Лекция
Привет, Вы узнаете о том , что такое качество кода, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое качество кода, ооп, оод, ооа, solid, grasp , настоятельно рекомендую прочитать все из категории Проектирование веб сайта или программного обеспечения.
Железный треугольник Объем работ (фичи, функционал, качество и т.д.) Время (график, сроки) Деньги (бюджет, ресурсы) Железный треугольник, или треугольник менеджмента. Его смысл в том, что ограничения на объем работ, сроки и бюджет должны быть разумными и нужно ими управлять (балансировать) Где же качество?
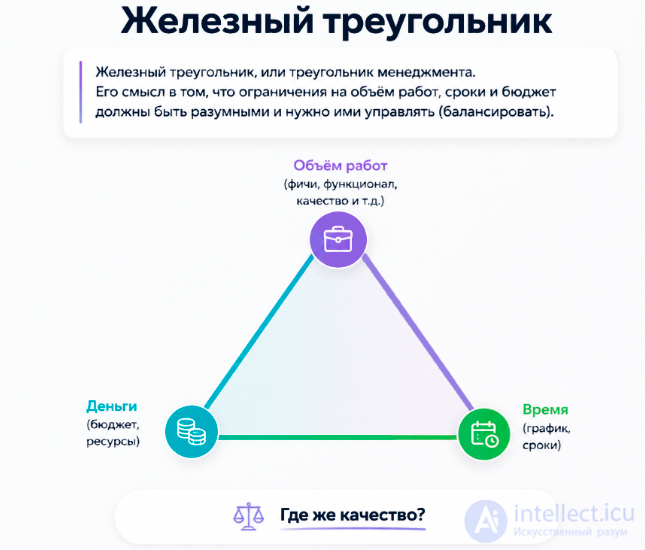

Железный треугольник Объем работ (фичи, функционал, качество и т.д.) Время (график, сроки) Деньги (бюджет, ресурсы) Качественное ПО получается в результате баланса между объемом работ, сроками и бюджетом Качество
К чему эти треугольники?
Ценности качественного кода
Расширяемость, гибкость (extensibility, agility)
Сопровождаемость (maintainability)
Простота (simplicity)
Читабельность, понятность (readability, clarity)
Тестируемость (testability)

•Организационные
–XP (eXtreme Programming)
–Code review
–Project management, methodology,
–Utilities: StyleCop, FxCop, Code Analysis
–Requirements…
•Технические
–Юнит-тесты
–TDD, Defensive programming style
–OOP/OOD, principles
•Обучение
•Внешние – программистские практики
–Парное программирование
–Статический анализ кода
–Code review ,
–Unit-tests, TDD/BDD
•Внутренние - правильное проектирование и рефакторинг кода как способ превращения плохого кода в более хороший
–OOP/OOD, principles,
–Programming style
Просмотр кода (англ. code review) или инспекция кода (англ. code inspection) — систематическая проверка исходного кода программы с целью обнаружения и исправления ошибок, которые остались незамеченными в начальной фазе разработки. Целью просмотра является улучшение качества программного продукта и совершенствование навыков разработчика.
В процессе инспекции кода могут быть найдены и устранены такие проблемы, как ошибки в форматировании строк, состояние гонки, утечка памяти и переполнение буфера, что улучшает безопасность программного продукта. Системы контроля версий дают возможность проведения совместной инспекции кода. Кроме того, существуют специальные инструментальные средства для совместной инспекции кода.
Программное обеспечение для автоматизированной инспекции кода упрощает задачу просмотра больших кусков кода, систематически сканируя его на предмет обнаружения наиболее известных уязвимостей.
StyleCop, FxCop, Code Analysis, Ndepend Цель автоматизировать review кода и обратить внимание на распространенные ошибки и скользкие участки. В идеале внедрить стат. анализ в CI (build process)
Управление проектом напрямую влияет на результаты и удовлетворенность от работы – Хаотическое управление = низкое качество (e.g. Cowboy coding)
Парное программирование
Всесторонний code review
Юнит-тесты на весь код (TDD)
YAGNI, не пишем того, что не нужно
Изменчивые требования
Частая коммуникация с заказчиком и в команде
Никакие утилиты стат. анализа не заменят людей
Позволяет писать качественные код
Повышает коммуникации
Улучшает команду
Парное программирование способствует

Юнит-тесты – позволяют контролировать соответствие кода задуманному поведению.
ТDD – подход к написанию кода начиная с тестов. «Тесты вперед»
Рефакторинг — это контролируемый процесс улучшениякода, без написания новой функциональности. Результатрефакторинга — это чистый код и простой дизайн.
Defensive programming Использование осетров (asserts)
Использование контрактов кода (code contracts)
Ассерты или контракты как мини юнит-тесты если что то идет не так
Защитное программирование (defensive coding) — это стиль написания компьютерных программ, призванный сделать их более отказоустойчивыми в случае возникновения серьезных функциональных отклонений. Обычно подобное незапланированное поведение возникает из-за наличия багов в программе, но оно может быть обусловлено и совсем другими причинами: поврежденными данными, отказами аппаратного обеспечения, багами, которые возникают в программе в процессе ее доработки. Оказываясь в критической ситуации, код, написанный в защитном стиле, пытается принять максимально разумные меры с небольшим снижением производительности. Также такой код не должен допускать создания условий для возникновения новых ошибок.
История
Впервые я столкнулся с термином «защитное программирование» в книге Кернигана и Ритчи (The C Programming Language, 1st Edition). После тщательных поисков мне не удалось найти более ранних упоминаний этого термина. Вероятно, он был придуман по аналогии с «безопасным вождением», о котором стали активно рассуждать в начале 1970-х, за несколько лет до появления книги Кернигана и Ритчи.
В предметном указателе к книге K&R указано две страницы, на которых употребляется этот термин. На стр. 53 он означает написание кода, не допускающего возникновения багов, а на стр. 56 этот термин понимается уже немного иначе: создание кода, снижающего вероятность возникновения багов при последующих изменениях кода в процессе его доработки. В любом случае с тех пор термин «защитное программирование» употреблялся во многих книгах. Обычно под ним понимается обеспечение работоспособности кода даже при наличии багов — например, в книге «The Pragmatic Programmer» Эндрю Ханта и Дэйва Томаса (где о «программировании в защитном стиле» рассказывается в главе «Pragmatic Paranoia»), а также в других источниках.
Различия в толковании
Несмотря на то, что этот термин вполне четко понимается на протяжении последних 20 с лишним лет, его точное значение в последнее время стало размываться в результате появления ряда статей (как правило, не прошедших экспертную оценку) на разных сайтах и в блогах. Например, в одноименной статье Википедии и на нескольких сайтах, ссылающихся на нее, «защитное программирование» трактуется как подход к обработке ошибок. Разумеется, обработка ошибок и защитное программирование — родственные понятия, но они определенно не являются полными синонимами, равно как одно не является частным случаем другого (подробнее об этом — ниже).
Еще одна классическая и часто цитируемая статья, озаглавленная просто «Defensive Programming», имеет очень высокий рейтинг на сайте Codeproject.com. Это по-своему замечательная и содержательная статья, но она рассказывает не строго о защитном программировании, а, по признанию самого автора, «о методах, полезных при отлавливании программных ошибок». Как будет показано ниже, защитное программирование оказывает противоположный эффект — оно не отлавливает ошибки, а скорее скрывает их. Упомянутая статья с Codeproject.com затрагивает многие темы, и ее следовало бы переименовать, например, в «Good Coding Practices».
Сравнение обработки ошибок и защитного программирования
Многие разработчики нечетко представляют себе разницу между обработкой ошибок и защитным программированием. Постараюсь ее объяснить.
При обработке ошибок отыскиваются и исправляются ситуации, в которых что-то идет не так, причем вы знаете, что такая ситуация возможна, хотя и маловероятна. Напротив, защитное программирование — это попытка учесть последствия таких проблем, которые на первый взгляд кажутся «невозможными». Подобные «невозможные» проблемы делятся на две категории, вполне возможно, что поэтому и возникает некоторая путаница.
Проблемы первой категории невозможны в одних обстоятельствах, но вполне вероятны в других. Например, если у нас есть функция, приватная в определенном модуле или программе, мы можем гарантировать, что ей всегда будут передаваться валидные аргументы. Но если эта же функция входит в состав общедоступной библиотеки, то вы не можете быть уверены, что она никогда не получит плохих данных. Если функция приватная, то целесообразно применить защитное программирование, чтобы обеспечить, что функция «поступит разумно» даже в такой ситуации, которая кажется невозможной. Если функция общедоступная, то к ней можно добавить обработку ошибок на тот случай, что ей будут переданы невалидные данные.
Итак, выбираемая нами стратегия — защитное программирование или явное добавление обработки ошибок — зависит от области применения конкретной программы. Подробнее мы поговорим об этом в разделе «Область применения».
Вторая проблема заключается в том, что возможны пограничные случаи, в которых возможность или невозможность возникновения определенных условий является спорной. Рассмотрим следующий набор сценариев, которые могут сложиться в программе, если она получит невалидные данные:
В какой момент мы можем быть уверены, что данные не могут оказаться невалидными? Я считаю, что совершенно невозможен случай, в котором файл с невалидными данными продолжает генерировать верную контрольную сумму (см. сценарий 6). Тем не менее, если данные обладают повышенной критичностью с точки зрения безопасности, необходимо учесть и вероятность того, что файл был специально подправлен для получения «верной» контрольной суммы. В таком случае придется использовать криптографическую контрольную сумму, например SHA1.
Правда, мне известно, что во многих программах предполагается, что все файлы с бинарными данными безусловно являются валидными (сценарий 4 или 5). Но при этом часто встречаются программы, которые начинают вести себя непредсказуемо, если получат поврежденные файлы с бинарными данными.
Думаю, любой согласится, что можно быть вполне уверенным в том, что локальная переменная, которую вы только что записали (сценарий 9), не изменится. Тем не менее в случае аппаратной ошибки, намеренной подделки или других причин такая переменная может неожиданно принять некорректное значение.
Итак, не всегда ясно, в каких случаях вам понадобится специальный код для обработки ошибок, а в каких будет достаточно защитного программирования.
Пример
Классический пример защитного программирования можно найти практически в любой программе, когда-либо написанной на C. Речь о случаях, когда условие завершения пишется не как тест на неравенство ( < ), а как тест на неэквивалентность (!=). Например, типичный цикл пишется так:
size_t len = strlen(str);
for (i = 0; i < len; ++i)
result += evaluate(str[i]);
а не так:
size_t len = strlen(str);
for (i = 0; i != len; ++i)
result += evaluate(str[i]);
Очевидно, оба фрагмента должны работать аналогично, поскольку переменная 'i' может только увеличиваться и ни при каких условиях не может стать неравной 'len'. Почему же условия завершения цикла всегда пишутся только по первому образцу, а не по второму?
Во-первых, последствия возникновения «невозможного» условия очень пагубны и, вероятно, могут привести к всевозможным неприятным последствиям в готовой программе — например, к возникновению бесконечного цикла или нарушению доступа к памяти. Такое «невозможное» условие вполне может возникнуть в некоторых ситуациях:
for (i = 0; i != len; ++i)
{
while (!isprint(str[i])) // патологическое изменение кода, при котором 'i' может никогда не оказаться равным 'len'
++i;
result += evaluate(str[i]);
}
Разумеется, несколько последних случаев, вызываемые программными ошибками, встречаются наиболее часто. Именно поэтому защитное программирование зачастую ассоциируется с защитой от багов.
Культура C
Есть еще два аспекта языка C, определяющих, как и когда в нем используется защитное программирование. Я имею в виду, во-первых, акцент C на эффективности кода и, во-вторых, применяемые здесь подходы к обработке ошибок.
Начнем с эффективности. Одна из базовых предпосылок работы с C заключается в том, что программист знает, что делает. Язык не защищает нас от возможных ошибок, тогда как другие хотя бы пытаются это делать. Например, на C при записи данных легко забросить их за пределы массива — но если при доступе к массиву применяется проверка границ (выполняемая компилятором), то программа будет работать медленнее даже при совершенно безопасном коде.
Поскольку в C делается акцент на эффективность, защитное программирование применяется лишь в тех случаях, когда оно не оказывает негативного влияния на производительность или если такое влияние минимально. Об этом говорит сайт https://intellect.icu . Типичный пример приведен выше, поскольку оператор «меньше» обычно не уступает по скорости «не равно».
Второй аспект — это организация обработки ошибок в C. Обычно ошибки в C обрабатываются с использованием возвращаемых значений ошибок. Обработка ошибок зачастую играет в коде C определяющую роль, поэтому потенциальные условия возникновения ошибок игнорируются, если они представляются маловероятными. Например, никто и не подумает проверять возвращаемое значение ошибки от printf(). На самом деле условия ошибок порой игнорируются и тогда, когда этого делать не следует, но это уже тема для другой дискуссии.
Итак, если наличие «маловероятных» ошибок обычно не проверяется, целесообразно обрабатывать «невозможные» условия, поскольку, если возникнут подобные маловероятные ошибки, они значительно осложнят весь процесс обработки. Разумеется, в языках с обработкой исключений многие подобные проблемы легко снимаются путем выдачи программного исключения.
Область применения
Многие противоречивые мнения о защитном программировании возникают из-за того, что область его применения не всегда четко очерчена. Например, если у нас есть функция, принимающая строковый параметр (const char *), то хочется предположить, что ей никогда не будет передан указатель NULL, так как в этом нет практически никакого смысла. Если это приватная функция, то вы можете во всех случаях гарантировать отсутствие передачи NULL; но если функция может быть применена не только вами, то на такое отсутствие NULL рассчитывать нельзя, лучше указать в документации, что указатель NULL здесь использоваться не должен.
В любом случае даже если вы считаете условие невозможным, то будет разумно застраховаться от него при помощи защитного хода. Многие функции просто возвращаются, если им неожиданно был передан NULL. Опять же такой случай отличается от обработки ошибок, поскольку значение ошибки не генерируется.
Поэтому, обсуждая защитное программирование, всегда следует учитывать область применения рассматриваемого кода. Как раз этот момент не учтен в статье Википедии на данную тему.
Симптомы
При работе с программой, содержащей ошибки, симптомы защитного программирования заметны довольно часто (но могут быть приняты за ошибки управления). Думаю, любому доводилось видеть программы, которые ведут себя странно: выбрасывают на экран окна, игнорируют команды и даже отображают сообщения о «неизвестной ошибке». Обычно эти явления спровоцированы багами и тем, как программа пытается справиться с возникшими проблемами.
Иногда ей это удается, но гораздо чаще программа просто падает, а не работает. В худшем случае она может незаметно нанести огромный ущерб — в частности, спровоцировать потерю или повреждение данных. Когда я начинаю замечать такие странные явления, я обычно сразу сохраняю работу и перезапускаю программу.
Проблемы защитного программирования
Итак, теперь мы вполне четко понимаем основную проблему защитного программирования. Защитное программирование скрывает от нас наличие багов
Некоторые люди считают, что это хорошо. Да, хорошо для готовой программы, уже находящейся в использовании, — конечно, мы не хотим ставить перед пользователем проблемы, которых он даже не понимает. С другой стороны, если просто продолжать работать, когда что-то уже сломалось, это может кончиться плохо. Поэтому нужно попытаться как-то сообщить о возникшей проблеме — как минимум, сделать соответствующую запись в файле логов.
Гораздо хуже то, что защитное программирование скрывает ошибки и на этапах разработки и тестирования. Думаю, никто не считает, что это хорошо. Альтернатива — это использование подхода, иногда именуемого «агрессивное программирование» или «принцип быстрого отказа» (fail fast). Такие подходы нацелены как раз на быстрое проявление ошибок, а не на замалчивание.
Я применяю защитное программирование так, что в готовых сборках остается возможность для обработки неожиданных или условно невозможных ситуаций. Но я также добавляю контрольные операторы для проверки невозможных ситуаций — такие операторы нужны, чтобы в программу не проникли баги. Кроме того, во время тестирования я работаю преимущественно с отладочной сборкой (где уже используются такие утверждения), проверяя готовый продукт уже при окончательном приемочном тестировании. Для самых критических моментов я также явно добавляю код для обработки ошибок, поскольку в готовых сборках контрольные операторы удаляются.
Упражнение
Наконец, предлагаю вам пищу для размышлений. В стандартной библиотеке C есть функция, принимающая строку цифр и возвращающая целое число. Эта функция называется atoi.
Если вы не знакомы с atoi(), уточню, что она не возвращает никаких кодов ошибок, но останавливается, как только ей встречается первый же неожиданный символ. Например, atoi("two") просто возвращает нуль.
Является ли поведение atoi() примером защитного программирования? Почему?
К его появлению приводит быстрая и бездумная разработка Когда мы понимаем, что можем написать дизайн лучше, но в силу причин не делаем этого – мы откладываем долг. Выплачивать придется рефакторингом

Теория. Гради Буч. Объектно-ориентированный анализ и проектирование.
В этой книге есть определения ООА, ООД, ООП. Краткое определение трудно воспринимается в отрыве от книги:
Цитата:
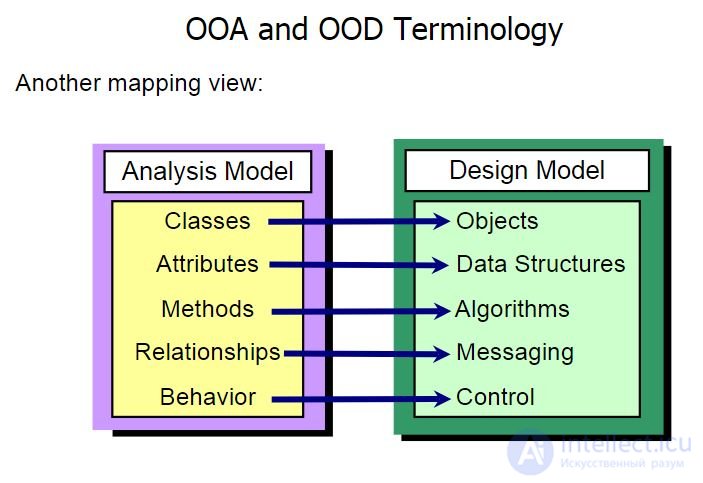
Объектно-ориентированный анализ - это методология, при которой требования к системе воспринимаются с точки зрения классов и объектов, выявленных в предметной области.
Объектно-ориентированное проектирование - это методология проектирования, соединяющая в себе процесс объектной декомпозиции и приемы представления логической и физической, а также статической и динамической моделей проектируемой системы.
Объектно-ориентированное программирование - это методология программирования, основанная на представлении программы в виде совокупности объектов, каждый из которых является экземпляром определенного класса, а классы образуют иерархию наследования.
Практика. Крэг Ларман. Применение UML 2.0 и шаблонов проектирования
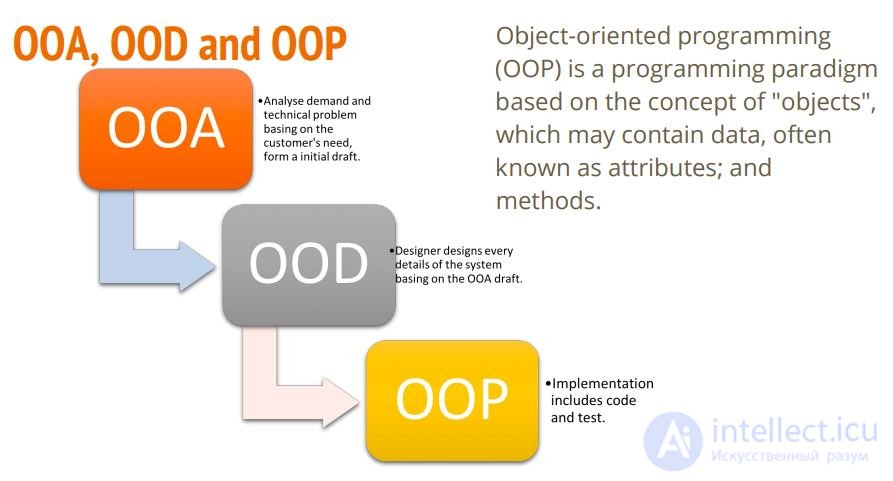
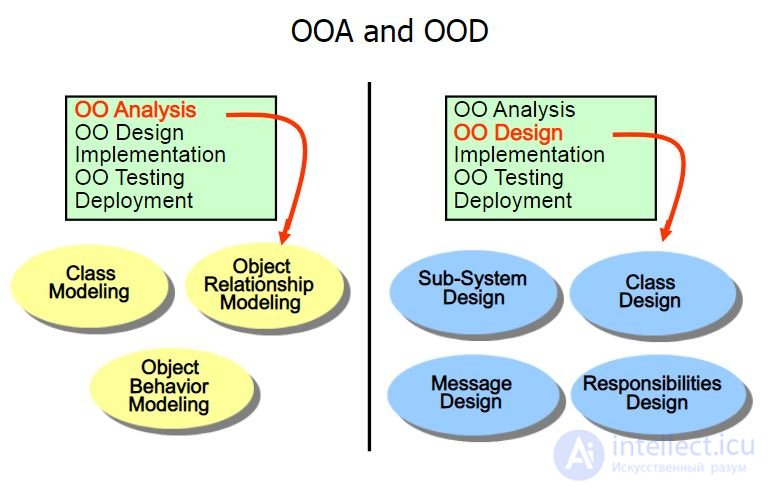
Фаза 1. OOA – Объектно-ориентированный анализ. (ОСМЫСЛЕНИЕ)
пример 1 Смотришь на постановку задачи, обдумывая, ну и как же сделать эту фиговину. Пытаешься понять, из чего оно в общем и целом состоит и могло бы быть, читая описание, рисуешь всякие там стрелочки, классики, объектики и прочие комментарии в вольном стиле и мысли, приходящие в голову. Когда процесс надоедает (кончается криатифф), переходишь к следующему этапу.
пример 2 Менеджер привел заказчика. Заказчик хочет сферического коня в вакууме. Руководитель берет тимлида, ведущего программиста и все трое со всех сил стараются понять, чего же он хочет. Далее уже без заказчика гл. программист сидит и доооолго думает, что это будет за зверь, как же этот конь будет выглядеть, какие части (не путать с калассами) будут в проекте.
После выделения частей коня решено, что он будет состоят из трех частей: сервер-служба, гуй-клиент-настройщик, веб-морда.
Пример 3 OOA – анализ основанный на юз-кейсах. Прикинуть как пользователи будут вести себя с софтом и описать эти случаи. Получится список сценариев, которые ясно раскроют картину происходящего.
Фаза 2. OOD – Объектно-ориентированное проектирование (UML ДИАГРАММА КЛАССОВ)
Пример 1 Читаешь все каля-маля, нарисованные во время этапа анализа и блуждания по сайтам с котиками, в надежде, что тебя посетит гениальная идея. Пытаешься весь поток сознания хоть как-то систематизировать, разложив его по классам и объектам, продумываешь связи между ними, как они типично будут взаимодействовать друг с другом. Что-то придет само, что-то придется высидеть, а то и захочется нарисовать что-то совершенно абстрактное и вроде как бесполезное, но исключительно стильно выглядящее. Понимаешь, что не клеится. Мнешь лист бумаги, кидаешь в угол комнаты или коллегу по работе. Берешь другой, рисуешь заново, классы, связи, диаграммы стандартные и в свободном стиле, напоминающие инструкции по перебору двигателей. Когда понимаешь, что лучше ты все равно уже не придумаешь, переходишь к фазе внедрения в жизнь.
Пример 2 Тимлиду поручено сделать сервер и он начинает думать в сторону того, как будет устроен сервер, рисует одному ему понятные стрелочки и продумывает очень иерархию частей этого сервера и их взаимодействие.
Пример 3 ООD – на основе полученных сценариев выявляются существительные (классы) и глаголы (операции/методы). Все это можно красиво оформить в UML. И переходить к ООП.
Прочитав один раз книгу Крэг Ларман – UML 2.0…до сих пор использую этот подход при написании софта.
Фаза 3. OOP – объектно-ориентированное программирование (КОД НА КОНКРЕТНЫХЯЗЫКАХ ПРОГРАММИРОВАНИЯ)
Пример 1 Берешь свой любимый язык программирования (Ассемблер и HTML не подойдут – нету размаха), и претворяешь наскальные письмена с предыдущей фазы в жизнь – раскладываешь классы на составляющие, разбрасываешь их по файлам исходников, закручиваешь взаимные связи, тихо офигевая от того кошмара, который выходит, понимаешь, что все не так плохо, как кажется, а намного хуже, и ты себе поставишь памятник, если оно хоть когда-нибудь заработает. Пишешь кучу строк текста, попутно матерясь на непроинициализированные указатели, утекшие мегабайты памяти, из-за которых ты хотел нарастить себе оперативку уже до 2 гигов, копаешься в документации, и вот однажды оно оживает и начинает напоминать желаемый результат. Еще труда – и ты у финишной черты.
Затягиваешься сигаретой, выпиваешь бутылку вина, с благоговейным ужасом смотря на то, что ты сделал, понимая, что второй раз ты это не повторишь. Смотришь на себя в зеркало, играя бицепсами/скулами (нужное подчеркнуть) и говоришь себе “Ну какой же я молодец!”.
пример 2
Сижу я. Решаю, что "ConectionPool <>------ ClientProcessor" (агрегирование), при этом ClientProcessor будет наследником того-то и того-то... Рисую UML, показываю тимлиду. Кивает - делаю.
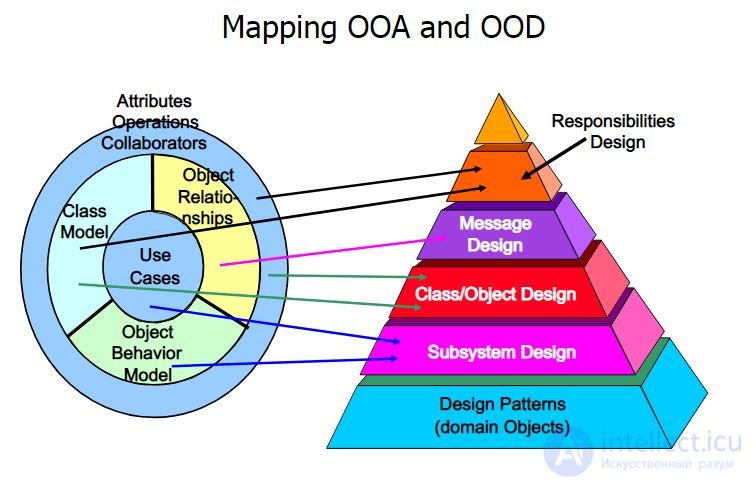
Почитайте статью и про ООП вообще. Это действительно довольно большая тема для одного ответа на данном ресурсе. Думаю, поняв концепцию ООП, что такое объект, в чем разница между объектом и классом, Вы придете к выводу, зачем и когда это нужно.
Но если вкратце: классы нужны для создания своих структур данных, которые будут содержать какую-то логику обработки. Вся логика хранится в описании класса, при этом оставляя в вызывающей программе лаконичные вызовы, без лишнего кода.
SOLID это свод пяти основных принципов ООП, введенный Майклом Фэзерсом в начале нулевых. Эти принципы — часть общей стратегии гибкой и адаптивной разработки, их соблюдение облегчает расширение и поддержку проекта.
Придумал принципы SOLID Роберт Мартин (Uncle Bob). Естественно, что в своих работах он освещает эту тему.
Книга “Принципы, паттерны и методики гибкой разработки на языке C#” 2011 года. Большинство статей, которые я видел, основываются именно на этой книге. К сожалению, она дает расплывчатое описание принципов, что сильно ударило по их популярности.
Видео сайта cleancoders.com. Дядюшка Боб в шутливой форме на пальцах рассказывает, что же именно означают принципы и как их применять.
Книга “Clean Architecture” 2017 года. Описывает архитектуру, построенную из кирпичиков, удовлетворяющих SOLID принципам. Дает определение структурному, объектно-ориентированному, функциональному программированию. Содержит лучшее описание SOLID принципов, которое я когда-либо видел.
SOLID всегда упоминают в контексте ООП. Так получилось, что именно в ООП языках появилась удобная и безопасная поддержка динамического полиморфизма. Фактически, в контексте SOLID под ООП понимается именно динамический полиморфизм.
Полиморфизм дает возможность для разных типов использовать один код.
Полиморфизм можно грубо разделить на динамический и статический.
Кроме привычных языков вроде Java, C#, Ruby, JavaScript, динамический полиморфизм реализован, например в
SOLID принципы советуют, как проектировать модули, т.е. кирпичикам, из которых строится приложение. Цель принципов — проектировать модули, которые:
A module should be responsible to one, and only one, actor.
Старая формулировка: A module should have one, and only one, reason to change.
Часто ее трактовали следующим образом: Модуль должен иметь только одну обязанность. И это главное заблуждение при знакомстве с принципами. Все несколько хитрее.
На каждом проекте люди играют разные роли (actor): Аналитик, Проектировщик интерфейсов, Администратор баз данных. Естественно, один человек может играть сразу несколько ролей. В этом принципе речь идет о том, что изменения в модуле может запрашивать одна и только одна роль. Например, есть модуль, реализующий некую бизнес-логику, запросить изменения в этом модуле может только Аналитик, но никак не DBA или UX.
A software artifact should be open for extension but closed for modification.
Старая формулировка: You should be able to extend a classes behavior, without modifying it.
Это определенно может ввести в ступор. Как можно расширить поведение класса без его модификации? В текущей формулировке Роберт Мартин оперирует понятием артефакт, т.е. jar, dll, gem, npm package. Чтобы расширить поведение, нужно воспользоваться динамическим полиморфизмом.
Например, наше приложение должно отправлять уведомления. Используя dependency inversion, наш модуль объявляет только интерфейс отправки уведомлений, но не реализацию. Таким образом, логика нашего приложения содержится в одном dll файле, а класс отправки уведомлений, реализующий интерфейс — в другом. Таким образом, мы можем без изменения (перекомпиляции) модуля с логикой использовать различные способы отправки уведомлений.
Этот принцип тесно связан с LSP и DIP, которые мы рассмотрим далее.
Имеет сложное математическое определение, которое можно заменить на: Функции, которые используют базовый тип, должны иметь возможность использовать подтипы базового типа, не зная об этом.
Классический пример нарушения. Есть базовый класс Stack, реализующий следующий интерфейс: length, push, pop. И есть потомок DoubleStack, который дублирует добавляемые элементы. Естественно, класс DoubleStack нельзя использовать вместо Stack.
У этого принципа есть забавное следствие: Объекты, моделирующие сущности, не обязаны реализовывать отношения этих сущностей. Например, у нас есть целые и вещественные числа, причем целые числа — подмножество вещественных. Однако, double состоит из двух int: мантисы и экспоненты. Если бы int наследовал от double, то получилась бы забавная картина: родитель содержит 2-х своих детей.
В качестве второго примера можно привести Generics. Допустим, есть базовый класс Shape и его потомки Circle и Rectangle. И есть некая функция Foo(List list). Мы считаем, что List можно привести к List. Однако, это не так. Допустим, это приведение возможно, но тогда в list можно добавить любую фигуру, например rectangle. А изначально list должен содержать только объекты класса Circle.
Make fine grained interfaces that are client specific.
Под интерфейсом здесь понимается именно Java, C# интерфейс. Разделение интерфейса облегчает использование и тестирование модулей.
Depend on abstractions, not on concretions.
Что такое модули верхних уровней? Как определить этот уровень? Как оказалось, все очень просто. Чем ближе модуль к вводу/выводу, тем ниже уровень модуля. Т.е. модули, работающие с BD, интерфейсом пользователя, низкого уровня. А модули, реализующие бизнес-логику — высокого уровня.
Что такое зависимость модулей? Это ссылка на модуль в исходном коде, т.е. import, require и т.п. С помощью динамического полиморфизма в runtime можно обратить эту зависимость.
Есть модуль Logic, реализующий логику, который должен отсылать уведомления. В этом же пакете объявляется интерфейс ISender, который используется Logic. Уровнем ниже, в другом пакете объявляется ConcreteSender, реализующий ISender. Получается, что в момент компиляции Logic не зависит от ConcreteSender. В runtime, например, через конструктор в Logic устанавливается экземпляр ConcreteSender.
Отдельно стоит отметить частый вопрос “Зачем плодить абстракции, если мы не собираемся заменять базу данных?”.
Логика тут следующая. На старте проекта, мы знаем, что будем использовать реляционную базу данных, и это точно будет Postgresql, а для поиска — ElasticSearch. Мы даже не планируем их менять в будущем. Но мы хотим отложить принятие решений о том, какая будет схема таблиц, какие будут индексы, и т.п. до момента, пока это не станет проблемой. И на этот момент мы будем обладать достаточной информацией, чтобы принять правильное решение. Также мы можем раньше отладить логику нашего приложения, реализовать интерфейс, собрать обратную связь от заказчика, и минимизировать последующие изменения, ведь многое реализовано только в виде заглушек.
Принципы SOLID подходят для проектов, разрабатываемых по гибким методологиям, ведь Роберт Мартин — один из авторов Agile Manifesto.
Принципы SOLID стремятся свести изменение модулей к их добавлению и удалению.
Принципы SOLID способствуют откладыванию принятия технических решений и разделению труда программистов.
Как и любой инструмент, принципы проектирования нужно применять с умом.
Можно выделить два случая, когда применение принципов проектирования приведет к увеличению проблем, и не приведет ни к чему хорошему.
YAGNI
Подробности — в ответе на вопрос «Нарушает ли OCP и DIP (из SOLID) принцип YAGNI?».
Принципы проектирования предназначены для смягчения определенной проблемы разработки (да, именно «смягчения», но не решения проблемы), добавляя при этом свои собственные проблемы.
Поскольку иногда проблемы программисты придумывают себе сами, то следование (особенно буквальное) принципам проектирования приведет к перекосу дизайна, не решая при этом реальной проблемы.
Другими словами, чрезмерное увлечения принципами проектирования может привести к переусложненному решению там, где эта сложность не нужна.
«over»-SOLID
Подробнее в статье «О принципах проектирования».
Есть ряд типовых паталогических случаев использования SOLID-принципов:
Anti-SRP – Принцип размытой ответственности. Классы разбиты на множество мелких классов, в результате чего логика размазывается по нескольким классам/модулям.
Anti-OCP – Принцип фабрики фабрик. Дизайн является слишком обобщенным и расширябельным, выделяется слишком большое число уровней абстракции.
Anti-LCP – Принцип непонятного наследования. Принцип проявляется либо в чрезмерном количестве наследования, либо в его полном отсутствии, в зависимости от опыта и взглядов местного главного архитектора.
Anti-ISP – Принцип тысячи интерфейсов. Интерфейсы классов разбиваются на слишком большое число составляющих, что делает их неудобными для использования всеми клиентами.
Anti-DIP – Принцип инверсии сознания или DI-головного мозга. Интерфейсы выделяются для каждого класса и пачками передаются через конструкторы. Понять, где находится логика становится практически невозможно.
Про принципы SOLID в сети есть много информации. В каких-то местах – она заумная до ужаса, в каких-то – описано понятным человеческим языком. Почему-то, в последнее время я не могу терпеть слишком заумных объяснений. На поверку дня убеждаюсь, что человек, который действительно знает о чем говорит, всегда может объяснить вещи “человеческим” или более понятным языком, чем принято в кандидатских работах.
Но про принципы GRASP написано немного, а многое из того что написано – отравляет понимание своей заумностью. Конечно вопрос не из простых. Но и сложность тоже не космическая.
Итак, пункт первый – зачем эти принципы?
Объектно-ориентированное программирование (ООП) – я бы сказал, что это набор основных концепций (абстракция, инкапсуляция, наследование, полиморфизм), конструкций (классы, методы) и принципов. ООП – это модель, обобщенная модель части предметной или объектной области для программирования окружающего. Это программирование по обобщенной модели, выражение объектной модели в терминах языка программирования. И модель эта, как и любая другая модель, - осознано ограничена.
Так вот, громадной частью ООП является набор принципов. И тут вроде бы все ясно. Только вот принципов много. И разные авторы выделяют как основные иногда схожие, а иногда и разные принципы, и что удивительно – все правильные.
Моделировать – не сложно. Только проблема в том что мы все таки имеем дело с моделью. А когда объекты (сущности) уже созданы, тогда вступает в игру именно программирование и проектирование. Объекты должны взаимодействовать и при этом модель должна быть гибкой и простой. Вот тут нам и помогают принципы.
GRASP – это набор принципов по версии такого эксперта как Крэг Ларман, который написал о них в своей книге - Applying UML and Patterns: An Introduction to Object-Oriented Analysis and Design and Iterative Development Книга как и книга GoF(Gang of four) заняла свое место в истории и соответственно принципы GRASP, которым посвящена малая часть книги тоже.
Возможно, они не так популярны как скажем принципы SOLID, скорее всего, мне кажется, потому что они определенны более обобщенными. Эти принципы более абстрактные чем шаблоны GoF или SOLID.
Итак принципы GRASP, точнее сказать не принципы, а шаблоны в оригинале. General Responsibility Assignment Software Patterns – это можно перевести так – паттерны распределения ответственности. Суть в том, что это не строгие паттерны как у GoF, это скорее тот смысл, которым мы наделяем объекты. Так что принципы распределения общей ответственности подходит больше чем паттерны. И поэтому название статьи не шаблоны GRASP как было бы идеологически верно, а все таки принципы GRASP.
GRASP выделяет следующие принципы-шаблоны:
Теперь давайте рассмотрим каждый из них по порядку.
Информационный эксперт или просто эксперт – это скорее ответственность. Экспертом может быть любой класс. Тут даже дело не в проектировании, а в осведомленности. Зачем нам нужен информационный эксперт? Затем, что если объект владеет всей нужной информацией для какой-то операции или функционала, то значить и этот объект будет выполнять либо делегировать выполнение этой операции.
Итак рассмотрим пример. Есть некая система продаж. И есть класс Sale (продажа). Нам необходимо посчитать общую сумму продаж. Тогда кто будет считать общую сумму по продажам? Конечно же класс – Sales, потому что именно он обладает всей информацией необходимой для этого.
Creator или Создатель – суть ответственности такого объекта в том, что он создает другие объекты. Сразу напрашивается аналогия с фабриками. Так оно и есть. Фабрики тоже имеют именно ответственность – Создатель.
Но есть ряд моментов, которые должны выполнятся, когда мы наделяем объект ответственность создатель:
1. Создатель содержит или агрегирует создаваемые объекты
2. Создатель использует создаваемые объекты
3. Создатель знает как проинициализировать создаваемый объект
4. Создатель записывает создаваемые объекты (эту штуку я до конце не понял на самом деле)
Уже где-то слышали, не правда ли? Controller или Контролер – это объект-прослойка между UI логикой и предметной (бизнес) логикой приложения. Создаем контроллер так чтобы все вызовы от UI перенаправлялись именно ему и соответственно все данные UI тоже получает через него.
Напоминает MVC, MVP? Так и есть. Это по сути Presenter из MVP и контроллер из MVC. Разница между MVC и MVP есть, но это касается только направлений вызовов, ну и это тему естественно другой беседы.
Итак, котроллер отвечает на такой вопрос: “Как UI должен взаимодействовать с доменной логикой приложения?” или просто “Как взаимодействовать с системой?”. Это чем то напоминает фасад. Фасад тоже предоставляет облегченный доступ к целой подсистеме объектов. Так и тут контроллер для UI своего рода фасад которые предоставляет доступ к целой подсистеме бизнес логики.
Тоже известная штука. Low Coupling или Слабая связанность. Если объекты в приложении сильно связанны то любой изменение приводит к изменениям во всех связанных объектах. А это неудобно и порождает баги. Вот по-этому везде пишут что необходимо чтобы код был слабо связан и зависел от абстракций.
Например если наш класс Sale реализует интерфейс ISale и другие объекты зависят именно от ISale, т.е. от абстракции, то когда мы захотим внести изменения касательно Sale – нам нужно будет всего лишь подменить реализацию.
Low Coupling встречается и в SOLID принципах в виде – Dependency Injection. Сейчас можно часто услышать такой принцип. Но суть остается прежней: “Программируйте на основе абстракций (интерфейс, абстрактный класс и т.п.), а не реализаций”.
High Cohesion или высокая сцепленность – это соотносится к слабой связанности, они идут в паре и одно всегда приводит к другому. Это как инь и янь, всегда вместе. Дело в том что наши классы когда мы их задумываем имеют какую-то одну ответственность (Single resposibility principle), например Sale(продажа) обладает всеми ответственностями которые касаются продаж, например как мы уже говорили вычисление общей суммы – Total. Но давайте представим что мы совершили оплошность и привнесли в Sale еще такую ответственность как Payment (платеж). Что получится? Получится что одни члены класса которые касаются Sale буду между собой достаточно тесно связанны, и также членные класса которые оперируют с Payment между собой будут тесно связаны, но в целом сцепленность класса SaleAndPayment будет низкой, так как по сути мы имеем дело с двумя обособленными частями в одном целом. И резонно будет провести рефакторинг и разделить класс SaleAndPayment на Sale и Payment, которые внутри будут тесно связанны или по другому сцеплены.
Так что высокая сцепленность это как мера того что мы не нарушаем single resposibility principle. Вернее сказать, выскоая сцепленность получается в результате соблюдения такого приципа из SOLID как single resposibility principle (SRP).
Основной вопрос на который дает ответ высокая сцепленность – “Как поддерживать объекты сфокусированными на одной ответственности, понятными, управляемыми и как побочный эффект иметь слабо связанный код?”. Их разделять. Подробнее это описано в 17 главе книги Лармана.
Pure Fabrication или чистая выдумка или чистое синтезирование. Суть в выдуманном объекте. Такой себе принцип-хак. Но без него никак. Аналогом может быть шаблон Service(сервис) в парадигме DDD.
Иногда, сталкиваемся с таким вопросом: “Какой объект наделить ответственностью, но принципы информационный эксперт, высокая сцепленность не выполняются или не подходят?”. Использовать синтетический класс который обеспечивает высокую сцепленность. Тут без примера точно не разобраться.
Итак – ситуация. Какой класс должен сохранять наш объект Sale в базу данных? Если подчиняется принципу “информационный эксперт”, то Sale, но наделив его такой ответственностью мы получаем слабую сцепленность внутри него. Тогда можно найти выход, создав синтетическую сущность – SaleDao или SaleRepository, которая будет сильно сцеплена внутри и будет иметь единую ответственность – сохранять Sale в базу.
Так как мы выдумали этот объект а не спроектировали с предметной области, то и он подчиняется принципу “чистая выдумка”.
Indirection или посредник. Можно столкнутся с таким вопросом: “Как определить ответственность объекта и избежать сильной связанности между объектами, даже если один класс нуждается в функционале (сервисах), который предоставляет другой класс?” Необходимо наделить ответственностью объект посредник.
Например возвратимся опять же MVC. UI логике на самом деле нужен не контроллер, а модель, доменная логика. Но мы не хотим? чтобы UI логика была сильно связанна с моделью, и возможно в UI мы хотим получать данные и работать с разной предметной логикой. А связывать UI слой с бизнес логикой было бы глупо, потому что получим код который будет сложный для изменений и поддержки. Выход – вводим контроллер как посредника между View и Model.
Так что распределяйте ответственности своим объектам ответственно (с умом).
Protected Variations или сокрытие реализации или защищенные изменения. Как спроектировать объекты, чтобы изменения в объекте или объекта не затрагивали других? Как избежать ситуации когда меняя код объекта придется вносить изменения в множество других объектов системы?
Кажется мы такое обсуждали уже. И пришли к выводу что нужно использовать low coupling или dependency injection. Именно! Но суть в принципа немного в другом. Суть в том чтобы определить “точки изменений” и зафиксировать их в абстракции (интерфейсе). “Точки изменений” – не что иное как наши объекты, которые могут меняться.
То есть суть в принципа, чтобы определить места в системе, где поведение может изменится и выделить абстракцию, на основе которой и будет происходить дальнейшее программирование с использованием этого объекта.
Все это делается для того чтобы обеспечить устойчивость интерфейса. Если будет много изменений связанных с объектов, он, в таком ключе, считается не устойчивым и тогда нужно выносить его в абстракцию от которой будем зависеть, либо распределять обязанности и ответственность в код иным образом
Polymorphism или полиморфизм. Тоже знакомо, не так ли? Так вот это об том же полиморфизме, который мы знаем из ООП. Если заметить то достаточно много паттернов GoF, да и вообще паттернов, построено на полиморфизме. Что он дает?Он дает возможность трактовать однообразно разные объекты с одинаковым интерфейсом (спецификацией). Давайте вспомним такие паттерны как Strategy, Chain of Resposibility, Command… – их много. И все по своей суть основываются на полиморфизме.
Полиморфизм решает проблему обработки альтернативных вариантов поведения на основе типа. Тут яркий пример это шаблон GoF – Strategy (Стратегия).
Например, для реализации гибкого функционала для шифрования можно определить интерфейс IEncryptionAlgorithm с методом Encrypt, и объект создатель, который вернет IEncryptionAlgorithm, создав внутри себя актуальную реализацию этого интерфейса.
Писать код качественно абсолютно не сложно. Через пару итераций те штуки, за которыми раньше разработчики следили, становятся естественными (вырабатывается внутренняя культура). Надо только правильно настроить процесс. Не утаю, что вначале это будет отнимать лишнее время. Но вскоре все окупится с торицей.
Анализ данных, представленных в статье про качество кода, подтверждает эффективность применения современных технологий для обеспечения инновационного развития и улучшения качества жизни в различных сферах. Надеюсь, что теперь ты понял что такое качество кода, ооп, оод, ооа, solid, grasp и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Проектирование веб сайта или программного обеспечения

Комментарии