Лекция
Это продолжение увлекательной статьи про анализ текстовой информации.
...
Сидоров].
Список сущностей обновляется следующим образом:
e1 — тип: человек, имя: "Петр Сергеевич Иванов";
e2 — тип: должность, значение: "вице-президент" фирмы: е3;
e3 — тип: фирма, имя: "ООО "Анкор";
e5 — тип: человек;
e6 — тип: человек, имя: "Иван Андреевич Сидоров";
e7 — тип: покинул, человек: e1, должность: е2;
e8 — тип: заменил, человек: е6, человек: е5.
Описанным образом могут быть получены основные ключевые понятия. По ним может выполняться анализ текстов методами Data Mining для решения задач классификации, кластеризации и др.
В результате локального анализа из текста извлекаются ключевые понятия: сущности и события. Для получения более структурированной информации выполняется анализ ссылок. Его целью является разрешение ссылок, представленных местоимениями и описываемыми группами имен существительных. В нашем примере таким местоимением является "Его" (сущность e5). Для разрешения этой ссылки будет выполняться поиск первой предшествующей сущности с типом "человек". В нашем примере такой сущностью является e1. В результате ссылки на e5 должны быть заменены ссылками на e1. Таким образом, список сущностей и событий обновится следующим образом:
e1 — тип: человек, имя: "Петр Сергеевич Иванов";
e2 — тип: должность, значение: "вице-президент" фирмы: е3;
e3 — тип: фирма, имя: "ООО "Анкор";
e6 — тип: человек, имя: "Иван Андреевич Сидоров";
e7 — тип: покинул, человек: e1, должность: е2;
e8 — тип: заменил, человек: е6, человек: е1.
При анализе ссылок также надо учитывать иерархию понятий (как в случае "фирма" и "фабрика").
Во многих ситуациях определенная информация о событии может распространяться на другие предложения. Используя механизмы вывода, можно получить новые факты. В нашем примере, строя выводы на смысле сказуемого "заменил", можно получить новый факт, что Иван Андреевич Сидоров тоже был вице-президентом. Такой вывод можно сделать на основе системы порождающих правил, таких как следующие:
покинул (X-человек, Y-должность) & заменил (Z-человек, X-человек) =>
вступил (Z-человек, Y-должность);
вступил (X-человек, Y-должность) & заменил (X-человек, Z-человек) =>
покинул (Z-человек, Y-должность).
Такие правила позволяют добавить еще одно событие:
e1 — тип: человек, имя: "Петр Сергеевич Иванов";
e2 — тип: должность, значение: "вице-президент" фирмы: е3;
e3 — тип: фирма, имя: "ООО "Анкор";
e6 — тип: человек, имя: "Иван Андреевич Сидоров";
e7 — тип: покинул, человек: e1, должность:е2;
e8 — тип: заменил, человек: е6, человек: е1;
e9 — тип: вступил, человек: е6, человек: е2.
Врезультате описанной последовательности действий можно получить следующие извлеченные ключевые понятия, представленные в виде табл. 9.1.
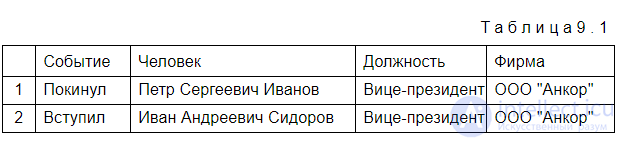
В описанном подходе не определялось время событий. Однако для многих методов это важно или для вывода в аналитический отчет, или для хронологии последовательности событий. В таких случаях информация о времени может быть получена из разных источников, включая абсолютные даты и время (например, "28 июля 2006 года"), относительные упоминания времени ("последняя неделя"), времена глаголов и знаний о последовательности вывода событий.
Извлеченные понятия должны быть преобразованы в единую форму. Это позволяет выполнять индексированный поиск и другие операции максимально правильно. Например, слова "изучающий" и "изучение" должны быть идентифицированы как одно слово "изучать
Классификация текстовых документов, так же как и в случае классификации объектов (см. гл. 5), заключается в отнесении документа к одному из заранее известных классов. Часто классификацию применительно к текстовым документам называют категоризацией или рубрикацией. Очевидно, что данные названия происходят от задачи систематизации документов по каталогам, категориям и рубрикам. При этом структура каталогов может быть как одноуровневой, так и многоуровневой (иерархической).
Формально задачу классификации текстовых документов описывают набором множеств. Множество документов представляется в виде:
D = {d1, ..., di , ..., dn}.
Категории документов представляются множеством:
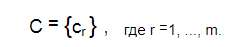
Иерархию категорий можно представить в виде множества пар, отражающих отношение вложенности между рубриками:
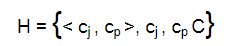
(категория cp вложена в категорию cj ).
В задаче классификации требуется на основе этих данных построить процедуру, которая заключается в нахождении наиболее вероятной категории из множества C для исследуемого документа di .
Большинство методов классификации текстов так или иначе основаны на предположении, что документы, относящиеся к одной категории, содержат одинаковые признаки (слова или словосочетания), и наличие или отсутствие таких признаков в документе говорит о его принадлежности или непринадлежности к той или иной теме.
Таким образом, для каждой категории должно быть множество признаков:
F(C) = (cr ),
где F (cr ) =< f1, ..., fk , ..., fz > .
Такое множество признаков часто называют словарем, т. к. оно состоит из лексем, которые включают слова и/или словосочетания, характеризующие категорию.
Подобно категориям каждый документ также имеет признаки, по которым его можно отнести с некоторой степенью вероятности к одной или нескольким категориям:
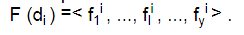
Множество признаков всех документов должно совпадать с множеством признаков категорий, т. е.:
F(C) = F(D) = F(di ).
Необходимо заметить, что данные наборы признаков являются отличительной чертой классификации текстовых документов от классификации объектов в Data Mining, которые характеризуются набором атрибутов.
Решение об отнесении документа di к категории cr принимается на основании пересечения:
F(di ) F(cr ).
Задача методов классификации состоит в том, чтобы наилучшим образом выбрать такие признаки и сформулировать правила, на основе которых будет приниматься решение об отнесении документа к рубрике.
Существует два противоположных подхода к формированию множества F(C) и построению правил:
машинное обучение — предполагается наличие обучающей выборки документов, по которому строится множество F(C) ;
экспертный метод — предполагает, что выделение признаков — множества F(C) — и составление правил производится экспертами.
В случае машинного обучения анализируется статистика лингвистических шаблонов (таких как лексическая близость, повторяемость слов и т. п.) из документов обучающей выборки. В нее должны входить документы, относящиеся к каждой рубрике, чтобы создать набор признаков (статистическую сигнатуру) для каждой рубрики, который впоследствии будет использоваться для классификации новых документов. Достоинством данного подхода является отсутствие необходимости в словарях, которые сложно построить для больших предметных областей. Однако чтобы избежать неправильной классификации, требуется обеспечить хорошее представительство документов для каждой рубрики.
Во втором случае формирование словаря (множества F(C) ) может быть выполнено на основе набора терминов предметной области и отношений между ними (основные термины, синонимы и родственные термины). Классификация может затем определить рубрику документа в соответствии с частотой, с которой появляются выделенные в тексте термины (ключевые понятия).
Возможна и комбинация двух описанных подходов, когда выделение признаков и составление правил выполняются автоматически на основе обучающей выборки, и в то же время правила строятся в таком виде, чтобы эксперту была понятна логика автоматической рубрикации, и у него была возможность вручную корректировать эти правила.
Для классификации текстовых документов успешно используются многие методы и алгоритмы классификации Data Mining: Naive Bayes, метод наименьших квадратов, C4.5, SVM и др. Некоторые из них подробно были описаны в гл. 5. Очевидно, что требуется модификация этих методов для работы с текстовой информацией. Как правило, адаптация алгоритмов связана с тем, что понятие независимой переменной связано не с атрибутами объекта, а с наличием в текстовом документе того или иного признака f . Рассмотрим модификацию таких алгоритмов на примере метода Naive Bayes, описанного в разд. 5.3.2.
Метод Naive Bayes предполагает вычисление вероятностей принадлежности текстового документа к каждой рубрике. Решение о принадлежности принимается по максимальной вероятности:
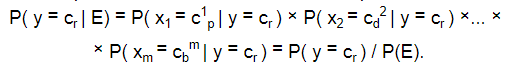
Зависимая переменная y указывает на принадлежность документа к категории cr . Событие E заключается в наличии в текстовом документе признаков (лемм), характеризующих категорию cr . При этом независимой переменной xg является признак fi — наличие слова (леммы) из словаря F(c ) для категории cr в текстовом документе di , т. е.:
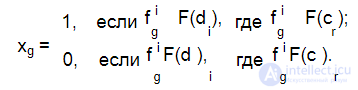
В остальном вычисление вероятности принадлежности документа к той или иной категории по методу Байеса выполняется так же, как это описано в разд. 5.3.2.
Аналогичную трактовку получают зависимая и независимая переменные и в других методах классификации при использовании их для текстовых документов.
Для классификации текстовых документов были разработаны и другие методы и разрабатываются новые. Примером такого метода является классификация, основанная на полнотекстовом поиске [49]. С помощью этого метода на основе обучающей выборки формируются запросы к полнотекстовой поисковой машине, соответствующие каждой из рубрик. Затем эти запросы выполняются для исследуемого документа, и выбирается та рубрика, запросы которой в наибольшей степени соответствуют исследуемому документу. Особенностью метода является то, что результат машинного обучения представляет собой набор запросов к поисковой системе и легко интерпретируется.
Большинство алгоритмов кластеризации требуют, чтобы данные были представлены в виде модели векторного пространства (vector space model) [44]. Это наиболее широко используемая модель для информационного поиска.
Она концептуально проста и использует метафору для отражения семантического подобия как пространственной близости.
В этой модели каждый документ представляется в многомерном пространстве, в котором каждое измерение соответствует слову в наборе документов.
Эта модель представляет документы матрицей слов и документов:
M =| F | × | D |,
где F = { f1, ..., fk , ..., fz } ; D = {d1, ..., di , ..., dn} , di — вектор в z -мерном пространстве Rz .
Набор признаков F конструируется при помощи исключения редких слов и слов с высокой частотой. Исключение слов означает, что слова рассматриваются только как признаки, если они встречаются бóльшее количество раз, чем обозначенный частый порог, или меньшее количество раз, чем обозначенный нечастый порог. Значения порогов определяются экспериментально.
Каждому признаку fk в документе di ставится в соответствие его вес ωk i ,который обозначает важность этого признака для данного документа. Для вычисления веса могут использоваться разные подходы, например алгоритм TFIDF (Term Frequency Inverse Document Frequency). Идея этого подхода — гарантировать, что вес признака будет находиться в диапазоне от 0 до 1. При этом чем чаще слово появляется в тексте, тем его вес выше, и наоборот: чем частота меньше, тем вес меньше. Формула, по которой вычисляется вес, имеет следующий вид:

Необходимо отметить, что в знаменателе находится сумма по всем документам, кроме рассматриваемого. Таким образом, вес функции нормализуется относительно всех документов. Эта модель часто называется "мешок слов" (bag-of-words).
Кроме метода TFIDF для взвешивания термов часто используется подход TLTF (Term Length Term Frequency). Идея метода TLTF базируется на том, что слова, которые появляются часто, стремятся быть краткими. Такие слова не описывают основную тему документа, т. е. являются стоп-словами. Наоборот, слова, которые появляются редко, стремятся быть длинными.
Кластеры в данной модели представляются аналогично документам в виде векторов:
C = {c1, ..., cj , ..., cm} ,
где cj — вектор в z -мерном пространстве Rz . Вектор cj часто является центром кластера (центроидом).
При этом целью кластеризации является группировка документов (представленных векторами) по кластерам в соответствии с близостью их к центрам. Близость документа и кластера, представленных пространственными векторами, вычисляется как угол между этими векторами:
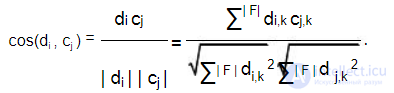
Все алгоритмы кластеризации основываются на измерениях похожести по различным критериям. Некоторые используют слова, часто появляющиеся вместе (лексическую близость), другие используют извлекаемые особенности (такие как имена людей и т. п.). Разница заключается также и в создаваемых кластерах. Выделяют три основных типа методов кластеризации документов:
иерархический — создает дерево со всеми документами в корневом узле и одним документом в узле-листе. Промежуточные узлы содержат различные документы, которые становятся более и более специализированными по мере приближения к листьям дерева. Этот метод полезен, когда исследуют новую коллекцию документов и хотят получить общее представление о ней;
бинарный — обеспечивает группировку и просмотр документальных кластеров по ссылкам подобия. В один кластер помещаются самые близкие по своим свойствам документы. В процессе кластеризации строится базис ссылок от документа к документу, основанный на весах и совместном употреблении определяемых ключевых слов;
нечеткий — включает каждый документ во все кластеры, но при этом связывает с ним весовую функцию, определяющую степень принадлежности данного документа определенному кластеру.
Как описывалось в главе 6, методы иерархической кластеризации бывают:
агломеративные — кластеризация выполняется, начиная с индивидуальных элементов, группируя их в кластеры (снизу вверх);
дивизимные — кластеризация выполняется, начиная с единого кластера и разбивая его на несколько (сверху вниз).
Иерархическая агломеративная кластеризация (НАС — Hierarchical Agglomerative Clustering) изначально представляет каждый из N документов отдельным кластером. В процессе кластеризации эти кластеры объединяются, и количество кластеров уменьшается до тех пор, пока один кластер не будет содержать все N документов. Такой подход различается методами группировки отдельных кластеров:
односвязный метод группирует ближайших членов;
полносвязный — дальних членов;
среднесвязный — ближайших к середине членов. Результатами такой кластеризации является дентограмма.
Представителем дивизимной иерархической кластеризации текстовых документов является алгоритм дивизимного разделения по главному направлению (PDDP — Principal Direction Divisive Partitioning). Он строит бинарное дерево, в котором каждый узел содержит документы. PDDP начинает строить дерево с корневого кластера, который содержит все документы. Далее он рекурсивно делит каждый лист дерева на два дочерних узла, пока сохраняется критерий деления. Для сохранения балансировки бинарного дерева PDDP использует функцию разброса для определения необходимости разделения узла. Эта функция вычисляет, насколько близки элементы в кластере. Например, если среднеквадратичное расстояние кластера больше заданного порогового значения, то кластер (узел дерева) должен быть разделен. Матрица слов и документов используется для определения главного направления и разделения гиперпространства.
Например, пусть имеется матрица слов и предложений. Для того чтобы разделить матрицу на две подматрицы (узла), каждый документ проектируется на главное направление. Главным направлением матрицы является собственный вектор e = {e1, ..., e2 , ..., eT } ковариационной матрицы ∑ = (d − c)(d − c)T .
Проекция документа di определяется следующим образом:
v = e (d − c) ,
где v — это значение, которое используется, чтобы определить разделение
кластера; — центроид матрицы. c
Все документы, для которых v ≤ 0 , группируются в левый узел, документы, для которых v > 0 , помещаются в правый узел. Проекция может быть интерпретирована фактом существования гиперплоскости, которая делит набор многомерных векторов на две отдельные группы.
Интерактивная кластеризация обычно создает кластеры, оптимизируя целевую функцию, описанную локально (среди документов одного и того же кластера) или глобально (через все документы).
Типичным представителем интерактивных алгоритмов является алгоритм k -средних (подробно описанный в главе 6). Он интерактивно выполняет деление данных на k -кластеров, минимизируя расстояния между элементами кластеров и их центрами.
Для задачи кластеризации текстовых документов он адаптируется следующим образом. Имеется множество документов:
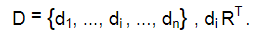
Алгоритм k -средних создает k декомпозиций так, чтобы если {c1, c2 , ...,ck }
представляет собой k центров, то минимизируется следующая целевая фунуция
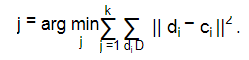
Задача аннотирования документов является актуальной для любых хранилищ информации: от библиотек до интернет-порталов. Аннотирование требуется также и конкретному человеку, например, для быстрого ознакомления с интересующей его публикацией или с подборкой статей по одной тематике.
В настоящее время наиболее распространено ручное аннотирование, к достоинствам которого можно отнести, безусловно, высокое качество составления аннотации — ее "осмысленность". Типичные недостатки ручной системы аннотирования — высокие материальные затраты и присущая ей низкая скорость.
Хорошее аннотирование предполагает содержание в аннотации предложений, представляющих максимальное количество тем, представленных в документе, при минимальной избыточности.
Согласно статье [45], процесс аннотирования распадается на три этапа:
1.Анализ исходного текста.
2.Определение его характерных фрагментов.
3.Формирование соответствующего вывода.
Большинство современных работ концентрируются вокруг разработанной технологии реферирования одного документа.
Выделяют два основных подхода к автоматическому аннотированию текстовых документов:
Извлечение — предполагает выделение наиболее важных фрагментов (чаще всего это предложения) из исходного текста и соединение их в аннотацию.
Обобщение — предполагает использование предварительно разработанных грамматик естественных языков, тезаурусы, онтологические справочники и др., на основании которых выполняется переформулирование исходного текста и его обобщение.
Вподходе, основанном на извлечении фрагментов методом сопоставления шаблонов, выделяют наиболее лексически и статистически значимые части.
Врезультате аннотация в данном случае создается простым соединением выбранных фрагментов.
Вбольшинстве методов, основанных на данном подходе, используются весовые коэффициенты, вычисляемые для каждого фрагмента. Вычисления выполняются в соответствии с такими характеристиками, как расположение фрагмента в тексте, частота появления, частота использования в ключевых предложениях, а также показатели статистической значимости. Общий вид формулы вычисления веса фрагмента текста U выглядит следующим образом:
Weight(U) = Location(U) + KeyPhrase(U) + StatTerm(U) + AddTerm(U).
Весовой коэффициент расположения (Location) в данной модели зависит от того, где во всем тексте или в отдельно взятом параграфе появляется данный фрагмент — в начале, в середине или в конце, а также используется ли он в ключевых разделах, например, во вводной части или в заключении.
Ключевые фразы представляют собой лексические резюмирующие конструкции, такие как "в заключение", "в данной статье", "согласно результатам анализа" и т. д. Весовой коэффициент ключевой фразы (KeyPhrase) может зависеть также и от принятого в данной предметной области оценочного термина, например, "отличный" (наивысший коэффициент) или "малозначащий" (значительно меньший коэффициент).
Кроме того, при назначении весовых коэффициентов в этой модели учитывается показатель статистической важности (StatTerm). Статистическая важность вычисляется на основании данных, полученных в результате анализа автоматической индексации, при которой вычисляются весовые коэффициенты лексем (например, методами TFIDF или TLTF).
И наконец, эта модель предполагает просмотр терминов в фрагменте текста и определение его весового коэффициента в соответствии с дополнительным
наличием терминов (AddTerm) — появляются ли они также в заголовке, в колонтитуле, в первом параграфе и в пользовательском запросе. Выделение приоритетных терминов, наиболее точно отражающих интересы пользователя, — это один из путей настроить аннотацию на конкретного человека или группу.
В подходе обобщения для подготовки аннотации требуются мощные вычислительные ресурсы для систем обработки естественных языков (NLP — Natural Language Processing), в том числе грамматики и словари для синтаксического разбора и генерации естественно-языковых конструкций. Кроме того, для реализации этого метода нужны некие онтологические справочники, отражающие соображения здравого смысла, и понятия, ориентированные на предметную область, для принятия решений во время анализа и определения наиболее важной информации. Данный подход предполагает использование двух основных типов методов.
Первый тип опирается на традиционный лингвистический метод синтаксического разбора предложений. В этом методе применяется также семантическая информация для аннотирования деревьев разбора. Процедуры сравнения манипулируют непосредственно деревьями с целью удаления и перегруппировки частей, например, путем сокращения ветвей на основании некоторых структурных критериев, таких как скобки или встроенные условные или подчиненные предложения. После такой процедуры дерево разбора существенно упрощается, становясь, по существу, структурной "выжимкой" исходного текста.
Второй тип методов аннотирования опирается на понимание естественного языка. Синтаксический разбор также входит составной частью в такие методы анализа, но деревья разбора в этом случае не порождаются. Напротив, формируются концептуальные структуры, отражающие всю исходную информацию, которая аккумулируется в текстовой базе знаний. В качестве структур могут быть использованы формулы логики предикатов или такие представления, как семантическая сеть или набор фреймов. Примером может служить шаблон банковских транзакций (заранее определенное событие), в котором перечисляются организации и лица, принимающие в нем участие, дата, объем перечисляемых средств, тип транзакции и т. д.
Подход, основанный на извлечении фрагментов, легко настраивается для обработки больших объемов информации. Из-за того что работа таких методов основана на выборке отдельных фрагментов, предложений или фраз, текст аннотации, как правило, лишен связности. С другой стороны, такой подход выдает более сложные аннотации, которые нередко содержат информацию, дополняющую исходный текст. Так как он опирается на формальное представление информации в документе, то его можно настроить на достаточно высокую степень сжатия, например, для рассылки сообщений на мобильные устройства.
Подход, основанный на обобщении и предполагающий опору на знания, как правило, требует полноценных источников знаний. Это является серьезным препятствием для его широкого распространения. Поэтому разработчики средств автоматического аннотирования все больше склоняются к гибридным системам, а исследователям все более успешно удается объединять статистические методы и методы, основанные на знаниях.
Рассмотрим метод аннотирования документов, основанный на использовании карты текстовых отношений (TRM — Text Relationship Map). Идея метода заключается в представлении текста в виде графа [46]:
G = (P, E),
где P = { p1, p2 , ..., pk , ..., pn} — взвешенные векторы слов, соответствующие
фрагментам документа. Вектор включает в себя веса составляющих его слов. Например, k -й фрагмент будет представлен вектором:
{ωk , ωk , ..., ωk i , ..., ωk m},
,1 ,2 , ,
где ωk i — вес слова, находящегося в позиции i фрагмента k ; E — множество дуг между узлами графа:
E ={( pk , pb ), pk , pb V}.
На рис. 9.3 изображен пример такой карты. Каждый узел на карте соответствует некоторому фрагменту текста (предложению, абзацу, разделу, параграфу) и представляется взвешенным вектором термов. Связи создаются между двумя узлами, если они имеют высокую меру подобия между параграфами, которая обычно вычисляется как скалярное произведение между векторами, представляющими эти фрагменты.
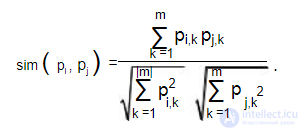
Другими словами, если имеется связь между двумя узлами, то говорят, что соответствующие фрагменты "семантически близки". Количество входящих в узел дуг на карте соответствует важности фрагмента и служит причиной его извлечения в резюме. Например, на рис. 9.3 количество входящих дуг узла P5
равно 5, т. к. в него входят дуги от узлов P1, P2 , P3 , P4 и P6 . Это значение максимально по сравнению с другими узлами. Следовательно, узел P5 своим содержанием может покрыть фрагменты, соответствующие связанным с ним узлам, и он должен быть помещен в аннотацию.
Основным недостатком данного подхода является то, что учитывается только один аспект важности фрагмента, а именно: его отношение с другими фрагментами документа. Здесь не рассматривается информативность слов, имеющихся внутри отдельного фрагмента. В результате в резюме могут быть выбраны фрагменты, тесно связанные с другими, но не характеризующие тематику документа (не имеющие внутри себя ключевых слов).
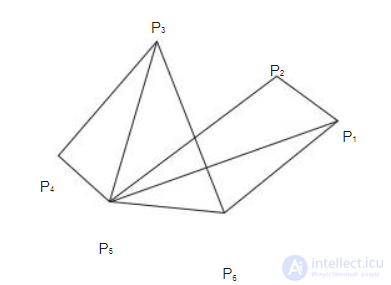
Рис. 9.3. Пример карты текстовых отношений
Для устранения этого недостатка в работе [47] предлагается использовать понятие локального и глобального свойства фрагмента, в качестве которого используются предложения документов. При этом в качестве локальных свойств рассматриваются кластеры слов внутри предложения, веса которых вычисляются методом TLTF. В качестве глобального свойства выступает отношение данного предложения со всеми остальными в тексте, которое определяется методом TRM. Комбинируя оба свойства, данный метод определяет степень значимости предложения и необходимость его включения в резюме.
Для вычисления кластеров слов в предложении используется не частота появления термов в тексте (как во многих методах), а более сложные правила. Если представить последовательность слов в предложении, как последовательность:
β = {wu , ..., wv} ,
то слова включаются в кластер, если выполняются следующие условия:
первое wu и последнее wv слова в предложении значимые;
значимые слова разделяются не более чем заранее определенным количеством незначимых слов.
Например, мы можем разделить последовательность слов в предложении следующим образом:
w1 [w2 w3 w4] w5 w6 w7 w8 [w9 w10 w11 w12].
В этом случае предложение состоит из 12 слов. Полужирным шрифтом выделены значимые слова (w2, w4, w9, w11, w12). Кластеры заключены в квадратные скобки. Они сформированы согласно условию, что значимые слова должны быть разделены не более чем тремя незначимыми словами. Необходимо обратить внимание, что в предложении может быть несколько кластеров (в нашем примере их два). Наибольшее значение кластера определяет значимость предложения. Значение кластера в предложении si вычисляется по формуле:
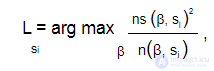
где ns (β, si ) — количество значимых слов в кластере; n(β, si ) — общее количество слов в кластере.
Как было сказано ранее, в качестве глобального свойства предложения используется его отношение с другими предложениями в документе. Оно вычисляется с помощью карты отношений в тексте (метод TRM).
Описанные локальные и глобальные свойства определяют различные аспекты значимости предложений. Локальное свойство определяет долю информации внутри предложения, а глобальное свойство больше определяет структурный аспект документа, оценивая информативность всего предложения. Для большей эффективности предлагается рассматривать оба аспекта в совокупности, объединяя их в единую оценку информативности предложения, которая может быть использована для заключения: выносить ли данное предложение в резюме или нет. Для вычисления комбинированной оценки используется формула:
F(si ) = λG′ + (1 − λ)L′ ,
где:
G′ — нормализованная глобальная связанность предложения, вычисляется по формуле:
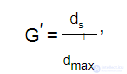
в которой dmax — максимальное количество ребер для одного узла на карте отношений в тексте,
dsi — количество ребер для узла соответствующего предложению si ;
L′ — нормализованное значение локальной кластеризации предложения si , вычисляется по формуле:
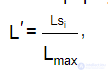
где Lmax — максимальная локальная кластеризация во всем тексте;
λ — параметр, изменяющийся в зависимости от важности составляющих G′ или L′ .
Таким образом, получается интегрированная оценка для всех предложений, на основании которой можно сделать выбор предложений в резюме.
Начиная c версии Oracle 7.3.3, средства текстового анализа являются неотъемлемой частью продуктов Oracle. В Oracle9i эти средства развились и получили новое название — Oracle Text — программный комплекс, интегрированный в СУБД, позволяющий эффективно работать с запросами, относящимися к неструктурированным текстам. При этом обработка текста сочетается с возможностями, которые предоставлены пользователю для работы с реляционными базами данных. В частности, при написании приложений для обработки текста стало возможно использование SQL. Данное средство входит в состав и последней версии Oracle 11g.
Система Oracle Text обеспечивает решение следующих задач анализа текстовой информации:
1 Обзор подготовлен по материалам статьи Дмитрия Ландэ "Глубинный анализ текстов. Технология эффективного анализа текстовых данных".
2 http://technet.oracle.com/products/text/content.html.

Основной задачей, на решение которой нацелены средства Oracle Text, является задача поиска документов по их содержанию — по словам или фразам, которые при необходимости комбинируются с использованием булевых операций. Результаты поиска ранжируются по значимости, с учетом частоты встречаемости слов запроса в найденных документах. Для повышения полноты поиска Oracle Text предоставляет ряд средств расширения поискового запроса,
продолжение следует...
Часть 1 3 Анализ текстовой информации - Text Mining
Часть 2 3.Классификация текстовых документов (описание задачи классификации текстов, методы классификации текстовых
Часть 3 Средства от IBM — Intelligent Miner for Text1 - 3
К сожалению, в одной статье не просто дать все знания про анализ текстовой информации. Но я - старался. Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое анализ текстовой информации, text mining, интеллектуальный анализ текстов, иат и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Интеллектуальный анализ данных
Комментарии
Оставить комментарий
Интеллектуальный анализ данных
Термины: Интеллектуальный анализ данных