запускаемых из командной строки или из скриптов независимо друг от друга. Система содержит следующие основные утилиты для решения задач анализа текстовой информации:
IBM Intelligent Miner for Text объединяет мощную совокупность инструментов, базирующихся в основном на механизмах поиска информации (information retrieval), что является спецификой всего продукта. Система включает ряд базовых компонентов, которые имеют самостоятельное значение вне пределов технологии Text Mining:
1 http://www-3.ibm.com/software/data/iminer/fortext/.

Американская компания SAS Institute выпустила систему SAS Text Miner для сравнения определенных грамматических и словесных рядов в письменной речи. Text Miner весьма универсальна, поскольку может работать с текстовыми документами различных форматов — в базах данных, файловых системах и даже в Web.
Text Miner обеспечивает логическую обработку текста в среде пакета SAS Enterprise Miner. Это позволяет пользователям обогащать процесс анализа данных, интегрируя неструктурированную текстовую информацию с существующими структурированными данными, такими как возраст, доход и характер покупательского спроса.
1 http://www.sas.com/technologies/analytics/datamining/textminer/.

Пример успешного использования логических возможностей Text Miner демонстрирует компания Compaq Computer Corp., которая в настоящее время тестирует Text Miner, анализируя более 2,5 Гбайт текстовых документов, полученных по e-mail и собранных представителями компании. Ранее обработать такие данные было практически невозможно.
Программа Text Miner позволяет определять, насколько правдив тот или иной текстовый документ. Обнаружение лжи в документах производится путем анализа текста и выявления изменений стиля письма, которые могут возникать при попытке исказить или скрыть информацию. Для поиска таких изменений используется принцип, заключающийся в поиске аномалий и трендов среди записей баз данных без выяснения их смысла. При этом в Text Miner включен обширный набор документов различной степени правдивости, чья структура принимается в качестве шаблонов. Каждый документ, "прогоняемый" на детекторе лжи, анализируется и сравнивается с этими эталонами, после чего программа присваивает документу тот или иной индекс правдивости. Особенно полезной программа может стать в организациях, получающих большой объем электронной корреспонденции, а также в правоохранительных органах для анализа показаний наравне с детекторами лжи, чье действие основано на наблюдении за эмоциональным состоянием человека.
Интересен пример использования Text Miner в медицине. В одной из американских национальных здравоохранительных организаций было собрано свыше 10 тысяч врачебных записей о заболеваниях сердца, собранных из клиник по всей стране. Анализируя эти данные с помощью Text Miner, специалисты обнаружили некоторые административные нарушения в отчетности, а также смогли определить взаимосвязь между сердечно-сосудистыми заболеваниями и другими недугами, которые не были определены традиционными методами.
Вместе с тем, компания SAS Institute отмечает, что выпустит свой продукт Text Miner в основном для привлечения внимания бизнес-интеллигенции.
Российская компания Мегапьютер Интеллидженс, известная своей системой PolyAnalyst класса Data Mining, разработала также систему TextAnalyst. Она решает следующие задачи Text Mining:
Система TextAnalyst рассматривает технологию Text Mining в качестве отдельного математического аппарата, который разработчики программного обеспечения могут встраивать в свои продукты, не опираясь на платформы информационно-поисковых систем или СУБД. Основная платформа для применения системы — Microsoft Windows Существует плагин TextAnalyst для браузера .
В последнее время анализ текста привлекает все больше внимания в различных областях, таких как безопасность, коммерция, наука.
Многие пакеты анализа текста, такие как Aerotext и Attensity, нацелены на рынок приложений безопасности, в частности на анализ источников простого текста, например новостных сайтов.
Исследования и разработки подразделений крупных компаний, таких как IBM, Apple и Microsoft, исследуют технологии анализа текста с целью будущей автоматизации процессов анализа и извлечения данных.
ехнология интеллектуального анализа текста в настоящее время широко применяется в самых разных государственных, исследовательских и деловых целях. Все эти группы могут использовать интеллектуальный анализ текста для управления записями и поиска документов, относящихся к их повседневной деятельности. Юристы могут использовать интеллектуальный анализ текста , например, для электронных открытий . Правительства и военные группировки используют интеллектуальный анализ текста в целях национальной безопасности и разведки. Научные исследователи включают подходы интеллектуального анализа текста в усилия по организации больших наборов текстовых данных (то есть решение проблемы неструктурированных данных ), для определения идей, передаваемых через текст (например, анализ настроений в социальных сетях [15] [16] [17] ) и поддерживатьнаучное открытие в таких областях, как науки о жизни и биоинформатика . В бизнесе приложения используются для поддержки конкурентной разведки и автоматического размещения рекламы , а также для многих других видов деятельности.
Многие программные пакеты для интеллектуального анализа текста продаются для приложений безопасности , особенно для мониторинга и анализа онлайн-источников открытого текста, таких как новости Интернета , блоги и т. Д., В целях национальной безопасности . [18] Он также занимается изучением шифрования / дешифрования текста .
В биомедицинской литературе описан ряд приложений интеллектуального анализа текста [20], в том числе вычислительные подходы для помощи в исследованиях стыковки белков , [21] взаимодействий белков , [22] [23] и ассоциаций белок-болезнь. [24]Кроме того, с большими наборами текстовых данных о пациентах в клинической сфере, наборами демографической информации в популяционных исследованиях и сообщениями о побочных эффектах интеллектуальный анализ текста может облегчить клинические исследования и точную медицину. Алгоритмы интеллектуального анализа текста могут облегчить стратификацию и индексацию конкретных клинических событий в больших наборах текстовых данных пациентов с симптомами, побочными эффектами и сопутствующими заболеваниями из электронных медицинских карт, отчетов о событиях и отчетов о конкретных диагностических тестах. [25] Одним из приложений онлайн-анализа текста в биомедицинской литературе является PubGene , общедоступная поисковая система, которая сочетает биомедицинский анализ текста с сетевой визуализацией. [26] [27] GoPubMed это поисковая система по биомедицинским текстам, основанная на знаниях. Методы интеллектуального анализа текста также позволяют нам извлекать неизвестные знания из неструктурированных документов в клинической области
Методы и программное обеспечение интеллектуального анализа текста также исследуются и разрабатываются крупными фирмами, включая IBM и Microsoft , для дальнейшей автоматизации процессов интеллектуального анализа и анализа, а также различными фирмами, работающими в области поиска и индексирования в целом, как способ улучшения своих результатов. . В государственном секторе большие усилия были сосредоточены на создании программного обеспечения для отслеживания и мониторинга террористической деятельности . [29] В учебных целях программное обеспечение Weka является одним из самых популярных вариантов в научном мире, выступая в качестве отличной отправной точки для новичков. Для программистов на Python есть отличный инструментарий под названием NLTK.для более общих целей. Для более продвинутых программистов есть также библиотека Gensim , которая фокусируется на текстовых представлениях на основе встраивания слов.
Интеллектуальный анализ текста используется крупными медиа-компаниями, такими как Tribune Company , для уточнения информации и предоставления читателям большего опыта поиска, что, в свою очередь, увеличивает «липкость» сайта и прибыль. Кроме того, на серверной части редакторы получают выгоду, поскольку могут делиться, связывать и упаковывать новости в разных ресурсах, что значительно увеличивает возможности монетизации контента.
Интеллектуальный анализ текста начинает использоваться и в маркетинге, а точнее в аналитическом управлении взаимоотношениями с клиентами . Coussement и Van den Poel (2008) применяют его для улучшения моделей прогнозной аналитики для оттока клиентов (ухода клиентов ). Интеллектуальный анализ текста также применяется для прогнозирования доходности акций.
Анализ тональности может включать анализ обзоров фильмов для оценки того, насколько они благоприятны для фильма. Для такого анализа может потребоваться маркированный набор данных или маркировка аффективности слов. Ресурсы для аффективности слов и понятий были сделаны для WordNet и ConceptNet , соответственно.
Текст использовался для обнаружения эмоций в смежной области аффективных вычислений. Текстовые подходы к аффективным вычислениям использовались во многих корпусах, таких как оценки учащихся, детские рассказы и новости.
Проблема интеллектуального анализа текста важна для издателей, которые владеют большими базами данных с информацией, требующей индексации для поиска. Это особенно верно в отношении научных дисциплин, в которых очень конкретная информация часто содержится в письменном тексте. Поэтому были предприняты такие инициативы, как предложение Nature по интерфейсу интеллектуального анализа открытого текста (OTMI) и стандартное определение типа документа публикации журнала (DTD) Национального института здравоохранения, которое будет предоставлять семантические подсказки машинам для ответа на конкретные запросы, содержащиеся в текст, не снимая барьеров для публичного доступа со стороны издателей.
Академические учреждения также стали участвовать в инициативе интеллектуального анализа текста:
Вычислительные методы были разработаны для помощи в поиске информации из научной литературы. Опубликованные подходы включают методы поиска , определения новизны и уточнения омонимов ] среди технических отчетов.
Автоматический анализ обширных текстовых корпусов дал ученым возможность анализировать миллионы документов на нескольких языках с очень ограниченным ручным вмешательством. Ключевые вспомогательные технологии - это синтаксический анализ, машинный перевод , категоризация тем и машинное обучение.
Автоматический синтаксический анализ текстовых корпусов позволил извлекать акторов и их реляционные сети в широком масштабе, превращая текстовые данные в сетевые. Результирующие сети, которые могут содержать тысячи узлов, затем анализируются с использованием инструментов теории сетей для определения ключевых участников, ключевых сообществ или сторон и общих свойств, таких как надежность или структурная стабильность всей сети или центральность определенных узлы. Это автоматизирует подход, представленный количественным нарративным анализом , посредством которого тройки субъект-глагол-объект отождествляются с парами акторов, связанных действием, или парами, образованными актором-объектом.
Контент-анализ долгое время был традиционной частью социальных наук и медиа-исследований. Автоматизация контент-анализа позволила совершить революцию « больших данных » в этой области с исследованиями в социальных сетях и газетном контенте, который включает миллионы новостей. Гендерная предвзятость , удобочитаемость , схожесть контента, предпочтения читателей и даже настроение были проанализированы на основе методов интеллектуального анализа текста для миллионов документов. Анализ читабельности, гендерной и тематической предвзятости был продемонстрирован Flaounas et al. [52]показать, как разные темы имеют разные гендерные предубеждения и уровни читабельности; также была продемонстрирована возможность определять паттерны настроения у огромного населения путем анализа содержания Twitter.
По результатам данной главы можно сделать следующие выводы.
Обнаружение знаний в тексте — это нетривиальный процесс обнаружения действительно новых, потенциально полезных и понятных шаблонов в неструктурированных текстовых данных.
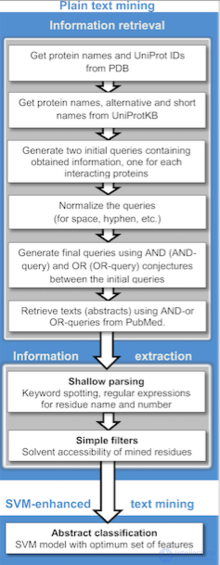
Процесс анализа текстовых документов можно представить как последовательность нескольких шагов: поиск информации, предварительная обработка документов, извлечение информации, применение методов Text Mining, интерпретация результатов.
Обычно используют следующие приемы удаления неинформативных слов и повышения строгости текстов: удаление стоп-слов, стемминг, N-граммы, приведение регистра.
Задачами анализа текстовой информации являются: классификация, кластеризация, автоматическое аннотирование, извлечение ключевых понятий, навигация по тексту, анализ трендов, поиск ассоциаций и др.
Извлечение ключевых понятий из текстов может рассматриваться и как отдельная прикладная задача, и как отдельный этап анализа текстов. В последнем случае извлеченные из текста факты используются для решения различных задач анализа.
Процесс извлечения ключевых понятий с помощью шаблонов выполняется в две стадии: на первой из текстовых документов извлекаются отдельные факты с помощью лексического анализа, на второй стадии выполняется интеграция извлеченных фактов и/или вывод новых фактов.
Большинство методов классификации текстов так или иначе основаны на предположении, что документы, относящиеся к одной категории, содержат одинаковые признаки (слова или словосочетания), и наличие или от-
сутствие таких признаков в документе говорит о его принадлежности или непринадлежности к той или иной теме.
Большинство алгоритмов кластеризации требуют, чтобы данные были представлены в виде модели векторного пространства, которая широко применяется для информационного поиска и использует метафору для отражения семантического подобия как пространственной близости.
Выделяют два основных подхода к автоматическому аннотированию текстовых документов: извлечение (выделение наиболее важных фрагментов) и обобщение (использование предварительно собранных знаний).
До недавнего времени веб-сайты чаще всего использовали текстовый поиск, который находил только документы, содержащие определенные пользователем слова или фразы. Теперь, благодаря использованию семантической сети , интеллектуальный анализ текста может находить контент на основе значения и контекста (а не только по конкретному слову). Кроме того, программное обеспечение для интеллектуального анализа текста можно использовать для создания больших досье информации о конкретных людях и событиях. Например, можно создавать большие наборы данных на основе данных, извлеченных из новостных отчетов, для облегчения анализа социальных сетей или контрразведки . По сути, программное обеспечение интеллектуального анализа текста может действовать подобно аналитику разведки или библиотекарю-исследователю, хотя и с более ограниченным объемом анализа. Анализ текста также используется в некоторых фильтрах спама в электронной почте.как способ определения характеристик сообщений, которые могут быть рекламой или другим нежелательным материалом. Анализ текста играет важную роль в определении настроений финансового рынка .
Все больший интерес проявляется к многоязычному интеллектуальному анализу данных: возможности собирать информацию на разных языках и группировать похожие элементы из разных лингвистических источников в соответствии с их значением.
Проблема использования значительной части корпоративной информации, которая происходит в «неструктурированной» форме, была признана на протяжении десятилетий. [59] Это признано в самом раннем определении бизнес-аналитики (BI) в статье журнала IBM Journal от HP Luhn в октябре 1958 года «Система бизнес-аналитики», в которой описывается система, которая:
"... использовать машины обработки данных для авто-абстракции и автокодирования документов и для создания профилей интересов для каждой из" точек действия "в организации. Как входящие, так и созданные внутри документы автоматически абстрагируются, характеризуясь словом шаблон и автоматически отправляется в соответствующие точки действий ".
Тем не менее, по мере того как информационные системы управления развивались, начиная с 1960-х годов, а бизнес-аналитика возникла в 80-х и 90-х годах как категория программного обеспечения и область практики, упор делался на числовые данные, хранящиеся в реляционных базах данных. Это неудивительно: текст в «неструктурированных» документах трудно обрабатывать. Появление текстовой аналитики в ее нынешней форме связано с переориентацией исследований в конце 1990-х годов с разработки алгоритмов на приложения, как описано профессором Марти А. Херстом в статье «Распутывание текстовых данных»: [60]
В течение почти десятилетия сообщество компьютерной лингвистики рассматривало большие текстовые коллекции как ресурс, который нужно использовать для создания более совершенных алгоритмов анализа текста. В этой статье я попытался предложить новый акцент: использование больших онлайн-коллекций текстов для открытия новых фактов и тенденций, касающихся самого мира. Я полагаю, что для достижения прогресса нам не нужен полностью искусственный интеллектуальный анализ текста; скорее, сочетание анализа, основанного на вычислениях и управляемом пользователем, может открыть дверь к захватывающим новым результатам.
Заявление Херста о потребностях от 1999 года довольно хорошо описывает состояние технологии и практики текстовой аналитики десять лет спустя.
К сожалению, в одной статье не просто дать все знания про анализ текстовой информации. Но я - старался. Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое анализ текстовой информации, text mining, интеллектуальный анализ текстов, иат и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Интеллектуальный анализ данных
Часть 1 3 Анализ текстовой информации - Text Mining
Часть 2 3.Классификация текстовых документов (описание задачи классификации текстов, методы классификации текстовых
Часть 3 Средства от IBM — Intelligent Miner for Text1 - 3
Комментарии
Оставить комментарий
Интеллектуальный анализ данных
Термины: Интеллектуальный анализ данных