Лекция
Привет, Вы узнаете о том , что такое тестовые данные, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое тестовые данные , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
При рассмотрении задачи проектирования теста были описаны два важных артефакта: тестовые сценарии и тестовые наборы. В отсутствие данных для тестов эти два артефакта реализовать невозможно. Они являются описаниями условий, сценариев и путей, но не предусматривают конкретных значений для реализации. тестовые данные сами по себе не являются артефактом, но заметно влияют на успех или неудачу теста. Тестирование не может быть выполнено без данных для тестов. Они требуются для следующего:
Поэтому определение значений - это важная часть работы при создании тестовых наборов, см. Рабочий продукт: тестовый набор и Рекомендация: тестовый набор.
При определении фактических данных для тестов следует учитывать четыре параметра:
Так же необходите проверять предельно крайние значения. например если ожидается ввод строки то это пустая строка, иочень длинная если число то это отрицальное большое число, положительнлоое большое число и ноль и тд
Эти параметры подробно описываются в следующих разделах:
Объем - это количество данных для тестирования. Объем данных - это важный параметр; если данных слишком мало, они могут не отразить все возможные ситуации, если же слишком много - то с ними будет трудно работать. Лучше всего, если тестирование начинается с небольшого объема данных, пригодного для критически важных (и, как правило, позитивных) тестовых наборов. По мере того как достоверность тестирования будет увеличиваться, объем данных должен расширяться, пока не охватит все существенные случаи развертывания в среде (в разумных пределах).
Полнота данных означает степень изменения данных для тестирования. Ее можно увеличивать, создавая больше записей. Часто этого достаточно, но фактически нам требуется видеть изменения данных, с которыми можно встретиться в реальной ситуации. Без этого в тестировании можно упустить из виду какие-либо ошибки, да и не все ограничиваются получением строго $40.00 из банкомата. Поэтому в тесте нужно учесть вариацию данных в реальной среде, например, получение $20.00 или $110.00. Кроме того, данные должны учитывать возможные вариации фактических данных, например:
Значения тестовых данных могут содержать выбору физических или статистических данных на основе реальных данных. Оба метода имеют свою ценность и рекомендуются к использованию.
Для того чтобы создать данные для тестирования на основе физических данных, определите допустимый диапазон значений для каждого элемента и убедитесь в том, что для каждого такого элемента в тестовых данных содержится хотя бы одна запись с допустимыми значениями.
Пример:
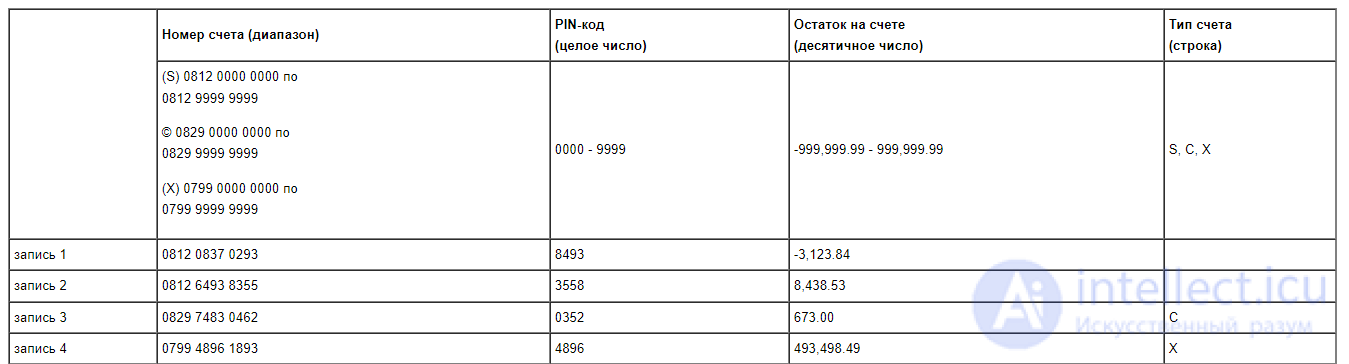
Эта таблица содержит минимальное число записей, которые могли бы представлять допустимые значения данных. Для каждого из трех диапазонов номеров счетов присутствует одна запись, все PIN-коды входят в допустимый диапазон, есть несколько вариантов остатка на счете, включая и отрицательный, и записи охватывают все три типа счета. Эта таблица содержит минимальное число данных, и ее можно улучшить, добавив значения на границе каждого из диапазонов и внутри диапазона -
Преимущество физического представления состоит в том, что данные тестов ограничены по объему, ими легко управлять, и они содержат допустимые значения. Недостаток заключается в том, что не отражены статистические тенденции реальных данных. Реальные данные обычно статистически неоднородны, и их тенденции могут влиять на производительность. Это фактор не будет учитываться при работе с физическим представлением.
Статистический подход к созданию данных для тестирования отражает особенности данных, с которыми работает реальная система. Например, можно проанализировать базу данных рабочей системы и выявить следующее:
с учетом этой статистики тестовые данные могли бы включать 294 записи (а не 4, как раньше):

Эта таблица отражает только типы счетов. При статистическом подходе к созданию данных для тестирования следует включить значимые элементы данных. В этом примере это могло бы означать учет фактических остатков на счете.
Недостатком статистического подхода будет то, что данные могут не отражать весь диапазон допустимых значений.
Обычно применяется сочетание обоих методов, и тестовые данные включают значения, отражающие как аспект производительности, так и аспект полноты.
Понятие полноты тестовых данных относится и к тестовым данным, которые применяются как входные данные для теста, и тем, которые применяются как вспомогательные к уже имеющимся данным.
Охват - это применимость тестовых данных для цели теста. Она связана с объемом и полнотой данных. Большое число данных не означает, что среди них обязательно есть нужные данные. Как и в том, что касается полноты тестовых данных, мы должны убедиться, что данные отвечают цели теста, то есть приведет ли выполнение теста к ответу на поставленные вопросы.
Например, в следующей таблице первые четыре записи содержат допустимые значения для каждого элемента данных. Однако для счетов типа C и X нет записей с отрицательным остатком. Поэтому, хотя эти тестовые данные и включают запись с отрицательным остатком (приемлемая полнота), но их было бы недостаточно для тестирования отрицательных остатков для всех типов счета (недостаточный охват). Это упущение преодолевается тем, что в данные добавляются записи, содержащие отрицательный остаток для двух других типов счетов.
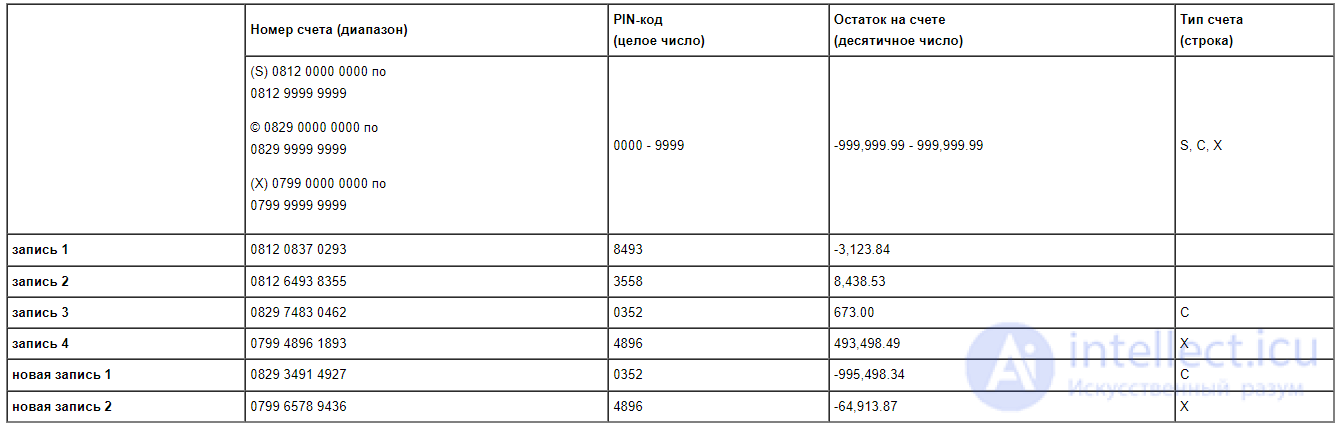
Понятие охвата тестовых данных относится и к тестовым данным, которые применяются как входные данные для теста, и тем, которые применяются как вспомогательные к уже имеющимся данным.
Понятие физической структуры тестовых данных относится только к тестовым данным, которые применяются как вспомогательные к уже имеющимся данным, например, в базе данных или таблице правил.
Тестирование - это не процесс, который происходит только один раз. Тестирование повторяется и в итерациях, и между ними. Для того чтобы тестирование было точным, достоверным и эффективным, тестовые данные следует вернуть в исходное состояние перед выполнением теста. Это особенно важно для автоматизированных тестов.
Точность, достоверность и эффективность тестирования достигаются тогда, когда тестовые данные не зависят от внешних факторов, и их состояние известно до, во время и после выполнения теста. Для достижения этой цели необходимо решить две проблемы:
Все эти вопросы влияют на работу с базой данных для тестирования, проектирование модели тестирования и взаимодействие с другими объектами.
Неустойчивость тестовых данных может возникнуть по следующим причинам:
Для того чтобы тестирование было достоверным и полным, тестовые данные должны быт полностью изолированы от таких воздействий. Для этого применяются следующие способы:
Важным вопросом в архитектуре тестовых данных является состояние данных в начале теста. Это особенно важно при автоматизации тестирования. И сам объект тестирования, и тестовые данные должны быть в нужном, контролируемом состоянии. При этом возникает возможность достичь повторяемости результатов тестирования и уверенности в достоверности тестов.
Для решения этого вопроса обычно применяются четыре стратегии:
Подробнее все они описаны далее.
Фактический метод будет зависеть от разных факторов, включая физические особенности базы данных, техническую компетентность участников тестирования, доступность внешних ролей (не относящихся к тесту), и сам целевой объект тестирования.
Предпочтительный способ возвращения данных в исходное состояние - это обновление данных. При этом создается копия базовых данных в их исходном состоянии. По завершении выполнения теста (или перед его началом) копия тестовых данных помещается в среду тестирования. Таким образом обеспечивается тождественность тестовых данных перед началом теста.
В этом методе данные можно сохранить для разных начальных состояний. Например, тестовые данные могут включать архивы для состояния в конце дня, конце недели, конце месяца и пр. При этом участник тестирования может быстро восстановить состояние любого теста, например, теста варианта использования, отвечающего концу месяца.
Если данные нельзя обновить, то следующим способом может быть восстановление исходного состояния данных с помощью какой-либо программы. Повторно инициализировать данные можно для каких-либо вариантов использования с помощью инструментов, восстанавливающих начальное значение тестовых данных.
При этом нужно особенно внимательно следить за тем, чтобы в данные, их отношения и ключевые значения не вкрались никакие ошибки.
Одним из преимуществ этого метода может быть тестирование с недопустимыми значениями из базы данных. В обычных условиях база данных не содержит недопустимых значений, потому что их не разрешается туда вводить (например, это запрещает правило проверки в клиенте). Однако данные могут быть изменены другим способом (например, при обновлении из другой системы). При тестировании необходимо убедиться, что недопустимые данные будут распознаваться и обрабатываться правильно, независимо от того, как они возникли.
Простым методом восстановления исходного состояния данных может быть "обращение изменений", вносимых в данные в ходе тестирования. Этот метод опирается на возможность целевого объекта отменять изменения, то есть добавлять удаленные данные и восстанавливать значения измененных данных.
Этот метод содержит и соответствующие риски, а именно:
Если этот метод единственно доступен в вашей среде, то не применяйте ключи, индексы и указатели в базе данных как средства проверки. Так, для определения того, был ли пациент записан в базу данных, используйте его имя, а не ИД пациента, генерируемый системой.
Этот способ наименее приемлем для восстановления начального состояния тестовых данных. Фактически он не решает этот вопрос. Вместо этого состояние данных по завершении выполнения какого-либо теста становится начальным состоянием тестовых данных для другого теста. Обычно при этом требуется внести изменения в входные данные для теста и/или в варианты использования и тестовые данные, применяемые для анализа результатов.
В некоторых случаях такой подход является необходимым, например, в конце месяца. Если архив данных на конец месяца отсутствует, то тестовые данные и тестовые сценарии для каждого дня месяца необходимо "прокрутить вперед", чтобы привести данные в состояние, пригодное для теста в конце месяца.
С этим методом связаны следующие риски:
Класс эквивалентности — часть области входных или выходных данных, для которой поведение компонента или системы считается одинаковым.
Класс эквивалентности – это набор тестов, от выполнения которых ожидается один и тот же результат. В простейшем случае тест представляет собой набор входных данных, вводимых в тестируемую программу. В случае эквивалентных тестов эти данные обладают общими свойствами.
Группа тестов представляет собой класс эквивалентности, если выполняются следующие условия:
Необходимо стремиться выявить как можно больше классов эквивалентности. Это сэкономит время тестирования и сделает тестирование более эффективным, избавив тестировщика от повторения эквивалентных тестов. Разбив все предполагаемые тесты на классы, можно затем выделить в каждом из них один или несколько наиболее эффективных тестов; остальные тесты выполнять незачем.
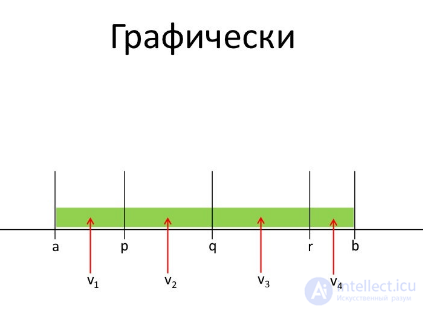
Пример Система просит ввести в поле арабскую цифру. Класс эквивалентности = [0,1,2,3,4,5,6,7,8,9] Чтобы проверить правильность, достаточно взять один элемент, например, 4.
Граничные значения Очень часто проблемы возникают, если ввести значения на границах классов эквивалентности. Граничное значение — входное значение, которое находится на грани эквивалентной области или на наименьшем расстоянии от обеих сторон грани, например, минимальное или максимальное значение области.
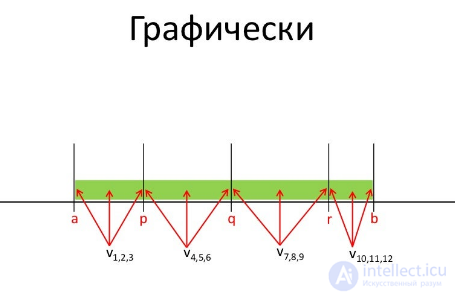
пример Граничные значения Для возраста совершеннолетия граничные значения — 17 и 18. В 17 еще не совершеннолетний, а в 18 — уже.
Обычно для системы (за исключением самых простых приложений) невозможно протестировать все логически возможные входные комбинации. Поэтому одна из важнейших задач для разработчиков - выбрать для тестирования те комбинации, где с наибольшей вероятностью можно найти большинство ошибок.
Тестирование, основанное на анализе классов эквивалентности (синонимы: разбиение на области эквивалентности, анализ области) - это анализ тестирования методом "черного ящика". Цель анализа - сократить до минимума общее число циклов тестирования и обнаружить при этом максимальное возможное количество ошибок . Этот метод позволяет разделить ряд входных и выходных данных на конечное число классов эквивалентности и выбрать характерное тестовое значение для каждого класса. Результаты тестирования характерного значения класса считаются "эквивалентными" другим значениям того же класса. Если при тестировании характерного значения ошибки не были найдены, предполагается, что все другие "эквивалентные" значения также не будут содержать ошибки.
невалидные значения
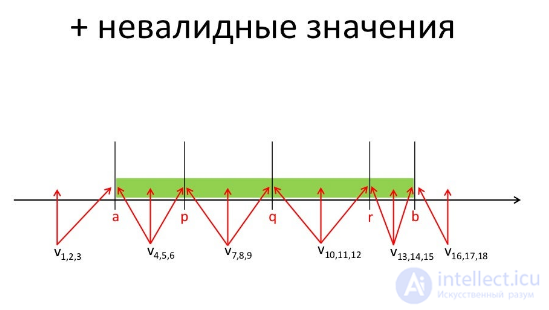
Невалидный - значит недействующий, некорректный, неправильный, несоответствующий требованиям. Например: Невалидный e-mail означает, что адрес имеет неверный формат, состоит из неправильных символов внеправильной последовательности
Преимущество анализа классов эквивалентности в том, что он позволяет придерживаться выборочной стратегии и сокращать объем комбинаторного взрыва потенциально необходимых тестов. Это метод позволяет вывести логические критерии выбора отдельных тестов из всех возможных тестов. Ниже перечислены области, где требуется проведение большого количества тестов, и где применение классов эквивалентности могло бы облегчить работу:
Существуют разные стратегии и методы для проведения тестирования с разбиением на классы эквивалентности. Некоторые примеры приведены ниже:
Теория разбиения на классы эквивалентности, предложенная Гленфордом Майерсом (Glenford Myers) [MYE79], направлена на сокращение общего числа необходимых тестовых сценариев путем разбиения входных условий на конечное число классов эквивалентности. Создается два типа классов: допустимые входные данные программы рассматриваются как допустимый класс эквивалентности, а все остальные входные данные заносятся в недопустимый класс эквивалентности.
Ниже приведены рекомендации по определению классов эквивалентности:
Для каждого класса эквивалентности предполагается, что граничные условия позволяют с большей вероятностью найти ошибки, чем остальные условия. Граничными условиями считаются ближайшие значения, стоящие с обеих сторон крайних значений, определяющих границы класса.
При тестировании граничных условий из тестируемого диапазона выбираются следующие значения: минимальное значение (min), значение, на одно больше минимального (min+), значение, на одно меньше максимального (max-), и максимальное значение (max). В этом случае разработчики выбирают несколько тестовых сценариев для каждого класса эквивалентности. При относительно небольшом количестве тестов велика вероятность обнаружения ошибок. Разработчикам не приходится тестировать огромное количество значений, для которых результаты тестирования незначительно отличаются друг от друга.
Рекомендации по выбору граничных значений:
-1.0 до 1.0, протестируйте значения -1.0, 1.0, -1.001 и 1.001.10 до 100, протестируйте 9, 10, 100, 101.@ и [, потому что в коде ASCII символ @ предшествует A, а символ [ следует сразу за Z.n), протестируйте программу, где сумма равна n-1, n или n+1.-0.01 и b +0.01.После применения двух указанных выше стратегий анализа граничных значений рекомендуется исследовать программу на наличие "специальных значений", с помощью которых можно обнаружить множество ошибок. Некоторые примеры приведены ниже:
Перечень классов эквивалентности лучше организовать в виде таблицы. Обычно классов эквивалентности оказывается много, поэтому нужен удобный и продуманный способ организации собранной информации. Пример перечня классов эквивалентности:
|
Входное событие |
Допустимые классы эквивалентности |
Недопустимые классы эквивалентности |
|
Ввод числа |
Числа от 1 до 99 |
Число 0 Числа больше 99 Выражение, результатом которого является недопустимое число (например: 5 – 5 = 0) Отрицательные числа Буквы и др. нечисловые символы |
|
Ввод первой буквы наименования |
Заглавная буква Прописная буква |
Не буква |
Для каждого класса эквивалентности достаточно провести один-два теста. Лучшими из них будут те, которые проверяют значения, лежащие на границах класса. Неправильные операторы сравнения (например, > вместо ≥) вызывают ошибки только при граничных значениях аргументов. В то же время программа, которая сбоит при промежуточных значениях диапазона, почти наверняка будет сбоить и при его граничных значениях.
Необходимо протестировать каждую границу класса эквивалентности с обеих сторон. Программа, которая пройдет эти тесты, скорее всего, пройдет и все остальные, относящиеся к данному классу.
Остранд и Болсер (Ostrand and Balcer) разработали метод разбиения, который позволяет испытателям анализировать спецификацию системы, создавать тестовые сценарии и управлять ими. Если большинство стратегий сфокусированы на работе с исходным кодом, метод Остранда и Болсера также предполагает использование данных спецификации и проектирования.
Главное преимущество этого метода в том, что он позволяет обнаруживать ошибки еще до создания кода, потому что источником ввода является спецификация, и тестирование основано на ее анализе. Недоработки в спецификациях можно обнаружить на ранних стадиях, часто до ее реализации в коде.
Ниже перечислены шаги для применения метода "разбиение на категории":
Примеры нахождения классов эквивалентности и границ разбиения для тестовых данных
Исследование, описанное в статье про тестовые данные, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое тестовые данные и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Качество и тестирование программного обеспечения. Quality Assurance.
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

Комментарии