Лекция
Это окончание невероятной информации про интеллектуальный анализ данных.
...
добытого знания, после проверки нового знания практикой. Исследование достигнутых практических результатов завершает оценку ценности добытого средствами Data Mining нового знания.
Как уже отмечалось ранее, для применения того или иного метода Data Mining к данным их необходимо подготовить к этому. Например, поставлена задача построить фильтр электронной почты, не пропускающий спам. Письма представляют собой тексты в электронном виде. Практически ни один из существующих методов Data Mining не может работать непосредственно с текстами. Чтобы работать с ними, необходимо из исходной текстовой информации предварительно получить некие производные параметры, например: частоту встречаемости ключевых слов, среднюю длину предложений, параметры, характеризующие сочетаемость тех или иных слов в предложении, и т. д. Другими словами, необходимо выработать некий четкий набор числовых или нечисловых параметров, характеризующих письмо. Эта задача наименее автоматизирована в том смысле, что выбор системы данных параметров производится человеком, хотя, конечно, их значения могут вычисляться автоматически. После выбора описывающих параметров изучаемые данные могут быть представлены в виде прямоугольной таблицы, где каждая строка представляет собой отдельный случай, объект или состояние изучаемого объекта, а каждая колонка — параметры, свойства или признаки всех исследуемых объектов. Большинство методов Data Mining работают только с подобными прямоугольными таблицами.
Полученная прямоугольная таблица пока еще является слишком сырым материалом для применения методов Data Mining, и входящие в нее данные необходимо предварительно обработать. Во-первых, таблица может содержать параметры, имеющие одинаковые значения для всей колонки. Если бы исследуемые объекты характеризовались только такими признаками, они были бы абсолютно идентичны, значит, эти признаки никак не индивидуализируют исследуемые объекты. Следовательно, их надо исключить из анализа. Вовторых, таблица может содержать некоторый категориальный признак, значения которого во всех записях различны. Ясно, что мы никак не можем использовать это поле для анализа данных и его надо исключить. Наконец, просто этих полей может быть очень много, и если все их включить в исследование, то это существенно увеличит время вычислений, поскольку практически для всех методов Data Mining характерна сильная зависимость времени от количества параметров (квадратичная, а нередко и экспоненциальная). В то же время зависимость времени от количества исследуемых объектов линейна или близка к линейной. Поэтому в качестве предварительной обработки данных необходимо, во-первых, выделить то множество признаков, которые наиболее важны в контексте данного исследования, отбросить явно неприменимые из-за константности или чрезмерной вариабельности и выделить те, которые наиболее вероятно войдут в искомую зависимость. Для этого, как правило, используются статистические методы, основанные на применении корреляционного анализа, линейных регрессий и т. д. Такие методы позволяют быстро, хотя и приближенно оценить влияние одного параметра на другой.
Мы обсудили очистку данных по столбцам таблицы (признакам). Точно так же бывает необходимо провести предварительную очистку данных по строкам таблицы (записям). Любая реальная база данных обычно содержит ошибки, очень приблизительно определенные значения, записи, соответствующие каким-то редким, исключительным ситуациям, и другие дефекты, которые могут резко понизить эффективность методов Data Mining, применяемых на следующих этапах анализа. Такие записи необходимо отбросить. Даже если подобные "выбросы" не являются ошибками, а представляют собой редкие исключительные ситуации, они все равно вряд ли могут быть использованы, поскольку по нескольким точкам статистически значимо судить об искомой зависимости невозможно. Эта предварительная обработка или препроцессинг данных и составляет второй этап процесса обнаружения знаний.
Итак, основной целью технологии Data Mining является извлечение знаний из больших объемов данных. Однако если полученные знания не будут использоваться, то они, а также и все затраты на их извлечение будут бесполезны. По этой причине одной из задач анализа информации является управление полученными знаниями.
Управление знаниями (Knowledge Management) основано на интегральном подходе к созданию, накоплению и управлению кодифицированными и не кодифицированными знаниями.
Знания можно классифицировать, например, следующим образом:
embodied — физические и физиологические знания, в т. ч. навыки, например, знание парикмахера, который делает прическу;
embrained — знания, хранилищем которых является сознание, например, знания консультантов;
encodied — кодифицированные знания, содержащиеся на разнообразных носителях информации: на бумаге, в базах данных и т. д.;
embedded — материализованные знания, содержащиеся в технологиях, архитектуре, процедурах;
encultured — общие интеллектуальные модели, разделяемые коллегами.
Существуют и другие виды знаний, однако в рамках Управления знаниями рассматриваются перечисленные ранее.
Знания также можно разделить на две большие группы:
явные (explicit), например, кодифицированные;
неявные (tacit), то есть личностные, которые по мнению специалистов не поддаются кодификации.
Вуправлении знаниями выделяют два основных подхода:
метод, ориентированный на продукты — здесь в центре внимания находятся документы, хранение данных, истории событий и шаблоны решений. В данном случае знания рассматриваются без учета тех людей, которые их создают (или обнаруживают), и без тех, кто их использует;
метод, ориентированный на процессы — это более целостный подход к управлению знаниями за счет выделения среды, в которой генерируются и распространяются знания. Его можно рассматривать как процесс социальной коммуникации. Это означает, что знания концентрируются у тех, кто их обнаруживает, а распространение информации производится путем личных контактов. В процессе формируются самоорганизующиеся группы — сообщества, которые участвуют в развивающемся естественным образом общении.
В настоящее время технология Data Mining представлена целым рядом коммерческих и свободно распространяемых программных продуктов. Достаточно полный и регулярно обновляемый список этих продуктов можно найти на сайте www.kdnuggets.com, посвященном Data Mining. Классифицировать программные продукты Data Mining можно по тем же принципам, что положены в основу классификации самой технологии. Однако подобная классификация не будет иметь практической ценности. Вследствие высокой конкуренции на рынке и стремления к полноте технических решений многие из продуктов Data Mining охватывают буквально все аспекты применения аналитических технологий. Поэтому целесообразнее классифицировать продукты Data Mining по тому, каким образом они реализованы и, соответственно, какой потенциал для интеграции они предоставляют. Очевидно, что и это условность, поскольку такой критерий не позволяет очертить четкие границы между продуктами. Однако у подобной классификации есть одно несомненное преимущество. Она позволяет быстро принять решение о выборе того или иного готового решения при инициализации проектов в области анализа данных, разработки систем поддержки принятия решений, создания хранилищ данных и т. д.
Итак, продукты Data Mining условно можно разделить на три больших категории:
входящие, как неотъемлемая часть, в системы управления базами данных;
библиотеки алгоритмов Data Mining с сопутствующей инфраструктурой;
коробочные или настольные решения ("черные ящики").
Продукты первых двух категорий предоставляют наибольшие возможности для интеграции и позволяют реализовать аналитический потенциал практически в любом приложении в любой области. Коробочные приложения, в свою очередь, могут предоставлять некоторые уникальные достижения в области Data Mining или быть специализированными для какой-либо конкретной сферы применения. Однако в большинстве случаев их проблематично интегрировать в более широкие решения.
Включение аналитических возможностей в состав коммерческих систем управления базами данных является закономерной и имеющей огромный потенциал тенденцией. Действительно, где, как ни в местах концентрации данных, имеет наибольший смысл размещать средства их обработки. Исходя из этого принципа, функциональность Data Mining в настоящий момент реализована в следующих коммерческих базах данных:
Oracle;
Microsoft SQL Server;
IBM DB2.
Каждая из названных СУБД позволяет решать основные задачи, связанные с анализом данных, и имеет хорошие возможности для интеграции. Однако только Oracle может считаться действительно аналитической платформой. Помимо реализации функциональности Data Mining, Oracle имеет мощные средства для анализа неструктурированной текстовой информации (Oracle Text), информации, имеющей сетевую модель организации (Oracle Network Data Models), и информации, имеющей пространственные атрибуты (Oracle Spatial Topology). Таким образом, используя СУБД Oracle как платформу для построения аналитической системы, можно решить практически любую поставленную задачу: от построения рекомендательных систем для интернетмагазинов до многофункциональных систем поддержки принятия решений для различных государственных и силовых ведомств. Далее приводится обзор основных аналитических возможностей Oracle.
Oracle Data Mining включает в себя четыре наиболее мощных и зарекомендовавших себя алгоритма классификации (supervised learning):
Naive Bayes (NB) — использует теорию вероятности для классификации объектов;
Decision Trees — классифицирует объекты путем построения деревьев решений;
Adaptive Bayes Networks (ABN) — расширенный вариант алгоритма NB;
Support Vector Machines — использует теорию вычисления близости векторов для классификации объектов.
Для решения задач кластеризации и ассоциативного анализа (unsupervised learning) в Oracle применяется пять алгоритмов:
Enhanced k-Means Clustering — для обнаружения групп схожих объектов;
Orthogonal Partitioning Clustering — для кластеризации методом ортогонального деления;
Anomaly Detection — для обнаружения редких, вызывающих подозрение событий (аномалий);
Association Rules — для обнаружения шаблонов в событиях;
Nonnegative Matrix Factorization (NMF) — для уменьшения количества атрибутов.
Oracle также включает в себя алгоритм Minimum Description Length (MDL) для решения проблемы важности атрибутов. С его помощью можно определить те атрибуты, которые имеют наибольшее влияние на зависимые поля или атрибуты.
В последние годы особую важность приобрели задачи, связанные с обработкой больших массивов генетической информации. Для их решения Oracle предлагает алгоритм BLAST (Basic Local Alignment Search Technique), позволяющий в геномных данных отыскивать последовательности, которые наиболее точно соответствуют определенным последовательностям.
Доступ к функциональности Data Mining в Oracle осуществляется либо посредством расширения языка SQL, либо с помощью прикладного программного интерфейса на Java. Отметим, что данный интерфейс совместим со спецификацией JDM.
Анализ текстовой информации в Oracle представлен целым рядом технологий, которые обеспечивают следующие возможности:
качественный полнотекстовый поиск:
•сортировка результатов поиска по релевантности;
•автоматическое приведение слов в запросе к нормальной грамматической форме (стемминг);
•поиск с указанием расположения фрагмента в тексте (заголовках, параграфах);
•поиск фраз и точных совпадений слов;
•использование логических операторов (И, ИЛИ и т. д.) при составлении запросов;
•автоматическая фильтрация шумовых слов в запросе (союзы, частицы и др.);
•автоматическое расширение запросов семантически близкими словами (синонимы и др.);
•автоматическое расширение запросов клавиатурно близкими словами (опечатки);
•расширение запросов с помощью масок (wildcard-символы: '*', '?');
•поиск документов по указанной теме;
•нечеткий поиск (созвучные слова, типичные ошибки и т. д.);
автоматическое определение темы документа;
автоматическое аннотирование документов;
управление базами знаний системы (тезаурусы, словари тем, синонимы и т. д.);
автоматическая классификация входящих документов;
поиск групп схожих документов (кластеризация);
поддержка нескольких естественных языков (русский, английский);
автоматическое распознавание распространенных форматов (Word, XML, PDF и т. д.).
Таким образом, Oracle Text позволяет строить системы обработки неструктурированной информации любого уровня: от поискового портала до интеллектуальных систем документооборота. В настоящее время Oracle Text поддерживает множество языков, в том числе русский.
Анализ сетевой информации в Oracle позволяет выявлять неявные связи между объектами, организованными в сетевые структуры или графы. На первый взгляд это может показаться достаточно абстрактной областью применения, однако подобные возможности являются крайне востребованными, например, в силовых ведомствах. Всевозможные службы разведки, расследования налоговых преступлений и обнаружения нелегального финансирования терроризма, полицейские организации и т. д. располагают обширными базами данных, где фиксируются определенные аспекты деятельности объектов. В частности, их непосредственные и видимые связи друг с другом. Очевидно, что помимо видимых и зафиксированных связей существуют также неявные, опосредованные связи. Они то и представляют наибольший интерес для расследований.
Для решения такой задачи Oracle Network Data Models содержит следующую функциональность по анализу графов:
определить все пути, соединяющие два данных узла;
найти все узлы, достижимые с данного узла;
найти все узлы, из которых возможно попасть в данный узел;
определить кратчайший путь между узлами;
определить наиболее эффективный путь, включающий указанные узлы;
определить узлы, в которые можно попасть с данного узла в пределах указанной стоимости пути;
определить, достижим ли целевой узел с данного узла;
определить минимальное покрывающее дерево;
определить ближайших соседей (по количеству) для данного узла.
Технологии анализа пространственной информации (Oracle Spatial Topology) содержат весь необходимый инструментарий для построения геоинформационных систем разных уровней сложности.
Среди многочисленных библиотек Data Mining, существующих в настоящий момент на рынке, особо следует выделить систему с открытым кодом Weka. Это динамично развивающаяся, обширная коллекция разнообразных алгоритмов, разработанная в новозеландском университете Waikato. Она реализована на языке Java, имеет достаточно простой программный интерфейс, снабжена графической оболочкой и хорошо документирована. Все это, включая свободное распространение, делает библиотеку Weka исключительно популярной. Среди недостатков библиотеки можно отметить недостаточное внимание разработчиков к проблеме масштабируемости. Это означает, что работа со сверхбольшими данными, требующая специфического подхода к разработке и оптимизации существующих алгоритмов, в Weka практически не проделана.
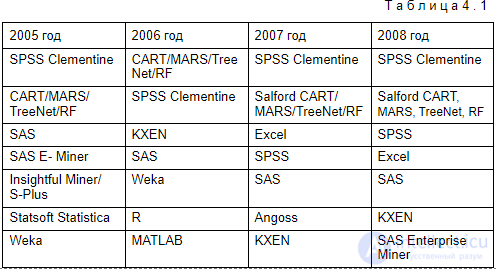
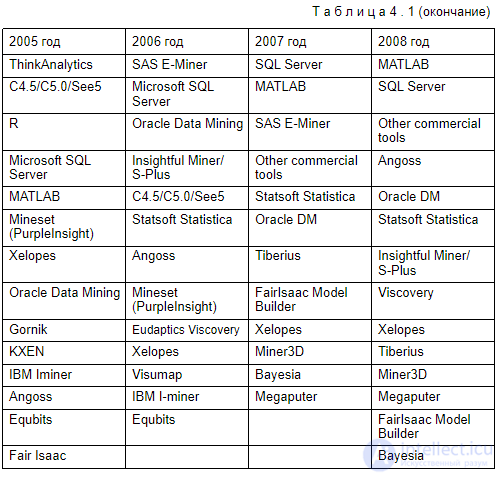
Использование коробочных коммерческих продуктов имеет наибольший смысл в тех проектах, где интеллектуальный анализ данных является основной целью, а не сопровождает построение более обширной системы, например, системы поддержки принятия решений. В этом случае выбор конкретного продукта может определяться множеством факторов — от предметной ориентации до цены. Чтобы упростить проблему выбора, приведем наиболее объективные и несколько неформальные данные о популярности Data Mining средств на основе ежегодных опросов на сайте www.kdnuggets.com (табл. 4.1).
Списки продуктов в таблице упорядочены по степени убывания "популярности". Как видно, из года в год лидируют одни и те же инструменты, хотя общий список насчитывает не менее сотни наименований. Очевидно, что при выборе подходящего средства Data Mining в первую очередь следует рассматривать и сравнивать между собой перечисленные продукты.
К сожалению, в одной статье не просто дать все знания про интеллектуальный анализ данных. Но я - старался. Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое интеллектуальный анализ данных, data mining и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Интеллектуальный анализ данных
Часть 1 1 Интеллектуальный анализ данных - Data Mining
Часть 2 Промышленное производство - 1 Интеллектуальный анализ данных - Data Mining
Часть 3 Подготовка исходных данных - 1 Интеллектуальный анализ данных - Data
Комментарии
Оставить комментарий
Интеллектуальный анализ данных
Термины: Интеллектуальный анализ данных