Лекция
Привет, Вы узнаете о том , что такое автоматическая раскраска, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое автоматическая раскраска , настоятельно рекомендую прочитать все из категории Computational Neuroscience (вычислительная нейронаука) Теория и приложения искусственных нейронных сетей.
Вы видели подпункт https://www.reddit.com/r/Colorization/ Reddit ? Люди используют фотошоп, чтобы добавить цвета к старым черно-белым фотографиям. Это хорошая проблема для автоматизации, потому что идеальные данные для обучения легко получить: любое цветное изображение может быть ненасыщенным и использоваться в качестве примера.
Этот проект представляет собой попытку использовать современные методы глубокого обучения для автоматического раскрашивания черно-белых фотографий.
За последние несколько лет сверточные нейронные сети (CNN) произвели революцию в области компьютерного зрения. Каждый год в конкурсе ImageNet Challenge (ILSVRC) количество ошибок резко падает из-за повсеместного принятия моделей CNN среди участников. С этого года ошибка классификации в ILSVRC считается лучше, чем у людей. Удивительные визуализации показали, что предварительно обученные модели классификации можно переоборудовать для других целей.
http://googleresearch.blogspot.com/2015/06/inceptionism-going-deeper-into-neural.html
http://arxiv.org/abs/1508.06576
Вот некоторые из моих лучших раскрасок примерно после трех дней тренировок. Входными данными для модели является изображение в градациях серого слева. На выходе получается среднее изображение. Правильное изображение - это истинный цвет, который модель никогда не видит. (Это изображения из набора для проверки.)








Есть и плохие чехлы, которые в основном выглядят черно-белыми или окрашенными в сепию .
Вот несколько случайных изображений для проверки, если вы хотите получить лучшее представление о его компетенции. Файлы изображений названы в честь итерации обучения, в которой они находятся. Таким образом, номер с более высоким номером будет иметь лучший цвет.
С этого момента я предполагаю, что вы немного знакомы с тем, как работают CNN. Для отличного введения ознакомьтесь с CS231n Karpathy . http://cs231n.github.io/convolutional-networks/
В моделях классификации CNN (например, для ILSVRC) можно извлечь больше информации, чем только окончательная классификация. Цайлер и Фергус показали, как визуализировать, какие промежуточные слои CNN могут представлять - и оказалось, что такие объекты, как автомобильные колеса и люди, уже начинают распознаваться на третьем уровне. Промежуточные слои в моделях классификации могут предоставлять полезную информацию о цвете.
Первым делом нужно было выбрать предварительно обученную модель для использования.
Поэтому я хотел использовать предварительно обученную модель классификации изображений (из зоопарка моделей Caffe ) для извлечения функций для раскрашивания. Я выбрал модель VGG-16, потому что она имеет простую архитектуру, но при этом конкурентоспособна (второе место в ILSVRC 2014 года). В этой статье представлена идея «гиперколонок» в CNN http://arxiv.org/abs/1411.5752 . Гиперстолбец для пикселя во входном изображении - это вектор всех активаций выше этого пикселя. Я реализовал это путем пересылки изображения через сеть VGG, а затем извлечения нескольких слоев (в частности, тензоров перед каждой из первых 4 операций максимального объединения), увеличения их масштаба до исходного размера изображения и объединения их всех вместе.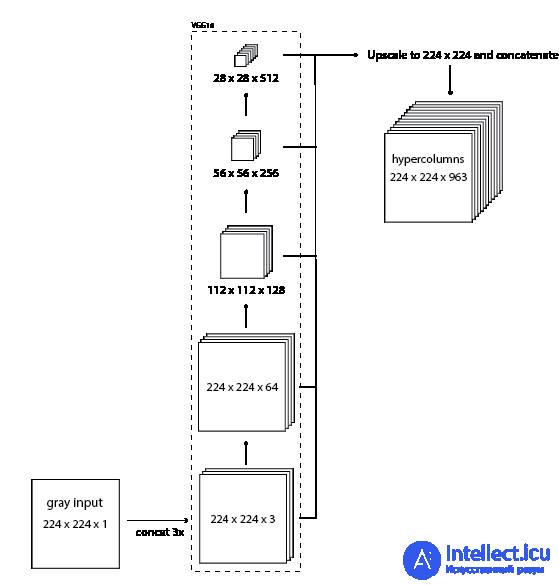
Результирующий тензор гиперстолбцов содержит массу информации о том, что находится на этом изображении. Используя эту информацию, я смогу раскрасить изображение.
Вместо того, чтобы реконструировать все цветное изображение RGB, я обучил модели создавать два цветовых канала, которые я объединяю с входным каналом шкалы серого для создания изображения YUV . Об этом говорит сайт https://intellect.icu . Канал Y - это интенсивность. Это гарантирует, что интенсивность вывода всегда будет такой же, как и на входе. (В этой дополнительной сложности нет необходимости, модель может научиться полностью реконструировать изображение, но изучение только двух каналов помогает отладке.)
Изначально я использовал цветовое пространство Hue-Saturation-Value (HSV). (Поскольку это было единственное цветовое пространство с каналом оттенков серого, о котором я знал.) Проблема с HSV заключается в том, что канал оттенка обтекает. (0, x, y) сопоставляется с тем же пикселем RGB, что и (1, x, y). Это делает функцию потерь более сложной, чем евклидово расстояние. Я также не уверен, что это круглое свойство оттенка может испортить градиент - я решил избежать этого. Также формула преобразования YUV в и из RGB - это просто умножение матриц, HSV более сложный.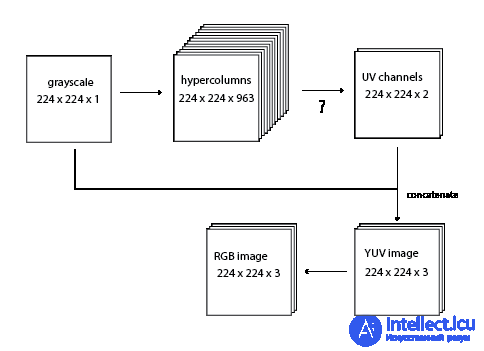
Что использовать для операции со знаком вопроса? Самый простой способ - использовать свертку 1x1 с 963 каналов до 2 каналов. То есть умножьте каждый гиперстолбец на матрицу (963, 2), добавьте двумерный вектор смещения и пропустите через сигмоид. К сожалению, эта модель недостаточно сложна для представления цветов в ImageNet. Он сведется к ненасыщенным изображениям.
Я пробовал различные скрытые слои и более крупные свертки, но прежде чем я перейду к этому, я хочу поговорить о потере и некоторых других вариантах.
Наиболее очевидная функция потерь - это функция евклидова расстояния между выходным сетевым RGB-изображением и истинным цветным RGB-изображением. В некоторой степени это работает, но я обнаружил, что модели сходятся быстрее, когда я использовал более сложную функцию потерь.
Размытие сетевого вывода и изображения в истинных цветах, а также выполнение евклидова расстояния, кажется, дает градиенту достойную помощь. (Я закончил тем, что усреднил нормальное расстояние rgb и два расстояния размытия с гауссовыми ядрами 3 и 5 пикселей.
Также я рассчитываю расстояние только в УФ-пространстве. Вот точный код .

Я использую ReLU в качестве функций активации повсюду, за исключением последнего вывода в UV-каналы - там я использую сигмоид, чтобы сжать значения от 0 до 1. Я использую пакетную норму (BN) вместо членов смещения после каждой свертки. Я экспериментировал с использованием ELU вместо и в дополнение к BN, но без особого успеха. Я не добился больших успехов с дырявыми ReLU. Я экспериментировал с использованием отсева в разных местах, но, похоже, это не сильно помогло. Скорость обучения 0,1 использовалась со стандартным SGD. Без потери веса.
Модели были обучены на наборе данных обучения классификации ILSVRC 2012 . Тот же обучающий набор, что и для предварительно обученного VGG16. Это 147 ГБ и более 1,2 миллиона изображений!
Я экспериментировал с множеством различных архитектур для преобразования гиперколонок в UV-каналы. Я буду сравнивать здесь два скрытых слоя с глубиной 128 и 64, 3x3 шага 1 между ними.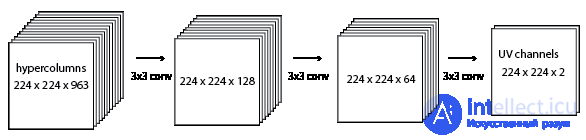
Эта модель может быть достаточно сложной, чтобы изучать цвета в ImageNet. Но я никогда не тратил достаточно времени, чтобы полностью его тренировать, потому что нашел лучшую настройку. Думаю, проблема с этой моделью будет сразу очевидна для любого, кто раньше работал с CNN. Это было не для меня.
В отличие от моделей классификации, здесь нет максимального объединения. Мне нужен вывод с полным разрешением 224 x 224. Гиперстолбцы и последующий слой глубины 128 занимают много памяти! Я смог запустить только такую модель, как эта, 1 изображение на партию на моем 2-гигабайтном NVIDIA GTX 750ti.
Я придумал новую модель, которую я называю «остаточным кодировщиком» - потому что это почти автоматический кодировщик, но от черно-белого к цветному, с остаточными связями. Модель передает изображение в градациях серого через VGG16, а затем, используя самый высокий слой, выводит некоторую информацию о цвете. Затем он увеличивает масштаб угадывания цвета и добавляет информацию со следующего самого высокого уровня, и так далее, работая до нижней части VGG16, пока не будет тензор 224 x 224 x 3. Меня вдохновила победа в классификации Microsoft Research на ILSVRC 2015, в которой они добавляют остаточные соединения, пропускающие каждые два слоя. Я использовал остаточные связи, чтобы добавить информацию по мере ее продвижения вниз по VGG16.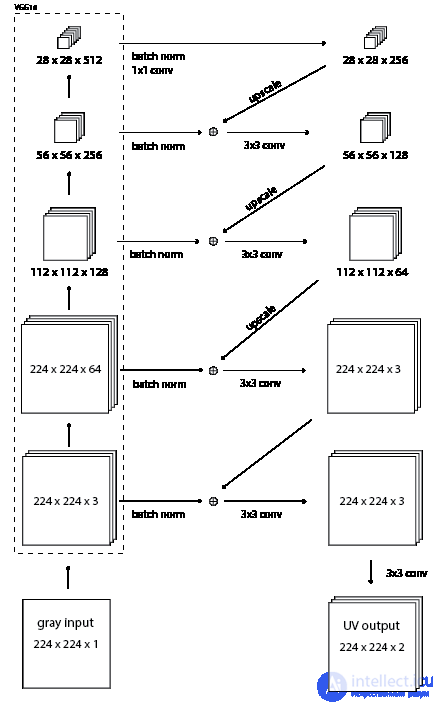
Эта модель использует гораздо меньше памяти. Мне удалось запустить его с 6 изображениями за пакет. Вот сравнение обучения этой новой модели кодировщика остатков и исходной модели гиперстолбца.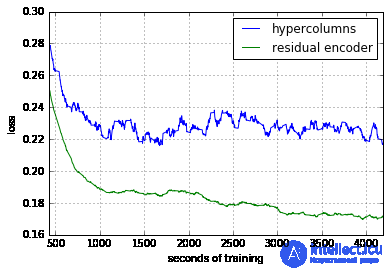
Давайте сравним несколько ручных раскрасок из подпрограммы раскраски Reddit с автоматически раскрашенными изображениями из модели. Конечно, можно ожидать, что ручная раскраска всегда будет лучше. Вопрос в том, насколько плохое авто раскрашивание.
Слева
оригинал черно-белый
Среднее
автоматическое раскрашивание с использованием модели остаточного кодировщика (после 156000 итераций, 6 изображений в пакете)
Правильная
ручная раскраска от Reddit
Модель здесь плохо справилась. В небе есть легкие оттенки синего, но в остальном мы получаем только оттенок сепии. Дальнейшая тренировка, вероятно, раскрасит остальное небо, но, вероятно, никогда не придаст особого оттенка зданию или вагону поезда 
Достойная раскраска! Он получил правильный оттенок кожи, не раскрасил его белую одежду и добавил немного зеленого к фону. Это не добавило правильного тона его рукам и не имело богатой насыщенности, которая делает раскрашенную вручную версию популярной. 
Небо только слегка голубое, и его грудь не окрашивается. Также он покрасил свою рубашку в зеленый цвет, возможно, потому, что шерсть имеет растительную текстуру и находится в нижней части изображения. В остальном неплохо. 
Это Анна Франк в 1939 году. Модель не может раскрашивать подушки, потому что подушки могут быть любого цвета. Даже если тренировочный набор полон подушек (что я не думаю), все они будут разных цветов, и модель, вероятно, в конечном итоге усреднит их до оттенка сепии. Человек может выбрать случайный цвет, и даже если он ошибается, это будет выглядеть лучше, чем отсутствие цвета. 
Еще одна плохая окраска. О цвете машины теряется информация. Человек, раскрасивший эту фотографию, просто предположил, что она красная, но с таким же успехом она могла быть зеленой или синей. Модель кажется средним по цвету автомобилей, которые она видела, и вот результат. ( сообщение на Reddit )


Любит окрашивать черных животных в коричневый цвет?
Любит окрашивать траву в зеленый цвет.
Вот обученная модель TensorFlow, с которой можно поиграть:
colorize-20160110.tgz.torrent 492M https://tinyclouds.org/colorize/colorize-20160110.tgz.torrent
Эта модель содержит модель VGG16 от Карена Симоняна и Эндрю Зиссермана (которую я преобразовал в TensorFlow ). Он доступен только для некоммерческого использования.
Это вроде как работает, но есть еще много чего улучшить:
сверточные нейронные сети (CNN)
Исследование, описанное в статье про автоматическая раскраска, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое автоматическая раскраска и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Computational Neuroscience (вычислительная нейронаука) Теория и приложения искусственных нейронных сетей

Комментарии