Лекция
Привет, сегодня поговорим про потоки, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое потоки, процессы, нити, контексты, классификация потоков , настоятельно рекомендую прочитать все из категории Операционные системы и системное программировние.
Рассмотрим различные потоковые модели, которые реализованы в современных операционных системах (preemptive, cooperative threads). Также кратко рассмотрим как потоки и средства синхронизации реализованы в Win32 API и Posix Threads. Хотя в современном программировании больше популярны скриптовые языки, однако основы — должны знать все.
Системный вызов (syscall). Данное понятие, вы будете встречать достаточно часто в данной статье, однако несмотря на всю мощь звучания, его определение достаточно простое :) Системный вызов — это процесс вызова функции ядра, из приложение пользователя. Режим ядра — код, который выполняется в нулевом кольце защиты процессора (ring0) с максимальными привилегиями. Режим пользователя — код, исполняемый в третьем кольце защиты процессора (ring3), обладает пониженными привилегиями. Если код в ring3 будет использовать одну из запрещенных инструкций (к примеру rdmsr/wrmsr, in/out, попытку чтения регистра cr3, cr4 и т.д.), сработает аппаратное исключение и пользовательский процесс, чей код исполнял процессор в большинстве случаях будет прерван. Системный вызов осуществляет переход из режима ядра в режим пользователя с помощью вызова инструкции syscall/sysenter, int2eh в Win2k, int80h в Linux и т.д.
И так, что же такое поток? Поток (thread) — это, сущность операционной системы, процесс выполнения на процессоре набора инструкций, точнее говоря программного кода. Общее назначение потоков — параллельное выполнение на процессоре двух или более различных задач. Как можно догадаться, потоки были первым шагом на пути к многозадачным ОС. Планировщик ОС, руководствуясь приоритетом потока, распределяет кванты времени между разными потоками и ставит потоки на выполнение.
На ряду с потоком, существует также такая сущность, как процесс. Процесс (process) — не что более иное, как некая абстракция, которая инкапсулирует в себе все ресурсы процесса (открытые файлы, файлы отображенные в память...) и их дескрипторы, потоки и т.д. Каждый процесс имеет как минимум один поток. Также каждый процесс имеет свое собственное виртуальное адресное пространство и контекст выполнения, а потоки одного процесса разделяют адресное пространство процесса.
Каждый поток, как и каждый процесс, имеет свой контекст. Контекст — это структура, в которой сохраняются следующие элементы:
Значительная часть этой информации фиксируется в виде слова состояния программы PSW (program status word – EFLAGS в процессоре Pentium).
Также следует отметить, что в случае выполнения системного вызова потоком и перехода из режима пользователя, в режим ядра, происходит смена стека потока на стек ядра. При переключении выполнения потока одного процесса, на поток другого, ОС обновляет некоторые регистры процессора, которые ответственны за механизмы виртуальной памяти (например CR3), так как разные процессы имеют разное виртуальное адресное пространство. Здесь я специально не затрагиваю аспекты относительно режима ядра, так как подобные вещи специфичны для отдельно взятой ОС.
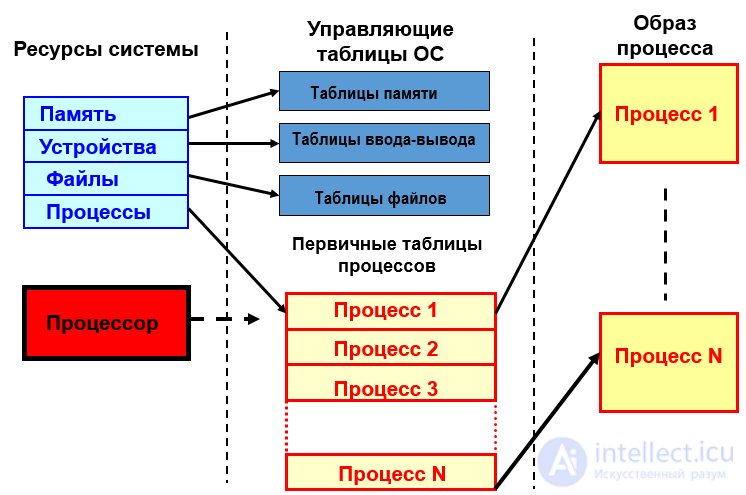
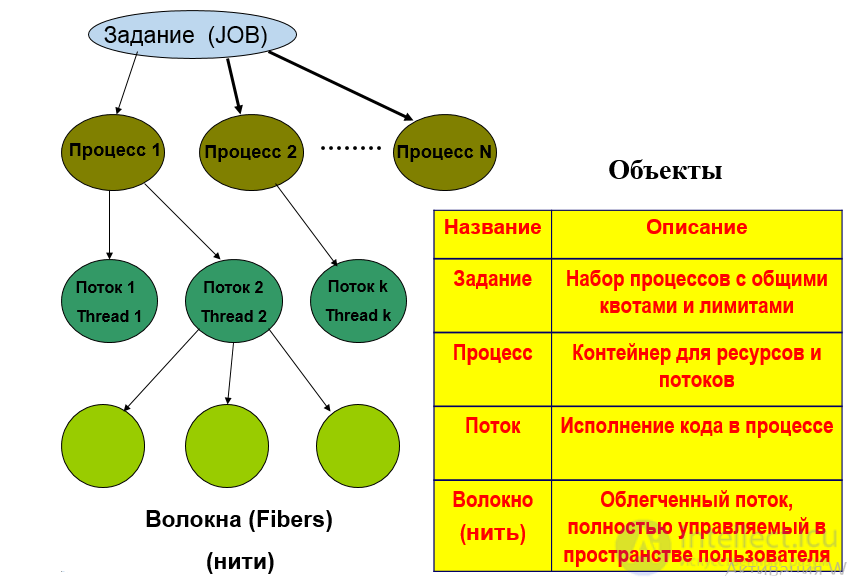
Рис Концепция процессов и потоков. Задания, процессы, потоки ( нити ), волокна

Рис Взаимосвязь между заданиями, процессами и потоками
В общем случае, справедливы следующие рекомендации:
Волокно (fiber) — облегченный поток, выполняемый в режиме пользователя. Волокно затребует значительно меньше ресурсов, и позволяет в некоторых случаях минимизировать количество системных вызовов и следственно увеличить производительность. Обычно волокна выполняются в контексте потока, который их создал и затребуют лишь сохранения регистров процессора при их переключении. Какбы-то нибыло, но волокна не сыскали должной популярности. Они были реализованы в свое время в множестве BSD ОС, но со временем выбрасывались оттуда. Win32 API также реализует механизм волокон, но используется он лишь для облегчения портирования софта, написанного под другую ОС. Следует отметить, что за переключение волокон ответственен либо планировщик уровня процесса, либо переключение должно быть реализовано в самом приложении, проще говоря вручную :)
Поскольку классификация потоков — вопрос неоднозначный, то предлагаю их классифицировать следующим способом:
Как уже было написано выше, потоки могут быть созданы не только в режиме ядра, но и в режиме пользователя. Планировщиков потоков в ОС может быть несколько:
Итак. Модель 1:1 — самая простая модель. Согласно ее принципам, любой поток созданный в любом процессе управляется напрямую планировщиком ядра ОС. Т.е. имеем отображении 1 к 1 потока пользовательского процесса на поток ядра. Такая модель реализована в Linux начиная с ядра 2.6, а также Windows.
Модель N:M отображает некоторое число потоков пользовательских процессов N на M потоков режима ядра. Проще говоря имеем некую гибридную систему, когда часть потоков ставится на выполнение в планировщике ОС, а большая их часть в планировщике потоков процесса или библиотеки потоков. Как пример можно привести GNU Portable Threads. Данная модель достаточно трудно реализуема, но обладает большей производительностью, так как можно избежать значительного количества системных вызовов.
Модель N:1. Как вы наверное догадались — множество потоков пользовательского процесса отображаются на один поток ядра ОС. Например волокна.
Во времена DOS, когда однозадачные ОС перестали удовлетворять потребителя, программисты и архитекторы задумали реализовать многозадачную ОС. Самое простое решение было следующим: взять общее количество потоков, определить какой-нибудь минимальный интервал выполнения одного потока, да взять и разделить между всеми -братьями- потоками время выполнения поровну. Так и появилось понятие кооперативной многозадачности (cooperative multitasking), т.е. все потоки выполняются поочередно, с равным временем выполнения. Никакой другой поток, не может вытеснить текущий выполняющийся поток. Такой очень простой и очевидный подход нашел свое применение во всех версиях Mac OS вплоть до Mac OS X, также в Windows до Windows 95, и Windows NT. До сих пор кооперативная многозадачность используется в Win32 для запуска 16 битных приложений. Также для обеспечения совместимости, cooperative multitasking используется менеджером потоков в Carbon приложениях для Mac OS X.
Однако, кооперативная многозадачность со временем показала свою несостоятельность. Росли объемы данных хранимых на винчестерах, росла также скорость передачи данных в сетях. Стало понятно, что некоторые потоки должны иметь больший приоритет, как-то потоки обслуживания прерываний устройств, обработки синхронных IO операций и т.д. В это время каждый поток и процесс в системе обзавелся таким свойством, как приоритет. Подробнее о приоритетах потоков и процессов в Win32 API вы можете прочесть в книге Джефри Рихтера, мы на этом останавливатся не будем ;) Таким образом поток с большим приоритетом, может вытеснить поток с меньшим. Такой прицип лег в основу вытесняющей многозадачности (preemptive multitasking). Сейчас все современные ОС используют данный подход, за исключением реализации волокон в пользовательском режиме.
Как уже писалось выше, реализация планировщика потоков может осуществлятся на разных уровнях. Итак:
Образ процесса: программа, данные, стек и атрибуты процесса
|
Информация |
Описание |
|
Данные пользователя |
Изменяемая часть пользовательского адресного пространства (данные программы, пользовательский стек и модифицируемый код) |
|
Пользовательская программа |
Программа, которую нужно выполнить |
|
Системный стек |
Один или несколько системных стеков для хранения параметров и адресов вызова процедур и системных служб |
|
Управляющий блок процесса |
Данные, необходимые ОС для управления процессом: 1) дескриптор процесса, 2) контекст процесса |
Дескриптор процесса содержит:
Для описания состояний процессов используется несколько моделей. Самая простая — модель трех состояний (рис. 1). Она определяет следующие состояния процесса:
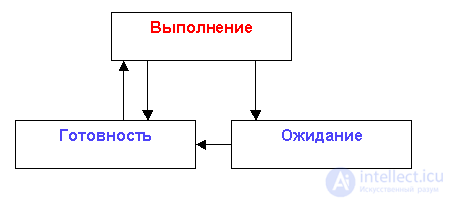
Рис. 1. Модель трех состояний
Простейшая модель процесса
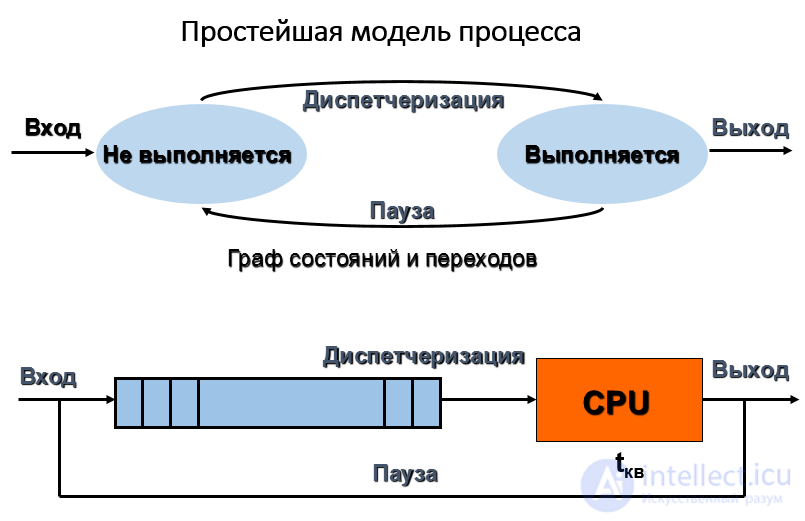
Выполнение — это активное состояние, во время которого процесс обладает всеми необходимыми ему ресурсами. В этом состоянии процесс непосредственно выполняется процессором.
Ожидание — это пассивное состояние, во время которого процесс заблокирован и не может быть выполнен, потому что ожидает какое-то событие, например, ввода данных или освобождения нужного ему устройства.
Готовность — это тоже пассивное состояние, процесс тоже заблокирован, но в отличие от состояния ожидания, он заблокирован не по внутренним причинам (ведь ожидание ввода данных — это внутренняя, «личная» проблема процесса — он может ведь и не ожидать ввода данных и свободно выполняться — никто ему не мешает), а по внешним, независящим от процесса, причинам.
Когда процесс может перейти в состояние готовности? Предположим, что наш процесс выполнялся до ввода данных. До этого момента он был в состоянии выполнения, потом перешел в состояние ожидания — ему нужно подождать, пока мы введем нужную для работы процесса информацию. Затем процесс хотел уже перейти в состояние выполнения, так как все необходимые ему данные уже введены, но не тут-то было: так как он не единственный процесс в системе, пока он был в состоянии ожидания, его «место под солнцем» занято — процессор выполняет другой процесс. Тогда нашему процессу ничего не остается как перейти в состояние готовности: ждать ему нечего, а выполняться он тоже не может.
Из состояния готовности процесс может перейти только в состояние выполнения. В состоянии выполнения может находится только один процесс на один процессор. Если у вас n-процессорная машина, у вас одновременно в состоянии выполнения могут быть n процессов.
Из состояния выполнения процесс может перейти либо в состояние ожидания, либо в состояние готовности. Почему процесс может оказаться в состоянии ожидания, мы уже знаем — ему просто нужны дополнительные данные или он ожидает освобождения какого-нибудь ресурса, например, устройства или файла. В состояние готовности процесс может перейти, если во время его выполнения, квант времени выполнения «вышел». Другими словами, в операционной системе есть специальная программа — планировщик, которая следит за тем, чтобы все процессы выполнялись отведенное им время. Например, у нас есть три процесса. Один из них находится в состоянии выполнения. Два других — в состоянии готовности. Планировщик следит за временем выполнения первого процесса, если «время вышло», планировщик переводит процесс 1 в состояние готовности, а процесс 2 — в состояние выполнения. Затем, когда, время отведенное, на выполнение процесса 2, закончится, процесс 2 перейдет в состояние готовности, а процесс 3 — в состояние выполнения.
Более сложная модель — это модель, состоящая из пяти состояний. В этой модели появилось два дополнительных состояния: рождение процесса и смерть процесса.
Рождение процесса — это пассивное состояние, когда самого процесса еще нет, но уже готова структура для появления процесса.
Смерть процесса — самого процесса уже нет, но может случиться, что его «место", то есть структура данных , осталась в списке процессов. Такие процессы называются зобми.
Диаграмма модели пяти состояний представлена на рис. 2.
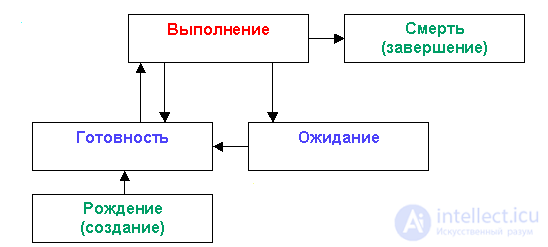
Рис.5. Модель пяти состояний
В ОС РВ время перехода процесса из одного состояния в другое должно быть детерминированно. Функции контроля за временем (deadline) возлагаются на планировщика (о планировании будет сказано далее).
Описатель потока: блок управления потоком и контекст потока (в многопоточной системе процессы контекстов не имеют).
Способы реализации пакета потоков:
Поток на уровне пользователя (в пользовательском пространстве)
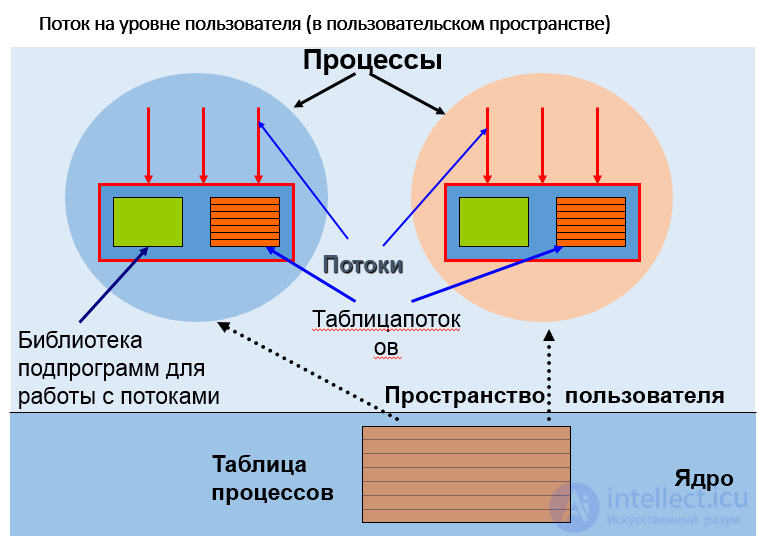
ДОСТОИНСТВА :Потока на уровне пользователя
Поток на уровне пользователя НЕДОСТАТКИ:
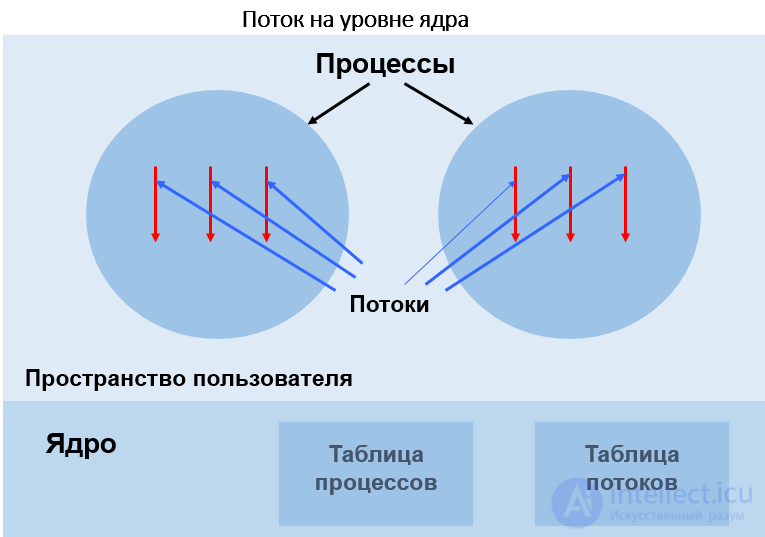
Поток на уровне ядра
ДОСТОИНСТВА:
НЕДОСТАТКИ:
Над процессами можно производить следующие операции:
Для создания процесса операционной системе нужно:
Если вы все еще не устали, предлагаю небольшой обзор API для работы с потоками и средствами синхронизации в win32 API. Если вы уже знакомы с материалом, можете смело пропускать этот раздел ;)
Потоки в Win32 создаются с помощью функции CreateThread, куда передается указатель на функцию (назовем ее функцией потока), которая будет выполнятся в созданом потоке. Поток считается завершенным, когда выполнится функция потока. Если же вы хотите гарантировать, что поток завершен, то можно воспользоватся функцией TerminateThread, однако не злоупотребляйте ею! Данная функция «убивает» поток, и отнюдь не всегда делает это корректно. Функция ExitThread будет вызвана неявно, когда завершится функция потока, или же вы можете вызвать данную функцию самостоятельно. Главная ее задача — освободить стек потока и его хендл, т.е. структуры ядра, которые обслуживают данный поток.
Поток в Win32 может пребывать в состоянии сна (suspend). Можно «усыпить поток» с помощью вызова функции SuspendThread, и «разбудить» его с помощью вызова ResumeThread, также поток можно перевести в состояние сна при создании, установив значение параметра СreateSuspended функции CreateThread. Не стоит удивлятся, если вы не увидите подобной функциональности в кроссплатформенных библиотеках, типа boost::threads и QT. Все очень просто, pthreads просто не поддерживают подобную функциональность.
Средства синхронихации в Win32 есть двух типов: реализованные на уровне пользователя, и на уровне ядра. Первые — это критические секции (critical section), к второму набору относят мьютексы (mutex), события (event) и семафоры (semaphore).
Критические секции — легковесный механизм синхронизации, который работает на уровне пользовательского процесса и не использует тяжелых системных вызовов. Он основан на механизме взаимных блокировок или спин локов (spin lock). Поток, который желает обезопасить определенные данные от race conditions вызывает функцию EnterCliticalSection/TryEnterCriticalSection. Если критическая секция свободна — поток занимает ее, если же нет — поток блокируется (т.е. не выполняется и не отъедает процессорное время) до тех пор, пока секция не будет освобождена другим потоком с помощью вызова функции LeaveCriticalSection. Данные функции — атомарные, т.е. вы можете не переживать за целостность ваших данных ;)
О мьютексах, событиях и семафорах было сказано достаточно много, по этому детально останавливатся я на них не буду. Следует заметить, что у всех этих механизмов есть общие черты:
Сложно представить, какая из *nix подобных операционных систем, не реализует этот стандарт. Стоит отметить, что pthreads также используется в различных операционных системах реального времени (RTOS), потому требование к этой библиотеке (вернее стандарту) — жестче. К примеру, поток pthread не может пребывать в состоянии сна. Также в pthread нет событий, но есть гораздо более мощный механизм — условных переменных (conditional variables), который с лихвой покрывает все необходимые нужды.
Поговорим об отличиях. К примеру, поток в pthreads может быть отменен (cancel), т.е. просто снят с выполнения посредством системного вызова pthread_cancel в момент ожидания освобождения какого-нибудь мьютекса или условной переменной, в момент выполнения вызова pthread_join (вызывающий поток блокируется до тех пор, пока не закончит свое выполнение поток, приминительно к которому была вызвана функция) и т.д. Для работы с мьютексами и семафорами существует отдельные вызовы, как-то pthread_mutex_lock/pthread_mutex_unlock и т.д.
Conditional variables (cv) обычно используется в паре с мьютексами в более сложных случаях. Если мьютекс просто блокирует поток, до тех пор, пока другой поток не освободит его, то cv создают условия, когда поток может заблокировать сам себя до тех пор, пока не произойдет какое-либо условия разблокировки. Например, механизм cv помогает эмулировать события в среде pthreads. Итак, системный вызов pthread_cond_wait ждет, пока поток не будет уведомлен о том, что случилось определенное событие. pthread_cond_signal уведомляет один поток из очереди, что cv сработала. pthread_cond_broadcast уведомляет все потоки, которые вызывали pthread_cond_wait, что сработала cv.
Для того чтобы, структурировать свое понимание – что представляют собой threads (это слово переводят на русский язык как «нити» почти везде, кроме книг по Win32 API, где его переводят как «потоки») и чем они отличаются от процессов, можно воспользоваться следующими двумя определениями:
Очень важно понять, что thread – это концептуально именно виртуальный процессор и когда мы пишем реализацию threads в ядре ОС или в user-level библиотеке, то мы решаем именно задачу «размножения» центрального процессора во многих виртуальных экземплярах, которые логически или даже физически (на SMP, SMT и multi-core CPU платформах) работают параллельно друг с другом.
На основном, концептуальном уровне, нет никакого «контекста». Контекст – это просто название той структуры данных, в которую ядро ОС или наша библиотека (реализующая threads) сохраняет регистры виртуального процессора, когда она переключается между ними, эмулируя их параллельную работу. Переключение контекстов – это способ реализации threads, а не более фундаментальное понятие, через которое нужно определять thread.
При подходе к определению понятия thread через анализ API конкретных ОС обычно вводят слишком много сущностей – тут тебе и процессы, и адресные пространства, и контексты, и переключения этих контекстов, и прерывания от таймера, и кванты времени с приоритетами, и даже «ресурсы», привязанные к процессам (в противовес threads). И все это сплетено в один клубок и зачастую мы видим, что идем по кругу, читая определения. Увы, это распространенный способ объяснять суть threads в книгах, но такой подход сильно путает начинающих программистов и привязывает их понимание к конкретике реализации.
Понятное дело, что все эти термины имеют право на существование и возникли не случайно, за каждым из них стоит какая-то важная сущность. Но среди них нужно выделить главные и второстепенные (введенные для реализации главных сущностей или навешанные на них сверху, уже на следующих уровнях абстракции).
Главная идея thread – это виртуализация регистров центрального процессора – эмуляция на одном физическом процессоре нескольких логических процессоров, каждый из которых имеет свое собственное состояние регистров (включая указатель команд) и работает параллельно с остальными.
Главное свойство процесса в контексте этого разговора – наличие у него своих собственных страничных таблиц, образующих его индивидуальное адресное пространство. Процесс не является сам по себе чем-то исполнимым.
Можно говорить в определении, что «у каждого процесса в системе всегда есть по крайней мере один thread». А можно сказать иначе –адресное пространство логически лишено смысла для пользователя, если оно не видно хотя бы одному виртуальному процессору (thread). Поэтому логично, что все современные ОС уничтожают адресное пространство (завершают процесс) при завершении работы последнего thread, работающего на данном адресном пространстве. И можно не говорить в определении процесса, что в нем есть «по крайней мере, один thread». Тем более, что на нижнем системном уровне процесс (как правило) может существовать как объект ОС даже не имея в своем составе threads.
Если Вы посмотрите исходники, например, ядра Windows, то Вы увидите, что адресное пространство и прочие структуры процесса конструируются до создания в нем начальной нити (начальной thread для этого процесса). По сути, изначально в процессе не существует threads вообще. В Windows можно даже создать thread в чужом адресном пространстве через user-level API…
Если смотреть на thread как на виртуальный процессор – то его привязка к адресному пространству представляет собой загрузку в виртуальный регистр базы станичных таблиц нужного значения. :) Тем более, что на нижнем уровне именно это и происходит – каждый раз при переключении на thread, связанную с другим процессом, ядро ОС перезагружает регистр указателя на страничные таблицы (на тех процессорах, которые не поддерживают на аппаратном уровне работу со многими пространствами одновременно).
Как уже говорилось, СРВ — это программно-аппаратный комплекс, осуществляющий мониторинг какого-то объекта и/или управление им в условиях временнЫх ограничений. Возникающие на объекте события подлежат обработке в СРВ. Будем сопоставлять каждому типу события задачу.
ЗАДАЧА (TASK) — блок программного кода, ответственный за обработку тех или иных событий, возникающих на объекте управления.
Задача может быть «оформлена» в виде:
РАБОТА ЗАДАЧИ (JOB) — процесс исполнения блока программного кода в ходе обработки события.
Каждая работа задачи характеризуется следующими временнЫми параметрами:
Диаграмма ниже иллюстрирует эти параметры:
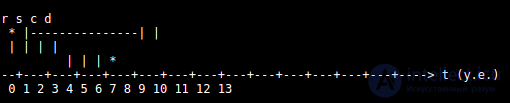
Приведенная на этой диаграмме работа задачи имеет следующие параметры:

Мультипрограммирование в системах разделения времени и потоки

Основные функции управления процессами и потоками
События, приводящие к созданию процессов:
Задачи реального времени могут выполняться в виде процессов или потоков. Между ними не должно быть слишком много взаимодействий, и в большинстве случаев они имеют различную природу — жесткого реального времени, мягкого реального времени, условного времени. Для обеспечения более эффективного решения задач реального времени стоит использовать многопотоковые программы как менее требовательные к ресурсам.
Надеюсь, эта статья про потоки, была вам полезна, счастья и удачи в ваших начинаниях! Надеюсь, что теперь ты понял что такое потоки, процессы, нити, контексты, классификация потоков и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Операционные системы и системное программировние

Комментарии