Лекция
Привет, сегодня поговорим про интеллектуальный анализ данных, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое интеллектуальный анализ данных, data mining , настоятельно рекомендую прочитать все из категории Интеллектуальный анализ данных.
Подробно рассматриваются понятие Data Mining. Описано возникновение, перспективы, проблемы Data mining. Приведенный взгляд на технологию
Data Mining как на часть рынка информационных технологий. подробно рассматривается понятие данных. Объясняется значение понятий "объект" и 8
"атрибут", "выборка", "зависимая и независимая переменная". подробно обсуждаются типы шкал. Приводятся различные типы наборов данных. Коротко разные понятия базы данных и СУБД. Описываются стадии Data Mining и действия, которые выполняются в рамках этих стадий. Рассмотрены известные классификации методов Data Mining. Приведена сравнительная характеристика некоторых методов, основанная на их свойствах. Характеризуется основная суть задач
Data Mining и их классификация. Подробно рассмотрены понятия "информация "," знание ", а также сопоставление и сравнение этих понятий.
ПЛАН
1 Извлечение данных - Data Mining.
2 Задачи Data Mining.
3 Классификация задач Data Mining.
4 Задача классификации и регрессии (задача поиска ассоциативных правил, задача кластеризации).
5 Практическое применение Data Mining (интернет-технологии, торговля, телекоммуникации, промышленное производство, медицина, банковское дело, страховой бизнес, другие области применения).
6 Модели Data Mining (прогнозные модели, описательные модели).
7 Методы Data Mining (базовые методы, нечеткая логика, генетические ал
горитмы, нейронные сети).
8 Процесс выявления знаний (основные этапы анализа, подготовка входных данных).
9 Управление знаниями (Knowledge Management).
10 Средства Data Mining.
Основной задачей аналитика является генерация гипотез. Он решает ее, основываясь на своих знаниях и опыте. Однако знания есть не только у человека, но и в накопленных данных, которые подвергаются анализу. Такие знания часто называют "скрытыми", т. к. они содержатся в гигабайтах и терабайтах информации, которые человек не в состоянии исследовать самостоятельно. В связи с этим существует высокая вероятность пропустить гипотезы, которые могут принести значительную выгоду.
Очевидно, что для обнаружения скрытых знаний необходимо применять специальные методы автоматического анализа, при помощи которых приходится практически добывать знания из "завалов" информации. За этим направлением прочно закрепился термин добыча данных или Data Mining. Классическое определение этого термина дал в 1996 г. один из основателей этого направления — Григорий Пятецкий-Шапиро.
Внимание!
Data Mining — исследование и обнаружение "машиной" (алгоритмами, средствами искусственного интеллекта) в сырых данных скрытых знаний, которые ранее не были известны, нетривиальны, практически полезны, доступны для интерпретации человеком.
Data mining (рус. добыча данных, интеллектуальный анализ данных , глубинный анализ данных) — собирательное название, используемое для обозначения совокупности методов обнаружения в данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности. Термин введен Григорием Пятецким-Шапироruen в 1989 году .
Английское словосочетание «data mining» пока не имеет устоявшегося перевода на русский язык. При передаче на русском языке используются следующие словосочетания : просев информации, добыча данных, извлечение данных, а также интеллектуальный анализ данных . Более полным и точным является словосочетание «обнаружение знаний в базах данных» (англ. knowledge discovery in databases, KDD).
Основу методов data mining составляют всевозможные методы классификации, моделирования и прогнозирования, основанные на применении деревьев решений, искусственных нейронных сетей, генетических алгоритмов, эволюционного программирования, ассоциативной памяти, нечеткой логики. К методам data mining нередко относят статистические методы (дескриптивный анализ, корреляционный и регрессионный анализ, факторный анализ, дисперсионный анализ, компонентный анализ, дискриминантный анализ, анализ временных рядов, анализ выживаемости, анализ связей). Такие методы, однако, предполагают некоторые априорные представления об анализируемых данных, что несколько расходится с целями data mining (обнаружение ранее неизвестных нетривиальных и практически полезных знаний).
Одно из важнейших назначений методов data mining состоит в наглядном представлении результатов вычислений (визуализация), что позволяет использовать инструментарий data mining людьми, не имеющими специальной математической подготовки.
Применение статистических методов анализа данных требует хорошего владения теорией вероятностей и математической статистикой.
Методы data mining (или, что то же самое, knowledge discovery in data, сокращенно KDD) лежат на стыке баз данных, статистики и искусственного интеллекта .
Область data mining началась с семинара, проведенного Григорием Пятецким-Шапиро в 1989 году .
Ранее, работая в компании GTE Labs, Григорий Пятецкий-Шапиро заинтересовался вопросом: можно ли автоматически находить определенные правила, чтобы ускорить некоторые запросы к крупным базам данных. Тогда же было предложено два термина — data mining («добыча данных» ) и knowledge discovery in data (который следует переводить как «открытие знаний в базах данных»).
В 1993 году вышла первая рассылка «Knowledge Discovery Nuggets», а в 1994 году был создан один из первых сайтов по data mining.
Первоначально задача ставится следующим образом:
Необходимо разработать методы обнаружения знаний, скрытых в больших объемах исходных «сырых» данных. В текущих условиях глобальной конкуренции именно найденные закономерности (знания) могут быть источником дополнительного конкурентного преимущества.
Что означает «скрытые знания»? Это должны быть обязательно знания:
Эти требования во многом определяют суть методов data mining и то, в каком виде и в каком соотношении в технологии data mining используются системы управления базами данных, статистические методы анализа и методы искусственного интеллекта.
Data mining и базы данных
Методы data mining могут быть применены как для работы с большими данными, так и для обработки сравнительно малых объемов данных (полученных, например, по результатам отдельных экспериментов, либо при анализе данных о деятельности компании) . В качестве критерия достаточного количества данных рассматривается как область исследования, так и применяемый алгоритм анализа .
Развитие технологий баз данных сначала привело к созданию специализированного языка — языка запросов к базам данных. Для реляционных баз данных — это язык SQL, который предоставил широкие возможности для создания, изменения и извлечения хранимых данных. Затем возникла необходимость в получении аналитической информации (например, информации о деятельности предприятия за определенный период), и тут оказалось, что традиционные реляционные базы данных, хорошо приспособленные, например, для ведения оперативного учета на предприятии, плохо приспособлены для проведения анализа. Это привело, в свою очередь, к созданию т. н. «хранилищ данных», сама структура которых наилучшим способом соответствует проведению всестороннего математического анализа.
Data mining и искусственный интеллект
Знания, добываемые методами data mining, принято представлять в виде закономерностей (паттернов). В качестве таких выступают:
Алгоритмы поиска таких закономерностей находятся на пересечении областей: Искусственный интеллект, Математическая статистика, Математическое программирование, Визуализация, OLAP.
Рассмотрим свойства обнаруживаемых знаний, данные в определении, более подробно.
Знания должны быть новые, ранее неизвестные. Затраченные усилия на открытие знаний, которые уже известны пользователю, не окупаются. Поэтому ценность представляют именно новые, ранее неизвестные знания.
нания должны быть нетривиальны. Результаты анализа должны отражать неочевидные, неожиданные закономерности в данных, составляющие так называемые скрытые знания. Результаты, которые могли бы быть получены более простыми способами (например, визуальным просмотром), не оправдывают привлечение мощных методов Data Mining.
Знания должны быть практически полезны. Найденные знания должны быть применимы, в том числе и на новых данных, с достаточно высокой степенью достоверности. Полезность заключается в том, чтобы эти знания могли принести определенную выгоду при их применении.
Знания должны быть доступны для понимания человеку. Найденные закономерности должны быть логически объяснимы, в противном случае существует вероятность, что они являются случайными. Кроме того, обнаруженные знания должны быть представлены в понятном для человека виде.
ВData Mining для представления полученных знаний служат модели. Виды моделей зависят от методов их создания. Наиболее распространенными являются: правила, деревья решений, кластеры и математические функции.
Методы Data Mining помогают решить многие задачи, с которыми сталкивается аналитик. Из них основными являются: классификация, регрессия, поиск ассоциативных правил и кластеризация. Далее приведено краткое описание основных задач анализа данных.
Задача классификации сводится к определению класса объекта по его характеристикам. Необходимо заметить, что в этой задаче множество классов, к которым может быть отнесен объект, известно заранее.
Задача регрессии подобно задаче классификации позволяет определить по известным характеристикам объекта значение некоторого его параметра. В отличие от задачи классификации значением параметра является не конечное множество классов, а множество действительных чисел.
При поиске ассоциативных правил целью является нахождение частых зависимостей (или ассоциаций) между объектами или событиями. Найденные зависимости представляются в виде правил и могут быть использованы как для лучшего понимания природы анализируемых данных, так и для предсказания появления событий.
Задача кластеризации заключается в поиске независимых групп (кластеров) и их характеристик во всем множестве анализируемых данных. Решение этой задачи помогает лучше понять данные. Кроме того, группировка однородных объектов позволяет сократить их число, а следовательно, и облегчить анализ.
Перечисленные задачи по назначению делятся на описательные и предсказательные.
Описательные (descriptive) задачи уделяют внимание улучшению понимания анализируемых данных. Ключевой момент в таких моделях — легкость и прозрачность результатов для восприятия человеком. Возможно, обнаруженные закономерности будут специфической чертой именно конкретных исследуемых данных и больше нигде не встретятся, но это все равно может быть полезно и потому должно быть известно. К такому виду задач относятся кластеризация и поиск ассоциативных правил.
Решение предсказательных (predictive) задач разбивается на два этапа. На первом этапе на основании набора данных с известными результатами строится модель. На втором этапе она используется для предсказания результатов на основании новых наборов данных. При этом, естественно, требуется, чтобы построенные модели работали максимально точно. К данному виду задач относят задачи классификации и регрессии. Сюда можно отнести и задачу поиска ассоциативных правил, если результаты ее решения могут быть использованы для предсказания появления некоторых событий.
По способам решения задачи разделяют на supervised learning (обучение с учителем) и unsupervised learning (обучение без учителя). Такое название произошло от термина Machine Learning (машинное обучение), часто используемого в англоязычной литературе и обозначающего все технологии Data Mining.
В случае supervised learning задача анализа данных решается в несколько этапов. Сначала с помощью какого-либо алгоритма Data Mining строится модель анализируемых данных — классификатор. Затем классификатор подвергается обучению. Другими словами, проверяется качество его работы, и, если оно неудовлетворительное, происходит дополнительное обучение классификатора. Так продолжается до тех пор, пока не будет достигнут требуемый уровень качества или не станет ясно, что выбранный алгоритм не работает корректно с данными, либо же сами данные не имеют структуры, которую можно выявить. К этому типу задач относят задачи классификации и регрессии.
Unsupervised learning объединяет задачи, выявляющие описательные модели, например закономерности в покупках, совершаемых клиентами большого магазина. Очевидно, что если эти закономерности есть, то модель должна их представить и неуместно говорить об ее обучении. Достоинством таких задач является возможность их решения без каких-либо предварительных знаний об анализируемых данных. К этим задачам относятся кластеризация и поиск ассоциативных правил.
При анализе часто требуется определить, к какому из известных классов относятся исследуемые объекты, т. е. классифицировать их. Например, когда человек обращается в банк за предоставлением ему кредита, банковский служащий должен принять решение: кредитоспособен ли потенциальный клиент или нет. Очевидно, что такое решение принимается на основании данных об исследуемом объекте (в данном случае — о человеке): его место работы, размер заработной платы, возраст, состав семьи и т. п. В результате анализа этой информации банковский служащий должен отнести человека к одному из двух известных классов: "кредитоспособен" и "некредитоспособен".
Другим примером задачи классификации является фильтрация электронной почты. В этом случае программа фильтрации должна классифицировать входящее сообщение как спам (spam — нежелательная электронная почта) или как письмо. Данное решение принимается на основании частоты появления в сообщении определенных слов (например, имени получателя, безличного обращения, слов и словосочетаний: "приобрести", "заработать", "выгодное предложение" и т. п.).
Вобщем случае количество классов в задачах классификации может быть более двух. Например, в задаче распознавания образа цифр таких классов может быть 10 (по количеству цифр в десятичной системе счисления). В такой задаче объектом классификации является матрица пикселов, представляющая образ распознаваемой цифры. При этом цвет каждого пиксела является характеристикой анализируемого объекта.
ВData Mining задачу классификации рассматривают как задачу определения значения одного из параметров анализируемого объекта на основании значений других параметров. Определяемый параметр часто называют зависимой переменной, а параметры, участвующие в его определении, — независимыми переменными. В рассмотренных примерах независимыми переменными являлись:
зарплата, возраст, количество детей и т. д.;
частота появления определенных слов;
значения цвета пикселов матрицы.
Зависимыми переменными в этих же примерах являлись соответственно:
кредитоспособность клиента (возможные значения этой переменной — "да" и "нет");
тип сообщения (возможные значения этой переменной — "spam" и "mail");
цифра образа (возможные значения этой переменной — 0, 1, ... , 9).
Необходимо обратить внимание, что во всех рассмотренных примерах независимая переменная принимала значение из конечного множества значений: {"да", "нет"}, {"spam", "mail"}, {0, 1, ... , 9}. Если значениями независимых и зависимой переменных являются действительные числа, то задача называется задачей регрессии. Примером задачи регрессии может служить задача определения суммы кредита, которая может быть выдана банком клиенту.
Задача классификации и регрессии решается в два этапа. На первом выделяется обучающая выборка. В нее входят объекты, для которых известны значения как независимых, так и зависимых переменных. В описанных ранее примерах такими обучающими выборками могут быть:
информация о клиентах, которым ранее выдавались кредиты на разные суммы, и информация об их погашении;
сообщения, классифицированные вручную как спам или как письмо;
распознанные ранее матрицы образов цифр.
На основании обучающей выборки строится модель определения значения зависимой переменной. Ее часто называют функцией классификации или регрессии. Для получения максимально точной функции к обучающей выборке предъявляются следующие основные требования:
количество объектов, входящих в выборку, должно быть достаточно большим. Чем больше объектов, тем точнее будет построенная на ее основе функция классификации или регрессии;
в выборку должны входить объекты, представляющие все возможные классы в случае задачи классификации или всю область значений в случае задачи регрессии;
для каждого класса в задаче классификации или для каждого интервала области значений в задаче регрессии выборка должна содержать достаточное количество объектов.
На втором этапе построенную модель применяют к анализируемым объектам (к объектам с неопределенным значением зависимой переменной).
Задача классификации и регрессии имеет геометрическую интерпретацию. Рассмотрим ее на примере с двумя независимыми переменными, что позволит представить ее в двумерном пространстве (рис. 4.1). Каждому объекту ставится в соответствие точка на плоскости. Символы "+" и "−" обозначают принадлежность объекта к одному из двух классов. Очевидно, что данные имеют четко выраженную структуру: все точки класса "+" сосредоточены в центральной области. Построение классификационной функции сводится
к построению поверхности, которая обводит центральную область. Она определяется как функция, имеющая значения "+" внутри обведенной области и "−" — вне ее.
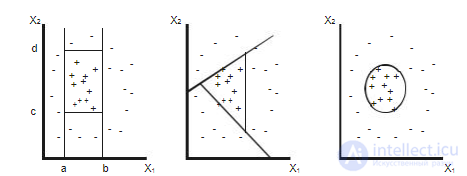
Рис. 4.1. Классификация в двумерном пространстве
Как видно из рисунка, есть несколько возможностей для построения обводящей области. Вид функции зависит от применяемого алгоритма.
Основные проблемы, с которыми сталкиваются при решении задач классификации и регрессии, — это неудовлетворительное качество исходных данных, в которых встречаются как ошибочные данные, так и пропущенные значения, различные типы атрибутов — числовые и категорические, разная значимость атрибутов, а также так называемые проблемы overfitting и underfitting. Суть первой из них заключается в том, что классификационная функция при построении "слишком хорошо" адаптируется к данным и встречающиеся в них ошибки и аномальные значения пытается интерпретировать как часть внутренней структуры данных. Очевидно, что в дальнейшем такая модель будет некорректно работать с другими данными, где характер ошибок будет несколько иной. Термином underfitting обозначают ситуацию, когда слишком велико количество ошибок при проверке классификатора на обучающем множестве. Это означает, что особых закономерностей в данных не было обнаружено, и либо их нет вообще, либо необходимо выбрать иной метод их обнаружения.
Поиск ассоциативных правил является одним из самых популярных приложений Data Mining. Суть задачи заключается в определении часто встречающихся наборов объектов в большом множестве таких наборов. Данная задача является частным случаем задачи классификации. Первоначально она решалась при анализе тенденций в поведении покупателей в супермаркетах. Анализу подвергались данные о совершаемых ими покупках, которые покупатели складывают в тележку (корзину). Это послужило причиной второго часто встречающегося названия — анализ рыночных корзин (Basket Analysis). При анализе этих данных интерес прежде всего представляет информация о том, какие товары покупаются вместе, в какой последовательности, какие категории потребителей какие товары предпочитают, в какие периоды времени и т. п. Такая информация позволяет более эффективно планировать закупку товаров, проведение рекламной кампании и т. д.
Например, из набора покупок, совершаемых в магазине, можно выделить следующие наборы товаров, которые покупаются вместе: {чипсы, пиво}; {вода, орехи}. Следовательно, можно сделать вывод, что если покупаются чипсы или орехи, то, как правило, покупаются и пиво или вода соответственно. Обладая такими знаниями, можно разместить эти товары рядом, объединить их в один пакет со скидкой или предпринять другие действия, стимулирующие покупателя приобрести товар.
Задача поиска ассоциативных правил актуальна не только в сфере торговли. Например, в сфере обслуживания интерес представляет информация о том, какими услугами клиенты предпочитают пользоваться в совокупности. Для получения этой информации задача решается применительно к данным об услугах, которыми пользуется один клиент в течение определенного времени (месяца, года). Это помогает определить, например, как наиболее выгодно составить пакеты услуг, предлагаемых клиенту.
В медицине анализу могут подвергаться симптомы и болезни, наблюдаемые у пациентов. В этом случае знания о том, какие сочетания болезней и симптомов встречаются наиболее часто, помогают в будущем правильно ставить диагноз.
При анализе часто вызывает интерес последовательность происходящих событий. При обнаружении закономерностей в таких последовательностях можно с некоторой долей вероятности предсказывать появление событий в будущем, что позволяет принимать более правильные решения. Такая задача является разновидностью задачи поиска ассоциативных правил и называется
сиквенциальным анализом.
Основным отличием задачи сиквенциального анализа от поиска ассоциативных правил является установление отношения порядка между исследуемыми наборами. Данное отношение может быть определено разными способами. При анализе последовательности событий, происходящих во времени, объектами таких наборов являются события, а отношение порядка соответствует хронологии их появления.
Сиквенциальный анализ широко используется, например, в телекоммуникационных компаниях, для анализа данных об авариях на различных узлах сети. Информация о последовательности совершения аварий может помочь в обнаружении неполадок и предупреждении новых аварий. Например, если известна последовательность сбоев: {e5, e2, e7, e13, e6, e1, ... }, где ei — код сбоя, то на основании факта появления сбоя e2 можно сделать вывод о скором появлении сбоя e7. Зная это, можно предпринять профилактические меры, устраняющие причины возникновения сбоя. Если дополнительно обладать и знаниями о времени между сбоями, то можно предсказать не только факт его появления, но и время, что часто не менее важно.
Задача кластеризации состоит в разделении исследуемого множества объектов на группы "похожих" объектов, называемых кластерами (cluster). Слово cluster переводится с английского как сгусток, пучок, группа. Родственные понятия, используемые в литературе, — класс, таксон, сгущение. Часто решение задачи разбиения множества элементов на кластеры называют кластерным анализом.
Кластеризация может применяться практически в любой области, где необходимо исследование экспериментальных или статистических данных. Об этом говорит сайт https://intellect.icu . Рассмотрим пример из области маркетинга, в котором данная задача называется сегментацией.
Концептуально сегментирование основано на предпосылке, что все потребители разные. У них разные потребности, разные требования к товару, они ведут себя по-разному: в процессе выбора товара, в процессе приобретения товара, в процессе использования товара, в процессе формирования реакции на товар. В связи с этим необходимо по-разному подходить к работе с потребителями: предлагать им различные по своим характеристикам товары, поразному продвигать и продавать товары. Для того чтобы определить, чем отличаются потребители друг от друга и как эти отличия отражаются на требованиях к товару, и производится сегментирование потребителей.
В маркетинге критериями (характеристиками) сегментации являются: географическое местоположение, социально-демографические характеристики, мотивы совершения покупки и т. п.
На основании результатов сегментации маркетолог может определить, например, такие характеристики сегментов рынка, как реальная и потенциальная емкость сегмента, группы потребителей, чьи потребности не удовлетворяются в полной мере ни одним производителем, работающим на данном сегменте рынка, и т. п. На основании этих параметров маркетолог может сделать вывод о привлекательности работы фирмы в каждом из выделенных сегментов рынка.
Для научных исследований изучение результатов кластеризации, а именно выяснение причин, по которым объекты объединяются в группы, способно открыть новые перспективные направления. Традиционным примером, который обычно приводят для этого случая, является периодическая таблица элементов. В 1869 г. Дмитрий Менделеев разделил 60 известных в то время элементов на кластеры или периоды. Элементы, попавшие в одну группу, обладали схожими характеристиками. Изучение причин, по которым элементы разбивались на явно выраженные кластеры, в значительной степени определило приоритеты научных изысканий на годы вперед. Но лишь спустя 50 лет квантовая физика дала убедительные объяснения периодической системы.
Кластеризация отличается от классификации тем, что для проведения анализа не требуется иметь выделенную зависимую переменную, поэтому она относится к классу unsupervised learning. Эта задача решается на начальных этапах исследования, когда о данных мало что известно. Ее решение помогает лучше понять данные, и с этой точки зрения задача кластеризации является описательной.
Для задачи кластеризации характерно отсутствие каких-либо различий как между переменными, так и между объектами. Напротив, ищутся группы наиболее близких, похожих объектов. Методы автоматического разбиения на кластеры редко используются сами по себе, а только для получения групп схожих объектов. После определения кластеров используются другие методы Data Mining, чтобы попытаться установить, что означает такое разбиение, чем оно вызвано.
Кластерный анализ позволяет рассматривать достаточно большой объем информации и резко сокращать, сжимать большие массивы информации, делать их компактными и наглядными.
Отметим ряд особенностей, присущих задаче кластеризации.
Во-первых, решение сильно зависит от природы объектов данных (и их атрибутов). Так, с одной стороны, это могут быть однозначно определенные, количественно очерченные объекты, а с другой — объекты, имеющие вероятностное или нечеткое описание.
Во-вторых, решение в значительной степени зависит и от представления кластеров и предполагаемых отношений объектов данных и кластеров. Так, необходимо учитывать такие свойства, как возможность/невозможность принадлежности объектов к нескольким кластерам. Необходимо определение самого понятия принадлежности кластеру: однозначная (принадлежит/не принадлежит), вероятностная (вероятность принадлежности), нечеткая (степень принадлежности).
В системах электронного бизнеса, где особую важность имеют вопросы привлечения и удержания клиентов, технологии Data Mining часто применяются для построения рекомендательных систем интернет-магазинов и для решения проблемы персонализации посетителей Web-сайтов. Рекомендации товаров и услуг, построенные на основе закономерностей в покупках клиентов, обладают огромной убеждающей силой. Статистика показывает, что почти каждый посетитель магазина Amazon не упускает возможности посмотреть на то, что же купили "Customers who bought this book also bought: ... " ("Те, кто купил эту книгу, также купили ..."). Персонализация клиентов или, другими словами, автоматическое распознание принадлежности клиента к определенной целевой аудитории позволяет компании проводить более гибкую маркетинговую политику. Поскольку в электронной коммерции деньги и платежные системы тоже электронные, то важной задачей становится обеспечение безопасности при операциях с пластиковыми карточками. Data Mining позволяет обнаруживать случаи мошенничества (fraud detection). В области электронной коммерции также остаются справедливыми все методологии Data Mining, разработанные для обычного маркетинга. С другой стороны, эта область тесно связана с понятием Web Mining.
Специфика Web Mining заключается в применении традиционных технологий Data Mining для анализа крайне неоднородной, распределенной и значительной по объему информации, содержащейся на Web-узлах. Здесь можно выделить два направления: Web Content Mining и Web Usage Mining. В первом случае речь идет об автоматическом поиске и извлечении качественной информации из перегруженных "информационным шумом" источников Интернета, а также о всевозможных средствах автоматической классификации и аннотировании документов. Данное направление также называют Text Mining (более подробно см. гл. 9). Web Usage Mining направлен на обнаружение закономерностей в поведении пользователей конкретного Web-узла (группы узлов), в частности на то, какие страницы в какой временной последовательности и какими группами пользователей запрашиваются. Web Mining более подробно описан в гл. 14.
Для успешного продвижения товаров всегда важно знать, что и как продается, а также кто является потребителем. Исчерпывающий ответ на первый вопрос дают такие средства Data Mining, как анализ рыночных корзин и сиквенциальный анализ. Зная связи между покупками и временные закономерности, можно оптимальным образом регулировать предложение. С другой стороны, маркетинг имеет возможность непосредственно управлять спросом, но для этого необходимо знать как можно больше о потребителях — целевой аудитории маркетинга. Data Mining позволяет решать задачи выделения групп потребителей со схожими стереотипами поведения, т. е. сегментировать рынок. Для этого можно применять такие технологии Data Mining, как кластеризация и классификация.
Сиквенциальный анализ помогает торговым предприятиям принимать решения о создании товарных запасов. Он дает ответы на вопросы типа "Если сегодня покупатель приобрел видеокамеру, то через какое время он вероятнее всего купит новые батарейки и пленку?".
Телекоммуникационный бизнес является одной из наиболее динамически развивающихся областей современной экономики. Возможно, поэтому традиционные проблемы, с которыми сталкивается в своей деятельности любая компания, здесь ощущаются особо остро. Приведем некоторые цифры. Телекоммуникационные компании работают в условиях жесткой конкуренции, что проявляется в ежегодном оттоке около 25 % клиентов. При этом известно, что удержать клиента в 4—5 раз дешевле, чем привлечь нового, а вот вернуть ушедшего клиента будет стоить уже в 50—100 раз больше, чем его удержать. Далее, как и в целом в экономике, справедливо правило Парето — только 20 % клиентов приносят компании основной доход. Помимо этого существует ряд клиентов, наносящих компании прямой вред. 10 % всего дохода телекоммуникационной индустрии в год теряется из-за случаев мошенничества, что составляет $4 млрд. Таким образом, использование технологий Data Mining, направленных как на анализ
продолжение следует...
Часть 1 1 Интеллектуальный анализ данных - Data Mining
Часть 2 Промышленное производство - 1 Интеллектуальный анализ данных - Data Mining
Часть 3 Подготовка исходных данных - 1 Интеллектуальный анализ данных - Data
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

Комментарии