Лекция
Привет, сегодня поговорим про языковая структура, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое языковая структура, диаметр сообщения, алгоритм шеворошкина-сухотина, координатная сетка алисы кобер, алгоритм хэрриса, анализ текста , настоятельно рекомендую прочитать все из категории Искусственный интеллект.
языковая структура
Понимание языкового сообщения сродни дешифровке. Применение логики помогает понять неизвестное сообщение. Этот принцип есть основа машинного понимания текста.
Письменность хеттских племен была расшифрована благодаря закономерностям в языке. Было найдено шесть табличек, и была выдвинута гипотеза о том, что им соответствуют шесть понятий: две страны (Хамату и Палаа), два города (Куркума, Туванава) и два царя (Варпалава, Таркумува).

Сосчитаем количество слогов в известных нам словах и количество знаков в табличках. Количество знаков равно количеству слогов плюс один. Первый вывод - это письмо слоговое. Заметим, что некоторые знаки встречаются только в конце. Очевидно, что это какие-то служебные символы. Продолжая рассуждения, мы придем к выводу, что одному знаку соответствует один слог.
Рассматривая первую табличку и сравнивая ее со словом Вар-па-ла-ва, можно сообразить, что первый и четвертый знаки, как и слоги, одинаковы, за исключением черточки и буквы "р". Значит черточка означает букву "р". Зная, как пишется "ва", можно определиться с третьей и шестой табличкой. Вторая табличка - Куркума, так как два одинаковых идут слога друг за другом и есть черточка, означающая букву "р". теперь мы знаем, как пишется "ма". Легко найти "Хамату" на шестой табличке. Зная все переводы, логически установим смысл служебных знаков в конце слов. Последний знак говорит о классе понятия - страна, город, царь. Заметим, что возможна расшифровка и другим путем, значит информация избыточна. После расшифровки можно написать самому сообщение на хеттском языке.
Задание 5. Напишите на хеттском языке "царь Артур", "город Тарту", "страна Тува", "город Нарва", "царь Парта".
Расшифровка в данном случае была упрощена тем, что мы имели дело с билингвой. Имелась информация на двух языках сразу. Поэтому расшифровке поддался достаточно небольшой текст.
Расшифровка языка Муйув (Папуа-Новая Гвинея)
Известные фразы:
atok - Я стою около него.
kuton - Ты стоишь в стороне.
isiw - Он остается около тебя.
kusim - Ты остаешься около меня.
iw - Он идет к тебе.
Расшифровка с учетом закономерностей
1. a - я;
ku - ты;
i - он;
2. w - к тебе;
m - ко мне;
k - к нему;
n - в сторону;
3. to - стоять;
si - остается;
_ - идет.
ak - Я иду к нему.
asin - Я остаюсь в стороне.
kun - Ты уходишь.
В тексте присутствуют неоднозначности, в силу того, что мы сами говорим неоднозначно.
Пример. "Письма знакомой из Киева не заменят фотографии его любимой и милой дочери Марии" - фраза, имеющая более 1000 смыслов. Обратите внимание:
- "письма (чьи?) знакомой" или "письма (кому?) знакомой";
- письма из Киева или знакомая из Киева?
- дочери (кого) Марии или дочери по имени Мария?
- "любимая" и "милая дочь" это одно лицо или два разных человека?
Расшифровка сообщений - процесс итерационный. Выдвигается какая-либо гипотеза, если далее по тексту она не подтверждается, то мы вынуждены возвращаться и менять гипотезу.
Чем больше сообщение, тем меньше неоднозначности будет при восприятии текста. Поэтому требуется передавать избыточные сообщения. Чем больше текста, тем больше вероятность, что вас поймут. Диаметр сообщения для однозначного его прочтения зависит от числа графем (гавайский - 19, русский - 33, армянский - 38), от числа звуков, обозначенной одной графемой (твердые - мягкие), от степени избыточности (количества знаков дублирующих друг друга). Обычно у буквенных языков избыточность составляет 70 -80%. У словесного языка (Китай) избыточность - 50%. У слогового - 60%.
Наименьшая длина сообщения для однозначного прочтения называется диаметром сообщения. В гавайском языке диаметр составляет 20 знаков, в русском языке - 70 знаков, в армянском - 80 знаков, в китайском - 1000000 знаков.
Еще закономерности.
Начало письма там, где выровнен край. Грамматических морфем (окончания, предлоги, союзы) меньше, чем лексических (корни). Они чаще встречаются и сочетаются с большим числом разнообразных лексических морфем. Текст сжимается к концу строки. Перед глаголом не может быть предлога. Между подлежащим и сказуемым не бывает союза. И так далее. Общий свод правил пока не составлен. Выявляют закономерности и более сложными исследованиями.
Вот как работает алгоритм отделения гласных от согласных. Возьмем фразу из статьи "Загадочные письмена" "Один из..." и представим себе, что перед нами текст на неизвестном языке. Где здесь гласные, а где согласные? Запишем текст без пробелов между словами, но оставляя знаки препинания - они как бы разрывают звуковую цепь. Для каждой буквы выпишем всех ее непосредственных левых и правых соседей внутри звуковой цепи. Для первой буквы о это будут сочетания: од, бол, ров, воч, гор, мов, бот, хот, вор, рош, ров, ког, гоп (удобнее записывать их в столбик). Теперь выделим повторяющиеся пары (независимо от того, какая буква является левым, а какая правым соседом). Для первых четырех букв о, д, и, н получим:
| Для о | Для д | Для и | Для н |
| о: в (5 раз) о: р (5 раз) о: г (3 раза) о: б (2 раза) о: т (2 раза) |
д: и (2 раза) д: е (2 раза) |
и: н (5 раз) и: р (4 раза) и: ш (3 раза) и: д (2 раза) и: т (2 раза) и: ф (2 раза) и: м (2 раза) |
н: и (5 раз) н: ы (4 раза) н: е (3 раза) н: а (2 раза) н: с (2 раза) |
Из первого и третьего можно предположить, что о и и относят-ся к одному классу, так как у них общие соседи р и т тогда в, р, г, б, т, н. д, ш, ф, м относятся к другому классу. Но из четвертого следует, что н в свою очередь противопоставлено и, ы, е, а, с, которые должны принадлежать к первому классу.
Таким образом, мы получаем разбиение: первый класс - о, и, ы, е, а, с; второй класс - в, р, г, б, т, н, д, ш, ф, м. Данные второго пункта подтверждают его.
Как решить, какой из выделенных классов составляют гласные, а какой - согласные? Обычно в звуковой системе языка разных гласных меньше, чем разных согласных; соответственно и в алфавите гласных букв должно быть меньше. Очевидно, первый класс - гласные, второй - согласные. Вы видите, что в одном случае алгоритм дал ошибку: с попала в класс гласных. Однако если взять более длинный текст для анализа, скорее всего ошибка исчезнет.
Выводы сделаны на очень небольшом материале, и тем не менее мы получили верное распределение для 15 букв из 16. Алгоритм Шеворошкина - Сухотина проверяли на материале русского, английского, немецкого, французского и испанского языков в текстах по 10 тыс. знаков. На материале немецкого языка алгоритм дал три ошибки (за счет однозвучных буквосочетаний), на английском, русском и французском материале - по одной ошибке, на испанском - ни одной.
координатная сетка алисы кобер
Идея Алисы Кобер в общих чертах заключается в том, чтобы, словно рентгеновским лучом, просветить структуру слоговых знаков неизвестного письма, отделив согласные от гласных.
Анализируя критские глиняные таблички, Алиса Кобер обнаружила, что в них записаны изменяемые слова. На это указывали общие знаки основы и разные окончания. Многие из слов могли быть существительными - при них стояли числа (знаки для чисел дешифровал еще Эванс). Изменяемые слова можно было собрать в парадигмы - вроде наших склонений. Только у критских существительных в текстах выделялись всего три падежные формы. Если сопоставить с русскими словами, это могло выглядеть, допустим, так:
| раб-а | дом-а |
| раб-ами | дом-ами |
| раб-у | дом-у |
В критском письме эти слова записывались бы слоговыми знаками:
| x1-y1 | x2-y2 |
| ра-ба | до-ма |
| х1-у1-а | x2-y2-a |
| ра-ба-ми | до-ма-ми |
| x1-z1 | x2-z2 |
| ра-бу | до-му. |
Здесь х - графическая основа слов, у, уа, z - разные падежные окончания.
Исследуя изменяющиеся слова, Вентрис заметил, что в роли у используются не любые знаки, а лишь немногие. Из этого он заключил, что в разных у имеется один и тот же гласный Г1, характерный для данного падежного окончания, и разные согласные (С1, С2...), относящиеся к разным корням. Тогда для каждой тройки тот же конечный согласный корня (С1, С2...) должен иметься и в z в паре с другим гласным Г2, соответствующим третьему падежному окончанию.
Этот вывод можно представить в виде таблицы:
| Согласный | Гласный | |
| Г1 | Г2 | |
| C1 | y1(ба) | z1 (бу) |
| С2 | y2 (ма) | z2 (му) |
Эта таблица и есть зародыш координатной сетки, открывающей два измерения критских слоговых знаков - "согласное" и "гласное". Отыскивая новые "существительные", продолжим ряд С (допустим, стол-а - С3 = л, жук-а - С4= к). Отыскивая новые типы изменений слов, можно продолжить ряд гласных. Если учесть все типы слов (допустим, могут быть изменения типа грамматического рода прилагательных - хорош-ая, хорош-ий, хорош-ее), то в виде подобной таблицы, но с гораздо большим числом ячеек можно представить всю грамматику языка (систему изменений слов), по крайней мере используемую в текстах.
Пока, однако, в таблице - координатной сетке - еще нет ни одного звукового значения, которое могло бы связать полученную грамматику с конкретным языком (наши русские подстановки не в счет). Об этом говорит сайт https://intellect.icu . Вот эти конкретные звуковые значения и надо получить методом подстановки, пробуя грамматические окончания разных языков. Правильно найденный язык, оказавшись "ключом", сразу откроет звуковые значения многих знаков, из которых сложатся слова известного языка.
А. Кобер указала путь, по которому в процессе систематических и кропотливых поисков можно прийти к верному результату. Пройти этот путь до конца сумел Майкл Вентрис.
Выдающийся представитель американской дескриптивной лингвистики Зеллиг Хэррис (1909-1992) разработал алгоритм деления высказывания на морфемы на незнакомом языке. Обычно, когда требуется разобрать слово по составу, мы ищем однокоренные слова, т. е. слова, сходные не только по звучанию, но и по значению. Алгоритм Хэрриса хорош тем, что он не требует обращения к значению, ведь он задуман для работы с неизвестным языком. Однако информацию об исследуемом языке алгоритм, конечно, получает - в виде исходного текста большого объема, из которого выбирают высказывание для анализа. Текст обрабатывают не вручную, а на компьютере.
Идея, лежащая в основе алгоритма, проста и знакома многим по игре в "балду". Играющие по очереди составляют слово из букв. Первая буква может быть любой, с каждой следующей возможность выбора значительно уменьшается, а для последней обычно остается только один вариант. Примерно так же строится и связный текст. Неопределенность выбора буквы (количество вариантов) постепенно падает от начала к концу слова и резко возрастает на границах слов.
Итак, в исходном тексте (где слова могут быть записаны без пробелов, а у Хэрриса еще и в фонетической транскрипции - ведь он работал с бесписьменными индейскими языками) выбирают для анализа некоторое высказывание. Его можно рассматривать как цепочку букв или знаков транскрипции между точками или паузами. На первом шаге берут первую букву высказывания и выписывают из текста все ее сочетания с другими буквами. Например, такое высказывание: На выходе получим новое разбиение. Проверив весь текст, выясняют, что н встречается в сочетаниях: на, но, ни, не, ны, ну, нн, нт, нс, нч, т. е. за н в тексте следуют всего десять разных "преемников".
На втором шаге исследуют буквосочетание на. У него во всем тексте встречаются следующие продолжения: в, д, с, м, х, я, ш, з, р, ч, б, г; всего 12 "преемников". На третьем шаге исследуем буквосочетание нав. Для него обнаружились всего четыре "преемника": ы, о, и, с. Эту процедуру повторяют до конца высказывания, добавляя на каждом шаге по одной букве к проверяемому буквосочетанию. Результаты - число "преемников" - заносят в таблицу:
| н | на | нав | навы | ... |
| 10 | 12 | 4 | 2 | ... |
Если верна исходная гипотеза, что разнообразие букв больше на границах слов (морфем), чем внутри слова (морфемы), то большие числа должны указывать на такие границы - пики неопределенности. В данном примере наибольшее число 12, после него и проводят морфемную границу.
Чтобы уточнить результаты деления на морфемы, эту же процедуру проделывают от конца высказывания, вычисляя число "предшественников" сначала последней буквы, затем двух последних и т. д. Отделив часть слова от границы, можно начать процедуру анализа со следующей исходной точки, в данном случае со слова выходе.
Надежность результата зависит от объема текста. Алгоритм Хэрриса проверили на 100 предложениях английского текста, в 85 % случаев морфемы оказались выделены правильно. Правда, тексты пришлось взять в транскрипции: английская орфография заметно отстала от развития самого языка.
Еще о дешифровке сообщении на различных языках можно прочитать подробнее...
Покажем фрагмент математической модели русского языка.

Используя эту модель можно провести как анализ слов, так и синтез слов в предложении. Заметим, что это не полная таблица.
Анализ текста происходит по следующему алгоритму.
По списку знаков препинания текст и предложения следует разбить на слова.
Определить окончания у каждого слова.
Определить часть речи и уточнить атрибуты у каждого слова. Конфликты разбираются с помощью ряда специальных правил (например: у глагола нет предлога; глагол на "-оть" употребляется с существительным в винительном падеже без предлога; между подлежащим и сказуемым нет союза).
Определить части предложения (пример правила - дополнение - это существительное с предлогами для в родительном падеже, за в творительном падеже, под в винительном падеже, без в родительном падеже и так далее).
Определить субъекты и объекты в тексте и наличие связей между ними.
Объекты и субъекты образуют в своих отношениях модель проблемы. Привнесение вопроса к модели замыкает ее. Теперь можно решать любые обратные задачи, задавая вопросы к тексту.
Вопросы могут быть 4 уровней.
1 уровень.Вопросы, ответ на которые содержится в тексте. "Куда пошла Красная Шапочка?"
2 уровень.Вопросы, ответ на которые можно получить логическим выводом. "Что было раньше: выход из дома или вход в лес?"
3 уровень.Вопросы, для ответа на которые требуется наличие дополнительной базы знаний. "Где была Красная Шапочка между 13-00 и 15-00?". Здесь требуется знание скорости пешехода, характера Красной Шапочки, зависимости скорости, времени и пути, карты местности и так далее.
4 уровень.Вопросы, на которые можно найти ответ, зная модель поведения, аргументы поведения личности. "Почему Красная Шапочка не пошла в компании с охотниками?"
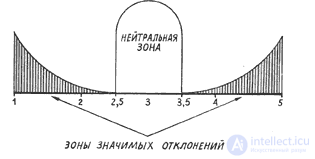
Слово обладает двумя свойствами: понятийное ядро и ореол. Понятийное ядро заключает в себе смысл, ореол - окраску слова. Например, слова папа, папулечка, отец несут один смысл (родитель - мужчина), но несут разную эмоциональную окраску. Но если ореол объективно существует, то его можно измерить.
Возьмем группу людей (для определенности - 50 чел.). И по шкале от 1 (очень хорошо) до 5 (очень плохо) просим определить оценку задаваемому слову. Измеряем частость оценок. Например, если на слово "дом" получили следующие оценки: 1 (очень хорошо) - 35 человек, 2 (хорошо) - 10 человек, 3 (нейтрально) -3 человек, 4 (плохо)- 2 человек, 5 (очень плохо) - 0 человек. Вычисляем среднее - 1*35+2*10+3*3+4*2+5*0=72; 72/50 = 1.44; 1.44 - ореол слова "дом". Померили ореолы других слов и нанесли на шкалу. Разные слова заняли разное положение на шкале.

Всего было опробовано около 75 шкал. Их назвали шкалами Осгуда. Из 75 - базовыми оказались три.
Фактор оценки (хорошее - плохое, светлое - темное и др.).
Фактор силы (большое - малое, сильное - слабое и др.).
Фактор активности (статичное - динамичное, быстрое - медленное, и др.).
Иногда выделяют еще одну шкалу родокомфортности (женское - мужское, круглое - угловатое, нежное - грубое и др.).
Три базовых шкалы отложили в пространстве - получили куб Осгуда. Любое слово имеет свою точку в кубе Осгуда.
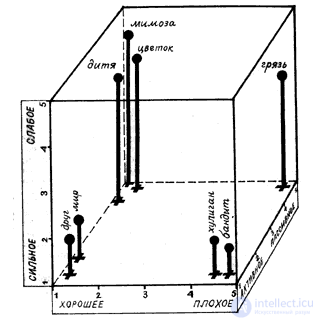
Но некоторые понятия могут и растекаться, иметь некоторую область, - например, "дождь".
В 60-х годах Ю. Орлов высказал мысль, что между звучанием и значением есть соответствие. Звуки измеримы по шкале Осгуда. о - светлый; р -устрашающий; к - быстрый; ш - медленный и т.д. По наличию звуков, можно вычислить слово и определить его местоположение в кубе Осгуда. При этом нужно учитывать следующие особенности:
слово нужно раскладывать на звуки, а не буквы (например, акно, йаблако);
требуется различать, какой звук идет за исследуемым;
нужно вносить поправку на ударение;
первый звук - самый важный; часто встречающиеся звуки - малозаметные.
Оценки, даваемые людьми, и оценки, получаемые в ходе разбора слова, совпадали. Можно понять смысл слова по его звучанию. Эта теория объясняет происхождение языка. Язык возникал как звукоподражание (шорох, рык, писк, шелест, набат, храп, лепет, взрыв).
Исследования (статистические опросы) показали, что звуки имеют цвет: а - густокрасный, е - зеленый, а - красный, и - синий, ю - голубоватый и т.д. Это значит, что тексты имеют окраску.
АОЕИ - опорные буквы и главные цвета (подобно RGB состовляющим).
Если соответствия звуков речи определенным цветам существуют, пусть даже в подсознании, то они должны где-то проявляться, звукоцвет должен как-то функционировать в речи. И пожалуй, прежде всего нужно искать проявление звукоцветовых ореолов в поэзии: там, где звуковая сторона особенно важна. Эффект звукоцвета может сыграть свою роль в том случае, когда в стихотворении создается определенная цветовая картина, и рисунок гласных стиха должен бы поддержать, <подсветить> эту картину звуками соответствующего цвета.
Если это так, то естественно ожидать, что при описании, например, красных предметов и явлений в тексте будет подчеркнута роль красных А и Я; они будут встречаться чаще, чем обычно, особенно в наиболее важных, наиболее заметных позициях (скажем, в ударных). Описание чего-либо синего будет сопровождаться нагнетением синих И, Ю, У; зеленого - нагнетением Е, Ё и т. д.
Стоило начать проверку этой гипотезы, как в сухих статистических подсчетах стала на глазах проявляться живая игра звукоцветовых ореолов поэтического языка, поражающая своей неожиданностью, своим разнообразием и точным соответствием понятийному смыслу и общему экспрессивно-образному строю произведений. Судите сами. У А. Блока есть стихотворение, которое он написал под впечатлением от картины В. Васнецова <Гамаюн, птица вещая>. Стихотворение о грозных пророчествах передает трагический колорит картины - мрачно-багровый цвет казней, пожаров, крови.
А. Блок
Гамаюн, птица вещая
На гладях бесконечных вод,
Закатом в пурпур облеченных,
Она вещает и поет,
Не в силах крыл поднять смятенных.
Вещает иго злых татар,
Вещает казней ряд кровавых,
И трус, и голод, и пожар,
Злодеев силу, гибель правых...
Предвечным ужасом объят,
Прекрасный лик горит любовью,
Но вещей правдою звучат
Уста, запекшиеся кровью!..
В тексте стихотворения (включая заголовок) подсчитывается количество каждой из 10 звукобукв, перечисленных в таблице. Чтобы учесть особую роль ударных гласных, они при счете удваиваются. Так как Ё, Я, Ю, Й связываются лишь с оттенками основных цветов и еще потому, что встречаются они сравнительно редко, самостоятельного значения в звукоцветовой картине стиха они не имеют. Поэтому приплюсовываются к основным гласным. Поскольку звукобуква Ё оказалась двухцветной, то ее количество разделяется поровну между О и Е. Синева Й выражена слабо, поэтому количество Й сокращается наполовину и только затем приплюсовывается к И. Подсчитывается также количество всех букв с удвоением ударных (величина N).
Затем определяются доля (частотность) каждой гласной в тексте стихотворения (Рк) и единицы размаха колебаний этих частотностей для данного текста:
q=SQRT[PN*(1-PN)/N]
Полученные частотности сопоставляются с нормальными (среднестатистическими для языка), и вычисляются нормированные разности этих частотностей, чтобы установить, случайно или нет наблюдаемые в стихотворении частотности отличаются от нормальных и как именно отличаются.
Z=(Pk-PN)/q
Звукоцвет в стихотворении "Гамаюн, птица вещая"
| Звукобуквы | n | Pk | PN | q | Z | Цвет |
| О+0,5 Ё | 28 | 0,089 | 0,126 | 0,019 | -1,95 | |
| А+Я | 50 | 0,159 | 0,116 | 0,018 | 2,39 | красный |
| Е+0,5 Ё | 31 | 0,098 | 0,102 | 0,017 | -0,24 | |
| И+0,5 Й | 20,5 | 0,065 | 0,077 | 0,015 | -0,80 | |
| У+Ю | 16 | 0,051 | 0,040 | 0,011 | 1,00 | темный сине-зеленый |
| Ы | 11 | 0,035 | 0,024 | 0,009 | 1,22 | черный, коричневый |
| Всего звукобукв в стихотворении 315 | ||||||
Как видим, звуков A и Я в обычной речи должно было бы встретиться 116 на тысячу, а в стихотворении их гораздо больше (Pk=0,159). При q=0,018 такое отклонение частотности (0,159 - 0,116 = 0,044 превышает случайное в 2,39 раза, то есть едва ли может быть случайным. Значит, поэт интуитивно нагнетал красные А и Я, чаще обеспечивая им ударные позиции (вещАет кАзней рЯд кровАвых). Вторым по превышению нормы идет Ы, придавая красному тону мрачное, трагическое звучание. Наконец, У (также с превышением частотности над нормой) добавляет звукоцветовой картине темные сине-зеленые и лиловые оттенки. Частотность всех остальных гласных ниже нормы. Если теперь изобразить в цвете игру доминирующих в стихотворении гласных, то получится картина в красно-багровой и черно-синей гамме, кое-где с темной прозеленью. А это и есть цветовая гамма картин Васнецова. Остается только поражаться, насколько точно талант поэта подсказал ему выбор и пропорции доминантных звукобукв.
Таким способом на компьютере "просчитано" много стихотворений. Для некоторых из них в общей табличке приведены итоговые величины (Z), чтобы можно было убедиться, что обнаруженные звукоцветовые соответствия - не парадокс статистики, не случайное совпадение цифр. Значимые превышения частотностей отмечены в табличке полужирным шрифтом. В последнем, восьмом столбце дана цветовая расшифровка полученных результатов.
8
| Стихотворения | Звукобуквы и величины | Цвет | |||||
| O+0,5 Ё | А+Я | Е+0,5 Ё | И+0,5 Й | У+Ю | Ы | ||
| А. Блок "Гамаюн, птица вещая" | -1,95 | 2,39 | -0,24 | -0,80 | 1,00 | 1,22 | темно-красный, темный сине-зеленый |
| С. Есенин "Отговорила роща золотая..." | 1,0 | -0,33 | 0,82 | 0,20 | -1,0 | -0,17 | желтый, зеленый |
| Арсений Тарковский "Перед листопадом" | 3,47 | 1,93 | -1,43 | -0,83 | -3,33 | 0,14 | желтый, красный |
| I строфа | 2,80 | 1,21 | -1,25 | -1,29 | -2,22 | -0,50 | желтый |
| II строфа | 1,65 | -1,20 | -1,43 | 1,88 | -0,28 | 2,71 | темно-синий |
| III строфа | 0,45 | 2,27 | 0,43 | -1,84 | -1,72 | -0,43 | красный |
|
C. Есенин Отговорила роща золотая Кого жалеть? Ведь каждый в мире cтранник Стою один среди равнины голой, Не жаль мне лет, растраченных- напрасно, Не обгорят рябиновые кисти, И если время, ветром разметая, |
А. Тарковский Все разошлись. На прощанье осталась Выпало лето холодной иголкой Если считаться начнем, я не вправе Там, в заоконном тревожном покое, |
Исследования показали, что газетный текст, текст инструкций - серый, не выраженный, а заговоры, песни, молитвы ярко окрашены.
Окраска произведения может меняться по мере изменения сюжета. Поэтому оценивать необходимо не все произведение, а частями. Смесь красок частей может дать необоснованно серый цвет. Замечено, что чем гениальнее поэт, тем четче выражена окраска произведения.
Одно сообщение на разных языках имеет сходную окраску. Это объясняет единство происхождения языков.
Для знатоков математики приведем формулу, по которой определяется время дивергенции в глоттохронологии:
С (А, В) = rt, откуда t(A, В) = log С(A, B) : log r,
где t - время в тысячелетиях, возраст дивергенции между языками A и В; С - доля общих для языков А и В слов из 100-словного списка Сводеша (от 0 до 1); r - индекс сохранности базового словаря за одно тысячелетие (для 100-словного списка r=0,86, log r=-0,0655).
Можно подсчитать, что если, например, не совпадают всего семь слов из базовых 100, языки разделились примерно 500 лет назад; если 26 - то разделение произошло примерно 2 тыс. лет назад, а если совпадают лишь 22 слова из 100, то 10 тыс. лет назад, и т. д.
На графике показано, как, по Сводешу зависит процент совпадающих слов от времени (t), когда разошлсь языки.


С помощью звуковых сообщений можно управлять человеком. Широко используется в религии и рекламных компаниях.
Механизм таков - звук имеет окраску, окраска влияет на эмоции, сильные эмоции провоцируют действия. Известно, что слова воздействуют на мозг, нервную систему. Не удивительно, что зубную боль можно "заговорить", так как боль - возбуждение определенного участка мозга. С помощью слов можно изменить картину очагов возбуждения в мозгу.
Суггестивная лингвистика - осознанный вход в подсознание, целенаправленное воздействие на подсознание. Можно говорить о суггестивной лингвистике как о внушении, т.е. как о словесном воздействии, воспринимаемой без критики (в отличии от убеждения).
Многие исследователи проводили анализ показателей текста, чтобы выявить закономерности - что именно действует на человека как внушение.
N - число лексических единиц в тексте;
L - число слов в тексте, которые встретились в тексте хотя бы один раз;
Lf1 - слова, которые встретились в T только раз;
Lfk - число слов, которые находятся в T с частотой >1.
Lr1- максимальная частотность слова.
1. C - индекс дистрибуции (чем, эта величина больше, тем богаче словарь);
C = (fr12+ L2)1/2
2. Ii - индекс итерации (индекс повторения слов в замкнутом тексте);
Ii= N:L
3. Ie - индекс исключительности (специфичности) лексики;
Ie=20* Lf1:N
4. P - индекс предсказуемости (чем P меньше, тем привлекательнее текст);
P = 100 - (Lf1*100):N
5. Iq - индекс плотности текста. Пропорционален числу повторяющихся слов в T и длины T. (чем богаче тематика, тем выше Iq, чем однообразнее тема, тем Iq ниже );
6. Iext - объем экстенсивности словаря. Пропорционален широте лексики, разнообразия выражения.
7. If - индекс стереотипности. Длина интервала средней части повторяющихся слов. Если If больше, то главное не форма, а содержание (для беглового чтения, нестилизовано, спонтанная речь). If меньше у художественных текстов, беллетристики.
При положительной установке длина и глубина предложений, количество сложных предложений больше, чем при отрицательной установке.
Показатели заговоров
1. C - высокое;
2. Ii = 1.42;
3. Исключительных слов больше половины (11.84);
4. Предсказуемость низкая (40.32);
5. Iq = 3.43. Тематическое богатство T.
6. Iext = 14.04. Лексическое насыщение.
7. Стереотипность = 1.54 Текст художественный.
8. Существительных больше (33.65%).
9. Местоимений меньше (10.36%), что придает тексту обезличенность, универсальность. Большее количество предлогов (длинный путь к объекту).
10. По золотому сечению имеем 2 части, с разными характеристиками.
Пример заговора "на кровь": "Шла баба по ричке, вела быка на нитке, нитка порвалась, кровь унеслась. Стану я раб божий на пашень, кровь моя не капнет, стану на кирпич, кровь запекись. Закрепитеся мои слова двенадцатью ключами, крепкими замками. Аминь."
Показатели молитв
Цвет - голубой (лазурь, небо - в картинах). Высоких звуков больше. Длина слова больше. Молитвы по индексам близки к заговорам (генетическая близость).
Пример молитвы: "Отче наш, Иже еси на Небесах! Да святится имя Твое, да приидет Царствие Твое, да будет воля Твоя, яко на небеси и на земли. Хлеб насущный даждь нам днесь; и остави нам долги наша, якоже и мы оставляем должником нашим; и не введи нас во искушение, но избави нас от лукового."
| Лексикон | Заговор | Молитва | Мантры | Заклинание | Гипноз | Аутотренинг |
| Прекрасный | 25 | 9 | -21 | 18 | -22 | 36 |
| Светлый | 30 | 45 | -48 | 5 | -1 | 26 |
| Нежный | 33 | 33 | -42 | -15 | 12 | 15 |
| Возвышенный | 62 | -7 | -2 | 26 | 3 | 38 |
| Тихий | -89 | -2 | -5 | -36 | 26 | -32 |
| Суровый | 19 | -37 | 84 | 25 | -10 | 7 |
| Печальный | -67 | -28 | 8 | -11 | 18 | -24 |
| Темный | -10 | -8 | 33 | 0,4 | 13 | 0,5 |
| Тяжелый | -37 | -33 | 42 | 15 | -15 | -15 |
| Устрашающий | -17 | -16 | 85 | -13 | 18 | -13 |
В общем, мой друг ты одолел чтение этой статьи об языковая структура. Работы впереди у тебя будет много. Смело пиши комментарии, развивайся и счастье окажется в твоих руках. Надеюсь, что теперь ты понял что такое языковая структура, диаметр сообщения, алгоритм шеворошкина-сухотина, координатная сетка алисы кобер, алгоритм хэрриса, анализ текста и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Искусственный интеллект
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

Комментарии