Лекция
Это окончание невероятной информации про архитектура нейронных сетей.
...
— время.
Например:
Есть футболист, который бегает по полю;
Это интересно!
Чуть более детально, как мультмодальное обучение выглядит внутри.
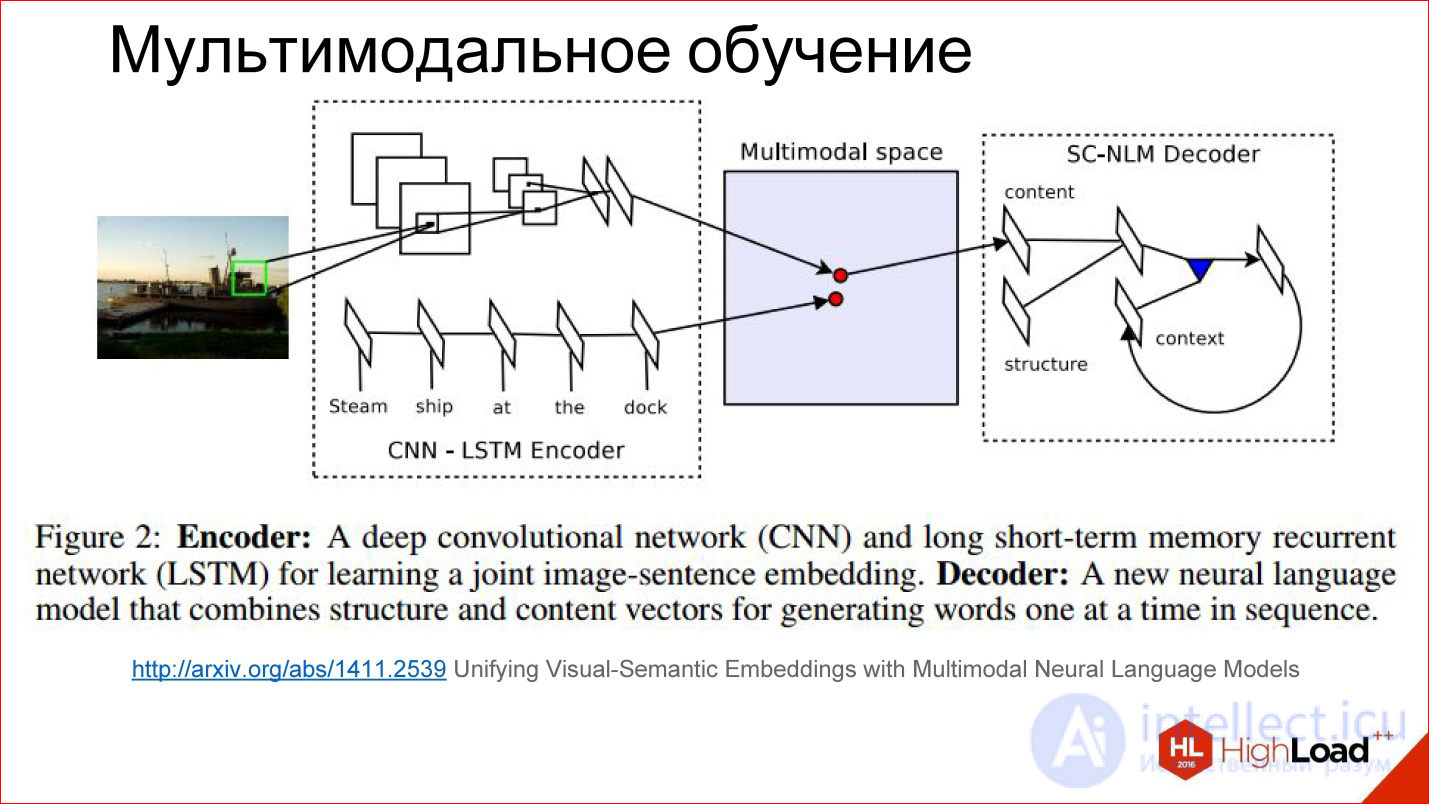
http://arxiv.org/abs/1411.2539
Есть какое-то хитрое пространство, которое мы никак не видим, но оно внутри нейросети существует в виде этих весов, которые она для себя считает. Получается так, что в процессе обучения мы учим как бы 2 разные нейросети: сверточную и рекуррентную для текста, который описывает картинку и для самой картинки генерировать вектора в этом хитром пространстве в одном месте. То есть сводить 2 модальности в одну.
Если мы это научились делать, то дальше там до некоторой степени не важно: подаем картинку — генерируем текст, подаем текст — находим картинку. Можно играться с разными штуками и строить интересные вещи.
Кстати, уже есть попытки строить сети, которые по тексту генерят картинки. Это интересно, это тоже работает. Пока еще не очень хорошо, но потенциал огромен.
Когда надо работать с последовательностями произвольной длины на входе и/или выходе
Вторая интересная тема — Sequence Learning или парадигма seq2seq. Я даже не буду это переводить. Идея в том, что много ваших задач сводится к тому, что у вас есть последовательности. То есть не просто картинка, которую нужно классифицировать, выдать одно число, а есть одна последовательность, а на выходе нужна другая последовательность.
Например, перевод — классическая задача Sequence 2 Sequence Learning: задали текст на английском, хотите получить на французском.
Таких задач много на самом деле. Это кейс описания картинки.

http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Обычные нейросети, которые мы рассматривали — что-то загнали, прогнали через сеть, сняли на выходе — не интересно.
Есть вариант под названием One to many. Загнали картинку в сеть, а дальше она пошла работать, работать и сгенерила описание этой картинки. Здорово.
Можно в обратную сторону. Например, классификация текстов. Это любимая задача всех маркетологов — твиты классифицировать — они положительные или отрицательные в смысле эмоциональной окраски. Вы загнали ваше предложение в рекуррентную нейросеть, а потом в конце она выдала одно число — да, позитивно окрашенный твит, нет, негативно окрашенный твит, или нейтральный, например.
Есть история про перевод. Вы долго загоняли последовательность на одном языке. Дальше сеть поработала и начала генерить последовательность на другом языке. Это вообще самая общая постановка.
Есть еще одна интересная постановка, когда входы и выходы синхронизированы. Например, если нужно аннотировать каждый кадр изображения — есть на нем что-то или нет.
На рисунке представлены все варианты Sequence 2 Sequence Learning, и это очень мощная парадигма. Она мощна тем, что если внутри нейросети все дифференцируемо — а нейросети, которые мы обсуждали, все внутри насквозь дифференцируемы, это значит, что вы можете обучать нейросеть, так сказать, end-to-end: подали на вход одни последовательности, на выход другие, а что происходит внутри, вам вообще не важно. Нейросеть сама справится — на вход куча примеров на английском, на выход — куча примеров на французском – отлично, она сама обучится переводу. Причем действительно с хорошим качеством, если у вас большая база данных и хорошие вычислительные мощности, чтобы все это прогнать.

Еще одна безумно важная вещь, про которую почти нигде не говорят, но без которой не работает ни распознавание речи Google, ни Baidu, ни Microsoft – CTC.

https://github.com/baidu-research/warp-ctc
CTC — это такой хитрый выходной слой. Что он делает? Есть много задач, в которых на самом деле не важно выравнивание внутри этой последовательности. Есть задача распознавания речи. Вы взяли звук, порезали на короткие фреймы по 50 мс, например, а дальше на выходе нужно сгенерить, какое слово это было, последовательность фонем. По большому счету, вам не важно, в каком месте исходного сигнала была та или иная фонема. Важен только порядок между собой, чтобы просто слово на выходе получить.
То, что можно выкинуть всю информацию про точное положение, на самом деле очень много, чего добавляет. Например, не нужно иметь точную разметку фонем по всем фреймам звука, потому что получить такую разметку — безумно дорого. Нужно посадить человека, который будет все размечать.
Можно просто все взять и выкинуть — есть входные данные, есть выход — что должно получиться в терминах выходной последовательности — слово, есть этот хитрый CTC-слой, который сам сделает какое-то выравнивание внутри себя, и это позволит, опять же, end-to-end обучить такую хитрую сеть, для которой вы вообще ничего не размечали.
Это мощнейшая вещь, она тоже не во всех современных пакетах реализована. Но, например, год назад Baidu выложил свою реализацию слоя CTC — это здорово.
Еще пару слов про разные архитектуры.

https://github.com/farizrahman4u/seq2seq
Есть классическая архитектура Encoder-Decoder. Пример с переводом, про который я говорил, практически целиком сводится к этой архитектуре.
Есть одна входная нейросеть, в нее подаются слова. Выход этой нейросети как бы игнорируется до тех пор, пока не подан символ конца предложения. После этого включается в дело вторая сеть, которая считывает состояние первой сети и с него начинает генерить слова на выход. На вход подаются ее же результаты на предыдущем шаге.
Это работает. Многие системы перевода работают так.
Но у этой архитектуры есть одна проблема — тоже бутылочное горлышко. Вектор состояния (размер скрытого слоя), который передается, ограничен и фиксирован. То есть получается, что он одинаковый и для короткого предложения, и для безумно длинного — это не очень хорошо. Может оказаться, что длинное предложение не впишется в этот объем.
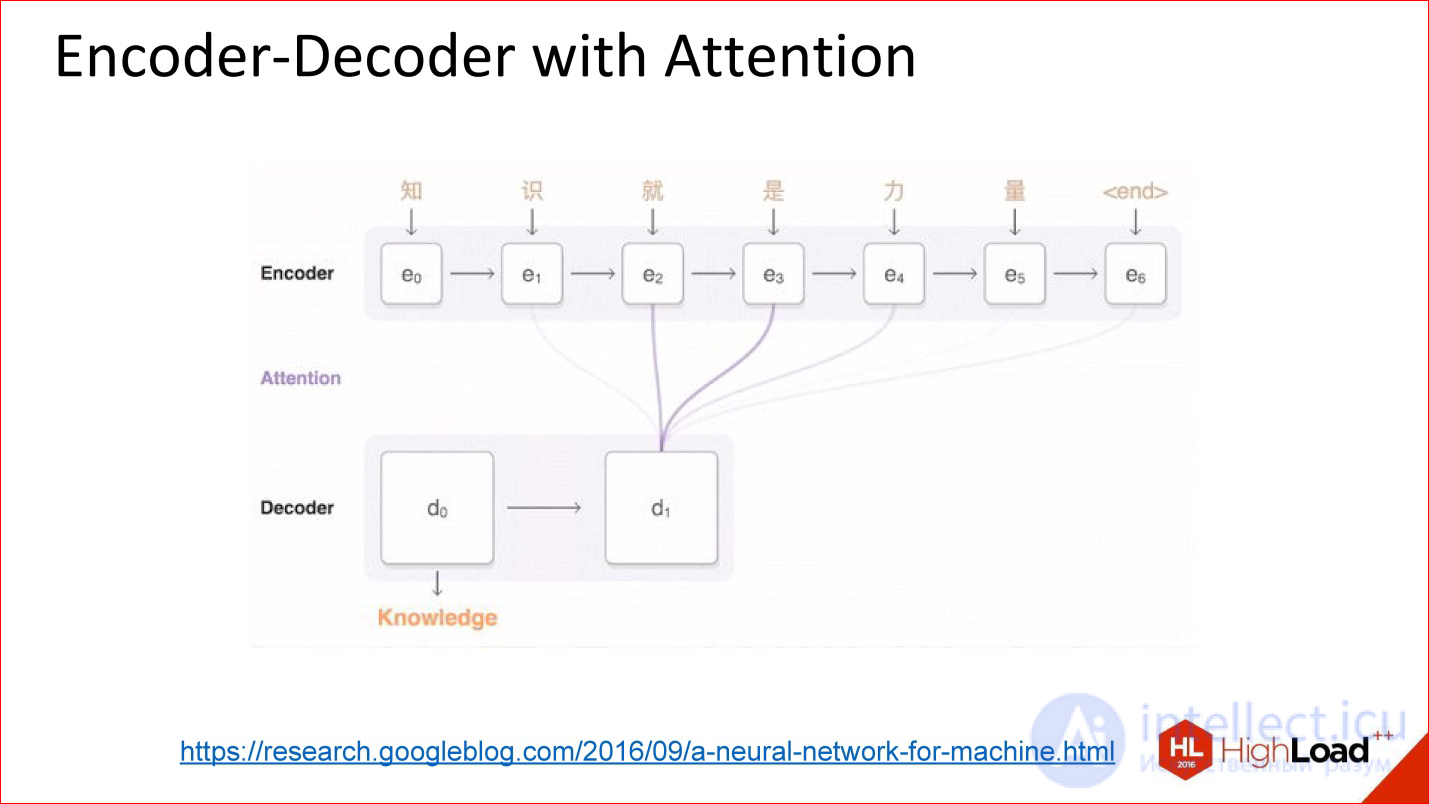
https://research.googleblog.com/2016/09/a-neural-network-for-machine.html
Появились архитектуры, что называется, с вниманием.
Внимание — это такая хитрая штука, которая на самом деле, по сути, очень простая. Идея в том, что теперь декодер выхода на нейросеть смотрит не на выходное значение предыдущей нейросети, а на все ее промежуточные состояния, но с какими-то весами. Веса — это коэффициенты, насколько сильно нужно взять каждое из тех состояний в итоговую большую сумму, с которой будет работать декодер.
То есть внимание — это на самом деле простая линейная комбинация всех предыдущих состояний энкодера, которая тоже обучается.
Нейросети с вниманием по факту работают очень здорово. На задачах перевода и других сложных задачах они по качеству очень сильно превосходят нейросети без внимания.

Трансформер (англ. Transformer) — архитектура глубоких нейронных сетей, представленная в 2017 году исследователями из Google Brain.По аналогии с рекуррентными нейронными сетями (РНС) трансформеры предназначены для обработки последовательностей, таких как текст на естественном языке, и решения таких задач как машинный перевод и автоматическое реферирование. В отличие от РНС, трансформеры не требуют обработки последовательностей по порядку. Например, если входные данные — это текст, то трансформеру не требуется обрабатывать конец текста после обработки его начала. Благодаря этому трансформеры распараллеливаются легче чем РНС и могут быть быстрее обучены.
Каждый кодировщик состоит из механизма самовнимания (вход из предыдущего слоя) и нейронной сети с прямой связью (вход из механизма самовнимания). Каждый декодировщик состоит из механизма самовнимания (вход из предыдущего слоя), механизма внимания к результатам кодирования (вход из механизма самовнимания и кодировщика) и нейронной сети с прямой связью (вход из механизма внимания).

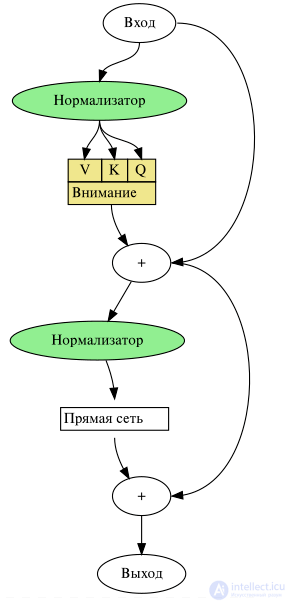

Каждый механизм внимания параметризован матрицами весов запросов  , весов ключей
, весов ключей  , весов значений
, весов значений  . Для вычисления внимания входного вектора X к вектору Y, вычисляются вектора
. Для вычисления внимания входного вектора X к вектору Y, вычисляются вектора  ,
,  ,
,  . Эти вектора используются для вычисления результата внимания по формуле:
. Эти вектора используются для вычисления результата внимания по формуле:

Трансформеры используются в чатботах - GPT подобных. в компьютерных системах -переводчиках и вдругих областях,
Выбирать тип сети следует, исходя из постановки задачи и имеющихся данных для обучения. Для обучения с учителем требуется наличие для каждого элемента выборки «экспертной» оценки. Иногда получение такой оценки для большого массива данных просто невозможно. В этих случаях естественным выбором является сеть, обучающаяся без учителя (например, самоорганизующаяся карта Кохонена или нейронная сеть Хопфилда). При решении других задач (таких, как прогнозирование временных рядов) экспертная оценка уже содержится в исходных данных и может быть выделена при их обработке. В этом случае можно использовать многослойный перцептрон или сеть Ворда.
После выбора общей структуры нужно экспериментально подобрать параметры сети. Для сетей, подобных перцептрону, это будет число слоев, число блоков в скрытых слоях (для сетей Ворда), наличие или отсутствие обходных соединений, передаточные функции нейронов. При выборе количества слоев и нейронов в них следует исходить из того, что способности сети к обобщению тем выше, чем больше суммарное число связей между нейронами. С другой стороны, число связей ограничено сверху количеством записей в обучающих данных.
После выбора конкретной топологии необходимо выбрать параметры обучения нейронной сети. Этот этап особенно важен для сетей, обучающихся с учителем. От правильного выбора параметров зависит не только то, насколько быстро ответы сети будут сходиться к правильным ответам. Например, выбор низкой скорости обучения увеличит время схождения, однако иногда позволяет избежать паралича сети. Увеличение момента обучения может привести как к увеличению, так и к уменьшению времени сходимости, в зависимости от формы поверхности ошибки. Исходя из такого противоречивого влияния параметров, можно сделать вывод, что их значения нужно выбирать экспериментально, руководствуясь при этом критерием завершения обучения (например, минимизация ошибки или ограничение по времени обучения).
В процессе обучения сеть в определенном порядке просматривает обучающую выборку. Порядок просмотра может быть последовательным, случайным и т. д. Некоторые сети, обучающиеся без учителя (например, сети Хопфилда), просматривают выборку только один раз. Другие (например, сети Кохонена), а также сети, обучающиеся с учителем, просматривают выборку множество раз, при этом один полный проход по выборке называется эпохой обучения. При обучении с учителем набор исходных данных делят на две части — собственно обучающую выборку и тестовые данные; принцип разделения может быть произвольным. Обучающие данные подаются сети для обучения, а проверочные используются для расчета ошибки сети (проверочные данные никогда для обучения сети не применяются). Таким образом, если на проверочных данных ошибка уменьшается, то сеть действительно выполняет обобщение. Если ошибка на обучающих данных продолжает уменьшаться, а ошибка на тестовых данных увеличивается, значит, сеть перестала выполнять обобщение и просто «запоминает» обучающие данные. Это явление называется переобучением сети или оверфиттингом. В таких случаях обучение обычно прекращают. В процессе обучения могут проявиться другие проблемы, такие как паралич или попадание сети в локальный минимум поверхности ошибок. Невозможно заранее предсказать проявление той или иной проблемы, равно как и дать однозначные рекомендации к их разрешению.
Все выше сказанное относится только к итерационным алгоритмам поиска нейросетевых решений. Для них действительно нельзя ничего гарантировать и нельзя полностью автоматизировать обучение нейронных сетей. Однако, наряду с итерационными алгоритмами обучения, существуют не итерационные алгоритмы, обладающие очень высокой устойчивостью и позволяющие полностью автоматизировать процесс обучения
Даже в случае успешного, на первый взгляд, обучения сеть не всегда обучается именно тому, чего от нее хотел создатель. Известен случай, когда сеть обучалась распознаванию изображений танков по фотографиям, однако позднее выяснилось, что все танки были сфотографированы на одном и том же фоне. В результате сеть «научилась» распознавать этот тип ландшафта, вместо того, чтобы «научиться» распознавать танки. Таким образом, сеть «понимает» не то, что от нее требовалось, а то, что проще всего обобщить.
Тестирование качества обучения нейросети необходимо проводить на примерах, которые не участвовали в ее обучении. При этом число тестовых примеров должно быть тем больше, чем выше качество обучения. Если ошибки нейронной сети имеют вероятность близкую к одной миллиардной, то и для подтверждения этой вероятности нужен миллиард тестовых примеров. Получается, что тестирование хорошо обученных нейронных сетей становится очень трудной задачей.
Таким образом, архитектуры нейронных сетей играют ключевую роль в развитии искусственного интеллекта, определяя эффективность и применимость моделей в различных задачах. От простых персептронов до сложных трансформеров, каждая архитектура имеет свои преимущества и области применения. Развитие нейросетевых структур позволяет достигать новых высот в обработке данных, распознавании образов, анализе последовательностей и генерации контента. По мере совершенствования технологий мы можем ожидать появления еще более мощных и универсальных моделей, способных решать сложные задачи с высокой точностью и эффективностью.
Часть 1 Архитектуры нейронных сетей. Классификация и виды нейросетей, принцип работы, применение
Часть 2 Архитектуры нейросетей. Нейросети прямого распространения - Архитектуры нейронных сетей. Классификация
Часть 3 Sequence Learning и парадигма seq2seq - Архитектуры нейронных сетей. Классификация
Комментарии
Оставить комментарий
Computational Neuroscience (вычислительная нейронаука) Теория и приложения искусственных нейронных сетей
Термины: Computational Neuroscience (вычислительная нейронаука) Теория и приложения искусственных нейронных сетей