Лекция
Привет, Вы узнаете о том , что такое обработка данных в психологии, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое обработка данных в психологии , настоятельно рекомендую прочитать все из категории Математические методы в психологии.
Слово «статистика» часто ассоциируется со словом «математика», и это пугает студентов, связывающих это понятие со сложными формулами, требующими высокого уровня абстрагирования.
Однако, как говорит Мак-Коннелл, статистика — это прежде всего способ мышления, и для ее применения нужно лишь иметь немного здравого смысла и знать основы математики. В нашей повседневной жизни мы, сами о том не догадываясь, постоянно занимаемся статистикой. Хотим ли мы спланировать бюджет, рассчитать потребление бензина автомашиной, оценить усилия, которые потребуются для усвоения какого-то курса, с учетом полученных до сих пор отметок, предусмотреть вероятность хорошей и плохой погоды по метеорологической сводке или вообще оценить, как повлияет то или иное событие на наше личное или совместное будущее, — нам постоянно приходится отбирать, классифицировать и упорядочивать информацию, связывать ее с другими данными так, чтобы можно было сделать выводы, позволяющие принять верное решение.
Все эти виды деятельности мало отличаются от тех операций, которые лежат в основе научного исследования и состоят в синтезе данных, полученных на различных группах объектов в том или ином эксперименте, в их сравнении с целью выяснить черты различия между ними, в их сопоставлении с целью выявить показатели, изменяющиеся в одном направлении, и, наконец, в предсказании определенных фактов на основании тех выводов, к которым приводят полученные результаты. Именно в этом заключается цель статистики в науках вообще, особенно в гуманитарных. В последних нет ничего абсолютно достоверного, и без статистики выводы в большинстве случаев были бы чисто интуитивными и не могли бы составлять солидную основу для интерпретации данных, полученных в других исследованиях.
Для того чтобы оценить огромные преимущества, которые может дать статистика, мы попробуем проследить за ходом расшифровки и обработки данных, полученных в эксперименте. Тем самым, исходя из конкретных результатов и тех вопросов, которые они ставят перед исследователем, мы сможем разобраться в различных методиках и несложных способах их применения. Однако, перед тем как приступить к этой работе, нам будет полезно рассмотреть в самых общих чертах три главных раздела статистики.
1. Описательная статистика, как следует из названия, позволяет описывать, подытоживать и воспроизводить в виде таблиц или графиков
данные того или иного распределения, вычислять среднее для данного распределения и его размах и дисперсию.
2. Задача индуктивной статистики — проверка того, можно ли распространить результаты, полученные на данной выборке, на всю популяцию, из которой взята эта выборка. Иными словами, правила этого раздела статистики позволяют выяснить, до какой степени можно путем индукции обобщить на большее число объектов ту или иную закономерность, обнаруженную при изучении их ограниченной группы в ходе какого-либо наблюдения или эксперимента. Таким образом, при помощи индуктивной статистики делают какие-то выводы и обобщения, исходя из данных, полученных при изучении выборки.
3. Наконец, измерение корреляции позволяет узнать, насколько связаны между собой две переменные, с тем чтобы можно было предсказывать возможные значения одной из них, если мы знаем другую.
Существуют две разновидности статистических методов или тестов, позволяющих делать обобщение или вычислять степень корреляции. Первая разновидность — это наиболее широко применяемые параметрические методы, в которых используются такие параметры, как среднее значение или дисперсия данных. Вторая разновидность — это непараметрические методы, оказывающие неоценимую услугу в том случае, когда исследователь имеет дело с очень малыми выборками или с качественными данными; эти методы очень просты с точки зрения как расчетов, так и применения. Когда мы познакомимся с различными способами описания данных и перейдем к их статистическому анализу, мы рассмотрим обе эти разновидности.
Как уже говорилось, для того чтобы попытаться разобраться в этих различных областях статистики, мы попробуем ответить на те вопросы, которые возникают в связи с результатами того или иного исследования. В качестве примера мы возьмем один эксперимент, а именно — изучение влияния потребления марихуаны на глазодвигательную координацию и на время реакции. Методика, используемая в этом гипотетическом эксперименте, а также результаты, которые мы могли бы в нем получить, представлены ниже.
При желании вы можете заменить какие-то конкретные детали этого эксперимента на другие — например, потребление марихуаны на потребление алкоголя или лишение сна, — или, что еще лучше, подставить вместо этих гипотетических данных те, которые вы действительно получили в вашем собственном исследовании. В любом случае вам придется принять «правила нашей игры» и выполнять те расчеты, которые здесь от вас потребуются; только при этом условии до вас «дойдет» существо предмета, если это уже не случилось с вами раньше.
Важное примечание. В разделах, посвященных описательной и индуктивной статистике, мы будем рассматривать только те данные эксперимента, которые имеют отношение к зависимой переменной «поражаемые мишени». Что касается такого показателя, как время реакции, то мы обратимся к нему только в разделе о вычислении корреляции. Однако само собой разумеется, что уже с самого начала значения этого показателя надо обрабатывать так же, как и переменную «поражаемые мишени». Мы предоставляем читателю заняться этим самостоятельно с помощью карандаша и бумаги.
Одна из задач статистики состоит в том, чтобы анализировать данные, полученные на части популяции, с целью сделать выводы относительно популяции в целом.
Популяцияв статистике не обязательно означает какую-либо группу людей или естественное сообщество; этот термин относится ко всем существам или предметам, образующим общую изучаемую совокупность, будь то атомы или студенты, посещающие то или иное кафе.
Выборка — этонебольшое количество элементов, отобранных с помощью научных методов так, чтобы она была репрезентативной, т.е. отражала популяцию в целом.
(В отечественной литературе более распространены термины соответственно «генеральная совокупность» и «выборочная совокупность». — Прим. перев.)
Данные в статистике — это основные элементы, подлежащие анализу. Данными могут быть какие-то количественные результаты, свойства, присущие определенным членам популяции, место в той или иной последовательности — в общем любая информация, которая может быть классифицирована или разбита на категории с целью обработки.
Не следует смешивать «данные» с теми «значениями», которые эти данные могут принимать. Для того чтобы всегда различать их, Шатийон (Chatillon, 1977) рекомендует запомнить следующую фразу: «Данные часто принимают одни и те же значения» (так, если мы возьмем, например, шесть данных — 8, 13, 10, 8, 10 и 5, то они принимают лишь четыре разных значения — 5, 8, 10 и 13).
Построение распределения — это разделение первичных данных, полученных на выборке, на классы или категории с целью получить обобщенную упорядоченную картину, позволяющую их анализировать.
Существуют три типа данных:
1. Количественные данные, получаемые при измерениях (например, данные о весе, размерах, температуре, времени, результатах тестирования и т. п.). Их можно распределить по шкале с равными интервалами.
2. Порядковые данные, соответствующие местам этих элементов в последовательности, полученной при их расположении в возрастающем порядке (1-й, ..., 7-й, ..., 100-й, ...; А, Б, В. ...).
3. Качественные данные, представляющие собой какие-то свойства элементов выборки или популяции. Их нельзя измерить, и единственной их количественной оценкой служит частота встречаемости (число лиц с голубыми или с зелеными глазами, курильщиков и не курильщиков, утомленных и отдохнувших, сильных и слабых и т.п.).
Из всех этих типов данных только количественные данные можно анализировать с помощью методов, в основе которых лежат параметры (такие, например, как средняя арифметическая). Но даже к количественным данным такие методы можно применить лишь в том случае, если число этих данных достаточно, чтобы проявилось нормальное распределение. Итак, для использования параметрических методов в принципе необходимы три условия: данные должны быть количественными, их число должно быть достаточным, а их распределение — нормальным. Во всех остальных случаях всегда рекомендуется использовать непараметрические методы.
Описательная статистика позволяет обобщать первичные результаты, полученные при наблюдении или в эксперименте. Процедуры здесь сводятся к группировке данных по их значениям, построению распределения их частот, выявлению центральных тенденций распределения (например, средней арифметической) и, наконец, к оценке разброса данных по отношению к найденной центральной тенденции.
Гипотетический эксперимент. Влияние потребления марихуаны на глазодвигательную координацию и время реакции
На группе из 30 добровольцев-студентов и студенток, курящих обычные сигареты, но не марихуану, — был проведен опыт по изучению глазодвигательной координации. Задача испытуемых заключалась в том, чтобы поражать предъявляемые на дисплее движущиеся мишени, манипулируя подвижным рычагом. Каждому испытуемому были предъявлены 10 последовательностей из 25 мишеней.
Для того чтобы установить исходный уровень, рассчитали среднее число попаданий из 25, а также среднее время реакции для 250 попыток. Далее группа была разделена на две подгруппы как можно более равным образом. Семь девушек и восемь юношей из контрольной группы получили сигарету с обычным табаком и сушеной травой, дым от которой напоминал по запаху дым марихуаны. В отличие от этого семь девушек и восемь юношей из опытной (экспериментальной) группы получили сигарету с табаком и марихуаной. Выкурив сигарету, каждый испытуемый снова был подвергнут тесту на. глазодвигательную координацию.
В табл. 1 и 2 представлены средние результаты обоих измерений для испытуемых той и другой группы до и после воздействия.
Таблица 1. Результативность испытуемых контрольной и опытной групп (среднее число пораженных мишеней из 25 в 10 сериях испытаний)
| Контрольная группа | Опытная группа | ||||
| Испытуемые | Фон (довоздей-ствия) |
После воздействия (табак с нейтральной добавкой) | Испытуемые | Фон (до воздей-ствия) |
После воздействия (табак с марихуаной) |
| Д1 | 19 | 21 | Д8 | 12 | 8 |
| 2 | 10 | 8 | 9 | 21 | 20 |
| 3 | 12 | 13 | 10 | 10 | 6 |
| 4 | 13 | 11 | 11 | 15 | 8 |
| 5 | 17 | 20 | 12 | 15 | 17 |
| 6 | 14 | 12 | 13 | 19 | 10 |
| 7 | 17 | 15 | 14 | 17 | 10 |
| Ю1 | 15 | 17 | Ю9 | 14 | 9 |
| 2 | 14 | 15 | 10 | 13 | 7 |
| 3 | 15 | 15 | 11 | И | 8 |
| 4 | 17 | 18 | 12 | 20 | 14 |
| 5 | 15 | 16 | 13 | 15 | 13 |
| 6 | 18 | 15 | 14 | 15 | 16 |
| 7 | 19 | 19 | 15 | 14 | 11 |
| 8 | 22 | 25 | 16 | 17 | 12 |
| Итого | 237 | 240 | Итого | 228 | 169 |
| Средняя | 15,8 | 16,0 | Средняя | 15,2 | 11,3 |
| Стандартное отклонение | 3,07 | 4,25 | Стандартное отклонение | 3,17 | 4.04 |
| Девушки: Д1-Д14 | Юноши: Ю1-Ю16 | ||||
Таблица 2. Время реакции испытуемых контрольной и опытной групп (среднее время 1/10 с в серии из 10 испытаний)
| Контрольная группа | Опытная группа | ||||
| Испытуемые | Фон (до воздей-ствия) |
После воздействия ( табак с нейтральной добавкой) | Испытуемые | Фон (до воздей-ствия) |
После воздействия (табак с марихуаной) |
| Д 1 | 8 | 9 | Д 8 | 15 | 17 |
| 2 | 15 | 16 | 9 | 11 | 13 |
| 3 | 13 | 14 | 10 | 16 | 20 |
| 4 | 14 | 13 | 11 | 13 | 18 |
| 5 | 15 | 12 | 12 | 18 | 21 |
| 6 | 13 | 15 | 13 | 14 | 22 |
| 7 | 14 | 15 | 14 | 13 | 19 |
| Ю1 | 12 | 10 | Ю9 | 15 | 20 |
| 2 | 16 | 13 | 10 | 18 | 17 |
| 3 | 13 | 15 | 11 | 15 | 19 |
| 4 | 11 | 12 | 12 | 11 | 14 |
| 5 | 18 | 13 | 13 | 14 | 12 |
| 6 | 12 | И | 14 | 11 | 18 |
| 7 | 13 | 12 | 15 | 12 | 21 |
| 8 | 14 | 10 | 16 | 15 | 17 |
| Средняя | 13,4 | 12,7 | Средняя | 14,06 | 17,9 |
| Стандартное отклонение | 2,29- | 2,09 | Стандартное отклонение | 2,28 | 2,97 |
| Девушки: Д1-Д14 | Юноши: Ю1-Ю16 | ||||
Группировка данных
Для группировки необходимо прежде всего расположить данные каждой выборки в возрастающем порядке. Так, в нашем эксперименте для переменной «число пораженных мишеней» данные будут располагаться следующим образом:
Контрольная группа
| Фон: | 10 | 12 | 13 | 14 | 14 | 15 | 15 | 15 | 17 | 17 | 17 | 18 | 19 | 19 | 22 |
| После воздействия: | 8 | 11 | 12 | 13 | 15 | 15 | 15 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 25 |
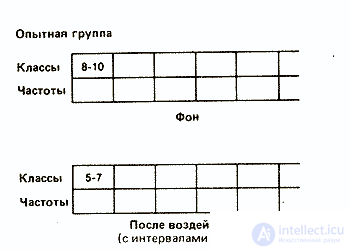
Опытная группа (дополнить цифрами самостоятельно)
Фон: ............
После воздействия: .......
Распределение частот (числа пораженных мишеней)
Уже при первом взгляде не полученые ряды можно заметить, что многие данные принимают одни и те же значения, причем одни значения встречаются чаще, а другие — реже. Поэтому было бы интересно вначале графически представить распределение различных значений с учетом их частот. При этом получают следующие столбиковые диаграммы:
Контрольная группа
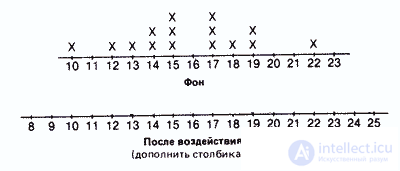
Опытная группа

Такое распределение данных по их значениям дает нам уже гораздо больше, чем представление в виде рядов. Однако подобную группировку используют в основном лишь для качественных данных, четко разделяющихся на обособленные категории.
Что касается количественных данных, то они всегда располагаются на непрерывной шкале и, как правило, весьма многочисленны. Поэтому такие данные предпочитают группировать по классам, чтобы яснее видна была основная тенденция распределения.
Такая группировка состоит в основном в том, что объединяют данные с одинаковыми или близкими значениями в классы и определяют частоту для каждого класса. Способ разбиения на классы зависит от того, что именно экспериментатор хочет выявить при разделении измерительной шкалы на равные интервалы. Например, в нашем случае можно сгруппировать данные по классам с интервалами в две или три единицы шкалы:
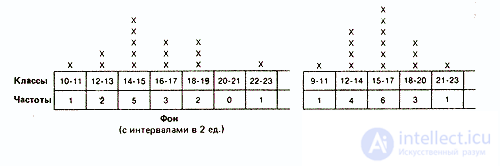
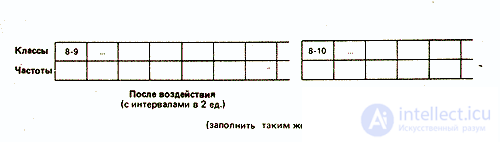
Выбор того или иного типа группировки зависит от различных соображений. Так, в нашем случае группировка с интервалами между классами в две единицы хорошо выявляет распределение результатов вокруг центрального «пика». В то же время группировка с интервалами в три единицы обладает тем преимуществом, что дает более обобщенную и упрощенную картину распределения, особенно если учесть, что число элементов в каждом классе невелико. При большом количестве данных число классов по возможности должно быть где-то в пределах от 10 до 20, с интервалами до 10 и более. Именно поэтому в дальнейшем мы будем оперировать классами в три единицы.
Опытная группа
Данные, разбитые на классы по непрерывной шкале, нельзя представить графически так, как это сделано выше. Поэтому предпочитают использовать так называемые гистограммы способ графического представления в виде примыкающих друг к другу прямоугольников:
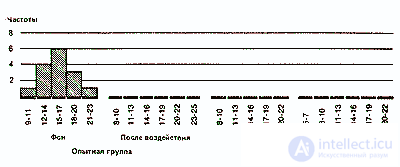
Наконец, для еще более наглядного представления общей конфигурации распределения можно строить полигоны распределения частот. Об этом говорит сайт https://intellect.icu . Для этого отрезками прямых соединяют центры верхних сторон всех прямоугольников гистограммы, а затем с обеих сторон «замыкают» площадь под кривой, доводя концы полигонов до горизонтальной оси (частота = 0) в точках, соответствующих самым крайним значениям распределения. При этом получают следующую картину:

Если сравнить полигоны, например, для фоновых (исходных) значений контрольной группы и значений после воздействия для опытной группы, то можно будет увидеть, что в первом случае полигон почти симметричен (т.е. если сложить полигон вдвое по вертикали, проходящей через его середину, то обе половины належатся друг на друга), тогда как для экспериментальной группы он асимметричен и смещен влево (так что справа у него как бы вытянутый шлейф).
Полигон для фоновых данных контрольной группы сравнительно близок к идеальной кривой, которая могла бы получиться для бесконечно большой популяции. Такая кривая — кривая нормального распределения - имеет колоколообразную форму и строго симметрична. Если же количество данных ограничено (как в выборках, используемых для научных исследований), то в лучшем случае получают лишь некоторое приближение (аппроксимацию) к кривой нормального распределения.
Если вы построите полигон для фоновых значений опытной группы и значений после воздействия для контрольной группы, то вы наверняка заметите, что так же будет обстоять дело и в этих случаях.
Если распределения для контрольной группы и для фоновых значений в опытной группе более или менее симметричны, то значения, получаемые в опытной группе после воздействия, группируются, как уже говорилось, больше в левой части кривой. Это говорит о том, что после употребления марихуаны выявляется тенденция к ухудшению показателей у большого числа испытуемых.
Для того чтобы выразить подобные тенденции количественно, используют три вида показателей моду, медиану и среднюю.
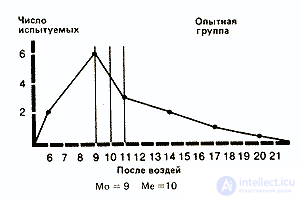
1. Мода (Мо) — это самый простой из всех трех показателей. Она соответствует либо наиболее частому значению, либо среднему значению класса с наибольшей частотой. Так, в нашем примере для экспериментальной группы мода для фона будет равна 15 (этот результат встречается четыре раза и находится в середине класса 14-15-16), а после воздействия — 9 (середина класса 8-9-10).
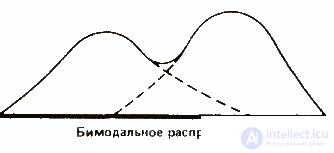
Мода используется редко и главным образом для того, чтобы дать общее представление о распределении. В некоторых случаях у распределения могут быть две моды; тогда говорят о бимодальном распределении. Такая картина указывает на то, что в данном совокупности имеются две относительно самостоятельные группы.
2. Медиана (Me) соответствует центральному значению в последовательном ряду всех полученных значений. Так, для фона в экспериментальной группе, где мы имеем ряд
10 11 12 13 14 14 15 15 15 15 17 17 19 20 21,
медиана соответствует 8-му значению, т.е. 15. Для результатов воздействия в экспериментальной группе она равна 10.
В случае если число данных n, четное, медиана равна средней арифметической между значениями, находящимися в ряду на n/2-м и n/2+1-м местах. Так, для результатов воздействия для восьми юношей опытной группы медиана располагается между значениями, находящимися на 4-м (8/2 = 4) и 5-м местах в ряду. Если выписать весь ряд для этих данных, а именно
7 8 9 11 12 13 14 16,
то окажется, что медиана соответствует (11 + 12)/2=11,5 (видно, что медиана не соответствует здесь ни одному из полученных значении).
3. Средняя арифметическая (М) (далее просто «средняя») — это наиболее часто используемый показатель центральной тенденции. Ее применяют, в частности, в расчетах, необходимых для описания распределения и для его дальнейшего анализа. Ее вычисляют, разделив сумму всех значений данных на число этих данных. Так, для нашей опытной группы она составит 15,2(228/15) для фона и 11,3(169/15) для результатов воздействия.
Если теперь отметить все эти три параметра на каждой из кривых экспериментальной группы, то будет видно, что при нормальном распределении они более или менее совпадают, а при асимметричном распределении — нет.
Прежде чем идти дальше, полезно будет вычислить все эти показатели для обеих распределений контрольной группы — они пригодятся нам в дальнейшем:

Оценка разброса
Как мы уже отмечали, характер распределения результатов после воздействия изучаемого фактора в опытной группе дает существенную информацию о том, как испытуемые выполняли задание. Сказанное относится и к обоим распределениям в контрольной группе:
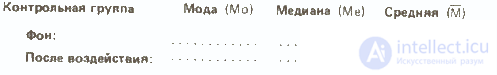
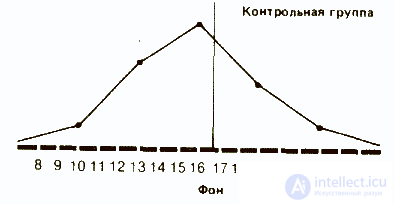
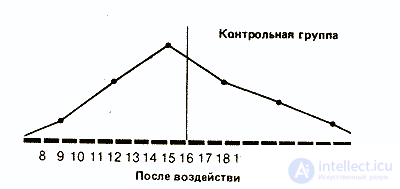
Сразу бросается в глаза, что если средняя в обоих случаях почти одинакова, то во втором распределении результаты больше разбросаны, чем в первом. В таких случаях говорят, что у второго распределения больше диапазон, или размах вариаций, т. е. разница между максимальным и минимальным значениями.
Так, если взять контрольную группу, то диапазон распределения для фона составит 22-10=12, а после воздействия 25-8=17. Это позволяет предположить, что повторное выполнение задачи на глазодвигательную координацию оказало на испытуемых из контрольной группы определенное влияние: у одних показатели улучшились, у других ухудшились. Здесь мог проявиться эффект плацебо, связанный с тем, что запах дыма травы вызвал у испытуемых уверенность в том. что они находятся под воздействием наркотика. Для проверки этого предположения следовало бы повторить эксперимент со второй контрольной группой, в которой испытуемым будут давать только обычную сигарету.
Однако для количественной оценки разброса результатов относительно средней в том или ином распределении существуют более точные методы, чем измерение диапазона.
Чаще всего для оценки разброса определяют отклонение каждого из полученных значений от средней (М-М), обозначаемое буквой d, а затем вычисляют среднюю арифметическую всех этих отклонений. Чем она больше, тем больше разброс данных и тем более разнородна выборка. Напротив, если эта средняя невелика» то данные больше сконцентрированы относительно их среднего значения и выборка более однородна.
Итак, первый показатель, используемый для оценки разброса, — это среднее отклонение. Его вычисляют следующим образом (пример, который мы здесь приведем, не имеет ничего общего с нашим гипотетическим экспериментом). Собрав все данные и расположив их в ряд
3 5 6 9 11 14,
находят среднюю арифметическую для выборки:
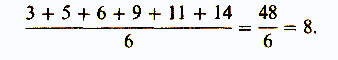
Затем вычисляют отклонения каждого значения от средней и суммируют их:

Однако при таком сложении отрицательные и положительные отклонения будут уничтожать друг друга, иногда даже полностью, так что результат (как в данном примере) может оказаться равным нулю. Из этого ясно, что нужно находить сумму абсолютных значений индивидуальных отклонений и уже эту сумму делить на их общее число. При этом получится следующий результат:
среднее отклонение равно
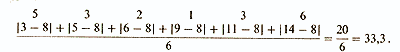
продолжение следует...
Часть 1 Статистика и обработка данных в психологии
Часть 2 Индуктивная статистика - Статистика и обработка данных в психологии
Часть 3 Корреляционный анализ - Статистика и обработка данных в психологии
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

Комментарии