Привет, сегодня поговорим про поток данных, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое
поток данных , настоятельно рекомендую прочитать все из категории Операционные системы и системное программировние.
поток данных (англ. stream) в программировании — абстракция, используемая для чтения или записи файлов, сокетов и т. п. в единой манере.
Потоки являются удобным унифицированным программным интерфейсом для чтения или записи файлов (в том числе специальных и, в частности, связанных сустройствами), сокетов и передачи данных между процессами.
Поддержка потоков включена в большинство языков программирования и едва ли не во все современные (на 2008 год) операционные системы.
При запуске процесса ему предоставляются предопределенные стандартные потоки.
Возможность перенаправления потоков позволяет связывать различные программы, и придает системе гибкость, являющуюся частью философии Unix.
История
Концепция потоков данных при обработке данных может быть прослежена, среди прочего, к каналам, предложенным Дугласом Макилроем для связывания макросов , которые были реализованы в 1964 году как «файлы связи» в системе разделения времени Дартмута и интегрированы в Unix. операционная система в 1972 году . Это соединение данных между двумя процессами, основанное на принципе FIFO . Принцип потоков теперь можно найти в большинстве современных языков программирования .
Поток данных представляет собой последовательность кодированных в цифровом виде когерентных сигналов ( пакетов из данных или пакетов данных ) , используемых для передачи или получать информацию , которая находится в процессе передачи. Поток данных - это набор информации, извлеченной от поставщика данных. Он содержит необработанные данные, которые были собраны из поведения пользователей в браузере на веб-сайтах, на которых размещен специальный пиксель. Потоки данных полезны для специалистов по данным для больших данных и ИИ.поставка алгоритмов. Основными поставщиками потоков данных являются компании, занимающиеся информационными технологиями .
Поток данных в программировании
Абстракция потока особенно важна в языке программирования Си, где он представляет собой источник ввода и/или вывода данных, обычно байтов, связанный с файлом, устройством, либо другим процессом. Работа с потоками перенесена во многие другие языки:
- C++: iostream из стандартной библиотеки C++.
- Языки платформы .NET Framework (например, C#): Base Class Library, пространство имен System.IO.
Поток данных в операционных системах
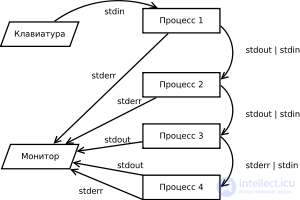
Пример цепи процессов общающихся с помощью потоков данных.
Командная оболочка UNIX интенсивно использует абстракцию потока для совместного выполнения нескольких утилит.
Формальное определение
Формально поток данных - это любая упорядоченная пара  где:
где:
-
 представляет собой последовательность из кортежей и
представляет собой последовательность из кортежей и
-
 представляет собой последовательность положительных интервалов реального времени .
представляет собой последовательность положительных интервалов реального времени .
Содержание [
Поток данных содержит разные наборы данных, которые зависят от выбранного формата данных.
- Атрибуты - каждый атрибут потока данных представляет определенный тип данных, например идентификатор сегмента / точки данных, отметку времени, геоданные.
- Атрибут отметки времени помогает определить, когда произошло событие.
- Идентификатор субъекта - это кодированный алгоритмом идентификатор, извлеченный из файла cookie.
- Необработанные данные включают информацию прямо от поставщика данных без обработки ни алгоритмом, ни человеком.
- Обработанные данные - это данные, которые были подготовлены (каким-то образом изменены, проверены или очищены) для использования в будущих действиях.
Использование
Существуют различные области использования потоков данных:
- Обнаружение и оценка мошенничества - необработанные данные используются в качестве исходных данных для алгоритма борьбы с мошенничеством ( методы анализа данных для обнаружения мошенничества ). Об этом говорит сайт https://intellect.icu . Например, временная метка или количество появлений файлов cookie или анализ точек данных используются в системе оценки для обнаружения мошенничества или для того, чтобы убедиться, что получатель сообщения не является ботом (так называемый трафик, не связанный с людьми ).
- Искусственный интеллект - необработанные данные обрабатываются как набор поездов и набор тестов во времясоздания алгоритмов искусственного интеллекта и машинного обучения .
- Необработанные данные используются для профилирования и персонализации, чтобы настроить профили пользователей и разделить их для сегментации, например, по полу или местоположению (на основе точки данных ).
- Бизнес-аналитика - необработанные данные - это источник информации для систем бизнес-аналитики , используемый для пополнения профилей пользователей подробной информацией о них, например, путем покупки или геоданными. Эта информация используется для бизнес-анализа и прогнозных исследований.
- Таргетинг - данные, обработанные специалистами по данным, улучшают онлайн-кампании и используются для охвата целевой аудитории.
- CRM Enrichment - сырые данные интегрированы с системой управления взаимоотношениями с клиентами . Интеграция CRM позволяет заполнить пробелы в профилях пользователей демографическими данными, интересами или покупательскими намерениями.
Интеграция
Основные интеграции с потоками данных:
- Потоки данных интегрированы с такими системами, как платформа данных о клиентах (CDP), управление взаимоотношениями с клиентами (CRM) или платформа управления данными (DMP) для обогащения профилей пользователей внешними данными. Можно расширить знания о существующих пользователях, используя внешние источники.
- Потоки данных используются для обогащения систем бизнес-аналитики и повышения точности анализа и вывода более точных выводов.
- В случае интеграции системы управления контентом (CMS) поток данных используется для идентификации пользователей и персонализации их посещения, даже если это их первый визит. Благодаря анализу данных фактическое содержание веб-сайта адаптируется к пользователю.
- Потоки данных интегрированы с платформой спроса (DSP) в экосистеме программной рекламы. Стороны (например, рекламодатели) могут обмениваться идентификаторами пользователей и связывать с ними существующие профили.
- Потоки данных используются для выбора соответствующих сегментов пользователей (например, людей, интересующихся автомобильной промышленностью) и использования их в онлайн-кампании. Сегменты обогащаются дополнительными пользовательскими характеристиками из потока данных и затем отправляются в DSP.
Визуальные источники данных
В потоке данных видно, какое устройство использовалось на стороне пользователя - это видно в пользовательском агенте :
- мобильный - когда пользователь использует мобильный браузер для исследования, у него узкое разрешение экрана и версия мобильного приложения соответственно;
- рабочий стол - когда пользователь использует настольный браузер или версию приложения.
Следующая информация передается об используемом устройстве:
- Фактический URL-адрес посещенного веб-сайта, на котором произошло событие
- Пользовательский агент
- Геолокация
- Интернет-протокол (IP)
Форматы
Точка данных - это тег, который собирает информацию об определенном действии, выполненном пользователем на веб-сайте. Точки данных существуют двух типов, значения которых используются для создания соответствующих аудиторий. Это:
- "событие" с информацией о наступлении определенного события (например, нажатие на ссылку или показ рекламы)
- "атрибут" с числовыми или буквенно-цифровыми значениями.
Сегмент - это логический оператор, построенный на определенных точках данных с использованием операторов AND, OR или NOT.
Гибридные данные - необработанные данные из форматов данных точки и сегмента.
URL-адреса - это набор информации о конкретном URL-адресе , который был посещен.
GDPR
Информация, собираемая с веб-сайтов, основана на поведении пользователей. Поставщики данных предоставляют как личную, так и неличную информацию. В потоке данных доступны два типа пользовательских данных:
- Персональные данные (PII) , - информация , которая позволяет четко или путем комбинирования с методами идентификации данных идентификации личности. Примеры PII: страховой идентификатор, адрес электронной почты, номер телефона, IP-адрес , геолокация, биометрические данные .
- Non-личная информация (не PII) является информацией , которая не может быть использована для идентификации личности или для отслеживания местоположения. Файл cookie или идентификатор устройства - это пример не-PII.
Вау!! 😲 Ты еще не читал? Это зря!
- Стандартные потоки
- Враппер
- Именованный канал
- Битовый поток
- Служба оповещения
- Алгоритм потока данных
- Программирование , ориентированное на поток данных
- Поток данных
- Протокол потоковой передачи
- Простой API для XML (SAX)
- Потоковый API для XML (StAX)
- Потоковые преобразования для XML (STX)
Надеюсь, эта статья про поток данных, была вам полезна, счастья и удачи в ваших начинаниях! Надеюсь, что теперь ты понял что такое поток данных
и для чего все это нужно, а если не понял, или есть замечания,
то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Операционные системы и системное программировние
Из статьи мы узнали кратко, но содержательно про поток данных

Комментарии