Лекция
Сразу хочу сказать, что здесь никакой воды про кодирование текстовой информации, и только нужная информация. Для того чтобы лучше понимать что такое кодирование текстовой информации, алгоритм хаффмана , настоятельно рекомендую прочитать все из категории Информатика.
Текстовую информацию кодируют двоичным кодом через обозначение каждого символа алфавита определенным целым числом. С помощью восьми двоичных разрядов возможно закодировать 256 различных символов. Данного количества символов достаточно для выражения всех символов английского и русского алфавитов.
В первые годы развития компьютерной техники трудности кодирования текстовой информации были вызваны отсутствием необходимых стандартов кодирования. В настоящее время, напротив, существующие трудности связаны с множеством одновременно действующих и зачастую противоречивых стандартов.
Для английского языка, который является неофициальным международным средством общения, эти трудности были решены. Институт стандартизации США выработал и ввел в обращение систему кодирования ASCII (American Standard Code for Information Interchange – стандартный код информационного обмена США).
Для кодировки русского алфавита были разработаны несколько вариантов кодировок:
1) Windows-1251 – введена компанией Microsoft; с учетом широкого распространения операционных систем (ОС) и других программных продуктов этой компании в Российской Федерации она нашла широкое распространение;
2) КОИ-8 (Код Обмена Информацией, восьмизначный) – другая популярная кодировка российского алфавита, распространенная в компьютерных сетях на территории Российской Федерации и в российском секторе Интернет;
3) ISO (International Standard Organization – Международный институт стандартизации) – международный стандарт кодирования символов русского языка. На практике эта кодировка используется редко.
Ограниченный набор кодов (256) создает трудности для разработчиков единой системы кодирования текстовой информации. Вследствие этого было предложено кодировать символы не 8-разрядными двоичными числами, а числами с большим разрядом, что вызвало расширение диапазона возможных значений кодов. Система 16-разрядного кодирования символов называетсяуниверсальной – UNICODE. Шестнадцать разрядов позволяет обеспечить уникальные коды для 65 536 символов, что вполне достаточно для размещения в одной таблице символов большинства языков.
Несмотря на простоту предложенного подхода, практический переход на данную систему кодировки очень долго не мог осуществиться из-за недостатков ресурсов средств вычислительной техники, так как в системе кодирования UNICODE все текстовые документы становятся автоматически вдвое больше. В конце 1990-х гг. технические средства достигли необходимого уровня, начался постепенный перевод документов и программных средств на систему кодирования UNICODE.
Вспомним некоторые известные нам факты:Множество символов, с помощью которых записывается текст, называется алфавитом. Число символов в алфавите – это его мощность. Формула определения количества информации: N = 2b, где N – мощность алфавита (количество символов), b – количество бит (информационный вес символа). В алфавит мощностью 256 символов можно поместить практически все необходимые символы. Такой алфавит называется достаточным. Т.к. 256 = 28, то вес 1 символа – 8 бит. Единице измерения 8 бит присвоили название 1 байт: 1 байт = 8 бит. Двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти. Каким же образом текстовая информация представлена в памяти компьютера?
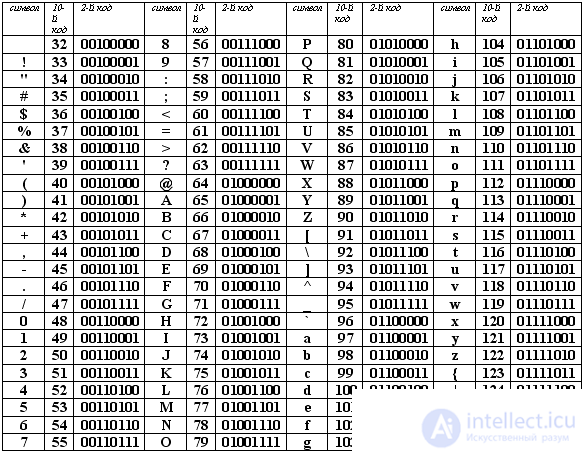
Удобство побайтового кодирования символов очевидно, поскольку байт - наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации. Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу.Понятно, что это дело условное, можно придумать множество способов кодировки. Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления. Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.Для разных типов ЭВМ используются различные таблицы кодировки. Международным стандартом для ПК стала таблица ASCII (читается аски) (Американский стандартный код для информационного обмена). Таблица кодов ASCII делится на две части. Международным стандартом является лишь первая половина таблицы, т.е. Об этом говорит сайт https://intellect.icu . символы с номерами от 0 (00000000), до 127 (01111111). Структура таблицы кодировки ASCII
Первая половина таблицы кодов ASCII
Обращаю ваше внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита. Для букв русского алфавита также соблюдается принцип последовательного кодирования. Вторая половина таблицы кодов ASCII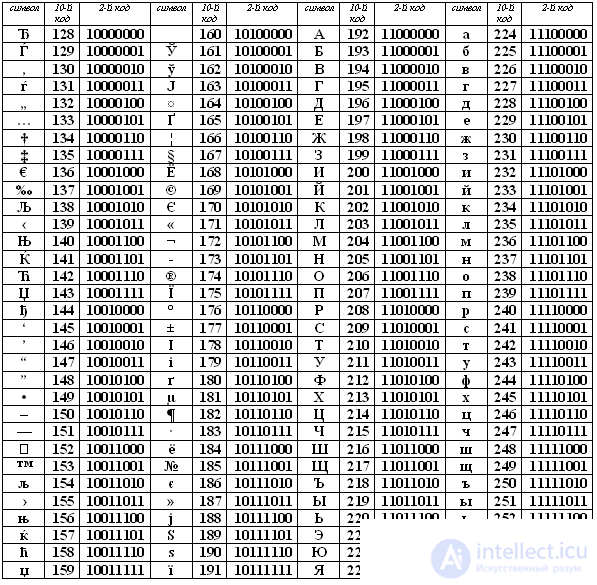
К сожалению, в настоящее время существуют пять различных кодировок кириллицы (КОИ8-Р, Windows. MS-DOS, Macintosh и ISO). Из-за этого часто возникают проблемы с переносом русского текста с одного компьютера на другой, из одной программной системы в другую. Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ8 ("Код обмена информацией, 8-битный"). Эта кодировка применялась еще в 70-ые годы на компьютерах серии ЕС ЭВМ, а с середины 80-х стала использоваться в первых русифицированных версиях операционной системы UNIX. От начала 90-х годов, времени господства операционной системы MS DOS, остается кодировка CP866 ("CP" означает "Code Page", "кодовая страница"). Компьютеры фирмы Apple, работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac. Кроме того, Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5. Наиболее распространенной в настоящее время является кодировка Microsoft Windows, обозначаемая сокращением CP1251. С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode. Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов. Попробуем с помощью таблицы ASCII представить, как будут выглядеть слова в памяти компьютера.Внутреннее представление слов в памяти компьютера
Иногда бывает так, что текст, состоящий из букв русского алфавита, полученный с другого компьютера, невозможно прочитать - на экране монитора видна какая-то "абракадабра". Это происходит оттого, что на компьютерах применяется разная кодировка кирилистических символов . |
Проблема использования таких различных таблиц приводила к тому, что текст, написанный на одном компьютере, мог некорректно читаться на другом. Например:
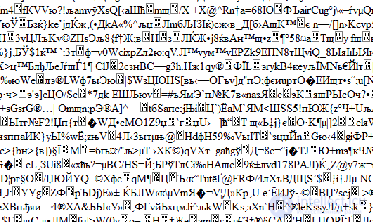
Поэтому была разработана международная таблица кодировки Unicode, включающая в себя как символы английского, русского, немецкого, арабского и других языков. На каждый символ в такой таблице отводится 16 бит, то есть она позволяет кодировать 65536 символов. Однако использование такой таблицы сильно «утяжеляет» текст. Поэтому существуют различные алгоритмы неравномерной кодировки текста, например, алгоритм хаффмана .
АЛГОРИТМ ХАФФМАНА
Идея алгоритма Хаффмана основана на частоте появления символа в последовательности. Символ, который встречается в последовательности чаще всего, получает новый очень маленький код, а символ, который встречается реже всего, получает, наоборот, очень длинный код.
Пусть нам дано сообщение aaabcbeeffaabfffedbac.
Чтобы узнать наиболее выгодный префиксный код для такого сообщения, надо узнать частоту появления каждого символа в сообщении.
Шаг 1.
Подсчитайте и внесите в таблицу частоту появления каждого символа в сообщении:
У вас должно получиться:
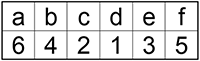
Шаг 2.
Расположите буквы в порядке возрастания их частоты.
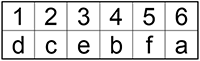
Шаг 3.
Теперь возьмем два символа с наименьшей чистотой и представим их листьями в дереве, частота которого будет равна сумме частот этих листьев.
Символы d и c превращаются в ветку дерева:
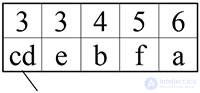
Шаг 4.
Проделываем эти шаги до тех пор, пока не получится дерево, содержащее все символы.
Итак, сортируем таблицу:
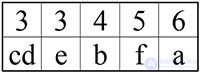
Шаг 5.
Объединяем символ e и символ cd в ветку дерева:
d
C
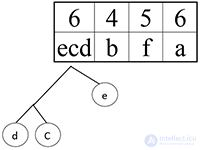
Шаг 6.
Сортируем:
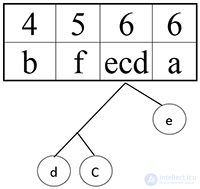
Шаг 7.
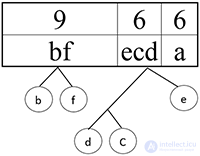
Шаг 8.
Сортируем:
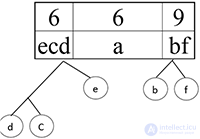
Шаг 9.
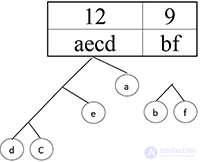
Шаг 10.
Сортируем:
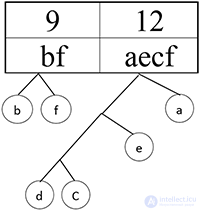
Шаг 11.
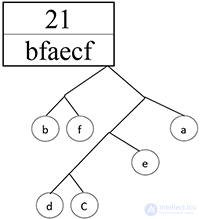
Шаг 12.
Получился префиксный код. Теперь осталось расставить 1 и 0. Пусть каждая правая ветвь обозначает 1, а левая — 0.
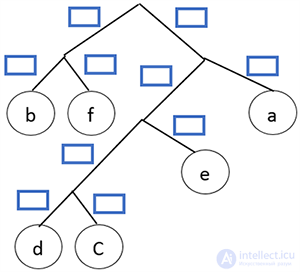
Шаг 13.
Составляем код буквы, идя по ветке дерева от буквы к основанию дерева.
Тогда код для каждой буквы будет:
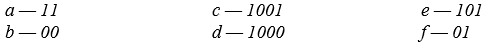
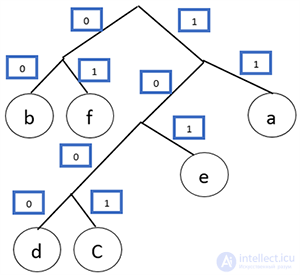
Задание №1
Закодируйте ASCII кодом слово MOSCOW.
Решение:
Составим таблицу и поместим туда слово MOSCOW. Используя таблицу ASCII кодов, закодируем все буквы слова:
|
M |
O |
S |
C |
O |
W |
|
1001101 |
1001111 |
1010011 |
1000011 |
1001111 |
1110111 |
ОТВЕТ: 100110110011111010011100001110011111110111
Задание №2
Используя табличный код Windows1251, закодируйте слово КОМПЬЮТЕР.
Решение:
|
К |
О |
М |
П |
Ь |
Ю |
Т |
Е |
Р |
|
234 |
206 |
204 |
239 |
252 |
254 |
242 |
197 |
208 |
Ответ: 234206204239252254242197208
Задание №3
Используя алгоритма Хаффмана, закодируйте сообщение: Россия
Решение:
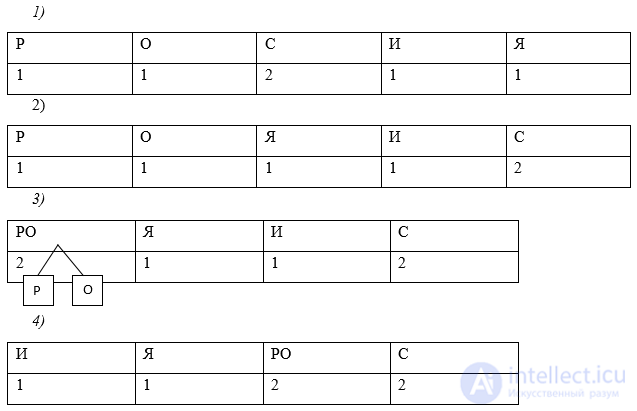
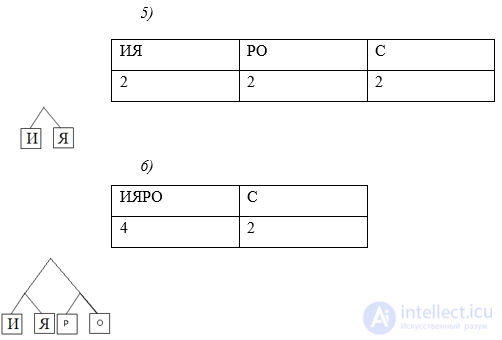
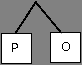
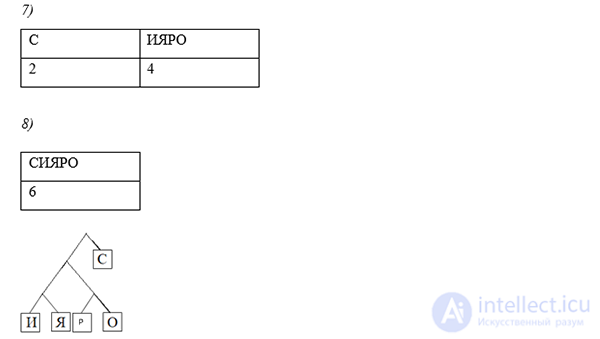
Давайте все левые ветви обозначим «1», а правые – «0»
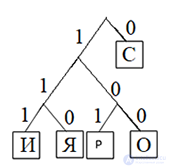
Таким образом: С — 0, Р — 101, О — 100, И — 111, Я — 110
ОТВЕТ: 10110000111110
Пожалуйста, пиши комментарии, если ты обнаружил что-то неправильное или если ты желаешь поделиться дополнительной информацией про кодирование текстовой информации Надеюсь, что теперь ты понял что такое кодирование текстовой информации, алгоритм хаффмана и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Информатика

Комментарии