Лекция
Привет, Вы узнаете о том , что такое конструирование психодиагностических тестов, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое конструирование психодиагностических тестов, традиционные ма тические модели, алгоритмы , настоятельно рекомендую прочитать все из категории Математические методы в психологии.
Публикуется по материалам монографии В. А. Дюка
«Компьютерная психодиагностика», (С-Пб., 1994)
Введение
Важное значение в развитии экспериментальных психодиагностических методик имеют технические средства стимуляции, регистрации и обработки психодиагностической информации. Эти технические средства нашли свое наиболее полное воплощение в современных высокопроизводительных компьютерах с их мощными операциональными и изобразительными возможностями.
Использование в психодиагностике возможностей современных компьютеров компактно хранить, быстро извлекать, оперативно и всесторонне анализировать и наглядно отображать экспериментальную информацию влечет за собой эффекты, которые условно можно назвать количественными и качественными.
Первый тип количественных эффектов связан главным образом с автоматизацией рутинных операций традиционного психодиагностического эксперимента, таких как инструктаж испытуемого, предъявление стимулов и регистрация ответов испытуемого, ведение протокола, расчет и выдача результатов и т. п. За счет такой автоматизации повышаются уровень стандартизации, точность и скорость получения выходных диагностических данных, что бывает крайне необходимо в таких областях, как клиническое обследование или психологическое консультирование. Кроме того, оперативность обработки информации при компьютерном эксперименте позволяет проводить в сжатые сроки массовые психодиагностические обследования, которые, в частности, используются для решения задач профессионального психологического отбора или профессиональной ориентации в условиях дефицита временных и других ресурсов.
Качественные эффекты можно разделить на две категории. Первую категорию составляют эффекты, обеспечиваемые возможностями современных компьютеров реализовывать новые виды психодиагностических экспериментов. Сюда относятся возможности генерировать новые виды стимулов (динамические и полимодальные), по-новому организовывать стимульную последовательность (например, так называемое адаптивное тестирование), регистрировать ранее не доступные параметры реакций испытуемых, оформлять психодиагностические методики в виде компьютерных игр и т. п. Вторая категория качественных эффектов сопряжена с применением в психодиагностике последних достижений в области информационных технологий. Эти достижения касаются способов создания и ведения компьютерных баз данных, алгоритмов распознавания образов в психодиагностике и методов искусственного интеллекта, основанных на манипулировании знаниями в рассматриваемой предметной области.
Рассмотрим внешнюю сторону типичной процедуры «ручной» обработки данных психодиагностического тестирования.
Испытуемый возвращает психологу бланк обследования, на котором отмечены выбранные им варианты ответов на вопросы (задания) психодиагностического теста. Психолог подсчитывает количество «попаданий» ответов испытуемого в соответствии c диагностическим «ключом». Затем психолог с помощью таблиц или номограмм переводит подсчитанное количество в новое число — стандартизированную оценку. Эта оценка или несколько оценок, определенных подобным образом, являются результатом психодиагностического тестирования, который позволяет психологу выносить суждение об особенностях испытуемого, делать определенный прогноз на будущее и давать те или иные рекомендации.
Описанная процедура преобразования ответов испытуемого в диагностический показатель лежит в основе большинства психодиагностических тестов. Известны более сложные способы компоновки первичной диагностической информации. Но уже за этой внешне простой измерительной процедурой стоит кропотливая работа создателя психодиагностического теста, связанная с получением и трудоемким анализом экспериментально-психологических данных. Некоторые виды такого анализа можно проводить вручную или с помощью микрокалькулятора. Однако по-настоящему глубокий эмпирико-статистический анализ, обеспечивающий обоснованные, точные и надежные диагностические результаты, немыслим без применения современных компьютерных методов.
В работе исследователя по конструированию психодиагностического теста можно выделить три основных этапа.
На первом этапе экспериментатор, исходя, главным образом, из теоретических представлений о диагностируемом конструкте, формирует «черновой» вариант теста. В этот вариант включаются задания, ответы на которые, по мнению экспериментатора, должны отражать индивидуально-психологические различия испытуемых по данному конструкту. Определение «чернового» варианта психодиагностического теста (исходного множества диагностических признаков) является трудно формализуемой задачей. Поэтому в рамках настоящей главы будут даны только самые общие рекомендации по формированию исходного множества диагностических признаков.
На втором этапе исследователь выбирает диагностическую модель и определяет ее параметры. Под диагностической моделью понимается способ компоновки (преобразования, агрегирования) исходных диагностических признаков (вариантов ответов на задания теста) в диагностический показатель. Таких способов может быть бесконечное множество. В данной главе будет в основном рассмотрена традиционная для психодиагностики линейная диагностическая модель, в которой компоновка исходных признаков осуществляется путем суммирования их с определенными весами.
Первичным материалом для нахождения параметров диагностической модели являются данные экспериментального обследования «черновым» вариантом психодиагностического теста репрезентативной выборки испытуемых. Результаты обследования сводятся в таблицу экспериментальных данных типа объект — признак. Основными категориями, характеризующими структуру экспериментальных. данных и использующимися для определения различными методами параметров диагностической модели, служат категории сходства и различия строк и столбцов (объектов и признаков) таблицы экспериментальных данных. Так как экспериментально-психологическая информация имеет специфический характер, в настоящей главе часть внимания уделена описанию этой специфики и особенностям применения разнообразных мер сходства и различия объектов и признаков.
Для определения параметров диагностической модели используются две стратегии эмпирико-статистического анализа данных.
Первая стратегия основывается на критерии автоинформативности экспериментальных данных, который подразумевает, что диагностическую модель можно непосредственно определить путем аппроксимации геометрической структуры множества объектов в пространстве исходных признаков, не прибегая к сведениям об эмпирических (внешних) отношениях исследуемых объектов, а опираясь только на числовые отношения сходства и различия объектов и признаков. Хорошую линейную диагностическую модель (линейную аппроксимацию) удается построить, когда значительная часть исходных признаков отличается высокой взаимосвязанностью (внутренней согласованностью) и остальные признаки не могут конкурировать с этим согласованным влиянием на структуру данных. Если внутренняя согласованность обусловлена отражением требуемого психологического конструкта, то параметры линейной диагностической модели (веса признаков) дает метод главных компонент. Если в множество исходных признаков входят несколько групп взаимосвязанных признаков, то одну или сразу несколько диагностических моделей можно получить, используя методы факторного анализа. И, наконец, полезные практические результаты дает метод контрастных групп, в котором используется эффект повышения внутренней согласованности «черновой» версии линейной диагностической модели. Все указанные методы с той или иной степенью подробности рассмотрены в настоящей главе.
Вторая стратегия определения параметров диагностической модели основана на привлечении и активном использовании дополнительной обучающей информации о диагностируемом свойстве исследуемых объектов. Критерии, по которым формируется обучающая информация, называются критериями внешней информативности или внешними критериями. Главными представителями методов, опирающихся на внешние критерии, являются методы регрессионного и дискриминантного анализа. В данной главе описываются типы и способы получения обучающей информации, а также приводятся необходимые сведения о классическом линейном регрессионном и дискриминантном анализе. Эти сведения расширены рассмотрением различных модификаций указанных видов анализа, применяющихся в психодиагностике с учетом специфики экспериментально-психологических измерений. Кроме того, отдельный подраздел посвящен построению кусочно-линейных диагностических моделей, которые реализуются в так называемом типологическом подходе.
На третьем этапе разработчик теста проводит стандартизацию и испытания построенной диагностической модели. В последней части главы описаны способы получения стандартизированных диагностических оценок и рассмотрены основные характеристики психодиагностических тестов, подвергающиеся испытанию и отражающие качество разработанного инструмента психодиагностики.
При формировании исходного множества признаков («чернового» варианта психодиагностического теста) исследователь располагает большой свободой. Если по своей внешней форме эксперимент укладывается в определенную классификационную схему и сравнительно нетрудно отдать предпочтение тому или иному классу психодиагностических методик, то выбор конкретного вида стимульных воздействий на испытуемого и алфавита регистрируемых ответов практически ничем не ограничен. В то же время, изучая какой-либо аспект многомерного взаимодействия человека с окружающим миром, нельзя заранее точно предугадать, что выбранное множество стимулов и регистрируемых ответов будет в достаточно полной мере отражать все многообразие проявлений тестируемого свойства и обеспечит инвариантность теста по отношению к широкому кругу посторонних факторов. Поэтому формирование исходного множества диагностических признаков является трудно формализуемой задачей и для ее решения можно предложить лишь самые общие рекомендации.
Первым очевидным шагом является самый тщательный анализ предмета тестирования, теоретического конструкта, положенного в основу тестируемого свойства, и его взаимоотношений с другими психологическими конструктами. Конечным шагом такого анализа должно быть четкое вербальное определение исследуемого понятия и расчленение его на основные части /Мельников В. М. и др., 1985/.
Следующим шагом при конструировании нового теста является разработка тестовых заданий. Для этого прежде всего устанавливается иерархия ранее выделенных частей психологического феномена. Затем непосредственно формулируются тестовые задания и проводится качественный анализ степени соответствия пропорций представленности элементов измеряемого свойства в этих заданиях. Такой анализ, как правило, производится с привлечением экспертов, которые выносят суждения о том, охватывает ли совокупность предлагаемых тестовых заданий декларируемое психологическое свойство и его составные части.
В целом разрабатываемая система исходных признаков должна удовлетворять следующим требованиям /Мельников В. М. и др., 1985/.
1) Полнота описания. Система исходных признаков должна охватывать все выделенные аспекты измеряемого понятия.
2) Экономность описания. При разработке системы признаков следует избегать излишнего объема исходной информации, который может затруднить дальнейший эмпирико-статистический анализ параметров диагностической модели.
3) Четкая структурированность системы признаков. Признаки должны группироваться, относительно равномерно описывая все стороны измеряемого явления.
4) Количественная определенность отбираемых признаков. Эта определенность требуется для проведения эмпирико-статистического анализа. Признаки должны быть выражены в номинальной, качественной или количественной шкале.
Приведенные требования не являются исчерпывающими. При составлении, например, тестов-опросников большое внимание должно уделяться приемам снижения возможности фальсификации ответов и уменьшения систематической ошибки тестирования. Сюда относится, в частности, введение в методику специальных признаков для выявления тенденции испытуемого давать о себе социально одобряемую информацию и для коррекции возможных искажений результатов, вносимых фактором «социальной желательности». Также к методическим приемам уменьшения систематической ошибки относится соблюдение в тест-опросниках баланса между прямыми и обратными вопросами и т. д.
В целом можно сказать, что формирование исходного множества признаков при конструировании нового психодиагностического теста является трудоемким и тонким занятием, требующим от специалиста-психодиагноста разносторонних и глубоких профессиональных знаний, а также зрелого опыта и развитой интуиции.
На практике чаще встречается другой подход к решению задачи формирования исходных признаков, в котором такими признаками выступают элементы известных тестов. Возможно заимствование отдельных элементов у ранее апробированных тестов, составление нового теста из частей известных методик и использование в качестве исходного множества признаков полного набора тестовых заданий многомерных психодиагностических методик. Примером составления нового теста из частей известных методик может служить разработанный В. М. Мельниковым и Л. Т. Ямпольским психодиагностический тест /1985/, в котором стимульный материал представляет собой комбинацию утверждений и вопросов из популярных тестов для многомерного исследования личности MMPI и 16PF Р. Кэттелла. Иллюстрацией использования полного набора тестовых заданий в качестве исходного материала для конструирования нового диагностического правила является разработанный в Психоневрологическом институте имени В. М. Бехтерева опросник для определения уровня невротизации и психопатизации, в который вошли 90 утверждений из оригинального теста MMPI /Методика определения..., 1980/.
Преимущества первого подхода, где конструируется полностью новый тест, заключается в том, что в нем максимально учитывается специфика конкретной психодиагностической задачи, находящая свое выражение в более целенаправленном подборе тестовых стимулов, формулировке отдельных вопросов и заданий, использовании терминологии, характерной для изучаемой прикладной области и т. п. В то же время, как указывалось выше, реализация этого подхода сопряжена со значительными усилиями в теоретической проработке как общей концепции теста, так и множества частных деталей. Второй подход не обладает гибкостью первого подхода, но позволяет избежать необходимости решения многих частных проблем, так как опирается на уже апробированную исходную структуру известных тестов. Основанием для его широкого использования служит скрытый потенциал многомерных психодиагностических тестов, отражающих широкий диапазон индивидуально-психологических различий, который может быть развернут относительно нового психологического концепта.
Определив исходное множество признаков, исследователь получает «черновой» вариант будущего психодиагностического теста. Дальнейшая отработка этого варианта основывается на эмпирико-статистическом анализе, методы которого рассматриваются ниже.
Структура экспериментально-психологических данных и свойства линейных диагностических моделей
Без применения эмпирико-статистического анализа не обходится ни одна серьезная попытка конструирования или адаптации тестов /Шмелев А. Г., Похилько В. И., 1985/. Исходным материалом для такого анализа служат результаты экспериментального обследования репрезентативной выборки испытуемых с помощью «чернового» варианта психодиагностического теста. Из полученных данных формируется двумерная таблица экспериментальных данных (ТЭД).
В приведенной таблице приняты следующие обозначения:
N — общее количество объектов (испытуемых);
p — общее количество признаков;
xj — «j»-й признак (в дальнейшем наряду с термином «признак» будут употребляться также термины «показатель» и «переменная»);
Таблица 1. Таблица экспериментальных данных
| Объекты (испытуемые) | Исходные признаки |
| x1 x2 ... xj ... xp | |
|
х1 |
x11 x12 ... x1j ... x1p x21 x22 ... x2j ... x2p . . . xi1 xi2 ... xij ... xip . . . xN1 xN2 ... xNj ... xNp |
Xij — значение «j»го признака, измеренное у «i»-го объекта.
В соответствии с данной символикой приняты также обозначения:
x=(x1,...,xр)' — вектор признаков (знак «( )'» означает транспонирование);
хi=(xi1, ..., xip)'—«i»-й объект;
X={xi} — множество объектов.
Особенностью психодиагностических экспериментальных данных является то, что исходные признаки xi, как правило, измерены в номинальных и порядковых (ординальных) шкалах /Суппес П. и др., 1967; Пфанцагль И., 1976; Айвазян С. А. и др., 1983/. Для большинства тестов с закрытыми ответами типа «Выбор», «Восстановление частей» и «Переструктурирование» между возможными вариантами ответов испытуемых нельзя априорно установить ни количественных отношений, ни отношений порядка. Это — номинальные измерения.
В теории измерений номинальные шкалы считаются простейшими и самыми «бедными» (их называют также шкалами наименований и классификационными шкалами). Если обозначить числами возможные варианты ответов испытуемого на тестовые задания, то эти числа будут иметь смысл только абстрактных символов, обозначающих каждый вариант ответов и никакие другие отношения между указанными числами, кроме их равенства, значения не имеют. При сравнении двух испытуемых по признаку, измеренному в номинальной шкале, можно сделать единственный вывод о совпадении или несовпадении значения признака. Поэтому при анализе таких признаков каждую отметку номинальной шкалы считают отдельным самостоятельным признаком. Он принимает всего два значения А и В и разность (А — В) уже может интерпретироваться как степень важности несовпадения данного признака при сравнении двух объектов. Чаще всего применяют значения А=0 и В=1, то есть признак равен либо 0, либо 1, а степень важности признака xi задается весом wi, на который умножается xi. Такие признаки называют двоичными, бинарными, булевыми, а в психодиагностике часто используют термин «дихотомические признаки». Процедура преобразования исходных показателей в набор признаков с двумя градациями носит название дихотомизации /Миркин Б. Г., 1980/. После проведения дихотомизации номинальные измерения становятся доступны для применения широкого спектра различных методов многомерного количественного анализа с учетом специфики данного вида измерений.
К ординальным переменным относятся, например, признаки, даваемые психодиагностическими методиками с закрытыми ответами на тестовые задания типа «Оценивание». Также иногда в качестве исходных признаков для построения нового диагностического показателя используются значения различных психологических шкал и факторов, которые, являясь нормативными измерениями, с очень большой осторожностью следует относить к количественным измерениям. Для ординальных признаков существенен лишь порядок градаций на шкале, и для них считаются допустимыми любые монотонные преобразования, не нарушающие этот порядок. Методологически строгим является применение к ординальным признакам методов обработки, результат которых инвариантен относительно допустимых преобразований порядковой шкалы /Енюков И. С., 1986/. Поэтому количественный анализ ординальных переменных, как и дихотомических, имеет свою специфику. В то же время некоторые авторы (например, Филмер П. и др., 1978) отмечают, что даже тогда, когда измерения осуществляются в шкалах порядка или более высокого уровня, анализ данных разумно строить так, как будто мы имеем дело с номинальными шкалами.
Описанные выше особенности экспериментальных данных в психодиагностике следует учитывать при выборе диагностической модели и методов эмпирико-статистической оценки ее параметров. В этой диагностической модели должна в определенной форме выражаться связь измеряемого вектора признаков х с тестируемым свойством, которое в дальнейшем будет обозначаться как у. То есть должен быть раскрыт механизм преобразования у=у(х). Первое требование, предъявляемое к математической модели, — это необходимое требование к конечному результату, который обязан быть максимально точным и надежным. Второе требование — лаконичность и интерпретируемость способа получения конечного результата. Указанные требования находятся в тесной взаимосвязи. Чем более экономно по форме и содержательно по смыслу преобразование у=у(х) при соблюдении заданной точности модели, тем более общие закономерности структуры экспериментальных данных вскрывает используемая модель и, значит, тем более устойчива и надежна количественная оценка диагностируемого показателя, получаемая с помощью преобразования у(х).
Структура экспериментальных данных, особенности которой в контексте решаемой диагностической задачи описывает математическая модель, отражается посредством двух основных категорий взаимоотношений между элементами ТЭД — категорий сходства и различия. Сходство и различие объектов ТЭД определяется мерами близости (удаления), а признаков — мерами связи. Ординальный и дихотомический характер исходных признаков выражается в специфике этих мер, которые рассматриваются ниже.
Матрица связи задает отношение «признак-признак» и представляет собой двумерную симметричную квадратную матрицу размера рхр

где Sij — мера связи между признаками xi и xj.
Известно большое количество мер связи между признаками. Они отличаются как объемом вычислений, так и теми аспектами связи, которые они отражают. Различные авторы предлагают разные основания для классификации этих мер связи (например, Елисеева И. И. и др., 1977; Миркин Б. Г., 1980; Никифоров А. М. и др., 1988). Здесь будут рассмотрены две представительные группы связи между признаками /Статистические методы..., 1979/.
В первой группе используется принцип ковариации, а во второй — принцип сопряженности признаков. Исходя из первого принципа, заключение о наличии связи между переменными делается в том случае, когда увеличение значения одной переменной сопровождается устойчивым увеличением или уменьшением значений другой. В математическом выражении задача сводится к вычислению ковариации, то есть сопутствующего изменения численных значений признаков. Сюда относится в первую очередь коэффициент корреляции Пирсона (rkj), который представляет собой произведение моментов и является мерой линейной связи двух переменных xk и xj. Он вычисляется по формуле

Многие меры связи отличаются от приведенного коэффициента корреляции Пирсона внешней формой, но являются, по сути, алгебраическим преобразованием этого коэффициента, учитывающим специфику (тип) сопоставляемых признаков. Taк, например, коэффициент ранговой корреляции Спирмена (rs), часто применяемый для анализа ординальных переменных, представляет собой алгебраическое упрощение rkj. То же самое можно сказать о точечном бисериальном коэффициенте корреляции (rpb) который служит мерой связи между дихотомической и количественной переменными. Некоторые другие коэффициенты, в частности тетрахорический коэффициент корреляции (rtet) и бисериальный коэффициент корреляции (rbis), можно интерпретировать как аппроксимации rkj для определенных типов признаков /Гласе Дж. и др., 1976/.
Несколько иной подход в рассматриваемой группе мер связи основывается на подсчете числа несовпадений в ранжировке объектов по сопоставляемым переменным. Этот подход разработал М. Кендалл /1974/, когда предпринял попытку истолковать процесс измерения связи между переменными, не прибегая к принципу произведения моментов. Он рассмотрел два порядковых признака xi и хj, на каждый из которых N объектов отображаются в N последовательных рангов (1, 2,..., N). Из N объектов формируется N(N — l)/2 пар, и для каждой пары подсчитывается количество совпадений порядка на признаке xj с порядком на признаке xj. Это количество обозначается «Р». Таким же образом определяется количество несовпадений (инверсий) «Q».
Коэффициент ранговой корреляции, получивший название «тау» Кендалла, вычисляется по формуле
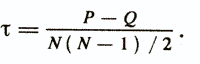
Несмотря на различие в подходах, между коэффициентами ранговой корреляции Спирмена и Кендалла, как отмечается в /Гласе Дж. и др., 1976/, существует тесная логическая связь. В то же время τ Кендалла имеет интересную для математических статистиков интерпретацию: если из N объектов случайно выбираются два объекта, то разность между вероятностью того, что они будут иметь одинаковый порядок как по xi, так и по xj, и вероятностью того, что у них будет наблюдаться различие в порядках по xi и хj, равна величине τ(«тау»). На основе подсчета количества совпадений и инверсий сконструирован целый ряд различных мер связи. В частности, этот принцип используется в коэффициенте бисериальной ранговой корреляции Кертена и Гласса (rrb), который применяется для изучения взаимодействия дихотомической и порядковой переменных. В то же время Гласc/Glass G. V., 1966/ показал, что rrb аналогичен бисериальному коэффициенту корреляции для порядковых переменных и для его вычисления можно обойтись без подсчета совпадений и инверсий.
Вторая обширная группа мер связи, основанная на принципе взаимной сопряженности, направлена на выяснение следующего факта: появляются ли некоторые значения одного признака одновременно с определенными значениями другого чаще, чем это можно объяснить случайным стечением обстоятельств. В данном случае фиксируется только сам факт наличия или отсутствия интересующих значений признака независимо от их количественного выражения /Никифоров А. М. и др., 1988/. Общим, как бы переходным, для первой и второй групп мер связи является популярный в психодиагностических исследованиях коэффициент φ, который предназначен для измерения связи двух дихотомических признаков или, иными словами, для анализа таблиц сопряженности 2X2 (табл. 2).
Таблица 2. Таблица сопряженности дихотомических признаков
| Признак xj | Признак xi | Итог | |
| 0 | 1 | ||
| 1 | а | b | a+b |
| 0 | с | d | c+d |
| Итог | a+c | b+d | |
Коэффициент φ представляет собой алгебраическое упрощение обычного коэффициента корреляции Пирсона rij с учетом специфики дихотомических признаков и вычисляется по формуле

Другие меры связи, основанные на принципе взаимной сопряженности, например коэффициенты Чупрова, Крамера, контингенции Пирсона и т. д., подробно рассматриваются в /Кендалл М. и др., 1976; Миркин Б. Г., 1976; Елисеева И. И. и др., 1977; Статистические методы..., 1979; Айвазян С. А. и др., 1983/.
Таблица 3. Рекомендуемые меры связи между различными типами признаков
Открыть таблицу »»»
В целом по проблеме выбора той или иной меры связи для решения конкретной задачи можно сказать следующее. Применение к одним и тем же данным различных мер связи нередко приводит к отличающимся результатам. Это обусловлено тем, что математики, конструировавшие коэффициенты корреляции, как правило, исследовали их свойства в предельных ситуациях — около 0 или 1 /Елисеева И. И. и др., 1977/. Поведение же различных мер связи внутри интервала [0,1] сравнительно мало изучено. Поэтому на практике предпочтительный выбор какой-либо меры связи бывает непросто обосновать, а результаты использования разных мер трудно сравнивать. Во многом такой выбор определяется личными симпатиями исследователя. В качестве рекомендации предлагается таблица 3, в которую сведены наиболее часто употребляемые в психологии меры связи для признаков разного типа. Подробно все коэффициенты, указанные в таблице, анализируются в /Гласc Дж. и др., 1976/.
Матрица близостей (удаленностей) задает отношение «объект-объект» и представляет собой квадратную симметричную матрицу NхN с неотрицательными элементами

Элементы dij являются значениями некоторой меры близости (удаленности) между объектами хi и хj. Чаще в анализе данных используются меры удаленности. К этим мерам предъявляются следующие требования:
1. Максимальное сходство объекта с самим собой —
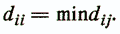
2. Требование симметрии —

3. Выполнение неравенства треугольника -
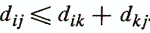
Последнее требование предъявляется к матрицам расстояний (диагональные элементы должны быть равны нулю). Матрица D, удовлетворяющая перечисленным трем требованиям, допускает толкование структуры взаимоотношений объектов исследования как некоторой геометрической конфигурации точек в многомерном пространстве признаков.
Приведем наиболее распространенные меры расстояния между объектами хi и хj
.
1) Евклидово расстояние -
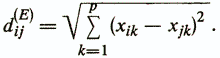
Эта мера может применяться для вычисления расстояния между объектами, описанными количественными, качественными и дихотомическими признаками. Ее использование целесообразно, когда признаки однородны по смысловой нагрузке и одинаково важны для решаемой задачи.
2) Взвешенное евклидово расстояние —
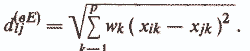
Данную меру используют, когда необходимо количественно шразить важность каких-либо признаков или выравнять мас-птабы неоднородных признаков.
продолжение следует...
Часть 1 Конструирование психодиагностических тестов: традиционные математические модели и алгоритмы
Часть 2 2. Методы, основанные на критерии автоинформативности системы признаков - Конструирование
Часть 3 Дискриминантный анализ - Конструирование психодиагностических тестов: традиционные математические модели и
Часть 4 Типологический подход - Конструирование психодиагностических тестов: традиционные математические модели и
Часть 5 - Конструирование психодиагностических тестов: традиционные математические модели и алгоритмы
Часть 6 - Конструирование психодиагностических тестов: традиционные математические модели и алгоритмы
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.
Комментарии
Оставить комментарий
Математические методы в психологии
Термины: Математические методы в психологии