Лекция
Привет, Вы узнаете о том , что такое методы передачи данных, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое методы передачи данных, rest архитектура, cgi приложения, rest api, hateoas, методы http-запросов, oauth, communication endpoint , настоятельно рекомендую прочитать все из категории Выполнение скриптов на стороне сервера PHP (LAMP) NodeJS (Backend) .
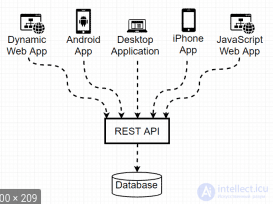
REST — это стиль архитектуры программного обеспечения для построения распределенных масштабируемых веб-сервисов. Рой выступал за использование стандартных HTTP методов так, чтобы придавать запросам определенный смысл.
REST (сокр. от англ. Representational State Transfer — «передача состояния представления») — архитектурный стиль взаимодействия компонентов распределенного приложения в сети. REST представляет собой согласованный набор ограничений, учитываемых при проектировании распределенной гипермедиа-системы. В определенных случаях (интернет-магазины, поисковые системы, прочие системы, основанные на данных) это приводит к повышению производительности и упрощению архитектуры. В широком смысле компоненты в REST взаимодействуют наподобие взаимодействия клиентов и серверов во Всемирной паутине. REST является альтернативой RPC .
1) лучше использовать простой минимальный и типичный и стандартный путь / запрос REST API для
1.1 получение каждого списк должен выполняться так:
GET {base_url}/v1/categories
GET {base_url}/v1/items
с параметрами фильтров и не использовать слова внутри путей (все, фильтр и т. д.)
каждый endpoint со списком может состоять из параметров фильтров или затребуемых полей (если испольуются - то нужно их описать)
1.2 для получеания одной сущности :
GET {base_url}/v1/item/{id}
для создания
POST {base_url}/v1/item + params
для обновления
PUT/PATCH /{base_url}/v1/item/{id} + params
для удаления
DELETE {base_url}/v1/item/{id}
2) каждый ответ (респонс) от сервера должен быть типовым:
2.1 если возвращаемые данные - список
{
"items/or/data" : [ …. list of entities
{"id":1, name:"intellect.icu"} ,
{…}
],
"page" : 1,
"total/or/totalpage” :12
}
2.2 если возвращается одна сущность
{
"id":1,
"name":"intellect.icu" ...
}
2.3 если возвращается сложный зависимый список (это очень редко но возможно)
{
"items/or/data" : [ …. list of entities
{"id":1, name:"intellect.icu",
"sublist":["item1","item2"]} ,
{…}
],
"page" : 1,
"total/or/totalpage” :12
}
3. все ошибки валидации должны иметь одинаковаую структуру
HTTP код 422 и тело ответа:
{
"message": "Could not to add a new item.",
"errors": {
"name_field1": ["The text message for this field."],[...],
"name": ["The name is required"]
}
}
В сети Интернет вызов удаленной процедуры может представлять собой обычный HTTP-запрос (обычно «GET» или «POST»; такой запрос называют «REST-запрос»), а необходимые данные передаются в качестве параметров запроса.

Для веб-служб, построенных с учетом REST (то есть не нарушающих накладываемых им ограничений), применяют термин «RESTful».
В отличие от веб-сервисов (веб-служб) на основе SOAP, не существует «официального» стандарта для RESTful веб-API. Дело в том, что REST является архитектурным стилем, в то время как SOAP является протоколом. Несмотря на то, что REST не является стандартом сам по себе, большинство RESTful-реализаций используют стандарты, такие как HTTP, URL, JSON и XML.
Взаимодействие REST API осуществляется через endpoint.
Communication endpoint Конечная точка связи является типом сети связи узла . Это интерфейс, предоставляемый взаимодействующей стороной или каналом связи. Примером последнего типа конечной точки связи является тема Publish–subscribe (публикации-подписки) или группа в системах групповой связи .


Рой Филдинг предложил использовать Web не только для общения между человеком и машиной, но и для общения между машинами.REST задуман так, что если правильно применять, то можно построить приложение (с API), которое будет работать и масштабироваться веками.. Здесь нет ни слова об API, HTTP или красивых URL. однако на практике расширяют это понятие на прмере api, url, методов.
Таким образом, данные HTTP-запросы будут иметь различный смысловую нагрузку в REST:
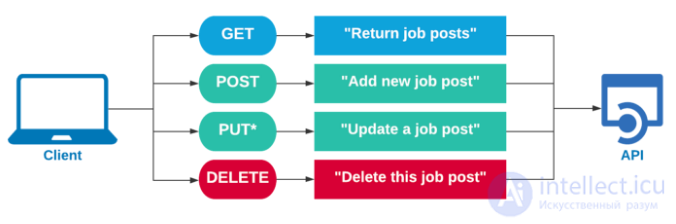
Выше только некоторые виды запросов, а вот весь их список: CONNECT, DELETE, GET, HEAD, OPTIONS, PATCH, POST, PUT, TRACE.

Итак, одна транзакция по RESTful API будет состоять, как минимум, из следующего:
Задумаемся на минуту, что же происходит, когда мы набираем в браузере строку somestring и нажимаем . Браузер посылает серверу запрос somestring? Нет, конечно. Все немного сложнее. Он анализирует строку, выделяет из нее имя сервера и порт (а также имя протокола, но нам это сейчас не интересно), устанавливает соединение с Web-сервером по адресу сервер:порт и посылает ему что-то вроде следующего:
GET somestring HTTP/1.0\n
...другая информация...
\n\n
Здесь \n означает символ перевода строки, а \n\n — два обязательных символа новой строки, которые являются маркером окончания запроса (точнее, окончания заголовков запроса). Пока мы не пошлем этот маркер, сервер не будет обрабатывать наш запрос.
Как видим, после GET-строки могут следовать и другие строки с информацией, разделенные символом перевода строки. Их обычно формирует браузер. Такие строки называются заголовками (headers), и их может быть сколько угодно. Протокол HTTP как раз и задает правила формирования и интерпретации этих заголовков. Вот мы и начинаем знакомство с протоколом HTTP. Как видите, он представляет собой ни что иное, как просто набор заголовков, которыми обмениваются сервер и браузер, и еще пару соглашений насчет метода POST, которые мы вскоре рассмотрим.
Не все заголовки обрабатываются сервером — некоторые просто пересылаются запускаемому сценарию с помощьюпеременных окружения.
Переменные окружения представляют собой именованные значения параметров, которые операционная система (точнее, процесс-родитель) передает запущенной программе. Программа может с помощью специальных функций получить значение любой установленной переменной окружения, указав ее имя. Именно так и должен поступать CGI-сценарий, когда захочет узнать значение того или иного заголовка запроса. К сожалению, набор передаваемых сценарию заголовков ограничен стандартами, и некоторые заголовки нельзя получить из сценария никаким способом (ему просто недоступна соответствующая переменная окружения). Такие случаи мы будем оговаривать особо.
Ниже приводятся некоторые заголовки запросов с их описаниями, а также имена переменных окружения, которые использует сервер для передачи их CGI-сценарию.
Метод запроса GET
Формат запроса: GET сценарий?параметры HTTP/1.0
>>> Переменные окружения: REQUEST_URI; в переменной QUERY_STRING сохраняется значение и параметры, в переменной REQUEST_METHOD — ключевое слово GET.
Этот заголовок является обязательным (если только не применяется метод POST) и определяет адрес запрашиваемого документа на сервере. Также задаются параметры, которые пересылаются сценарию (если сценарию ничего не передается, или же это обычная статическая страница, то все символы после знака вопроса и сам знак опускаются). Вместо строки HTTP/1.0 может быть указан и другой протокол - например, HTTP/1.1. Именно его соглашения и будут учитываться сервером при обработке данных, поступивших от пользователя, и других заголовков.
Строка сценарий?параметры задается в том же самом формате, в котором она входит в URL. Неплохо было бы назвать эту строку как-нибудь более реалистично, чтобы учесть возможность присутствия в ней командных параметров. Такое название действительно существует и звучит как URI (Universal Resource Identifier - Универсальный идентификатор ресурса). Очень часто его смешивают с понятием URL (вплоть до того, что это происходит даже в официальной документации по стандартам HTTP). Под словом URL мы понимаем полный путь к некоторой Web-странице вместе с параметрами, а URI - это его часть, расположенная после имени (или IP-адреса) хоста и номера порта.
Метод запроса POST
Формат запроса: POST сценарий?параметры HTTP/1.0
>>> Переменная окружения: REQUEST_URI; в переменной QUERY_STRING сохраняется значение и параметры, в переменной REQUEST_METHOD — слово POST.
Настал момент рассмотреть метод POST. Приведем сразу практический пример метода запроса POST:
POST /script.cgi HTTP/1.0\n
Content-length: 8\n
\n
Hello!!!
Сервер начнет обработку запроса, не дожидаясь передачи данных после маркера конца заголовков. Иными словами, сценарий запустится сразу же после отправки \n\n, а уж ждать или не ждать, пока придет строка Hello! длиной 6 байт - его дело. Последнее означает, что сервер никак не интерпретирует POST-данные (точно так же, как он не интерпретирует некоторые заголовки), а пересылает их непосредственно сценарию. Но как же сценарий узнает, когда данные кончаются, т. е. когда ему прекращать чтение информации, поступившей от браузера? В этом ему поможет переменная окружения Content-Length, и именно на нее следует ориентироваться.
Зачем нужен метод POST? В основном для того, чтобы передавать большие объемы данных. Например, при загрузке файлов через Web или при обработке больших форм. Кроме того, метод POST часто используют для эстетических целей: дело в том, что при применении GET, как вы, наверное, уже заметили, URL сценария становится довольно длинным и неизящным. Переданные сценарию параметры не отображаются в окне браузера, POST-запрос оставляет URL без изменения.
Архитектура REST описывается шестью ограничениями. Эти ограничения, применительно к архитектуре, первоначально были представлены Роем Филдингом (Roy Fielding) в его докторской диссертации и определяют основы RESTful стиля.
Шесть ограничений:
Единый интерфейс определяет интерфейс между клиентами и серверами. Это упрощает и отделяет архитектуру, которая позволяет каждой части развиваться самостоятельно. Четыре принципа единого интерфейса:
Отдельные ресурсы определяются в запросе, для чего используется URI, как идентификаторы ресурсов. Сами ресурсы концептуально отделены от представлений, которые возвращаются клиенту. Например, сервер не отправляет свою базу данных, а, скорее, некоторые HTML, XML или JSON, которые представляет некоторые записи в базе данных, например, на финском языке и в UTF-8, в зависимости от деталей запроса и реализации сервера.
Когда пользователь имеет представление о ресурсе, в том числе о связанных метаданных, он имеет достаточно информации для изменения или удаления ресурса на сервере, если у него есть на это разрешение
Каждое сообщение содержит достаточно информации для описания того, как его выполнить. Например, вызываемый парсер может описываться с помощью Internet media type (так же известным как MIME) Ответы также явно указывают на их способность кешировать.
Клиенты предоставляют статус через содержимое body, параметры строки запроса, заголовки запросов и запрашиваемый URI (имя ресурса). Это называется гипермедиа (или гиперссылки с гипертекстом)
Наряду с приведенным выше описанием, HATEOS также означает, что, в случае необходимости ссылки содержатся в теле ответа (или заголовках) для поддержки URI извлечения самого объекта или запрошенных объектов. Об этом говорит сайт https://intellect.icu . Позднее, мы затронем эту тему глубже.
Единый интерфейс так же означает, что любой REST сервис должен обеспечивать его фундаментальный дизайн.
Так как REST это акроним для REpresentational State Transfer, отсутствие состояний является важной чертой. Таким образом, это значит, что необходимое состояние для обработки запроса содержится в самом запросе, либо в рамках URI, параметрах строки запроса, тела или заголовках. URI уникально идентифицирует ресурс и тело содержит состояние (или изменение состояния) этого ресурса. Затем, после того, как сервер завершит обработку, состояние или его часть(и) отдается обратно клиенту через заголовки, статус и тело ответа.
Большинство из нас, кто был в этой отрасли, привыкли к программированию в контейнере, который дает нам понятие "Сессия, которая поддерживает состояние нескольких HTTP запросов. В REST, клиент должен включать всю информация для сервера для выполнения запроса, перепосылая состояние по необходимости, если это состояние должно охватывать несколько запросов. Отсутствие состояний обеспечивает большую масштабируемость, так как сервер не должен поддерживать или общаться через состояние сеанса. Кроме того, балансировщику нагрузки не придется беспокоиться о связанности сессии и системы.
Так в чем различие между состоянием и ресурсом? Состояние или состояние приложения, это то, что сервер заботится выполнить запрос для получения данных необходимых для текущей сессии или запроса. Ресурсное состояние, или ресурс, это данные, которые определяют представление ресурса, например, данные хранящиеся в базе данных. Рассмотрим состояние приложения как данные, которые могут варьироваться в зависимости от клиента и запроса. С другой стороны, состояние ресурсов постоянно по каждому клиенту, который запрашивает его.
Каждый встречал проблему с кнопкой "Назад" в своем веб приложении, когда оно ведет себя по разному в одной точке, потому что ожидались действия в определенном порядке? Такое происходит, когда нарушен принцип отсутствия состояний. Есть случаи, когда не соблюдается принцип отсутствия состояний, например, three-legged OAuth, ограничение скорости вызова API и т.д. Однако, приложите максимум усилий, чтобы состояние приложения не занимало несколько запросов к вашему сервису.
Как и в World Wide Web, клиент может кэшировать ответы. Таким образом, ответы явно или неявно определяют себя как кешируемые или нет, для предотвращения повторного использования клиентами устаревших или некорректных данных в ответ на дальнейшие запросы. Хорошо спроектированное кэширование частично или полностью устраняет некоторые клиент-серверные взаимодействия, способствуя дальнейшей масштабируемости и производительности.
Единый интерфейс отделяет клиентов от серверов. Разделение интерфейсов означает, что, например, клиенты не связаны с хранением данных, которое остается внутри каждого сервера, так что мобильность кода клиента улучшается. Серверы не связаны с интерфейсом пользователя или состоянием, так что серверы могут быть проще и масштабируемы. Серверы и клиенты могут быть заменяемы и разрабатываться независимо, пока интерфейс не изменяется.
Обычно клиенты не могу сказать - они подключены напрямую к серверу или общаются через посредника. Промежуточный сервер может улучшить масштабируемость системы, обеспечивая балансировку нагрузки и предоставляя общий кэш. Слои также могут отвечать за политику безопасности.
Серверы могут временно расширять или кастомизировать функционал клиента, передавая ему логику, которую он может исполнять. Например, это могут быть скомпилированные Java-апплеты или клиентские скрипты на Javascript
Филдинг указывал, что приложения, не соответствующие приведенным условиям, не могут называться REST-приложениями. Если же все условия соблюдены, то, по его мнению, приложение получит следующие преимущества
, мы позволяем распределенной системе любого типа иметь такие свойства как: производительность, расширяемость, простота, обновляемость, понятность, портативность и надежность.
Замечание Единственным необязательным ограничением для RESTful архитектуры - это "код по требованию". Если сервис не проходит по любым другим условиям, то его совершенно точно нельзя назвать RESTful.
Существует 2 основных типа ресурса в архитектуре REST: коллекция и элемент коллекции.
Коллекция представляет собой набор самостоятельных и самодостаточных элементов.
Пример ссылки на коллекцию пользователей:
/api/users
Элемент коллекции пользователей, или конкретный пользователь, в таком случае, может быть представлен в виде:
/api/users/ae1111
Существительные — хорошо, глаголы — плохо.
Имена коллекций должны представлять сущности (существительные во множественном числе), и они должны быть максимально конкретными и понятными (самодокументирующимися). Если речь идет о собаках, то это должны быть собаки, а не просто животные.
Каждым ресурсом в RESTful API управляет несколько определенных минимально необходимых глаголов. Для большинства случаев достаточно 4 основных глагола (HTTP метода):
Идемпотентность означает, что сколько бы раз мы не вызывали такой метод — результат будет один и тот же.
| Ресурс | POST | GET | PUT | DELETE |
|---|---|---|---|---|
| /users | Создать пользователя | Показать список всех пользователей | Обновить список всех пользователей | Удалить всех пользователей |
| /users/111111 | Ошибка | Показать Василия Пупкина | Если есть, обновить Пупкина, если нет Ошибка | Удалить Василия Пупкина |
Если необходимо показать иерархическую связь между объектами, делаем так.
Коллекция машин пользователя:
/api/users/11111/cars
Конкретная машина:
/api/users/1111/cars
Не стоит писать длинные адреса — это плохо:
/api/users/11111/cars/33333/door/2222
Такие адреса нелегко читать и искать в документации, часто это вообще не имеет смысла — идентификаторы уникальные и «/cars/33333» абсолютно однозначно относится к «/users/111111». Данный вариант следует сократить:
/api/cars/33333/door/22222
Следует различать 2 основных семейства статус кодов (HTTP Status Code):
4xx — проблема возникла на стороне пользователя и он сам может ее исправить, правильно введя необходимую для запроса информацию.
5xx — проблема возникла на сервере и для ее решения пользователь может отправить запрос к службе поддержки.
Ошибки должны быть четко описаны, чтобы не только пользователь знал, что ему необходимо сделать, но и вы легко ориентировались, если пользователь присылает вам запрос для решения проблемы.
Пример хорошо написанного ответа на ошибку:
HTTP Status Code: 401
{«status»: 401, «message»: «Authentication Required», «code»: 20003, «more_info»: «http://www.example.com/docs/errors/20003»}
Помните! Вы пишете API для таких же разработчиков как и Вы.
Используйте необходимый минимум статус кодов в приложении.
Иногда может быть достаточно 3:
Если мало, дополняйте по мере необходимости:
Старайтесь оценить пользу от каждого добавленного Вами элемента для пользователя. Помните, что большое количество, особенно ненужных элементов, способно запутать даже опытных разработчиков.
В некоторых случаях полезно иметь параметр для подавления статус кода ошибки, что бы клиент всегда, при необходимости, мог получить код 200, например.
PUT /api/users/111111?supress_status_code=200
Это добавит нелишней гибкости Вашему API.
Обязательно указывайте номер версии, даже если не планируете изменение интерфейса — все может быстро измениться.
варианты осуществления версионности

в урл, в заголовках
Версию можно указать в строке адреса:
/api/v2/users/11111
или в параметрах запроса:
/api/users/11111?v=2
Нет смысла делать длинными названия версий, вставлять в них точки: v1.03
Версии интерфейса должны меняться максимально редко, в то время как внутреннюю логику работы API можно менять, как только появилась необходимость. В реальности настоящая версия API может быть, например, v2.011-beta2, но версия интерфейса, и, соответственно, представленная в адресе версия будет просто 2.
Любая коллекция, какой бы маленькой, по Вашему мнению, она не была должна отдаваться постранично. Определитесь с форматом выдачи коллекции, например, Content-Type: application/json {«data»:{}, «paging»: {«limit»: 50, «offset»: 0, «total»: 150}} старайтесь всегда использовать одинаковый формат во всех ответах приложения — облегчите жизнь и себе и разработчикам клиентского ПО.
Стоит выбрать какие-то дефолнные значения для параметров «limit», «offset», и, скорее всего, ограничивать максимальное значение для «limit».
Если в Вашем GET запросе необходимо использовать различные фильтры — поместите их за знаком вопроса (в параметрах URL):
GET /api/users?limit=10&offset=4&age=30&height=170&weight=120
Позвольте клиенту получать только те поля в запросе, которые ему нужны:
GET /api/users/11111?fields=fitst_name,last_name,age,gender,finger_count
Не ограничивайтесь каким-то одним форматом. Сделайте опционально несколько, например, json и xml. Таким легким способом можно значительно упростить разработку для клиентов, и отпадет необходимость выбора чего-то одного. Формат возвращаемых данных можно описывать как в HTTP заголовках, так и в строке запроса:
ACCEPT: application/json
GET /api/users/11111.json
И обязательно стоит выбрать какой-то формат по умолчанию.
Так же существуют Бинарные и более современные технологии: BSON, CBOR, MessagePack.
Требования к формату представления данных, используемые в REST API:
бинарный;
быстрый (с поддержкой Zero-copy);
без схемы;
поддерживаются существующие в JSON типы для конвертации.
Например MessagePack, позволяет ускорить прак тически на половину относительно JSON, что позволит увеличить вовлеченность или конверсию.
BSON хранит длины для строк и бинарных данных, позволяя пропускать атрибуты, которые нам не интересны. JSON же последовательно считывает данные и не может попускать элемент, не прочитав его значение до конца. Таким образом, если мы будем хранить большие объемы бинарных данных внутри формата, данная особенность может сыграть для нас важную роль
Формат полностью совместим с JSON, It’s like JSON. but fast and small. При конвертации данных из MessagePack в JSON мы не потеряем данные, чего нельзя сказать, например, про формат BSON. Правда, есть ряд ограничений, накладываемых на различные типы данных:
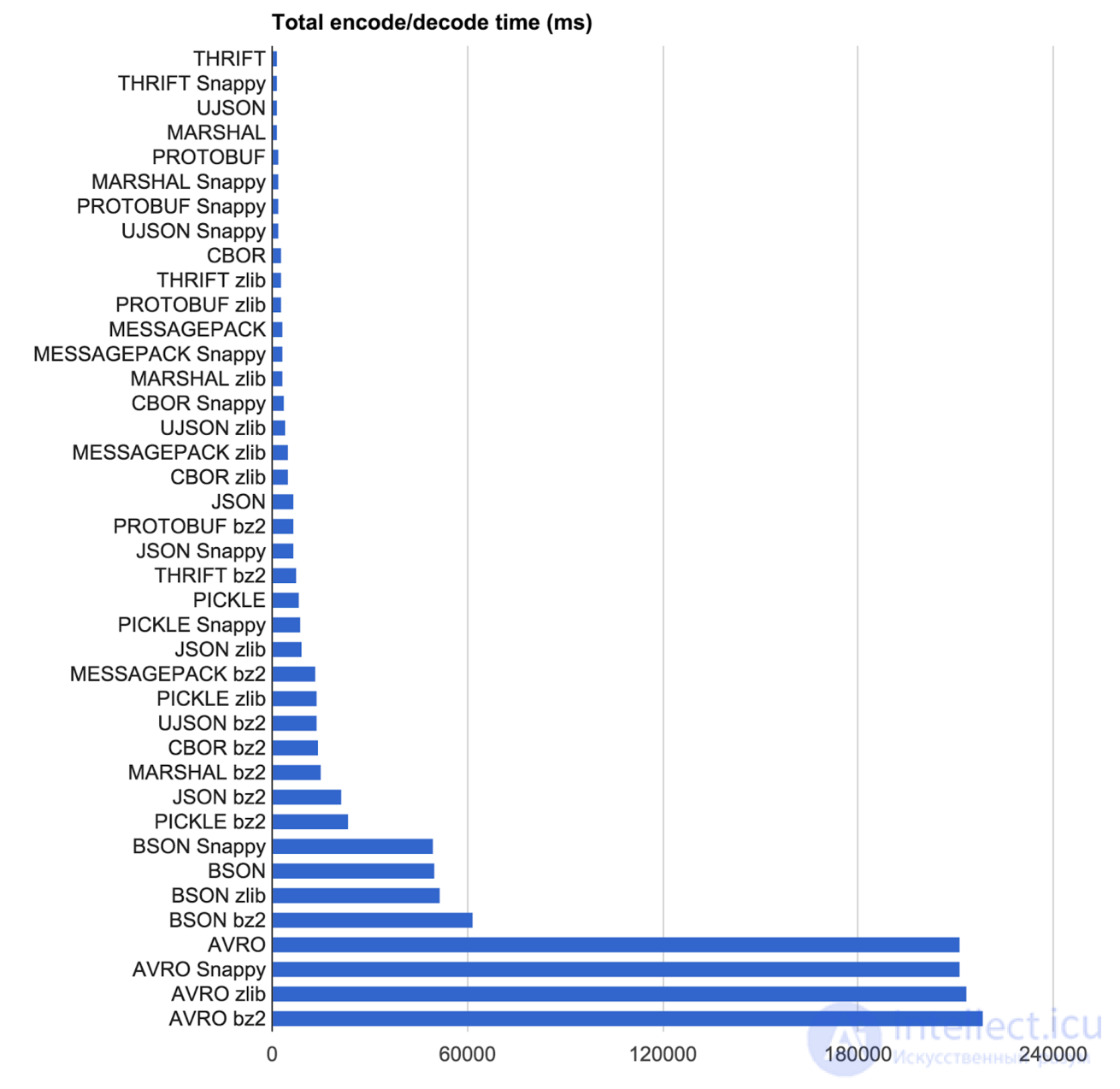
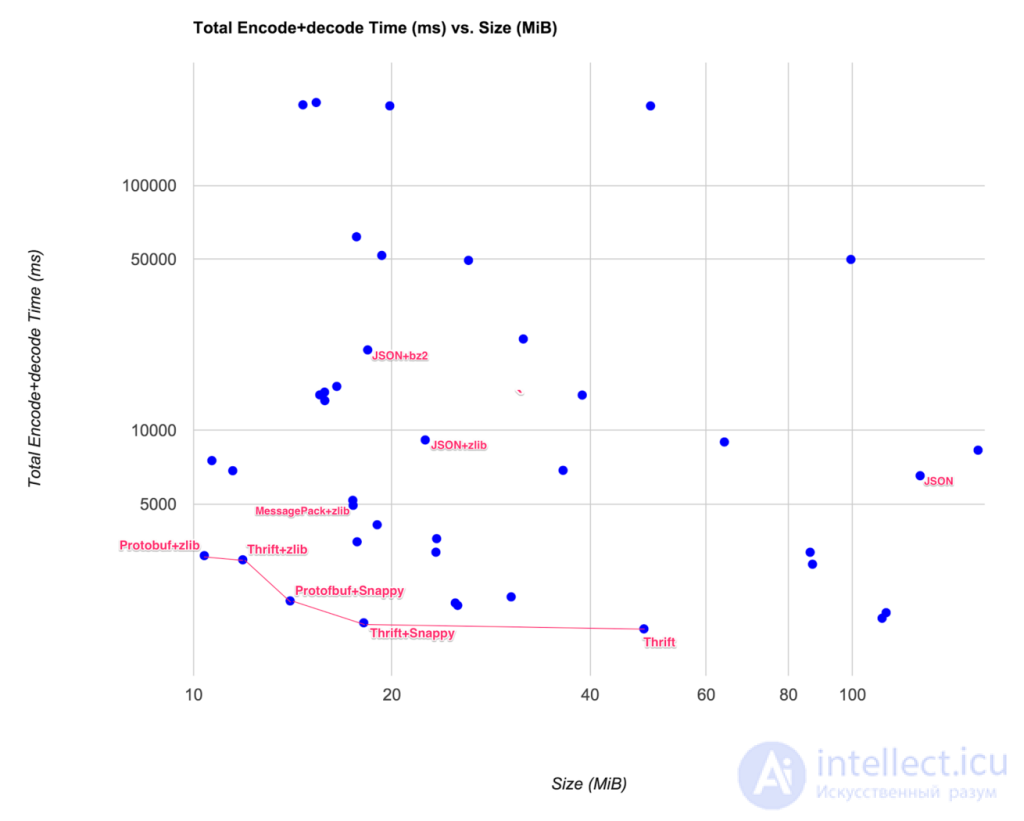
Компромиссы каждого варианта кодирования и сжатия можно сравнить друг с другом на диаграмме рассеяния. Эффективность по Парет , показанный красной линией на графике, потенциально дает нам наиболее оптимальные решения: Эффективность по Парето По сути, нижний левый угол — это то, к чему мы стремились: небольшой размер и короткое время кодирования и декодирования.
Это один из немногих видов ресурса, которому суждено остаться глаголом. Имею в виду глобальный поиск.
GET /api/search?q=some+text+to+find+now
Опять же в зависимости от системы используемого поискового движка можно применять различные фильтры.
Какой-то локальный поиск, в пределах коллекции, можно осуществить и простыми фильтрами:
GET /api/users?q=some+users+to+find+now
Используйте, по возможности, последнюю версию OAuth — OAuth 2.0 — эта система хорошо известна разработчикам, и хорошо себя зарекомендовала. Зачем выдумывать велосипед?
Это один из самых важных аспектов хорошего API. Время, потраченное на хорошую документацию, с лихвой окупятся долгими месяцами работы службы поддержки. Фокус прост — опишите сжато и четко все получаемые и отдаваемые данные, а также назначение методов. Помните! Вы пишете для программистов. Не стоит описывать какие-то очевидные моменты. Приведите все отдаваемые статус коды; перечислите все принимаемые параметры опишите их, где необходимо; давайте ссылки на более подробный материал; приводите примеры получаемых данных, если это уместно, с их описанием.
Старайтесь отдавать в ответах ссылки на все связанные ресурсы, если хотите соответствовать принципу HATEOAS, и называться RESTful. За это Вас будут очень любить разработчики клиентских программ — им не придется самим генерировать эти ссылки.
Фасад Паттерн для API.
Разработку любого API следует начинать с детальной проработки интерфейса. Фактически к началу написания кода на руках должны быть все URI Вашего API с подробной документацией всех параметров каждого доступного для данного URI метода, со всеми возвращаемыми статус кодами и форматами возвращаемых данных. В идеале, этот интерфейс уже не должен меняться в ходе дальнейшей разработки. Такой подход в значительной степени облегчает и ускоряет работу над основным кодом API, и позволяет параллельно писать клиентское ПО уже на самых начальных этапах разработки.
Помните! Интерфейс API должен быть максимально простым и понятным, только так можно достичь счастья и гармонии.
Термин HATEOAS означает фразу «Hypermedia As The Engine Of Application State» (Гипермедиа как двигатель состояния приложения). Чтобы понять это глубже, нам сначала нужно понять значение гипермедиа. Взгляните на следующую веб-страницу:
Когда браузер загружает страницу, вы определенно можете увидеть весь контент, который может предложить эта страница. Что еще более интересно, страница также позволяет вам выполнять множество действий с этими данными, например:
Теперь давайте посмотрим, как ведут себя наши REST API:
Если вы посмотрите на типичный запрос GET к RESTful серверу, такой как этот:

Запрос GET localhost:8080/users получает набор данных трех пользователей в этом случае. Отправив запрос с помощью GET localhost:8080/users/1, вы получите сведения только о первом пользователе. Как правило, когда мы выполняем запрос REST, мы получаем только данные, а не какие-либо действия с ними. Вот где HATEOAS восполняет пробел. Запрос HATEOAS позволяет вам не только отправлять данные, но и указывать связанные действия:

Этот пример был в формате JSON. Формат XML для другого примера будет выглядеть примерно так:
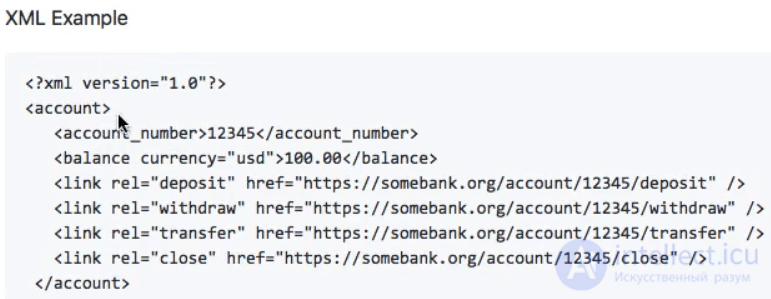
Когда вы отправляете этот запрос для получения данных учетной записи, вы получаете оба:
С HATEOAS запрос на REST ресурс дает мне как данные, так и действия, связанные с данными.
Единственная самая важная причина для HATEOAS — слабая связь (loose coupling). Если потребителю службы REST необходимо жестко закодировать все URL-адреса ресурсов, он тесно связан с реализацией вашей службы. Вместо этого, если вы вернете URL-адреса, которые он может использовать для действий, он будет слабосвязанным. Нет строгой зависимости от структуры URI, так как она указана и используется в ответе. Несколько важных тем, связанных с HATEOAS:
При разработке службы RESTful необходимо указать, как возвращать данные и ссылки, соответствующие запросу. HAL — это формат, который обеспечивает простой и согласованный способ гиперссылки между ресурсами в вашем REST API. Вот пример:
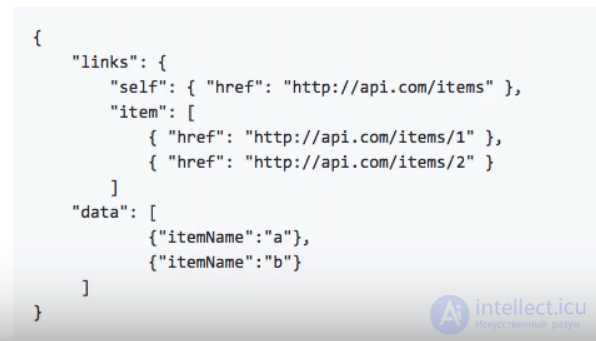
С HAL у вас есть несколько категорий представлений:
Если вам довелось использовать Spring Framework для разработки REST сервиса, то Spring HATEOAS — хороший механизм для вашего сервиса.
Как и первая версия, OAuth 2.0 основан на использовании базовых веб-технологий: HTTP-запросах, редиректах и т. п. Поэтому использование OAuth возможно на любой платформе с доступом к интернету и браузеру: на сайтах, в мобильных и desktop-приложениях, плагинах для браузеров…
Ключевое отличие от OAuth 1.0 — простота. В новой версии нет громоздких схем подписи, сокращено количество запросов, необходимых для авторизации.
Общая схема работы приложения, использующего OAuth, такова:
Результатом авторизации является access token — некий ключ (обычно просто набор символов), предъявление которого является пропуском к защищенным ресурсам. Обращение к ним в самом простом случае происходит по HTTPS с указанием в заголовках или в качестве одного из параметров полученного access token'а.
В протоколе описано несколько вариантов авторизации, подходящих для различных ситуаций:
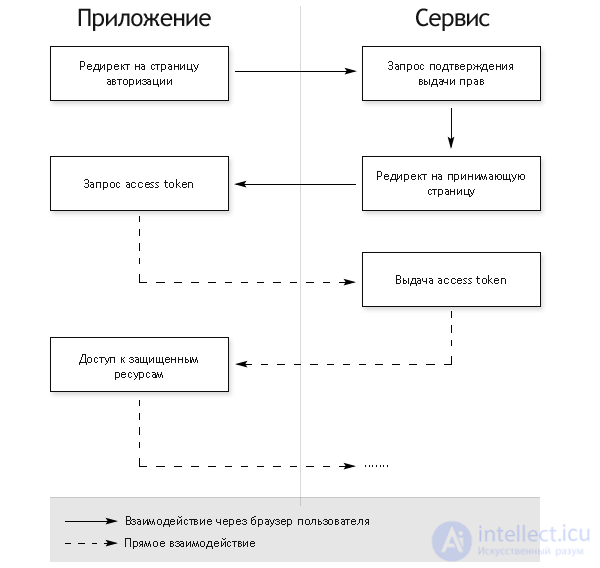
Это самый сложный вариант авторизации, но только он позволяет сервису однозначно установить приложение, обращающееся за авторизацией (это происходит при коммуникации между серверами на последнем шаге). Во всех остальных вариантах авторизация происходит полностью на клиенте и по понятным причинам возможна маскировка одного приложения под другое. Это стоит учитывать при внедрении OAuth-аутентификации в API сервисов.
Здесь и далее примеры приводятся для API intellect.icu, но логика одинаковая для всех сервисов, меняются только адреса страниц авторизации. Обратите внимание, что запросы надо делать по HTTPS.
Редиректим браузер пользователя на страницу авторизации:
> GET /oauth/authorize?response_type=code&client_id=1111&
redirect_uri=http%3A%2F%2Fintellect.icu%2Fcb%2F123 HTTP/1.1
> Host: connect.intellect.icu
Здесь и далее, client_id и client_secret — значения, полученные при регистрации приложения на платформе.
После того, как пользователь выдаст права, происходит редирект на указанный redirect_uri:
< HTTP/1.1 302 Found < Location: http://example.com/cb/123?code=gfjfgjgfjb0y
Обратите внимание, если вы реализуете логин на сайте с помощью OAuth, то рекомендуется в redirect_uri добавлять уникальный для каждого пользователя идентификатор для предотвращения CSRF-атак (в примере это 123). При получении кода надо проверить, что этот идентификатор не изменился и соответствует текущему пользователю.
Используем полученный code для получения access_token, выполняя запрос с сервера:
> POST /oauth/token HTTP/1.1
> Host: connect.intellect.icu
> Content-Type: application/x-www-form-urlencoded
>
> grant_type=authorization_code&client_id=49&client_secret=dgfhfgef&code=gfjfgjgfjb0y&
redirect_uri=http%3A%2F%2Fexample.com%2Fcb%2F123
< HTTP/1.1 200 OK
< Content-Type: application/json
<
< {
< "access_token":"tfrtgu",
< "token_type":"bearer",
< "expires_in":86400,
< "refresh_token":"thdtthTDHtrht",
< }
Обратите внимание, что в последнем запросе используется client_secret, который в данном случае хранится на сервере приложения, и подтверждает, что запрос не подделан.
В результате последнего запроса получаем сам ключ доступа (access_token), время его «протухания» (expires_in), тип ключа, определяющий как его надо использовать, (token_type) и refresh_token о котором будет подробнее сказано ниже. Дальше, полученные данные можно использовать для доступа к защищенным ресурсам, например, API intellect.icu:
> GET /platform/api?oauth_token=tbhuiGDSGGGg76rf&client_id=5119&format=json&method=users.getInfo&
sig=... HTTP/1.1
> Host: apps.intellect.icu
Описание в спецификации

Этот вариант требует поднятия в приложении окна браузера, но не требует серверной части и дополнительного вызова сервер-сервер для обмена authorization code на access token.
Открываем браузер со страницей авторизации:
> GET /oauth/authorize?response_type=token&client_id=454119 HTTP/1.1 > Host: connect.intellect.icu
После того, как пользователь выдаст права, происходит редирект на стандартную страницу-заглушку, для intellect.icu это connect.intellect.icu/oauth/success.html:
< HTTP/1.1 302 Found
< Location: http://connect.intellect.icu/oauth/success.html#access_token=jhgbujgjyhg&token_type=bearer&
expires_in=16400&refresh_token=thdtthTDHtrht
Приложение должно перехватить последний редирект, получить из адреса acess_token и использовать его для обращения к защищенным ресурсам.
Авторизация по логину и паролю представляет простой POST-запрос, в результате которого возвращается access token. Такая схема не представляет из себя ничего нового, но вставлена в стандарт для общности и рекомендуется к применению только, когда другие варианты авторизации не доступны.
> POST /oauth/token HTTP/1.1
> Host: connect.intellect.icu
> Content-Type: application/x-www-form-urlencoded
>
> grant_type=password&client_id=31337&client_secret=deadbeef&username=api@corp.intellect.icu&
password=qwerty
< HTTP/1.1 200 OK
< Content-Type: application/json
<
< {
< "access_token":"hgfvyfyujfygjftyf32",
< "token_type":"bearer",
< "expires_in":96400,
< "refresh_token":"thdtthTDHtrht",
< }
Обычно, access token имеет ограниченный срок годности. Это может быть полезно, например, если он передается по открытым каналам. Чтобы не заставлять пользователя проходить авторизацию после истечения срока действия access token'а, во всех перечисленных выше вариантах, в дополнение к access token'у может возвращаться еще refresh token. По нему можно получить access token с помощью HTTP-запроса, аналогично авторизации по логину и паролю.
> POST /oauth/token HTTP/1.1
> Host: connect.intellect.icu
> Content-Type: application/x-www-form-urlencoded
>
> grant_type=refresh_token&client_id=31337&client_secret=dfhdfhdfhdfh&refresh_token=thdtthTDHtrht
< HTTP/1.1 200 OK
< Content-Type: application/json
<
< {
< "access_token":"JRTr5677",
< "token_type":"bearer",
< "expires_in":86400,
< "refresh_token":"thdtthTDHtrht",
< }
swagger.io Swagger уже разрабатывают достаточно давно. Это программное решение для генерации документации .
В качестве разметки используется JSON которую можно сгенерировать из PHP docs, так же на основе этого JSON файла можно автоматически сгенерировать как код клиента так и код сервера (прототипный ) на разных языках програаамирования, что существуенно ускорит разработку или внедрение тестирования.

postman.com Платформа совместной работы для разработки API и многие другие
В заключение, эта статья об методы передачи данных подчеркивает важность того что вы тут, расширяете ваше сознание, знания, навыки и умения. Надеюсь, что теперь ты понял что такое методы передачи данных, rest архитектура, cgi приложения, rest api, hateoas, методы http-запросов, oauth, communication endpoint и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Выполнение скриптов на стороне сервера PHP (LAMP) NodeJS (Backend)
Комментарии
Оставить комментарий
Выполнение скриптов на стороне сервера PHP (LAMP) NodeJS (Backend)
Термины: Выполнение скриптов на стороне сервера PHP (LAMP) NodeJS (Backend)