Лекция
Привет, Вы узнаете о том , что такое общение с роботом, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое общение с роботом , настоятельно рекомендую прочитать все из категории Искусственный интеллект.
В последнее время в информационных технологиях все явственнее стали ощущаться тенденции технического прорыва. Все быстрее становятся тактовые частоты процессоров и все меньше габариты чипов. Все доступнее большие размеры памяти за меньшую стоимость. И, судя по сообщениям в прессе, это далеко не предел в технической гонке. Уже появляются сообщения о попытках создания чипов на основе живой ткани, что обещает миру невиданные возможности. Но так ли скоро поспевает информационный прогресс за техническим?
Для игр, видео, музыки, бухгалтерских приложений и большинства баз данных вполне хватает имеющихся мощностей. Чем дальше вперед уходит технический прогресс, тем менее извинительно его отставание от информационного. Ведь в этой области, по сравнению с технической, пока ничего радикально нового не предложено, а следовательно, некуда прогрессировать. Это прекрасно понимают разработчики технических средств для информационных технологий: увольняется персонал, закрываются производства, падают цены на продукцию. Но и в информационной области дела обстоят не лучше. Если ранее работы в ней был непочатый край, то сейчас дело явно застопорилось. Судите сами — все больше настоящих специалистов, но области применения их знаний практически все те же: web-разработка, управление базами данных и разработка бухгалтерских приложений. Следовательно, многие из специалистов остаются не у дел. А что уж говорить о людях, не знающих языков программирования или вообще не умеющих программировать, но способных повлиять на информационные технологии своей неординарностью, необычным талантом, знаниями и умениями в других сферах. Их бы привлечь! Хочу поделиться своими соображениями о том, как использовать этот потенциал. Надеюсь, это будет выгодно как материально, так и морально всем, кто прислушается к моим словам. Под «всеми» я понимаю вот кого:
1) неординарных людей с необычными талантами;
2) программистов, ищущих возможности приложения своих знаний и умений;
3) специалистов по разработке, созданию и подключению разных аппаратных компьютерных «примочек»;
4) всех, кто способен и далее наращивать тактовые частоты, увеличивать объемы памяти и тому подобное.
Что я понимаю под словами «материально» и «морально»? Я объясняю вам суть идеи. Используя ее, вы становитесь разработчиком очень дорогих систем. Вот вам и материальное удовлетворение. Кроме того, вы автор системы, и в зависимости от ее уровня вам достается соответствующий эквивалент признания. А его можно рассматривать как моральное удовлетворение.
Теперь о том, что же я придумал. А придумал простой способ, как в бытовых условиях создавать роботов с искусственным интеллектом, вполне сопоставимым с человеческим.
Если вы пессимист — это не для вас
Прекрасно представляю себе, сколько справедливого недоверия вызывают такие заявления. И это вполне понятно, но хочу прежде привести несколько примеров, которые помогут вам побороть пессимизм. Если же вы не в силах справиться с этим недругом, лучше перевернуть страницу.
Недавно разговорился со знакомым о возможности создания искусственного интеллекта. Он мне возьми да и скажи: «Да ну, такие вещи одними операторами IF не делаются (IF — по-русски «ЕСЛИ»)». На самом деле, следовало понимать: «Я не представляю себе, как это сделать». Ведь мой знакомый прекрасно понимал, что вопрос не в использовании каких-то операторов, а в сложности написания самого механизма интеллекта. Любой здравомыслящий человек не будет оспаривать того факта, что все известные нам сложнейшие программы на уровне машинных команд вообще работают с простейшими операторами и набором из нескольких регистров. Все зависит от того, насколько необычно человек смотрит на проблему и насколько нестандартно ее решает; пытается ли он понять факт или отворачивается от него. Именно нестандартные решения во многих случаях заставляют нас удивленно восклицать: «Не может быть. Как это получилось?» И, немного погодя: «Почему я до этого не додумался?» А все потому, что пытались решить проблему обычным методом. Ярким примером нестандартного подхода может служить программа Mars. Ее написали в то время, когда еще не было ни графических ускорителей, ни огромных объемов памяти. Программа на 386-м процессоре в реальном времени имитировала движение над поверхностью планеты. Кроме того, программа была написана так, что ее объем составлял всего 4 килобайта! Чувствуете разницу между ее объемом и объемом современных игровых движков (понятно, что они намного больше умеют, но все же). А как насчет жалоб современных геймеров на нехватку скорости их компьютеров для построения игровых сцен в реальном времени? А на 386-й машине без суперских видеоплат в программе Mars не выпадало ни одного кадра. И многие программисты того времени, увидев Mars, задавались вопросом: «Как это сделали, да еще в 4 килобайтах?» А ведь нестандартным решением была всего лишь замена сложной математики 3D-построения на таблицы заранее рассчитанных значений. Это привело не только к поднятию скорости рендеринга ландшафта планеты, но и к уменьшению размеров программы. И таких примеров в жизни очень много.
Как готовятся роботы
Разработка робота с искусственным интеллектом включает в себя разработку программной, логической и технической частей. Для начала вы должны сформировать необходимые группы разработчиков для каждой из частей. Как правило, один в поле не воин, поэтому такую работу стоит делать группой. Ну, это уже организаторские вопросы, которые решать вам, а не мне.
Группа разработки программной части, имхо, состоит из программистов и занимается написанием как программных внутренностей робота, так и редакторов его логических модулей. Здесь не будут рассматриваться способы написания программного движка робота, так как основная задача — донести идею до тех, кому когда-либо в жизни приходилось (или придется) разрабатывать логическую часть. Программная группа в состоянии сама разобраться, какие процедуры, функции и тому подобное необходимо написать в движке. Ей же придется дать логической группе некоторые представления об используемых в роботе типах данных. Вообще, всем группам придется тесно контактировать друг с другом, и программной группе часто придется выступать в роли координатора проекта.
Группа разработки логической части состоит из людей, способных описать логику работы живого существа (психологи, учителя, филологи и пр.)
Группа разработки технической части включает в себя специалистов, отвечающих за механические части робота (руки, ноги, глаза и т. д.). Если же делается какое-нибудь виртуальное существо, тогда без технической группы можно обойтись. Во всяком случае, вы должны четко продумать эти моменты.
Решив, какого робота вы будете делать, начинаете писать программный движок. За движком наступает очередь логической и технической части. По ходу создания логической части доводятся незавершенные моменты программной части. В результате получается готовый робот. В общем случае идея предполагает возможность написания универсального движка, на который потом цепляется логическая часть. То есть, «логики» могут купить уже готовый движок и подключать к нему свою логику.
Устройство логической части
Вся логическая часть состоит из набора матриц, в ячейках которых программируется логика функционирования робота. В любой ячейке матрицы допустимо хранить любой тип данных. Ячейка устроена так, что позволяет простым образом связывать ячейки разных матриц друг с другом независимо от их типов. Матрица поддерживает многоязычность, что позволяет в одной матрице разрабатывать логику сразу для нескольких стран. Кроме того, допускается использование любого элемента матрицы не по прямому назначению. И вообще, структура матрицы довольно проста и предоставляет некий универсальный скелет, части которого разработчик модернизирует под собственные нужды. Более того, идея подразумевает неограниченную модернизацию при сохранении простоты и единой линии реализации матриц интеллекта. Программный движок использует матрицы и буквально прыгает по их ячейкам, выполняя, обрабатывая и анализируя данные в них. Никто не ограничивает программный движок в способах обработки ячеек. Например, при попадании на некоторые ячейки или определенные типы данных допустимо вызывать различные внутренние функции программного движка. Допустимо обрабатывать некоторые ячейки как стартовые точки, порождающие цепочки каких-либо операций с автоматическим выходом на другие ячейки в цепочке, и так далее. Как видите, простор для творчества есть. Матрицы при относительной простоте позволяют создавать сложнейшую логику. Поэтому рассмотрим их 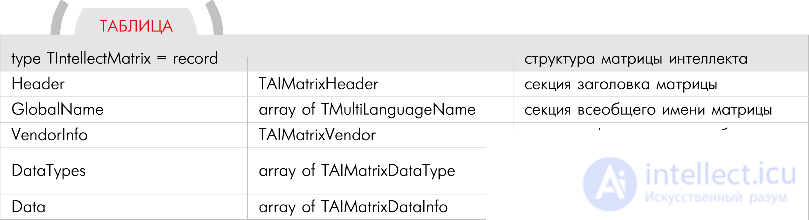
устройство поближе.
Любая матрица состоит из пяти секций: заголовка, всеобщего имени матрицы, информации разработчика, списка используемых в матрице типов данных, и ячеек матрицы. Далее я привел полную структуру матрицы.
Здесь и в дальнейшем все структуры будут описаны применительно к системе программирования Delphi. Думаю, программисты смогут адаптировать данные структуры для других языков. Черным цветом я выделил имена полей, красным цветом — их типы, синим — комментарии к ним.
Ниже отдельно приведены структуры для каждой секции матрицы. Мы будем рассматривать только те поля, которые необходимы группам разработки логической и программной частей. Такие поля я пометил значком x перед их именами. Остальные поля представляют интерес только для программной группы.
Секция заголовка матрицы
Секция заголовка содержит всю основную информацию для транспортировки матриц 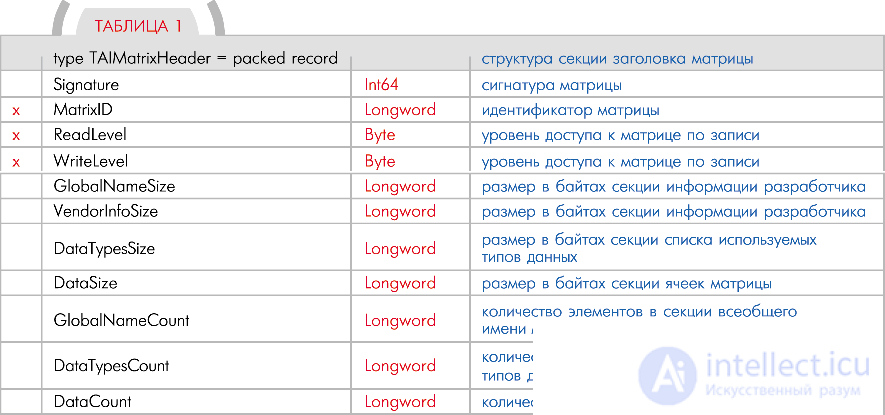 при помощи различных носителей информации (табл. 1).
при помощи различных носителей информации (табл. 1).
Поле MatrixID содержит уникальный идентификатор матрицы (ее номер). Чтобы обратиться к определенной ячейке какой-либо матрицы, необходимо указать идентификатор желаемой матрицы, а за ним идентификатор требуемой ячейки. Левая часть указателя на ячейку всегда будет содержать номер матрицы, а правая часть — номер ячейки. Например, указатель 43:25 указывает на 25-ю ячейку 43-й матрицы.
Поля ReadLevel и WriteLevel предназначены для задания уровня доступа по чтению и по записи к данной матрице. Чем больше значение в этих полях, тем выше должен быть уровень у инициатора запроса для доступа к данным матрицы. На практике эти поля могут вообще не использоваться, либо использоваться совершенно для других целей. Но при помощи них можно реализовать следующую схожую с человеческой особенность поведения робота.
Пример для поля ReadLevel. Роботу задают вопрос: Ты любишь Аню? А матрица с данными об Ане помечена как «очень личное» для робота (то есть, имеет самый высокий уровень доступа). Инициа тор запроса данных об Ане — в нашем случае это будет система построения ответа на вопрос — имеет низкий уровень доступа, чтобы оперировать самыми «сокровенными» чувствами робота. Но программный движок робота обязательно должен возвратить инициатору запроса какой-то результат, которым могут быть заранее занесенные в матрицу фиктивные данные для «не вхожих в круг секретности» инициаторов. Вот вам один из простых вариантов реализации лжи.
Пример для поля WriteLevel. Если для робота предусмотреть возможность порождать себе подобных, плюс возможность изменять какие-нибудь признаки наследственности, то неизбежно придется решать вопрос, каким образом робот будет менять эту наследственность. Ведь матрица ДНК робота в этом случае должна иметь максимальный уровень доступа по записи. А система изменения наследственных признаков робота должна располагать очень вескими основаниями (соответствующий уровень доступа), чтобы производить операции записи в матрице ДНК.
Секция всеобщего имени матрицы
Эта секция поддерживает многоязычность и предназначена для вполне обычной текстовой метки матрицы. Несмотря на то, что к матрице необходимо обращаться через ее идентификатор и номер ячейки, вам может понадобиться эта секция для каких-то нестандартных действий. Во-первых, при разработке логики робота очень удобно сопоставлять каждому идентификатору матрицы какое-нибудь общеупотребительное человеческое слово (имя). Во-вторых, появляется возможность реализовать в программном движке механизм обработки запросов с заведомо неизвестным идентификатором матрицы, но известным именем. Например, роботу задают вопрос: Ты знаешь Петю?. Очевидно, проанализировав секции всеобщих имен матриц, он сможет найти идентификаторы матриц, относящихся ко всем известным роботу Петям.
Как можно заметить, секция всеобщего имени представлена в структуре матрицы массивом из элементов с типом TMiltiLanguageName, что позволяет реализовать многоязычность. Поэтому здесь мы рассмотрим именно этот тип. Он позволяет задать имя на каком-нибудь конкретном языке мира. Идентификатор языка задается так, как он задается для Wide-строк в Windows. Например, код русского языка он равен 0419h, код украинского —0422h, английского —0409h, немецкого —0407h, французского —040Bh и так далее.
Обратите внимание, что количество элементов в секции всеобщего имени задается полем  GlobalNameCount секции заголовка матрицы (табл. 2).
GlobalNameCount секции заголовка матрицы (табл. 2).
Поле Name содержит всеобщее имя матрицы, по которому ее необходимо искать, пользуясь различными строковыми функциями поиска.
Поле Description позволяет указать рядом с именем матрицы какой-нибудь дополнительный комментарий к ней, к ее содержанию или назначению.
Секция информации разработчика
Данная секция содержит информацию, относящуюся к разработке соответствующей матрицы. Об этом говорит сайт https://intellect.icu . Поскольку разработчиками могут продаваться даже отдельные матрицы, то эта секция предназначается для заполнения данных о версии матрицы, 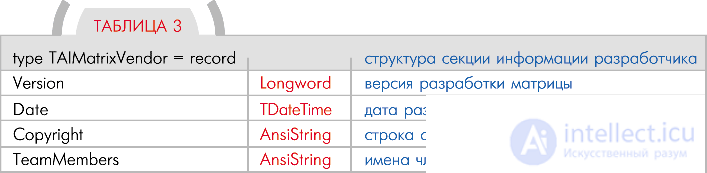 дате ее изготовления и т. п (табл. 3).
дате ее изготовления и т. п (табл. 3).
Все поля секции должны заполняться группой разработки логической части, но они никак не используются в самой логике робота. Думаю, что с назначением каждого из этих полей вы разберетесь и без моей помощи.
Секция используемых в матрице типов данных
Это вспомогательная секция, она не имеет влияния на логику робота. Ее назначение — хранить во время разработки матрицы список используемых в ней типов данных. В дальнейшем группа «логиков» решает, стоит ли удалить этот список из матрицы. Таким образом, данная секция может вообще отсутствовать. Она представлена массивом из элементов с типом TAIMatrixDataType. Количество элементов в секции задается полем DataTypesCount секции заголовка матрицы (табл. 4).
Секция может не отражать полный список используемых в матрице типов данных, но я думаю, что в нее стоит вносить все используемые типы. Тем более, что это позволит избежать проблем при стыковке разных матриц от разных  разработчиков. Пока нет никаких стандартов на нумерацию типов, и разные разработчики могут нумеровать их по своему. При помощи этой секции вы сможете разобраться, какие типы использовал разработчик матрицы в ее ячейках. Несмотря на то, что прямой связи между списком секции и действительно используемыми в матрице типами данных нет, все же неприятно покупать матрицу и быть в неведении относительно используемых в ней типов данных.
разработчиков. Пока нет никаких стандартов на нумерацию типов, и разные разработчики могут нумеровать их по своему. При помощи этой секции вы сможете разобраться, какие типы использовал разработчик матрицы в ее ячейках. Несмотря на то, что прямой связи между списком секции и действительно используемыми в матрице типами данных нет, все же неприятно покупать матрицу и быть в неведении относительно используемых в ней типов данных.
Вот пример некого небольшого списка использованных типов данных.
1. Нечеткая истина
3. Text
4. Целое число
32. Bitmap image
64. Обработчик правой руки
2048. Видеофрагмент
Как видно из списка, он несет чисто информативную функцию и не претендует на полноту и достоверность. Этим списком разработчик как бы заявляет своим коллегам и будущим сотрудникам, что он использовал такие-то и такие-то типы данных, тем самым помогая им быстрее разобраться в подключении матрицы.
Секция ячеек матрицы
Секция ячеек также представлена массивом из элементов с типом TAIMatrixDataInfo. Собственно говоря, она и содержит всю логику матрицы. Количество элементов в секции задается полем DataCount секции заголовка матрицы. Каждый конкретный элемент секции является отдельной ячейкой матрицы (табл. 5).
Поле CellID содержит уникальный идентификатор ячейки. Что значит этот идентификатор, было описано выше в поле идентификатора матрицы. 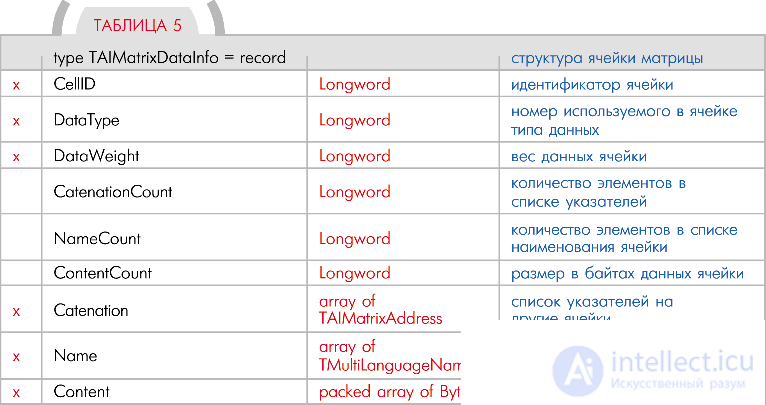 Обратите внимание, что ячейки внутри матрицы не обязательно упорядочивать. То есть, ячейка с большим номером может быть в самом начале матрицы, ячейка с меньшим номером может быть как в начале или середине, так и в конце матрицы.
Обратите внимание, что ячейки внутри матрицы не обязательно упорядочивать. То есть, ячейка с большим номером может быть в самом начале матрицы, ячейка с меньшим номером может быть как в начале или середине, так и в конце матрицы.
В ячейку помещаются какие-нибудь данные, а значит, они имеют какой-то тип. В поле DataType заносится номер помещенного в ячейку типа данных. Как было сказано ранее, частичный или полный список наименований используемых типов находится во вспомогательной секции DataTypes (см. структуру матрицы).
Поле DataWeight предназначено для задания какого-нибудь числового параметра данных в соответствующей ячейке по отношению к чему-то определенному.
Поле Catenation содержит список различных указателей на другие ячейки в матрицах (не только на ячейки текущей матрицы). Собственно, поле представлено массивом из элементов TAIMatrixAddress. Этот тип будет рассмотрен чуть ниже. Количество элементов в массиве задано полем CatenationCount этой же структуры. Несмотря на то, что все указатели имеют одинаковую структуру, вариации их видов и способов использования зависят только от возможностей программного движка вашего робота.
Поле Name предназначено для хранения имени конкретной ячейки. По своей структуре это поле схоже с полем всеобщего имени матрицы. Оно так же поддерживает многоязычность и тоже является массивом из элементов с типом TMultiLanguageName, но количество элементов в этом массиве задается полем NameCount структуры ячейки матрицы. Опять же, поле имени ячейки может использоваться для разных целей. Вам никто не мешает реализовать функции поиска по наименованиям ячеек. Тогда, например, на вопрос: «Что такое вилка?», робот сможет найти все адреса ячеек, которые содержат данные о вилках.
Поле Content представлено массивом из байт и содержит в себе помещенные в ячейку данные. Размер массива задан полем ContentCount этой же структуры. Массив просто содержит данные, а их структура определяется уже вашими собственными законами, разработанными вами же для этого типа данных. Например, нужно поместить классический текст: «Здравствуй, мир!» в ячейку. Это у нас будет тип данных — строка. Дадим этому типу, например, номер 18. Значит, в поле DataType заносим число 18, в поле ContentCount заносим число 16 (длина строки), а в массив поля Content заносим один за другим все символы строки. Или такой пример. Допустим, мне нужно использовать в ячейке свою структуру данных с двумя полями: одно из 7 байт (а не из 4-х, как обычно) для целого числа, а другое из 3 байт для какого-то признака. Даю этому типу данных свой номер. Представим, что у меня уже используется 18 разных типов данных. И новому, чтобы не нарушать нумерации, я решаю дать номер 19. Этот номер заношу в поле DataType. В поле ContentCount заношу число 10 (размер данных = 7 байт для первого поля плюс 3 байта для второго). Ну, и в массиве поля Content выделяю место для 10 байт моей собственной структуры данных. При необходимости заношу какие-то изначальные значения в поля этой структуры. Таким образом, в ячейке оказалась записана новая структура, а ее обработка уже входит в задачи программного движка робота. Ведь «логику» неинтересно, как извлекается, сохраняется или обрабатывается определенный тип данных. Для него поле Content является источником данных, а как они там хранятся — это не его вопрос, а программистов.
Теперь рассмотрим тип TAIMatrixAddress, с помощью которого задается указатель на другую ячейку (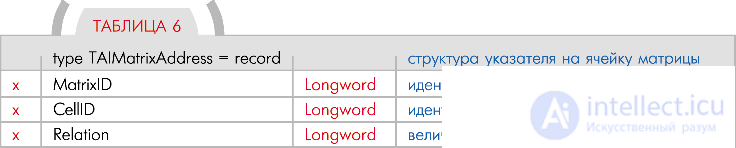 табл. 6).
табл. 6).
Поля MatrixID и CellID содержат указатель на определенную ячейку. Как было сказано выше, адрес ячейки задается идентификатором ее матрицы плюс идентификатором самой ячейки.
Поле Relation предназначено для задания типа соответствующего указателя. Кроме того, это поле можно использовать, например, для задания уровня весомости данного указателя по отношению к другим указателям в списке. То есть, возможности для использования поля очень широкие. В зависимости от его значения это может быть указатель перехода, указатель вызова какой-нибудь функции обработки периферийных устройств робота, указатель соответствия ячейки какой-то другой ячейке, указатель уровня важности обработки некой ячейки и так далее.
Знакомьтесь — основные типы данных.
Как уже было заявлено ранее, моя идея позволяет использовать любые типы данных. Не мне вас, учить какой из них и как использовать. Но все же я подробнее остановлюсь на одном типе, в основе своей заимствованном мной из нечеткой логики.
Тип FuzzyTrue —нечеткая истина — основной элемент для создания нечеткой логики. Если в булевой логике есть два значения (истина и ложь), то в нечеткой логике между истиной и ложью лежит много значений. Эти значения можно назвать долями вероятности результата. В обычном языке человек выражает доли вероятности при помощи наречий («чуть», «слегка», «менее», «более», «почти», «около», «где-то рядом», «совсем близко» и т. п.). А значит, на любой нечеткий смысл мы можем найти какой-то четкий диапазон понятий.
Рассмотрим пример. К вам обращаются: «Дай мне немного семечек». Несмотря на то, что «немного» — понятие растяжимое, вы отдадите действительно немного, а не все семечки. Немного — это всего лишь доля вероятности от всех имеющихся у вас семечек. И эта доля при всей своей кажущейся нечеткости имеет достаточно четкие математические грани. Причем, вспомните, каждое последующее отдаваемое «немного» начинает уменьшаться пропорционально оставшемуся количеству семечек. И каждое «немного» будет всегда приблизительно столько-то процентов от имеющихся семечек.
Теперь, если мы определенным словам сопоставим конкретные процентные отношения, то их смысл уже не будет казаться таким расплывчатым (процентные отношения взяты «с потолка», исключительно для наглядности).
Также обратите внимание на тот факт, что каждому нечеткому вопросу всегда явно или неявно ставится в ограничение соответствующий диапазон ответов. То есть, «дайте мне чуточку соли» от ее объема на столе, а не где-нибудь в вагоне на складе. Таким образом, при помощи типа FuzzyTrue можно дать четкий числовой ответ на нечеткий вопрос с конкретным диапазоном ответов. Не обязательно привязывать ответ к процентам. Это может быть, например, и 200 единиц от общего количества в 38000 единиц (немного сахара от его объема в мешке).
Как в булевой логике выполняются разные операции над булевыми типами, так и в нечеткой логике над типом FuzzyTrue можно выполнять операции AND, OR, XOR и т. п. Но результатом будет уже нечеткое множество, потому что операция выполняется не над одними долями вероятностей, а над долями, привязанными к их диапазонам результатов. Соответственно, полученное множество будет читаться приблизительно так: с такого по такой диапазон доля вероятности такая-то, от сих и до сих — сякая, в этом диапазоне — еще какая-нибудь и т. д. Значит, нечеткое множество можно представить массивом значений, где каждый первый элемент значения задает диапазон или какую-то определенную его точку, а второй элемент задает долю вероятности для этого диапазона или точки. Чтобы вы не запутались, объясню это на следующем примере.
Представим, что в одном магазине решили создать робота, раздающего рекламные буклеты входящим в магазин покупателям. Но раздавать нужно не всем подряд, а только определенному кругу людей. Считаем, что в магазине решили выбирать покупателей по возрастному признаку (а ведь робота можно научить выбирать и по дороговизне одежды, количеству золотых украшений, классу подъехавшей машины и т. д.). Нам пока не важно, как в магазине научили робота определять, стар или молод покупатель. Мы смотрим, как он использует нечеткое множество. Для простоты считаем, что он раздает один вид буклетов, подходящий для всех желаемых возрастных категорий. Если буклеты для каждой категории разные, то работа будет вестись с несколькими нечеткими множествами, а не с одним.
Итак, к примеру, робот получает от руководства магазина 1000 буклетов и несколько указаний по возрастным категориям:
Безусловно, малое количество параметров можно не объединять в множество и обрабатывать их скачками по разным ячейкам матрицы, где эти параметры сохранены. Но что если указаний становится все больше и больше? Все же лучше объединить их в множество и хранить в одной ячейке матрицы. В результате робот применяет операцию OR (логическое сложение) ко всем полученным указаниям и выводит из них нечеткое множество. Здесь я тоже процентные отношения взял «с потолка». Элементы нечеткого множества я упорядочил по первому полю элементов — диапазону возрастов. Второе поле — это процент выдаваемых от оставшихся у робота буклетов соответствующей возрастной категории покупателей. После операции OR 16-летний возраст попал в диапазон с большей долей вероятности. Заметьте, что в 40-летний возраст я поставил слово «каждому». На самом деле, вместо этого слова реально используется некое число, которое указывает программному движку робота, что это не процент от возрастной категории:
Далее робот оценивает возраст входящего покупателя, сравнивает возраст с нечетким множеством и поступает в зависимости от результата, извлеченного из нечеткого множества.
Строим словарный запас робота.
Я думаю, не только мне, но и многим из вас хотелось бы, чтобы разработанный робот мог не только выполнять возложенные на него функции, но и быть способным общаться с человеком, понимать смысл его речей. Опять же, оставим в стороне чисто технические аспекты проблемы (синтезатор голоса, распознавание произнесенного текста), но присмотримся внимательнее к проблеме распознавания смысловой структуры речи. Сначала мне хотелось бы привести следующий показательный пример.
Как-то я проходил мимо футбольного поля, где ребята играли в футбол. Один из мальчиков, получив мяч, начинает двигаться к воротам противника. Перед ним появляется несколько защитников противника. В этот момент с другой половины поля его товарищ по команде кричит: «Сергей, открытый!» Сергей пасует крикнувшему — действительно, ведь он один из всей команды нападающих никем не заблокирован.
Мне, наблюдавшему эту сцену со стороны, был понятен смысл произнесенной фразы. В данной ситуации слово «открытый» обозначало возможность свободного продвижения принимающего пас к воротам противника. А представьте, например, если бы мальчик крикнул: «Сергей, микросхема!» Никто бы не понял смысла этой фразы, поскольку никому невдомек, какое отношение имеет микросхема к футболу. Очевидно, для построения системы распознавания смысла важен как словарный запас робота, так и соотнесенность слов и словосочетаний с происходящими событиями. Я предлагаю вам следующую идею организации словарного запаса робота.
Итак, выделяется одна матрица, которая будет содержать весь словарный запас робота. Каждое слово (либо словосочетание) помещается в отдельную ячейку матрицы. Текст слова помещается в поле Name соответствующей ячейки. Чтобы нашему роботу не ударить в грязь лицом перед представителем культуры, пересыпающим слова сленгом, руганью или терминологией, реально включить в одно поле различные варианты данного слова, в том числе иноязычные (мы же понимаем фразы типа «Okay, я согласен»). Не забываем и о том, что поле Name в своем внутреннем подполе Description позволяет для каждого имени указать его описание — то есть, запросто можно расположить, например, соответствующую данному слову энциклопедическую статью (между делом — у нас уже получается что-то похожее на многоязычный энциклопедический словарь). Поле DataType и поле Content используете по своему усмотрению. Возможно, вы захотите прикреплять какую-то дополнительную информацию (картинки, данные, ссылки и т. п.) к каждому слову. Эти два поля как раз подходят для этих целей. Поле Catenation содержит список употреблений данного слова в разных областях знаний робота. Фактически, в это поле помещаются указатели на ячейки других матриц, содержащие известные роботу знания о нем. Одно слово в разных областях знаний может обозначать совершенно разные понятия. Поле Catenation перечисляет все варианты понятий данного слова в разных областях знаний робота. Каждый указатель на ячейку матрицы состоит из двух частей. Если левая часть указателя равна нулю (не указана матрица), значит, такой указатель обозначает, что данное слово не относится к какой-либо определенной области знаний, а его универсальный для всех областей смысл находится в ячейке некоторой предопределенной матрицы, где ячейка этой матрицы задана правой частью указателя. То есть, нуль будет подменяться каким-то реальным номером заранее предопределенной матрицы, а номер ячейки возьмется из правой части указателя. Если же левая часть указана, а правая равна нулю (нет номера ячейки, а матрица указана), тогда такой указатель обозначает лишь отношение данного слова к соответствующей области знаний, но не его трактовку (вспомните, например, как мы говорим: «Это что-то из области медицины, но не знаю, что точно»). Ну, а когда и левая, и правая части указаны, будем считать, что указатель отсылает к возможной трактовке данного слова.
Теперь посмотрим, как все это работает. Робот играет в футбол. Считаем, что его система опознавания происходящих событий установила, что сейчас происходит событие, ну допустим, с номером матрицы 24 (предположим, ее имя «Играем в футбол»). В какой-то момент робот слышит фразу: «Сергей, открытый!» Сработала система распознавания произнесенной фразы. Опознала первое слово «Сергей», передала его на дальнейшую обработку системе распознавания смысла. Вот сейчас то место, где принимается за работу система опознавания. Она производит поиск в матрице словарного запаса той ячейки, в которой записано слово «Сергей». Найдя требуемую ячейку, система анализирует список указателей в поле Catenation этой же ячейки. Представим, что в этом списке есть только один указатель 0:8. При анализе игнорируются все указатели, идентификатор матрицы которых не равен содержимому, допустим, ячейки 24:5 (матрица «Играем в футбол», а имя пятой ячейки, предположим, будет «На какой области знания построен футбол»). Как можно догадаться, в ячейке 24:5 хранится номер матрицы, являющейся областью знания робота о футболе. Предположим, что в ячейке 24:5 хранится идентификатор матрицы 57 (допустим, ее имя «Знания о футболе»). В результате анализа наша система не нашла ни одного указателя на матрицу с номером 57. Значит, система уже может сделать один вывод: слово «Сергей» не относится к знаниям о футболе. Поэтому система выполняет второй раз анализ списка указателей. Но теперь она ищет первый указатель с левой частью, равной нулю. Помните, как было сказано, что нуль будет подменяться реальным идентификатором заранее предопределенной матрицы (предположим, это будет матрица 11, имя которой «Универсальные знания»). На второй стадии анализа система нашла указатель 0:8. Для себя подменяет нуль на 11, в итоге получается указатель 11:8 (матрица «Универсальные знания», а имя восьмой ячейки, предположим, будет «Имена людей»). Таким образом, система опознала смысл слова. Она выяснила, что слово «Сергей» принадлежит к классу имен людей и, вероятнее всего, этим словом к кому-то сейчас обратились. Более того, система владеет указателем на трактовку данного слова. А ведь распознавание смысла необходимо системе принятия решения. И она ждет этот указатель от системы распознавания — по этому указателю расположена очень важная для системы принятия решений информация (что предпринять, как это выполнить и т. д.). Теперь представьте, что система принятия решений находит в ячейке по указателю 11:8 такие инструкции к действиям: 1) определить, находится ли в вызывающей матрице объект с этим именем; 2) если он есть, тогда определить, принадлежит ли это имя самому роботу; 3) если имя принадлежит роботу, продолжать анализировать фразу дальше, иначе остановить распознавание.
Нашего робота зовут Сергей и обращались к нему, а значит, анализ выполняется дальше. Теперь опознано второе слово — «открытый» — и оно опять передается системе распознавания смысла. Все снова закрутилось по тому же сценарию. Нашли в словаре ячейку со словом «открытый». Анализируем список указателей поля Catenation этой ячейки. Допустим, там есть три указателя (15:67, 57:25 и 38:21). На первой же стадии анализа нашли указатель на ячейку 57:25 (матрица «Знания о футболе», а имя 25-й ячейки, предположим, будет «Неприкрытый игрок»). Полученный указатель передается системе принятия решений. И она с вопросом «что же мне предпринять?» смотрит на данные в указанной ячейке. А там хранятся следующие инструкции: 1) проанализировать вероятность дальнейшего продвижения к воротам противника; 2) если вероятность не превышает 80%, тогда отдать пас 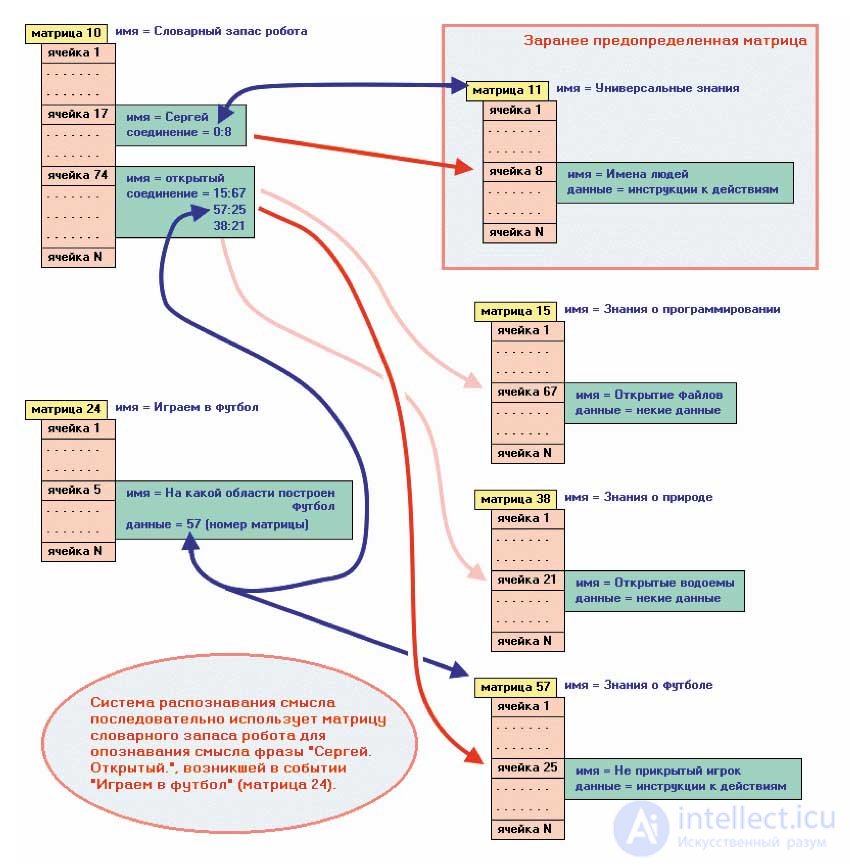 кричащему, иначе продвигаться к воротам самому.
кричащему, иначе продвигаться к воротам самому.
На данной картинке изображен механизм выполнения описанных операций при работе системы распознавания смысла. Матрица 24 является вызывающей, поскольку в ней произошло внешнее событие (кричали), и именно для этой матрицы инициирована операция распознавания. Естественно, что матрица 24 не знает, где расположен словарный запас робота. Это знают внутренние функции системы распознавания программного движка. А в их обязанности тоже входит знать, какая матрица будет заранее предопределенной, а также выяснить, на какие дополнительные матрицы (знания) опирается матрица 24. И уже по этим данным провести распознавание.
Подключаем эмоции
Вот уж точно подмечено: «Словом можно и убить». Как иногда остро человек реагирует на произнесенную фразу! Всего лишь незначительная на первый взгляд подмена слова в предложении может в корне преобразить его смысл. И даже если с формальной точки зрения смысл предложения не меняется, эмоционально фраза может восприниматься совершенно иначе. Посудите сами, как меняется эмоциональная окраска, например, таких фраз: «Слышишь, ты, солнышко мое» и «Послушай, солнышко мое». И в первом, и в другом случае логически говорили об одном и том же. Но эмоционально фразы воспринимаются по разному. В первом случае начало «Слышишь, ты» придает окраску пренебрежительного обращения к человеку. Вторая фраза намного мягче первой. Отсюда делаем простой вывод: слова имеют свой эмоциональный вес и, в зависимости от него, могут придать негативное или позитивное отношение к тексту. Представьте, если бы вам кто-то сказал такое: «К пяти домажем три и будет восемь». Вы бы наверняка поняли смысл предложения, но отметили бы про себя грубость собеседника.
А теперь попробуем научить робота получать эмоции от услышанной речи. Я предлагаю следующую идею. Обратите внимание, что в предыдущем разделе мы не использовали поле DataWeight ячеек словарного запаса робота. Если в это поле для каждого слова занести некое число, характеризующее его как приятное или неприятное для слушающего, то для любой фразы можно получить какое-то количественное положительное или отрицательное отношение к ней. Рассмотрим это на примере предложенных ранее фраз.
Допустим, слову «слышишь» мы присвоим негативный вес в -100 единиц, слову «ты» — негативный вес в -10 единиц, слову «солнышко» — положительный вес в +50 единиц, слову «мое» — вес в +25 единиц и слову «послушай» — вес в -10 единиц. Теперь сложим все значения для каждой фразы отдельно. Для фразы «Слышишь, ты, солнышко мое» мы получим негативный вес в -35 единиц. А вот для фразы «Послушай, солнышко мое» этот вес уже будет положительным и равен -10+50+25=65 единиц. Таким образом, робот получает числовое выражение эмоционального отношения к сказанному. Уже на основании этих чисел он может судить, как ему отнестись к чужой речи. Диапазон значений поля DataWeight позволяет варьировать эмоциональную окраску предложения в достаточно больших пределах (от неприязни до симпатии и т. п.)
Как научить догадываться
В одной из передач «Поле чудес» был вопрос (к сожалению, я уже не помню его точную формулировку) о том, что изготовляли в прошлом в некой стране из водорослей. Причем, что немаловажно, это нечто изготовлялось именно для человека. Сначала никто не мог понять, что имелось ввиду. После того, как Якубович жестами постарался подсказать игрокам отгадку, стало ясно, о чем шла речь. Он намекнул на длину водорослей, их структуру и цвет. А игрокам осталось только догадаться, что это был парик.
В данном случае весь процесс догадки выглядит приблизительно так. Игрок по подсказанным признакам (длина, структура, цвет) выделил из данных о человеке все, что имеет сходные признаки. Далее, сравнив названия выделенных признаков с уже открытыми буквами, игрок догадался об ответе. У игроков разный объем накопленных данных о человеке, поэтому один игрок успевает догадаться, а другой и до конца игры не поймет, о чем речь.
Чтобы научить робота догадываться, необходимо по возможности каждое желаемое для догадывания свойство снабдить указателями на сходные свойства других объектов. Естественно, глупо пытаться связать все с всем. Робот изначально может иметь только какой-то базовый набор связок, а остальные вдруг понадобившиеся свойства связывать уже в процессе своей эволюции — так же как маленький ребенок развивается постепенно, а не сразу в момент рождения знает все.
Поле для указателей у нас уже есть. Это поле Catenation ячейки матрицы. Но нам нужен не просто указатель, а указатель с возможностью задания величины схожести одного свойства с другим. Ведь, к примеру, длина водорослей может полностью совпадать с длиной волос, или не совсем, или частично, и т. д. По отношению к длине руки она совпадает на столько-то и столько, по отношению к ноге — на столько-то и вот столько. У кого величина схожести больше, тот и ближе к результату догадки.
Поскольку поле Catenation включает в себя помимо полей указателя поле Relation, то мы можем поместить в него величину схожести данного свойства с другим свойством, определяемым указателем поля Catenation.
Что мы получили в результате? Ячейка матрицы с данными о водорослях снабжается серией указателей схожести с разными объектами. Обратите внимание, что указатели могут быть перемешаны с другими типами указателей. Вспомните пример со словарным запасом робота. Ведь поле Relation может трактоваться по вашему собственному принципу. Например, если в нем 0, то это указатель словарного запаса, 1 — указатель чего-то еще, 2 отсылает еще к чему-то, а все остальные значения — указатель с соответствующей величиной схожести. Теперь робот анализирует список указателей. Есть схожесть с длиной такого цветка. Нет, не подходит. Есть схожесть с цветом такой птицы. Нет, опять не то. Есть схожесть с чем-то еще ... и так далее. Ага, робот ничего не нашел, а значит, не смог догадаться, о чем речь. Потом ему сказали ответ, и он вносит в данные о водорослях, что из них когда-то делали парики. Но еще он обязан в поле указателей ячейки данных о водорослях добавить указатели схожести водорослей с волосами по длине, цвету и структуре. Естественно, каждый указатель должен быть снабжен своим значением величины схожести.
Почему робот обязан это сделать? А потому что если этого не сделать, то он будет обычной железкой, неспособной размышлять. Ему задают вопрос: «Что в прошлом в такой-то стране изготовляли из водорослей для людей?» Он отвечает: «Парики». Ему задают следующий вопрос: «Что в прошлом в соседней стране не захотели изготовлять из водорослей для людей?» Он отвечает: «Не знаю». Хотя с правильно написанной системой анализа, ориентирующейся на указатели схожести он должен был бы догадаться. Вот почему он обязан это делать.
Заключение
Роботы нужны везде. Естественно, они могут создаваться как во благо, так и во вред. Хотелось бы, чтобы было побольше хороших целей, но это уже вопросы этики разработчика. Просится намек, но он будет выражен необычной гипотезой. Думаю, вы поймете, насколько могут оказаться важны ваши усилия для развития человечества.
Жила-была одна цивилизация. Шло время. Цивилизация развивалась. И наконец, достигла того уровня, когда научилась делать искусственных живых существ. Прошло еще время, и было решено провести конкурс на лучших искусственных существ. Энное количество самых лучших существ было отправлено на корабле в далекий космос. Неизвестно почему, но именно Земля стала родным домом этих существ. Шло время. И уже новая цивилизация развивалась на Земле. Вот уже и эта цивилизация научилась делать искусственных существ. Вот уже и они проводят конкурс. И вот уже с Земли поднимается космический корабль, чтобы увезти новую жизнь в далекие просторы космоса. Возможно, ее создатели уже никогда не увидят своих детищ, как и не увидят величественный расцвет будущей цивилизации. А жизнь будет идти своим чередом, сквозь все цивилизации и эпохи.
Я не хочу навязывать вам каких-либо гипотез, но посмотрите на нашу цивилизацию глазами стороннего наблюдателя. Нет сомнения в том, что на Земле именно человек венчает эволюцию. Теперь представьте, что произойдет, когда человек научится делать по-настоящему живых существ. А я в этом уверен, он их сделает. Не сегодня и не завтра, пройдет еще очень много времени, но человек станет делать роботов, потому что они ему нужны. Будут совершенствоваться технологии изготовления, будет расти опыт создания искусственных существ, и когда-нибудь придет время, когда из под «скальпеля» робототехников выйдут те же Адам и Ева. Я не имею ввиду, что они будут похожи на библейских персонажей. По большому счету, это и не так важно. Важно лишь то, что они будут похожи на людей способностью воспроизводить себе подобных и существовать без посторонней помощи. И знаете, почему человек когда-нибудь это сделает? Потому что этого требует эволюция. Но эволюция не самого человека, а земной цивилизации — огромного живого организма.
Можно сколько угодно говорить, что из немыслимого количества планет Вселенной только на одной Земле случайно правильно легли друг к другу молекулы углерода, образовав когда-то первую клетку, из которой потом вышла вся земная цивилизация. Которая, в свою очередь, уже приближается к синтезу этой самой жизни искусственным путем. Неужели человек нарушает теорию эволюции? Ведь еще ни одно живое существо на Земле не порождало новую ветвь жизни таким образом. Неизбежно возникает вопрос: если человек произошел от какого-то существа на Земле, то почему между человеком и всеми земными существами такая пропасть в развитии? Разве кого-то из наших четвероногих друзей заботит мысль о существовании подобных им существ где-то еще во Вселенной? Кто из них пытался, например, помолиться Богу или создать себе помощника, который бы готовил еду, убирал жилище и т. д.
Мы не воспринимаем свою цивилизацию как живой организм. Но согласно той же теории эволюции, и он эволюционирует, и тоже способен порождать себе подобных —другие цивилизации. Человек — это как бы родильная часть цивилизации. Им создается зародыш (первые живые роботы), им же они развиваются (создаются более совершенные модели, их взаимосвязи между собой — грубо говоря, кто у кого будет на побегушках), и только потом происходят «роды» (не у себя же на планете, где уже есть жизнь, причем довольно агрессивная и жестокая — с ней человеку делать нечего, только «прогибаться»).
Да, все это гипотезы. Но согласитесь, они также неплохо объясняют разницу в развитии между человеком и другими земными существами. Одним словом, инопланетяне, боги и все такое.
Анализ данных, представленных в статье про общение с роботом, подтверждает эффективность применения современных технологий для обеспечения инновационного развития и улучшения качества жизни в различных сферах. Надеюсь, что теперь ты понял что такое общение с роботом и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Искусственный интеллект
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

Комментарии