Лекция
Привет, сегодня поговорим про сведения из высшей ма тики , обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое сведения из высшей ма тики , настоятельно рекомендую прочитать все из категории Computational Neuroscience (вычислительная нейронаука) Теория и приложения искусственных нейронных сетей.
Векторное пространство. Базис. Ортогональные проекции. Гиперсферы и гиперповерхности. Матрицы. Линейные преобразования.
Традиционно используемым для описания нейронных сетей математическим языком является аппарат векторной и матричной алгебры. Для максимального упрощения изложения, ограничивая набор общематематических сведений только этим аппаратом, хотелось бы подчеркнуть, что в современной нейронауке широко используются и другие разделы математики. Среди них - дифференциальные уравнения, применяемые для анализа нейронных сетей в непрерывном времени, а также для построения детальных моделей нейрона; Фурье-анализ для описания поведения системы при кодировании в частотной области; теория оптимизации как основа для разработки алгоритмов обучения; математическая логика и булева алгебра - для описания двоичных сетей, и другие. Изложенный в этой лекции материал носит справочный характер и не претендует на полноту. Исчерпывающие сведения по теории можно найти в книге Гантмахера, а также в стандартных курсах линейной алгебры и аналитической геометрии.
Основным структурным элементом в описании способов обработки информации нейронной сетью является вектор - упорядоченный набор чисел, называемых компонентамивектора. В дальнейшем вектора будут обозначаться латинскими буквами ( a, b, c, x ), а скаляры - числа - греческими буквами ( a, b, g, q ). Для обозначения матриц будут применяться заглавные латинские буквы. В зависимости от особенностей рассматриваемой задачи компоненты вектора могут быть действительными числами, целыми числами (например, для обозначения градаций яркости изображения), а также булевыми числами "ноль-один" или "минус один - один". Компоненты вектора x = ( x1, x2, ... xn ) можно рассматривать, как его координаты в некотором n-мерном пространстве. В случае действительных компонент это пространство обозначается, как Rn и включает в себя набор всех возможных совокупностей из n действительных чисел. Говорят, что вектор x принадлежит пространству Rn (или x из Rn). В дальнейшем, если нам потребуется набор векторов, мы будем нумеровать их верхними индексами, чтобы не путать с нумерацией компонент: {x1, x2, ..., xk}.
В нашем рассмотрении мы не будем делать разницы в понятиях вектор (упорядоченная совокупность компонент) и образ (совокупность черт или признаков образа). Способы выбора совокупности признаков и формирования информационного вектора определяются конкретными приложениями.
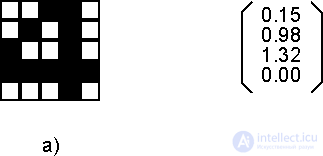
Рис. 2.1. Примеры векторов: а) булев вектор с 25 компонентами, нумеруемыми по строкам, б) действительный вектор из пространства R4.
Множество векторов с действительными компонентами является частным случаем более общего понятия, называемого линейным векторным пространством V, если для его элементов определены операции векторного сложения "+" и умножения на скаляр ".", удовлетворяющие перечисленным ниже соотношениям (здесь x,y,z - вектора из V, а a, b - скаляры из R):
Свойство 1) называют свойством коомутативности, соотношения 2) и 3) - свойством дистрибутивности, а 4) - свойством ассоциативности введенных операций. Об этом говорит сайт https://intellect.icu . Примером линейного векторного пространства является пространство Rn с покомпонентными операциями сложения и умножения.
Для двух элементов векторного пространства может быть определено их скалярное (внутреннее) произведение : (x,y) = x1y1 + x2y2 + ... + xnyn. Скалярное произведение обладает свойствами симметричности, аддитивности и линейности по каждому сомножителю:
Равенство нулю скалярного произведения двух векторов означает их взаимную ортогональность, сообразно обычным геометрическим представлениям.
Два различных образа (или вектора) могут быть в той или иной мере похожи друг на друга. Для математического описания степени сходства векторное пространство может быть снабжено скалярной метрикой - расстоянием d(x,y) между всякими двумя векторами x и y. Пространства, с заданной метрикой называют метрическими. Для метрики должны выполняться условия неотрицательности, симметричности, а также неравенство треугольника:В дальнейшем изложении будут в основном использоваться две метрики - Евклидово расстояние и метрика Хемминга. Евклидова метрика для прямоугольной системы координат определяется формулой:
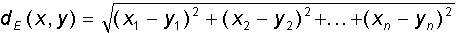
Хеммингово расстояние dH используется обычно для булевых векторов (компоненты которых равны 0 или 1), и равно числу различающихся в обоих векторах компонент.
Для векторов вводится понятие нормы ||x|| - длины вектора x. Пространство в котором определена норма векторов называется нормированным. Норма должна обладать следующими свойствами:
Пространства с Евклидовой метрикой и нормой называют Евклидовым пространством. Для образов, состоящих из действительных признаков мы будем в дальнейшем иметь дело именно с Евклидовым пространством. В случае булевых векторов размерности n рассматриваемое пространство представляет собой множество вершин n-мерного гиперкуба с Хемминговой метрикой. Расстояние между двумя вершинами определяется длиной кратчайшего соединяющего их пути, измеренной вдоль ребер.
Важным для нейросетевых приложений случаем является множество векторов, компоненты которых являются действительными числами, принадлежащими отрезку [0,1]. Множество таких векторов не является линейным векторным пространством, так как их сумма может иметь компоненты вне рассматриваемого отрезка. Однако для пары таких векторов сохраняются понятия скалярного произведения и Евклидового расстояния.
Вторым интересным примером, важным с практической точки зрения, является множество векторов одинаковой длины (равной, например, единице). Образно говоря, "кончики" этих векторов принадлежат гиперсфере единичного радиуса в n-мерном пространстве. Гиперсфера также не является линейным пространством (в частности, отсутствует нулевой элемент).
Для заданной совокупности признаков, определяющих пространство векторов, может быть сформирован такой минимальный набор векторов, в разной степени обладающих этими признаками, что на его основе, линейно комбинируя вектора из набора, можно сформировать все возможные иные вектора. Такой набор называется базисом пространства. Рассмотрим это важное понятие подробнее.
Вектора x1, x2, ..., xm считаются линейно независимыми, если их произвольная линейная комбинация a1x1 + a2x2 + ... + amxm не обращается в ноль, если только все константы a1 ...am не равны одновременно нулю. Базис может состоять из любой комбинации из n линейно независимых векторов, где n - размерность пространства.
Выберем некоторую систему линейно независимых векторов x1, x2, ..., xm, где m < n. Все возможные линейные комбинации этих векторов сформируют линейное пространство размерности m, которое будет являться подпространством или линейной оболочкой L исходного n-мерного пространства. Выбранная базовая система из m векторов является, очевидно, базисом в подпространстве L. Важным частным случаем линейной оболочки является подпространство размерности на единицу меньшей, чем размерность исходного пространства (m=n-1), называемое гиперплоскостью. В случае трехмерного пространства это обычная плоскость. Гиперплоскость делит пространство на две части. Совокупность гиперплоскостей разбивает пространство на несколько множеств, каждое из которых содержит вектора с близким набором признаков, тем самым осуществляется классификация векторов.
Для двух подпространств может быть введено понятие их взаимной ортогональности. Два подпространства L1 и L2 называются взаимно ортогональными, если всякий элемент одного подпространства ортогонален каждому элементу второго подпространства.
Произвольно выбранные линейно независимые вектора необязательно являются взаимно ортогональными. Однако в ряде приложений удобно работать с ортогональными системами. Для этого исходные вектора требуется ортогонализовать. Классический процесс ортогонализации Грама-Шмидта состоит в следующем: по системе линейно независимых ненулевых векторов x1, x2, ..., xm рекуррентно строится система ортогональных векторов h1, h2, ..., hm. В качестве первого вектора h1 выбирается исходный вектор x1. Каждый следующий (i-ый) вектор делается ортогональным всем предыдущим, для чего из него вычитются его проекции на все предыдущие вектора:
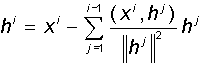
При этом, если какой-либо из получившихся векторов hi оказывается равным нулю, он отбрасывается. Можно показать, что, по построению, полученная система векторов оказывается ортогональной, т.е. каждый вектор содержит только уникальные для него признаки.
Далее будут представлены теоретические аспекты линейных преобразований на векторами.
Равно тому, как был рассмотрен вектор - объект, определяемый одним индексом (номером компоненты или признака), может быть введен и объект с двумя индексами, матрица. Эти два индекса определяют компоненты матрицы Aij, располагаемые по строкам и столбцам, причем первый индекс i определяет номер строки, а второй j - номер столбца. Интересно отметить, что изображение на рисунке 2.1.а) может трактоваться и как вектор с 25 компонентами, и как матрица с пятью строками и пятью столбцами.
Суммой двух матриц A и B одинаковой размерности (n x m) является матрица С той же размерности с компонентами, равными сумме соответствующих компонент исходных матриц: Cij = Aij + Bij. Матрицу можно умножить на скаляр, при этом в результате получается матрица той же размерности, каждая компонента которой умножена на этот скаляр. Произведением двух матриц A (n x l) и B (l x m) также является матрица C (n x m), компоненты которой даются соотношением:
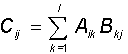
Заметим, что размерности перемножаемых матриц должны быть согласованными - число столбцов первой матрицы должно равняться числу строк второй.
В важном частном случае, когда вторая матрица является вектором (т.е. матрицей с одной из размерностей, равной единице (m=1)), представленное правило определяет способ умножения матрицы на вектор:
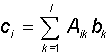
В результате умножения получается также вектор с, причем для квадратной матрицы A (l x l) его размерность равна размерности вектора-сомножителя b. При произвольном выборе квадратной матрицы A можно построить произвольное линейное преобразование y=T(x) одного вектора (x) в другой (y) той же размерности: y=Ax. Более точно, для того, чтобы преобразование T одного вектора в другой являлось линейным, необходимо и достаточно, чтобы для двух векторов x1 и x2 и чисел a и b выполнялось равенство: T(ax1 + bx2) =aT(x1) + bT(x2). Можно показать, что всякому линейному преобразованию векторов соотвествует умножение исходного вектора на некоторую матрицу.
Если в приведенной выше формуле для умножения матрицы A на вектор x компоненты этого вектора неизвестны, в то время, как A и результирующий вектор b известны, то о выражении A x = b говорят, как о системе линейных алгебраических уравнений относительно компонент вектора x. Система имеет единственное решение, если вектора, определяемые строками квадратной матрицы A, являются линейно независимыми.
Часто используемыми частными случаями матриц являются диагональные матрицы, у которых все элементы вне главной диагонали равны нулю. Диагональную матрицу, все элементы главной диагонали которой равны единице, называют единичной матрицей I. Линейное преобразование, определяемое единичной матрицей, является тождественным: Ix=x для всякого вектора x.
Для матриц определена, кроме операций умножения и сложения, также операция транспонирования. Транспонированная матрица AT получается из исходной матрицы A заменой строк на столбцы: (Aij)T = Aji. Матрицы, которые не изменяются при транспонировании, называют симметричными матрицами. Для компонент симметричной матрицы S имеет место соотношение Sij = Sji. Всякая диагональная матрица, очевидно, является симметричной.
Пространство квадратных матриц одинаковой размерности с введенными операциями сложения и поэлементного умножения на скаляр, является линейным пространством. Для него также можно ввести метрику и норму. Нулевым элементом служит матрица, все элементы которой равны нулю.
В заключении приведем некоторые тождества для операций над матрицами. Для всяких A,B и C и единичной матрицы I имеет место:
В общем, мой друг ты одолел чтение этой статьи об сведения из высшей ма тики . Работы впереди у тебя будет много. Смело пиши комментарии, развивайся и счастье окажется в твоих руках. Надеюсь, что теперь ты понял что такое сведения из высшей ма тики и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Computational Neuroscience (вычислительная нейронаука) Теория и приложения искусственных нейронных сетей
Комментарии
Оставить комментарий
Computational Neuroscience (вычислительная нейронаука) Теория и приложения искусственных нейронных сетей
Термины: Computational Neuroscience (вычислительная нейронаука) Теория и приложения искусственных нейронных сетей