Лекция
Привет, Вы узнаете о том , что такое анализ пунктов при конструировании, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое анализ пунктов при конструировании, применении тест-опросников, ручные, компьютерные алгоритмы , настоятельно рекомендую прочитать все из категории Математические методы в психологии.
Во многих областях практической психологии широко используются измерительные психодиагностические методики, к которым относятся тесты на измерение способностей, достижений, аппаратурные методики, основанные на стандартизированном самоотчете — опросники и техники субъективного шкалирования. Корректность в применении этих методик обеспечивается не только содержательными представлениями, но и выполнением особых требований психометрики — требований валидности, надежности, репрезентативности тестовых норм.
Тестовые методики призваны решить определенный ограниченный круг задач. Это задачи массовой экспресс-диагностики. Здесь не исключены ошибки в индивидуальных случаях, диагноз и прогноз даются лишь с вероятностной точностью.
В настоящем сообщении рассмотрены конкретные приемы эмпирико-статистической отладки тестов, которыми психолог может воспользоваться как при наличии современной вычислительной техники, так и в ее отсутствие. Эти приемы позволяют проверить, «работает» ли тест в целом и, если он плохо дифференцирует испытуемых, в каких своих частях (заданиях, вопросах) тест «не срабатывает». Применение этих приемов полезно и необходимо не только при разработке новых тестов, но и при всяком изменении диагностической ситуации в применении старого теста (например, переход от добровольного к принудительному обследованию), при переносе теста с одной популяции (на которой установлены тестовые нормы) на другую. Это прежде всего относится к техникам самоотчета и, в частности, к тест-опросникам, полностью зависящим от того, как конкретный испытуемый интерпретирует семантику вопросов и связывает ее с субъективной гипотезой о цели обследования. Но описываемые здесь алгоритмы применимы и к любым другим тестам: результаты выполнения тестовых заданий также могут формально кодироваться в виде бинарной переменной — 1 («решил») или 0 («не решил»).
Тест-опросник состоит, как правило, из так называемых ли-вопросов, или «да-нет»-вопросов [4]: каждый вопрос содержит утверждение, с которым испытуемому предлагается соглашаться или не соглашаться. В результате ответ испытуемого кодируется как дихотомическая переменная со значениями «+1» («верно») и «-1» («неверно»). Балл теста подсчитывается суммированием ответов «верно» на «прямые» пункты теста (это вопросы, позитивно связанные с измеряемой чертой) и ответов «неверно» на «обратные» пункты (вопросы, негативно связанные с измерямой чертой). Алгебраически такой простейший способ подсчета тестового балла может быть описан формулой (1):
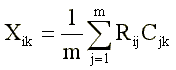
где:
Хik — балл i-того испытуемого по k-той шкале (черте);
Rij — ответ i-того испытуемого на j-тый пункт тест-опросника;
Cjk — ключ (шкальное значение) j-того пункта по k-той шкале;
m — количество пунктов в к-той шкале (для которых Сjk № 0).
Обычно Rij = {-1,+1} и Cjk={-1, 0, +1}.
Чтобы как-то минимизировать и без того большие погрешности тест-опросника, психолог обязан понимать психологический смысл этой процедуры. Пункт тест-опросника должен являться эмпирическим индикатором диагностического концепта — личностной черты. Если психолог приезжает в маленький городок, в котором до вокзала всем жителям шаг шагнуть, то вопрос «Вы заказываете такси перед отправлением на вокзал?» здесь заведомо не будет иметь никакого отношения к такой черте, как «тревожность». В подобных условиях такой вопрос просто некорректен, не информативен, его следует исключить из перечня. Прежде чем применить какой-то тест-опросник на особом контингенте лиц, психолог должен постараться взглянуть на каждый вопрос глазами испытуемого. Это требует немалой профессиональной интуиции. При наличии большой батареи вопросов добиться полной имитации ответов испытуемых не удается ни одному психологу. Здесь на помощь приходит аппарат эмпирико-статистического анализа пунктов (в зарубежной тестологии утвердился особый термин — "item analysis") [7].
В настоящее время без применения этого аппарата не обходится ни одна серьезная попытка конструирования или адаптации тестов.
Аппарат эмпирико-статистического анализа пунктов открывает возможность для приспосабливания методики к конкретным условиям ее применения. Эта возможность состоит в модификации шкальных ключей для отдельных пунктов (значений Сjk). Обычная архаическая доизмерительная стратегия такого приспособления состоит в том, что психолог переформулирует сам вопрос. Например, вместо вопроса о заказе такси в маленьком городе он будет задавать вопрос «Приходите ли вы на вокзал за полчаса до отправления поезда?» Таким образом, перечень вопросов изменяется. Результаты, полученные от респондентов из крупных и небольших городов, оказываются несопоставимыми. Противоположная тактика состоит в том, чтобы перечень вопросов оставлять неизменным, но в разных случаях пользоваться разными векторами шкальных ключей <С>. (Во всех случаях задаются оба вопроса. Этот подход позволяет соединить две (обычно рассматриваемые как независимые) задачи конструирования теста: отбор информативных признаков (пунктов с Cjk № 0) и построение шкалы (уточнение градуального Cjk).) При этом вопрос про такси будет иметь Сjk = 0.0 в маленьком городе (где k — шкала «тревожности») и, наоборот, Сjk = +1.0 в большом.
Как же эмпирически устанавливать значения Сjk в отсутствии компьютера, т. е. вручную? Здесь мы опишем простейший метод, который, как показали специально проведенные нами исследования, дает результаты, достаточно хорошо совпадающие с результатами громоздких компьютерных алгоритмов.
Идеи этого алгоритма в разнообразных модификациях использовались во множестве работ зарубежных и отечественных авторов. Рассмотрим ситуацию, возникающую в отсутствие внешнего критерия валидности.
Пусть психолог имеет тест-опросник, ориентированный на измерение какой-то одной личностной черты (одномерный опросник) и содержащий М вопросов. Об опрашиваемом контингенте психолог не имеет никакой априорной эмпирической информации, но исходит из предположения, что индивиды в этой выборке значимо отличаются между собой по степени выраженности рассматриваемой черты k. Психолог хочет приспособить тест-опросник к измерению черты k на данном контингенте с помощью уточнения шкальных ключей Cjk. Для этого ему целесообразно взять для предварительного психометрического исследования случайную выборку из N индивидов. Для успешного анализа пунктов требуется использовать М і 50 и N і 100. Меньшие значения М и N, как правило, приводят к слишком большому отсеву пунктов (многие потенциально информативные, диагностически ценные пункты получают Cjk = 0).
На сформированной выборке психолог проводит обследование и получает массив результатов в виде прямоугольной матрицы размерностью N×М, где по строкам испытуемые, по столбцам — пункты, на пересечении — значения Rij ответов i-го испытуемого на j-й вопрос тест-опросника.
Для каждого столбца (для каждого пункта) психолог на основании исходных предположений назначает С0jk — исходные шкальные ключи. Затем для каждой строки (каждого испытуемого) матрицы |R| по формуле (1) подсчитывается суммарный тестовый балл Хik. Среди всех {X} отыскивают 30% испытуемых с наибольшими значениями тестового балла и 30% — с наименьшими. Они включаются соответственно в «высокую» и «низкую» экстремальную группы. В дальнейшем по каждому пункту учитываются только ответы испытуемых из экстремальных групп. Шкальные ключи Сjk уточняются с помощью расчета четырехклеточной корреляции между ответами на пункт и попаданием в экстремальную группу. Для каждого пункта строится матрица сопряженности 2×2:
| Экстремальная группа | ||
| Ответ | Высокая | Низкая |
| «Верно» | a | b |
| «Неверно» | c | d |
В клеточках таблички 2 × 2 указываются частоты. Например, в клеточке а суммируется частота встречаемости тех испытуемых, которые попали в «высокую» группу и ответили «верно» на данный j-й пункт опросника, в клеточке b — число испытуемых из «низкой» группы, ответивших «верно». и т. п. Очевидно, что «хороший» пункт, обладающий высокой дискриминативностью относительно экстремальных групп, должен обладать высоким контрастом значений a и b, с одной стороны, и одновременно высоким контрастом с и d — с другой. При этом контрасты должны иметь противоположный знак: если а больше b («верно» чаще отвечает «высокая» группа), то с должно быть меньше а («неверно» чаще отвечает «низкая» группа); наоборот, в случае «обратных» пунктов, когда разность а-b отрицательна, то разность с-d должна быть положительна. Существуют различные коэффициенты, которые учитывают эти требования [6], [3]. Мы предлагаем использовать наиболее популярный из них фи-коэффициент [27]:
(2)
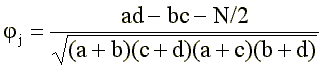
где N — сумма всех элементов таблички: N = a+b+c+d (В случае «обратных» пунктов, когда разность (ad-be) отрицательна, величину, надо к числителю, наоборот, прибавить, а не отнять, числитель формулы (2) получает вид: ad-bc+N*/2.)
Так как при использовании равных и известных по объему экстремальных групп а+с = b+d = S, формула (2) несколько упрощается:
(3)
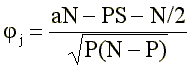
где Р — сумма ответов «верно» на данный пункт: Р=а+b.
Значимость фи-коэффициента устанавливается из следующего приближенного соотношения:
(4)
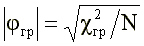
где: c2гp — стандартный квантиль распределения хи-квадрат с одной степенью свободы. Как известно. c21; 0.05 = 3,84 и c21; 0.01 = 6,63.
Таким образом, если при выборке N=100 вычисленное значение фи-коэффициента превышает по модулю 0.26, то это означает, что с пренебрежимой вероятностью ошибки в 1% можно делать вывод о том, что данный пункт вносит значимый вклад в суммарный балл. Если j і 0.26, пункт следует считать «прямым» (ответ «верно» свидетельствует в пользу измеряемой черты), если j Ј -0.26, пункт следует считать обратным (ответ «неверно» свидетельствует в пользу измеряемой черты).
Если количество пунктов М=50, психологу предстоит строить 50 матриц 2 × 2 и 50 раз подсчитывать фи-коэффициент с использованием формулы (3). Понятно, что для облегчения процедуры следует использовать при подсчете формулы (3) карманный калькулятор, а для построения табличек сопряженности удобно изготовить трафаретку (наподобие ключа при подсчете суммарных баллов): на полоске прозрачной бумаги (полиэтилена) указать кружками расположение по строкам матрицы |R| испытуемых из «высокой» группы и треугольниками — испытуемых из «низкой» группы. Тогда при попадании в столбце ответа «+» в кружок единица записывается в клетку «а», при попадании ответа «+» в треугольник — в клетку «b» и т. д.
После того как для всех М пунктов подсчитаны jj и проверены на значимость (j сопоставлены с |jгр|), психолог выводит новые уточненные значения C1jk: если jj і jгр, то C1jk = +1; если jj Ј -jгр, то C1jk = -1, если -jгр < jj<jгр, то C1jk=0 (т. е. при подсчете суммарного балла пункт не учитывается).
Если все уточненные C1jk совпали с исходными предполагаемыми ключами C0jk, то можно делать вывод о том, что психометрический эксперимент полностью подтвердил проверяемый тест-опросник по всем пунктам, из которых он состоит. Но на практике такого полного совпадения не бывает никогда.
В отсутствие полного совпадения требуется выполнить новый цикл вычислительной обработки. По уточненному вектору — ключу <С1> по формуле (1) вновь подсчитываются суммарные баллы для всех испытуемых. Затем опять определяются экстремальные группы, вновь подсчитываются фи-корреляции для всех М пунктов опросника. (Если сразу несколько испытуемых на границе между экстремальной и нейтральной группой набрали одинаковый балл, то следует всех испытуемых с одинаковым баллом включить в одну группу, добиваясь, чтобы экстремальная была ближе к 30%, тогда численности экстремальных групп могут быть не одинаковы и следует воспользоваться формулой (2) при подсчете jj.) Очевидно, что процедура достигает результативной остановки, если <Ct> = <Ct+1> т. Об этом говорит сайт https://intellect.icu . е. когда ключ, полученный на очередном шаге обработки, совпадает полностью (по всем j) с ключом, полученным на предыдущем шаге.
В данном случае этот момент можно определить заранее: искомое условие достигается уже тогда, когда стабилизируются составы «высокой» и «низкой» групп (а именно составы экстремальных групп определяют значения фи-корреляции). Для оценки качества пунктов часто применяют более трудоемкую в вычислительном отношении точечно-бисериальную корреляцию [2], [25]. В этом случае остановиться можно при равенстве ct+1ik= ctik
Нами накоплен значительный эмпирический опыт использования указанного простого алгоритма. С помощью этого алгоритма овладевают приемами анализа пунктов студенты общего и специального практикумов факультета психологии [22]. Сравнение результатов этого алгоритма с более точными компьютерными алгоритмами (например, факторный анализ по методу главных компонент) показало, что достигается удовлетворительное соответствие «ручных» и «компьютерных» ключей в среднем уже на пятом-шестом шаге приближения.
Надо сказать, что сходимость (скорость стабилизации вектора <Сtjk>) данного алгоритма зависит от степени разработанности самого опросника. Этот алгоритм быстро приводит к выделению устойчиво полезных пунктов, если большинство пунктов опросника хороши. Наоборот, если таких пунктов меньше половины, то процедура затягивается. В этом случае лучше остановить процесс обсчета уже после первого приближения <С'> и, если найдено слишком мало значимых jj, заняться переформулированием старых или добавлением новых вопросов (после чего проводить новое обследование).
Значимые показатели jj указывают на согласованность данного пункта с диагностическим концептом всего опросника в целом — с большинством других пунктов. А. Анастази относит рассмотренный показатель к внутренней валидности [2]. Это в какой-то мере оправдано в том случае, если к формулированию пунктов привлекались разные эксперты-психологи. Тот факт, что между ответами на разные пункты найдены корреляции, говорит о конвергентной валидности пунктов, как своего рода микротестов. Но при слишком высоких корреляциях повышение одномоментной надежности (альфа-коэффициент Кронбаха, см. [23]) сочетается с понижением внешней валидности — валидности по внешнему критерию.
При отборе пунктов по внешнему критерию (при построении теста по критерию) описанные простые вычислительные приемы также могут быть применены. Так, например, мы хотим построить или адаптировать опросник мотивации профессиональных достижений к прогнозу успеваемости студентов вуза. Приемлемая стратегия такова. По критерию успеваемости (внешний критерий) отбираются экстремальные группы заведомо успевающих и неуспевающих студентов. Эти две группы составляют выборку, которой предъявляется тест-опросник. Затем по матрице |R| подсчитывается фи-корреляция каждого пункта с попаданием в «высокую» или «низкую» группу по внешнему критерию (Числитель в формуле (2) принимает вид: (ad-bc).). На основе значимых j определяются значения Cj ключа, который затем используется для подсчета по результатам опроса прогностического балла успеваемости. (При более корректной проспективной валидизации момент отбора экстремальных групп производится после проведения самого опроса. Это требует привлечения больших выборок — «с запасом» — для выделения экстремальных групп.) Подобную стратегию (с использованием коэффициента «косинус-пи») применял Ю. М. Орлов при построении опросника «мотивации достижения» [17].
К сожалению, при отборе пунктов по критерию редко выполняется обязательное правило «перекрестной валидизации» [2]: полученные значения jj должны быть проверены на независимой выборке (или на половине целой выборки). Также редко учитывается, к сожалению, что построение теста по критерию — это прагматическая стратегия, которая не обеспечивает психологической однородности измеряемого конструкта: в ключ <С> могут быть включены психологически различные факторы. Тест-опросники, построенные по внешнему критерию, при последующей факторизации, как правило, «распадаются» на ряд независимых факторов. С этой точки зрения, оптимальную тестовую батарею (набор пунктов) по критерию можно получить, применяя анализ множественных корреляций: весовые коэффициенты bj для каждого пункта в уравнении множественной регрессии «очищены» от неоправданного (с точки зрения экономичности) дублирования пунктов, слишком тесно коррелированных друг с другом (об алгоритме см. [1], [26]). Но вычислительная трудоемкость этого метода требует обязательного использования компьютера, уже когда М > 5.
В тех случаях, когда мы хотим не только прогнозировать, но и знать, с помощью каких психологических факторов обеспечивается прогноз, мы должны проводить внутреннюю валидизацию тест-опросника. Описанный алгоритм вычисления j по согласованности с суммарным баллом сохраняет свой смысл.
За период с 1977 по 1984 г. с помощью алгоритмов подобного типа нами проведен анализ пунктов при адаптации и конструировании многих личностных опросников: на измерение тревожности, импульсивности, догматизма, локуса-контроля [12], социальной желательности, склонности к риску, конформности, экстраверсии — интроверсии, по Айзенку, нейротизма, по Айзенку, самоуверенности, завистливости (неопубликованные материалы практикумов по психологии) и др. В учебном пособии [21] предлагается практическое задание для овладения этой процедурой на материале опросника ригидности. Эта же процедура применима для экспериментальной отладки опросниковых шкал установок и отношений, как, например, «удовлетворенность браком» [18], «отношение к стрессу» (неопубликованные материалы ВКНЦ АМН СССР), «отношение к психометрике» (неопубликованные материалы спецсеминара по психометрике).
Укажем пример результатов работы этого алгоритма на материале известного опросника Айзенка. Как известно, этот опросник включает сразу три шкалы, так что для каждого пункта по аналогичному принципу могут быть рассчитаны jik по отношению к попаданию в экстремальную группу по любой из трех шкал (при любом k). Например, вопрос «Часто ли вы действуете под влиянием минутного настроения?» Вместо полюса «экстраверсия» оказался эмпирически отнесенным к полюсу «нейротизм» (испытуемые интерпретируют такое поведение, как выражение «эмоциональной неустойчивости», а не как выражение «самоуверенной импульсивности», свойственной экстравертам). Вопрос «Когда на вас кричат, вы отвечаете тем же?» вместо полюса «экстраверсия» оказался скоррелированным с попаданием в группу «откровенных» («верно» значимо чаще отвечают те, кто набирает меньше очков по шкале «лжи»). Легко видеть, что подобные нюансы смысловой интерпретации вопросов трудно предвидеть, не располагая эмпирическими данными и не проводя их статистической обработки.
Если первый из описанных здесь алгоритмов является традиционным (для мировой психометрики) способом анализа пунктов, пригодным для ручных вычислений, то данный алгоритм — наша авторская разработка. Его преимущества — в еще большей простоте вычислений, более быстрой и более высокой дифференцирующей силе построенной шкалы.
При том же уровне структурированности массива |R| сходимость ключей достигается за счет 3-4 итераций (апробировано на ЭВМ с помощью программ, составленных на языках Бейсик и Фортран А.Г. Шмелевым). Выделенный вектор опять же высоко конгруэнтен (совпадает) с первой или второй главной компонентой одномерного опросника. При факторизации одномерного опросника практически всегда выделяются два фактора: один соответствует измеряемому свойству, другой — социальной желательности ответа; сила второго фактора зависит от диагностической ситуации и уровня подозрительности контингента испытуемых.
Алгоритм раздельного коррелирования ответов, подобно очень сложным алгоритмам латентно-структурного анализа [14], позволяет учитывать при подсчете суммарного балла с разным весом ответы «верно» и «неверно». Формула (1) несколько модифицируется:
(5)
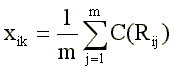
где C(Rij) — ключ, заданный как вторичная переменная, принимающая различные значения в зависимости от того, какое из заранее предусмотренных значений Rij реализовано. Такая модификация позволяет учесть разную силу ответов «верно» и «неверно», их разное диагностическое значение.
На каждом очередном t-м шаге вычислений по ключу <Ct-1ik> и по матрице |R| с помощью формулы (5) подсчитываются суммарные баллы xik. Как и в первом алгоритме, из {x+} выделяются «высокая» и «низкая» группы, и для каждого j-го пункта строится четырехклеточная табличка сопряженности. Ключ для ответа «верно» определяется по формуле:
(6)
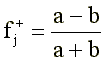
Понятно, что f+j достигает +1, если «верно» отвечают только представители «высокой» группы, и -1, если «верно» отвечают только испытуемые из «низкой» группы. Значимость f+j можно оценить с помощью следующего приближенного соотношения:
(7)
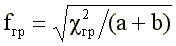
Ключ для ответа «неверно» определяется по формуле:
(8)
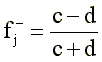
Проверка значимости f-j аналогична с учетом подстановки c+d=a+b.
В компьютерном варианте легко использовать ключи, принимающие всевозможные значения на отрезке [-1, +1], т.е. приравнивать C(Rjk) =fjk. При ручных вычислениях лучше применить целочисленную семибалльную шкалу [-3, +3] с формулой перехода
Cjk = 3 fjk
и округлением до ближайшего целого. Конечно, присваивать пунктам Cjk, отличные от нуля, нужно только в том случае, если fj значимо превышает fгр по модулю.
Практическое испытание данного алгоритма показало, что более высокими fj, как правило, обладают менее социально одобряемые ответы. Например, в опроснике на «склонность к риску» ответ «верно» на вопрос «Я быстро меняю свои интересы и увлечения» получил f+ = 0.60 (Р < 0.05), а ответ «неверно» получил f - = —0.26 (не значимо). Понятно, что устойчивость интересов — более социально одобряемая форма поведения, поэтому более информативен ответ «верно» (контраст между а и b сильнее контраста между c и d. По этим же причинам для вопроса «Я быстрей испытываю скуку, чем большинство людей, делающих то же самое»:
f+ = 0.63, а f - = -0.29.
Информативнее менее «благоразумные» ответы. Например, для пункта «Люди слишком часто безрассудно тратят собственное здоровье, переоценивая его запасы» f+ = -0.14, a f - = +0.75 (значимо на уровне р < 0.05). В опроснике на «тревожность» в вопросе «Я опасаюсь, что о моих недостатках станет известно другим» более информативным оказался ответ «неверно»: f+ = 0.33, a f - = -0.78.
Достоинство алгоритма-2 в том, что он позволяет отыскать значимые связи там, где алгоритм-1 фиксирует только незначимую корреляцию. Читателю можно посоветовать самому убедиться в этом, подставляя в табличку 2 × 2 различные значения частот а, b, с, d. Поэтому алгоритм-2 можно считать более эффективным и при отборе пунктов по внешнему критерию. Не требуя вычисления никаких подкоренных выражений, алгоритм-2 может быть реализован даже в отсутствии карманных калькуляторов и таблиц. (Оценку значимости можно производить по формуле c2эм = f2(a + b) и сравнивать c2эм и c2гр.)
Обсуждение компьютерных алгоритмов нельзя не начать с факторного анализа. Вот уже более полувека факторный анализ остается основным инструментом психометрики индивидуальных различий. Следует различать применение факторного анализа для обоснования теоретических представлений (о структуре личности, структуре интеллекта) и его применения для проверки надежности и валидности методик. Факторный анализ особенно необходим в тех случаях, когда психолог имеет дело с многомерным (многофакторным) тестом и хочет получить «простую» факторную структуру, т. е. такую, в которой максимальное количество пунктов получит значимые нагрузки (значения Сik) только по одному фактору.
Но и в случае одномерных тест-опросников не следует отказываться от возможности применить факторный анализ, если такая возможность имеется (теперь практически все вычислительные центры располагают стандартным пакетом с программой факторного анализа). Факторный анализ позволяет обеспечить дискриминантную валидность тест-опросника по отношению к артефактному фактору социальной желательности значимые Сik присваиваются только тем пунктам, которые имеют незначимые или взаимно уравновешивающие друг друга нагрузки по фактору социальной желательности [24].
Опыт применения факторного анализа к изучению эмпирических корреляции между пунктами таких популярных многофакторных (многошкальных) тестов, как 16PF и MMPI обсуждался нами подробно в другом сообщении ([10], в печ.). Отметим здесь только, что в большинстве практических ситуаций нельзя ожидать, что выборка испытуемых окажется столь репрезентативна что исчерпывающим образом будет воспроизведена вся факторная структура тест-опросника. Наоборот, чаще всего больший вес получают те факторы, которые соответствуют специфичные для данной выборки направлениям межиндивидуальных различии, а те факторы, по которым различия не найдены, вообще исчезают. В практических целях использование факторного анализа пунктов теста эффективно в такой модификации, когда в исходный прямоугольный массив |R| в качестве M+1-гo столбца в дополнение к М пунктам теста добавляется переменная -критерий (или несколько критериев). В этом случае факторный анализ позволяет одновременно увидеть и то, с какими факторами связан критерий, и то, из каких пунктов состоят эти факторы в данном случае.
Если психолог — пользователь компьютера — может заказать программу регрессионного анализа, то у него возникает удобная возможность произвести отбор оптимальной компактной батареи (перечня) пунктов по критерию: значимые регрессионные веса получают только те пункты, которые вносят свой собственный незаменимый вклад в предсказание критерия. В сочетании с факторным анализом в указанной выше модификации регрессионный анализ одновременно обеспечивает психолога пониманием тех психологических факторов (механизмов), благодаря которым достигается (или потенциально может быть достигнуто) предсказание.
Как и факторный анализ, кластерный анализ имеет дело с матрицей М × М всевозможных попарных корреляций между всеми пунктами опросника. Алгоритм иерархической кластеризации по методу среднего расстояния (см. [8]) группирует пункты в кластеры, соответствующие, как правило, факторам, получаемым после варимакс-вращения главных компонент.
Психологам, не располагающим стандартными программами для ЭВМ, полезно познакомиться с книгой Дж. Дэвиса, в которой приводятся листинги (тексты) программ факторного, регрессионного и кластерного анализа на Фортране, а также популярные пояснения к ним, ориентированные на специалистов-предметников [9].
Из комбинаторики давно известно понятие «клики»: это полный подграф, т. е. такое подмножество вершин целого графа, внутри которого все возможные пары вершин связаны ребрами [13]. В своих работах мы предпочитаем употреблять этот термин в транскрипции «клайк», освобожденной от отрицательного оценочного оттенка [19].
Как известно, алгоритмы кластер-анализа решают задачу разбиения объектов (пунктов теста) на множество непересекающихся классов. Это довольно сильное ограничение, которое совершенно не обязательно применять к эмпирическим данным, так как лучшей концептуальной интерпретируемостью могут обладать размытые пересекающиеся категории (группировки объектов). Жесткое разбиение разрывает некоторые группировки, которые лежат на границах между другими группировками. Представляет исследовательский и практический интерес применение в анализе пунктов больших многомерных опросников алгоритма клайк-анализа, позволяющего выделить из матрицы интеркорреляции между пунктами прежде всего клайки, т. е. подмножества пунктов, связанных между собой значимыми парными корреляциями.
Авторами статьи на языке-трансляторе Фортран была написана и практически реализована на ЭВМ ЕС-1055 и ЕС-1060 программа, позволяющая выделять основные клайки из матриц высокой разномерности. Согласно этой программе на первом этапе на основании матрицы интеркорреляций между пунктами строились эмпирическая гистограмма частотного распределения всех подсчитанных коэффициентов корреляции. (Нами использовался линейный коэффициент корреляции Пирсона с предварительной нормализацией коррелируемых параметров-пунктов.) Как и следовало ожидать, для разнородных многомерных опросников такое распределение оказалось очень близким по форме к нормальной кривой. На основании этого распределения назначался эмпирически обоснованный порог значимой корреляции, отсекающий по правилу «трех сигм» 0.1% от всех корреляций. Относительно этого порога компьютер затем производил перебор всех клайков. При этом новый пункт зачислялся в клайк в том случае, если модуль его корреляций со всеми остальными пунктами из клайка был не ниже порога G.
Программа была применена к массиву данных, полученных от 380 испытуемых по тест-опроснику Кэттела 16PF (форма В). Для этих данных по правилу «трех сигм» порог заведомо неслучайной значимой линейной корреляции оказался равным 0.18.
Для выделения наиболее существенных клайков в памяти ЭВМ резервировался массив - каталог клайков. Самый первый клайк записывался в этот массив сразу. Второй клайк сравнивался с первым по следующему коэффициенту сходства:
(9)
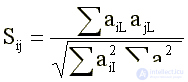
где: Sij — коэффициент сходства (косинус) векторов, описывающих i-й и j-й клайки; aiL — L-й элемент i-го вектора-клайка.
Первоначально aiL может принимать только одно из трех значений {-1, 0, +1), где 0 обозначает отсутствие данного L-го пункта в данном i-м клайке, +1 — превышающую nopoг G положительную корреляцию между L-м и первым ненулевым элементом клайка, -1 — превышающую по модулю порог G отрицательную корреляцию между i-м и первым ненулевым элементом клайка.
С каждым новым выделенным клайком программа осуществляла следующие операции. Новый клайк — кандидат — сравнивался по порядку (начиная с первого) со всеми клайками, включенными в каталог. Если ни с одним клайком из каталога Sij не превышало порога слияния Р, то клайк либо записывался в каталог на место, соответствующее численности в нем ненулевых элементов, либо, если он был меньше по численности, чем самый малочисленный клайк в каталоге, он вообще не запоминался ЭВМ. Как только с каким-то из старых клайков сходство Sij превышало порог Р, производилось слияние векторов-клайков по формуле среднего взвешенного:
(10)
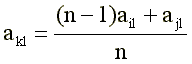
где: akl — элемент нового k-го «усредненного» клайка, возникшего в результате слияния i-го и j-го клайков;
n-1 — количество клайков, уже «слитых» в старом i-м клайке;
ajl — элемент нового клайка.
Понятно, что, как только программа начинает осуществлять слияния, в каталоге появляются клайки, элементы которых ail принимают градуальные значения на отрезке [-1,+1]. (Как и в факторном анализе, вес клайка определяется формулой Wj=Sa2iL) Эмпирически за счет интерпретации результатов, полученных с разными порогами Р, нами был подобран порог с оптимальным значением р=0.2 (при более высоких значениях Р в каталоге оказывается слишком много клайков, сходных между собой и по содержанию представляющих вариации основного фактора, каким для 16PF, по нашим результатам, оказался фактор «тревожность» (см.[10], в печ.).
Понятно, что введение в программу поиска клайков «слияний» существенно модифицировало алгоритм по сравнению с тем его вариантом, который был использован ранее при анализе матриц небольших размеров (например, 17×17 [19]). Применение подобной модификации является неизбежностью по отношению к рыхлым корреляционным матрицам высокой размерности (в несколько сотен элементов). С помощью слияний удается точнее описать основные области скопления пунктов, скоррелированных между собой.
Объем данного сообщения не позволяет подробно остановиться на интерпретации выделенных нами клайков при анализе пунктов 16PF. Укажем только, что их специфика по сравнению с факторами состоит в том, что они практически всегда сохраняют содержательные связи в ведущими, главными по весу факторами. Если при факторном анализе содержание главных факторов вычерпывается из корреляционной матрицы за счет вычитания репродуктивной матрицы (см. популярное описание этой операции в [16]), то при клайк-анализе такого устранения ведущих факторов не происходит. Получаемый каталог клайков близок к косоугольному факторному решению, но, очевидно, превосходит его по емкости, так как вбирает в себя корреляционную информацию, выходящую за рамки ортогонального базиса главных факторов.
По содержанию выделенные клайки обладают определенной концептуальной новизной. Ведущие характеристики индивидуальности (вторичные факторы 16 PF — тревожность, эксвия — инвия, конформизм, чувствительность и др.) предстают в клайках в своих тонко нюансированных вариациях, Например, диагностический конструкт «тревожность» специфицируется в виде многочисленных вариаций, связанных с разнообразием проявлений тревожности в различных предметных областях и ситуациях: это «социальная тревожность» (в общении с людьми), «ипохондрическая тревожность» (по отношению к своему соматическому состоянию), «тревожность достижения» (по отношению к риску успеха или неуспеха в деятельности) и т. п.
Изучая эффективность разработанного нами алгоритма клайк-аиализа, мы проводили специальное сравнение результатов кластер-анализа и клайк-анализа в применении к одному и тому же массиву ответов 380 испытуемых на тест-опросник 16PF (форма В). Выявлено значимое совпадение наиболее крупных кластеров, полученных по методу среднего расстояния, и наиболее крупных клайков. (Совпадение измерялось с помощью коэффициента конгруэтности (9), значимость оценивалась по хи-квадрату) Но результаты клайк-анализа оказались полнее: среди клайков можно найти практически все кластеры, но не все клайки описаны в виде кластеров. Немаловажно также отметить, что клайки обладают более высокой статистической устойчивостью по отношению к выборке: при расщеплении выборки пополам клайк-решение оказывалось более устойчивым, чем кластер-решение. Таким образом, относительно устойчивые клайки можно получать уже на выборках небольшого объема (от 100 до 200 испытуемых).
7. Анализ блоков
Как остроумно замечает Дж. Рэск (1973), с формальной, математической точки зрения, нет разницы между двумя входами прямоугольной матрицы «испытуемые×пункты». Все методы анализа, которые применимы к пунктам, также применимы и к анализу взаимоотношений между испытуемыми. В последнем случае попарные корреляции рассчитываются между строками матрицы |R|. Для факторного анализа такой подход давно известен под названием Р-варианта (в отличие от Q-варианта — анализа вопросов).
Удобно представить |R| как граф, отображающий одно множество вершин Q — испытуемых — в другое множество Q — вопросов (пунктов). Единица в клетке матрицы означает наличие ребра между вершинами Рi и qj
Назовем блоком в таком графе пару подмножеств P и Q таких, что для всякого Рi принадлежащего P, образ qj из Qимеет прообразом все подмножество P, т. е. из каждой вершины Р имеется ребро ко всякой вершине Q. Если соответствующие строки P и столбцы Q в матрице |R| сгруппировать рядом, то получится прямоугольник (блок) из клеток, содержащих только единицы (табл. 2).
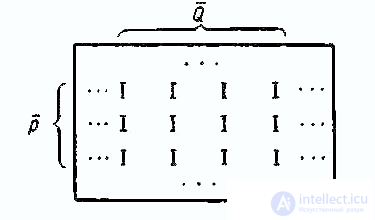
Как известно из комбинаторики (см. [13]), для отыскания полного подграфа для некоторой вершины Рi, следует транспонированную вектор-строку <Ri> умножить справа на матрицу |R| по правилам матричного умножения. В данном случае это будет означать поиск для данного испытуемого рi таких испытуемых из которых ответили «верно» на те же самые вопросы Q, что и рi. Точно так же для вопроса qi, можно найти все вопросы Q, на которые ответили «верно» те же самые испытуемые, но в данном случае транспонированный вектор-столбец <Q.q> нужно умножить слева на матрицу |R|.
Эти простые комбинаторные соображения поясняют основную идею разработанного нами алгоритма анализа блоков. (Ответы «неверно» кодируются в |R| значениями «-1».) Настоящий алгоритм включает N итерационных циклов (по числу N испытуемых или строк матрицы |R|). В ходе очередного i-цикла i-я транспонированная (превращенная в столбец) строка матрицы <R0i>=<Q0> умножается справа на матрицу |R|. Получаемая в результате строка <р'> нормализуется (делением на максимум из <р'>) и умножается слева на матрицу |R|. Новый вектор-столбец <Q'> умножается справа на |R|, и так продолжается до тех пор, пока и <Qt+1>, и <Qt>, а также <pt+1> и <pt> не стабилизируются с пренебрежимой погрешностью. В результате для каждого i-го испытуемого отыскивается приближенный блок, в который и испытуемые, и пункты входят с разными весовыми коэффициентами (аналогичными факторным нагрузкам в факторном анализе).
По написанной нами на языке Бейсик программе проводилась практическая апробация описанного алгоритма на мини-ЭВМ и сравнение его результатов с результатами обычного алгоритма по анализу главных компонент. Получено значимое совпадение: наиболее весомые блоки хорошо воспроизводили главные компоненты для пунктов. Преимущество блочного алгоритма в том, что он одновременно дает факторные веса для испытуемых (оценивается вес, с которым испытуемый вошел в данный блок), а также в том, что он гораздо быстрее и эффективнее работает по отношению к большим матрицам, содержащим много мелких блоков (многофакторные тест-опросники). Практическое удобство блока в том, что он одновременно описывает и диагностический конструкт (в виде набора пунктов с весовыми коэффициентами), и ту подвыборку испытуемых (определенного пола, возраста, специальности), на которой этот конструкт воспроизвелся.
Мы полагаем, что алгоритмам подобного типа принадлежит будущее в анализе централизованных компьютерных банков психодиагностической информации, собранных по некоторым базовым перечням вопросов в различных областях практической психологии.
Широкие перспективы открываются перед психологами с введением в будущем централизованной психодиагностической службы. В этом случае психолог-практик выписывает из методического центра так называемый базовый перечень вопросов определенной направленности (например, характерологический базовый перечень, видимо, будет включать около 1000 вопросов). В своем выборочном методическом исследовании психолог-практик собирает ответы своих испытуемых на все вопросы базового перечня и пересылает критериальную информацию о выборке, а также протоколы с ответами в методический центр. Центр, располагающий мощной вычислительной базой, производит компьютерный анализ присланного массива, дополняет свой банк данных и высылает психологу-практику результаты анализа, на основе которых практик отбирает компактный перечень вопросов (в 30-100 пунктов) для практического применения в целях массовой экспресс-диагностики.
Литература
Вопросы психологии, № 4, 1985. — С.126-134.
Представленные результаты и исследования подтверждают, что применение искусственного интеллекта в области анализ пунктов при конструировании имеет потенциал для революции в различных связанных с данной темой сферах. Надеюсь, что теперь ты понял что такое анализ пунктов при конструировании, применении тест-опросников, ручные, компьютерные алгоритмы и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Математические методы в психологии
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.
Комментарии
Оставить комментарий
Математические методы в психологии
Термины: Математические методы в психологии