Лекция
Это продолжение увлекательной статьи про архитектура нейронных сетей.
...
параметров
Например, если взять нейросеть из 3 скрытых слоев, которой нужно обрабатывать картинки 100*100 ps, это значит, что на входе будет 10 000 ps, и они заводятся на 3 слоя. В общем, если честно посчитать все параметры, у такой сети их будет порядка миллиона. Это на самом деле много. Чтобы обучить нейросеть с миллионом параметров, нужно очень много обучающих примеров, которые не всегда есть. На самом деле сейчас примеры есть, а раньше их не было — поэтому, в частности, сети не могли обучать, как следует.
Кроме того, сеть, у которой много параметров, имеет дополнительную склонность переобучаться. Она может заточиться на то, чего в реальности не существует: какой-то шум Data Set. Даже если, в конце концов, сеть запомнит примеры, но на тех, которых она не видела, потом не сможет нормально использоваться.
Плюс есть другая проблема под названием:
Помните ту историю про Backpropagation, когда ошибка с выходов отправляется на вход, распределяется по всем весам и отправляется дальше по сети? Далее эти производные — то есть градиент (производная ошибки) — прогоняются через нейросеть обратно. Когда в нейросети много слоев, от этого градиента в самом конце может остаться очень-очень маленькая часть. В этом случае веса на входе будет практически невозможно изменить потому, что этот градиент практически «сдох», его там нет.
Это тоже проблема, из-за которой глубокие нейросети тоже сложно обучать. К этой теме мы еще вернемся дальше, особенно на рекуррентных сетях.

Есть различные вариации FNN-сетей. Например, очень интересная вариация Автоэнкодер. Это сеть прямого распространения с так называемым бутылочным горлышком в середине. Это очень маленький слой, допустим, всего на 10 нейронов.
В чем преимущества такой нейросети?
Цель этой нейросети взять какой-то вход, прогнать через себя и на выходе сгенерировать тот же самый вход, то есть чтобы они совпадали. В чем смысл? Если мы сможем обучить такую сеть, которая берет вход, прогоняет через себя и генерирует точно такой же выход, это значит, что этих 10 нейронов в середине достаточно для описания этого входа. То есть можно очень сильно уменьшить пространство, сократить объем данных, экономно закодировать любые входные данные в новых терминах 10 векторов.
Это удобно, и это работает. Такие сети могут помочь вам, например, уменьшить размерность вашей задачи или найти какие-то интересные фичи, которые можно использовать.

Есть еще интересная модель RBM. Я ее написал в вариации FNN, но на самом деле это не правда. Во-первых, она не глубокая, во-вторых, она не Feed-Forward. Но она часто связана с FNN-сетями.
Что это такое?
Это неглубокая модель (на слайде она в уголке нарисована), у которой есть вход и есть какой-то скрытый слой. Вы подаете сигнал на вход и пытаетесь обучить скрытый слой так, чтобы он генерил этот вход.
Это генеративная модель. Если вы ее обучили, то потом можете генерить аналоги ваших входных сигналов, но чуть-чуть другие. Она стохастическая, то есть каждый раз она будет генерить что-то чуть другое. Если вы, например, обучили такую модель на генерацию рукописных единичек, она потом их нагенерит какое-то количество немножко разных.
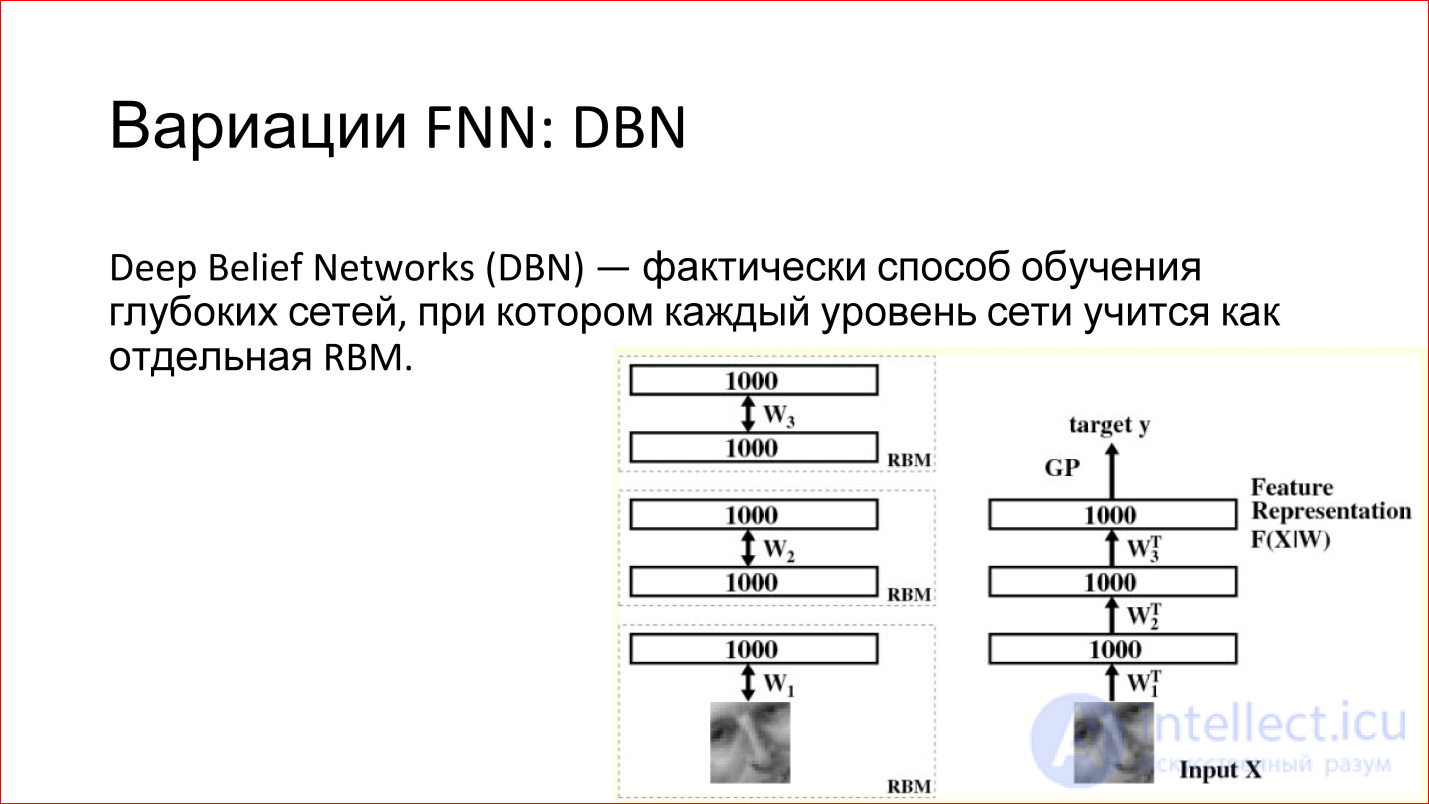
Чем хороши RBM — тем, что их можно использовать для обучения глубоких сетей. Есть такой термин — Deep Belief Networks (DBN) — фактически это способ обучения глубоких сетей, когда берутся отдельно 2 нижних слоя глубокой сети, подается вход и RBM обучается на этих первых двух слоях. После этого фиксируются эти веса. Далее берется второй слой, рассматривается как отдельная RBM и точно также обучается. И так по всей сети. Потом эти RBM стыкуются, объединяются в одну нейросеть. Получается глубокая нейросеть, какая и должна была бы быть.
Но теперь есть огромное преимущество — если бы раньше вы ее обучали просто с какого-то рандомного (случайного) состояния, то теперь оно не рандомное – сеть обучена восстанавливать или генерить данные предыдущего слоя. То есть у нее веса разумные, и на практике это приводит к тому, что такие нейросети действительно уже довольно неплохо обучены. Их потом можно слегка дообучить какими-то примерами, и качество такой сети будет хорошим.
Плюс есть дополнительное преимущество. Когда вы используете RBM, вы, по сути, работаете на неразмеченных данных, что называется Un supervised learning. У вас есть просто картинки, вы не знаете их классов. Вы прогнали миллионы, миллиарды картинок, которые вы скачали с Flickr’а или еще откуда-то, и у вас есть какая-то структура в самой сети, которая описывает эти картинки.
Вы не знаете, что это такое еще, но это разумные веса, которые можно потом взять и дообучить небольшим количеством различных картинок, и уже будет хорошо. Это классный вариант использования комбинации 2 нейросетей.
Дальше вы увидите, что вся эта история на самом деле — про Lego. То есть у вас есть отдельные сети —
рекуррентные нейросети , еще какие-то сети — это все блоки, которые можно совмещать. Они хорошо совмещаются на разных задачах.
Это были классические нейросети прямого распространения. Далее перейдем к сверточным нейросетям.
Convolutional Neural Networks, CNN
https://research.facebook.com/blog/learning-to-segment/
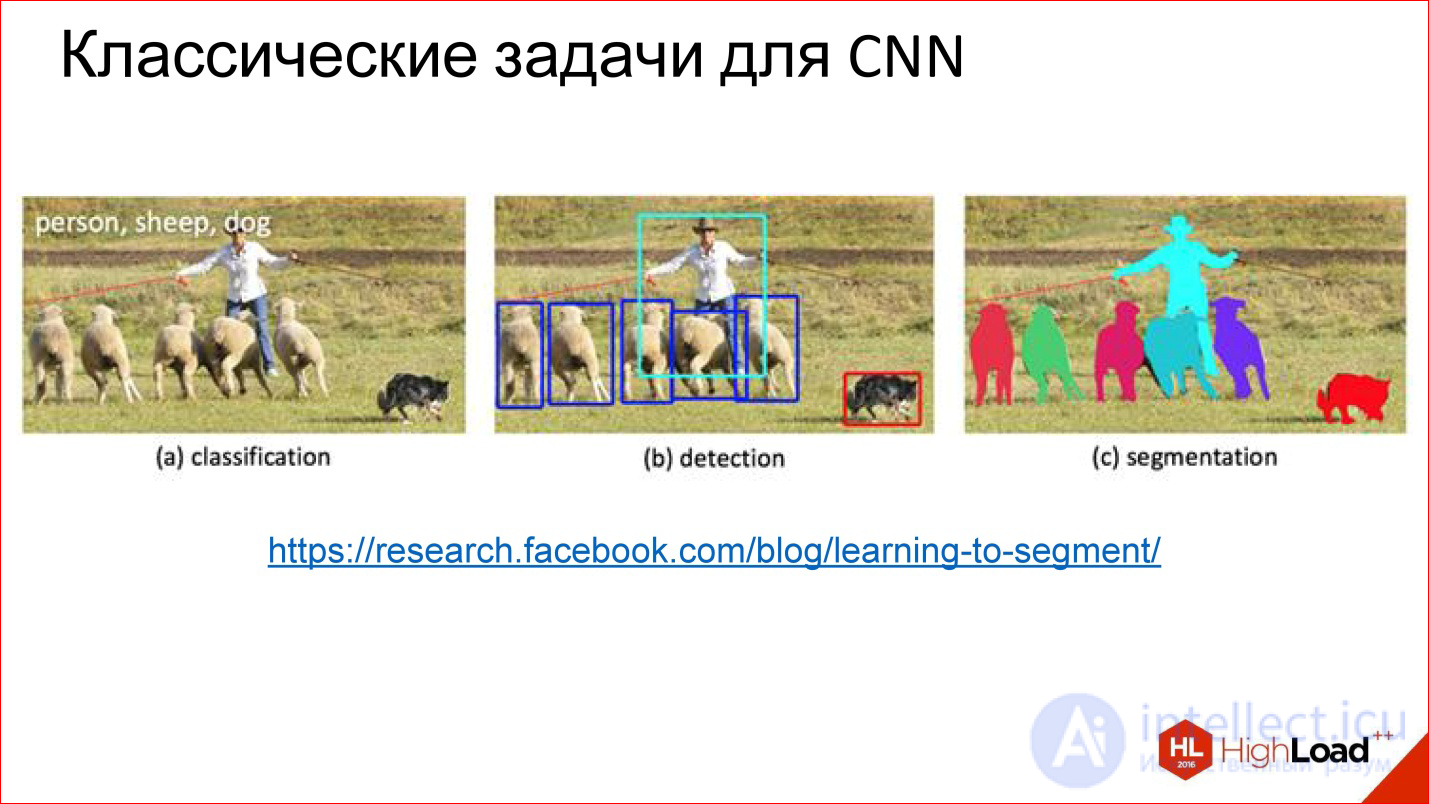
Сверточные нейросети решают 3 основные задачи:
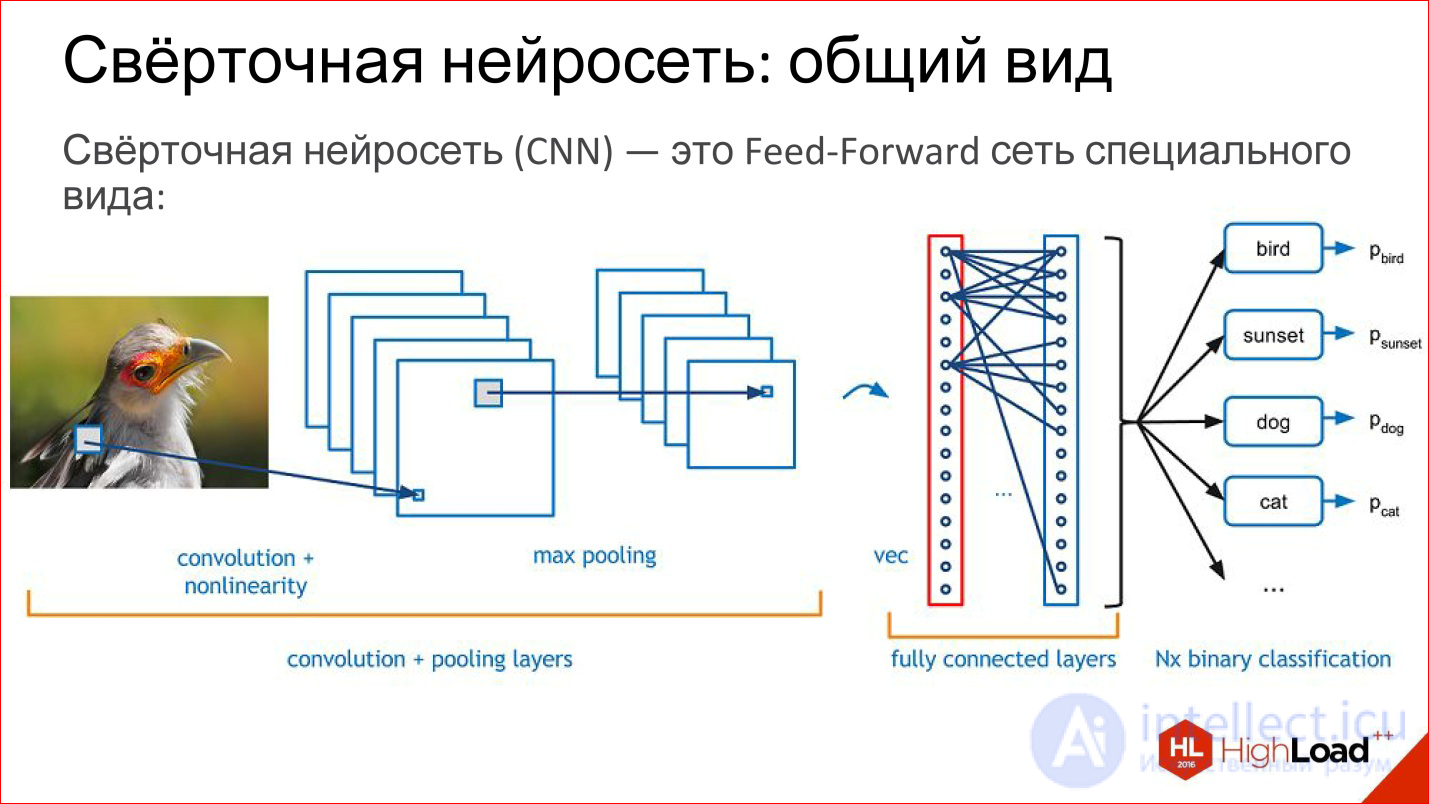
Что такое сверточная нейросеть? На самом деле сверточная нейросеть — это обычная Feed-Forward сеть, просто она немножко специального вида. Вот уже начинается Lego.
Что есть в сверточной сети? У нее есть:
Немного более подробно про все эти слои.

http://intellabs.github.io/RiverTrail/tutorial/
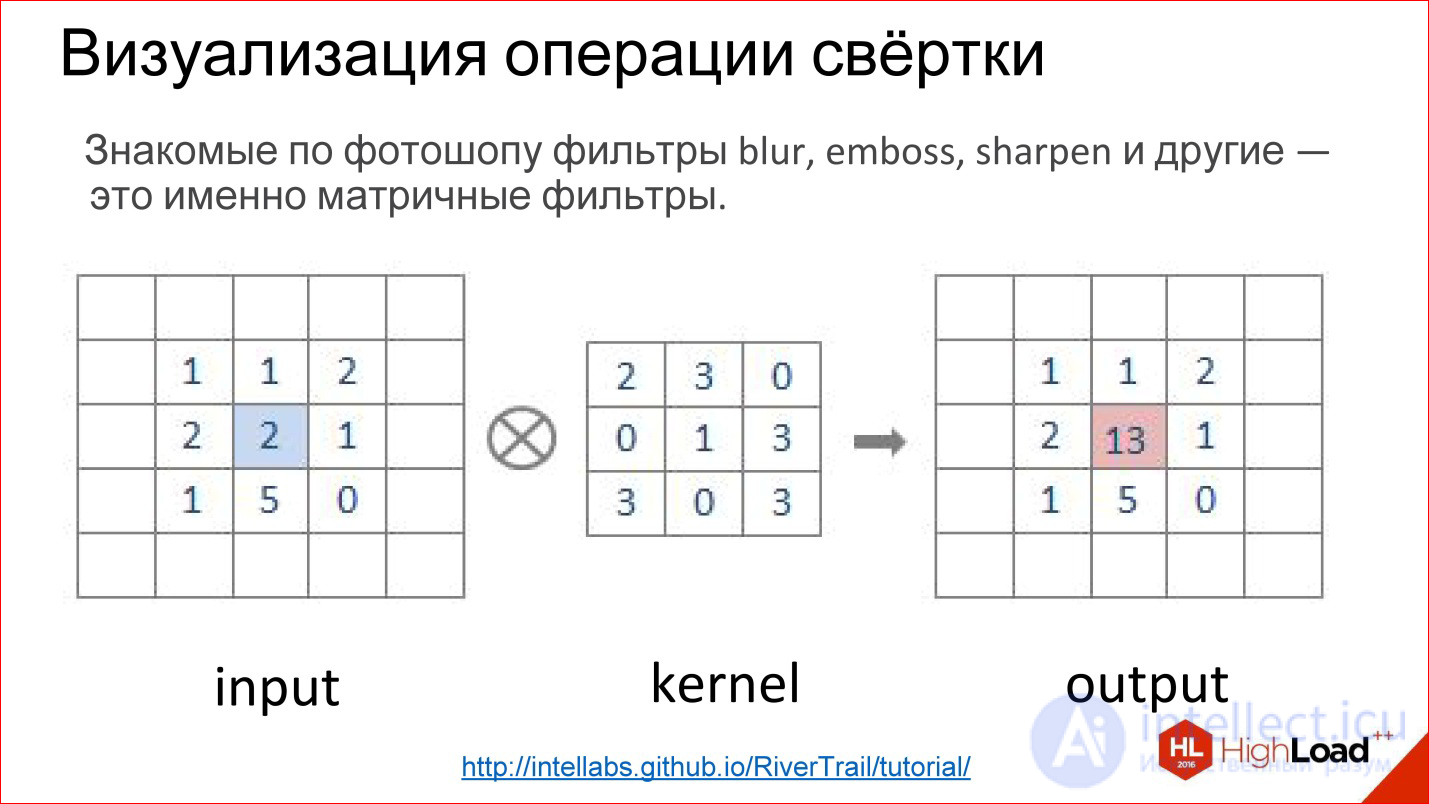
Что такое операция свертки? Это всех пугает, но на самом деле это очень простая вещь. Если вы работали в Photoshop и делали Gaussian Blur, Emboss, Sharpen и кучу других фильтров, это все матричные фильтры. Матричные фильтры — это на самом деле и есть операция свертки.
Как она реализована? Есть матрица, которая называется ядром фильтра (на рисунке kernel). Для Blur это будут все единицы. Есть изображение. Эта матрица накладывается на кусочек изображения, соответствующие элементы просто перемножаются, результаты складываются и записываются в центральную точку.
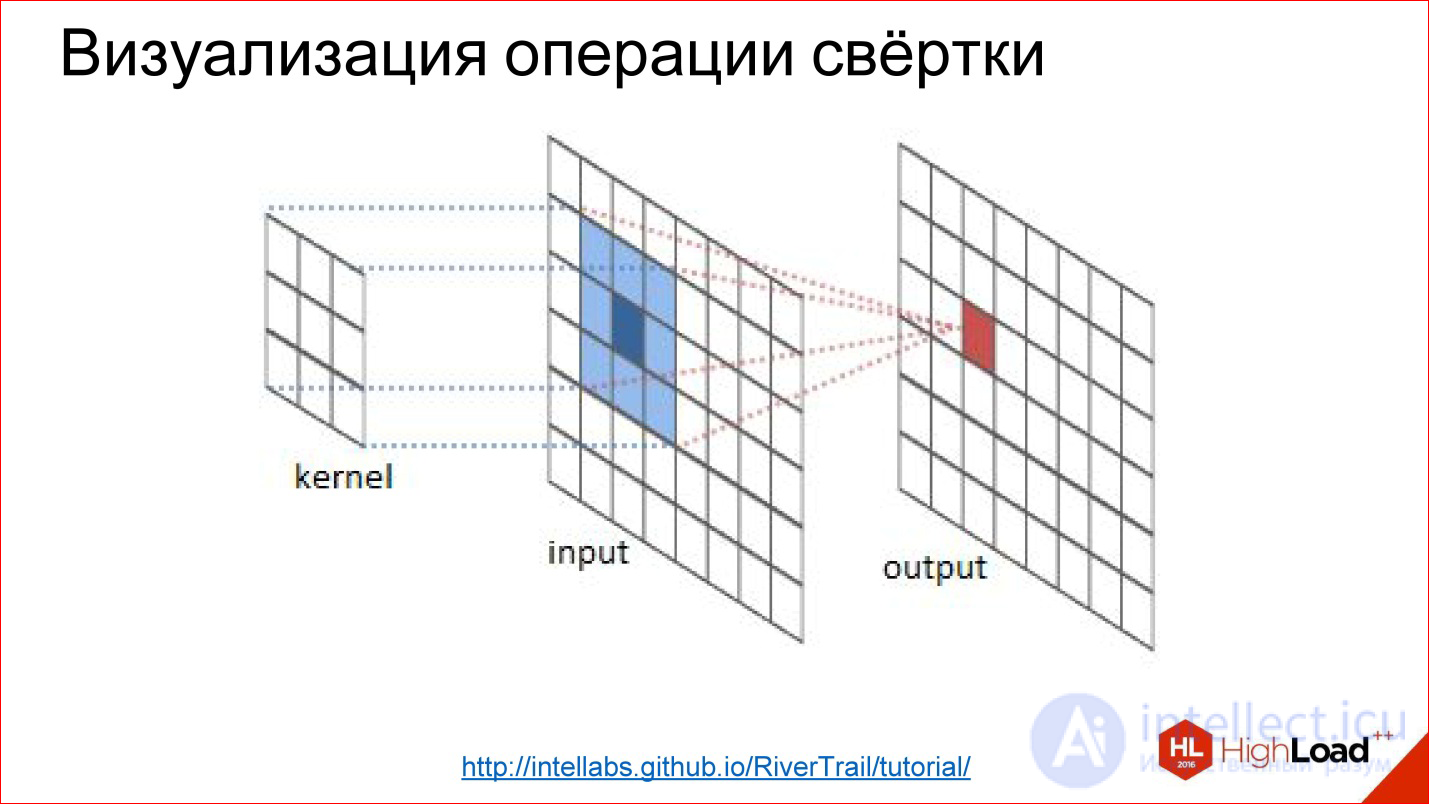
http://intellabs.github.io/RiverTrail/tutorial/
Так это выглядит более наглядно. Есть изображение Input, есть фильтр. Вы пробегаете фильтром по всему изображению, честно перемножаете соответствующие элементы, складываете, записываете в центр. Пробегаете, пробегаете — построили новое изображение. Все, это операция свертки.
То есть, по сути,
свертка в сверточных нейросетях — это хитрый цифровой фильтр (Blur, Emboss, что угодно еще), который сам обучается.
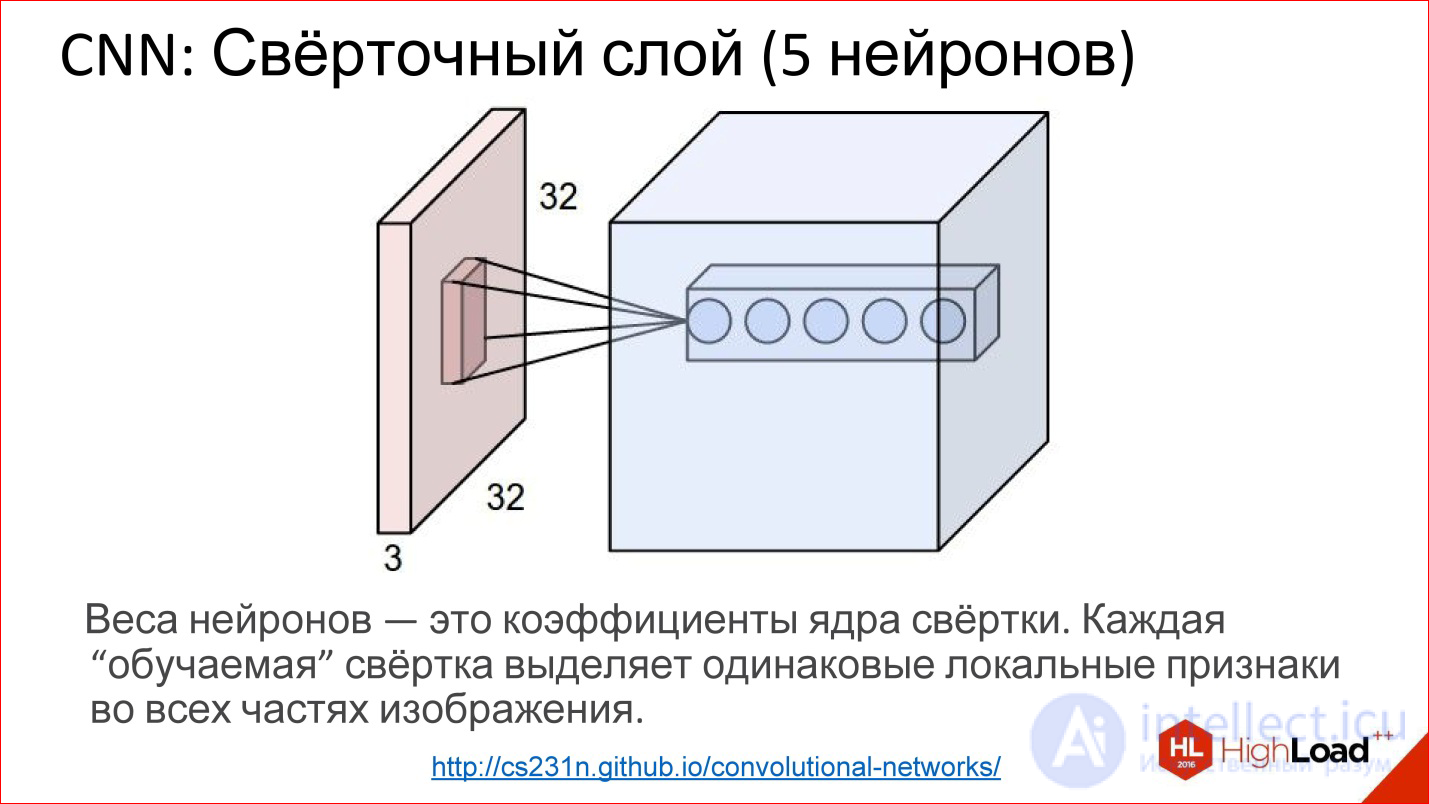
http://cs231n.github.io/convolutional-networks/
На самом деле сверточные слои все работают на объемах. То есть если даже взять обычное изображение RGB, там уже 3 канала — это, по сути, не плоскость, а объем из 3-х, условно, кубиков.
Свертка в этом случае уже представляется не матрицей, а тензором — кубиком на самом деле.
У вас есть фильтр, вы пробегаете по всему изображению, он сразу смотрит на все 3 цветовых слоя и генерит одну новую точку для одного этого объема. Пробегаете по всему изображению — построили один канал, одну плоскость нового изображения. Если у вас 5 нейронов — вы построили 5 плоскостей.
Так работает сверточный слой. Задача обучения сверточного слоя — это задача такая же, как в обычных нейросетях — найти веса, то есть фактически найти ту самую матрицу свертки, которая полностью эквивалентна весам в нейронах.
Что делают такие нейроны? Они фактически учатся искать какие-то фичи, какие-то локальные признаки в той небольшой части, которую они видят — и все. Прогон одного такого фильтра — это построение некой карты нахождения этих признаков в изображении.
Потом вы построили много таких плоскостей, дальше их используете как изображение, подавая на следующие входы.

http://vaaaaaanquish.hatenablog.com/entry/2015/01/26/060622
Операция Pooling — еще более простая операция. Это просто усреднение либо взятие максимума. Она тоже работает на каких-то небольших квадратиках, например, 2*2. Вы накладываете на изображение и, например, выбираете максимальный элемент из этого квадратика 2*2, отправляете на выход.
Таким образом вы уменьшили изображение, но не хитрым Average, а чуть более продвинутой штукой — взяли максимум. Это дает небольшую инвариантность к смещениям. То есть вам не важно, какой-то признак нашелся в этой позиции или на 2 ps вправо. Эта штука позволяет нейросети быть чуть более устойчивой к сдвигам изображения.
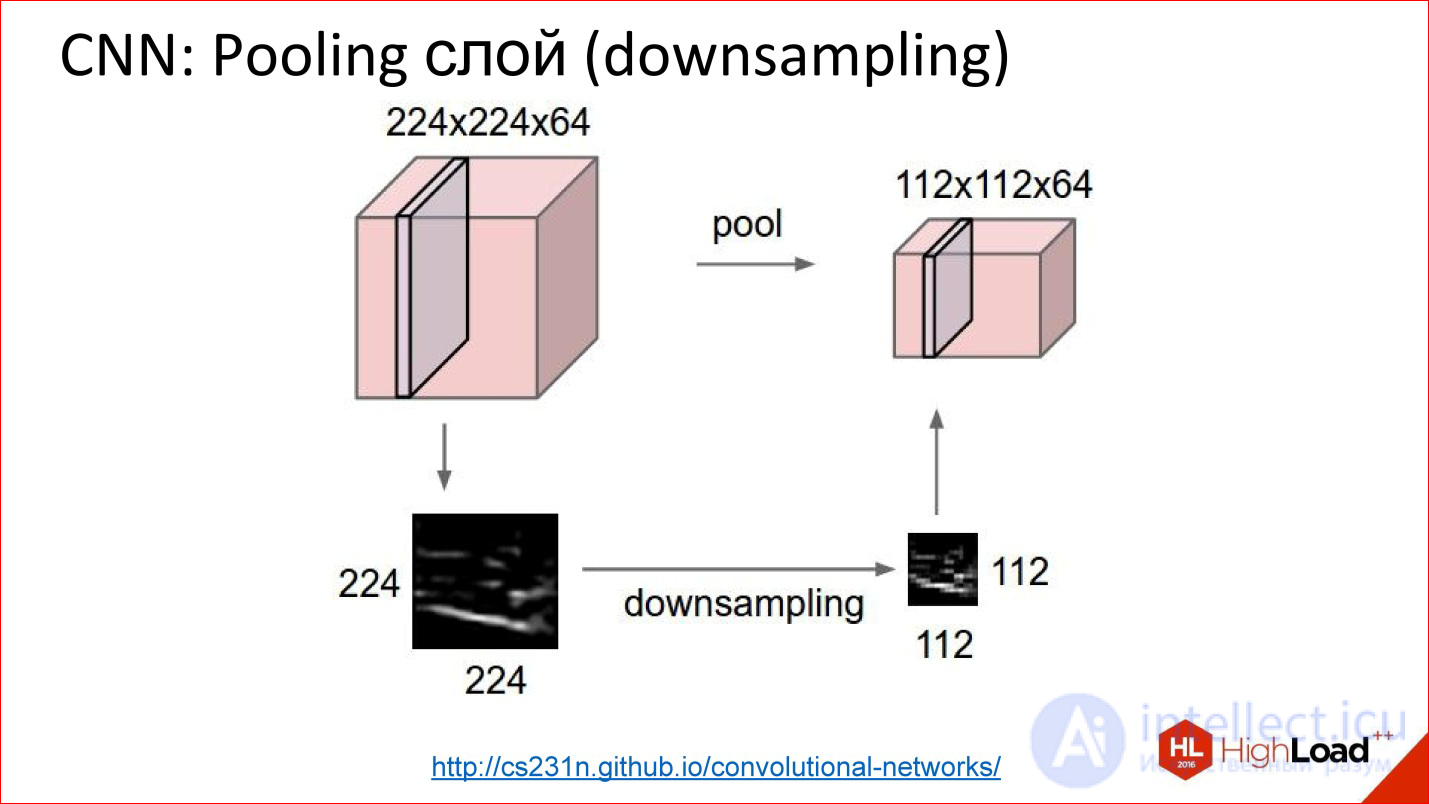
http://cs231n.github.io/convolutional-networks/
Так работает Pooling-слой. Есть кубик какого-то объема — 3 канала, 10, или 100 каналов, которые вы насчитали свертками. Он просто уменьшает его по ширине и по высоте, остальные размерности не трогает. Все — примитивная вещь.

Чем хороши сверточные сети?
Они хороши тем, что у них сильно меньше параметров, чем у обычной полносвязной сети. Вспомните пример с полносвязной сетью, который мы рассматривали, где получился миллион весов. Если взять аналогичную, точнее, похожую — аналогичной ее нельзя назвать, но близкую сверточную нейросеть, у которой будет такой же вход, такой же выход, тоже будет один полносвязный слой на выходе и еще 2 сверточных слоя, где тоже будет по 100 нейронов, как в базовой сети, то выяснится, что число параметров в такой нейросети уменьшилось больше, чем на порядок.
Это здорово, если параметров настолько меньше — сеть проще обучать. Мы это видим, ее действительно проще обучать.
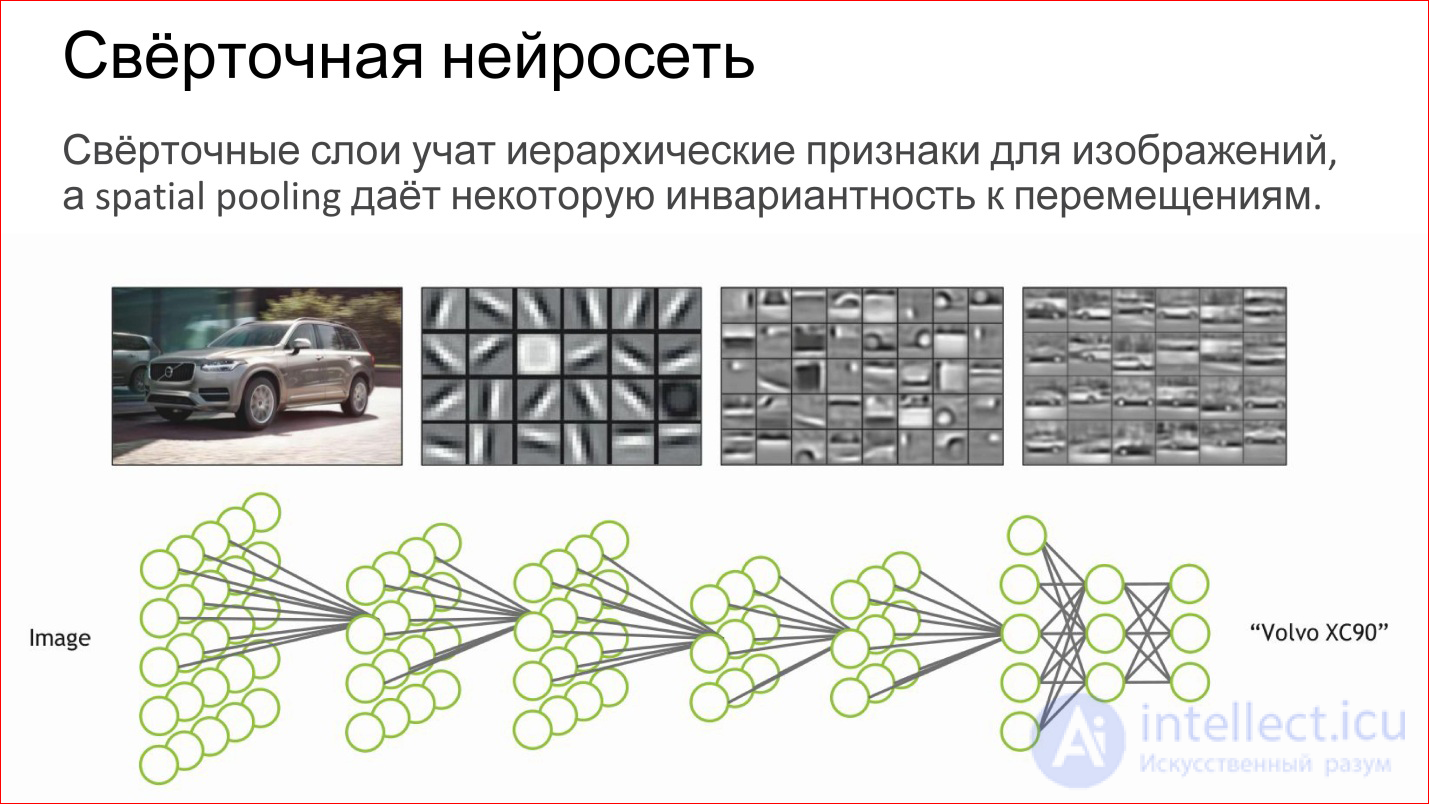
Что делает сверточная нейросеть?
По сути, она автоматически учит какие-то иерархические признаки для изображений: сначала базовые детекторы, линии разного наклона, градиенты и т.д. Из них она собирает какие-то более сложные объекты, потом еще более сложные.
Если вы воспринимаете нейрон как простую логистическую регрессию, простой классификатор, то нейросеть — это просто иерархический классификатор. Сначала вы выделяете простые признаки, из них комбинируете сложные признаки, из них еще более сложные, еще более сложные и в конце концов вы можете скомбинировать какой-то очень сложный признак — конкретный человек, конкретная машина, слон, что угодно еще.
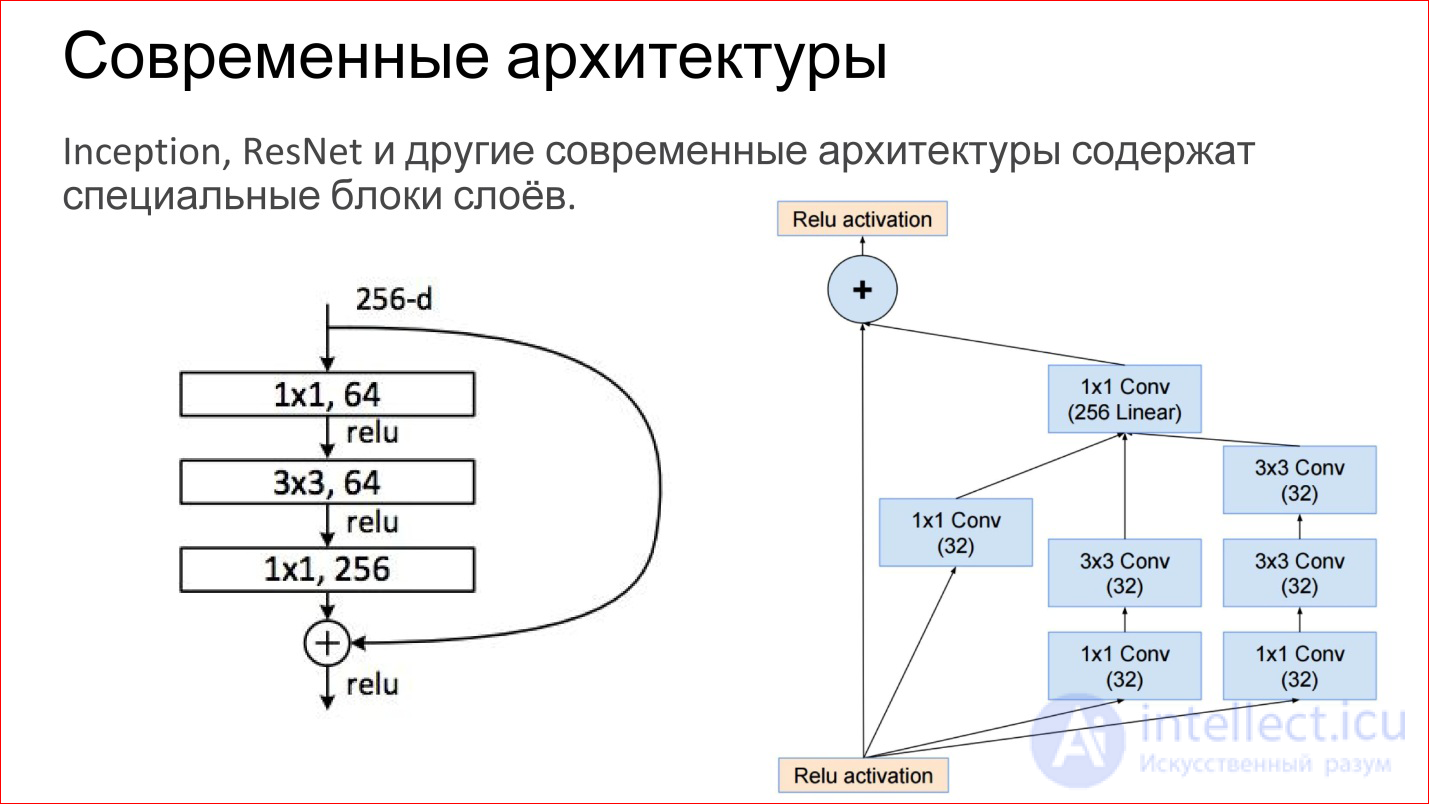
Современные архитектуры сверточных нейросетей сильно усложнились. Те нейросети, которые побеждали на последних соревнованиях ImageNet — это уже не просто какие-то сверточные слои, Pooling-слои. Это прямо законченные блоки. На рисунке приведены примеры из сети Inception (Google) и ResNet (Microsoft).
По сути, внутри те же самые базовые компоненты: те же самые свертки и пулинги. Просто теперь их больше, они как-то хитро объединены. Плюс сейчас есть прямые связи, которые позволяют вообще не трансформировать изображение, а просто передать его на выход. Это, кстати, помогает тому, что градиенты не затухают. Это дополнительный способ прохода градиента с конца нейросети к началу. Это тоже помогает обучать такие сети.
Это была совсем классика сверточных нейросетей. Да, там есть разные типы слоев, которые можно использовать для классификации. Но есть более интересные применения.

https://arxiv.org/abs/1411.4038
Например, есть такая разновидность сверточных нейросетей, называется Fully-convolutional networks (FCN). Про них редко говорят, но это классная вещь. Можно взять и оторвать последний многослойный персептрон, он не нужен — и выкинуть его. И тогда нейросеть магическим образом может работать на изображениях произвольного размера.
То есть она научилась, допустим, определять 1000 классов в изображениях кошечек, собачек, чего-то еще, а потом мы последний слой взяли и не оторвали, но трансформировали в сверточный слой. Там нет проблем — можно веса пересчитать. Тогда выясняется, что эта нейросеть как бы работает тем же самым окном, на которое она была обучена, 100*100 ps, но теперь она может пробежаться этим окном по всему изображению и построить как бы тепловую карту на выходе — где в этом конкретном изображении находится конкретный класс.
Вы можете построить, например, 1000 этих Heatmap для всех своих классов и потом использовать это для определения места нахождения объекта на картинке.
Это первый пример, когда сверточная нейросеть используется не для классификации, а фактически для генерации изображения.
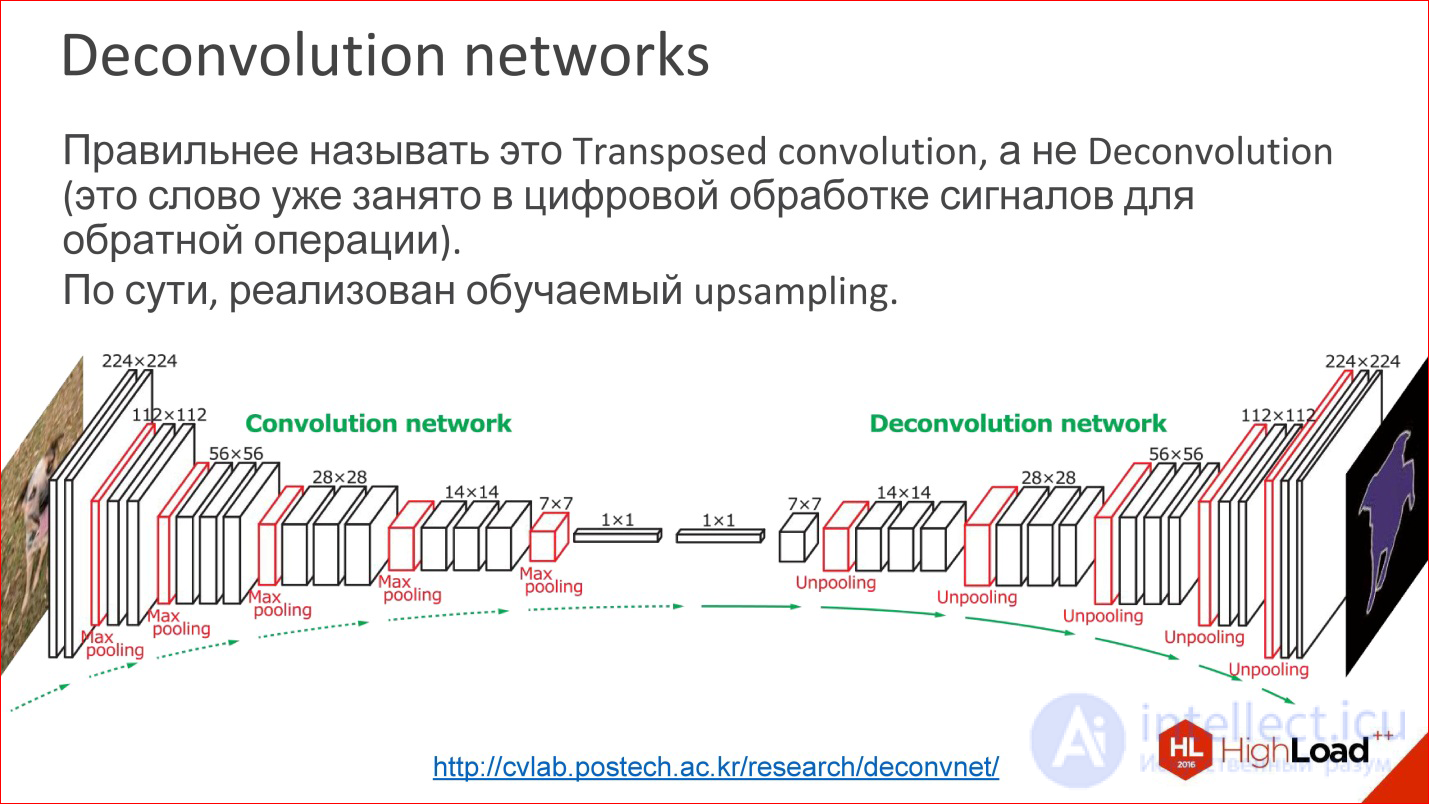
http://cvlab.postech.ac.kr/research/deconvnet/
Более продвинутый пример — Deconvolution networks. Про них тоже редко говорят, но это еще более классная штука.
На самом деле Deconvolution — это неправильный термин. В цифровой обработке сигналов это слово занято совсем другой вещью — похожей, но не такой.
Что это такое? По сути, это обучаемый Upsampling. То есть вы уменьшили в какой-то момент ваше изображение до какого-то небольшого размера, может, даже до 1 ps. Скорее, не до пикселя, а до какого-то небольшого вектора. Потом можно взять этот вектор и раскрыть.
Или, если в какой-то момент получилось изображение 10*10 ps, теперь можно делать Upsampling этого изображения, но каким-то хитрым способом, в котором веса Upsampling также обучаются.
Это — не магия, это работает, и фактически это позволяет обучать нейросети, которые из входной картинки получают какую-то выходную картинку. То есть вы можете подавать образцы входа/выхода, а то, что посередине, обучится само. Это интересно.
На самом деле много задач можно свести к генерации картинок. Классификация — классная задача, но она все-таки не всеобъемлющая. Есть много задач, где надо картинки генерить. Сегментация — это в принципе классическая задача, где надо на выходе картинку иметь.
Более того, если вы научились делать так, то можно сделать еще по-другому, более интересно.
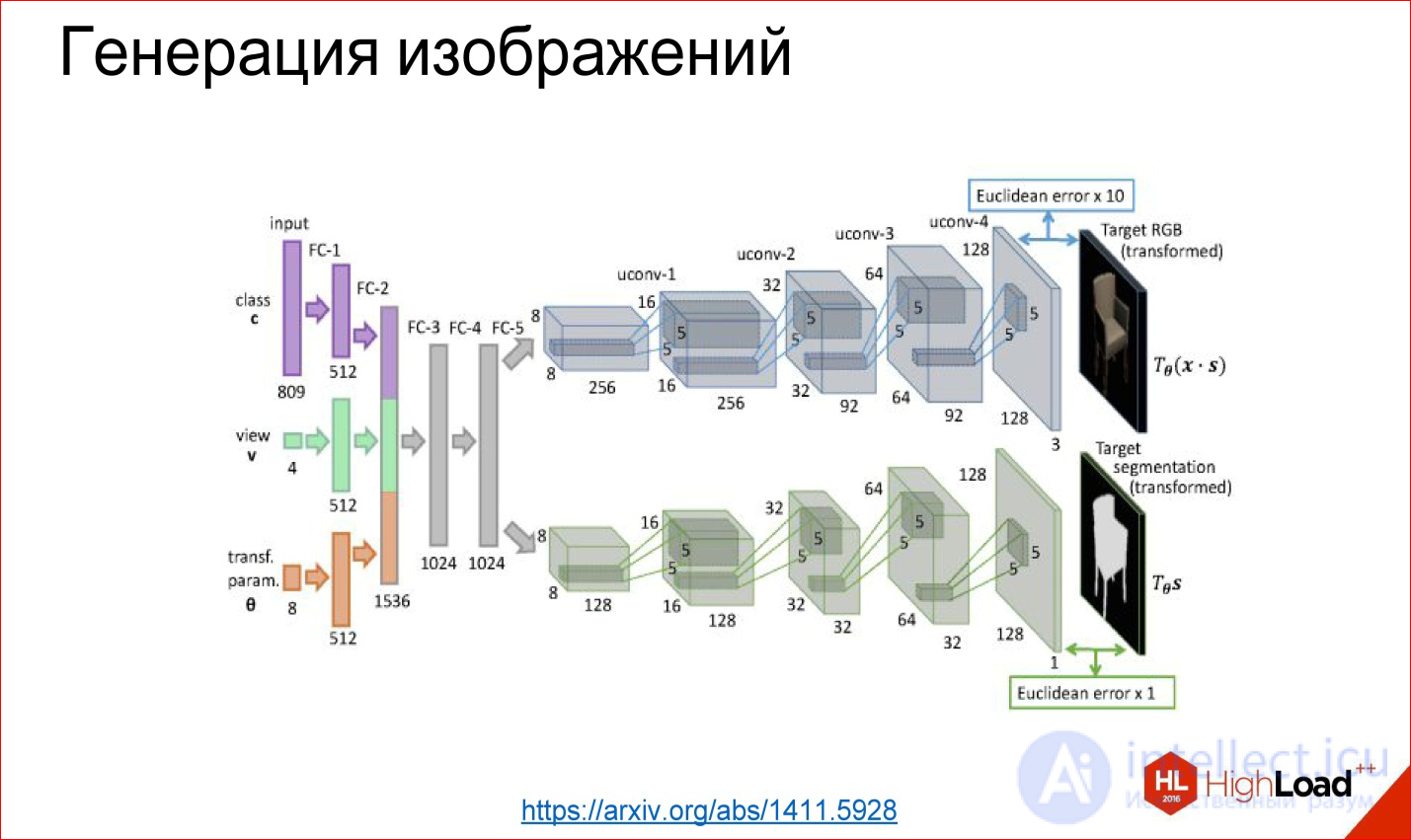
https://arxiv.org/abs/1411.5928
Можно первую часть, например, оторвать, а прикрутить какую-то опять полносвязную сеть, которую обучим — то, что ей на вход подается, например, номер класса: сгенери мне стул под таким-то углом и в таком-то виде. Эти слои генерят дальше какое-то внутреннее представление этого стула, а потом оно разворачивается в картинку.
Этот пример взят из работы, где действительно научили нейросеть генерить разные стулья и другие объекты. Это тоже работает, и это прикольно. Это собрано, в принципе, из тех же базовых блоков, но их по-другому завернули.

https://arxiv.org/abs/1508.06576
Есть неклассические задачи, например, перенос стиля, про который в последний год мы все слышим. Есть куча приложений, которые это умеют. Они работают на примерно таких же технологиях.
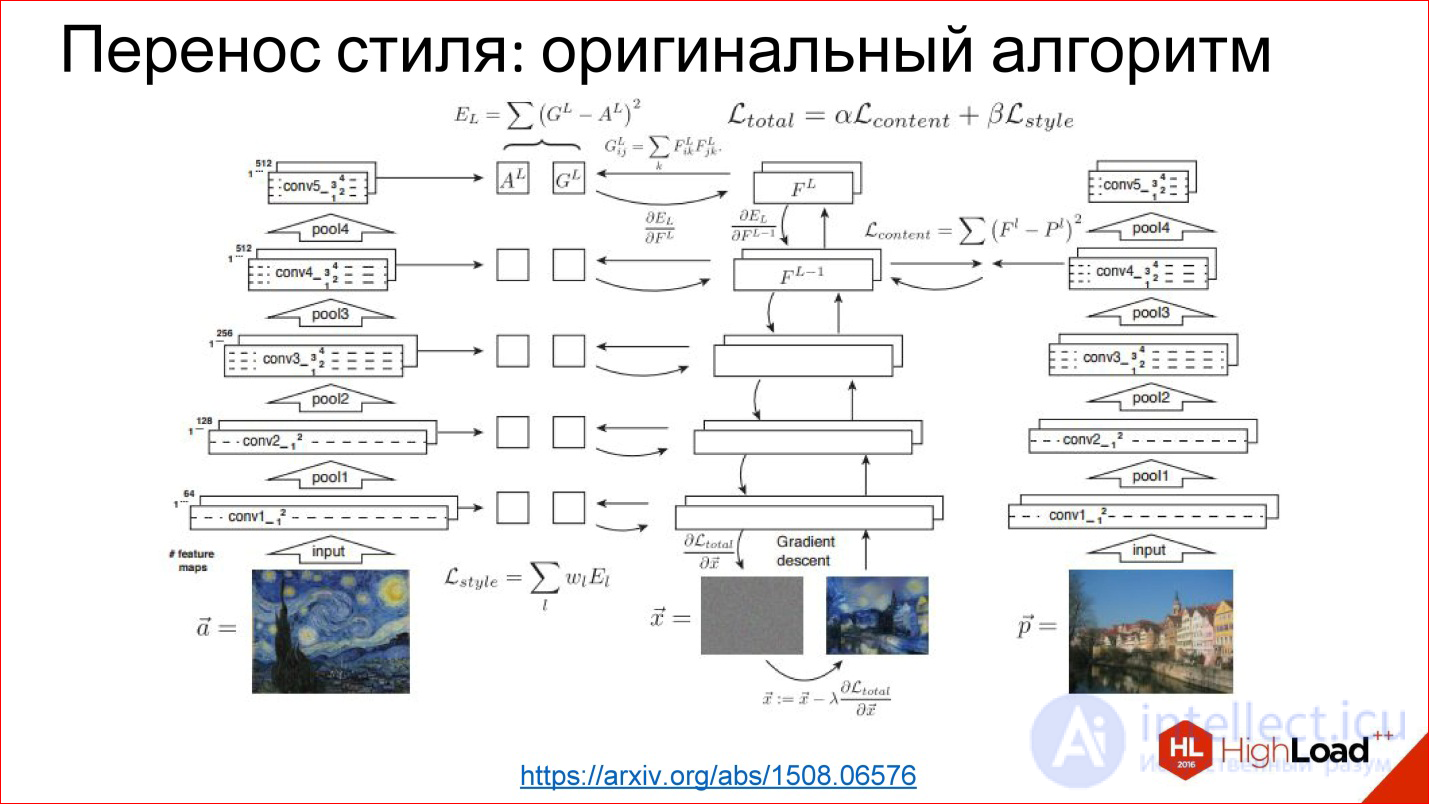
https://arxiv.org/abs/1508.06576
Есть готовая обученная сеть для классификации. Выяснилось, что если взять производную картинку, загрузить в эту нейросеть, то разные сверточные слои будут отвечать за разные вещи. То есть на первых сверточных слоях окажутся стилевые признаки изображения, на последних — контентные признаки изображения, и это можно использовать.
Можно взять картинку за образец стиля, прогнать ее через готовую нейросеть, которую вообще не обучали, снять стилевые признаки, запомнить. Можно взять любую другую картинку, прогнать, взять контентные признаки, запомнить. А потом рандомную картинку (шум) прогнать опять через эту нейросеть, получить признаки на тех же самых слоях, сравнить с теми, которые должны были получить. И у вас есть задача для Backpropagation. По сути, дальше градиентным спуском можно рандомную картинку трансформировать к такой, для которой эти веса на нужных слоях будут такими, как нужно. И вы получили стилизованную картинку.
Единственная проблема этого метода в том, что он долгий. Этот итеративный прогон картинки туда-сюда — это долго. Кто игрался с этим кодом по генерации стиля, знает, что классический код долгий, и надо помучиться. Все сервисы типа Призмы и так далее, которые генерят более-менее быстро, работают по-другому.
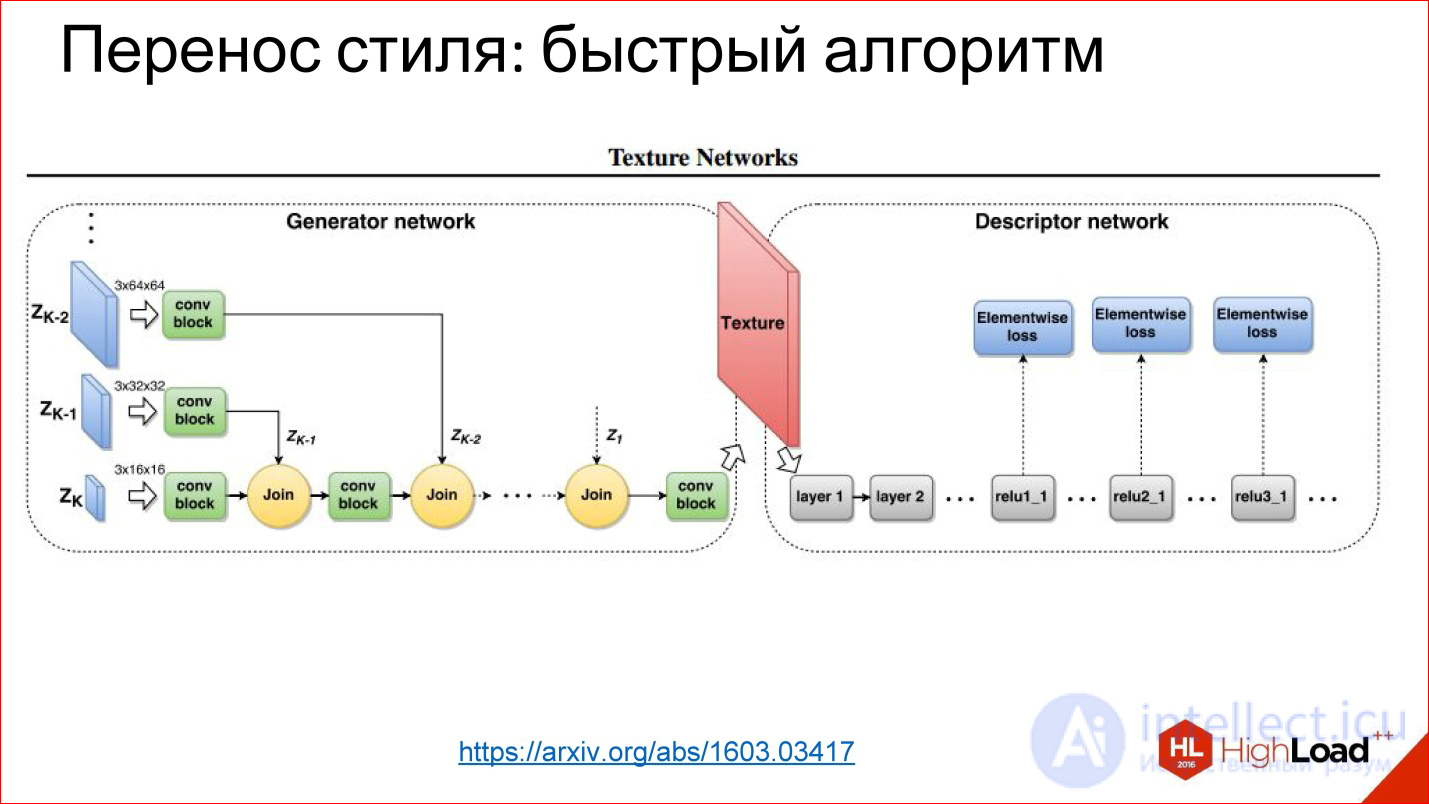
https://arxiv.org/abs/1603.03417
С тех пор научились генерить сети, которые просто за 1 проход генерят картинку. Это та же самая задача трансформации изображения, которую вы уже видели: есть на входе что-то, есть на выходе что-то, вы можете обучить все, что посередине.
В данном случае хитрость в том, что функцию потерь — ту самую функцию ошибки вы заводите на эту нейросеть, а функцию ошибки снимаете с обычной нейросети, которая обучена была для классификации.
Это такие хакерские методы использования нейросетей, но оказалось, что они работают, и это приводит к классным результатам.
Далее перейдем к рекуррентным нейросетям.
Recurrent Neural Networks, RNN
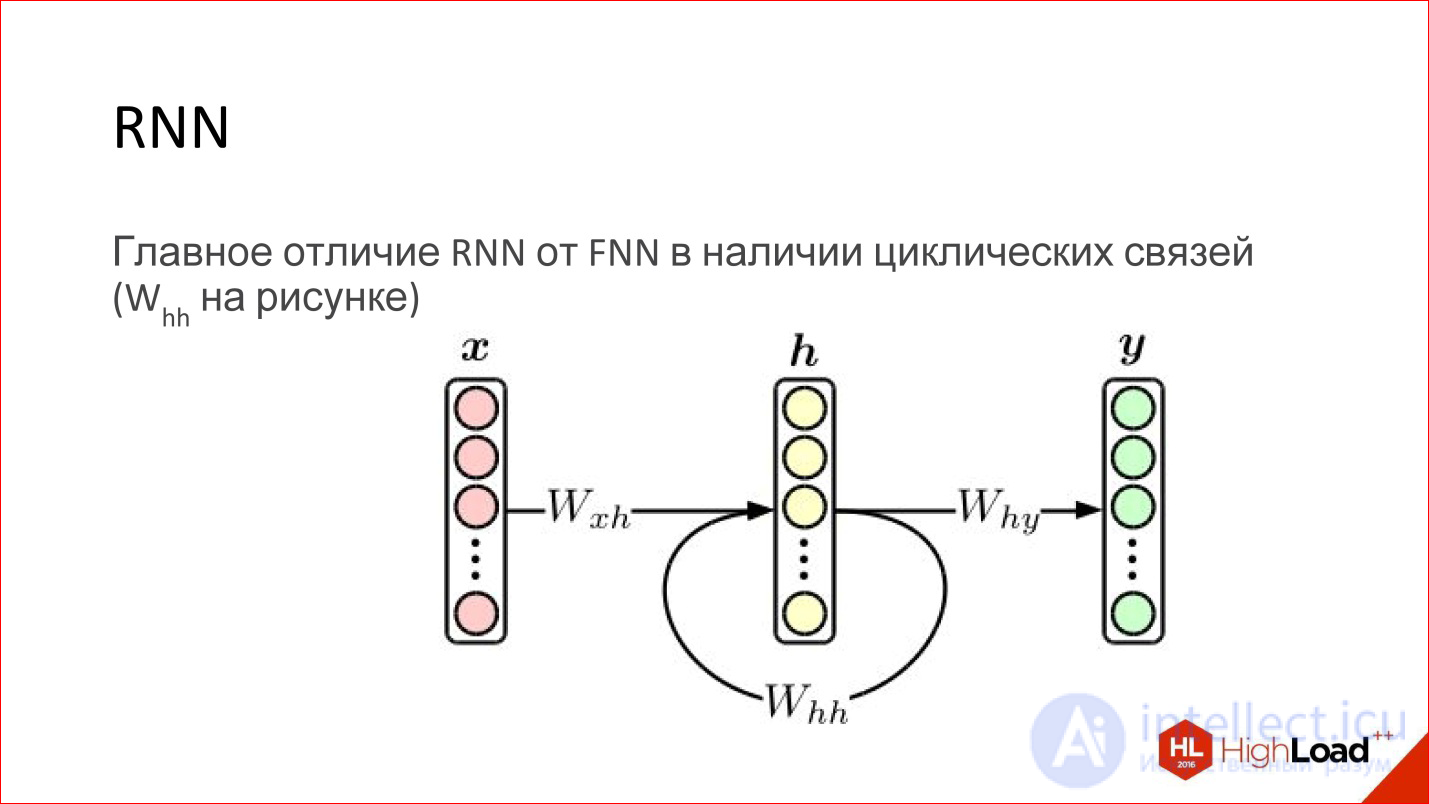
Рекуррентная нейросеть на самом деле очень крутая штука. На первый взгляд, главное отличие их от обычных FNN-сетей в том, что просто появляется какая-то циклическая связь. То есть скрытый слой свои же значения отправляет сам на себя на следующем шаге. Казалось бы, вроде бы минорная вещь, но есть принципиальная разница.

Про обычную нейросеть Feed-Forward известно, что это универсальный аппроксиматор. Они могут аппроксимировать более-менее любую непрерывную функцию (есть такая теорема Цыбенко). Это здорово, но рекуррентные нейросети — тьюринг полный. Они могут вычислить любое вычислимое.
По сути рекуррентные нейросети — это обычный компьютер. Задача — его правильно обучить. Потенциально он может считать любой алгоритм. Другое дело, что научить его сложно.
Кроме того, обычные Feed-Forward-нейросети никакой возможности не имеют учесть порядок во времени — нет в них этого, не представлено. Рекуррентные сети это делают явным образом, в них зашито понятие времени.
Обычные Feed-Forward сети не обладают никакой памятью, кроме той, которая была получена на этапе обучения, а рекуррентные обладают. За счет того, что содержимое слоя передается нейросети обратно, это как бы ее память. Она хранится во время работы нейросети. Это тоже очень многое добавляет.
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
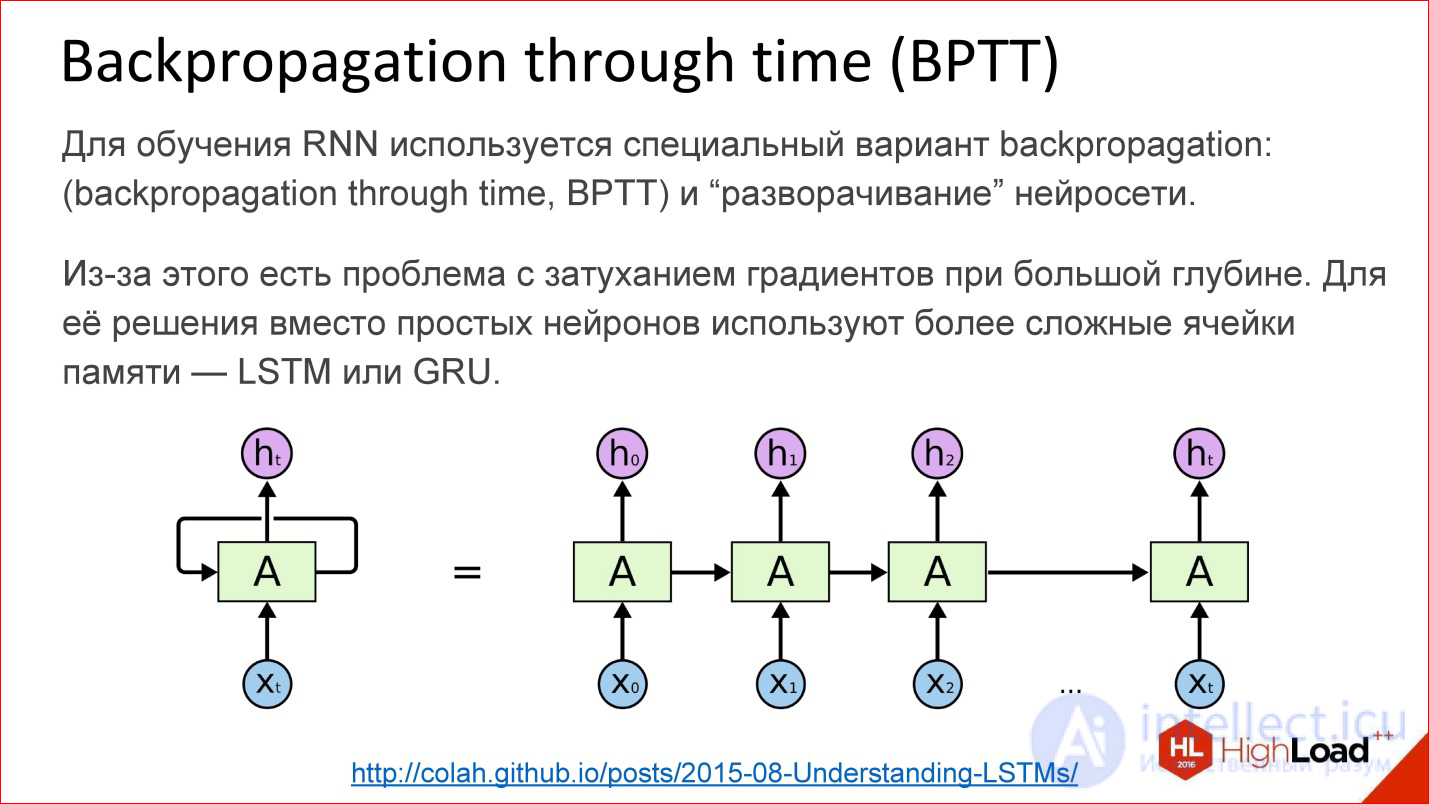
Как обучаются рекуррентные нейросети? На самом деле почти так же. Кроме Backpropagation, конечно, существует много других алгоритмов, но в данный момент Backpropagation работает лучше всего.
Для рекуррентных нейросетей есть вариация этого алгоритма — Backpropagation through time. Идея очень простая — вы берете рекуррентную нейросеть и цикл просто разворачиваете на сколько-то шагов, например, на 10, 20 или 100, и получается обычная глубокая нейросеть, которую после этого вы обучаете обычным Backpropagation.
Но есть проблема. Как только мы начинаем говорить про глубокие нейросети – где 10, 20, 100 слоев — от градиентов, которые с конца должны пройти в самое начало, за 100 слоев ничего не остается. С этим надо что-то делать. В этом месте придумали некий хак, красивое инженерное решение под названием LSTM или GRU- это ячейки памяти.
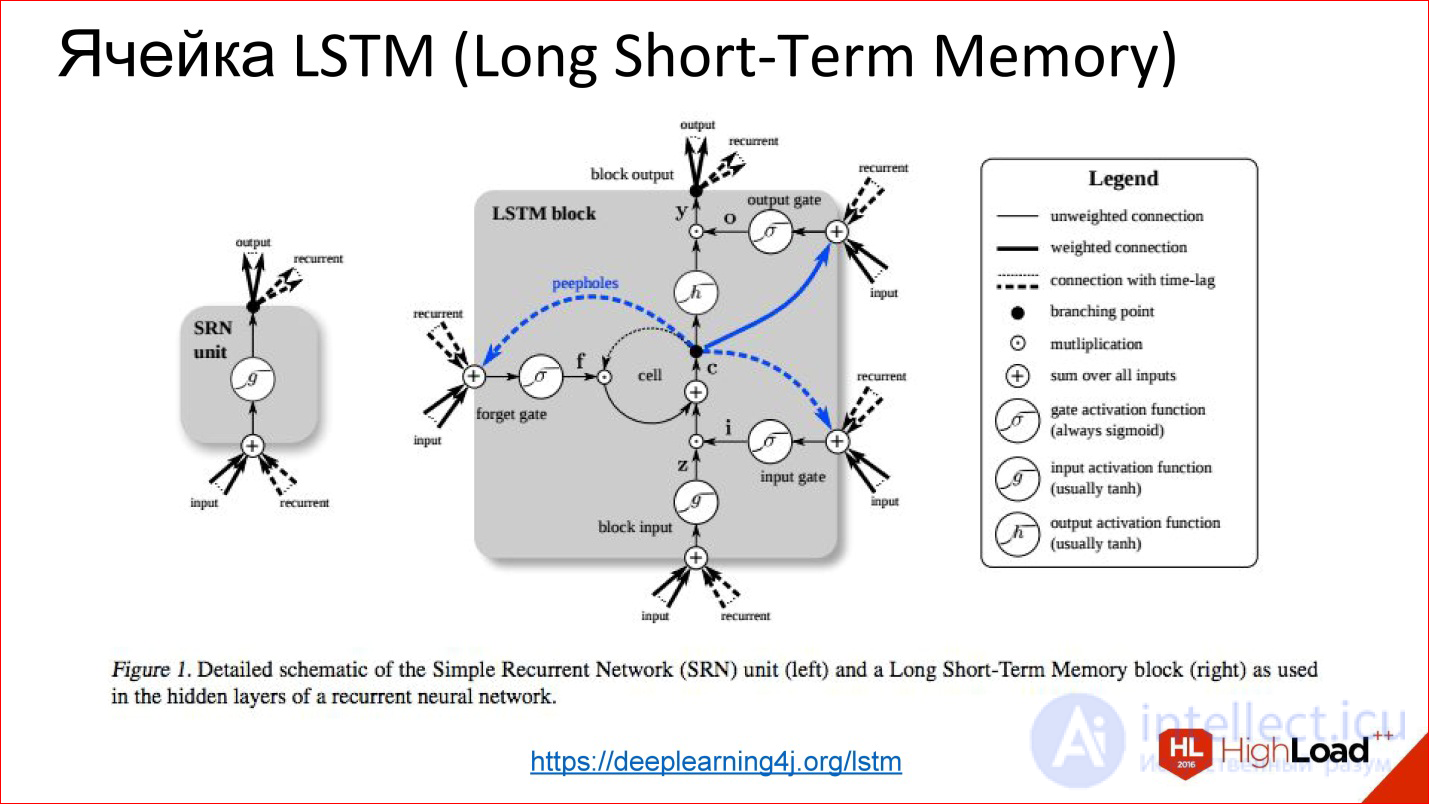
https://deeplearning4j.org/lstm
Их идея заключается в том, что визуализация обычного нейрона заменяется на некую хитрую штуку, у которой есть память и есть gate, которые контролируют то, когда эту память нужно сбросить, перезаписать или сохранить и т.д. Эти gate тоже обучаются так же, как и все остальное. Фактически эта ячейка, когда она обучилась, может сказать нейросети, что сейчас мы держим это внутреннее состояние долго, например, 100 шагов. Потом, когда нейросеть это состояние для чего-то использовала, его можно обнулить. Оно стало не нужно, мы пошли новое считать.
Эти нейросети на всех более-менее серьезных тестах сильно по качеству уделывают обычные классические рекуррентные, которые просто на нейронах. Почти все рекуррентные сети в данный момент построены либо на LSTM, либо на GRU.
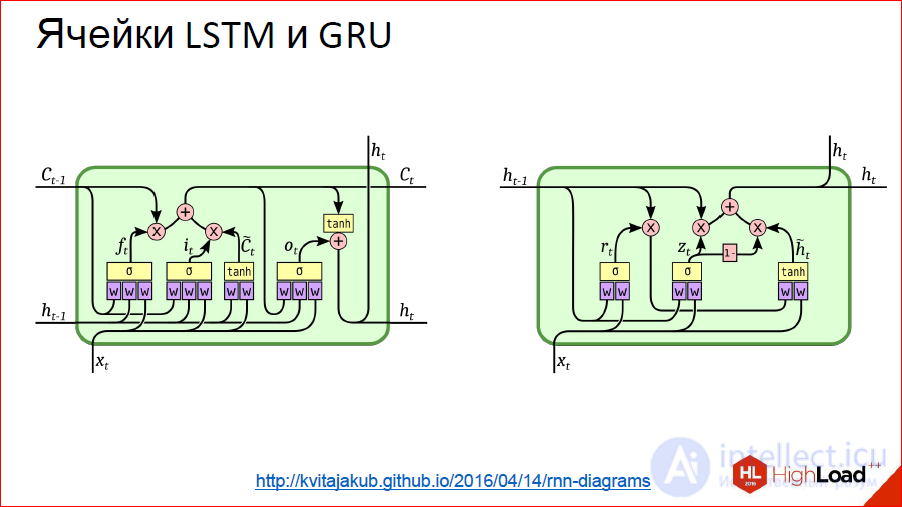
http://kvitajakub.github.io/2016/04/14/rnn-diagrams
Не буду углубляться, что это такое внутри, но это такие хитрые блоки, сильно сложнее, чем обычные нейроны, но, по сути, они похожи. Там есть некие gate, которые контролируют это самое «запомнить — не запомнить», «передать дальше — не передать дальше».
Это были классические рекуррентные нейросети. Дальше начинается тема, о которой часто умалчивается, но она тоже важная.
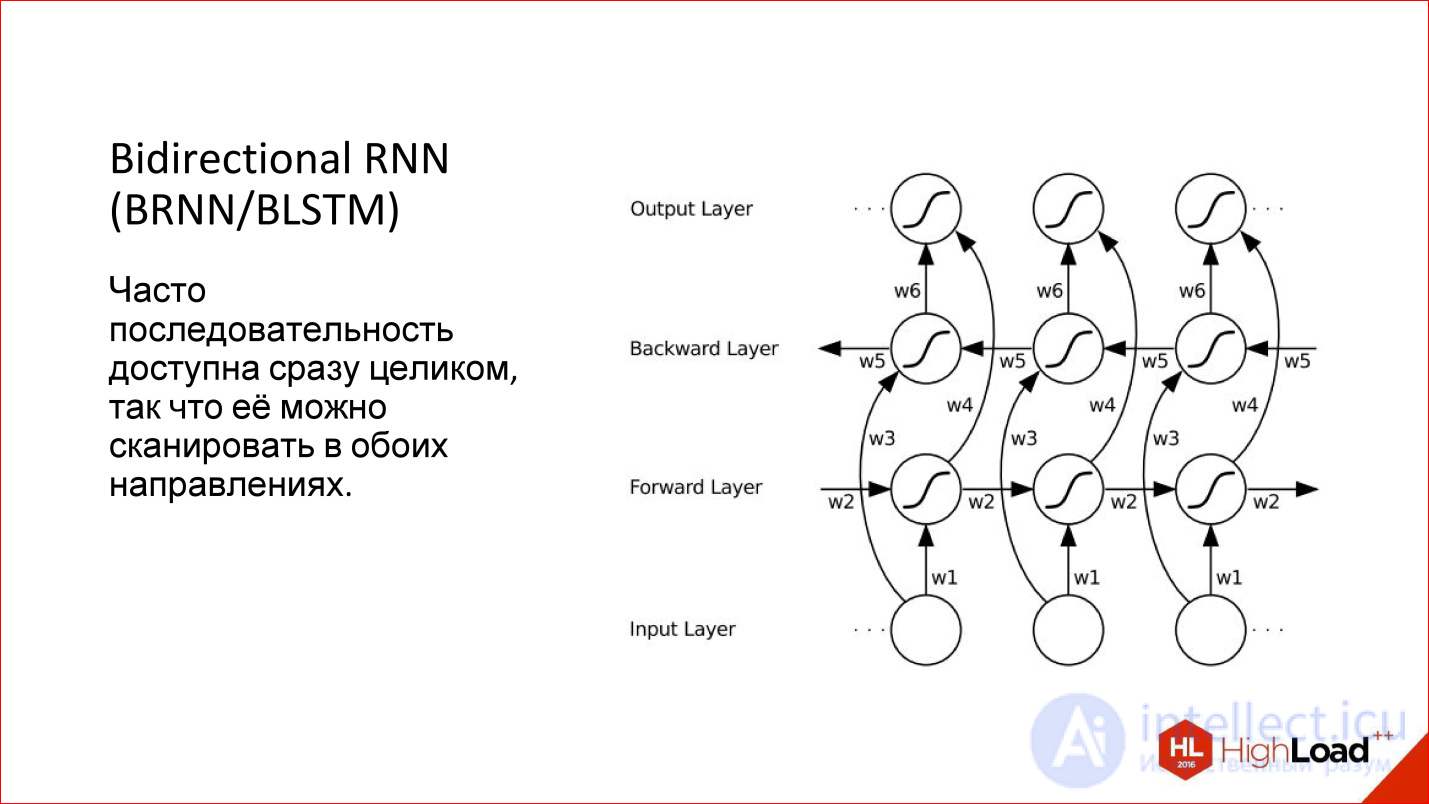
Когда мы работаем с последовательностью в рекуррентной сети, мы обычно подаем один элемент, потом следующий, и заводим предыдущее состояние сети на вход, возникает такое естественное направление — слева направо. Но оно же не единственное! Если у нас есть, например, предложение, мы начинаем подавать его слова в обычном порядке в нейросеть — да, это нормальный способ, но почему бы с конца не подать?
То есть во многих случаях последовательность дана уже целиком с самого начала. У нас есть это предложение, и нет смысла как-то выделять одно направление относительно другого. Мы можем прогнать нейросеть с одной стороны, с другой стороны, фактически имея 2 нейросети, а потом их результат скомбинировать.
Это и называется Bidirectional — двунаправленная рекуррентная нейросеть. Их качество еще выше, чем обычных рекуррентных сетей, потому что появляется больше контекста: для каждой точки теперь есть 2 контекста — что было до, и что будет после. Для многих задач это добавляет качества, особенно для задач, связанных с языком.
Например, есть немецкий язык, где в конце обязательно что-нибудь навесят, и предложение изменится — такая сеть поможет.
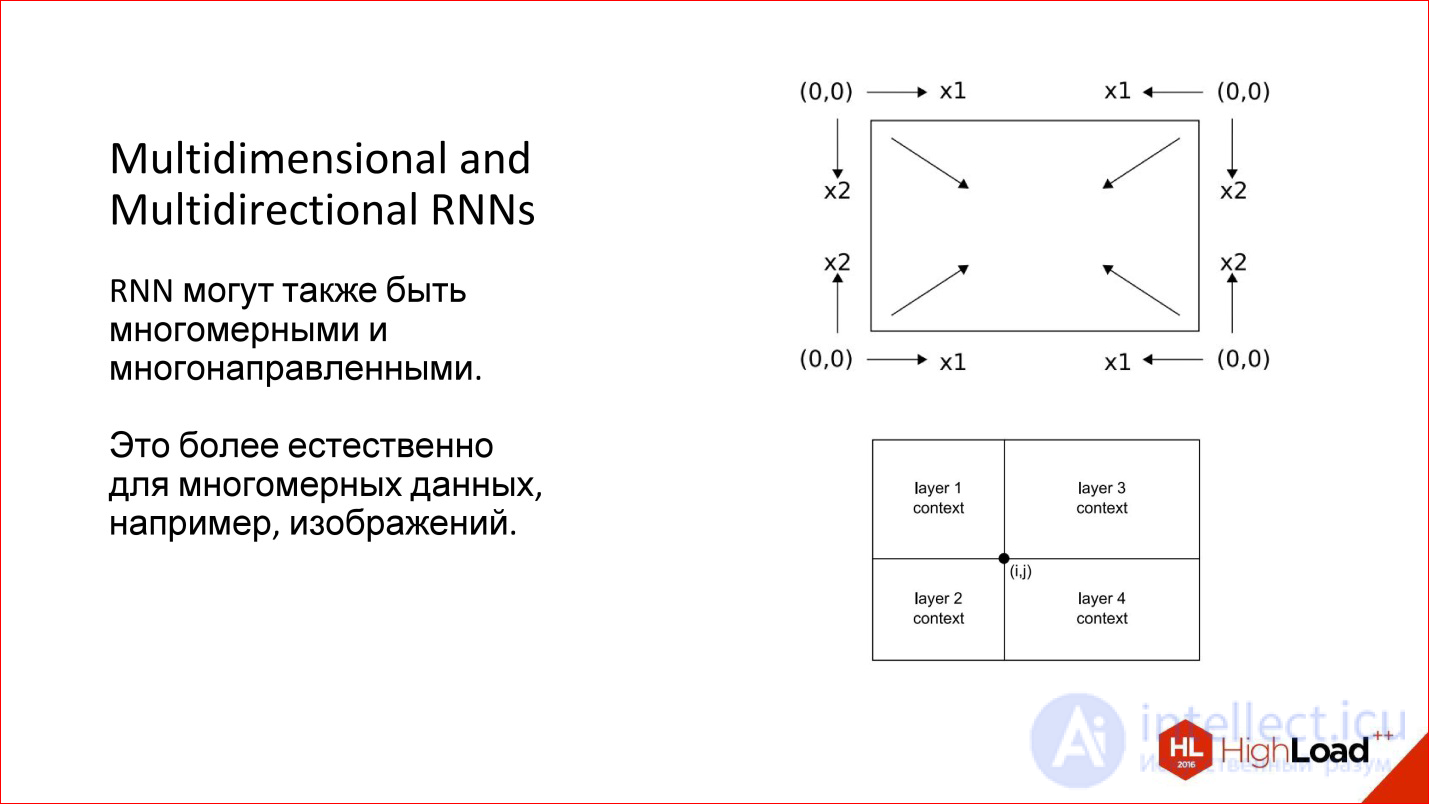
Более того, мы рассматривали одномерные случаи — например, предложения. Но есть же многомерные последовательности — то же изображение тоже можно рассмотреть как последовательность. Тогда у него вообще есть 4 направления, которые разумны по-своему. Для произвольной точки изображения есть, по сути, 4 контекста при таком обходе.
Есть интересные многомерные рекуррентные нейросети: они и многомерные, и многонаправленные. Сейчас они немножко подзабыты. Это, кстати, старая разработка, которой уже лет 10, наверное, но сейчас она начинает всплывать.
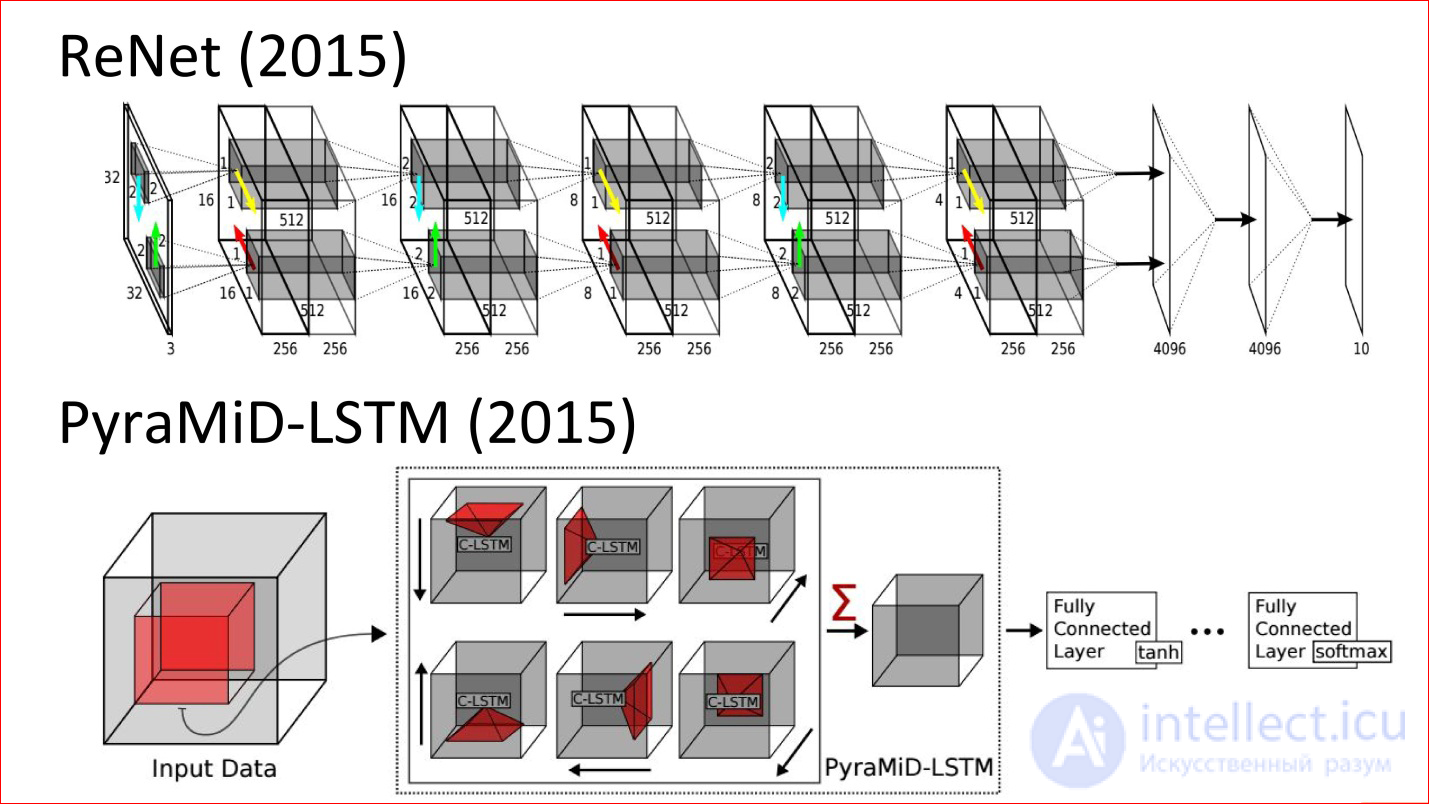
Вот свежие работы (2015 год). Это нейросеть — аналог классической нейросети LeNet, которая классифицировала рукописные цифры. Но теперь она ни разу не сверточная, а рекуррентная и многонаправленная. Там стрелочки есть, которые по разным направлениям проходят по изображению.
Второй пример — хитрая нейросеть, которая использовалась для сегментации мозговых срезов. Она тоже ни разу не сверточная, а рекуррентная, и она победила в каком-то очередном конкурсе.
На самом деле это крутые технологии. Думаю, что в ближайшее время рекуррентные сети очень сильно потеснят сверточные потому, что даже для изображений они добавляют очень много чего. Это потенциально более мощный класс.
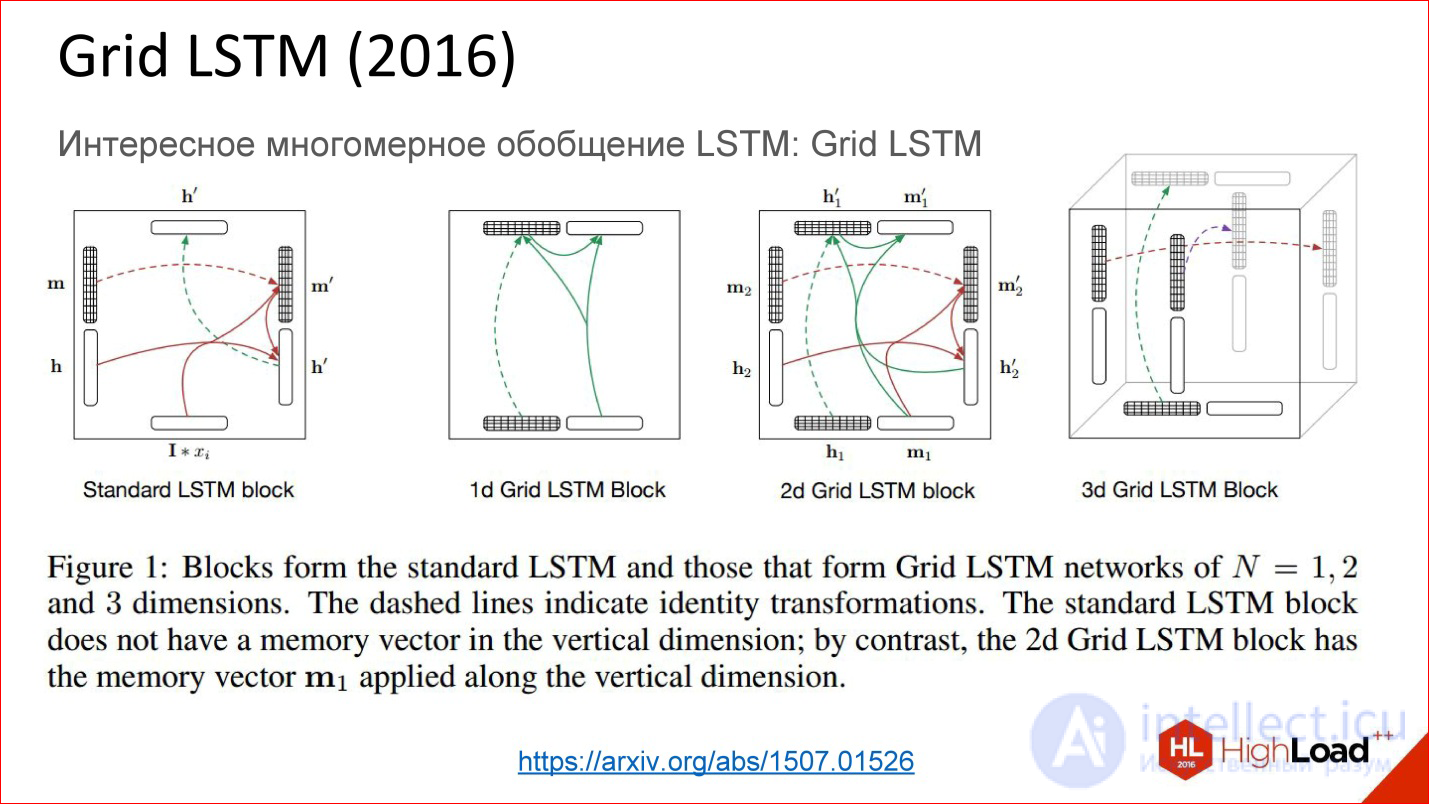
https://arxiv.org/abs/1507.01526
А еще есть совсем свежая разработка Grid LSTM, которая пока еще не очень осмыслена и осознана. На самом деле идея простая — взяли рекуррентную сеть, в какой-то момент заменили нейроны на какие-то хитрые ячейки, чтобы по времени можно было хранить состояние долго. Если наша сеть глубокая в этом направлении, то там нет никаких gate, градиенты также теряются. Что, если в этом направлении тоже что-то такое добавить? Да, добавили, оказалось круто!
Просто проблема — сейчас почти нет готовых программных библиотек, где это реализовано. Есть 1-2 кусочка кода, которые можно попытаться использовать. Надеюсь, что в ближайший год появятся общедоступные эти вещи, и будет совсем круто.
Это замечательная вещь, смотрите, что с ней будет, она хорошая.
Теперь начинаются продвинутые темы.
Мультимодальное обучение (Multimodal Learning)
Смешивание различных модальностей в одной нейросети, например, изображение и текст
Мультимодальное обучение — это идейно тоже простая штука, когда мы берем и в нейросети смешиваем 2 модальности, например, картинки и текст. До этого мы рассматривали случаи работы на 1 модальности — только на картинках, только на звуке, только на тексте. Но можно и смешать!

http://arxiv.org/abs/1411.4555
Например, есть классный кейс — генерация описания картинок. Вы подаете в нейросеть картинку, она на выходе генерит текст, допустим, на нормальном английском языке, который описывает, что происходит на этой картинке. Эта технология еще несколько лет назад казалась вообще не возможной потому, что непонятно было, как это сделать. Но сейчас это реализовано.
Кстати, мы выложили в открытый доступ видеозаписи последних пяти лет конференции разработчиков высоконагруженных систем HighLoad++. Смотрите, изучайте, делитесь и подписывайтесь на канал YouTube.
Внутри все устроено просто. Есть сверточная нейросеть, которая обрабатывает изображение, выделяет из него какие-то признаки и записывает его в каком-то хитром векторе состояния. Есть рекуррентная сеть, которая научена из этого состояния генерить и разворачивать текст.
Это совмещение 2-х модальностей очень продуктивно. Таких примеров много.
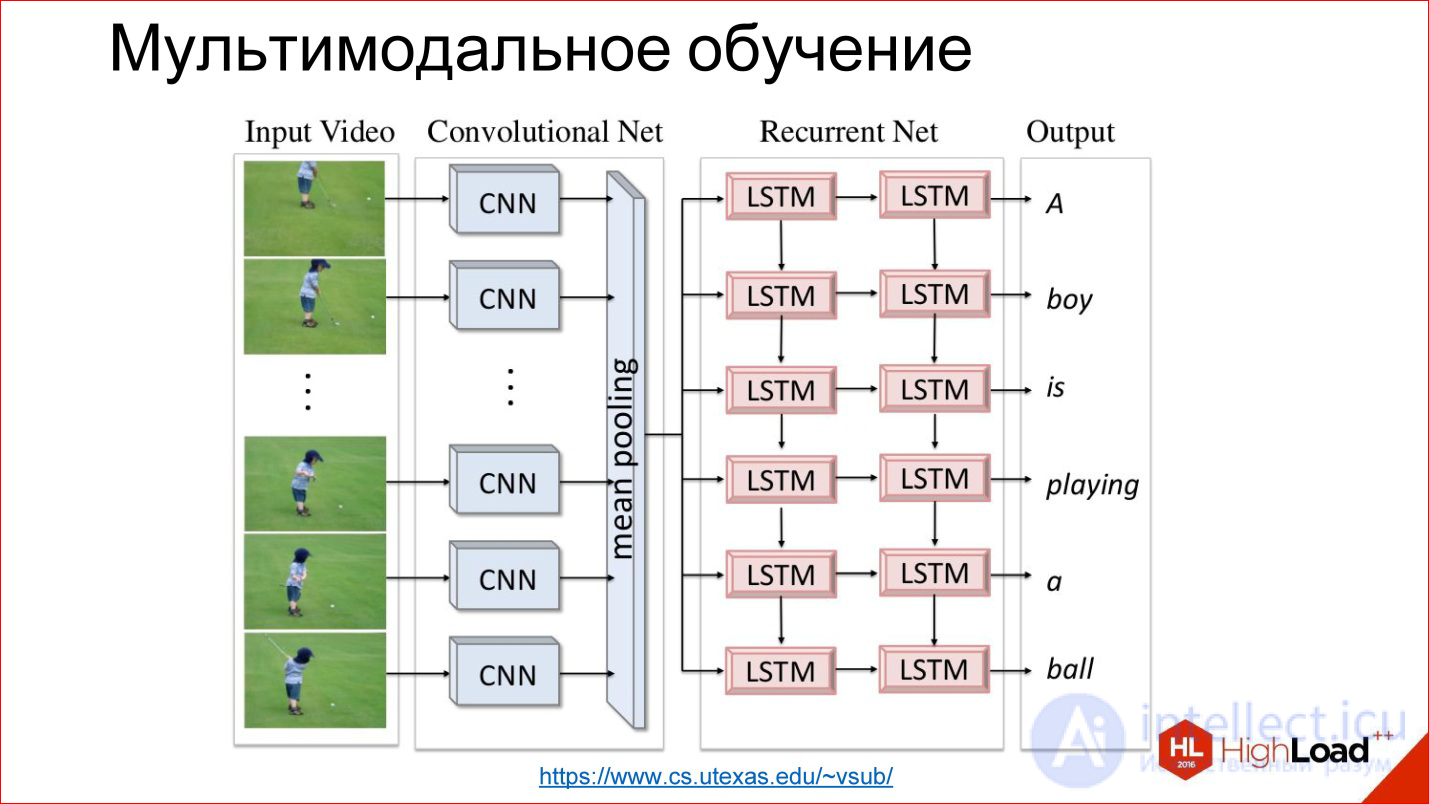
https://www.cs.utexas.edu/~vsub/
Есть, например, интересная задача аннотирования видео. По сути, к предыдущей задаче просто добавляется еще одно измерение — время.
Например:
Есть футболист, который бегает по полю;
Это интересно!
Чуть более детально, как мультмодальное обучение выглядит внутри.
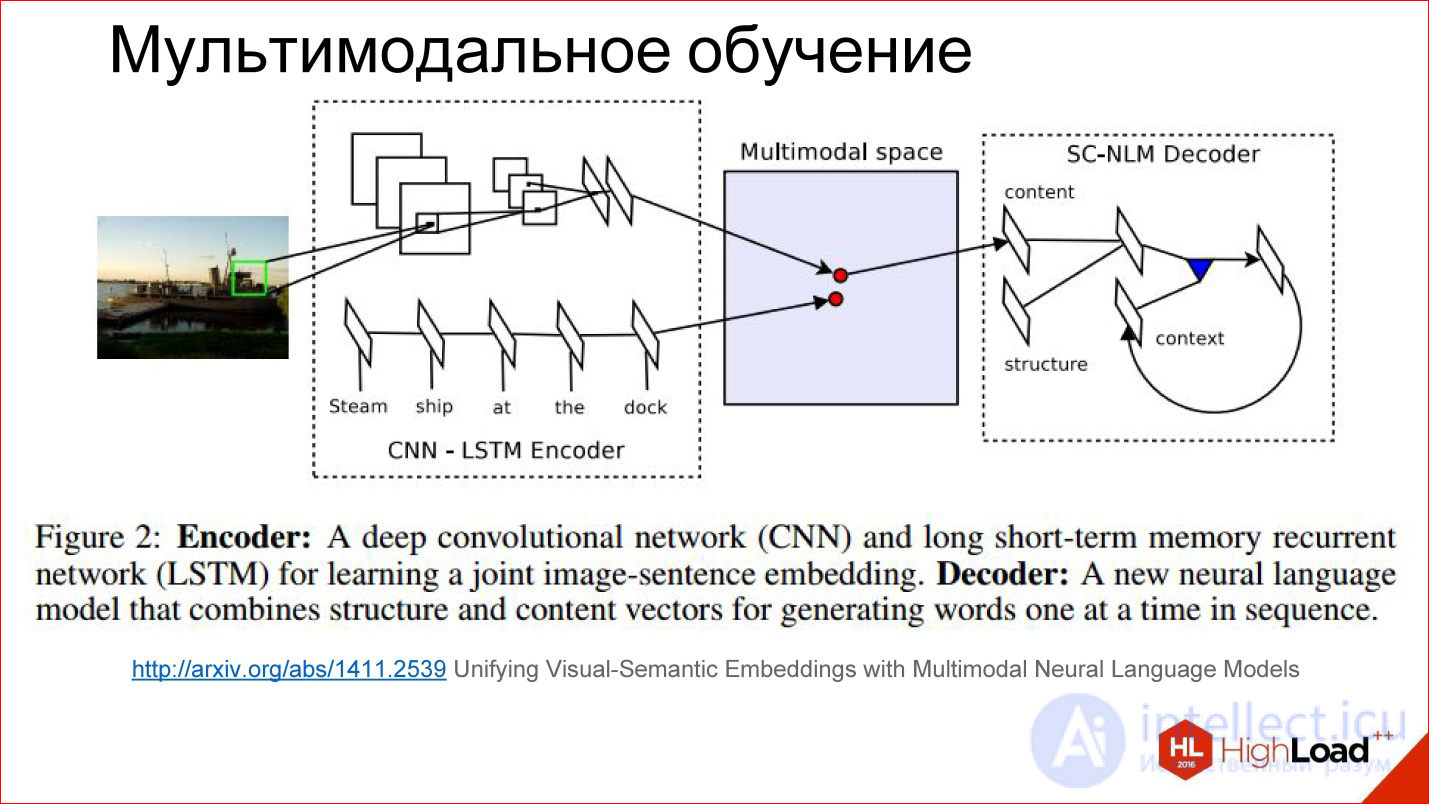
http://arxiv.org/abs/1411.2539
Есть какое-то хитрое пространство, которое мы никак не видим, но оно внутри нейросети существует в виде этих весов, которые она для себя считает. Получается так, что в процессе обучения мы учим как бы 2 разные нейросети: сверточную и рекуррентную для текста, который описывает картинку и для самой картинки генерировать вектора в этом хитром пространстве в одном месте. То
продолжение следует...
Часть 1 Введение в архитектуры нейронных сетей. Классификация и виды нейросетей, принцип работы
Часть 2 Архитектуры нейросетей: Сверточные нейросети - Введение в архитектуры нейронных сетей.
Часть 3 Sequence Learning и парадигма seq2seq - Введение в архитектуры нейронных
Анализ данных, представленных в статье про архитектура нейронных сетей, подтверждает эффективность применения современных технологий для обеспечения инновационного развития и улучшения качества жизни в различных сферах. Надеюсь, что теперь ты понял что такое архитектура нейронных сетей, классификация нейросетей, виды нейросетей, неросеть, свертка, сверхточные нейросети, рекуррентные нейросети, cnn, rnn и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Computational Neuroscience (вычислительная нейронаука) Теория и приложения искусственных нейронных сетей
Комментарии
Оставить комментарий
Computational Neuroscience (вычислительная нейронаука) Теория и приложения искусственных нейронных сетей
Термины: Computational Neuroscience (вычислительная нейронаука) Теория и приложения искусственных нейронных сетей