Лекция
Привет, сегодня поговорим про визуальный анализ данных, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое визуальный анализ данных, visual mining , настоятельно рекомендую прочитать все из категории Интеллектуальный анализ данных.
Рассматриваются вопросы визуального анализа данных. Приведены характектеристики средств визуализации данных, методов визуализации и методов геометрических преобразований. Сравниваются методы, ориентированные на пиксели, а также методы анализа иерархических образов и отображения иконок. Создаются методы и средства визуального представления информации, в частности, способы представления информации в одно-, двух-, трехмерном измерениях, а также способы отображения информации в более чем трех измерениях. описаны принципы качественной визуализации. Изложены основные тенденции в области визуализации.
" визуальный анализ данных " (Visual Data Analysis) или "Visual Mining" - это процесс анализа данных с использованием графических элементов, таких как графики, диаграммы, графы и визуализации, для облегчения понимания данных и выявления в них закономерностей, трендов и паттернов. Визуальный анализ данных является важной частью процесса бизнес-анализа и научных исследований, поскольку он позволяет исследователям и аналитикам лучше воспринимать и анализировать информацию, которая может быть сложной или большого объема.
Визуальный анализ данных может включать в себя следующие компоненты и методы:
Графики и диаграммы: Создание различных типов графиков и диаграмм (гистограммы, круговые диаграммы, линейные графики и т. д.), чтобы визуализировать данные.
Интерактивность: Возможность взаимодействия с визуализациями, например, при наведении курсора мыши на точки на графике, отображается дополнительная информация.
Дашборды: Создание дашбордов, которые объединяют несколько визуализаций и позволяют быстро просматривать ключевые метрики и показатели.
Кластеризация и классификация: Использование методов машинного обучения для выявления групп и паттернов в данных.
Тепловые карты (heatmap): Визуализация данных с использованием цветовой шкалы для выявления плотности и схожести.
Графы и сети: Исследование связей между объектами с помощью графовых структур.
Анимация: Использование анимации для отслеживания изменений в данных во времени.
3D-визуализация: Представление данных в трехмерном пространстве для более глубокого анализа.
Визуальный анализ данных позволяет обнаруживать скрытые паттерны, делать прогнозы и принимать более информированные решения. Он широко применяется в области бизнес-анализа, научных исследований, медицинской диагностики, финансов и многих других областях, где данные играют важную роль.
ПЛАН
Результаты, получаемые при анализе данных с помощью методов Data Mining, не всегда удобны для восприятия человеком. Во множестве классификационных или ассоциативных правил, в математических формулах человеку достаточно сложно быстро и легко найти новые и полезные знания. Из-за сложности информации это не всегда возможно и в простейших графических видах представления знаний, таких как деревья решений, дейтограммы, двумерные графики и т. п. В связи с этим возникает необходимость в более сложных средствах отображения результатов анализа. К ним относятся средства визуального анализа данных, которые в зарубежной литературе часто называют термином Visual Mining.
Основной идеей визуального анализа данных является представление данных в некоторой визуальной форме, позволяющей человеку погрузиться в данные, работать с их визуальным представлением, понять их суть, сделать выводы и напрямую взаимодействовать с данными.
До недавнего времени визуальный анализ данных для отображения результатов на обычных мониторах использовал только двумерную или очень простую трехмерную графику. Более сложные графические образы отображать в реальном времени было достаточно сложно и дорого. Однако прогресс в области аппаратных средств вывода изображений способствовал и совершенствованию средств визуального анализа данных. В настоящее время существует достаточно большое количество различных видов графических образов, позволяющих представлять результаты анализа в виде, удобном для понимания человеком.
С помощью новых технологий пользователи способны оценивать: большие объекты или маленькие, далеко они находятся или близко. Пользователь в реальном времени может двигаться вокруг объектов или кластеров объектов и рассматривать их cо всех сторон. Это позволяет использовать для анализа естественные человеческие перцепционные навыки в обнаружении неопределенных образцов в визуальном трехмерном представлении данных.
Визуальный анализ данных особенно полезен, когда о самих данных мало известно и цели исследования до конца непонятны. За счет того, что пользователь напрямую работает с данными, представленными в виде визуальных образов, которые он может рассматривать с разных сторон и под любыми углами зрения, в прямом смысле этого слова, он может получить дополнительную информацию, которая поможет ему более четко сформулировать цели исследования.
Таким образом, визуальный анализ данных можно представить как процесс генерации гипотез. При этом сгенерированные гипотезы можно проверить или автоматическими средствами (методами статистического анализа или методами Data Mining), или средствами визуального анализа. Кроме того, прямое вовлечение пользователя в визуальный анализ имеет два основных преимущества перед автоматическими методами:
визуальный анализ данных позволяет легко работать с неоднородными и зашумленными данными, в то время как не все автоматические методы могут работать с такими данными и давать удовлетворительные результаты;
визуальный анализ данных интуитивно понятен и не требует сложных математических или статистических алгоритмов.
Следствием этих преимуществ является то, что визуальный анализ выполняется быстрее и в некоторых случаях дает лучший результат, чем автоматические методы анализа.
Еще одним важным достоинством визуального анализа является высокая степень конфиденциальности полученных сведений, т. к. они целиком сосредоточены в голове аналитика и не сохраняются даже в оперативной памяти компьютера.
Все перечисленные преимущества позволяют еще больше облегчить работу аналитика и повысить качество получаемых знаний при совместном использовании визуального анализа и методов автоматического анализа.
Визуальный анализ данных обычно выполняется в три этапа:
беглый анализ — позволяет идентифицировать интересные шаблоны и сфокусироваться на одном или нескольких из них;
увеличение и фильтрация — идентифицированные на предыдущем этапе шаблоны отфильтровываются и рассматриваются в большем масштабе;
детализация по необходимости — если пользователю нужно получить дополнительную информацию, он может визуализировать более детальные данные.
Процесс визуализации изображен на рис. 8.1. Так же как и при анализе данных, информация извлекается из некоторого источника, например, из базы данных или из файлов. Затем к ней могут быть применены алгоритмы Data Mining для выявления скрытых закономерностей (классификации, кластеризации и т. п.). Как результаты применения алгоритмов, так и исходные данные подвергаются обработке в ядре визуализации. Основной целью обработки является приведение многомерных данных к такому виду, который можно было бы представить на экране монитора. Виды визуальных образов будут описаны в следующих разделах.
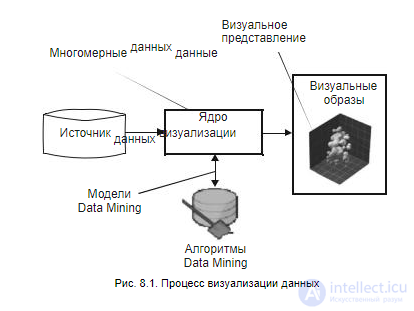
Рис. 8.1. Процесс визуализации данных
Существует достаточно большое количество средств визуализации данных, предоставляющих различные возможности. Для выбора таких средств рассмотрим более подробно три основные характеристики, описанные в статье [39]:
Наборы визуализируемых данных, как и в Data Mining, представляют собой матрицы, в которых ряды являются данными (например, записями об экспериментах, покупки в магазине и т. п.), а колонки — атрибутами данных. При этом данные могут характеризоваться одним или несколькими атрибутами. Кроме того, сами данные могут иметь более сложную структуру: иерархическую, текстовую, графическую и т. п. Таким образом, выделяют следующие виды данных, с которыми могут работать средства визуализации:
Одномерные данные обычно характеризуются одним атрибутом. Типичным примером одномерных данных являются хронологические данные (временные ряды), где единственным атрибутом является время. Необходимо обратить внимание, что с одной отметкой времени может быть связано одно или несколько значений данных.
Двумерные данные имеют два отдельных измерения. Типичным примером могут служить географические данные, характеризующиеся двумя атрибутами: долгота и широта. Обычно такие данные отображаются в виде точек в двумерной системе координат.
Кажущаяся простота визуализации одномерных и двумерных данных может быть обманчива. При большом объеме данных их визуализация может не дать желаемого эффекта. Например, при визуализации большого количества данных на длинном временном интервале, отображение их на экран приведет к необходимости значительного уменьшения масштаба и, как следствие, потери наглядности.
Многие наборы данных характеризуются более чем тремя измерениями, из-за чего просто отобразить их в виде двумерных или даже трехмерных точек не-
возможно. Об этом говорит сайт https://intellect.icu . Примерами многомерных данных являются реляционные таблицы баз данных, где атрибутами данных являются колонки. Для отображения таких данных на экране монитора требуются специальные методы визуализации, например, параллельные координаты (см. разд. 8.3.1).
Не все данные могут быть описаны в терминах измерений. К таким данным относятся тексты, гипертексты и т. п. Они характеризуются тем, что не могут быть описаны количественными характеристиками, и, как следствие, не все методы визуализации могут быть для них использованы. Поэтому перед визуализацией требуются дополнительные преобразования, подготавливающие тексты к виду, пригодному для использования методов визуализации.
Данные могут состоять в некоторых отношениях с другими частями информации. Для представления таких взаимосвязей широко используются графы. Граф состоит из набора узлов и соединяющих их линий, называемых дугами. Примерами таких данных могут являться: электронная почта, пересылаемая между людьми, гиперссылки между Web-документами, файловая структура диска и т. п. Для отображения таких связей используются специальные методы визуализации.
Другой класс данных — алгоритмы и программы. Копирование больших программных проектов является проблемой. Целью визуализации является поддержка в разработке программных средств, например, отображение потока информации в программе для лучшего понимания алгоритмов и написанного кода, отображение структуры тысячи строк исходного кода в виде графа и поддержки процесса отладки, визуализация ошибок. Существует большое количество инструментов и систем, которые реализуют эти задачи.
Для визуализации перечисленных типов данных используются различные визуальные образы и методы их создания [39, 40]. Очевидно, что количество визуальных образов, которыми могут представляться данные, ограничиваются только человеческой фантазией. Основное требование к ним — это наглядность и удобство анализа данных, которые они представляют. Методы визуализации могут быть как самые простые (линейные графики, диаграммы, гистограммы и т. п.), так и более сложные, основанные на сложном математическом аппарате. Кроме того, при визуализации могут использоваться комбинации различных методов. Выделяют следующие типы методов визуализации:

методы, ориентированные на пикселы — рекурсивные шаблоны, циклические сегменты и т. п.;
иерархические образы — древовидные карты и наложение измерений.
Простейшие методы визуализации, к которым относятся 2D/3D-образы, широко используются в существующих системах (например, в Microsoft Excel). К этим методам относятся: графики, диаграммы, гистограммы и т. п. Основным их недостатком является невозможность приемлемой визуализации сложных данных и большого количества данных.
Методы геометрических преобразований визуальных образов направлены на трансформацию многомерных наборов данных с целью отображения их в декартовом и в недекартовом геометрических пространствах. Данный класс методов включает в себя математический аппарат статистики. К нему относятся такие популярные методы, как диаграмма разброса данных (scatter plot), параллельные координаты (Parallel Coordinates), гипердоли (Hyperslice) и др. Более подробно эти методы будут описаны в разд. 8.3.1.
Другим классом методов визуализации данных являются методы отображения иконок. Их основной идеей является отображение значений элементов многомерных данных в свойства образов. Такие образы могут представлять собой: человеческие лица, стрелки, звезды и т. п. Визуализация генерируется отображением атрибутов элементов данных в свойства образов. Такие образы можно группировать для целостного анализа данных. Результирующая визуализация представляет собой шаблоны текстур, которые имеют различия, соответствующие характеристикам данных и обнаруживаемые преаттентивным1 восприятием. Более подробно эти методы будут описаны в разд. 8.3.2.
Основной идеей методов, ориентированных на пикселы, является отображение каждого измерения значения в цветной пиксел и их группировка по принадлежности к измерению. Так как один пиксел используется для отображения одного значения, то, следовательно, данный метод позволяет визуализировать большое количество данных (свыше одного миллиона значений). Более подробно эти методы будут рассматриваться в разд. 8.3.3.
Методы иерархических образов предназначены для представления данных, имеющих иерархическую структуру. В случае многомерных данных должны быть правильно выбраны измерения, которые используются для построения иерархии. Более подробно эти методы описаны в разд. 8.3.4.
В результате применения методов визуализации будут построены визуальные образы, отражающие данные. Однако этого не всегда бывает достаточно для
1 Преаттентивным восприятием называется способность человека обрабатывать (воспринимать) информацию, не сознавая, что он вообще обратил на нее внимание. В процессе такой обработки информации неосознанно формируется и отношение к ней.
полного анализа. Пользователь должен иметь возможность работать с образами: видеть их с разных сторон, в разном масштабе и т. п. Для этого у него должны быть соответствующие возможности взаимодействия с образами:
Основная идея динамического проецирования заключается в динамическом изменении проекций при проведении исследования многомерных наборов данных. Примером может служить проецирование в двумерную плоскость всех интересующих проекций многомерных данных в виде диаграмм разброса (scatter plots). Необходимо обратить внимание, что количество возможных проекций экспоненциально увеличивается с ростом числа измерений, и следовательно, при большом количестве измерений проекции будут тяжело воспринимаемы.
При исследовании большого количества данных важно иметь возможность разделять наборы данных и выделять интересующие поднаборы — фильтровать образы. При этом важно, чтобы данная возможность предоставлялась в режиме реального времени работы с визуальными образами (т. е. интерактивно). Выбор поднабора может осуществляться или напрямую из списка, или с помощью определения свойств интересующего поднабора. Выбор из списка неудобен при большом количестве поднаборов, в то же время запросы не всегда позволяют получить желаемый результат.
Примером масштабирования образов является "магическая линза" (Magic Lenses). Ее основная идея состоит в использовании инструмента, похожего на увеличительное стекло, чтобы выполнять фильтрацию непосредственно при визуализации. Данные, попадающие под увеличительное стекло, обрабатываются фильтром, и результат отображается отдельно от основных данных. Линза показывает модифицированное изображение выбранного региона, тогда как остальные визуализированные данные не детализируются.
Масштабирование — это хорошо известный метод взаимодействия, используемый во многих приложениях. При работе с большим объемом данных этот метод хорош для представления данных в сжатом общем виде, и, в то же время, он предоставляет возможность отображения любой их части в более детальном виде. Масштабирование может заключаться не только в простом увеличении объектов, но в изменении их представления на разных уровнях. Так, например, на нижнем уровне объект может быть представлен пикселом,
на более высоком уровне — неким визуальным образом, а на следующем — текстовой меткой.
Метод интерактивного искажения поддерживает процесс исследования данных с помощью искажения масштаба данных при частичной детализации. Основная идея этого метода заключается в том, что часть данных отображается с высокой степенью детализации, а одновременно с этим остальные данные показываются с низким уровнем детализации. Наиболее популярные методы — это гиперболическое и сферическое искажения, которые часто используются на иерархиях и графах, но могут применяться и в других визуальных образах.
Существует достаточно много методов визуализации, но все они имеют как достоинства, так и недостатки. Основная идея комбинирования заключается в объединении различных методов визуализации для преодоления недостатков одного из них. Различные проекции рассеивания точек, например, могут быть скомбинированы с методами окрашивания и компоновки точек во всех проекциях. Такой подход может быть использован для любых методов визуализации. Окраска точек во всех методах визуализации дает возможность определить зависимости и корреляции в данных. Таким образом, комбинирование нескольких методов визуализации обеспечивает бóльшую информативность, чем в общем независимое использование методов. Типичными примерами визуальных образов, которые могут комбинироваться, являются: точки рассеивания, гистограммы, параллельные координаты, отображаемые пикселы и карты.
Любое средство визуализации может быть классифицировано по всем трем параметрам, т. е. по виду данных, с которым оно работает, по визуальным образам, которые оно может предоставлять, и по возможностям взаимодействия с этими визуальными образами. Очевидно, что одно средство визуализации может поддерживать разные виды данных, разные визуальные образы и разные способы взаимодействия с образами.
Основная идея методов геометрических преобразований — визуализировать преобразования и проекции данных в декартовом и в недекартовом геометрических пространствах. К этим методам относятся:
точки и матрицы;
гипердоли;
поверхностные и объемные графики, контуры;
параллельные координаты;
текстуры и растры.
Матрица диаграмм разброса (Scatterplot Matrix) является комбинацией отдельных диаграмм разброса, что позволяет отображать более одного атрибута. Значения атрибутов отображаются в диагональных ячейках матрицы, а остальные ячейки представляют собой отношения между ними. Например, на рис. 8.2 показана матрица 5×5. Вдоль диагонали изображаются гистограммы пяти атрибутов, а, например, ячейка (2, 3) представляет отношение атрибута 2 с атрибутом 3. Соответственно, ячейка (3, 2) представляет отношение атрибута 3 с атрибутом 2.
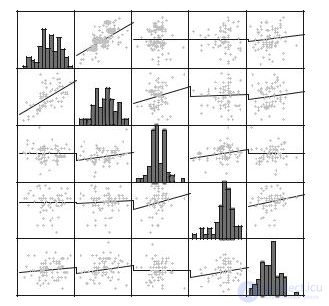
Рис. 8.2. Пример матрицы диаграмм разброса
Гипердоли являются модификацией матрицы диаграмм разброса. Основная концепция та же, за исключением того, что в ячейках матрицы отображаются скалярные функции. Таким образом, в диагональных ячейках матрицы отображается скалярная функция, представляющая отдельные атрибуты, а в остальных ячейках — скалярное отношение нескольких атрибутов.В данном методе визуализации могут быть использованы такие типы взаимодействия, как соприкосновение и связывание. Например, когда пользователь наводит курсор, или щелкает мышью на определенной точке, или выбирает несколько точек в одной из ячеек, представляющих отношение, то в остальных ячейках матрицы могут подсвечиваться эквивалентные точки.
Пользователь может взаимодействовать с данным представлением, описав визуальный фокус и диапазон значений (например, так, как в ячейке (2, 3) на рис. 8.3). При этом отображаться будут только данные в заданном диапазоне. Перемещая фокус, пользователь может быстро исследовать другие данные из близлежащих диапазонов.

Рис. 8.3. Пример гипердолей
На ранних фазах визуального анализа большие величины непрерывных данных могут отображаться с помощью объема. Объемный рендеринг позволяет пользователю видеть внутреннюю часть объемных графиков. Цвета, яркость и полупрозрачность используются, чтобы изобразить различия распределений и значения атрибутов. Подвижность объемных графиков используется, чтобы визуализировать различные их слои.
Объемные графики (рис. 8.4) представляют собой 3D-плоскость, на которой отображается отношение между данными. Контурные линии используются для соединения точек, соответствующих данным с одинаковыми атрибутами. Однако представление большого количества данных с помощью этого метода может быть затруднено из-за густоты точек и, как следствие, затемненности и неясности изображения.
Еще одним распространенным методом геометрических преобразований является метод параллельных координат. Данный метод предполагает представление атрибутов параллельными линиями на недекартовой плоскости. Данные представляются кривыми линиями, которые пересекают линии атрибутов. Точки пересечений соответствуют значениям соответствующих атрибутов отображаемых данных. На рис. 8.5 приведен пример для данных, характеризующихся 10-ю измерениями.
Это достаточно простой способ представления многомерных данных, но при большом количестве линий получается большая зашумленность изображения, что приводит к неинформативности визуализации.
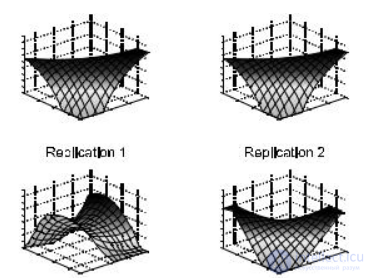
Рис. 8.4. Пример объемных графиков
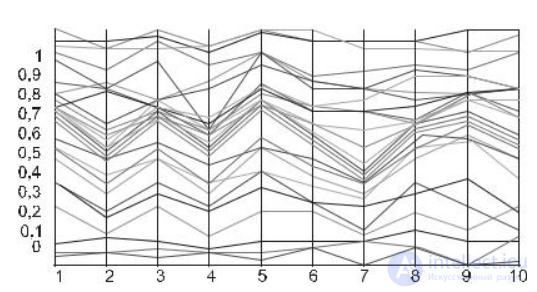
Рис. 8.5. Пример параллельных координат
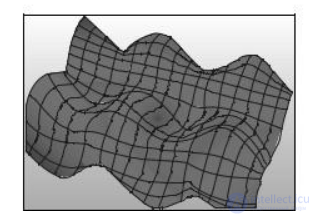
Рис. 8.6. Пример отображения текстур
Текстурная и растровая визуализации используют способность человека к преаттентивному (подсознательному) восприятию информации. Такой метод в совокупности с различными визуальными свойствами (такими как подсветка и интенсивность) позволяет отобразить большое количество атрибутов. Например, на рис. 8.6 с помощью текстуры представляется векторная и контурные диаграммы на плоскости.
Подход, основанный на отображении иконок, предполагает каждому объекту данных ставить в соответствие некоторую иконку. При этом атрибуты объекта должны отображаться различными визуальными свойствами иконок. Иконки могут комбинироваться в матрицы или графики и, таким образом, предоставляют возможность анализировать все объекты в целом.
Использование иконок предполагает следующие методы визуализации:
линейчатые фигуры;
"лица Чернова";
цветные иконки;
глифы 1 и др.
Линейчатая фигура представляет собой иконку с некоторым количеством ветвей (линий). Например, на рис. 8.7 представлены две фигуры, имеющие тело (длинная линия) и ветви (четыре коротких линии).
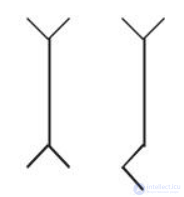
Рис. 8.7. Пример линейчатой фигуры
Каждый объект представляется отдельной фигурой. Атрибуты объекта отображаются с разными наклонами и местоположением линий (относительно
1 Глиф — визуальное представление символа шрифта, образ символа шрифта, а также печатное изображение символа шрифта.
тела). В этом методе можно также использовать цветовую гамму для представления атрибутов.
Для анализа всех данных целиком линейчатые фигуры могут группироваться и создавать текстурное изображение. На рис. 8.8 представлен пример такого изображения для данных с 20-ю атрибутами.
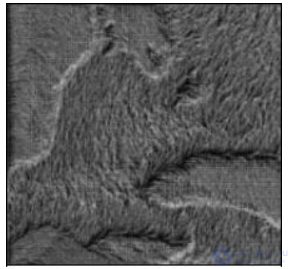
Рис. 8.8. Пример группировки линейчатых фигур
Другим хорошо известным методом отображения иконок является метод "лиц Чернова". Этот метод предполагает использовать для представления объектов образы человеческих лиц (рис. 8.9). При этом каждый атрибут отображается определенной характеристикой человеческого лица: длиной, формой и т. п.
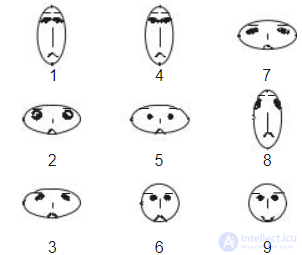
Рис. 8.9. Пример изображений лиц
Цветные иконки представляют атрибуты объектов цветом, формой, размером, границами, ориентацией (рис. 8.10).
Существует два подхода к раскрашиванию иконок:
1.Закрашивается линия, которая соответствует отдельному атрибуту.
2.Закрашивается часть иконки, соответствующая атрибуту.
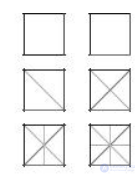
Рис. 8.10. Пример раскраски цветных иконок
Глифы представляют собой пикселы с более чем одним измерением. Они размещаются на 2D-площадке и их позиции описываются двумя атрибутами, тогда как другие атрибуты представляются цветом и формой. Некоторые модификации метода применяют глифы в виде цветов, звезд и др. На рис. 8.11 представлен пример скалярного глифа.

Методы, ориентированные на пикселы, используют для представления каждого элемента данных цветные пикселы. Выделяют следующие подобные методы:
В методе заполнения пространства каждый атрибут представляется пикселом. Цвет пиксела определяется диапазоном значений атрибута. Наборы пикселов для каждого объекта организовываются в определенные шаблоны: спирали, линейные шлейфы и т. п.
Метод рекурсивных шаблонов является комбинацией метода пиксельного заполнения пространства на множестве экранов. В рекурсивных шаблонах пикселы позиционируются в петли и спирали. Порядок заполнения начинается от центра и ведется к внешней границе шаблона (рис. 8.12).
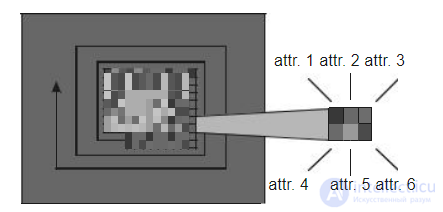
Рис. 8.12. Пример заполнения пространства по спирали
Дж. А. Хартингом и Б. Кляйнером. Метод заключается в графическом представлении многовариантной таблицы сопряженности, что является естественным расширением одномерных спиндиаграмм, которые в свою очередь являются модификацией гистограмм. Спиндиаграммы одного атрибута группируются вместе. Такие группы отображаются на экране (рис. 8.13).
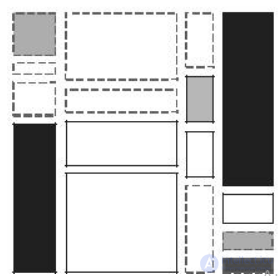
Рис. 8.13. Пример мозаики
Иерархические образы используются для отображения иерархий и отношений в данных. Они применяются в следующих методах:
Оси, представляющие каждый атрибут, накладываются горизонтально, при этом первое место в иерархии отводится наиболее изменяемому атрибуту. Такой метод может отображать до 20 атрибутов на одном экране. Для большого количества данных метод может использовать подпространственное масштабирование и, тем самым, походить на древовидную структуру.
На рис. 8.14 представлен пример иерархического расположения гистограмм. На первой гистограмме высота черных прямоугольников отражает значение зависимой переменной z. Независимые переменные x и y соответствуют горизонтальным осям, которые размещены внизу. На второй гистограмме высота серого прямоугольника определяется как сумма всех z-переменных, которые представлены черными прямоугольниками внутри. В данном примере имеется два черных квадрата высотой 1, следовательно, сумма равна 2. Третья гистограмма получается иерархическим наложением переменных. Для разных значений переменной y строятся диаграммы с одними и теми же значениями переменной x. Для каждого нового значения переменной y диаграммы строятся по тем же принципам, что и диаграмма, представленная на среднем рисунке. Полученные таким образом диаграммы объединяются в одну так, как это показано на третьей диаграмме. В примере иерархия осей выстраивается от атрибута x к z.

Основная идея метода наложения измерений заключается во вставке одной координатной системы в другую. Иными словами, два атрибута формируют внешнюю систему координат, два других атрибута формируют другую систему координат, встроенную в предыдущую, и т. д. Этот процесс может быть повторен несколько раз.
Наглядность данного метода заключается в зависимости от распределения данных внешней системы координат. Поэтому измерения, которые используются для внешней системы координат, должны быть выбраны тщательно. Первыми нужно выбирать наиболее важные измерения.
На рис. 8.15 приведен пример визуализации методом наложения измерений, в котором географическая долгота и широта добычи нефти отображаются внешними x и y осями, а качество добываемой нефти и глубина — внутренними x и y осями.

Рис. 8.15. Пример наложения измерений
Для визуализации данных используют два основных вида древовидных структур:
Древовидные карты иерархически делят экран, используя заполнение пространства (рис. 8.16). Этот метод использует разграниченные области для визуализации деревьев.
Следующие свойства всегда должны сохраняться для древовидных карт.
Если узел N1 является предком узла N2, то ограниченный прямоугольник N1 целиком окружает прямоугольник N2.
Ограниченные прямоугольники двух узлов пересекаются, если один узел является предком другого.
Узлы занимают площадь строго пропорционально их весу.
Вес узла больше или равен сумме весов его наследников.

|
Рис. 8.16. Пример древовидной карты |
Цвет используется, чтобы визуально представить тип содержимого узлов. Так, для этих целей могут использоваться оттенки, текстуры и яркость.
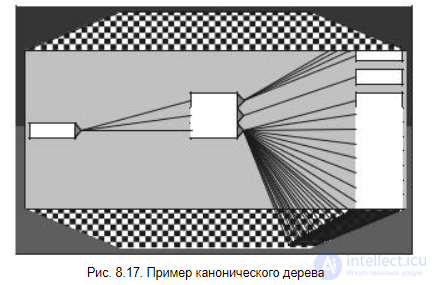
Каноническое дерево представляет собой древовидную структуру, которую можно интерактивно вращать и раскрывать новые ветви с данными (рис. 8.17).
Основной идеей визуального анализа данных является представление данных в некоторой визуальной форме, позволяющей человеку погрузиться в данные, работать с их визуальным представлением, понять их суть, сделать выводы и напрямую взаимодействовать с ними.
Визуальный анализ данных обычно выполняется в три этапа: беглый анализ, увеличение и фильтрация, детализация по необходимости.
Выделяют три основные характеристики средств визуализации: характер отображаемых данных, методы визуализации, возможности взаимодействия с визуальными образами.
Выделяют следующие виды данных, с которыми могут работать средства визуализации: одномерные, двумерные и многомерные данные, тексты и гипертексты, иерархические и связанные данные, алгоритмы и программы.
Выделяют следующие основные типы методов визуализации: стандартные 2D/3D-образы, геометрические преобразования, отображение иконок, ориентированные на пикселы методы, иерархические образы.
Для анализа визуальных образов часто используют следующие возможности взаимодействия: динамическое проецирование, интерактивная фильтрация, масштабирование образов, интерактивное искажение, интерактивное комбинирование.
Основная идея методов геометрических преобразований — визуализировать преобразования и проекции данных в декартовом и недекартовом геометрических пространствах.
Подход, основанный на отображении иконок, предполагает каждому объекту данных ставить в соответствие некоторую иконку, при этом атрибуты объекта должны отображаться с помощью различных визуальных свойств иконок.
Методы, ориентированные на пикселы, используют для представления каждого элемента данных цветные пикселы.
Иерархические образы используются для отображения иерархий и отношений в данных.
К сожалению, в одной статье не просто дать все знания про визуальный анализ данных. Но я - старался. Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое визуальный анализ данных, visual mining и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Интеллектуальный анализ данных
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

Комментарии