Лекция
Привет, сегодня поговорим про задачи параллельных вычислений, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое задачи параллельных вычислений, чрезвычайная параллельность , настоятельно рекомендую прочитать все из категории Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы.
Параллельные вычисления — способ организации компьютерных вычислений, при котором программы разрабатываются как набор взаимодействующих вычислительных процессов, работающих параллельно (одновременно). Термин охватывает совокупность вопросов параллелизма в программировании, а также создание эффективно действующих аппаратных реализаций. Теория параллельных вычислений составляет раздел прикладной теории алгоритмов .
Существуют различные способы реализации параллельных вычислений. Например, каждый вычислительный процесс может быть реализован в виде процесса операционной системы, либо же вычислительные процессы могут представлять собой набор потоков выполнения внутри одного процесса ОС. Параллельные программы могут физически исполняться либо последовательно на единственном процессоре — перемежая по очереди шаги выполнения каждого вычислительного процесса, либо параллельно — выделяя каждому вычислительному процессу один или несколько процессоров (находящихся рядом или распределенных в компьютерную сеть).
Основная сложность при проектировании параллельных программ — обеспечить правильную последовательность взаимодействий между различными вычислительными процессами, а также координацию ресурсов, разделяемых между процессами.
чрезвычайная параллельность (чрезвычайно параллельная задача, англ. embarrassingly parallel) — тип задач в системах параллельных вычислений, для которых не требуется прилагать больших усилий при разделении на несколько отдельных параллельных задач (распараллеливании). Чаще всего не существует зависимости (или связи) между этими параллельными задачами, то есть их результаты не влияют друг на друга.
Чрезвычайно параллельные задачи практически не требуют согласования между результатами выполнения отдельных этапов, что отличает их от задач распределенных вычислений, которые требуют связи промежуточных результатов. Параллельные задачи легки для исполнения на серверных фермах (серверных кластерах), они хорошо подходят для больших распределенных платформ в Интернете, таких как BOINC.
Типичным примером чрезвычайно параллельной задачи является работа графического процессора (GPU) при расчете 3D проекций, когда каждый пиксель на экране может рассчитываться самостоятельно.
Построении вычислительных систем с максимальной производительностью
Поиск методов разработки эффективного программного обеспечения для параллельных вычислительных систем
Некоторые примеры чрезвычайно параллельных задач:
В некоторых параллельных системах программирования передача данных между компонентами скрыта от программиста (например, с помощью механизма обещаний), тогда как в других она должна указываться явно. Об этом говорит сайт https://intellect.icu . Явные взаимодействия могут быть разделены на два типа:
Параллельные системы, основанные на обмене сообщениями, зачастую более просты для понимания, чем системы с разделяемой памятью, и обычно рассматриваются как более совершенный метод параллельного программирования. Существует большой выбор математических теорий для изучения и анализа систем с передачей сообщений, включая модель акторов и различные виды исчислений процессов. Обмен сообщениями может быть эффективно реализован на симметричных мультипроцессорах как с разделяемой когерентной памятью, так и без нее.
У параллелизма с распределенной памятью и с передачей сообщений разные характеристики производительности. Обычно (но не всегда), накладные расходы памяти на процесс и времени на переключение задач у систем с передачей сообщений ниже, однако передача самих сообщений более накладна, чем вызовы процедур. Эти различия часто перекрываются другими факторами, влияющими на производительность.
Разумеется в такой системе можно также использовать и исключительно метод передачи сообщений, то есть запустить на каждом процессоре каждого узла отдельный процесс. В этом случае количество процессов (и потоков) будет равно количеству процессоров на всех узлах. Этот способ проще (в параллельной программе надо только увеличить количество процессов), но является менее эффективным, так как процессоры одного и того же узла будут обмениваться друг с другом сообщениями, словно они находятся на разных машинах .
Ускорение программы с помощью параллельных вычислений на нескольких процессорах ограничено размером последовательной части программы. Например, если можно распараллелить 95 % программы, то теоретически максимальное ускорение будет 20-кратным, невзирая на то, сколько процессоров используется.
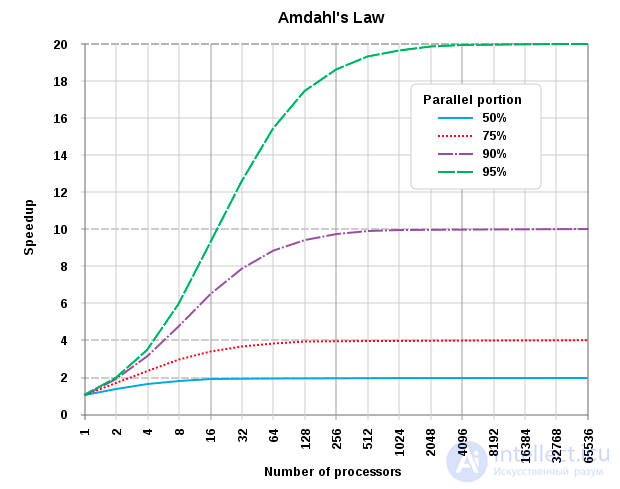
Закон Амдала (англ. Amdahl's law, иногда также Закон Амдаля — Уэра) — иллюстрирует ограничение роста производительности вычислительной системы с увеличением количества вычислителей. Джин Амдал сформулировал закон в 1967 году, обнаружив простое по существу, но непреодолимое по содержанию ограничение на рост производительности при распараллеливании вычислений: «В случае, когда задача разделяется на несколько частей, суммарное время ее выполнения на параллельной системе не может быть меньше времени выполнения самого медленного фрагмента» . Согласно этому закону, ускорение выполнения программы за счет распараллеливания ее инструкций на множестве вычислителей ограничено временем, необходимым для выполнения ее последовательных инструкций.
Пусть необходимо решить некоторую вычислительную задачу. Предположим, что ее алгоритм таков, что доля {\displaystyle \alpha } от общего объема вычислений может быть получена только последовательными расчетами, а, соответственно, доля {\displaystyle 1-\alpha }
от общего объема вычислений может быть получена только последовательными расчетами, а, соответственно, доля {\displaystyle 1-\alpha } может быть распараллелена идеально (то есть время вычисления будет обратно пропорционально числу задействованных узлов {\displaystyle p}
может быть распараллелена идеально (то есть время вычисления будет обратно пропорционально числу задействованных узлов {\displaystyle p} ). Тогда ускорение, которое может быть получено на вычислительной системе из {\displaystyle p} процессоров, по сравнению с однопроцессорным решением не будет превышать величины
). Тогда ускорение, которое может быть получено на вычислительной системе из {\displaystyle p} процессоров, по сравнению с однопроцессорным решением не будет превышать величины

Таблица показывает, во сколько раз быстрее выполнится программа с долей последовательных вычислений {\displaystyle \alpha } при использовании процессоров.
| \ |
10 | 100 | 1 000 |
|---|---|---|---|
| 0 | 10 | 100 | 1 000 |
| 10 % | 5,263 | 9,174 | 9,910 |
| 25 % | 3,077 | 3,883 | 3,988 |
| 40 % | 2,174 | 2,463 | 2,496 |
Из таблицы видно, что только алгоритм, вовсе не содержащий последовательных вычислений (  ), позволяет получить линейный прирост производительности с ростом количества вычислителей в системе. Если доля последовательных вычислений в алгоритме равна 25 %, то увеличение числа процессоров до 10 дает ускорение в 3.077 раз, а увеличение числа процессоров до 1000 даст ускорение в 3.988 раз.
), позволяет получить линейный прирост производительности с ростом количества вычислителей в системе. Если доля последовательных вычислений в алгоритме равна 25 %, то увеличение числа процессоров до 10 дает ускорение в 3.077 раз, а увеличение числа процессоров до 1000 даст ускорение в 3.988 раз.
Отсюда же очевидно, что при доле последовательных вычислений общий прирост производительности не может превысить  . Так, если половина кода — последовательная, то общий прирост никогда не превысит двух.
. Так, если половина кода — последовательная, то общий прирост никогда не превысит двух.
Закон Амдала показывает, что прирост эффективности вычислений зависит от алгоритма задачи и ограничен сверху для любой задачи с  . Не для всякой задачи имеет смысл наращивание числа процессоров в вычислительной системе.
. Не для всякой задачи имеет смысл наращивание числа процессоров в вычислительной системе.
Более того, если учесть время, необходимое для передачи данных между узлами вычислительной системы, то зависимость времени вычислений от числа узлов будет иметь минимум. Это накладывает ограничение на масштабируемость вычислительной системы, то есть означает, что с определенного момента добавление новых узлов в систему будет увеличивать время расчета задачи.
В общем, мой друг ты одолел чтение этой статьи об задачи параллельных вычислений. Работы впереди у тебя будет много. Смело пиши комментарии, развивайся и счастье окажется в твоих руках. Надеюсь, что теперь ты понял что такое задачи параллельных вычислений, чрезвычайная параллельность и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы
Комментарии
Оставить комментарий
Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы
Термины: Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы