Лекция
Привет, Вы узнаете о том , что такое пирамида тестирования, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое пирамида тестирования, сквозное тестирование, end-to-end , пирамиды тестирования , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
Тестирование в больших компаниях, в enterprise, чаще всего дело сложное и неблагодарное. Разрыв между бизнес-подразделениями и IT огромный: когда разработчик имеет видение на уровне кода, а проверку – на уровне модульных тестов, а заказчик мыслит работающими или неработающими даже не услугами, а целыми процессами, выходящими за рамки одной команды разработки, а то и целого подразделения\компании. И просит организовать бизнес-тестирование, или сквозное тестирование , или тестирование на основании сценариев от начала и до конца (end 2 end).
Доволно часто наши клиенты рассматривают тесты как пятое колесо, когда дело доходит до разработки. Вы знаете последствия: астрономическое количество проектных аномалий, пагубные ошибки в производстве и, что еще хуже, программное обеспечение, которое постепенно превращается в оссицирующуюся.
Иногда мы решаем провести тестирование, и нам удается убедить «высшие эшелоны» в выгоде и необходимости времени (и, следовательно, денег) тестирования, но:
А затем мы развернем тяжелую артиллерию: сквозные тесты, обычно тесты графического интерфейса типа Selenium:
Но через несколько недель или месяцев мы начинаем понимать, что это, возможно, не лучшая идея:
Тогда мы вкладываем еще больше средств, потому что говорим себе, что не сильно скучаем, и сейчас было бы стыдно все выбросить. И да, все можно улучшить , но какой ценой? И как долго? В целом, стратегия тестирования «черного ящика» не является ни самой эффективной, ни самой рентабельной.
Я вижу, как вы читаете больше одной улыбки, но будьте уверены: вы не одиноки.
Прежде чем я расскажу вам больше о тестовой пирамиде, давайте вспомним некоторые критерии, которые важно учитывать при рассмотрении стратегии тестирования. И, чтобы устранить слишком распространенное недоразумение, в этой статье мы поговорим исключительно об автоматизированных тестах.
Тест, каким бы он ни был, не имеет другой цели, кроме как дать вам обратную связь: «Моя программа делает то, что должна?» Мы можем судить о качестве этого отзыва по трем критериям:
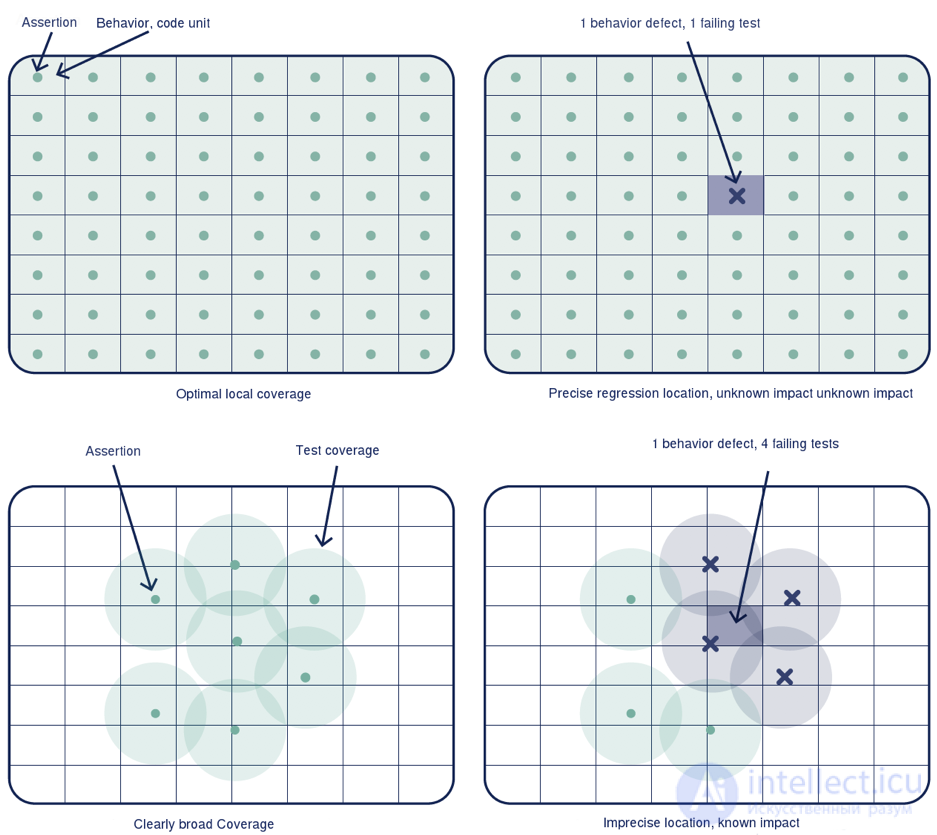
Источник: Кодекс культуры, технология OCTO
«Хватит называть твою сборку ненадежной. Вы когда-нибудь выходили в производство, когда, скажем, ваша функция поиска «иногда работает»? »
Паван Сударшан, Хотя Работы
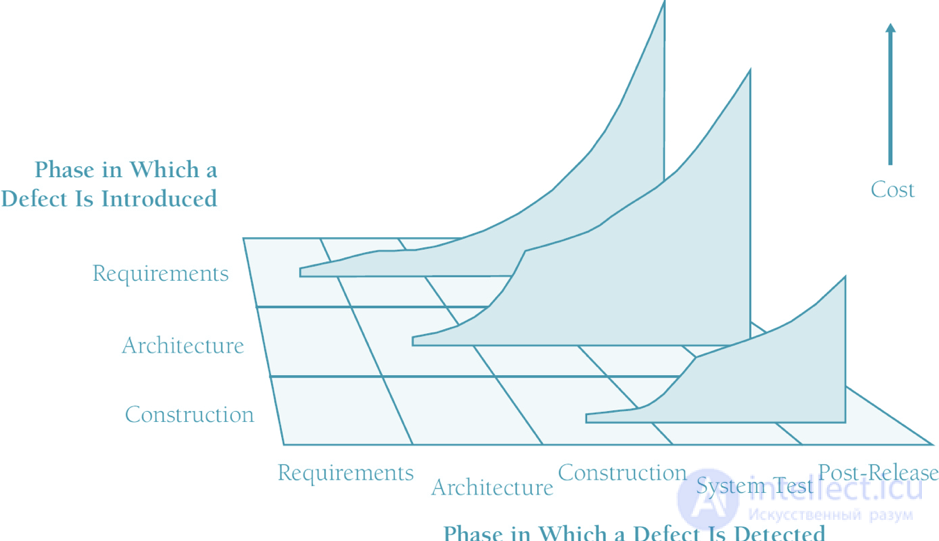
Источник: Код завершен, 2-е издание, Стив Макконнелл
Даже если тесты бывают быстрыми, есть даже действенный цикл: они просты в запуске и укрепляют доверие к вашему коду, побуждая вас писать еще больше.
Поэтому хорошая стратегия тестирования направлена на максимальное увеличение количества тестов, соответствующих этим трем критериям: точность, скорость и надежность.
Зная, что у вас вряд ли будет неограниченный бюджет, ваша стратегия тестирования будет обязательно зависеть от него. Вам необходимо сопоставить стоимость различных типов тестов со стоимостью, которую они предоставляют, иными словами, оценить их ROI.
В следующей таблице приведены основные критерии выбора типа теста для использования:
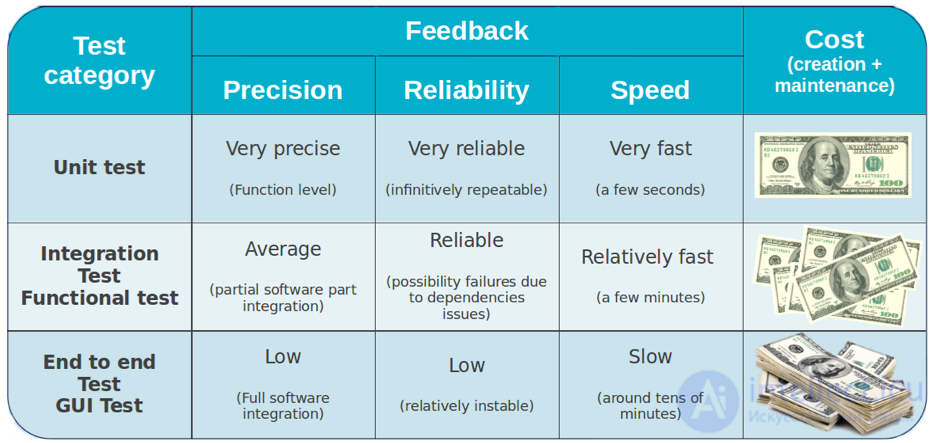
С этой точки зрения мы можем сказать: «Отлично! Мне нужно только выполнять модульные тесты », но существуют и другие типы тестов по уважительной причине: модульные тесты не могут проверить все.
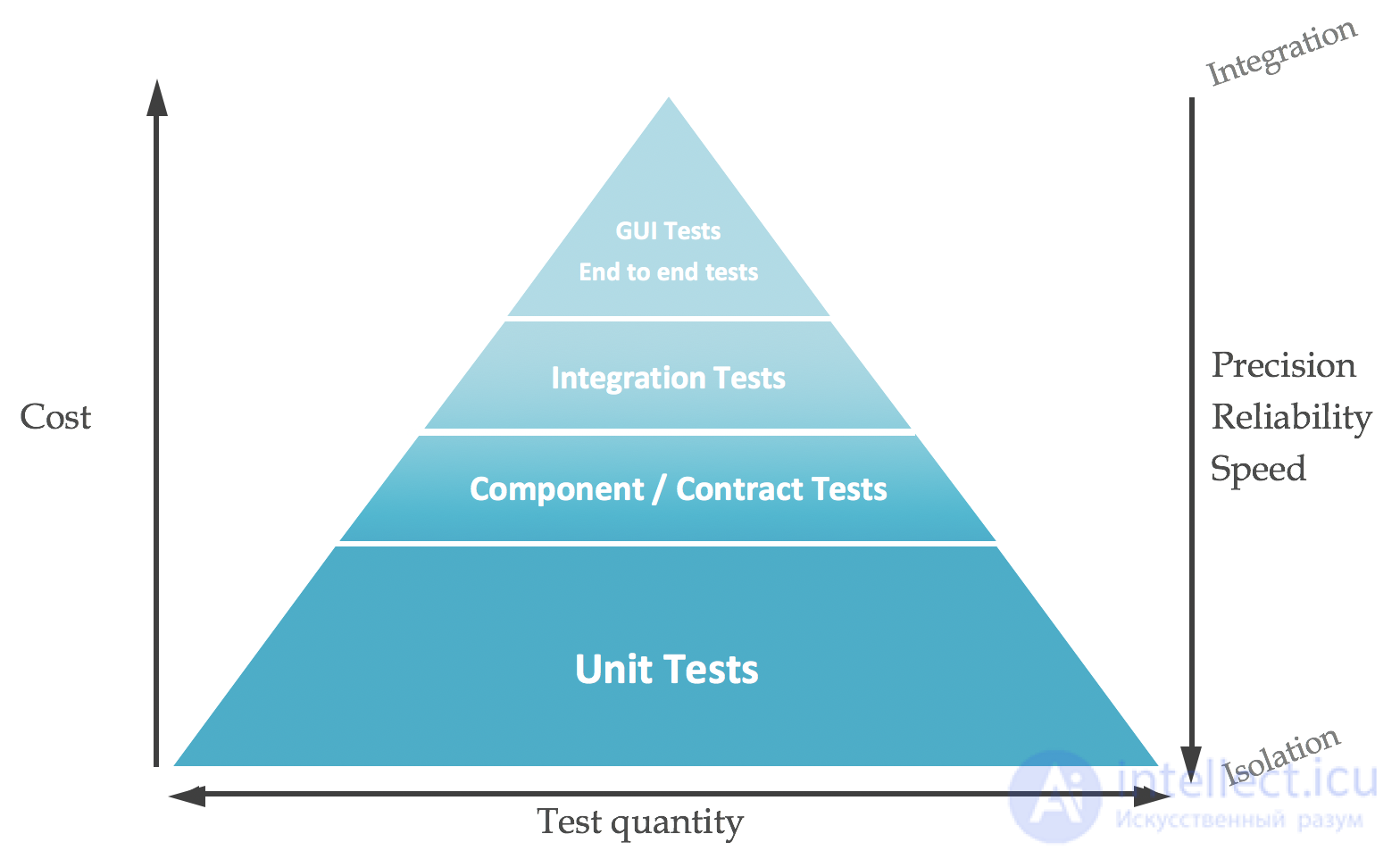
Теперь мы подошли к известной пирамиде тестирования, впервые описанной Майком Коном в своей книге « Успешно работать с Agile» , которая очень помогает при определении стратегии тестирования.
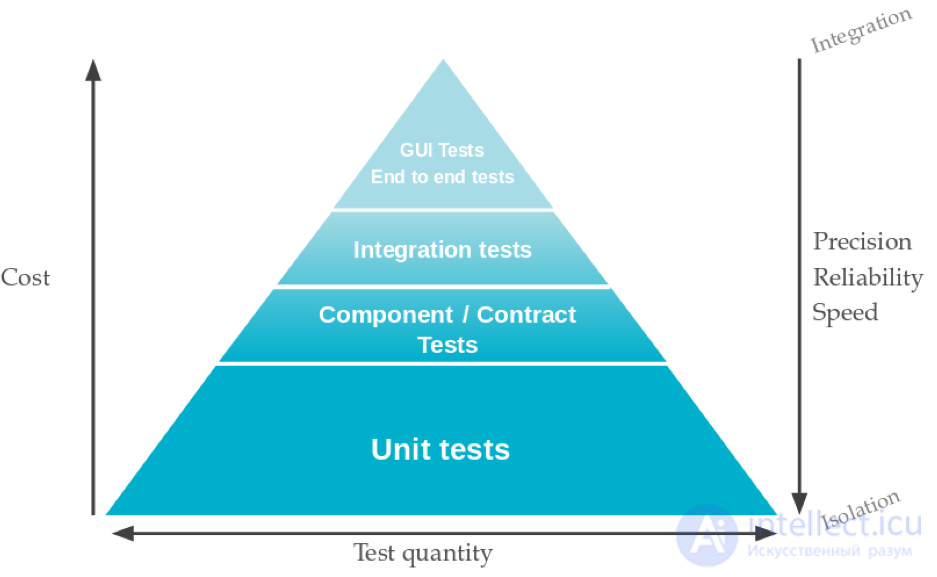

Это завершает наше обсуждение теории. В следующей статье мы более подробно рассмотрим основы пирамиды: модульное тестирование и применение его на практике в проекте Java / Spring.
Давайте начнем с самого начала – с двух столпов, откуда появилось это пресловутое «сквозное бизнес-тестирование», а именно с
пирамиды тестирования и со стандарта ISO9000.
С пирамидой тестирования, наверняка знаком любой тестировщик, поднаторевший в своей профессии и набившей шишек при общении со смежными подразделениями. Особенно часто к ней приходится апеллировать при обосновании автоматизации тестирования. Какие тесты дешевле и важнее разработать? А запустить?
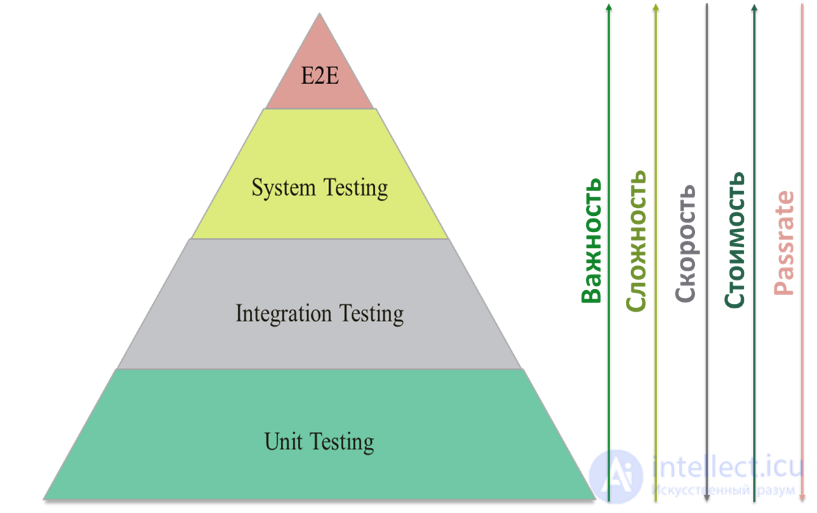
рис. пирамида тестирования
|
Сквозное тестирование |
Системное тестирование |
|
Проверяет программную систему, а также взаимосвязанные подсистемы. |
Проверяет только программную систему в соответствии со спецификациями требований. |
|
Проверяет весь сквозной поток процессов. |
Проверяет функциональные возможности и функции системы. |
|
Для тестирования рассматриваются все интерфейсы и серверные системы. |
Рассматриваются функциональное и нефункциональное тестирование |
|
Выполняется после завершения тестирования системы. |
Выполняется после интеграционного тестирования. |
|
Сквозное тестирование включает в себя проверку внешних интерфейсов, которую сложно автоматизировать. Следовательно, ручное тестирование предпочтительнее. |
Для тестирования системы можно выполнять как ручное, так и автоматизированное тестирование. |
Суть пирамиды тестирования не хитрая: в основе тестирования следует использовать самые простые и самые быстрые в написании и исполнении тесты – модульные тесты. Конечно, проверка интерфейсов классов и функций вряд ли та вещь, которую можно показать заказчику, но без этого прочного, монолитного, безотказного фундамента вряд ли что-то получится выстроить выше. Как правило несколько десятков функций, методов, классов реализуют какую-либо функциональность для заказчика, и по сути десяток модульных тестов можно свести к каким-то верхнеуровневым тестам. Заказчику нужна уже красивая квартира с отделкой, но при этом вряд ли он останется довольным, когда перекошенные окна в его квартире перестанут открываться, а пол и потолок пойдет трещинами от первого подувшего ветерка. Однако самому заказчику зайти в квартиру и проверить ее качество может быть не самой лучшей идеей. Согласитесь, сложно пользователю проверить качество бетона в фундаменте, так и воспроизвести все погодные условия. Об этом говорит сайт https://intellect.icu . Так и в тестировании, конечно, верхнеуровневое тестирование нужно, то только тогда, когда у нас отработали модульные тесты, так и тесты уже более высокого уровня.
Сложнее в разработке и дольше в исполнении более высокоуровневые тесты – интеграционные тесты, которые проверяют корректность работы одновременно работающих модулей, над которыми трудилась вся команда, выпуская свой продукт (систему). То есть проверяется интеграция кода, тестируется система без учета взаимодействия со внешними системами. Такие тесты уже подразумевают проверку высокоуровневую, скорее всего через обращение к систему через системное API или даже GUI (фронт). Работа с таким типом тестов сложнее – чтобы покрыть все ветки и нюансы кода нужно, скорее всего, задействовать большое количество сильно пересекающихся проверок на различных тестовых данных, а при автоматизации зачастую разрабатывать целый ворох условий и ветвлений в скриптах. То есть, с одной стороны мы уже приблизились к пользователю, усложнив себе жизнь, но с другой стороны, нам еще сложно находить общий язык, нам это обходится дороже, а качества проверок все еще недостаточно. То есть мы можем запустить заказчика в новую квартиру, он может все проверить, но без учета взаимодействия с другими жильцами, погодными условиями и коммунальными службами. Согласитесь, толка от идеального мира, модели, в реальной жизни, как правило, немного.
Если мы добавим и эти условия – посмотрим как наша система взаимодействует со внешними системами – поставщиками и потребителями, с нашим окружением, то есть проведем системное тестирование, то легко увидим, что сложность тестирования тоже возрастет. Нам нужно будет добиваться одновременной работоспособности всех взаимодействующих систем, хотя и без привлечения специалистов по ним. Нам пока что достаточно просто принять какие-то данные от наших поставщиков и передать наши данные нашим потребителям. В правильной последовательности и формате. Дальнейшая судьба данных нас не волнует. Главное – наша система работает правильно в правильном окружении. И все бы тут хорошо – для нашего заказчика мы можем провести уже полномасштабную демонстрацию, да только в реальной жизни это еще не все критерии успеха для нашей разработки. Конечно хорошо, что у заказчика появилась его квартира в прочном доме, но если от нее надо добираться, перелезая через колючую проволоку, затем на каноэ по озеру с крокодилами в шалаши, кишащие змеями, то, возможно, мы что-то не то и не там сделали?
Поэтому тут первая идея для сквозного тестирования – проверять не только наше окружение, но и все взаимосвязанные системы, через которые проходят данные принимаемые или отправляемые нашей системой. А это, в свою очередь, означает, что мы должны будем совместить несколько таких «пирамид тестирования» между собой. Постройка хрупкого моста, по которому мы проведем за ручку данные, ценные для пользователя.
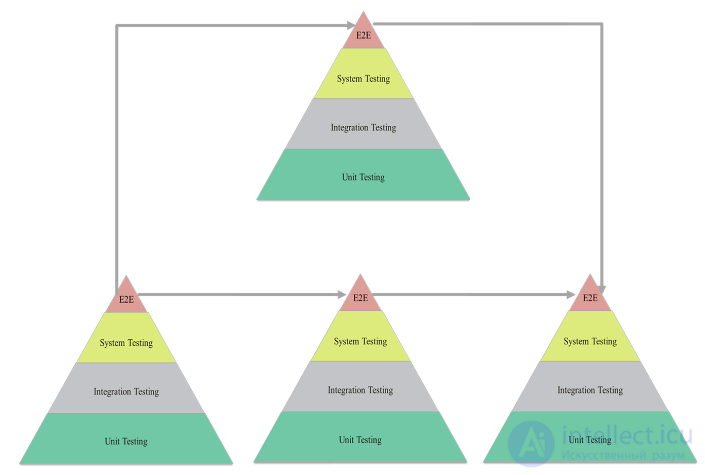
Вот только вопрос как это делать? Кому это делать? Как собирать воедино?
Серия стандартов, описывающих системы менеджмента качества, в том числе говорит о том, что любой процесс в организации должен быть описан, задокументирован, даже если это процесс выдачи граблей по осени дворнику. А раз так, что ни один процесс, который проходит внутри ПО, используемого и разрабатываемого в организации, не может не быть описан. Вопрос в том, как это делать? Конечно, лучшее описание, с точки зрения BDD — это описание поведения тестами, под которыми будет лежать пирамида тестирования. Но мы сразу же вернемся к нашей дилемме с объединением нескольких пирамид тонкими канатами от верхушки к верхушке, по которым без страховки будет ходить наш канатоходец-заказчик и его пользователи.
Process approach is a management strategy that requires organisations to manage its processes and the interactions between them. Thus you need to consider each major process of the company and their supporting processes.
Поэтому проще всего воспользоваться абстракциями – создать хотя бы схему процесса, и указать ее входы и выходы, сделать процесс контролируемым и измеряемым, обеспечить взаимосвязь с родительскими и дочерними процессами, как того и требует ISO9000
All processes have:
• inputs;
• outputs;
• operational control;
• appropriate measurement & monitoring.
Each process will have support processes that underpin and enable the process to become realised

Для этой цели лучше всего подходят бизнес-диаграммы, и чаще всего используются стандарты вроде UML, BPMN, ARIS и пр. А сами процессы становятся блок-схемами с нанизанными на них «кубиками». Между «кубиками» происходит взаимодействие, в стандарте BPMN — это поток действий и поток сообщений. И вот это как раз то, что нам нужно!
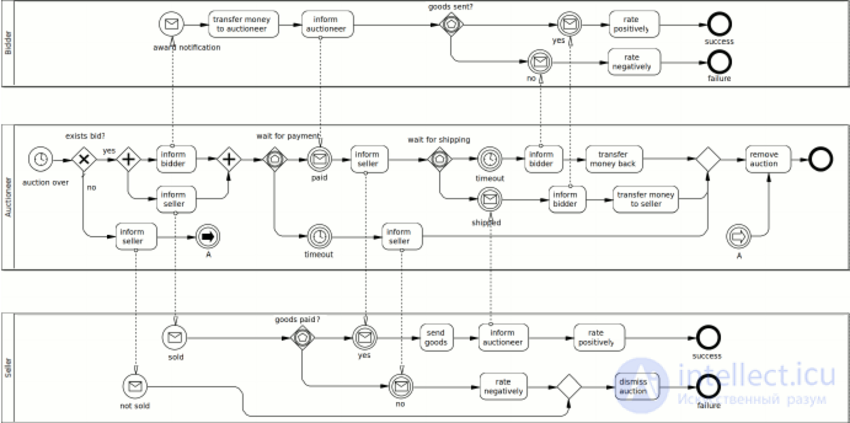
Любая компания, которая хочет иметь сертификат и следует стандарту ISO9000, скорее всего, обзавелась такими схемами, и они являются неотъемлемой частью верхнеуровневых требований. Если в компании работают хорошие аналитики, то, скорее всего, к низкоуровневым требованиям будут спускаться ссылки-требования на отдельные действия из схем. Они-то нам и нужны.
Фактически, на схемах мы можем увидеть процесс целиком, и понять, какой сценарий нам нужно построить, и к какой системе\команде бежать с какими данными в какой момент.
Я тут не преуменьшаю труд разработчиков, которые пишут грамотный код, который пересылает сообщения между разными частями программно-аппаратных комплексов, но все держать в уме невозможно. И когда процесс используется во множестве других процессов, лучше иметь такую «карту» при себе для проведения грамотного тестирования, и, тем более для построения тестовой модели.
Итак, мы имеем две вводных – у каждой команды\системы должна быть подготовлена пирамида из тестов – от самых мелких, модульных тестов, до сложных системных тестов, а так же тот факт, что в рамках организации у нас обязаны быть описаны требования в виде бизнес-процессов. Этот факт нам позволит быстро ответить заказчику, какой бизнес-процесс как работает, и на каком моменте из-за чего ломается, а самим, при получения дефектов с промышленной эксплуатации быстро произвести root cause analysis (анализ корневых причин возникновения дефектов). В теории.
А на практике все опять ложится на тестировщика – как из вороха тестов, тем более чужих, выбрать нужные, выстроить их в цепочку, а на вход каждой из систем подать нужные данные и сверить с корректно определенным ожидаемым результатом?
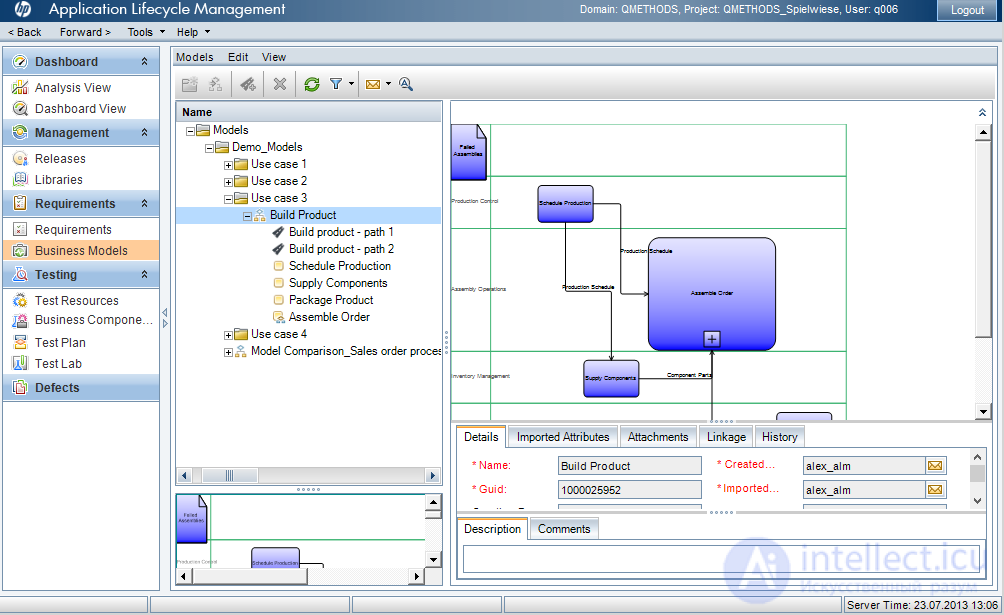
Самый простой вариант – изначально разрабатывать тесты на основании бизнес-моделей, а деление команд делать по проектам, реализующим тот или иной бизнес-процесс. Для этого в некоторых инструментах управления тестированием есть уже возможность загружать BPMN-схемы (например для HPE ALM – поддерживается загрузка в формате XPDL). HP ALM сам разобьет схему на набор требований (действий), а при желании создаст иерархию требований (модуль Requirements->Business Models). Далее наше дело покрыть требования тестами, а далее выстроить требования, а значит и тесты в цепочки, покрывающие наш бизнес-процесс. Эти цепочки в HPE ALM называются «путями» (path), и позволяют увидеть все комбинации последовательностей. При желании требования, цепочки можно сразу сконвертировать в тесты.
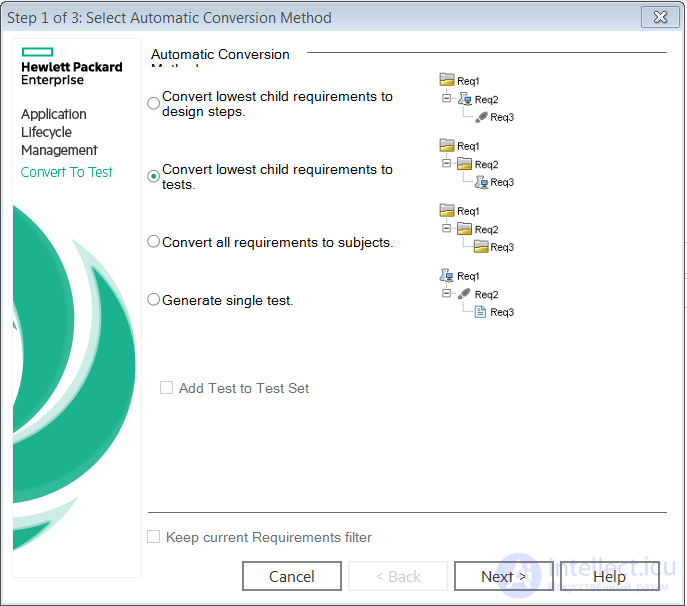
Но даже если не использовать инструменты тестирования, все равно придется из бизнес-процесса составлять цепочки. Тем более учитывая несовершенство инструментов (не все так радужно), а так же тот факт, что, скорее всего, тестовую модель нужно будет собирать пост-фактум, а исполнять и вовсе в виде регресса «общей командой», не прилепленной к новым проектам.
Сколькими путями может дойти грызунцик до шишки?
В этом случае нам нужно будет открыть тесты каждой из команд, найти привязанные к фигурирующим в бизнес-модели требованиям, и выстроить из них цепочки, сохранив в «общем пространстве». Создание общего пространства – это какой-то суррогат, но в любом случае оно должно быть, пусть в виде амбарной книги, excel, или проектной области в инструменте управления тестированием. Если снова говорить о HPE ALM, то за данный функционал отвечает модуль BPT (Business Process Testing), заодно позволяющий передавать результаты одного теста в параметры другого. Впрочем, при желании и упорном труде на HPE ALM это возможно и реализовать через перестроения тестовых наборов (Test set) в поток выполнения (Execution flow). Тогда при запуске полного набора будут по очереди вызываться тестировщики, ответственные за прохождения каждой из компонент сквозного сценария.
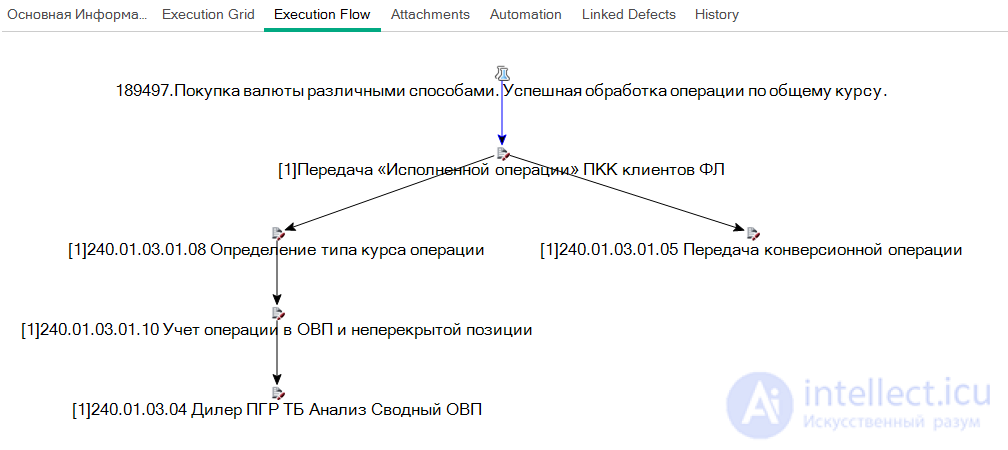
И, увы, одним лишь средством управления тестирования не обойтись. Из моей практики, почти что все инструменты имеют какие-то фатальные недостатки, и поэтому, если вы дойдете до этапа автоматизации тестирования по бизнес-процессу – то придете к созданию скрипта, который будет дергать в нужной последовательности тесты.

В итоге, можно сделать два вывода:
1) для сквозных сценариев используются с большой долей вероятности уже ранее разработанные тесты для каждой из систем, входящей в цепочку (сценарий) бизнес-процесса
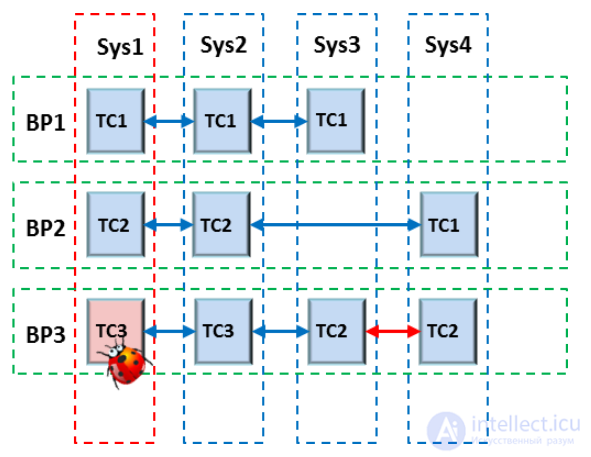
Можно все полные тестовые наборы компании представить в виде разреженной матрицы, где по столбцам распределены тесты для каждой системы (для простоты – системные), а по строкам – бизнес-процессы. То есть для тех или иных бизнес-процессов надо выбрать\создать тесты, покрывающие бизнес-процесс, установить взаимосвязи. Если покрытия нет – это повод восполнить пробелы в тестовой модели, либо удостовериться, что качество обеспечивается другими уровнями тестирования (интеграционное тестирование, модульное тестирование, ревью кода и прогон его через анализаторы).
2) Необходим инструмент наблюдения, трассирования и актуализации бизнес-процесса на предмет синхронизации с тестовой моделью.
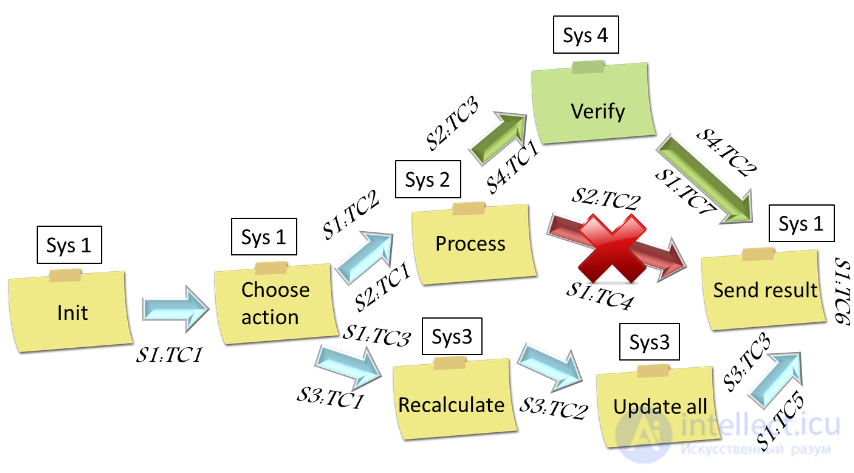
И если с созданием тестовой модели инструменты тестирования более-менее сносно справляются, то с актуализацией все в действительности очень плохо, зачастую проще модель пересоздать заново, чем пытаться увидеть изменения в процессе и тестовой модели. И опыт реальных команд говорит о том, что лучше создавать живую визуализацию архитектуры. Проще всего это сделать в общей зоне, воспользовавшись простой маркерной доской и стикерами. Тогда, команды, которые участвуют в бизнес-процессе могут наглядно видеть, как видоизменяется процесс (убираются и добавляются связи, убираются и добавляются действия). Главное – чтобы все имели доступ к доске. Плюс, обратите внимание, что если в процессе подразумевается сообщений между системами, то, как правило, хотя бы должно быть два теста от каждой системы – на отправку и на прием данных. Впрочем, вместо стикеров можно использовать целый лего-город (из крупных блоков), или что-то еще более креативное. Главное тут – один язык и одно информационное пространство, чего очень в enterprise не хватает.
Организация наглядного и правильного тестирования по бизнес-процессам – сложная и очень дорогая вещь. Обратите внимание, что E2E тестирование – это не просто приемка, пользовательское тестирование, которое будет выполнять заказчик, это выстраивание мостика, с учетом всех возможных ситуаций, по которому пойдет заказчик и поведет за собой в ногу пользователей.
Еще раз – E2E – это не прогулка на Ладе-Калине через мост, и даже не проезд на двух камазах. Это сложная инженерная работа, обвешивание мостов датчиками и проведение всех возможных проверок и ситуаций — по крайней мере описание этих сценариев.
Нужно или нет вашей компании такой идеальный чистовой прогон – дело исключительно ваших целей и потребностей. Всегда, как и при любом тестировании, следует оценить потенциальные риски от пропущенных дефектах на этой стадии, так и стоимость работ по подготовке и проведения сквозного тестирования. Оценить, что из этого обойдется вам дороже и только потом действовать. Но в случае сквозного тестирования по бизнес-процессам следует помнить, что оно не имеет смысла без прочного фундамента в виде 100% passrate unit-тестов (~90-100% coverage), без интеграционных тестов (~60-80% coverage, 90-100% passrate), без системных тестов (20-40% coverage, 80-100% passrate). Устанавливать критерии успешности (quality gates) – это больше требования к качеству выпускаемого продукта, главное здесь помнить, что объем E2E тестов – лишь верхушка пирамиды (1-2% coverage, ~99% passrate), которая не должна быть больше его основания, не быть при этом затычкой дыр с предыдущих этапов. Это – дополнение, которое априори считается закрытым на предыдущих этапах.
Организация подобного тестирования – главным образом работа по подготовке и синхронизации тестовых случаев и данных (тест-аналитика), а так же комплекс организационных мероприятий, синхронизация команд в одном месте в одно время на работоспособном тестовом полигоне. Помня это, не следует пробовать показывать заказчику «сквозное тестирование» раньше срока, чтобы не тратить время сразу большого количества людей без всех работающих компонентов, собранных воедино.
P.S. описанные инструменты, а так же практики – сугубо для примера, автор не ставил цели себе рекламировать продукты и декламировать единственно верным данный подход к сквозному тестированию.
Для чего:
что бы быть уверенным, что ничего не сломано в процессе
что бы сократить время регрессионого тестирования до нескольких минут
что бы тестировать не меняя рабочий процесс/код
Для WEB программирования
как применение поведенческие тесты
Пример теста
Установка
npm install cypress
Запускаем
./node_modules/.bin/cypress open
Выбираем тест
Пишем тесты в папке integrations
cd cypress/integration
Пишем тест в BDD-стиле с использованием cypress
describe('Guest test checkout', function(){
it('has to open PDP and pass checkout', function(){
cy.visit('https://example.com/paget1'); // <-- откроет страницу и дождется загрузки
cy.get('#add-to-cart').click(); // <-- найдет кнопку и нажмет ее когда она станет видимой
cy.get('.mini-cart-link-cart').click();
end-to-end Test Automation for Behavior-Driven Development
мы обсуждали теорию пирамиды тестирования - стратегии тестирования, обеспечивающей качество нашего приложения при разумных затратах. Примечательно, что мы обсудили понятие обратной связи и важность наличия быстрой, точной и надежной обратной связи. Модульные тесты обычно соответствуют этим критериям для скромных инвестиций. В этой статье мы разработаем конкретный пример для изучения использования автоматических модульных тестов и попытаемся ответить на некоторые из постоянных вопросов наших читателей.
«Разница между теорией и практикой заключается в том, что в теории нет разницы между теорией и практикой, но на практике она есть».
Ян Ван де Снепшой
Давайте перейдем к практической части. Для этого и для завершения нашего обзора тестов мы возьмем пример микросервисов. Конечно, этот выбор не является совершенно случайным: микросервисы должны быть максимально автономными (команда, соединение, развертывание и т. Д.), И эта автономия включается посредством тестирования: интеграция и сквозные тесты не совсем подходят, если Мы хотим постоянно развертывать наш сервис независимо от других.
Следующая диаграмма лаконично описывает архитектуру нашего примера:
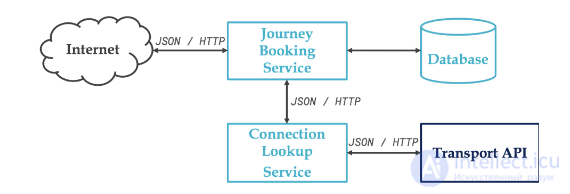
Мы решили создать набор служб для поиска и бронирования поездок на поезде, но вместо того, чтобы использовать API от национальной железнодорожной компании Франции, SNCF, мы выбрали Swiss Open API, доступный по адресу : https://transport.opendata.ch/. . Последний предоставит нам маршруты и расписание.
Служба поиска соединений является фасадом над этим API, который позволяет отделиться от этого внешнего сервиса. Наш интерес к этой статье более образовательный, но мы вернемся к нему.
И, наконец, сердце системы, служба бронирования путешествий отвечает за поиск маршрутов и их запись в базу данных.
Конечные точки:
GET /journeys/search?from=...&to=...
позволяет искать доступные маршруты, но не забронированные поездки (это точка входа для службы поиска).
GET /journeys
дает список всех зарезервированных поездок
GET /journeys/{id}
дает поездку, чей идентификатор передается в запросе
POST /journeys
позволяет забронировать поездку
PUT /journeys/{id}
позволяет изменить бронирование поездки
DELETE /journeys/{id}
удаляет поездку, идентификатор которой передается в запросе
Последние 5 конечных точек будут взаимодействовать с базой данных (в нашем случае, Postgres).
Наш микросервис бронирования структурирован, как показано на следующей диаграмме. Это очень стандартно, пример прост, а бизнес-логика минимальна. Было бы разумно сделать все в контроллере, но ради примера мы сохраним наш уровень обслуживания и посмотрим, куда он нас приведет.
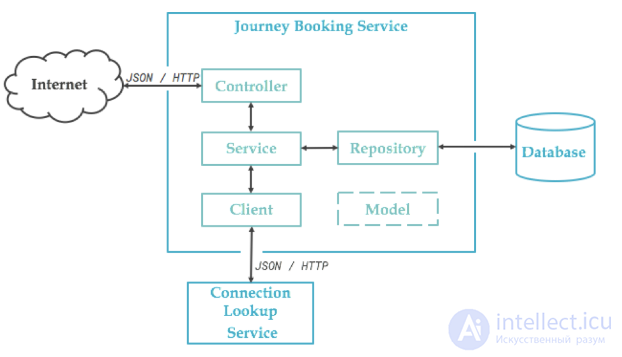
С технологической точки зрения мы будем использовать стандарт: Spring и его экосистему. Существует множество инструментов для тестирования Spring, и хорошо знать, что и когда использовать. Полный проект доступен на gitlab .
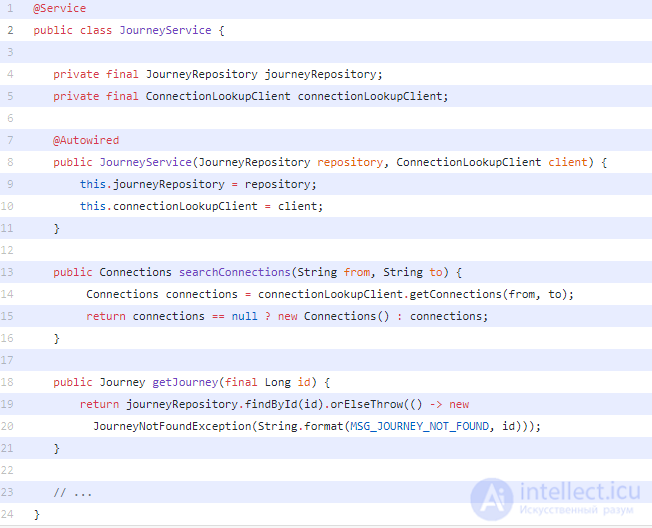
Мы начнем с основания пирамиды с юнит-тестами. Модульный тест направлен на проверку отдельного поведения (т. Е. Метода или подмножества метода), возникающего в результате бизнес-использования в отрыве от остального мира:
Некоторые скажут, что не нужно все изолировать. В эффективной работы с юнит - тестами Jay Fields вводит понятия социальных испытаний и одиночных испытаний. Лично я за то, чтобы изолировать как можно больше, чтобы избежать каких-либо помех. Для простоты наши модульные тесты не зависят от какого-либо внешнего ввода / вывода, то есть баз данных, файловых систем, сетей и т. Д.
Чтобы сделать это, мы используем то, что некоторые называют пробками, другие заглушки, насмешки или подделки - то, что в литературе называется Test Double . Это объект, который мы полностью контролируем и который заменяет тестируемый объект. Это позволяет нам проверять различные варианты поведения в зависимости от значений, возвращаемых двойным, например, счастливый путь, крайние и угловые случаи и ошибки.
Хотя можно создавать тестовые дубликаты вручную, существует также множество доступных библиотек, которые упрощают их реализацию: Mockito , EasyMock или JMockit являются наиболее известными в мире Java.
Если мы посмотрим на нашу предыдущую схему, мы проведем модульное тестирование каждого из объектов, составляющих наш компонент:
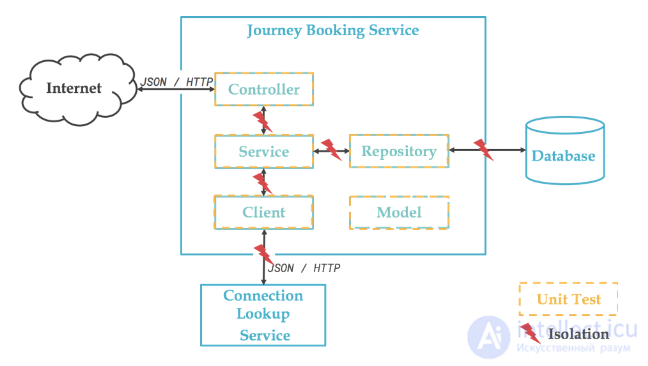
По правде говоря, поскольку Клиент реализован с библиотекой Feign , реального кода для тестирования нет:

Аналогично для части Repository, которая основана на Spring Data и поэтому не имеет кода:
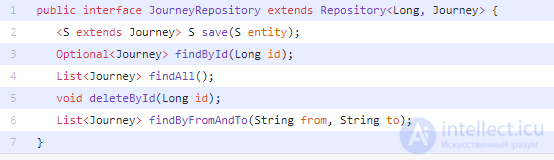
Мы вернемся к этим двум элементам в наших интеграционных тестах, поскольку наша цель не состоит в тестировании базовых сред, которые уже хорошо протестированы в других местах.
Итак, теперь у нас есть следующая схема:
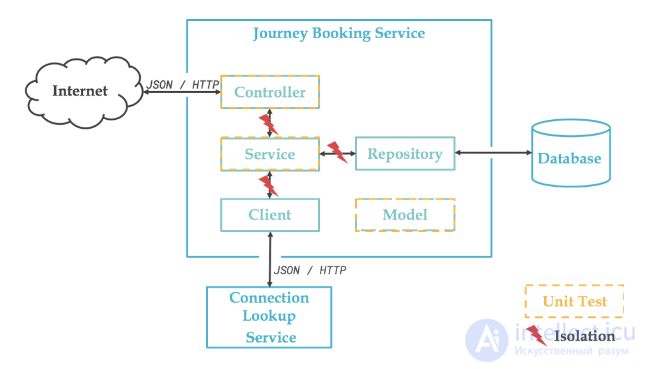

Как мы уже говорили, Контроллер - это почти простой служебный уровень, почти.
Служебные слои Utility layers
Обычный вопрос, который задают нам многие читатели: « Стоит ли тестировать служебный слой? «На что мы отвечаем другим вопросом: « Стоит ли иметь этот служебный слой? » , Часто эти слои предназначены только для обеспечения многоуровневой структуры и не имеют никакой цели, кроме как быть «на всякий случай».
В общем, практика TDD (Test Driven Development) помогает нам избежать этого. Не вдаваясь в подробности практики, которая стоила бы полной статьи , TDD стремится определить ожидаемое поведение с помощью теста перед его реализацией. Таким образом, мы сначала пишем тест, а затем самый простой код, который позволяет тесту пройти и, следовательно, удовлетворять указанному поведению. Это позволяет избежать чрезмерного проектирования и создания «на всякий случай» слоев и фокусируется на простейшем коде, который быстро предоставляет значение.
В нашем примере, хотя у контроллера, похоже, мало кода, у него все еще есть две обязанности: выставлять объекты передачи данных (DTO) вместо сущностей и выставлять API с помощью аннотаций. Код (хотя и минимальный) будет тестироваться индивидуально, а мы будем проверять экспозицию (отображение URL, управление кодом ошибки и т. Д.) В тестах компонентов.
Private методы
Еще один постоянный вопрос среди наших клиентов: « нужно ли / как тестировать частные методы? «.
100% покрытие или ничего
С помощью таких инструментов, как Jacoco , Cobertura или Clover , можно определить, какая часть нашего кода достигнута / покрыта при выполнении тестов. Помимо этого простого индикатора, эти инструменты позволяют нам увидеть, где были пройдены тесты и, особенно, где они провалились. Затем мы можем проверить, проверены ли критические пути нашего приложения или нет.
Мы должны позаботиться о том, чтобы полагаться на покрытие кода в качестве индикатора, потому что это может вводить в заблуждение: безусловно, можно выполнить 100% кода, ничего не тестируя (например, не утверждая ничего). Не стремитесь к 100%, вместо этого начните с того, что сосредоточьтесь на критических частях приложения, и следите за тенденцией охвата вашего кода. Это увеличивается? Уменьшение? Если вы хотите пойти дальше, можно применить мутационное тестирование (также известное как тестирование хаос-обезьяны), которое более или менее случайным образом изменяет бизнес-код и проверяет, что тест не пройден. Если тесты продолжат проходить, вероятно, код не будет эффективно проверяться. Платформа Pitest может автоматизировать это в Java.
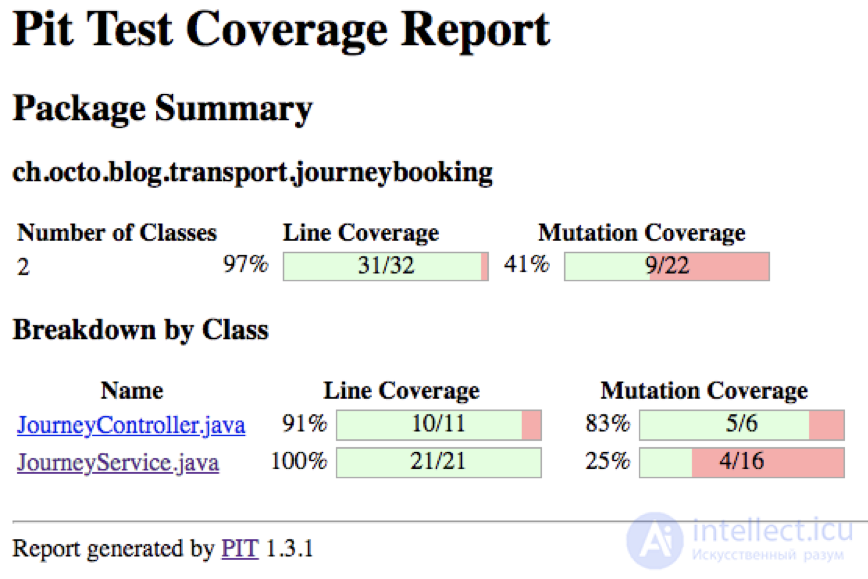
Например, в следующем отчете указывается, что JourneyService (после удаления всех утверждений) полностью покрывается тестами, но эти тесты довольно плохо оцениваются по охвату мутаций.
Пример «неполного» теста:
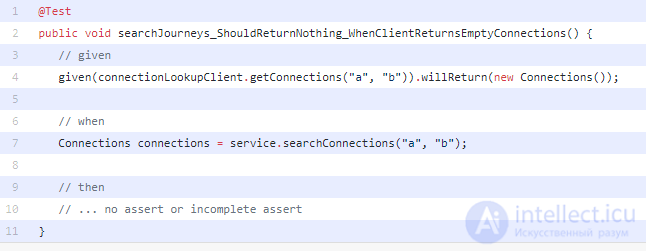
И связанный отчет:
Мы будем использовать JUnit, AssertJ и Mockito для реализации наших тестов, заметьте, что на этом уровне пирамиды нет Spring. Вот выдержка из наших тестов для JourneyService ( ссылка на Gitlab ):
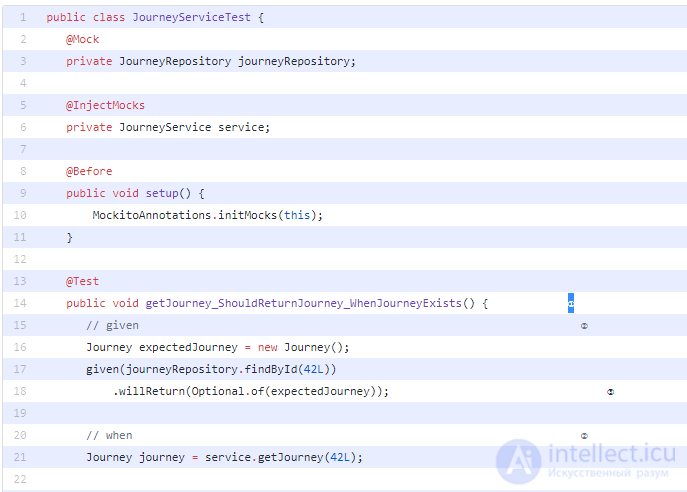
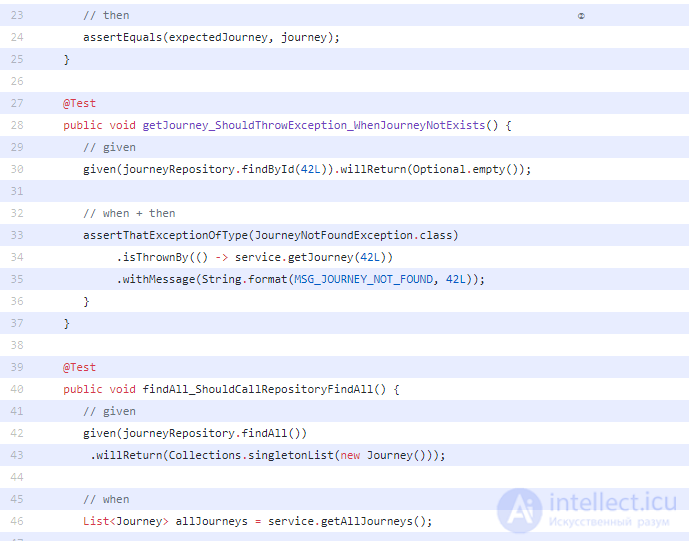
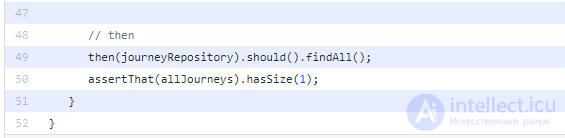
Несколько вещей, чтобы отметить в этом коде:
unitUnderTest_ShouldExpectedBehavior_WhenInitialState
Мы можем не соблюдать это соглашение об именах, но тестовый код должен быть максимально читабельным, если не более, чем бизнес-код. Пока это понятно, тестовый код документирует, что ваше приложение на самом деле делает лучше, чем любая документация.
Лично я использую некоторые комментарии из синтаксиса Behavior Driven Development (BDD): дано, когда, тогда, чтобы структурировать тест. Другие используют правило 3А: аранжировка, действие, утверждение . Ключ должен иметь хорошо структурированный и читаемый код.
Само собой разумеется, что эти тесты должны выполняться непрерывно в вашем конвейере сборки после каждой фиксации, чтобы как можно скорее обнаружить регрессии. Модульные тесты проверяют бизнес-аспекты вашего приложения, то есть бизнес-логику и алгоритмы. Они представляют собой защитную оболочку для любой модификации кода - то есть добавления функций, рефакторинга и исправления ошибок - и я не могу не подчеркнуть, что они необходимы.
Они необходимы, но не достаточны. В дальнейшем мы обсудим компонентные тесты, которые дополняют набор тестов, которые полезно иметь в своем наборе инструментов.
Исследование, описанное в статье про пирамида тестирования, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое пирамида тестирования, сквозное тестирование, end-to-end , пирамиды тестирования и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Качество и тестирование программного обеспечения. Quality Assurance.
Комментарии
Оставить комментарий
Качество и тестирование программного обеспечения. Quality Assurance.
Термины: Качество и тестирование программного обеспечения. Quality Assurance.