Лекция
Привет, мой друг, тебе интересно узнать все про моделирования человеческих рассуждений привязка к коммуникатору превращаем речь в мысль а мысль в речь , тогда с вдохновением прочти до конца. Для того чтобы лучше понимать что такое моделирования человеческих рассуждений привязка к коммуникатору превращаем речь в мысль а мысль в речь , настоятельно рекомендую прочитать все из категории Моделирование мыслительных процессов на естественном языке и Символьное моделирование.
Сразу предупреждаю сложно. Мозги придется выворачивать наизнанку.
Первый фильтр. БД "избитых фраз", с уже известным/просчитанным смыслом. Используется для ускорения просчета. Примеры: "после дождичка в четверг", "когда рак на горе свистнет" и т.п.
Заменяются на просто - НЕТ и далее переход на "рождение новой мысли".
Второй фильтр. Это "предсказание" следующей фразы. Беседа имеет определенную "тему разговора", "характер" и "стиль". То есть, смотря о чем идет разговор. Вопрос предполагает ответ. Лекция предполагает "запоминание". Спор предполагает обмен мнениями. Скандал предполагает обмен эмоциями. Для каждой ситуации хранится несколько вариантов "поведенческих моделей".
На основе этих моделей строится "линия поведения" (здесь вам и характер личности и настроение и пр.) Кроме того, собеседник так же имеет (предполагаемые) характер/настроение и т.п.
И в течении разговора отслеживается совпадение реальной и предполагаемой беседы, с корректировкой следующих предположений и корректировкой БД предположений.
Соответственно, фильтр вносит коррективы. Пример:
ИР: Земля имеет форму шара? (предполагается ответ ДА или НЕТ)
Ч: А сам ты как думаешь? (ответ не совпадает с предполагаемым, предполагался ответ, вместо этого вопрос. Анализ фразы. Предлагается самостоятельное выяснение вопроса. Поместить в буфер нерешенных задач, попробовать построить "временную" связь - предположение).
Третий фильтр. Отсеивание слов-паразитов. Мата. (для связки слов в предложения).
Изменение сложных конструкций на более простые по БД соответствия (синонимы).
Пример: "Глубокоуважаемый собеседник, не соблаговолите ли вы сообщить мне следующий факт..."
заменяется на: "скажи..."
"Нижайше кланяюсь и раболепно умоляю..." заменяется на "слушай..."
ЭМО-фильтр. Искажение в зависимости от эмоционального накала.
Смысл фразы "Да ты козел, меня уже задолбал своей тупостью" заменяется на "ты меня не понял"
(по БД соответствия и от "линии поведения") Откровенная ложь, насмешки, издевательства, унижения и пр. и соответствующая "линия поведения" например: игнорировать собеседника.
Лишь после обработки фильтрами начинается "распознавание фразы" и "перевод" ее во внутренний формат. В мысль.
И так, начнем с понимания/распознавания фраз и превращения их в связи.
Допустим на вход подана фраза:
"В моей комнате обои зеленого цвета"
Забудем на некоторое время о всех синтаксически-лингвистических обработках и пр.
Сейчас нам нужно понять главное. Любая фраза содержит в себе несколько групп связей.
Нам необходимо выделить их и построить гроздь.
(Совокупность всех гроздей в течении разговора называется "шаром мысли" наиболее близкое по значению слово "контекст" но не совсем. Контекст это "общий смысл" разговора, а "шар мысли" это выборка всех возможных связей разговора (их количество ограничивается контроллером "от глубокого ухода")).
"В моей комнате обои зеленого цвета"
Для этой фразы раскладка будет следующая:
При внимательном рассмотрение сложное предложение распадается на два простых.
(КОМНАТА)->ДА->[ИМЕЕТ]->(ОБОИ)
В комнате имеются обои.
Причем, объект (ОБОИ) имеет параметр цвет:
(КОМНАТА)->ДА->[ИМЕЕТ]->(ОБОИ)-|ЗЕЛЕНЫЙ|
Кроме того, есть еще "привязка_к_Я" делающая эту связь из абстрактной - конкретной.
(Я)->ДА->[ИМЕЕТ]->(КОМНАТА)
То есть если записать в виде двух отдельных связей, то получится так:
(Я)->ДА->[ИМЕЕТ]->(КОМНАТА)
(КОМНАТА)->ДА->[ИМЕЕТ]->(ОБОИ)-|ЗЕЛЕНЫЙ|
Но это будет неверно. Так как это две разных связи!
(КОМНАТА) это абстрактное понятие, поскольку находится очень высоко по дереву.
Значит необходимо объединить эти две связи в одну:
(Я)->ДА->[ИМЕЕТ]->(КОМНАТА)->ДА->[ИМЕЕТ]->(ОБОИ)-|ЗЕЛЕНЫЙ|
Немножко сложновато для понимания сразу, и сразу хочется возразить: А для чего вообще весь огород городить, если получилось то же самое?
Попробую объяснить. На входе мы имели фразу (текст) на выходе у нас мысль.
Красивыми бывают только слова, мысль некрасива с лингвистической точки зрения, она слишком проста и примитивна. Вот в этой "примитивности" и есть смысл. Мысль рациональна и легко поддается обработкам (сохранение/поиск в БД, проверки, замена/подмена одних данных другими).
При работе с текстом, то же самое сделать гораздо сложнее.
А теперь вспоминаем "правило наблюдателя". С этой мыслью было бы все хорошо, если бы она родилась внутри системы.
Но поскольку она попала к нам "извне" (введена с клавиатуры) следовательно, необходимо "инвертировать" понятие Я.
После этого преобразования наша мысль будет выглядеть так:
(ОН)->ДА->[ИМЕЕТ]->(КОМНАТА)->ДА->[ИМЕЕТ]->(ОБОИ)-|ЗЕЛЕНЫЙ|
Поскольку мысль "чужая" необходимо ее осмыслить/обработать/просчитать/загнать в БД:
1. Привязка к Я.
(Я)->ДА->[ЗНАЮ]:(ОН)->ДА->[ИМЕЕТ]->(КОМНАТА)->ДА->[ИМЕЕТ]->(ОБОИ)-|ЗЕЛЕНЫЙ|
Я узнал, что у него (собеседника) есть своя комната , в которой обои зеленого цвета.
2. Проверка мысли (расписывается по контроллерам/прерываниям):
а) контроллер правильная/НЕправильная мысль.
У него есть комната. (проверка процесса) У него может быть своя комната?
В комнате есть обои. (проверка процесса) В комнатах бывают обои?
Обои зеленого цвета (проверка параметра цвет) Обои могут быть зеленого цвета?
б) контроллер приоритета. (А это важно для меня? Мне вообще это нужно знать?)
б1) Я это уже знаю? Да/нет.
б2) Контекст разговора (а мы об этом вообще говорили? Фраза имеет отношение к разговору?)
б3) Что он имел в виду (перепроверка смысла фразы в рамках контекста, отдельно с предыдущей мыслью и отдельно с общей темой разговора, проверка на искажения - логику, ложь)
в) ЭМО-отношение к фразе (привязка к ЭМО-зоне) Фраза серьезная? Не шутка? Не розыгрыш?
г) Проверка буфера нерешенных задач (нам нужно знать, какого цвета обои в его комнате?)
д) ... /оставить возможность добавления модулей проверки/
3. Делаем окончательный вывод: фраза нейтральна. Данные второсортны. Сохраняем в БД с соответствующими метками/коэффициентами для контролера приоритета.
4. Подготовка ответа. (далее в статье "Рождение новой мысли")
Коротко еще:
(Здесь придется сделать ссылку на "инструкции" к понятиям.)
1. Любая ситуация обрабатывается по БД ситуаций и БД инструкций.
Простейшие ситуации это инструкции типа "Получил вопрос - дай на него ответ", или "когда говорят старшие - не перебивай". БД подобных инструкций пополняется все время.
2. Информация полученная во время разговора имеет определенный коэффициент "правдоподобности" (точности, истины, лжи) складывается из доверия собеседнику (он может ошибаться/врать/шутить и пр.) Кроме того, есть вариант неправильного "понимания" (декодирования) фразы ( ты меня не понял, я не это имел в виду) или неполное знание предмета разговора (отсутствуют некоторые данные/образы/связи). В этом случае используется соответствующая "линия поведения".
3. ЭМО-фильтр. Об этом говорит сайт https://intellect.icu . То же немаловажная часть разговора. Предсказание поведения очень сложно, необходимо иметь большую БД "ситуаций" вложить которые "вручную" не получится. Нужен очень хитрый алгоритм "запоминания" ситуаций и "сравнения текущей" (подобие-подобного)
Попробуем еще несколько примеров.
"В лесу водится большое количество животных, например - кабаны, лоси, волки, лисы, зайцы, белки, мыши."
В отличие от предыдущего случае, здесь все связи общие. Следовательно находятся выше по дереву и могут быть записаны в виде отдельных связей. Распишем:
(КАБАН)->ДА->(ЖИВОТНОЕ)
(ЛОСЬ)->ДА->(ЖИВОТНОЕ)
(ВОЛК)->ДА->(ЖИВОТНОЕ)
(ЛИСА)->ДА->(ЖИВОТНОЕ)
(ЗАЯЦ)->ДА->(ЖИВОТНОЕ)
(БЕЛКА)->ДА->(ЖИВОТНОЕ)
(МЫШЬ)->ДА->(ЖИВОТНОЕ)
(ЛЕС)->ДА->[ЕСТЬ]->(ЖИВОТНЫЕ)
В лесу водятся животные. А какие? Мы можем ответить на этот вопрос? В общем случае - нет.
Так если в список "животные" случайно попадут "жираф" и "верблюд" из другого предложения, то при выборке списком, они так же попадут в список "животные проживающие в лесу". Таким образом мы установили точку, до которой связь является общей а откуда становится конкретной. Итак дописываем:
(ЛЕС)->ДА->[ЕСТЬ]->(КАБАН)
(ЛЕС)->ДА->[ЕСТЬ]->(ЛОСЬ)
(ЛЕС)->ДА->[ЕСТЬ]->(ВОЛК)
(ЛЕС)->ДА->[ЕСТЬ]->(ЛИСА)
(ЛЕС)->ДА->[ЕСТЬ]->(ЗАЯЦ)
(ЛЕС)->ДА->[ЕСТЬ]->(БЕЛКА)
(ЛЕС)->ДА->[ЕСТЬ]->(МЫШЬ)
Либо укороченная запись:
(ЛЕС)->ДА->[ЕСТЬ]->(КАБАН)/(ЛОСЬ)/(ВОЛК)/(ЛИСА)/(ЗАЯЦ)/(БЕЛКА)/(МЫШЬ)
И так, "понимание" для фразы "В лесу водится большое количество животных, например - кабаны, лоси, волки, лисы, зайцы, белки, мыши", в окончательном виде будет выглядеть так:
(КАБАН)->ДА->(ЖИВОТНОЕ)
(ЛОСЬ)->ДА->(ЖИВОТНОЕ)
(ВОЛК)->ДА->(ЖИВОТНОЕ)
(ЛИСА)->ДА->(ЖИВОТНОЕ)
(ЗАЯЦ)->ДА->(ЖИВОТНОЕ)
(БЕЛКА)->ДА->(ЖИВОТНОЕ)
(МЫШЬ)->ДА->(ЖИВОТНОЕ)
(ЛЕС)->ДА->[ЕСТЬ]->(КАБАН)/(ЛОСЬ)/(ВОЛК)/(ЛИСА)/(ЗАЯЦ)/(БЕЛКА)/(МЫШЬ)
Теперь идем сюда и ознакомившись с текстом и построив соответствующую схему, учимся работать с данными и отвечать на вопросы.
Немного об общем/конкретном.
Возмем для примера предыдущую фразу, но слегка видозменим ее:
"В лесах Забайкалья водится большое количество животных, например - кабаны, лоси, волки, лисы, зайцы, белки, мыши."
В отличие от предыдущего случая, добавление всего одного слова, сразу сделало мысль конкретной. Все осталась так же:
(КАБАН)->ДА->(ЖИВОТНОЕ)
(ЛОСЬ)->ДА->(ЖИВОТНОЕ)
(ВОЛК)->ДА->(ЖИВОТНОЕ)
(ЛИСА)->ДА->(ЖИВОТНОЕ)
(ЗАЯЦ)->ДА->(ЖИВОТНОЕ)
(БЕЛКА)->ДА->(ЖИВОТНОЕ)
(МЫШЬ)->ДА->(ЖИВОТНОЕ)
(ЗАБАЙКАЛЬЕ)->ДА->[ЕСТЬ]->(ЛЕС)
(ЛЕС)->ДА->[ЕСТЬ]->(ЖИВОТНЫЕ)
Но вот такую структуру:
(ЛЕС)->ДА->[ЕСТЬ]->(КАБАН)/(ЛОСЬ)/(ВОЛК)/(ЛИСА)/(ЗАЯЦ)/(БЕЛКА)/(МЫШЬ)
мы уже не можем использовать, потому что ЛЕС - общее понятие, и не известно какой конкретный лес имеется в виду. А у нас в условии указан конкретный лес Забайкалья.
Кроме того, подобная запись может попортить наши представления о живности в лесах.
Поэтому наша запись станет еще длиннее:
(ЗАБАЙКАЛЬЕ)->ДА->[ЕСТЬ]->(ЛЕС)->ДА->[ЕСТЬ]->(КАБАН)/(ЛОСЬ)/(ВОЛК)/(ЛИСА)/(ЗАЯЦ)/(БЕЛКА)/(МЫШЬ)
А с учетом привязки_к_Я
(Я)->ДА->[ЗНАЮ]:(ЗАБАЙКАЛЬЕ)->ДА->[ЕСТЬ]->(ЛЕС)->ДА->[ЕСТЬ]->(КАБАН)/(ЛОСЬ)/(ВОЛК)/(ЛИСА)/(ЗАЯЦ)/(БЕЛКА)/(МЫШЬ)
Небольшая схемка (по нашему примеру с животными)
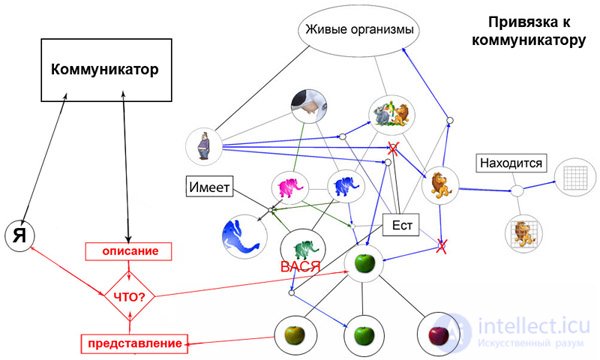
На ней изображена "привязка к коммуникатору".
Думаю что понятно изображено? Если нет, жду "уточняющих вопросов".
Вообще, то что мы так долго разбираем, это только "образное мышление".
Неоднократно заданный мне вопрос: Мыслим ли мы словами (ответ я уже давал)
И да, и нет. И вот почему:
Привязка к коммуникатору - это разные ветви ОДНОГО уравнения.
Огромная формула и посередине знак "=". Все что слева от знака - это мышление "словами", все что справа - образами. Но это еще далеко не все, есть еще абстрактное мышление (дай бог, что бы хотя бы через год, я смог вам описать его принцип работы :) и это еще не все...
Однако вернемся с небес на землю. Значит мы все таки мыслим словами?
Да. Процесс мышления словами и образами идет параллельно.
Примеры:
1.1 Земля имеет форму шара?
1.2 2Х2=?
и для сравнения:
2.1 Сколько сторон у додекаидра?
2.2 213Х2+174=? (без калькулятора!!!)
Как видите в первых двух вопросах вам не пришлось "думать", так как ответ уже был "на кончике языка". В двух вторых вопросах вам пришлось считать. А это уже задействованы не только п/п работы с памятью, но и логика и мыслительный процесс...
Наиболее устойчивые связи образов, помещаются в образ (верхнего уровня) и метятся ярлыком (индексируются). Это и называется Образ_как_совокупность_образов.
Примерное значение имеет слово - "понятие". Так же обстоят дела и с наиболее распространенными словосочетаниями. Имеется некий "виртуальный буфер" (кэш) в котором находятся наиболее часто используемые фразы, словечки, жаргонизмы и пр.
Профессия, образование, культурный уровень, коэффициент интеллекта, увлечения и пр. все это накладывает отпечаток на человека и от всего этого зависит, КАКИЕ именно фразы/знания находятся в этом буфере.
Для чего они там? Тут все просто, ДЛЯ УСКОРЕНИЯ процесса мышления. - КЭШ.
Эти знания УЖЕ просчитаны, проверены и очень часто востребованы.
Соответственно, сложный вопрос, это тот вопрос, ответ на который "не лежит на поверхности". И если необходимо "думать", это и есть процесс мышления.
Соответственно, мы говорим "сленгом", наиболее часто употребляемыми словами и предложениями. И "распознаем" эти фразы - быстрее.
Если же в буфер попадает "нестандартная фраза" (непривычная или неизвестная информация или "из другой оперы", соответственно мышление пойдет по другой цепочке нейронов и будут задействованы другие "механизмы" памяти и мышления)
Значит, что бы ПОНЯТЬ как осуществляется "привязка к коммуникатору", необходимо ЗНАТЬ как работает "образное мышление" и КАК работает коммуникатор.
Это подпрограмма (функция) на вход которой подается "фраза на внешнем языке" а на выходе "связь образов".
Но это еще не все. Недостаточно "простого перевода" (привязки), так как "внешний" и "внутренний" языки разные и "перевод" получается приблизительным. Кроме того, накладываются дополнительные "шумы и помехи". Важен СМЫСЛ. Истинное значение полученной связи.
Как раз если вдуматься, то становится понятно, почему до сих пор нет идеального переводчика (например с английского на русский) потому, что дело не в соответствии базы слов на анлийском/базе слов на русском (это как раз легко реализуемо) и даже дело не в грамматике (и это уже давным давно существует) и даже неологизмы и пр. можно подобрать. Проблема как раз заключена в том, что смысл все равно теряется. То есть после "буквального" (слово-в-слово) перевода, необходима дополнительная правка текста, для того, чтобы привести текст к синтаксически правильному написанию и не допустить искажения смыслового слоя.
Как же так? Мы ведь НИЧЕГО не меняли в оригинальном тексте, а смысл потерялся? Именно так! Одни и те же фразы, жаргонные словечки и пр. на разных языках имеют различный смысл. Особенно сильно это касается рекламных слоганов. Короткие и звучные фразы. Пример: рекламный слоган чупа-чупса. "Мы научили весь мир сосать". В России не катит... Смысл важен. Смысл не связан со словом. Смысл связан с мыслью. (т.е. чуть-чуть глубже) а это значит "идеальный переводчик" должен уметь "думать" на обоих языках, что бы перевести фразу, нужно понять не то, что сказано, а то, что подразумевалось.
"Компетентность" собеседника.
Собеседник может ошибаться/не знать, лгать, фантазировать, издеваться, шутить, наконец просто оказаться "дебилом" или тролем...
Поэтому и контекст очень важен, он может поменять смысл вообще на противоположный.
И общее эмоциональное состояние разговора (шутка это или серьезный разговор).
Ну и наконец, самое главное - ВАЖНОСТЬ (приоритет), если это НУЖНАЯ информация, то "слушать и вникать во все сказанное". Если просто треп, то "глубоко не задумываться", шутить и "развлекаться".
Исходя из всего вышесказанного, я не могу "авторитетно заявить", что коммуникатор (переводчик) отделен в отдельную подпрограмму. Он скорее всего - часть общей схемы. Но отделить его на схеме в отдельный блок - необходимо для понимания его важности.
>1. Сколько типов привязок комуникатора планируется?
Вообще-то 2.
1. вход/выход.
2. перепроверка
(а так ли он меня поймет?)
То есть после "генерирования" ответа, ответ вновь посылается на вход и "производится проверка распознавания" и привязки к "виртуальному" шару мысли по контексту (текущей беседы).
Если результат такой (ну или приблизительно такой) как планировалось, данные отправляются далее к органам речи. Но нужна ли такая сложность для чат-бота?
Этого я не знаю...
>2. Характеристики Объекта и Процесса.
Характеристики объекта зависят от объекта. Спускаемся вниз к "листьям" и смотрим, что объект из себя представляет. Какими характеристиками обладает.
Характеристики процесса зависят от объекта которым "наполнен" процесс.
"Собственные" характеристики процесса - второстепенны, я уже писал, расписываются по "розе ветров" (системе координат+время+важность)
>2.2 Как определяется где процесс, а где объект?
Тоже вопросик, из разряда "пойди туда - не знаю куда, принеси то, не знаю что".
При отсутствии БД "опознать" в новой информации где объект, а где процесс - невозможно. (хотя лингвистика наука хитрая и может помочь процентов на 70-80)
При "достаточно большой" БД, это уже не проблема. Так как мы имеем возможность "сравнивать". В ЕИ это реализовано несколькими разными вариантами мышления (ассоциативное, абстрактное мышления, интуиция, ну и конечно "опыт" - БД "удачных" опознаний).
Вопрос, КАК это реализовать для чат-бота?
Поэтому я предложил для начала, отказаться вообще от распознавания, пока не наберется "минимально необходимая БД". Ограничится для начала "диалогом на внутреннем языке" - языке образов.
Кроме того, есть 2 -3 идеи, как значительно расширить эту БД, не прибегая к кропотливому труду по "ручной набивке БД" (придется написать несколько очень простеньких алгоритмов, для пополнения БД, на основе толкового словаря, википедии, энциклопедий и пр. Так что, возможно такая проблема и не появится вообще.
Но если появится - по любому чат-бот ее не "решит" самостоятельно ;)
Поэтому придется заложить инструкцию "не знаешь-спроси".
>3. Как производится постановка цели для данного интеллекта?
Для конкретной реализации - чат-бота, целью является "полноценный диалог с человеком". А приоритетом "вторичных задач" типа; пополнение БД объектов/связей, уточнение смысла и пр. пусть он сам "занимается" ;)
Понимать это следует так: приоритет первоочередных задач устанавливается исходя из целой кучи параметров (ОЭС в том числе) и описывать их я пока не буду...
Хотя возможно, на первых порах просто "метить" вводимую инфу метками важности.
Что скажете?
ПОИСК СМЫСЛА ФРАЗЫ
У фразы может быть несколько смысловых слоев. Дай бог, научить бота поиску хотя бы одного...
Первый фильтр.
БД "избитых фраз", с уже известным/просчитанным смыслом. Используется для ускорения просчета.
По научному назывется - фразеологизмы.
Однако кроме этого бывает еще СЛЕНГ и Язык Падонкафф. Кроме того, специфические (для каждой профессии) сокращения слов/фраз или при долгих разговорах с одним человеком сокращения напоминающие смысл прошлых бесед.
Первое:
Работает как метка (ссылка, ярлык) на дополнительный текст. То есть вытаскивается целиком на "просчет" только при особой необходимости, а в повседневной беседе используется только СМЫСЛ фразы (понимание).
Как сделать? По таблице соответствия. Например:
ПАДАТЬ ДУХОМ это значит Отчаиваться, глубоко расстраиваться, приходить в уныние
УПАСТЬ ДУХОМ это значит ПАДАТЬ ДУХОМ
ПАСТЬ ДУХОМ это значит ПАДАТЬ ДУХОМ
То есть, если перевести в запись на внутреннем языке, выглядит так:
(ПАДАТЬ ДУХОМ)<-[ЭТО]<-ДА->(ОТЧАИВАТЬСЯ)
Или сокращенная форма записи:
(ПАДАТЬ ДУХОМ)<-ДА->(ОТЧАИВАТЬСЯ)
буквально значит равно =
Правая часть (выражения) = левая часть (выражения) - одинаковы по смысловому значению.
Противоположный пример:
Не падай духом.
ПАДАТЬ ДУХОМ это значит Отчаиваться, глубоко расстраиваться, приходить в уныние
(ПАДАТЬ ДУХОМ)<-[ЭТО]<-ДА->(ОТЧАИВАТЬСЯ)
Не падать духом это значит противоположное по смысловому значению.
(НЕ ПАДАТЬ ДУХОМ)<-[ЭТО]<-НЕТ->(ОТЧАИВАТЬСЯ)
Или сокращенная форма:
(НЕ ПАДАТЬ ДУХОМ)<-НЕТ->(ОТЧАИВАТЬСЯ)
Второе:
Хранить в БД обратные конструкции (антонимы) для связей. (То же самое, но наоборот)
То есть:
(НЕ ПАДАТЬ ДУХОМ)<-[ЭТО]<-НЕТ->(ПАДАТЬ ДУХОМ)
(ПАДАТЬ ДУХОМ)<-[ЭТО]<-ДА->(ОТЧАИВАТЬСЯ)
Третье: Хранить в БД как СИНОНИМЫ.
(ПАДАТЬ ДУХОМ)<-[ЭТО]<-ДА->(ОТЧАИВАТЬСЯ)
(ПАДАТЬ ДУХОМ)<-[ЭТО]<-ДА->(РАССТРАИВАТЬСЯ)
(ПАДАТЬ ДУХОМ)<-[ЭТО]<-ДА->(ПРИХОДИТЬ В УНЫНИЕ)
Или сокращенная запись:
(ПАДАТЬ ДУХОМ)<-[ЭТО]<-ДА->(ОТЧАИВАТЬСЯ)/(РАССТРАИВАТЬСЯ)/(ПРИХОДИТЬ В УНЫНИЕ)
Для "понятий" необходимо хранить (словарь) не только ссылку на понимание но и ссылку на "оригинальный текст словаря", может быть необходим как цитата.
Аналогично для разговоров (бесед) при напоминании об уже говоренном.
А помнишь я тебе рассказывал, как мы ходили 1 мая на демонстрацию?
Реакция бота: Помню/НЕ помню? Рассказывал/НЕ рассказывал? В БД есть упоминания? Есть/Нет.
Глубже погружения не происходит, до необходимости. Соответственно "поведенческая реакция" и привязка к Я:
Да, помню. Нет, напомни пожалуйста.
Структура данных.
Хранить в виде списка:
1. идентификатор
2. понимание (смысловое значение)
3. определение из словаря
4. уточнение (когда используется)
5. Эмо-составляющая
6. Инструкция (поведенческая реакция)
Аналогично работает и Третий фильтр..
Отсеивание слов-паразитов. Мата. (для связки слов в предложения).
Изменение сложных конструкций на более простые по БД соответствия (синонимы).
Пример: "Глубокоуважаемый собеседник, не соблаговолите ли вы сообщить мне следующий
факт..." заменяется на: "скажи..."
"Нижайше кланяюсь и раболепно умоляю..." заменяется на "слушай..."
Здесь только кроется маленький ньюанс, на который обычно не обращают внимания.
Нельзя так просто взять и выкинуть из предложения мат заменив его на тишину или "бип".
Мат имеет вполне нормальное (с точки зрения связей а не морали) смысловое значение.
Иногда даже более емкое, чем обычные слова. Существуют словари русского мата.
Существует бесчисленное количество популярных анекдотов играющих такую же роль общении,
как и фразеологизмы. (используется только смысловое содержание, ссылка на гроздь)
Выкинуть все это нельзя, так как смысловое значение потеряется либо изменится.
(НЕ ЗАКОНЧЕНО)
Если я не полностью рассказал про моделирования человеческих рассуждений привязка к коммуникатору превращаем речь в мысль а мысль в речь ? Напиши в комментариях Надеюсь, что теперь ты понял что такое моделирования человеческих рассуждений привязка к коммуникатору превращаем речь в мысль а мысль в речь и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Моделирование мыслительных процессов на естественном языке и Символьное моделирование
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

Комментарии