Лекция
Это продолжение увлекательной статьи про .
...
решения (полученные, возможно, с помощью ОО-технологии). Из всего этого становится очевидным, что основной трудностью реализации повторного использования является не организация использования повторно используемых компонентов, а в первую очередь - создание этих чертовых штуковин.
На стыке технических и организационных проблем возникает вопрос: как следует связывать индексирующую информацию, например ключевые слова с программными компонентами?
Принцип Самодокументирования говорит о том, что вся информация о модуле, включая индексирующую информацию и другие виды документации, - должна содержаться в самом модуле. Это важное требование учтено при разработке нотации классов, развиваемой в лекциях 7-18 этого курса. Механизм предусматривает возможность подключения данных индексирования к каждому компоненту.
Описание соответствующей синтаксической структуры не вызывает затруднений. В начале текста модуля предлагается написать предложение индексирования (indexing clause) в виде
Indexing
index_word1: value, value, value ...
index_word2: value, value, value ...
...
... Стандартное описание модуля (см. лекции 7-18) ...
Здесь каждое index_word (то есть - индексное слово) это идентификатор; каждое value (то есть - значение) это константа (целая, вещественная и т. д.), идентификатор, или какой либо другой стандартный лексический элемент. (Более подробно см. "Операторы индексирования", курса "Основы объектно-ориентированного проектирования")
Конкретные ограничения на выбор индексных слов и соответствующих значений отсутствуют, но какая либо отрасль промышленности, ассоциация по вопросам стандартизации (standards group), организация или проектная группа может, при необходимости, определить свои правила. Средства индексирования и поиска могут затем извлекать эту информацию, чтобы помочь разработчикам ПО в отыскании компонентов, удовлетворяющих определенным критериям.
Еще одной задачей, охватывающей как технические, так и организационные проблемы, является выбор представления для распространения: исходный текст или двоичный формат? Это спорный вопрос, и мы ограничимся рассмотрением только нескольких доводов с обеих сторон.
Разработчики коммерческого ПО часто распространяют лишь описание интерфейса (соответствующая краткая форма (short form) рассматривается в одной из последующих лекций) и исполняемый код. Тем самым разработчики защищают секреты производства и свои инвестиции. ("Использование утверждений (assertions) для документирования: сокращенная форма класса", )
Для изготовителя программного компонента польза от распространения исходного текста состоит в том, что это облегчает перенос программ (porting efforts). Можно избежать утомительной и малорентабельной деятельности по адаптации ПО к множеству несовместимых платформ, существующих в современном компьютерном мире, рассчитывая на то, что разработчики ОО-компиляторов и программных сред выполнят эту работу за вас. (Для потребителя это, конечно, контраргумент, поскольку инсталляция исходного текста более трудоемка и может привести к непредвиденным ошибкам.)
Возможно, более важным доводом в пользу распространения текста исходного кода является то, что попытки защитить свои изобретения и секреты производства путем удаления исходного текста из реализации программного продукта могут не приносить никакой существенной пользы. Самая трудоемкая работа при составлении хорошей повторно используемой библиотеки связана с проектированием интерфейсов компонентов, а не с реализацией; и именно это вы вынуждены опубликовать. Это особенно очевидно в мире структур данных и алгоритмов, для которых почти все необходимые методы описаны в литературе по компьютерным наукам. Чтобы успешно создать библиотеку, требуется встроить эти методы в модули, интерфейс которых сделает их полезными для разработчиков многих других приложений. Такое проектирование интерфейса является частью того, что вы должны выпустить в свет.
Важно отметить, что в случае ОО-модулей имеются две формы повторного использования компонентов: клиентами класса и наследниками класса. Вторая из этих форм объединяет повторное использование с расширяемостью. Описания интерфейсов (краткая форма) достаточно для клиентов, но не всегда достаточно для повторного использования на основе наследования.
Наконец, о педагогической стороне проблемы. Распространение исходных текстов библиотечных модулей является средством представления лучших образцов разработки ПО, способствующее разработке потребителями ПО в соответствующем стиле. Возникающая при этом стандартизация является одним из достоинств повторного использования. В определенной степени это будет иметь место даже в случае, когда доступны лишь интерфейсы, но лучше всего иметь полный текст.(Этот вопрос обсуждается в лекции, посвященной обучению ОО-технологии, в курса "Основы объектно-ориентированного проектирования".)
| Заметьте, что даже если доступен исходный код, то он не должен служить в качестве основного средства документации: для этого по-прежнему будет использоваться интерфейс модуля. |
Это обсуждение затронуло некоторые спорные экономические вопросы, обусловленные отчасти появлением промышленного производства компонентов ПО и, в более общем плане, прогрессом в области ПО. Как же справедливо вознаградить разработчиков за их достижения и обеспечить приемлемую степень защиты их изобретений, не нарушая законных интересов пользователей? Существуют две противоположные точки зрения:
[x]. С одной стороны, это принципы Лиги Сторонников Свободного Программирования (League for Programming Freedom): все ПО должно быть бесплатным и доступным в форме исходных текстов.(См. библиографические замечания.)
При любом всестороннем подходе к проблемам повторного использования следует наряду с техническими аспектами рассмотреть организационные и экономические вопросы: как сделать повторное использование частью культуры разработки ПО, как найти правильную структуру стоимости и правильную форму распространения компонентов, создать соответствующие средства для индексирования и поиска компонентов. Неудивительно, что эти вопросы легли в основу основных инициатив по повторному использованию, исходивших от правительств и больших корпораций, таких как программа STARS (Software Technology for Adaptable, Reliable Systems - Технология создания ПО для адаптивных, надежных систем) Министерства обороны США и "фабрики ПО" ("software factories"), введенные в действие некоторыми большими японскими фирмами.
Оставшаяся часть данной лекции посвящена первому из этих вопросов. В ней выясняется, почему общепринятые понятия модуля непригодны для широкомасштабного повторного использования, и определяются требования, которым должно удовлетворять лучшее решение, предлагаемое в последующих лекциях.
Как же должен выглядеть повторно используемый модуль?
Разработка ПО, как уже упоминалось, во многом связана с повторяемостью. Для понимания технической трудности повторного использования, следует понять природу повторяемости.
Несмотря на то, что программисты обычно время от времени повторяют одни и те же действия, но эти действия являются не совсем одинаковыми. Ведь если бы они были одинаковыми, то решение оказалось бы простым, по крайней мере, на бумаге. Однако на практике может измениться настолько много деталей задачи, что любая бесхитростная попытка обеспечить ее унификацию потерпит неудачу.
| Наглядной иллюстрацией являются работы норвежского художника Эдварда Мунка, многие из которых можно видеть в посвященном ему музее в Осло, на родине языка программирования Simula. Творчеством Мунка владели несколько жизненно-важных, глубоких тем: любовь, страдание, ревность, танец, смерть. Он без конца воспроизводил их в своих рисунках и живописи, пользуясь всякий раз одними и теми же образцами, но меняя технические приемы, цвета, резкость контуров, размер, освещение, настроение. |
В таком же положении находится и разработчик ПО, создавая новые варианты, развивающие одни и те же основные темы.
Возьмем пример, упоминавшийся в начале этой лекции: табличный поиск. Несомненно, алгоритм табличного поиска в общем виде всегда выглядит одинаково: начать с некоторой позиции в таблице t, затем приступить к последовательному просмотру таблицы, всякий раз проверяя, является ли искомым элемент в текущей позиции и, если это не так, то переходить к следующей позиции. Процесс завершается, если найден нужный элемент, либо проверка всех элементов оказалась безуспешной. Такая общая схема применима к многим возможным случаям представления данных и алгоритмам для табличного поиска, в том числе в массивах (отсортированных или не отсортированных), связных списках (отсортированных или не отсортированных), последовательных файлах, двоичных деревьях, Б-деревьях и различных хеш-таблицах.
Нетрудно превратить это неформальное описание в частично детализированную подпрограмму:
has (t: TABLE, x: ELEMENT): BOOLEAN is -- Присутствует ли x в t? local pos: POSITION do from pos := INITIAL_POSITION (x, t) until EXHAUSTED (pos, t) or else FOUND (pos, x, t) loop pos := NEXT (pos, x, t) end Result := not EXHAUSTED (pos, t) end
Хотя приведенный выше текст описывает общую схему работы алгоритма, он не является непосредственно выполняемым, поскольку содержит некоторые не вполне определенные фрагменты (написанные заглавными буквами). Они соответствуют аспектам задачи табличного поиска, зависящим от выбранной реализации: тип элементов таблицы (ELEMENT), с какой позиции начинать поиск (INITIAL_POSITION), как переходить от текущей позиции к следующей (NEXT), как проверить наличие искомого элемента на некоторой позиции (FOUND), как определить, что все интересующие нас позиции уже проверены (EXHAUSTED).
Поэтому вышеприведенный текст является не столько подпрограммой, а шаблоном подпрограммы, который можно превратить в действующую подпрограмму, лишь после уточнения фрагментов, написанных заглавными буквами.
Наличие всех этих вариантов выдвигает на первый план проблемы, возникающие при любой попытке размышлять над созданием модулей общего назначения в заданной прикладной области: как же воспользоваться наличием единого шаблона для согласования с таким большим числом различных вариантов? Это не только проблема реализации: почти так же трудно специфицировать модуль таким образом, чтобы модули-клиенты могли рассчитывать на взаимодействие с ним, не располагая его реализацией.
По этим соображениям обречены на неуспех простые решения проблемы повторного использования. Ввиду многосторонности и изменчивости ПО - не зря оно называется "soft - модули, не обладающие "гибкостью", не могут претендовать на возможность повторного использования.
"Замороженность" модуля приводит к дилемме - повторно использовать или переделать: повторно использовать модуль таким, какой он есть, или заново все переделать. Оба подхода слишком ограничительные. Типичная ситуация, когда существует модуль, обеспечивающий лишь частичное решение текущей задачи, и требуется адаптация модуля к конкретным потребностям. В этом случае желательно и повторно использовать и переделать: кое что повторно использовать, а кое что переделать - или, лучше всего, многое повторно использовать, а совсем немного переделать. Без способности объединения возможностей повторного использования и адаптации, методы повторного использования не могут удовлетворять практическим потребностям разработки ПО.
Поэтому не случайно почти любое обсуждение проблем повторного использования в этой книге затрагивает и проблему расширяемости (что приводит к охватывающему оба эти понятия термину "модульность", являющегося предметом обсуждения в предыдущей лекции). Всякий раз, когда вы начнете искать ответы на одно из этих требований, вы тут же столкнетесь и с другим требованием.
Такая взаимозависимость между повторным использованием и расширяемостью отмечалась ранее при обсуждении принципа Открыт-Закрыт. (См. "Принцип Открыт-Закрыт", )
Поиску подходящего представления модуля посвящена оставшаяся часть этой лекции и несколько следующих лекций. Нам предстоит согласовать между собой возможность повторного использования и расширяемость, закрытость и открытость, постоянство и изменчивость. Нам следует удовлетворить сегодняшние потребности и попытаться отгадать, что же понадобится завтра.
Как же найти такие модульные структуры, которые позволят создать компоненты, непосредственно готовые к повторному использованию, и, в то же время, допускающие возможность их адаптации?
Задача табличного поиска и шаблон подпрограммы has иллюстрируют жесткие требования, предъявляемые к любому решению. Можно воспользоваться этим примером для выяснения, что же следует предпринять для перехода от обнаружения относительно нечеткой общности вариантов к реальному набору повторно используемых модулей. Такой анализ выявляет пять важных проблем:
[x]. Изменчивость Типов (Type Variation).
[x]. Группирование Подпрограмм (Routine Grouping).
[x]. Изменчивость Реализаций (Implementation Variation).
[x]. Факторизация Общего Поведения (Factoring Out Common Behaviors).
Шаблон подпрограммы has предполагает, что таблица содержит объекты типа ELEMENT. При уточнении этой подпрограммы в применении к частному случаю можно использовать конкретный тип, например INTEGER или BANK_ACCOUNT, для таблицы целых чисел или банковских счетов.
Но это не совсем то, что требуется. Повторно используемый модуль поиска должен быть применим ко многим различным типам элементов без того чтобы пользователи вынуждены были производить "вручную" изменения в тексте программы. Другими словами, необходимо средство для описания модулей, в которых типы выступают в роли параметров (type-parameterized), или короче - родовых (полиморфных) модулей. Универсальность или полиморфность (genericity) (способность модулей быть родовыми) окажется важной частью ОО-метода; обзор этой концепции дается далее в этой лекции. (См. "Универсальность" ("Genericity"), )
Шаблон подпрограммы has, даже если его полностью детализировать и ввести параметризацию типа, все еще не будет пригоден в качестве повторно используемого компонента. Поиск в таблице зависит от того, как таблица создавалась, как в нее включаются элементы, как они удаляются. Отдельно взятая программа поиска - это еще не модуль повторного использования. Самодостаточный, повторно используемый модуль должен включать множество подпрограмм, обеспечивающих каждую из упомянутых операций - создание, включение, удаление, поиск.
Эта идея лежит в основе формирования модуля как "пакета", что имеет место в языках с инкапсуляцией таких как: Ada, Modula-2 и родственных им языках. Более подробно об этом будет сказано ниже.
Шаблон has является весьма общим; и, как мы уже убедились, на практике имеется широкий выбор соответствующих структур данных и алгоритмов. Нельзя ожидать, что один модуль сможет обеспечить работу в столь разнообразных условиях, - он оказался бы просто огромным. Для охвата всех возможных реализаций требуется семейство модулей.
Общая методика создания и применения повторно используемых модулей должна поддерживать идею семейства модулей.
Общая структура повторно используемого модуля должна позволять модулям-клиентам определять свои действия при отсутствии сведений о реализации модуля. Это требование называется Независимостью Представлений.
Предположим, что модулю-клиенту C некоторой прикладной системы (управления ресурсами банка, компилятора, системы географической информации) необходимо определить, содержится ли некоторый элемент x в некоторой таблице t (вкладов, слов языка, городов). Независимость Представлений для C означает возможность получить такую информацию с помощью обращения к подпрограмме
present := has (t, x)
не зная, какой вид имеет таблица t во время этого обращения. Автору модуля C нужно лишь знать, что t-это таблица из элементов определенного типа, и что x означает объект того же типа. Ему безразлично, является ли t деревом двоичного поиска, хеш-таблицей или связным списком. Он должен иметь возможность сосредоточиться на своей задаче управления активами, компиляции или географии.
Выбор подходящего алгоритма поиска, основанного на реализации таблицы t, является делом лишь того модуля, который организует эту таблицу.
Модуль-клиент C, содержащий упомянутое обращение к подпрограмме, мог бы получить t от одного из своих собственных клиентов (в виде аргумента вызова подпрограммы). Тогда для C имя t является лишь абстрактным идентификатором структуры данных, к детальному описанию которой он и не может иметь доступа.
if "t это массив, управляемый хешированием" then "Применить поиск с хешированием" elseif "t это дерево двоичного поиска" then "Применить обход дерева двоичного поиска" elseif (и т.д.) end
Было бы в равной степени неудобно иметь такую структуру в самом модуле (нельзя же ожидать, что модуль, организующий таблицу, знает обо всех текущих и будущих вариантах), так и воспроизводить ее в каждом модуле-клиенте. (См. "Единственный выбор", ) Решение состоит в том, чтобы обеспечить автоматический выбор, осуществляемый системой исполнения. Такова будет роль динамического связывания (dynamic binding), ключевой составляющей ОО-подхода, которая подробно будет рассматриваться при обсуждении наследования. (См. "Динамическое связывание" ("Dynamic binding"), )
Если требование Независимости Представлений отражает позицию клиента - игнорирование внутренних деталей и вариантов реализации - то последнее требование отражает позицию разработчиков повторно используемых классов. Их цель в получении преимуществ от любой общности (commonality), которая может существовать в семействе или подсемействе реализаций.
Многообразие реализаций, имеющее место в некоторых проблемных областях, требует, как уже отмечалось, решения, основанного на семействе модулей. Часто это семейство настолько велико, что естественно поискать соответствующие подсемейства. В случае табличного поиска первая попытка классификации может привести к трем обширным подсемействам:
[x]. Таблицы, организуемые по некоторой схеме хеширования.
[x]. Таблицы, организуемые как некоторая разновидность деревьев.
[x]. Таблицы, организуемые последовательно.
Каждая из этих категорий охватывает много вариантов, но в большинстве случаев можно найти существенную общность между этими вариантами. Рассмотрим, например, семейство последовательных реализаций - таких, в которых элементы сохраняются и отыскиваются в порядке их первоначального включения в таблицу.
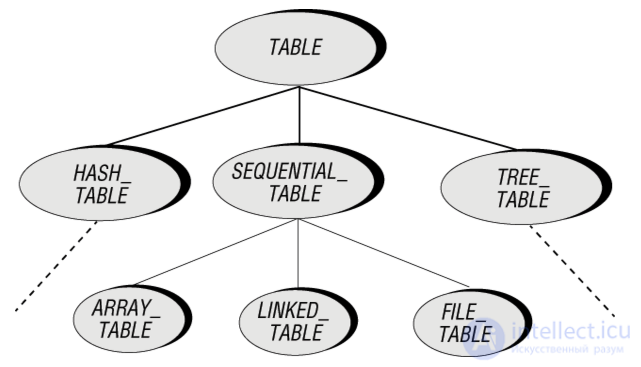
Рис. 4.1. Некоторые возможные реализации таблицы
Возможными представлениями последовательной таблицы являются массив, связный список и файл. Но независимо от варианта такой реализации, клиенты должны иметь возможность для любой последовательно организованной таблицы рассматривать ее элементы один за другим, перемещая (воображаемый) курсор, указывающий позицию элемента, рассматриваемого в настоящий момент. При таком подходе можно переписать подпрограмму поиска для последовательных таблиц в виде:
has (t: SEQUENTIAL_TABLE; x: ELEMENT): BOOLEAN is -- Содержится ли x в последовательной таблице t? do from start until after or else found (x) loop forth end Result := not after end
[x]. start (начать) , переместить курсор к первому элементу, если он имеется.
[x]. forth (следующий) , переместить курсор к следующей позиции.
[x]. after (после) , булев запрос, переместился ли курсор за последний элемент.
[x]. found (x) , булев запрос, возвращающий true, когда курсор указывает на элемент, имеющий значение x.
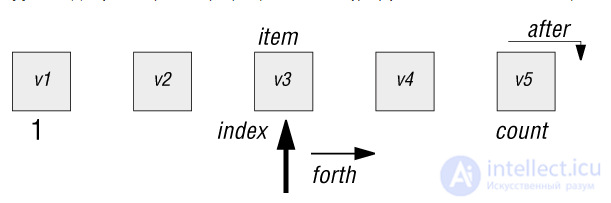
Рис. 4.2. Последовательная структура с курсором
Несмотря на сходство с шаблоном подпрограммы, использованным в начале этого обсуждения, новый текст - это уже не шаблон, это настоящая подпрограмма, написанная в непосредственно исполняемой нотации (такая нотация используется в лекциях 7-18 этого курса). Если задать реализации для четырех операций start, forth, after и found, то можно откомпилировать и выполнить последнюю версию has.
Каждое представление последовательной таблицы требует соответствующего представления курсора. Три примера таких представлений основаны на работе с массивом, связным списком и файлом.
В первом из них используется массив из capacity элементов, и таблица занимает позиции от 1 до count + 1. (Последнее значение необходимо в случае, когда курсор переместился на позицию после ("after") последнего элемента.)

Рис. 4.3. Представление последовательной таблицы с курсором на основе массива
Во втором представлении используется связный список, в котором доступ к первому элементу обеспечивается по ссылке first_cell и каждый элемент связан со следующим по ссылке right. При этом курсор можно представить ссылкой cursor.
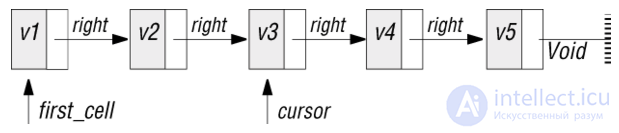
Рис. 4.4. Представление последовательной таблицы с курсором на основе связного списка
В третьем представлении используется последовательный файл, в котором курсор представляет просто текущую позицию чтения.
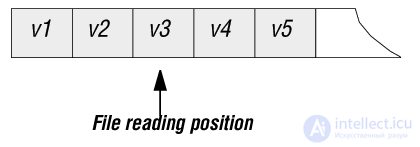
Рис. 4.5. Представление последовательной таблицы с курсором на основе последовательного файла
Реализация операций start, forth, after и found будет разной для каждого из вариантов. В следующей таблице4.3) показана реализация для каждого случая. Здесь t @ i означает i-й элемент массива t, который записывается как t [i] в языках Pascal или C; Void означает "пустую" ссылку; обозначение f- языка Pascal, для файла f, означает элемент в текущей позиции чтения из файла.
| start | forth | after | found (x) | |
| Массив | i :=1 | i :=i + 1 | i >count | t @ i =x |
| Связный список | c := first_cell | c :=c. right | c =Void | c. item =x |
| Файл | rewind | read | end_of_file | f -=x |
Таблица 4.1.Классы и методы
Повторное использование позволяет избежать ненужное дублирование, используя общность вариантов. Если в разных модулях появляются одинаковые или почти одинаковые фрагменты, то трудно обеспечить их целостность и гарантировать, что изменения или поправки достигли всех требуемых мест системы. Вновь могут возникнуть проблемы с управлением конфигурацией системы.
Наряду с требованиями к модульности, изложенными в предыдущей лекции, пять требований Изменчивости Типов, Группирования Подпрограмм, Изменчивости Реализаций, Независимости Представлений и Факторизации Общего Поведения определяют, чего следует ожидать от наших повторно используемых компонентов - абстрактных модулей.
Рассмотрим решения, предшествовавшие ОО-подходу, чтобы понять, что нас не устраивает, и что следует взять с собой в ОО-мир.
Классический подход к повторному использованию состоит в том, чтобы создавать библиотеки подпрограмм. Здесь термин подпрограмма (routine) означает программный элемент, который может быть вызван другими элементами для выполнения некоторого алгоритма, используя некоторые входные данные, создавая некоторые выходные данные, и, возможно, модифицируя другие данные. Вызывающий элемент передает свои входные данные (а иногда - выходные данные и модифицируемые данные) в виде фактических аргументов (actual arguments) . Подпрограмма может также возвращать выходные данные в виде результата; в этом случае она называется функцией.
Библиотеки подпрограмм успешно использовались в различных прикладных областях, в частности, для численных расчетов, где применение отличных библиотек привело к первым сообщениям об успехах повторного использования. Декомпозицию систем на подпрограммы, функциональную декомпозицию обеспечивает также метод нисходящего (сверху вниз) программирования. Подход, основанный на использовании библиотек подпрограмм, хорошо работает в случаях, когда можно определить множество (возможно - большое) отдельных задач, при наличии следующих ограничений:
[x]. R1 Каждая задача допускает простую спецификацию. Точнее, возможно охарактеризовать каждую отдельную задачу небольшим набором входных и выходных параметров.
[x]. R2 Задачи четко отличаются одна от другой, поскольку подход, основанный на подпрограммах, не позволяет воспользоваться возможной сколько-нибудь существенной их общностью - за исключением повторного использования некоторых конструкций.
[x]. R3 Отсутствуют сложные структуры данных, которые пришлось бы распределять между использующими их подпрограммами.
Поиск в таблице является хорошим примером ограниченных возможностей подпрограмм. Мы уже убедились, что подпрограмма поиска сама по себе не содержит достаточного контекста, чтобы служить в качестве функционально-завершенного модуля повторного использования. Даже если не обращать внимания на этот недостаток, мы столкнемся с двумя в равной степени неприятными решениями:
[x]. Подпрограмма поиска существует в одном варианте. Но тогда, чтобы охватить все возможные ситуации, ей потребуется длинный список аргументов и она окажется очень сложной.
[x]. Подпрограмм поиска много, каждая из которых относится к конкретному случаю и отличается от других лишь немногими деталями. Нарушается требование Факторизации Общего Поведения; возможные пользователи легко могут заблудиться в неразберихе подпрограмм.
В целом, подпрограммы являются недостаточно гибкими, чтобы удовлетворять потребностям повторного использования. Мы уже видели тесную связь между возможностью повторного использования и расширяемостью. Повторно используемый модуль должен быть открыт для расширения, но в случае подпрограммы единственным средством адаптации является передача аргументов. Это делает нас заложником дилеммы - Повторно использовать или Переделать: либо пользоваться этой подпрограммой в ее исходном виде,
продолжение следует...
Часть 1 4. Подходы к повторному использованию
Часть 2 Несколько слов об индексировании компонентов - 4. Подходы к повторному
Часть 3 Пакеты - 4. Подходы к повторному использованию
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

Комментарии
Оставить комментарий
Объектно-ориентированное программирование ООП
Термины: Объектно-ориентированное программирование ООП