Лекция
Это продолжение увлекательной статьи про конструирование психодиагностических тестов.
...
проверяют гипотезу Hо о равенстве единице последних р-n собственных чисел. Процедура такой проверки изложена, например, в /Енюков И. С., 1986/. Там же достаточно подробно для практического применения рассматриваются некоторые другие аспекты дискриминантного анализа.
Рассмотренные выше методы определения дискриминантных весовых векторов приводят к оптимальным результатам при соблюдении достаточно жестких условий нормальности распределений объектов внутри классов и равенства ковариационных матриц Si. В практике психодиагностических исследований эти условия, как правило. не выполняются. Но отклонения реальных распределений объектов от нормального и различия ковариационных матриц, которые в отдельных случаях хорошо теоретически изучены, не являются главными причинами ограниченного применения классических формул дискриминантного анализа. Здесь, как и при построении регрессионных психодиагностических моделей, качественный и дихотомический характер признаков, их большое количество и наличие групп связанных признаков обусловливают применение «грубых» алгоритмов нахождения дискриминантных функций. Данные алгоритмы также в основном сводятся к отбору информативных признаков с помощью эвристических процедур k — лучших признаков и последовательного увеличения и уменьшения группы признаков. Отличие указанных процедур заключается в иных критериях оптимальности признаков, чем при построении регрессионных моделей. Такие критерии в дискриминантном анализе формулируются относительно средней вероятности ошибочной классификации и часто мерой информативности признака при его добавлении в группу признаков или исключения из группы, не зависящей от объема группы, служит /Енюков И. С., 1986/
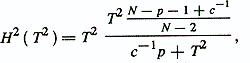
где Т2 — расстояние Махаланобиса между двумя диагностируемыми классами ω1 и ω2; с-1=N1-1+N2-1, В целом можно заключить, что для двух классов методы дискриминантного анализа во многом аналогичны методам регрессионного анализа. Расширением по отношению к регрессионной схеме в дискриминантном анализе служит представление о разделяющих границах диагностируемых классов, которое может приводить к более изощренным формам этих границ и процедурам их нахождения.
Публикации, посвященные типологическому подходу, обычно рассматривают его в рамках психопрогностики (например, Ямпольский Л. Т., 1986; Кулагин Б. В. и др., 1989). Известна точка зрения, которая разделяет психопрогностику и психодиагностику /Забродин Ю. М., 1984/. В то же время с позиции формального математического аппарата психопрогностика и психодиагностика имеют много общего. И в том и в другом случае испытуемый описывается набором чисел (р-мерным вектором признаков), точно так же каждому испытуемому ставится в соответствие значение некоторого критериального показателя z, и задача состоит в том, чтобы построить математическую модель, имеющую максимальную корреляцию с z или дискриминирующую испытуемых подобно z. Конечно, чем продолжительнее временной интервал, на который распространяется прогноз, тем с более серьезными трудностями сталкивается исследователь при определении критериального показателя и тем сложнее может оказаться структура модели у=у(х). Но, так или иначе, в данном изложении не будет проводиться граница между понятиями психопрогностики и психодиагностики, а внимание будет сконцентрировано большей частью на феноменологии процедуры обработки экспериментальных данных, получившей название типологического подхода.
Целесообразность применения типологического подхода обусловлена недостаточной эффективностью линейных диагностических моделей. Так, Л. Т. Ямпольский /1986/ отмечает, что это простейший способ интеграции индивидуальных факторов в реальное поведение и что психологические факторы (исходные признаки в диагностической модели. — В. Д.) могут взаимодействовать более сложным образом. В /Кулагин Б. В. и др., 1989/ рассматриваются проблемы построения диагностических моделей в целях профотбора и указывается, что, как правило, совокупность обследуемых кандидатов идеализированно считается однородной выборкой из некоторой генеральной совокупности и модель прогнозирования успешности профессиональной деятельности оказывается усредненной для всех испытуемых, включенных в обследование. Это приводит к снижению доли совпадения прогноза с реальной профессиональной успешностью, которая в данном случае практически никогда не превышает 70-80%. Далее рассуждения приведенных выше авторов хотя и несколько различаются, но приводят к одинаковым выводам. Эти рассуждения примерно таковы.
В условиях неоднородности обучающей выборки линейные диагностические модели должны смениться нелинейными. Однако решение задачи построения нелинейных моделей затруднено из-за отсутствия априорных сведений о виде искомых функций у=у(х). В таких случаях эффективный результат может быть достигнут с помощью методов кусочно-линейной аппроксимации у=у(х). В свою очередь, успешность кусочно-линейной аппроксимации зависит от того, насколько хорошо удается разбить испытуемых на однородные группы, для каждой из которых в отдельности строится собственная линейная диагностическая модель. Это можно рассматривать как индивидуализацию диагностического правила, которая заключается в выборе одной из нескольких функций у=у(х) для каждого испытуемого с учетом его принадлежности той или иной группе.
Таким образом, процедура построения диагностической модели состоит из двух этапов. На первом этапе производится разбиение всего множества испытуемых X={хi}, i=1,N на М однородных групп Gj(X=UGj), j= 1,MНа втором этапе для каждой группы Gj вырабатывается линейное диагностическое правило yj=yj(х) с помощью рассмотренных выше методов линейного регрессионного или дискриминантного анализа. Соответственно процедура собственно диагностики также осуществляется в два приема. Сначала определяется принадлежность испытуемого хi к одной из ранее выделенных групп Gj и затем для диагностики хi применяется требуемая диагностическая модель yj=yj(х).
«Слабое звено» данного подхода заключается в трудно формализуемом и нечетком определении понятия однородности группы объектов. Как известно, задаче разбиения объектов на однородные группы уделяется значительное место в общей проблематике анализа данных. Методы решения этой задачи носят разные названия: автоматическая классификация, распознавание без учителя, таксономия, кластерный анализ, расщепление смеси и т. д., но имеют одинаковую сущность. Все они в явной или неявной форме опираются на категорию близости (различия) объектов в пространстве признаков. Для решения задачи выделения однородных групп объектов исследования необходимо дать ответы на три основных вопроса:
а) какие признаки будут считаться существенными для описания объектов?
б) какая мера будет применяться для измерения близости объектов в пространстве признаков?
в) какой будет выбран критерий качества разбиения объектов на однородные группы?
На каждый из приведенных вопросов существует много вариантов ответов, и в зависимости от выбранного ответа можно получить совершенно различные разбиения объектов на однородные группы. Поэтому решение конкретной задачи выделения однородных групп объектов всегда не лишено субъективной оценки исследователя. В следующей главе будут более подробно рассмотрены возможные алгоритмы разбиения множества объектов на группы в рамках общей проблемы анализа многомерной структуры экспериментальных данных. Здесь же ограничимся рекомендациями, изложенными в /Ямпольский Л. Т., 1986; Кулагин Б. В. и др., 1989/, полезность которых подтверждена значимыми практическими результатами.
В работе /Кулагин Б. В. и др., 1989/ рекомендуется для группирования испытуемых отбирать признаки, хорошо дискриминирующие массив исходных данных и слабо коррелирующие между собой. Кроме того, набор этих признаков должен быть минимизирован. Л. Т. Ямпольский /1986/ предлагает выделять группировки объектов в пространстве общих факторов, полученных методами факторного анализа исходного пространства признаков. И в той и в другой работе важное, если не решающее, значение придается психологическому осмыслению выделяемых группировок испытуемых. Возможность четкой интерпретации полученных группировок как определенных психологических типов служит достаточно веским доводом в пользу не случайного разбиения испытуемых на группы, которое могло бы произойти под действием какого-либо иррелевантного решаемой диагностической задаче фактора (отсюда, собственно, и проистекает название «типологический подход»).
Оценка качества диагностической модели, полученной в результате применения типологического подхода, обычно осуществляется путем сравнения с обычной линейной диагностической моделью, построенной без разделения объектов обучающей выборки на группы. Например, используется следующий показатель
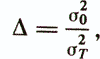
где σ20 — остаточная дисперсия обычной линейной регрессионной модели, а σ2T вычисляется по формуле
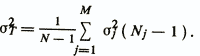
Здесь σ2j — остаточная дисперсия регрессионной диагностической модели уj= уj(х) для группировки Gj, определяемая из выражения
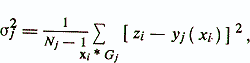
где N — общее количество испытуемых;
Nj — число испытуемых в группировке Gj;
М — число группировок.
Также для проверки гипотезы об идентичности обычной линейной регрессионной модели и набора регрессионных уравнений уj=yj(х) может быть использован F-критерий Фишера /Елисеева И. И. и др., 1977/
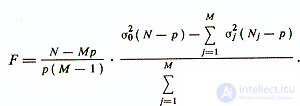
Эффективность типологического подхода по сугубо формальным соображениям не может быть ниже эффективности обычной линейной диагностической модели, которую можно рассматривать как вырожденный случай кусочно-линейной модели. В то же время кроме практического выигрыша типологический подход имеет определенную теоретическую ценность — он раскрывает взаимосвязь диагностики психологических черт, как группировок признаков, и психологических типов, как группировок испытуемых. Идеалом типологического подхода, замечает Б. В. Кулагин /1984/, является разработка такого метода, который позволит для каждой отдельной индивидуальности выбирать оптимальную диагностическую модель.
Результат тестирования испытуемого хi, вычисленный с помощью диагностической модели yi=у(хi), обычно называют первичной тестовой оценкой или, часто, «сырым» баллом. Для лучшего понимания этого результата в ряду других результатов производится его дальнейшее искусственное преобразование, основанное на анализе эмпирического распределения тестовых оценок в репрезентативной выборке испытуемых. Процедура такого преобразования носит название стандартизации.
Известно три основных вида стандартизации первичных тестовых оценок: 1) приведение к нормальному виду; 2) приведение к стандартной форме; 3) квантильная стандартизация /Мельников В. М. и др., 1985/.
Существуют два главных обстоятельства, которыми объясняется целесообразность искусственного приведения распределения первичных тестовых оценок к нормальному виду. Во-первых, значительная часть процедур классической математической статистики разработана для случайных величин с гауссовым нормальным распределением. И, во-вторых, это дает возможность описывать диагностические нормы в компактной форме.
Для определения способа преобразования у обычно рассматриваются гистограммы распределения первичных тестовых оценок. Они позволяют выявлять лево- и правостороннюю асимметрию, положительный или отрицательный эксцесс и другие отклонения от нормальности. В психологических исследованиях нередко встречаются логарифмические нормальные распределения «сырых» баллов. В этом случае приближение распределения к гауссовой форме достигается путем логарифмирования у. Напротив, для нормализации кривых распределений с пологой левой ветвью и крутой правой нередко применяются тригонометрические и степенные преобразования «сырых» баллов.
Применение компьютеров позволяет автоматизировать подбор и подгонку требуемого преобразования первичных тестовых оценок из заданного класса аналитических функций. Также компьютеры дают возможность достаточно просто реализовывать трудоемкую в ручном исполнении процедуру перехода к нормально распределенным оценкам путем новой оцифровки выходного тестового показателя. Эта процедура обычно одновременно используется для приведения тестовых оценок к стандартной форме и будет подробно рассмотрена ниже.
Под стандартной формой понимают линейное преобразование нормальной (или искусственно нормализованной) тестовой оценки следующего вида
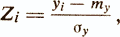
где Zi — стандартная тестовая оценка i-го испытуемого;
yi — нормальная оценка i-го испытуемого;
ту и σу — среднее арифметическое значение и среднеквадратическое отклонение у.
Стандартные Z-оценки распределены по нормальному закону с нулевым средним и единичной дисперсией. Это полезно для проведения сравнительного анализа стандартных оценок различных психодиагностических показателей. Но так как Z-оценки могут принимать дробные и отрицательные значения, что неудобно для восприятия, на практике чаще используются взвешенные стандартные оценки (Vi)
Vi=a+bZi,
где а и b — константы центрирования и пропорциональности соответственно. Параметр а имеет смысл в данном случае среднего арифметического значения взвешенной стандартной оценки V, a b интерпретируется как среднеквадратическое отклонение V.
В психодиагностике наиболее популярны следующие значения констант центрирования и пропорциональности (Общая психодиагностика, 1987):
1. Т-шкала Мак-Колла — а=50, b=10.
2. Шкала IQ — а=100, b=15.
3. Шкала «стэнайнов» (целочисленные значения от 1 до 9 — стандартная девятка) — а=5.0, b=2.
4. Шкала «стэнов» (стандартная десятка) — а=5.5, b=2. Как указывалось ранее, компьютеры позволяют достаточно просто осуществить нелинейную нормализацию сырых тестовых оценок у и перейти к взвешенным стандартным оценкам в любой из приведенных выше шкал. Процедура такого перехода заключается в новой оцифровке у и может выглядеть, например, следующим образом. Для любой отметки выбранной стандартной шкалы V известен ее процентильный ранг PR(Vk)=С. Он равен площади под кривой теоретического нормального распределения со средним а и среднеквадратическим отклонением b, вычисленной для значений V
Примером квантильной стандартизации служит процентильная стандартизация, когда отметке «сырой» шкалы у присваивается новое значение ее процентильного ранга PR(у). Квантиль является общим понятием, частными случаями которого могут быть, например, кроме процентилей, квартили, квинтели и децили. Три квартильные отметки (Q1, Q2, Q3) разбивают эмпирическое распределение тестовых оценок на 4 части (кварты) таким образом, что 25% испытуемых располагаются ниже Q1, 50% — ниже Q2 и 75% — ниже Q3. Четыре квинтеля (K1, К2, Кз, К4) делят выборку аналогичным образом на 5 частей с шагом 20% и девять децилей (D1, ..., D9) разбивают выборку на десять частей с шагом 10%.
Номер соответствующего квантиля используется в качестве новой преобразованной тестовой оценки. Квантильная шкала отличается тем, что ее построение никак не связано с видом распределения первичных тестовых оценок, которое может быть нормальным или иметь любую другую форму. Единственным условием для ее построения является возможность ранжирования испытуемых по величине у. Квантильные ранги имеют прямоугольное распределение, то есть в каждом интервале квантильнои шкалы содержится одинаковая доля обследованных лиц /Кулагин Б. В., 1984/. Стандартизация тестовых оценок путем их перевода в квантильную шкалу стирает различия в особенностях распределения психодиагностических показателей, так как сводит любое распределение к прямоугольному. Поэтому с позиции теории измерений квантильные шкалы относятся к шкалам порядка: они дают информацию, у кого из испытуемых сильнее выражено тестируемое свойство, но ничего не позволяют сказать о том, насколько или во сколько раз сильнее.
Построенная диагностическая модель может считаться психодиагностическим тестом только после прохождения всесторонних испытаний на предмет оценки психометрических свойств. Основными психометрическими свойствами психодиагностических методик, кроме стандартизированности, являются надежность и валидность /Анастази А., 1982; Гайда В. К. и др., 1982; Гильбух Ю. 3., 1982; 1986; Кулагин Б. В., 1984; Общая психодиагностика, 1987; Бурлачук Л. Ф. и др., 1989/.
Надежность теста — это характеристика методики, отражающая точность психодиагностических измерений, а также устойчивость результатов теста к действию посторонних случайных факторов /Бурлачук Л. Ф. и др., 1989/.
Результат психологического исследования обычно подвержен влиянию большого количества неучитываемых факторов (например, эмоциональное состояние и утомление, если они не входят в круг исследуемых характеристик, освещенность, температура и другие особенности помещения, в котором проводится тестирование, уровень мотивированности испытуемых и т. д.). Поэтому любая эмпирически полученная оценка по тесту yi представляется как сумма истинной оценки у¥ и ошибки измерения ε: yi=у¥ + е . В целях анализа надежности вводится понятие «параллельных тестов», которыми называются тесты, в одинаковой мере измеряющие данное свойство посредством одних и тех же действий и операций /Кулагин Б. В., 1984/. Это понятие является обобщенным, так как параллельными тестами могут быть и параллельные формы и повторные обследования испытуемых одной и той же методикой. Если принять допущения, что измеряемые у индивидуумов свойства мало изменяются во времени, а ошибки полностью случайны и несистематичны, то параллельные тесты дают результаты с одинаковыми средними значениями, среднеквадратическими отклонениями, интеркорреляциями и корреляциями с другими переменными.
Коэффициент надежности Ryy определяется как корреляция параллельных тестов, которая, в свою очередь, равна отношению
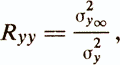
где σ2у¥ — дисперсия истинной оценки, а σ2у — дисперсия эмпирической оценки.
Корреляция параллельных тестов с какой-либо другой переменной z определяется соотношением
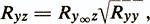
где Ry¥z — корреляция истинных оценок i>у¥ с переменной z. Эта формула показывает, что корреляция теста с любой внешней переменной ограничивается коэффициентом надежности. Например, если корреляция истинной оценки у¥ с переменной z (Ry¥z) равна 1,0, а коэффициент надежности (Ryy) равен 0,70, то эмпирическая корреляция (Ryz) составит 0,84.
Коэффициент надежности связан со стандартной ошибкой измерения (σε — среднеквадратическое отклонение ошибок измерения ε)
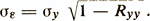
Отсюда следует, что при увеличении коэффициента надежности Ryy уменьшается ошибка σε.
Корреляция эмпирических и истинных оценок Ryy¥ называется индексом надежности и определяется соотношением
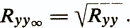
Существует три основных подхода к оценке надежности тестов, которые различаются факторами, принимаемыми за ошибки измерения.
Тест-ретест надежность. Коэффициент надежности (Ryy) измеряется с помощью повторного обследования одних и тех же испытуемых через определенное время и равен коэффициенту корреляции результатов двух тестирований. Ошибки измерения в данном случае обусловлены различиями в состоянии испытуемых, организации и условиях повторных обследований, запоминанием ответов, приобретением навыков работы с тестом и др. Тест-ретест надежность называют также надежность — устойчивость.
Надежность параллельных форм теста. Коэффициент надежности равен корреляции параллельных форм теста. Ошибки измерения в данном случае, кроме вышеуказанных факторов, связаны с различиями в характере действий и операций, присущих параллельным формам теста. Высокое значение коэффициента корреляции, помимо высокой надежности результатов сравниваемых тестов, указывает на эквивалентность содержания этих тестов. Поэтому коэффициент надежности для параллельных форм теста носит еще одно название — эквивалентная надежность.
Надежность как гомогенность тестов. В данном случае надежность оценивается путем вычисления интеркорреляций частей или элементов методики, рассматриваемых как отдельные параллельные тесты. Такой подход справедлив для оценки тестов, при построении которых использовалась диагностическая модель, основанная на критерии автоинформативности системы исходных признаков (на принципе внутренней согласованности тестовых заданий). Наиболее распространена процедура расщепления теста на две части: в одну входят, например, результаты четных заданий, а в другую — нечетных. Для определения надежности целого теста применяют формулу Спирмена — Брауна:
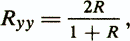
где R — корреляция между половинами теста.
С учетом того, что тест, построенный по принципу внутренней согласованности заданий, можно расщеплять на части разными способами, в психометрике для оценки надежности не редко используется коэффициент Кронбаха
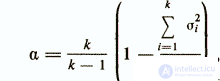
где а — обозначение коэффициента Кронбаха;
k — число заданий теста;
σ2i — дисперсия i-ro пункта теста;
σ2у —дисперсия целого теста.
Если ответы на каждый пункт теста являются дихотомическими переменными, то применяется аналогичная коэффициенту Кронбаха формула Кьюдера — Ричардсона
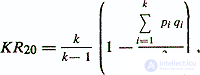
где KR20 — традиционное обозначение данного коэффициента надежности;
pi — доля 1-го варианта ответа на i-й вопрос;
qi = ( 1 — pi) — доля второго варианта ответа на i-и вопрос.
Известны другие коэффициенты надежности для гомогенных тестов. Большинство критериев, положенных в основу этих коэффициентов, опираются на тот факт, что матрица интеркорреляций заданий надежного теста имеет ранг, близкий к единице. Например, применяется коэффициент, получивший название тета-надежности теста /Общая психодиагностика, 1987/:
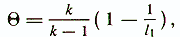
где k — количество пунктов теста.
l1 — наибольшее собственное число, соответствующее 1-й главной компоненте матрицы интеркорреляций пунктов теста.
Приведенные выше формулы могут использоваться только тогда, когда каждый испытуемый работает со всеми элементами теста. Это относится к методикам, которые не имеют ограничений во времени. Независимо от выполнения данного условия часто производится оценка надежности отдельных пунктов психодиагностического теста.
Надежность отдельных пунктов теста. Ретестовая надежность теста в целом зависит от устойчивости ответов испытуемых на отдельные пункты теста. Для проверки этой устойчивости вычисляется корреляция ответов испытуемых на проверяемый пункт с ответами при повторном тестировании. Для дихотомических пунктов обычно используется коэффициент φ и пункт считается недостаточно устойчивым, если φ< 0,5 .
Также нередко производится проверка так называемой дискриминативности заданий теста /Бурлачук Л. Ф. и др., 1989/, под которой понимается способность отдельных пунктов дифференцировать обследуемых относительно «максимального» или «минимального» результата теста в целом. Процедура проверки надежности пунктов направлена на повышение внутренней согласованности теста и соответствует описанному ранее методу контрастных групп. В качестве меры надежности пункта может использоваться коэффициент φ. Кроме того, часто применяется точечный бисериальный коэффициент корреляции rрв, который в данном случае называют коэффициентом (индексом) дискриминации.
В отличие от надежности валидность — мера соответствия тестовых оценок представлениям о сущности свойств или их роли в той или иной деятельности /Кулагин Б. В., 1984/. Выделяют три основных вида валидности — содержательную, эмпирическую (критериальную) и конструктную (концептуальную).
Содержательная валидность характеризует степень репрезентативности содержания заданий теста измеряемой области психических свойств /Бурлачук Л. Ф. и др., 1989/. Традиционно эта характеристика имеет наибольшее значение для тестов, исследующих деятельность, близкую или совпадающей с реальной (чаще всего учебной или профессиональной). Так как данная деятельность нередко складывается из разнородных факторов (проявления способностей личности, комплекс необходимых знаний и навыков, специфические способности), то подбор заданий, охватывающих главные аспекты изучаемого феномена, является одной из важнейших задач формирования адекватной модели тестируемой деятельности. Валидность по содержанию закладывается в тест уже при подборе заданий будущей методики. Этот вопрос рассмотрен выше, когда речь шла о формировании исходного множества диагностических признаков. Заключение о содержательной валидности, как правило, производится экспертами, которые выносят суждение о том, насколько охватывает данный тест декларируемые свойства и явления.
Следует отличать содержательную валидность от очевидной, лицевой, внешней валидности, которая является таковой с точки зрения испытуемого. Очевидная валидность означает то впечатление о предмете измерения, которое формируется у испытуемых при знакомстве с инструкцией и материалом теста. Она тоже играет заметную роль в тестировании, поскольку в первую очередь определяет отношение испытуемых к обследованию. Поэтому очевидную валидность иногда называют доверительной валидностью. В некоторых случаях содержательная и внешняя валидность совпадают, в других —очевидная валидность используется для маскировки истинных целей исследования.
Эмпирическая валидность — совокупность характеристик валидности теста, полученных с помощью сравнительного статистического анализа. Показатель эмпирической валидности выражается количественной мерой статистической связи между результатами тестирования и внешними по отношению к ним критериям оценки диагностируемого свойства. В качестве таких критериев могут выступать уже рассмотренные ранее экспертные оценки, экспериментальные и «жизненные» критерии. Эмпирическая валидность чаще всего выражается коэффициентом корреляции результатов тестирования у с критериальным показателем z. Известно, что корреляция двух переменных зависит от их надежности:
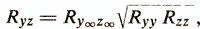
где Ry¥z¥ — корреляция истинных значений теста и критерия; Ryy — надежность теста; Rzz — надежность критерия. Эта формула показывает, что максимально возможная валидность ограничена величинами надежности теста и внешнего критерия.
Эмпирическая валидность может быть представлена другими показателями. Например, если внешний критерий характеризуется дихотомической переменной, в качестве показателя эмпирической валидности способен выступать процент лиц, оценки которых находятся в зоне перекрытия распределения показателей по тесту в дихотомических группах /Dunnette M. D., 1966/. Также распространенным способом представления статистической связи результатов тестирования служит табличная форма, в которой интервалы тестовых баллов сопоставлены с вероятностями принадлежности испытуемых различным диагностическим классам.
При оценке эмпирической валидности тестов необходимо устанавливать ее по крайней мере в 2 группах, так как корреляция теста и критерия может быть обусловлена специфическими для данной выборки факторами и не иметь общего значения /Кулагин Б. В., 1984/. Особенно важно, чтобы валидность теста определялась на выборке испытуемых, отличной от той, с помощью которой производился отбор заданий /Анастази А., 1982/. Для выполнения этого условия можно, например, разделить имеющийся экспериментальный материал пополам. В то же время предпочтительнее проведение нескольких исследований с последующим анализом и обобщением полученных данных.
Конструктная валидность — это валидность теста по отношению к психологическому концепту — научному понятию (или их совокупности) об измеряемом психическом свойстве (состоянии). Она выражает степень обоснованности индивидуальных различий, обнаруживаемых тестом, с позиций современного теоретического знания. Распространенным приемом определения конструктной валидности теста является его соотнесение с известными методиками, отражающими другие конструкты, предположительно как связанные, так и не зависимые от данного. При этом делается попытка априорно предсказать наличие или отсутствие связи между ними. Тесты, которые по предположению высоко коррелируют с валидизируемым тестом, называются конвергирующими, а не коррелирующие — дискриминантными. Концептуальная валидность может считаться удовлетворительной, если коэффициенты корреляции валидизируемого теста с группой конвергирующих тестов статистически значимо выше коэффициентов корреляции с группой дискриминантных тестов.. Подтверждение совокупности ожидаемых связей составляет важный круг сведений конструктной валидности и в зарубежной литературе носит также название «предполагаемой валидности».
В заключение главы представим в сжатом виде все этапы конструирования
продолжение следует...
Часть 1 Конструирование психодиагностических тестов: традиционные математические модели и алгоритмы
Часть 2 2. Методы, основанные на критерии автоинформативности системы признаков - Конструирование
Часть 3 Дискриминантный анализ - Конструирование психодиагностических тестов: традиционные математические модели и
Часть 4 Типологический подход - Конструирование психодиагностических тестов: традиционные математические модели и
Часть 5 - Конструирование психодиагностических тестов: традиционные математические модели и алгоритмы
Часть 6 - Конструирование психодиагностических тестов: традиционные математические модели и алгоритмы
Комментарии
Оставить комментарий
Математические методы в психологии
Термины: Математические методы в психологии