Лекция
Привет, мой друг, тебе интересно узнать все про паттерны организации источников данных, тогда с вдохновением прочти до конца. Для того чтобы лучше понимать что такое паттерны организации источников данных , настоятельно рекомендую прочитать все из категории Объектно-ориентированное программирование ООП.
Роль слоя источника данных состоит в том, чтобы обеспечить возможность взаимодействия приложения с различными компонентами инфраструктуры для выполнения необходимых функций. Главная составляющая подобной проблемы связана с поддержкой диалога с базой данных - в большинстве случаев реляционной. До сих пор изрядные массивы данных все еще хранятся в устаревших форматах, но практически все разработчики современных приложений, предусматривающих связь с системами баз данных, ориентируются на реляционные СУБД.
Одной из самых серьезных причин успеха реляционных систем является поддержка ими SQL - наиболее стандартизованного языка коммуникаций с базой данных. Хотя сегодня SQL все более обрастает раздражающе несовместимыми и сложными "улучшениями", поддерживаемыми различными поставщиками СУБД, синтаксис ядра языка, к счастью, остается неизменным и доступным для всех.
В первую обойму архитектурных решений входят, в частности, и такие, которые оговаривают способы взаимодействия бизнес-логики с базой данных. Выбор, который делается на этом этапе, имеет далеко идущие последствия и отменить его бывает трудно или даже невозможно. Поэтому он заслуживает наиболее тщательного осмысления. Нередко подобными решениями как раз и обусловливаются варианты компоновки бизнес-логики.
Несмотря на широкую поддержку корпоративными приложениями, использование SQL сопряжено с определенными трудностями. Многие разработчики просто не владеют SQL и потому, пытаясь сформулировать эффективные запросы и команды, сталкиваются с проблемами. Помимо того, все без исключения технологии внедрения предложений SQL в код на языке программирования общего назначения страдают теми или иным изъянами. (Безусловно, было бы лучше осуществлять доступ к содержимому базы данных с помощью неких механизмов уровня языка разработки приложения.) А администраторы баз данных хотели бы уяснить нюансы обработки SQL-выражений, чтобы иметь возможность их оптимизировать.
По этим причинам разумнее обособить код SQL от бизнес-логики, разместив его в специальных классах. Удачный способ организации подобных классов состоит в "копировании" структуры каждой таблицы базы данных в отдельном классе, который формирует шлюз (Gateway,), поддерживающий возможности обращения к таблице. Теперь основному коду приложения нет необходимости что-либо "знать" о SQL, а все SQL-операции сосредоточиваются в компактной группе классов.
Существует два основных варианта практического использования типового решения шлюз. Наиболее очевидный - создание экземпляра шлюза для каждой записи, возвращаемой в результате обработки запроса к базе данных (рис. 3.7). Подобный шлюз записи данных (Row Data Gateway,) представляет собой модель, естественным образом отображающую объектно-ориентированный стиль восприятия реляционных данных.
Во многих средах поддерживается модель множества записей (Record Set) - одна из основополагающих структур данных, имитирующая табличную форму представления содержимого базы данных. Инструментальными системами предлагаются даже графические интерфейсные элементы, реализующие схему множества записей. С каждой таблицей базы данных следует сопоставить соответствующий объект типа шлюз таблицы данных (Table Data Gateway) (рис. 3.8), который содержит методы активизации запросов, возвращающих множество записей.
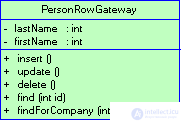
Рисунок 3.7 Для каждой записи, возвращаемой запросом, создается экземпляр шлюза записи данных
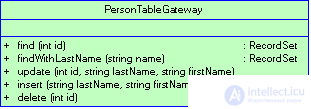
Рисунок 3.8 Для каждой таблицы базы данных создается экземпляр шлюза таблицы данных
Тот факт, что шлюз таблицы данных удачно сочетается с множеством записей, обеспечивает такому варианту шлюза очевидные преимущества при использовании модуля таблицы (Table Module). Это типовое решение следует иметь в виду и при работе с хранимыми процедурами. Нередко предпочтительно осуществлять доступ к базе данных только при посредничестве хранимых процедур, а не с помощью прямых обращений.
В подобной ситуации, определяя шлюз таблицы данных для каждой таблицы, следует
предусмотреть и коллекцию соответствующих хранимых процедур. Возможно так же создание в памяти еще и дополнительного шлюза таблицы данных, выполняющий функцию оболочки, которая могла бы скрыть механизм вызовов хранимых процедур.
При использовании модели предметной области (Domain Model) возникают другие альтернативы. В этом контексте уместно применять и шлюз записи данных, и шлюз таблицы данных. Впрочем, иногда в данной ситуации эти решения могут оказаться не вполне целенаправленными или просто несостоятельными.
В простых приложениях модель предметной области представляет отнюдь не сложную структуру, которая может содержать по одному классу домена в расчете на каждую таблицу базы данных. Объекты таких классов часто снабжены умеренно сложной бизнес-логикой. В этом случае имеет смысл возложить на каждый из них и ответственность за ввод-вывод данных, что, по существу, равносильно применению решения активная запись (Active Record) (рис. 3.9). Это решение можно воспринимать и так, будто, начав со шлюза записи данных, мы добавили в класс порцию бизнес-логики (может быть, когда обнаружили в нескольких сценариях транзакции (Transaction Script) повторяющиеся фрагменты кода).
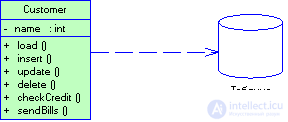
Рисунок 3.9 При использовании паттерна Active Record объект класса домена осведомлен о том, как взаимодействовать с базой данных
В подобного рода ситуациях дополнительный уровень опосредования, формируемый за счет применения шлюза, не представляет большой ценности. По мере усложнения бизнес-логики и возрастания значимости богатой модели предметной области простые решения типа активная запись начинают сдавать свои позиции. При разнесении бизнес-логики по все более мелким классам взаимно однозначное соответствие между классами домена и таблицами базы данных постепенно теряется. Реляционные базы данных не поддерживают механизм наследования, что затрудняет применение стратегий (strategies) и других развитых объектно-ориентированных типовых решений. А когда бизнес-логика становится все более беспорядочной, желательно иметь возможность ее тестирования без необходимости постоянно обращаться к базе данных. С усложнением модели предметной области все эти обстоятельства вынуждают создавать промежуточные функциональные уровни. Так, решение типа шлюза способно устранить некоторые проблемы, но оно все еще оставляет нас с моделью предметной области, тесно привязанной к схеме базы данных. В результате при переходе от полей шлюза к полям объектов домена приходится выполнять определенные преобразования, которые приводят к усложнению объектов домена.
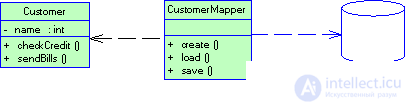
Рисунок 3.10 Преобразователь данных изолирует объекты домена от базы данных
Более удачный вариант состоит в том, чтобы изолировать модель предметной области от базы данных, возложив на промежуточный слой всю полноту ответственности за отображение объектов домена в таблицы базы данных. Подобный преобразователь данных (Data Mapper) (рис. 3.10) обслуживает все операции загрузки и сохранения информции, инициируемые бизнес-логикой, и позволяет независимо варьировать как модель предметной области, так и схему базы данных. Это наиболее сложное из архитектурных решений, обеспечивающих соответствие между объектами приложения и реляционными структурами, но его неоспоримое преимущество заключается в полном обособлении двух слоев.
Я не рекомендовал бы рассматривать шлюз в качестве основного механизма сохранения данных в контексте модели предметной области. Если бизнес-логика действительно проста и степень соответствия между классами и таблицами базы данных высока, удачной альтернативой окажется типовое решение активная запись. Если же вам приходится иметь дело с чем-то более сложным, самым лучшим выбором, вероятнее всего, будет преобразователь данных.
Рассмотренные типовые решения нельзя считать взаимоисключающими. В большинстве случаев речь будет идти о механизме сохранения информации из неких структур памяти в базе данных. Для этого придется выбрать одно из перечисленных решений - смешение подходов чревато неразберихой. Но даже если в качестве инструмента доступа к базе данных применяется, скажем, преобразователь данных, для создания оболочек таблиц или служб, трактуемых как внешние интерфейсы, вы вправе использовать, например, шлюз. Здесь и ниже, употребляя слово таблица (table), имеется в виду, что обсуждаемые приемы и решения применимы в равной мере ко всем данным, отличающимся табличным характером: к хранимым процедурам (stored procedures), представлениям (views), а так-же к промежуточным результатам выполнения "традиционных" запросов и хранимых процедур. К сожалению, какой-либо общий термин, который охватывал бы все эти понятия, отсутствует
Операции обновления (update) содержимого источников, не являющихся хранимыми таблицами, очевидно, более сложны, поскольку представление далеко не всегда можно модифицировать напрямую — вместо этого приходится манипулировать таблицами, на основе которых оно создано. В этом случае инкапсуляция представления/запроса с помощью подходящего типового решения — хороший способ сосредоточить логику операций обновления в одном месте, что делает использование виртуальных структур более простым и безопасным.
Впрочем, проблемы все еще остаются. Непонимание природы формирования виртуальных таблиц приводит к несогласованности операций: если последовательно выполнить операции обновления двух различных структур, построенных на основе одних и тех же хранимых таблиц, вторая операция способна повлиять на результаты первой. Конечно, в логике обновления можно предусмотреть соответствующие проверки, направленные на то, чтобы избежать возникновения подобных эффектов, но какую цену за все это придется заплатить.
Я обязан также упомянуть о самом простом способе сохранения данных, который можно использовать даже в наиболее сложных моделях предметной области. Еще на заре эпохи объектов многие осознали, что существует фундаментальное расхождение между реляционной и объектной моделями; это послужило стимулом создания объектно-ориентированных СУБД, расширяющих парадигму до аспектов сохранения информации об объектах на дисках. При работе с объектно-ориентированной базой данных вам не нужно заботиться об отображении объектов в реляционные структуры. В вашем распоряжении набор взаимосвязанных объектов, а о том, как и когда их считывать или сохранять, "беспокоится" СУБД. Помимо того, с помощью механизма транзакций вы вправе группировать операции и управлять совместным доступом к объектам. Для программиста все это выглядит так, словно он взаимодействует с неограниченным пространством объектов, размещенных в оперативной памяти.
Главное преимущество объектно-ориентированных баз данных - повышение производительности разработки приложений: хотя какие-либо воспроизводимые тестовые показатели официально не публиковались, в неформальных беседах постоянно высказываются суждения о том, что затраты на обеспечение соответствия между объектами приложения и реляционными структурами традиционной базы данных составляют приблизительно треть от общей стоимости проекта и не снижаются в течение всего цикла сопровождения системы.
В большинстве случаев, однако, объектно-ориентированные базы данных применения не находят, и основная причина такого положения вещей - риск. За реляционными СУБД стоят тщательно разработанные, хорошо знакомые и проверенные жизнью технологии, поддерживаемые всеми крупными поставщиками систем баз данных на протяжении длительного времени. SQL представляет собой в достаточной мере унифицированный интерфейс для разнообразных инструментальных средств.
Если у вас нет возможности или желания воспользоваться объектно-ориентированной базой данных, то, делая ставку на модель предметной области, вы должны серьезно изучить варианты приобретения инструментов отображения объектов в реляционные структуры. Хотя рассмотренные в типовые решения сообщат вам многое из того, что необходимо знать для конструирования эффективного преобразователя данных, на этом поприще от вас все еще потребуются значительные усилия. Поставщики коммерческих инструментов, предназначенных для "связывания" объектно-ориентированных приложений с реляционными базами данных, затратили многие годы на разрешение подобных проблем, и их программные продукты во многом более изобретательны, гибки и мощны, нежели те, которые можно "состряпать" кустарным образом. Сразу оговорюсь, что они недешевы, но затраты на их возможную покупку следует сопоставить со значительными расходами, которые вам придется понести, избрав путь самостоятельного создания и сопровождения этого слоя программного кода.
Нельзя не вспомнить о попытках разработки образцов слоя кода в стиле объектно-ориентированных СУБД, способного взаимодействовать с реляционными системами. В мире Java таким "зверем", например, является JDO, но о достоинствах или недостатках этой технологии пока нельзя сказать ничего определенного. У меня слишком малый опыт ее применения, чтобы приводить на страницах этой книги какие-либо категорические заключения.
Даже если вы решились на приобретение готовых инструментов, знакомство с представленными здесь типовыми решениями вовсе не помешает. Хорошие инструментальные системы предлагают обширный арсенал альтернатив "подключения" объектов к реляционным базам данных, и компетентность в сфере типовых решений поможет вам прийти к осмысленному выбору. Не думайте, что система в одночасье избавит вас от всех проблем; чтобы заставить ее работать эффективно, вам придется приложить изрядные усилия.
Название
Table Data Gateway (шлюз таблицы данных)
Назначение
Использование SQL в логике приложений может быть связано с некоторыми проблемами. Не все разработчики владеют языком SQL или хорошо в нем разбираются. В свою очередь, администраторы СУБД должны иметь удобный доступ к командам SQL для настройки и расширения своих баз данных.
Типовое решение шлюз таблицы данных содержит в себе все команды SQL, необходимые для извлечения, вставки, обновления и удаления данных из таблицы или представления. Методы этого типового решения используются другими объектами для взаимодействия с базой данных.
Принцип действия
Интерфейс шлюза таблицы данных чрезвычайно прост. Обычно он включает в себя несколько методов поиска, предназначенных для извлечения данных, а также методы обновления, вставки и удаления. Каждый метод передает входные параметры вызову соответствующей команды SQL и выполняет ее в контексте установленного соединения с базой данных. Как правило, это типовое решение не имеет состояний, поскольку всего лишь передает данные в таблицу и из таблицы.
Пожалуй, наиболее интересная особенность шлюза таблицы данных - это то, как он возвращает результат выполнения запроса. Даже простой запрос типа "найти данные с указанным идентификатором" может возвратить несколько записей. Это не составляет проблемы для сред разработки, допускающих множественные результаты, однако большинство классических языков программирования позволяют возвращать только одно значение.
В качестве альтернативы можно отобразить таблицу базы данных в какую-нибудь простую структуру наподобие коллекции. Это позволит работать с множественными результатами, однако потребует копирования данных из результирующего множества записей базы данных в упомянутую коллекцию. На мой взгляд, этот способ не слишком хорош, поскольку не подразумевает выполнения проверки времени компиляции и не предоставляет явного интерфейса, что приводит к многочисленным опечаткам программистов, ссылающихся на содержимое коллекции. Более удачным решением является использование универсального объекта переноса данных (Data Transfer Object).
Вместо всего перечисленного результат выполнения SQL-запроса может быть возвращен в виде множества записей (Record Set). Вообще говоря, это не совсем корректно, поскольку объект, расположенный в оперативной памяти, не должен "знать" об SQL-интерфейсе. Кроме того, если вы не можете создавать множества записей в собственном коде, это вызовет определенные трудности при замене базы данных файлом. Тем не менее этот способ весьма эффективен во многих средах разработки, широко использующих множество записей, например в таких, как .NET. В этом случае шлюз таблицы данных хорошо сочетается с модулем таблицы (Table Module). Если все обновления таблиц выполняются через шлюз таблицы данных, результирующие данные могут ыть основаны на виртуальных, а не на реальных таблицах, что уменьшает зависимость кода от базы данных.
Если вы используете модель предметной области (Domain Model), методы шлюза таблицы данных могут возвращать соответствующий объект домена. Следует, однако, иметь в виду, что это подразумевает двунаправленные зависимости между объектами домена и шлюзом. И те и другие тесно связаны между собой, поэтому необходимость создания таких зависимостей не слишком усложняет дело, однако мне это все равно не нравится.
Как правило, для каждой таблицы базы данных создается собственный шлюз таблицы данных. Впрочем, в наиболее простых случаях можно ограничиться разработкой одного шлюза таблицы данных, который будет включать в себя все методы для всех таблиц. Кроме того, отдельные шлюзы таблицы данных могут быть созданы для представлений (виртуальных таблиц) и даже для некоторых запросов, не хранящихся в базе данных в форме представлений. Конечно же, шлюз таблицы данных для представления не сможет обновлять данные и поэтому не будет обладать соответствующими методами. Тем не менее, если вы можете сами обновлять таблицы, инкапсуляция процедур обновления в методах типового решения шлюз таблицы данных - прекрасный выбор.
Применимость
Принимая решение об использовании шлюза таблицы данных, как, впрочем, и шлюза записи данных (Row Data Gateway), необходимо подумать о том, следует ли вообще обращаться к шлюзу и если да, то к какому именно.
Шлюз таблицы данных — это наиболее простое типовое решение интерфейса базы данных, поскольку оно замечательно отображает таблицы или записи баз данных на объекты. Кроме того, шлюз таблицы данных естественным образом инкапсулирует точную логику доступа к источнику данных. Это решение крайне редко используют с моделью предметной области, потому что гораздо большей изолированности модели предметной области от источника данных можно добиться с помощью преобразователя данных (Data Mapper). Типовое решение шлюз таблицы данных особенно хорошо сочетается с модулем таблицы. Методы шлюза таблицы данных возвращают структуры данных в виде множеств записей, с которыми затем работает модуль таблицы. На самом деле другой подход отображения базы данных для модуля таблицы придумать просто невозможно (по крайней мере, мне так кажется).
Подобно шлюзу записи данных, шлюз таблицы данных прекрасно подходит для использования в сценариях транзакции (Transaction Script). В действительности выбор од- ного из нескольких типовых решений зависит только от того, как они обрабатывают множественные результаты. Некоторые предпочитают осуществлять передачу данных посредством объекта переноса данных, однако мне это решение кажется более трудоемким (если только этот объект уже не был реализован где-нибудь в другом месте вашего проекта). Рекомендую использовать шлюз таблицы данных в том случае, если его представление результирующего множества данных подходит для работы со сценарием транзакции.
Что интересно, шлюзы таблицы данных могут выступать в качестве посредника при обращении к базе данных преобразователей данных. Правда, когда весь код пишется вручную, это не всегда нужно, однако данный прием может быть весьма эффективен, если для реализации шлюза таблицы данных используются метаданные, а реальное отображение содержимого базы данных на объекты домена выполняется вручную.
Одно из преимуществ использования шлюза таблицы данных для инкапсуляци доступа к базе данных состоит в том, что этот интерфейс может применяться и для обращения к базе данных с помощью средств языка SQL, и для работы с хранимыми процедурами. Более того, хранимые процедуры зачастую сами организованы в виде шлюзов таблицы данных. В этом случае хранимые процедуры, предназначенные для вставки и обновления данных, инкапсулируют реальную структуру таблицы. В свою очередь, процедуры поиска могут возвращать представления, что позволяет скрыть фактическую структуру используемой таблицы.
Название
Row Data Gateway (шлюз записи данных)
Назначение
Реализация доступа к базам данных в объектах, расположенных в оперативной памяти, имеет ряд недостатков. Прежде всего, если этим объектам присуща собственная бизнес-логика, добавление кода доступа к базе данных значительно повышает их сложность. Кроме того, это серьезно усложняет тестирование. Если объекты, расположенные в оперативной памяти, связаны с базой данных, тестирование выполняется крайне медленно из-за проблем, вызванных необходимостью доступа к базе данных. Особенно раздражает, когда приходится осуществлять доступ к нескольким базам данных, имеющим небольшие (но крайне досадные!) расхождения в реализации SQL
Типовое решение шлюз записи данных предоставляет в ваше распоряжение объекты, которые полностью аналогичны записям базы данных, однако могут быть доступны с помощью обычных механизмов используемого языка программирования. Все деталидоступа к источнику данных скрыты за интерфейсом.
Принцип действия
Шлюз записи данных выступает в роли объекта, полностью повторяющего одну запись, например одну строку таблицы базы данных. Каждому столбцу таблицы соответствует поле записи. Обычно шлюз записи данных должен выполнять все возможные преобразования типов источника данных в типы, используемые приложением, однако эти преобразования весьма просты. Рассматриваемое типовое решение содержит все данные о строке, поэтому клиент имеет возможность непосредственного доступа к шлюзу записи данных. Шлюз выступает в роли интерфейса к строке данных и прекрасно подходит для применения в сценариях транзакции (Transaction Script).
При реализации шлюза записи данных возникает вопрос: куда "пристроить" методы поиска, генерирующие экземпляр данного типового решения? Разумеется, можно воспользоваться статическими методами поиска, однако они исключают возможность полиморфизма (что могло бы пригодиться, если понадобится определить разные методы поиска для различных источников данных). В подобной ситуации часто имеет смысл создать отдельные объекты поиска, чтобы у каждой таблицы реляционной базы данных был один класс для проведения поиска и один класс шлюза для сохранения результатов этого поиска (рис. 3.11).
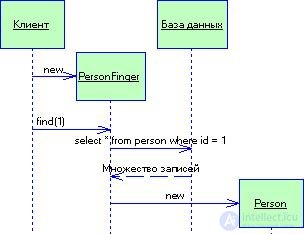
Рисунок 3.11 Взаимодействие со шлюзом записи данных для поиска нужной строки
Иногда шлюз записи данных трудно отличить от активной записи (Active Record). В этом случае следует обратить внимание на наличие какой-либо логики домена; если она есть, значит, это активная запись. Реализация шлюза записи данных должна включать в себя только логику доступа к базе данных и никакой логики домена.
Как и другие формы табличной инкапсуляции, шлюз записи данных можно применять не только к таблице, но и к представлению или запросу. Конечно же, в последних случаях существенно осложняется выполнение обновлений, поскольку приходится обновлять таблицы, на основе которых были созданы соответствующие представления или запросы. Кроме того, если с одними и теми же таблицами работают два шлюза записи данных, обновление второго шлюза может аннулировать обновление первого. Универсального способа предотвратить эту проблему не существует; разработчикам просто необходимо следить за тем, как построены виртуальные шлюзы записи данных. В конце концов, это же может случиться и с обновляемыми представлениями. Разумеется, вы можете вообще не реализовать методы обновления.
Шлюзы записи данных довольно трудоемки в написании. Тем не менее генерацию их кода можно значительно облегчить посредством типового решения отображение метаданных (Metadata Mapping). В этом случае весь код, описывающий доступ к базе данных, может быть автоматически сгенерирован в процессе сборки проекта.
Применимость
Принимая решение об использовании шлюза записи данных, необходимо подумать о двух вещах: следует ли вообще использовать шлюз, и если да, то какой именно — шлюз записи данных или шлюз таблицы данных (Table Data Gateway).
Как правило, шлюз записи данных используют вместе со сценарием транзакции. В этом случае доступ к базе данных легко реализовать таким образом, чтобы соответствующий код мог повторно использоваться другими сценариями транзакции.
Шлюз записи данных не используют с моделью предметной области (Domain Model). Если отображение на объекты домена достаточно простое, его можно реализовать и с помощью активной записи, не добавляя дополнительный слой кода. Об этом говорит сайт https://intellect.icu . Если же отображение сложное, для его реализации рекомендуется применить преобразователь данных (Data Mapper). Последний лучше справляется с отделением структуры данных от объектов домена, потому что объектам домена не нужно знать о структуре базы данных. Конечно же, шлюз записи данных можно использовать, чтобы скрыть структуру базы данных от объектовдомена. Это очень удобно, если вы собираетесь изменить структуру базы данных и не хотите менять логику домена. Тем не менее в этом случае у вас появится три различных представления данных: одно в бизнес-логике, одно в шлюзе записи данных и еще одно в базе данных. Для крупномасштабных систем это слишком много. Поэтому обычно используют шлюзы записи данных, отражающие структуру базы данных.
Интересно, что шлюз записи данных и преобразователь данных вполне могут сосуществовать. Несмотря на то что с первого взгляда это кажется излишней тратой сил, сочетание шлюза записи данных и преобразователя данных может оказаться весьма эффективным в том случае, если первый автоматически генерируется на основе метаданных, а второй создается вручную.
Если шлюз записи данных используется со сценарием транзакции, вы можете заметить, что в различных сценариях повторяется одна и та же бизнес-логика, которую можно было бы реализовать в шлюзе записи данных. Перенос этой логики в шлюз записи данных превратит его в активную запись. Это весьма удачное решение, поскольку позволяет избежать дублирования элементов бизнес-логики.
Название
Active Record (активная запись)
Назначение
Объект, выполняющий роль оболочки для строки таблицы или представления базы данных. Он инкапсулирует доступ к базе данных и добавляет к данным логику домена
Этот объект охватывает и данные и поведение. Большая часть его данных является постоянной и должна храниться в базе данных. В типовом решении активная запись используется наиболее очевидный подход, при котором логика доступа к данным включается в объект домена. В этом случае все знают, как считывать данные из базы данных и как их записывать в нее.
Принцип действия
В основе типового решения активная запись лежит модель предметной области (Domain Model), классы которой повторяют структуру записей используемой базы данных. Каждая активная запись отвечает за сохранение и загрузку информации в базу данных, а также за логику домена, применяемую к данным. Это может быть вся бизнес-логика приложения. Впрочем, иногда некоторые фрагменты логики домена содержатся в сценариях транзакции (Transaction Script), а общие элементы кода, ориентированные на работу с данными, в активной записи.
Структура данных активной записи должна в точности соответствовать таковой в таблице базы данных: каждое поле объекта должно соответствовать одному столбцу таблицы. Значения полей следует оставлять такими же, какими они были получены в результате выполнения SQL-команд; никакого преобразования на этом этапе делать не нужно. При необходимости вы можете применить отображение внешних ключей (Foreign Key Mapping), однако это не обязательно. Активная запись может применяться к таблицам или представлениям (хотя в последнем случае реализовать обновления будет значительно сложнее). Использование представлений особенно удобно при составлении отчетов.
Как правило, типовое решение активная запись включает в себя методы, предназначенные для выполнения следующих операций:
Методы извлечения и установки значений полей могут выполнять и другие действия, например преобразование типов SQL в типы, используемые приложением. Кроме того, get-метод может возвращать соответствующую активную запись таблицы, с которой связана текущая таблица (путем просмотра первой), даже если для структуры данных не было определено поле идентификации (Identity Field).
Классы активной записи довольно удобны с точки зрения разработчиков, однако непозволяют им полностью абстрагироваться от реляционной базы данных. Впрочем, это не так уж плохо, поскольку дает возможность использовать меньше типовых решений, предназначенных для отображения объектной модели на базу данных.
Активная запись очень похожа на шлюз записи данных (Row Data Gateway). Принципиальное отличие между ними состоит в том, что шлюз записи данных содержит только логику доступа к базе данных, в то время как активная запись содержит и логику доступа к данным, и логику домена. Как это часто бывает в мире программного обеспечения, граница между упомянутыми типовыми решениями весьма приблизительна, однако игнорировать ее все-таки не следует.
Поскольку активная запись тесно привязана к базе данных, рекомендую использовать в этом типовом решении статические методы поиска. Однако нет смысла выделть методы поиска в отдельный класс, как это делалось в шлюзе записи данных (здесь это не нужно, да и тестировать будет легче).
Как и другие типовые решения, предназначенные для работы с таблицами, активную запись можно применять не только к таблицам, но и к представлениям или запросам.
Применимость
Активная запись хорошо подходит для реализации не слишком сложной логики домена, в частности операций создания, считывания, обновления и удаления. Кроме того, она прекрасно справляется с извлечением и проверкой на правильность отдельной записи. Как уже отмечалось, при разработке модели предметной области основная проблема
заключается в выборе между активной записью и преобразователем данных (Data Mapper). Преимуществом активной записи является простота ее реализации. Недостаток же состоит в том, что активные записи хороши только тогда, когда точно отображаются на таблицы базы данных (изоморфная схема). Если бизнес-логика приложения достаточно сложна, вам наверняка захочется использовать имеющиеся отношения, коллекции, наследование и т.п. Все это не слишком хорошо отображается на активную запись, а добавление этих элементов "по частям" приведет к страшной неразберихе. В подобных ситуациях лучше воспользоваться преобразователем данных.
Еще одним недостатком использования активной записи является тесная зависимость структуры ее объектов от структуры базы данных. В этом случае изменить структуру базы данных или активной записи довольно сложно, а ведь по мере развития проекта подобная необходимость возникает очень и очень часто.
Активную запись хорошо сочетать со сценарием транзакции, особенно если вас смущает постоянное повторение одного и того же кода и сложность обновления таблиц и сценариев; подобные ситуации нередко сопровождают использование сценариев транзакции. В этом случае вы можете приступить к созданию активных записей, постепенно перенося в них повторяющуюся логику. В качестве еще одного полезного приема могу порекомендовать создать для таблицы оболочку в виде шлюза (Gateway) и затем постепенно перенести в нее логику, превращая шлюз в активную запись.
Название
Data Mapper (преобразователь данных)
Назначение
Слой преобразователей (Mapper), который осуществляет передачу данных между объектами и базой данных, сохраняя последние независимыми друг от друга и от самого преобразователя.
Объекты и реляционные СУБД используют разные механизмы структурирования данных. В реляционных базах данных не отображаются многие характеристики объектов, в частности коллекции и наследование. При построении объектной модели с большим объемом бизнес-логики эти механизмы позволяют лучше организовать данные и соответствующее им поведение. С другой стороны, использование подобных механизмов приводит к несовпадению объектной и реляционной схем.
Объектная модель и реляционная СУБД должны обмениваться данными. Несовпадение схем делает эту задачу крайне сложной. Если объект "знает" о структуре реляционной базы данных, изменение одного из них приводит к необходимости изменения другого.
Типовое решение преобразователь данных представляет собой слой программного обеспечения, которое отделяет объекты, расположенные в оперативной памяти, от базы данных. В функции преобразователя данных входит передача данных между объектами и базой данных и изоляция их друг от друга. Благодаря использованию этого типового решения объекты, расположенные в оперативной памяти, могут даже не "подозревать" о самом факте присутствия базы данных. Им не нужен SQL-интерфейс и тем более схема базы данных. (В свою очередь, схема базы данных никогда не "знает" об объектах, которые ее используют.) Более того, поскольку преобразователь данных является разновидностью преобразователя, он полностью скрыт от уровня домена.
Принцип действия
Основной функцией преобразователя данных является отделение домена от источника данных, однако реализовать эту функцию можно лишь с учетом множества деталей. Кроме того, конструкция слоев отображения также может быть реализована по-разному.
Для начала рассмотрим пример элементарного преобразователя данных. Структура этого слоя слишком проста и, возможно, не стоит тех усилий, которые могут быть потрачены на ее реализацию. Кроме того, простая структура преобразователя влечет за собой применение более простых (и поэтому лучших) типовых решений, что вряд ли подойдет для реальных систем. Тем не менее начинать объяснение новых идей лучше именно на простых примерах.
В этом примере у нас есть классы Person и PersonMapper. Для загрузки данных в объект Person клиент вызывает метод поиска класса PersonMapper (рис. 3.12). Преобразователь использует коллекцию объектов для проверки, загружены ли данные о запрашиваемом лице; если нет, он их загружает. Выполнение обновлений показано на рис. 3.13. Клиент указывает преобразователю на необходимость сохранить объект домена. Преобразователь извлекает данные из объекта домена и отсылает их в базу данных.
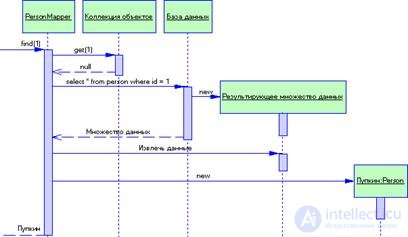
Рисунок 3.12 Извлечение данных их базы данных
При необходимости весь слой преобразователя данных может быть заменен, например, чтобы провести тестирование или чтобы использовать один и тот же уровень домена для работы с несколькими базами данных.
Рассмотренный нами элементарный преобразователь данных всего лишь отображает таблицу базы данных на эквивалентный ей объект по принципу "столбец-на-поле". Конечно же, в реальной жизни не все так просто. Преобразователи должны уметь обрабатывать классы, поля которых объединяются одной таблицей, классы, соответствующие нескольким таблицам, классы с наследованием, а также справляться со связыванием загруженных объектов. Все типовые решения объектно-реляционного отображения, рассмотренные в этой книге, так или иначе направлены на решение подобных проблем. Как правило, эти решения легче создавать на основе преобразователя данных, чем с помощью каких-либо других средств.
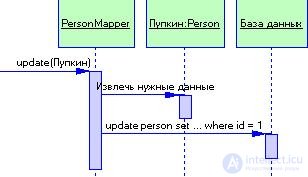
Рисунок 3.13 Сохранение данных
Для выполнения вставки и обновления данных слой отображения должен знать, какие объекты были изменены, какие созданы, а какие уничтожены. Кроме того, все эти действия нужно каким-то образом "уместить" в рамки транзакции. Хороший способ организовать механизм обновления — использовать типовое решение единица работы (Unit of Work).
В схеме, показанной на рис. 3.12, предполагалось, что один вызов метода поиска приводит к выполнению одного SQL-запроса. Это не всегда так. Например, загрузка данных о заказе, состоящем из нескольких пунктов, может включать в себя загрузку каждого пункта заказа. Обычно запрос клиента приводит к загрузке целого графа связанных между собой объектов. В этом случае разработчик преобразователя должен решить, как много объектов можно загрузить за один раз. Поскольку число обращений к базе данных должно быть как можно меньшим, методам поиска должно быть известно, как клиенты используют объекты, чтобы определить оптимальное количество загружаемых данных.
Описанный пример подводит нас к ситуации, когда в результате выполнения одного запроса преобразователь загружает несколько классов объектов домена. Если вы хотите загрузить заказы и пункты заказов, это можно сделать с помощью одного запроса, применив операцию соединения к таблицам заказов и заказываемых товаров. Полученное результирующее множество записей применяется для загрузки экземпляров класса заказов и класса пунктов заказа.
Как правило, объекты тесно связаны между собой, поэтому на каком-то этапе загрузку данных следует прерывать. В противном случае выполнение одного запроса может привести к загрузке всей базы данных! Для решения этой проблемы и одновременной минимизации влияния на объекты, расположенные в памяти, слой отображения использует загрузку по требованию (Lazy Load). По этой причине объекты приложения не могут совсем ничего не "знать" о слое отображения. Скорее всего, они должны быть "осведомлены" о методах поиска и некоторых других механизмах.
В приложении может быть один или несколько преобразователей данных. Если код для преобразователей пишется вручную, рекомендую создать по одному преобразователю для каждого класса домена или для корневого класса в иерархии доменов. Если же вы используете отображение метаданных (Metadata Mapping), можете ограничиться и одним классом преобразователя. В последнем случае все зависит от количества методов поиска. Если приложение достаточно большое, методов поиска может оказаться слишком много для одного преобразователя, поэтому разумнее будет разбить их на несколько классов, создав отдельный класс для каждого класса домена или корневой класс в иерархии доменов. У вас появится масса небольших классов с методами поиска, однако теперь разработчику будет гораздо проще найти то, что ему нужно.
Как и все другие поисковые механизмы баз данных, упомянутые методы поиска должны использовать коллекцию объектов, чтобы отслеживать, какие записи уже были считаны из базы данных. Для этого можно создать реестр (Registry) коллекций объектов либо назначить каждому методу поиска свою коллекцию объектов (при условии, что в течение одного сеанса каждый класс использует только один метод поиска).
Обращение к методам поиска
Чтобы получить возможность работать с объектом, его нужно загрузить из базы данных. Как правило, этот процесс запускается слоем представления, который выполняет загрузку некоторых начальных объектов, после чего передает управление слою домена. Слой домена последовательно загружает объект за объектом, используя установленные между ними ассоциации. Этот прием весьма эффективен при условии, что у слоя домена есть все объекты, которые должны быть загружены в оперативную память, или же что слой домена загружает дополнительные объекты только по мере необходимости путемприменения загрузки по требованию.
Иногда объектам домена может понадобиться обратиться к методам поиска, определенным в преобразователе данных. Как показывает практика, удачная реализация загрузки по требованию позволяет полностью избежать подобных ситуаций. Конечно же, при разработке простых приложений применение ассоциаций и загрузки по требованию может не оправдать затраченных усилий, однако добавлять лишнюю зависимость объектов домена от преобразователя данных тоже не следует.
В качестве решения этой дилеммы можно предложить использование отделенного интерфейса (Separated Interface). В этом случае все методы поиска, применяемые кодом домена, можно вынести в интерфейсный класс и поместить его в пакет домена.
Отображение данных на поля объектов домена
Преобразователи должны иметь доступ к полям объектов домена. Зачастую это вызывает трудности, поскольку предполагает наличие методов, открытых для преобразователей, чего в бизнес-логике быть не должно. (Я исхожу из предположения, что вы не совершили страшную ошибку, оставив поля объектов домена открытыми (public).) Универсального решения этой проблемы не существует. Вы можете применить более низкий уровень видимости, поместив преобразователи "поближе" к объектам домена (например, в одном пакете, как это делается в Java), однако подобное решение крайне запутает глобальную картину зависимостей, потому что другие части системы, которые "знают" об объектах домена, не должны "знать" о преобразователях. Вы можете использовать механизм отражения, который зачастую позволяет обойти правила видимости конкретного языка программирования. Это довольно медленный метод, однако он может оказаться гораздо быстрее выполнения SQL-запроса. И наконец, вы можете использовать открытые методы, предварительно снабдив их полями состояния, генерирующими исключение при попытке использовать эти методы не для загрузки данных преобразователем. В этом случае назовите методы так, чтобы их по ошибке не приняли за обычные get и set методы.
Описанная проблема тесно связана с вопросом создания объекта. Последнее можно осуществить двумя способами. Первый состоит в том, чтобы создать объект с помощью конструктора с инициализацией, который сразу же заполнит новый объект всеми необходимыми данными. Второй заключается в создании пустого объекта и последующем заполнении его данными.
При использовании конструктора с инициализацией возникает проблема, связанная с наличием циклических ссылок. Если у вас есть два объекта, ссылающихся друг на друга, попытка загрузки первого объекта приведет к загрузке второго объекта, что, в свою очередь, снова приведет к загрузке первого объекта и так до тех пор, пока не произойдет переполнение стека. Возможный выход— описать частный случай (Special Case). Обычно это делается с использованием типового решения загрузка по требованию. Написание кода для частного случая - задача далеко не из легких, поэтому рекомендую попробовать что-нибудь другое, например воспользоваться конструктором без аргументов для создания пустого объекта (empty object). Создайте пустой объект и сразу же поместите его в коллекцию объектов. Теперь, если загружаемые объекты окажутся связанными циклической ссылкой, коллекция объектов возвратит нужное значение для прекращения "рекурсивной" загрузки.
Как правило, заполнение пустого объекта осуществляется посредством set-методов. Некоторые из них могут устанавливать значения полей, которые после загрузки данных должны оставаться неизменяемыми. Чтобы предотвратить случайное изменение этих полей после загрузки объекта, присвойте set-методам специальные имена и, возможно, оснастите их полями проверки состояния. Кроме того, вы можете выполнить загрузку данных с использованием механизма отражения.
Отображения на основе метаданных
Разрабатывая корпоративное приложение для взаимодействия с базой данных, необходимо решить, как поля объектов домена будут отображаться на столбцы таблиц базы данных. Самый простой (и часто самый лучший) способ выполнить это - явно описать отображение в коде, что требует создания по одному классу преобразователя на каждый объект домена. Преобразователь выполняет отображение путем присвоения значений и содержит в себе SQL-команды для доступа к базе данных (обычно они хранятся в виде текстовых констант). В качестве альтернативы этому способу можно предложить использование отображения метаданных, которое сохраняет метаданные таблиц в виде обыкновенных данных, в классе или в отдельном файле. Огромное преимущество метаданных заключается в том, что они позволяют вносить изменения в преобразователь путем генерации кода или применения отражающего программирования (reflective programming) без написания дополнительного кода вручную.
Применимость
В большинстве случаев преобразователь данных применяется для того, чтобы схема базы данных и объектная модель могли изменяться независимо друг от друга. Как правило, подобная необходимость возникает при использовании модели предметной области. Основным преимуществом преобразователя данных является возможность работы с моделью предметной области без учета структуры базы данных как в процессе проектирования, так и во время сборки и тестирования проекта. В этом случае объектам домена ничего не известно о структуре базы данных, поскольку все отображения выполняются преобразователями.
Применение преобразователей данных помогает и в написании кода, поскольку по-зволяет работать с объектами домена без необходимости понимать принцип хранения соответствующей информации в базе данных. Изменение модели предметной области не требует изменения структуры базы данных и наоборот, что крайне важно при наличии сложных отображений, особенно при использовании уже существующих баз данных.
Разумеется, за все удобства нужно платить. "Ценой" использования преобразователя данных является необходимость реализации дополнительного слоя кода, чего можно избежать, применив, скажем, активную запись (Active Record). Поэтому основным критерием выбора того или иного типового решения является сложность бизнес-логики. Если бизнес-логика довольно проста, ее, скорее всего, можно реализовать и без применения модели предметной области или преобразователя данных. В свою очередь, реализация более сложной логики невозможна без использования модели предметной области и, как следствие этого, преобразователя данных.
Я бы не стал использовать преобразователь данных без модели предметной области. Но можно ли использовать модель предметной области без преобразователя данных? Если модель довольно проста, а ее разработчики сами контролируют изменения структуры базы данных, доступ объектов домена к базе данных можно осуществлять непосредственно с помощью активной записи. В этом случае роль преобразователя с успехом выполняют сами объекты домена. Тем не менее по мере усложнения логики домена функции доступа к базе данных лучше вынести в отдельный слой.
Хочу также обратить ваше внимание на то, что вам не понадобится разрабатывать полнофункциональный слой отображения базы данных на объекты домена с "нуля". Это весьма сложно, да и на рынке программного обеспечения существует масса подобных продуктов. В большинстве случаев рекомендую приобрести готовый преобразователь, вместо того чтобы заниматься его разработкой самому.
Когда речь заходит о взаимном отображении объектов и таблиц реляционной базы данных, внимание обычно сосредоточивается на структурных аспектах, то есть на том, как следует соотносить таблицы и объекты. Однако самая трудная часть проблемы - это выбор и обоснование архитектурной и функциональной составляющих.
Обсудив основные варианты архитектурных решений, рассмотрим функциональную (поведенческую) сторону, в частности вопрос о том, как обеспечить загрузку различных объектов и сохранение их в базе данных. На первый взгляд это не кажется слишком сложной задачей: объект можно снабдить соответствующими методами загрузки ("load") и сохранения ("save"). Именно такой путь целесообразно избрать, например, при использовании решения активная запись (Active Record). Загружая в память большое количество объектов и модифицируя их, система должна следить за тем, какие объекты подверглись изменению, и гарантировать сохранение их содержимого в базе данных. Если речь идет всего о нескольких записях, это просто. Но по мере увеличения числа объектов растут и проблемы: как быть, скажем, в такой далеко не самой сложной ситуации, когда необходимо создать записи, которые должны ссылаться на ключевые значения друг друга.
При выполнении операций считывания или изменения объектов система должна гарантировать, что состояние базы данных, с которым вы имеете дело, остается согласованным. Так, например, на результат загрузки данных не должны влиять изменения, вносимые другими процессами. В противном случае итог операции окажется непредсказуемым. Подобные вопросы, относящиеся к дисциплине управления параллельными заданиями, весьма серьезны. Они обсуждаются разделе "Управление параллельными заданиями".
Типовым решением, имеющим существенное значение для преодоления такого рода проблем, является единица работы (Unit of Work), использование которой позволяет отследить, какие объекты считываются и какие модифицируются, и обслужить операции обновления содержимого базы данных. Автору прикладной программы нет нужды явно вызывать методы сохранения — достаточно сообщить объекту единица работы о необходимости фиксации (commit) результатов в базе данных. Типовое решение единица работы упорядочивает все функции по взаимодействию с базой данных и сосредоточивает в одном месте сложную логику фиксации. Его лучшие качества проявляются именно тогда, когда интерфейс между приложением и базой данных становится особенно запутанным.
Решение единица работы удобно воспринимать в виде объекта, действующего как контроллер процессов отображения объектов в реляционные структуры. В отсутствие такового роль контроллера, принимающего решения о том, когда и как загружать и сохранять объекты приложения, обычно выполняет слой бизнес-логики. В процессе загрузки данных необходимо тщательно следить за тем, чтобы ни один из объектов не был считан дважды, иначе в памяти будут созданы два объекта, соответствующих одной и той же записи таблицы базы данных. Попробуйте обновить каждую из них, и неприятности не заставят себя ждать. Чтобы уйти от проблем, необходимо вести учет каждой считанной записи, а поможет в этом типовое решение коллекция объектов (Identity Map). Каждый раз при необходимости считывания порции данных вначале следует проверить, не содержится ли она в коллекции объектов. Если информация уже загружалась, можно предусмотреть возврат ссылки на нее. В этом случае любые попытки изменения данных будут скоординированы. Еще одно преимущество - возможность избежать дополнительного обращения к базе данных, поскольку коллекция объектов действует как кэш-память. Не забывайте, однако, что главное назначение коллекции объектов - учет идентификационных номеров объектов, а не повышение производительности приложения.
При использовании модели предметной области (Domain Model) связанные объекты загружаются совместно таким образом, что операция считывания одного объекта инициирует загрузку другого. Если связями охвачено много объектов, считывание любого из них приводит к необходимости загружать из базы данных целый граф объектов. Чтобы исключить подобное неэффективное поведение системы, необходимо умерить аппетит, сократив количество загружаемых объектов, но оставить за собой право завершения операции, если потребность в дополнительной информации действительно возникнет. Типовое решение загрузка по требованию (Lazy Load,) предполагает использование специальных меток вместо ссылок на реальные объекты. Существует несколько вариаций схемы, но во всех случаях реальный объект загружается только тогда, когда предпринимается попытка проследовать по ссылке, которая его адресует. Решение загрузка по требованию позволяет оптимизировать число обращений к базе данных.
Рассматривая проблему считывания информации из базы данных, рекомегдуется трактовать предназначенные для этого методы в виде функций поиска (finders), скрывающих посредством соответствующих входных интерфейсов SQL-выражения формата "select". Примерами подобных методов могут служить find (id) или findForCustomer (customer). Разумеется, если ваше приложение оперирует тремя десятками выражений "select" с различными критериями выбора, указанная схема становится чересчур громоздкой, но такие ситуации, к счастью, редки. Принадлежность методов зависит от вида используемого интерфейсного типового решения. Если каждый класс, обеспечивающий взаимодействие с базой данных, привязан к определенной таблице, в его состав наряду с методами вставки и замены уместно включить и методы поиска. Если же объект класса соответствует отдельной записи данных, требуется иной подход. В этом случае можно попробовать сделать методы поиска статическими, но за это придется заплатить некоторой долей гибкости, в частности вам более не удастся в целях тестирования заменить базу данных фиктивной службой (Service Stub). Чтобы избежать подобных проблем, лучше предусмотреть специальные классы поиска, включив в состав каждого из них методы, обеспечивающие инкапсуляцию тех или иных SQL-запросов. В результате выполнения запроса метод возвращает коллекцию объектов, соответствующих определенным записям данных.
Применяя методы поиска, следует помнить, что они выполняются в контексте состояния базы данных, а не состояния объекта. Если после создания в памяти объектов-записей данных, отвечающих некоторому критерию, вы активизируете запрос, который предполагает поиск записей, удовлетворяющих тому же критерию, то очевидно, что объекты, созданные, но не зафиксированные в базе данных, в результат обработки запроса не попадут.
При считывании данных проблемы производительности могут приобретать первостепенное значение. Необходимо помнить несколько эмпирических правил. Старайтесь при каждом обращении к базе данных извлекать немного больше записей, чем нужно. В частности, не выполняйте один и тот же запрос повторно для приобретения дополнительной информации. Почти всегда предпочтительнее получить как можно больше данных, но нужно отдавать себе отчет в том, что при использовании пессимистической стратегии управления параллельными заданиями это может привести к ненужному блокированию большого количества записей. Например, если необходимо найти 50 записей, удовлетворяющих определенному условию, лучше выполнить запрос, возвращающий 200 записей, и применить для отбора искомых дополнительную логику, чем инициировать 50 отдельных запросов.
Другой способ исключить необходимость неоднократного обращения к базе данных связан с применением операторов соединения (join), позволяющих с помощью одного запроса извлечь информацию из нескольких таблиц. Итоговый набор записей может содержать больше информации, чем требуется, но скорость его получения, вероятно, выше, чем в случае выполнения нескольких запросов, возвращающих в результате те же данные. Для этого следует воспользоваться шлюзом (Gateway), охватывающим информацию из нескольких таблиц, которые подлежат соединению, или преобразователем данных (Data Mapper), позволяющим загрузить несколько объектов домена с помощью единственного вызова.
Применяя механизм соединения таблиц, имейте в виду, что СУБД способны эффективно обслуживать запросы, в которых соединению подвергнуто не более трех-четырех таблиц. В противном случае производительность системы существенно падает, хотя воспрепятствовать этому, по меньшей мере частично, удается, например, с помощью разумной стратегии кэширования представлений. Работу СУБД можно оптимизировать самыми разными способами, включая компактное группирование взаимосвязанных данных, тщательное проектирование индексов и кэширование порций информации в оперативной памяти. Все эти технологии, однако, выбиваются из контекста книги (хотя должны быть присущи сфере профессиональных интересов хорошего администратора баз данных).
Во всех случаях, тем не менее, следует учитывать особенности конкретных приложений и базы данных. Наставления общего характера хороши до определенного момента, когда необходимо как-то организовать способ мышления, но реальные обстоятельства всегда вносят свои коррективы. Достаточно часто СУБД и серверы приложений обладают сложными механизмами кэширования, затрудняющими дать хоть сколько-нибудь точную оценку производительности приложения. Никакое правило не обходится без исключений, так что тонкой настройки и доводки системы избежать не удастся.
Во всех разговорах об объектно-реляционном отображении обычно и прежде всего имеется в виду обеспечение взаимно однозначного соответствия между объектами в памяти и табличными структурами базы данных на диске. Подобные решения, как правило, не имеют ничего общего с вариантами шлюза таблицы данных (Table Data Gateway) и находят ограниченное применение совместно с решениями типа шлюза записи данных (Row Data Gateway) и активной записи (Active Record), хотя все они, вероятно, окажутся востребованными в контексте преобразователя данных (Data Mapper).
Главная проблема, которая обсуждается в этом разделе, обусловлена тем, что связи объектов и связи таблиц реализуются по-разному. Проблема имеет две стороны. Во-первых, существуют различия в способах представления связей. Объекты манипулируют связями, сохраняя ссылки в виде адресов памяти. В реляционных базах данных связь одной таблицы с другой задается путем формирования соответствующего внешнего ключа (foreign key). Во-вторых, с помощью структуры коллекции объект способен сохранить множество ссылок из одного поля на другие, тогда как правила нормализации таблиц базы данных допускают применение только однозначных ссылок. Все это приводит к расхождениям в структурах объектов и таблиц. Так, например, в объекте, представляющем сущность "заказ", совершенно естественно предусмотреть коллекцию ссылок на объекты, описывающие заказываемые товары, причем последним нет необходимости ссылаться на "родительский" объект заказа. Но в схеме базы данных все обстоит иначе: запись в таблице товаров должна содержать внешний ключ, указывающий на запись в таблице заказов, поскольку заказ не может иметь многозначного поля.

Рисунок 3.14 Пример использования паттерна Отображение внешних ключей для реализации однозначной ссылки
Чтобы решить проблему различий в способах представления связей, достаточно сохранять в составе объекта идентификаторы связанных с ним объектов-записей, используя типовое решение поле идентификации (Identity Field [4]), а также обращаться к этим значениям, если требуется прямое и обратное отображение объектов и ключей таблиц базы данных. Это довольно скучно, но вовсе не так трудно, если усвоить основные приемы. При считывании информации из базы данных для перехода от идентификаторов записей к объектам используется коллекция объектов (Identity Map [4]). Связи, задаваемой внешним ключом, отвечает типовое решение отображение внешних ключей (Foreign Key Mapping [4]), устанавливающее подходящую связь одного объекта с другим (рис. 3.14). Если в коллекции объектов ключа нет, необходимо либо считать его из базы данных, либо применить вариант загрузки по требованию (Lazy Load). При сохранении информации объект фиксируется в таблице базы данных в виде записи с соответствующим ключом, а все ссылки на другие объекты, если таковые существуют, заменяются значениями полей идентификации этих объектов.
Если объект способен содержать коллекцию ссылок, требуется более сложная версия отображения внешних ключей, пример которой представлен на рис. 3.15. В этом случае, чтобы отыскать все записи, содержащие идентификатор объекта-источника, необходимо выполнить дополнительный запрос (или воспользоваться решением загрузка по требованию). Для каждой считанной записи, удовлетворяющей критерию поиска, создается соответствующий объект, и ссылка на него добавляется в коллекцию. Для сохранения коллекции следует обеспечить сохранение каждого объекта в ней, гарантируя корректность значений внешних ключей. Операция может быть довольно сложной, особенно в том случае, когда приходится отслеживать динамику добавления объектов в коллекцию и их удаления. В крупных системах с подобной целью применяются подходы, основанные на метаданных (об этом речь идет несколько позже). Если объекты коллекции не используются вне контекста ее владельца, для упрощения задачи можно обратиться к типовому решению отображение зависимых объектов (Dependent Mapping).
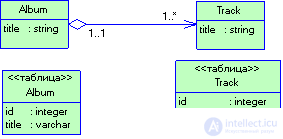
Рисунок 3.15. Пример использования паттерна Отображение внешних ключей для реализации коллекции ссылок
Совсем иная ситуация возникает, когда связь относится к категории "многие ко многим", то есть. коллекции ссылок присутствуют "с обеих сторон" связи. Примером может служить множество служащих и общий набор профессиональных качеств, отдельными из которых обладает каждый служащий. В реляционных базах данных проблема описания такой структуры преодолевается за счет создания дополнительной таблицы, содержащей пары ключей связанных сущностей (именно это предусмотрено в типовом решении отображение с помощью таблицы ассоциаций (Association Table Mapping), пример которого показан на рис. 3.16.

Рисунок 3.16 Пример использования паттерна Отображение с помощью таблицы ассоциаций для реализации связи «многие ко многим»
При работе с коллекциями принято полагаться на критерий упорядочения, с учетом которого она создана. В объектно-ориентированных языках программирования обшей практикой является использование типов упорядоченных коллекций, подобных спискам и массивам. Однако задача сохранения в реляционной базе данных содержимого коллекции с произвольным критерием упорядочения остается сложной. В качестве способов ее решения можно порекомендовать использование неупорядоченных множеств или определение критерия упорядочения на этапе выполнения запроса к коллекции (последний подход связан с большими затратами).
В некоторых случаях проблема обновления данных усугубляется из-за необходимости выполнять условия целостности на уровне ссылок (referential integrity). Современные СУБД позволяют откладывать (defer) проверку таких условий до завершения транзакции. Если "ваша" система такую возможность предоставляет, грех ею не воспользоваться. Если нет, система инициирует проверку после каждой операции записи. В такой ситуации вы обязаны соблюдать верный порядок прохождения операций. Не вдаваясь в детали, напомню, что один из подходов связан с построением и анализом графа, описывающего такой порядок, а другой состоит в задании жесткой схемы выполнения операций непосредственно в коде приложения. Иногда это позволяет снизить вероятность возникновения ситуаций взаимоблокировки (deadlock), для разрешения которых приходится осуществлять откат (rollback) тех или иных транзакций.
Для описания связей между объектами, преобразуемых во внешние ключи, используется типовое решение поле идентификации, но далеко не все связи объектов следует фиксировать в базе данных именно таким образом. Разумеется, небольшие объекты-значения (Value Object), описывающие, скажем, диапазоны дат или денежные величины, нецелесообразно представлять в отдельных таблицах базы данных. Объект-значение уместнее отображать в виде внедренного значения (Embedded Value), то есть набора полей объекта, "владеющего" объектом-значением. При необходимости загрузки данных в память объекты-значения можно легко создавать заново, не утруждая себя использованием коллекции объектов. Сохранить объект-значение также несложно - достаточно зафиксировать значения его полей в таблице объекта-владельца.
Можно пойти дальше и предложить модель группирования объектов-значений с сохранением их в таблице базы данных в виде единого поля типа крупный сериализованный
объект (Serialized LOB). Аббревиатура LOB происходит от словосочетания Large OBject и означает "крупный объект"; различают крупные двоичные объекты (Binary LOBs — BLOBs) и крупные символьные объекты (Character LOBs — CLOBs). Сериализация множества объектов в виде XML-документа — очевидный способ сохранения иерархических объектных структур. В этом случае для считывания исходных объектов будет достаточно одной операции. При выполнении большого количества запросов, предполагающих поиск мелких взаимосвязанных объектов (например, для построения диаграмм или обработки счетов), производительность СУБД часто резко падает, и крупные сериализованные объекты позволяют существенно снизить загрузку системы.
Недостаток такого подхода состоит в том, что в рамках "чистого" SQL сконструировать запросы к отдельным элементам сохраненной структуры не удастся. На помощь может прийти XML, позволяющий внедрить выражения формата XPath в вызовы SQL, хотя такой подход на данный момент пока не стандартизован. Крупные сериализованные объекты лучше всего применять для хранения относительно небольших групп объектов. Злоупотребление этим подходом приведет к тому, что база данных со временем будет напоминать файловую систему.
Выше уже упоминались составные иерархические структуры, которые традиционно плохо отображаются средствами реляционных систем баз данных. Существует и другая разновидность иерархий, еще более усугубляющих страдания приверженцев реляционной модели: речь идет об иерархиях классов, создаваемых на основе механизма наследования (inheritance). Поскольку SQL не предоставляет стандартизованных инструментов поддержки наследования, придется вновь прибегнуть к аппарату отображения.

Рисунок 3.17 Паттерн Наследование с одной таблицей предусматривает сохранение значений атрибутов всех классов иерархии в одной таблице
Рисунок 3.18 Паттерн Наследование таблиц для каждого конкретного класса предусматривает использование отдельных таблиц для каждого конкретного класса иерархии

Рисунок 3.19 Паттерн Наследование таблиц для каждого класса предусматривает использование отдельных таблиц для каждого класса иерархии
Существует три основных варианта представления структуры наследования: "одна таблица для всех классов иерархии" (наследование с одной таблицей (Single Table Inheritance) - рис. 3.18; "таблица для каждого конкретного класса" (наследование с таблицами для каждого конкретного класса (Concrete Table Inheritance) - рис. 3.19; "таблица для каждого класса" (наследование с таблицами для каждого класса (Class Table Inheritance) - рис. 3.20.
Возможен компромисс между необходимостью дублирования элементов данных и потребностью в ускорении доступа к ним. Решение наследование с таблицами для каждого класса - самый простой и прямолинейный вариант соответствия между классами и таблицами базы данных, но для загрузки информации об отдельном объекте в этом случае приходится осуществлять несколько операций соединения (join), что обычно сопряжено со снижением производительности системы. Решение наследование с таблицами для каждого конкретного класса позволяет обойти соединения, предоставляя возможность считывания всех данных об объекте из единственной таблицы, но существенно препятствует внесению изменений. При любой модификации базового класса нельзя забывать о необходимости соответствующего преобразования всех таблиц дочерних классов (и кода, обеспечивающего корректное отображение). Изменение самой иерархической структуры способно вызвать еще более серьезные проблемы. Помимо того, отсутствие таблицы для базового класса может усложнить управление ключами. Что касается наследования с одной таблицей, то самым большим недостатком этого решения является нерациональное расходование дискового пространства, поскольку каждая запись таблицы содержит поля для атрибутов всех созданных дочерних классов и многие из этих полей остаются пустыми. (Впрочем, некоторые СУБД "умеют" осуществлять сжатие неиспользуемых областей.) Большой размер записи приводит и к замедлению ее загрузки. Преимущество же наследования с одной таблицей заключается в том, что все данные, относящиеся к любому классу, сосредоточены в одном месте, а это значительно упрощает возможность внесения изменений и позволяет избежать операций соединения. Три упомянутых решения не являются взаимоисключающими - их вполне можно сочетать в рамках одной и той же иерархии классов: например, информацию о наиболее важных классах уместно объединить посредством наследования с одной таблицей, а для других классов воспользоваться решением наследование с таблицами для каждого класса. Разумеется, совмещение решений повышает сложность их применения.
Среди названных способов отображения иерархии наследования трудно выделить какой-либо один. Как и при использовании всех других типовых решений, необходимо принять во внимание конкретные обстоятельства и требования.
Отображение объектов в реляционные структуры, по существу, сводится к одной из трех общих ситуаций:
В простейшем случае, когда схема создается самостоятельно, а бизнес-логика отличается умеренной сложностью, оправдан подход, основанный на сценарии транзакции (Transaction Script) или модуле таблицы (Table Module); таблицы могут создаваться с помощью традиционных инструментов проектирования баз данных. Для исключения кода SQL из бизнес-логики применяется шлюз записи данных (Row Data Gateway,) или шлюз таблицы данных (Table Data Gateway). Используя модель предметной области (Domain Model), остерегайтесь структурировать приложение с оглядкой на схему базы данных и больше заботьтесь об упрощении бизнес-логики. Воспринимайте базу данных только как инструмент сохранения содержимого объектов. Наибольший уровень гибкости взаимного отображения объектов и реляционных структур обеспечивает преобразователь данных (Data Mapper), но это типовое решение отличается повышенной сложностью. Если структура базы данных изоморфна модели предметной области, можно воспользоваться активной записью (Active Record).
Хотя первоочередное построение модели представляет собой удобный способ восприятия предметной области, этот вариант действий правомерен только тогда, когда он реализуется в течение короткого итеративного цикла. Провести шесть месяцев за построением модели предметной области, не предусматривающей применения базы данных, а затем в один момент прийти к заключению о том, что сохранять кое-какую информацию все-таки было бы неплохо, не только несерьезно, но и весьма рискованно. Опасность заключается в том, что, если проект продемонстрирует изъяны на уровне производительности, исправить положение будет непросто. Каждую полуторамесячную или даже более краткую итерацию разработки модели и приложения следует сопровождать принятием решений, касающихся уточнения и расширения схемы базы данных. В этом случае у вас всегда будет самая свежая информация о том, как интерфейс взаимодействия приложения с базой данных ведет себя на практике. Итак, решая любую частную задачу, в первую очередь необходимо думать о модели предметной области, не забывая немедленно интегрировать каждую ее часть в базу данных.
Если схема базы данных создана загодя, в вашем распоряжении примерно те же альтернативы, но процесс несколько отличается. Если бизнес-логика проста, ее слой располагается "поверх" создаваемых классов шлюза записи данных или шлюза таблицы данных, имитирующих функции базы данных. При повышении уровня сложности бизнес-логики приходится прибегать к помощи модели предметной области, дополненной преобразователем данных, который должен обеспечить сохранение содержимого объектов приложения в существующей базе данных.
Наличие в тексте приложения повторяющихся фрагментов кода - признак его плохо продуманной структуры. Общие функции можно вынести "за скобки", например средствами наследования и делегирования - одними из главных механизмов объектно-ориентированного программирования, но существует и более изощренный подход, связанный с отображением метаданных (Metadata Mapping).
Типовое решение отображение метаданных основано на вынесении функций отображения в файл метаданных, задающий соответствие между столбцами таблиц базы данных и полями объектов. Наличие метаданных позволяет не повторять код отображения и заново генерировать его по мере необходимости. Даже пустяковый фрагмент метаданных, подобный приведенному ниже, способен весьма выразительно сообщить большой объем информации.
<class name = ‘Person’ tableName = ‘Person’>
<attr name=’id’ field=’person_id’>
<attr name=’lastName’ field=’last_name>
</class>
С помощью этой информации вам удастся определить операции считывания и записи данных, автоматического формирования любых SQL-выражений, поддержки множественных связей и т.п. Вот почему модель метаданных находит широкое применение в коммерческих инструментальных средствах отображения объектов и реляционных структур.
Отображение метаданных предлагает все необходимое для конструирования запросов в терминах прикладных объектов. Типовое решение объект запроса (Query Object) позволяет создавать запросы на основе объектов и данных в памяти, не требуя знаний SQL и деталей реляционной схемы, и применять инструменты отображения метаданных для трансляции таких выражений в соответствующие конструкции SQL.
Воспользуйтесь этими решениями на наиболее ранних стадиях проекта, и вам удастся применить одну из форм хранилища (Repository,), полностью скрывающего базу данных от взгляда извне. Любые запросы к базе данных могут трактоваться как объекты запроса в контексте хранилища: в этой ситуации разработчику приложения неведомо, откуда извлекаются объекты - из памяти или из базы данных. Решение хранилище весьма удачно сочетается с богатыми моделями предметной области (Domain Model).
В большинстве случаев приложение взаимодействует с базой данных при посредничестве некоторого объекта соединения (connection). Прежде чем выполнять команды и запросы к базе данных, соединение обычно необходимо открыть. Объект соединения должен пребывать в открытом состоянии на протяжении всего сеанса работы с базой данных. По завершении обслуживания запроса возвращается объект типа множество записей (Record Set). Некоторые интерфейсы позволяют манипулировать полученным множеством записей даже после закрытия соединения, а некоторые требуют наличия активного соединения. Если действия выполняются в рамках транзакции, последняя, как правило, ограничена контекстом определенного соединения, которое должно оставаться открытым, как минимум, до завершения транзакции.
Во многих средах открытие выделенного соединения сопряжено с расходованием строго ограниченных ресурсов, поэтому применение находят так называемые пулы соединений (connection pools). В этом случае приложение не открывает и закрывает соединение, а запрашивает его из пула и освобождает, когда оно больше не требуется. Сегодня поддержка пула соединений обеспечивается большинством вычислительных платформ, поэтому потребность в самостоятельной реализации подобной структуры возникает редко. Если все-таки вам приходится этим заниматься, прежде всего выясните, действительно ли применение пула повышает производительность системы. Нередко среда способна обеспечить более быстрое создание нового соединения, нежели повторное использование соединения из пула.
Платформы, поддерживающие механизм пула соединений, часто скрывают последний посредством дополнительных интерфейсов, так что операции создания нового объекта соединения и выделения объекта из пула для разработчика прикладной системы выглядят совершенно идентично. Аналогично, закрытие соединения в реальности может означать возврат соединения в общий пул, доступный для других процессов. Подобная инкапсуляция, безусловно, является положительным решением. Ниже будут употребляться термины "открытие" и "закрытие", но имейте в виду, что в конкретной ситуации они могут означать соответственно "захват" соединения из пула и его "освобождение" с возвращением в пул.
Неважно, как создаются соединения, но ими необходимо надлежащим образом управлять. Поскольку, как уже отмечалось, речь в данном случае идет о дорогостоящих вычислительных ресурсах, соединения следует закрывать сразу по завершении их использования. Помимо того, если применяется аппарат транзакций, необходимо гарантировать, что каждая команда внутри определенной транзакции активизируется при посредничестве одного и того же объекта соединения. Наиболее общая рекомендация такова: следует запросить объект соединения явно, используя вызов, обращенный к пулу или диспетчеру соединений, а затем ссылаться на этот объект в каждой команде, адресуемой к базе данных; по окончании использования объект необходимо закрыть. Но как поручиться, что ссылки на объект соединения присутствуют везде, где необходимо, и не забыть закрыть соединение по окончании работы.
Решение первой части проблемы состоит в передаче объекта соединения в любую команду в виде явно задаваемого параметра. К сожалению, при этом может оказаться, что объект соединения не будет передан единственному методу, расположенному в стеке вызовов на несколько уровней ниже, а присутствует во всевозможных вызовах методов. В этой ситуации целесообразно вспомнить о реестре (Registry). Поскольку вам наверняка не хочется, чтобы соединением пользовались несколько вычислительных потоков, необходимо применять вариант реестра уровня одного потока.
Даже если вы не так забывчивы, как я, то и в этом случае согласитесь, что требование
явного закрытия соединений довольно обременительно, поскольку его слишком легко оставить без внимания, что, разумеется, недопустимо. Соединение нельзя закрывать и после выполнения каждой команды, так как первая же попытка сделать подобное внутри транзакции приведет к ее откату.
Оперативная память, как и соединения, относится к числу ресурсов, которые надлежит возвращать системе сразу по завершении их использования. В современных средах разработки управление памятью и функции сборки мусора осуществляются автоматически. Поэтому один из способов закрытия соединения состоит в том, чтобы довериться сборщику мусора. При таком подходе соединение закрывается, если в ходе сборки мусора утилизируются объект соединения как таковой и все объекты, которые на него ссылаются. Удобно то, что здесь применяется та же хорошо знакомая схема управления памятью. Однако есть и проблема: соединение закрывается только тогда, когда сборщик мусора действительно утилизирует память, а это может произойти гораздо позже, чем исчезнет последняя ссылка, адресующая объект соединения, т.е. в ожидании закрытия он проведет немало времени. Возникнет подобная проблема или нет, во многом определяется особенностями среды разработки, которой вы пользуетесь.
Если рассуждать в более широком смысле, я не стал бы слишком полагаться на механизм сборки мусора. Другие схемы - даже с принудительным закрытием соединений - кажутся более надежными. Впрочем, сборку мусора можно считать своего рода страхвочным вариантом: как говорится, лучше позже, чем никогда.
Поскольку соединения логически тяготеют к транзакциям, удобная стратегия управления ими состоит в трактовке соединения как неотъемлемого "атрибута" транзакции: оно открывается в начале транзакции и закрывается по завершении операций фиксации или отката. Транзакции известно, с каким соединением она взаимодействует, и потому вы можете сосредоточиться на транзакции, более не заботясь о соединении как таковом. Поскольку завершение транзакции обычно имеет более "видимый" эффект, чем завершение соединения, вы вряд ли забудете ее зафиксировать (а если и забудете, то, поверьте мне, быстро об этом вспомните). Один из вариантов совместного управления транзакциями и соединениями демонстрируется в типовом решении единица работы (Unit Of Work).
Если речь идет о выполнении операций вне транзакций (например, о чтении заведомо неизменяемых данных), для каждой операции можно использовать "свежий" объект соединения. Совладать с любыми проблемами, касающимися использования объектов соединений с короткими периодами существования, поможет схема организации пула соединений.
При необходимости обработки данных в автономном режиме в контексте множества записей можно открыть соединение для загрузки информации в структуру данных, закрыть его и приступить к обработке. По завершении следует открыть новое соединение, активизировать транзакцию и сохранить результаты в базе данных. Если действовать по такой схеме, придется позаботиться о синхронизации данных с той информацией, которая изменялась другими транзакциями в период обработки содержимого множества записей.
Особенности процедур управления соединениями во многом обусловлены параметрами конкретных среды разработки и приложения
Я хотел бы услышать твое мнение про паттерны организации источников данных Надеюсь, что теперь ты понял что такое паттерны организации источников данных и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Объектно-ориентированное программирование ООП
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

Комментарии