Лекция
Это продолжение увлекательной статьи про средства анализа процессов .
...
па-
ры узлов x и y из множества P T верно x(F F−1)* y , где R−1
— инвер-
сия, а R* — рефлексивное и транзитивное замыкание отношения
R . Сеть
|
средства анализа процессов — Process Mining |
419 |
N = (P,T, F) сильно связана тогда и только тогда, когда для любой пары узлов x и y из множества P T верно xF* y .
Будем считать, что все сети слабо связаны и имеют, по крайней мере, две вершины. Сеть Петри, изображенная на рис. 15.11, связана, но не сильно.
Размеченная сеть Петри ( N, s0 ) , где N = (P,T, F) , ограничена тогда и только
|
тогда, когда множество достижимых разметок |
N , s конечно. |
|
|
|
Размеченная сеть Петри ( N, s0 ) , где N = (P,T, F) , безопасна тогда и только
тогда, когда для любого s ' N, s и p P , s '( p) ≤1 . Безопасность подразу-
и p P , s '( p) ≤1 . Безопасность подразу-
мевает ограниченность.
Размеченная сеть Петри, изображенная на рис. 15.11, безопасна (и поэтому ограничена), т. к. ни одна из 6 достижимых разметок не имеет более одного маркера на одной позиции.
Пусть (N, s) , где N = (P,T, F) — размеченная сеть Петри. Переход t T называется "живым" в сети (N, s) , тогда и только тогда, когда есть достижимая
|
разметка s ' N, s , такая что |
( N, s ') t |
. Сеть (N, s) называется "живой", |
|
|
|
|
|
|
|
если для каждой достижимой разметки |
s ' N, s |
и для каждого перехода |
|
|
|
|
|
|
|
t T существует достижимая разметка |
s '' N, s ' |
, такая что ( N, s '') t . То, |
|
|
|
|
|
|
что сеть "живая", предполагает, что все ее переходы "живые". Все переходы размеченной сети Петри, изображенной на рис. 15.11, "живые", однако сеть не является "живой", т. к. все переходы не могут сработать последовательно.
Workflow-ñåòè
Большинство Workflow-систем предоставляют стандартизированные структурные блоки, такие как AND -разделение, AND -соединение, XOR -разде- ление и XOR -соединение. Они используются для моделирования частичного, последовательного, условного и параллельного выполнений потоков задач. Очевидно, что сети Петри могут быть использованы для отслеживания процесса выполнения потоков задач. Задачи моделируются переходами, а зависимости — позициями и дугами. Каждой позиции соответствует условие, которое может быть использовано как предусловие или как постусловие для задач. AND -разделению соответствует переход с двумя или более исходящими позициями. AND -соединению соответствует переход с двумя или более входными позициями. XOR -соединению/разделению соответствуют позиции с двумя или более входными/выходными переходами. Учитывая тес-
ную связь между этими двумя понятиями, в дальнейшем будем считать понятия "задачи" и "переходы" взаимозаменяемыми.
Сеть Петри, которая моделирует очередность выполнения задач в потоке работ, называется сетью потоков работ (Workflow-сеть). Следует отметить, что Workflow-сеть определяет динамическое поведение каждого случая протекания потока задач в отдельности.
Пусть N = (P,T, F) — сеть Петри, а t — переход, не являющийся частью
P T . N — сеть потоков работ, или Workflow-сеть (WF-сеть), тогда и только тогда, когда выполняются следующие условия:
P содержит позицию i , такую что •i = (начальная позиция);
P содержит позицию o , такую что o• = (конечная позиция);
сеть N = (P,T {t}, F {(o,t), (t,i)}) сильно связана.
Сеть Петри, изображенная на рис. 15.11, является WF-сетью. Даже если сеть удовлетворяет изложенным ранее синтаксическим требованиям и является WF-сетью, соответствующий ей процесс может содержать ошибки, такие как: тупики, задачи, которые никогда не выполняются, активные тупики, мусор, оставляемый процессом после завершения работы, и т. д. Учитывая это, определим критерий бездефектности (правильной завершаемости).
Пусть N = (P,T, F) — WF-сеть с начальной позицией i P и конечной позицией o P . N является бездефектной тогда и только тогда, когда выполняются следующие условия:
размеченная сеть (N,[i]) является безопасной;
|
для любой разметки s N,[i] |
o s |
подразумевает, что s = [o] , т. е. при |
|
достижении конечной вершины сети N не должно быть маркеров в про- |
||
|
межуточных позициях; |
|
|
|
для любой разметки s N,[i] |
[o] |
N, s , т. е. конечная вершина дости- |
|
|
|
|
жима из любой разметки;
(N,[i]) содержит только живые переходы.
Множество всех бездефектных WF-сетей обозначается как W .
WF-сеть, изображенная на рис. 15.11, бездефектна. Свойство бездефектности может быть проверено путем использования стандартных методов анализа, разработанных для сетей Петри. Фактически свойство бездефектности соответствует свойствам живости и безопасности для короткозамкнутой сети.
Пусть N = (P,T, F) — сеть Петри с начальной разметкой s . Позиция p P
называется скрытой (имплицитной) в (N, s) тогда и только тогда, когда
|
Средства анализа процессов — Process Mining |
421 |
|
для всех достижимых разметок s ' N, s |
и переходов t p • |
|
|
|
|
s ' ≥ •t \ { p} s ' ≥ •t . |
|
Сеть Петри, изображенная на рис. 15.11, не содержит скрытых вершин, однако добавление позиции p , соединяющей переходы A и D , приведет к появлению скрытой вершины. Распознавание скрытых вершин затруднено тем, что их добавление не оказывает никакого влияния на поведение сети.
Структурированные Workflow-сети (SWF-сети) являются подклассом WF-се- тей, полученным путем наложения дополнительных ограничений. SWF-сети не должны содержать конструкций, изображенных на рис. 15.12.
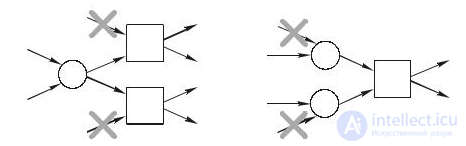
Рис. 15.12. Конструкции, запрещенные в SWF-сетях
Левый структурный блок иллюстрирует ограничение, что выбор и синхронизация не должны встречаться. Если два перехода имеют общую выходную позицию и таким образом "сражаются" за один и тот же маркер, у них никогда не должно быть синхронизации. Это означает, что "позиции-выборы" (позиции с несколькими выходными переходами) никогда не должны контролироваться синхронизациями.
Правый структурный блок, изображенный на рис. 15.12, иллюстрирует ограничение, что если есть синхронизация, все прямо предваряющие ей переходы должны сработать до момента синхронизации, т. е. не разрешается наличие синхронизаций, прямо перед XOR -соединением.
Структурированные сети потоков задач определяются следующим образом:
|
WF-cеть |
N = (P,T, F) |
является SFW-сетью тогда и только тогда, когда вы- |
|
|
полняются следующие условия: |
|||
|
для всех |
p P и |
t T , для которых ( p, t) F : |p•| >1 , предполагается, |
|
|
что |
• = |
; |
|
для всех 1 и t T , для которых ( p, t) F : | • t| >1 , предполагается, что
| • p| =1 ;
сеть N не содержит скрытых вершин.
Логи событий
Отправным пунктом для любого алгоритма Process Mining является лог событий (event log). Лог событий является множеством следов событий (event trace). Каждый след соответствует однократному протеканию процесса (case или process instance). Нужно отметить, что лог может содержать одинаковые следы события, что означает, что при различных протеканиях процесса события следовали одинаковому "пути" в процессе.
|
Пусть T — набор задач, тогда σ T* — след |
событий, а функция |
|
L : T* → N — лог событий. Для любого σ dom(L) |
L(σ) — количество по- |
явлений σ . Множество логов событий обозначается как L .
Здесь и далее используются следующие условные обозначения:
dom( f ) — область определения функции f ;
rng( f ) — область значений функции f .
σ L подразумевает, что σdom(L) L(σ) ≥1 .
Пример. Допустим L = [abcd, acbd, abcd] — лог для сети, изображенной на рис. 15.14, тогда L(abcd) = 2 , L(acbd) =1 , L(ab) = 0 .
На основании информации, содержащейся в логе, можно делать заключения о взаимных отношениях между событиями. В случае α -алгоритма любые две задачи в логе L должны находиться в одном из четырех возможных отношений упорядочивания:
>L — "следует за";
→L — "строго следует за";
|L — "параллельно";
#L — "не связано".
Данные отношения выделяются из локальной информации в логе событий. Отношения упорядоченности определяются следующим образом: пусть L —
лог событий над набором задач T , т. е. L : T* → N , a, b T :
a >L b тогда и только тогда, когда существует след σ = t1t2t3...tn , такой что
σ L и ti = a , а ti+1 = b , где i {1,..., n −1} ;
a →L b тогда и только тогда, когда a >L b и b >/ L a ;
a #L b тогда и только тогда, когда a >/ L b и b >/ L a .
Гарантией того, что лог событий содержит минимум информации, необходимый для успешного выявления потока задач, служит понятие полноты лога,

|
Средства анализа процессов — Process Mining |
423 |
|
которое определяется следующим образом: пусть N = (P,T, F) — бездефект- |
|
|
ная WF-сеть, т. е. N W . L является логом событий для |
N тогда и только |
тогда, когда dom(L) T* и каждый след σ L является последовательностью срабатывания в N , начинающейся в начальной позиции i и заканчивающей-
ся в конечной позиции , т. е. (N,[i]) σ ( N,[o]) . L является полным логом o
событий для сети N тогда и только тогда, когда для любого лога L' для
N : >L ' >L .
Для сети, изображенной на рис. 15.14, одним из возможных полных логов является следующий: L = {abcd, acbd, ef } . Из данного лога можно получить информацию о таких отношениях порядка:
a >L b , a >L c , b >L c , b >L d , c >L b , c >L d и e >L f ;
a →L b , a →L c , b →L d , c →L d и e →L f ;
b |L c и c |L b ;
x #L y и 1 для x {a,b,c, d} и y {e, f } .
Описание α-алгоритма
Данный алгоритм считается основным алгоритмом Process Mining (хотя и не самым эффективным), т. к. он является единственным, имеющим под собой теоретическую базу. Существует класс распознаваемых им моделей и доказательство того, что он может выявить модели этого класса из логов при условии наличия достаточной информации.
Пусть L — лог событий для набора задач T , тогда α(L) определяется следующим образом:
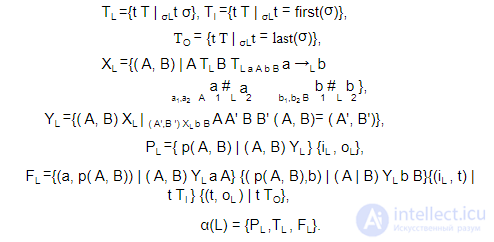
Схема алгоритма:
1.Просматриваются содержащиеся в логе следы событий. Создается множество переходов (TL ) WF-сети.
2.Создается множество выходных переходов TI для начальной позиции.
3.Создается множество входных переходов TO для конечной позиции.
4.Создается множество XL , используемое для определения позиций в рас-
познаваемой WF-сети. На данном шаге α -алгоритм определяет, какие переходы связаны между собой отношением casual. В каждом кортеже ( A, B) из множества XL каждый переход в множестве A , который строго
следует за всеми переходами в множестве B , и ни один переход множества A ( B ) не следует за другими переходами данного множества в какихлибо последовательностях срабатываний.
Эти ограничения на элементы множеств A и B позволяют корректно выявлять такие виды конструкций, как AND -разделения/соединения и XOR -разделения/соединения. Также следует отметить, что корректное выявление XOR -разделений/соединений требует совмещения вершин.
5.Создается множество YL , используемое для определения позиций в распознаваемой WF-сети. На данном шаге α -алгоритм отбирает наибольшие вершины из множества XL для подмножества YL , т. е. определяется окончательный набор вершин для распознаваемой сети (исключая начальную iL и конечную oL вершины сети).
6.Создаются позиции сети.
7.К созданным на предыдущем шаге позициям подсоединяются их входные/выходные переходы.
8.Полученная сеть возвращается алгоритмом.
Пусть N = (P,T, F) — бездефектная WF-сеть, т. е. N W . Пусть α — α -Mi- ning-алгоритм, устанавливающий соответствие между логами событий N и бездефектными WF-сетями, т. е. α: L →W . Если для любого полного лога событий L сети N алгоритм возвращает сеть N (без учета названий позиций), то можно говорить, что α может распознать N .
Следует отметить, что ни один Mining-алгоритм не может найти имена позиций. Поэтому имена позиций игнорируются, т. е. говорят, что α может распознать N без учета названий позиций.
Класс распознаваемых моделей
Теорема. Пусть N = (P,T, F) — бездефектная WF-сеть, и L — полный лог событий сети N . Если для всех a, b T , a • ∩• b = или b • ∩ • a = , то α(L) = N без учета названий позиций.
Из теоремы следует, что α -алгоритм гарантированно всегда распознает класс структурированных WF-сетей без коротких циклов.
В случае циклов длиной в одну задачу это происходит вследствие того, что B > B подразумевает, что B → B невозможно (рис. 15.16).

Рис. 15.13. Результат распознания α -алгоритмом циклов длиной в одну задачу
А в случае с циклами длиной в две задачи A > B и B > A подразумевает, что A| B и B | A, вместо A → B и B → A (рис. 15.17).
Кроме коротких циклов, α -алгоритм также не может обрабатывать невидимые задачи, дублируемые задачи и принудительный выбор. С чем это связано см. подробнее в [135].
Также следует отметить, что α -алгоритм весьма уязвим к шуму, т. е. к вкраплениям неправильно записанной или просто неверной информации в логе.
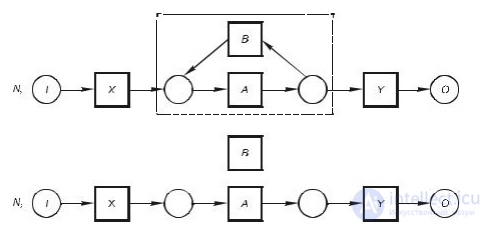
Рис. 15.14. Результат распознания α -алгоритмом циклов длиной в две задачи
Существуют модификации α -алгоритма, которые помогают избавиться от некоторых его недостатков, в частности существует алгоритм Heuristics Miner, в котором учитываются не только бинарные отношения, связывающие события между собой, но и частота их появления. На практике это выглядит следующим образом: если A > B встречается чаще, чем B > A, то вероятность того, что A → B выше, чем вероятность того, что B → A .
Вработах [137, 138] α -алгоритм расширен для извлечения коротких циклов.
Вних авторы, добавляя больше ограничений к понятию законченности протоколов, переопределяют бинарные отношения.
α-алгоритм был первоначально реализован в инструменте EMiT [140]. Впоследствии этот алгоритм стал программным расширением α -алгоритма в библиотеке ProM. Наконец, важно заметить, что α -алгоритм не принимает во внимание частоту отношения. Он только проверяет наличие отношения. Это также одна из причин, почему α -алгоритм не является устойчивым к шуму.
Подход Weijters и др. [141] может быть рассмотрен как расширение α -алго- ритма. Он работает, основываясь на отношении следования. Однако, чтобы вывести остающиеся отношения (причину, параллельность и несвязанность), он подсчитывает частоту отношения следования в протоколе. По этой причине данный подход может обрабатывать шум. Главная идея применяемой эвристики — если задача A чаще следует за задачей B , задача B менее часто следует за A , то вероятность, что A является причиной для B , выше. Поскольку алгоритм главным образом работает, основываясь на бинарных отношениях, нелокальные конструкции "не свободный выбор" не могут быть выявлены. Алгоритм был первоначально реализован в системе Little Thumb [142].
Ван Донджен (B. F. van Dongen) и др. [143, 144] ввели многошаговый подход к извлечению цепей процессов, ведомых событиями (Eventdriven Process Chains — EPCs). Первый шаг состоит в извлечении модели процесса для каждой трассы в экземпляре протокола. Чтобы сделать так, подход сначала удостоверяется, что ни одна задача не появляется более одного раза в трассе. Это означает, что каждому экземпляру задачи в трассе назначается уникальный идентификатор. После этого шага алгоритм выводит бинарные отношения, как α -алгоритм. Эти бинарные отношения выводятся на уровне протокола. Основанный на этих отношениях подход строит модель для каждого трека протокола. Эти модели показывают определенный порядок между экземплярами задач в треке. Обратите внимание, что на уровне трека никакой выбор не возможен, потому что все задачи (экземпляры) в треке были действительно выполнены. Второй шаг выполняет агрегирование (или слияние) извлеченных моделей, в течение первого шага, для каждого трека. В основном, агрегируются идентификаторы, которые ссылаются на экземпляры одной и той же задачи. Алгоритм различает три типа точек разделения/соединения: AND , OR и XOR . Тип точки разделения/соединения устанавливается, основываясь на подсчете ребрами агрегированных задач. Если точка разделения появляется так же часто, как его прямые преемники, то тип точки разделения AND . Если появление его преемников составляет количество раз, которое эта точка была выполнена, то это XOR . Иначе тип OR .
Вен (Wen) и др. [145, 146] написали два расширения для α -алгоритма (см. разд. 2.2.7). Первое расширение — α -алгоритм [145] — может извлекать структурированные сети потоков работ (SWF-сети) с короткими петлями. Расширение базируется на условии, что задачи в протоколе являются неатомными. Подход использует пересекающиеся времена выполнения задач, чтобы различить параллелизм и короткие петли. α -алгоритм был реализован как алгоритм Tsinghuaalpha, в библиотеке ProM.
Второе расширение — α ++-algorithm [146] — извлекает сети Петри с местными или нелокальными конструкциями non-freechoice. Это расширение развивается в работах [137, 138]. Главная идея подхода состоит в рассмотрении окна с размером, больше чем 1, чтобы установить зависимости между задачами в протоколе.
Подходы сравнивались на основании их способности обрабатывать простейшие конструкции в моделях процесса, а также присутствии шума в протоколе. Наиболее проблемные конструкции, которые не могут быть извлечены всеми подходами: петли (особенно произвольные), невидимые задачи, "не освобождают выбор" (особенно нелокальные) и двойные задачи.
Петли и невидимые задачи не могут быть добыты, главным образом потому, что они не поддерживаются представлением, которое используется подходами.
"Не свободный выбор" не обнаруживается в протоколах событий, потому что большинство подходов, основываются на анализе локальной информации. Нелокальный "не свободный выбор" требует, чтобы методы рассматривали более отдаленные отношения между задачами.
Двойные задачи не могут быть извлечены, потому что много подходов принимают отношение "один к одному" между задачами в протоколах и их ярлыках.
Наконец, шумом нельзя должным образом заняться, потому что много методов не учитывают частоту зависимостей задачи.
Проблема дублируемых задач
Большинство алгоритмов Process Mining для выявления перспективы управления потоком страдают серьезным недостатком. Данный недостаток заключается в том, что в теории, которая лежит в основе эвристических алгоритмов, практически всегда делается допущение, что одному уникальному событию должна соответствовать ровно одна вершина на модели (т. е. все вершины графов имеют уникальные метки). В результате, по мере прохода по логу, если алгоритмы встречают события, имеющие одинаковые имена, но разные события-предшественники и события-потомки, то в результирующей модели данные события объединяются в одну вершину, к которой подсоединяются все предшественники и все потомки (рис. 15.15).

Рис. 15.15. Результат попытки выявления дублируемых задач эвристическими алгоритмами
На данный момент существует всего несколько алгоритмов, позволяющих выявлять дублируемые задачи, в частности генетический алгоритм [147].
Описание алгоритма
Генетический алгоритм предъявляет следующие требования к выявляемой модели:
модель должна иметь ровно одну начальную задачу;
модель должна иметь ровно одну конечную задачу;
начальная вершина должна иметь семантику XOR -соединение/разделе- ние, в терминах сетей Петри это означает, что начальная задача должна иметь ровно одну входную и одну выходную позиции;
конечная вершина должна иметь семантику XOR -соединение/разделение, в терминах сетей Петри это означает, что начальная задача должна иметь ровно одну входную и одну выходную позиции.
Как нетрудно заметить, данные требования можно легко удовлетворить для любой модели, добавив в начало и в конец искусственные начальную и конечную задачи.
Алгоритм работает следующим образом (рис. 15.16): вначале с помощью ка- кого-нибудь эвристического алгоритма строится начальная популяция особей. Каждой особи сопоставляется мера соответствия желаемому результату, которая характеризует ее качество. В данном случае особь — это возможная модель процесса, а степень соответствия — функция, которая оценивает, насколько хорошо особь воспроизводит поведение в логе. Популяции эволюционируют путем выбора наилучших особей и создания новых особей, используя генетические операторы, такие как оператор пересечения (crossover — совмещение частей двух и более особей) и оператор мутации (случайная модификация особи).
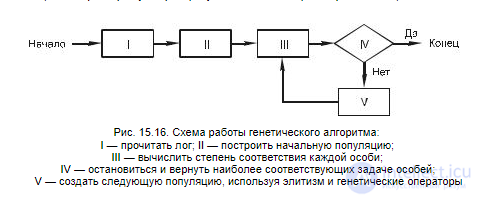
Рис. 15.16. Схема работы генетического алгоритма:
I — прочитать лог; II — построить начальную популяцию;
III — вычислить степень соответствия каждой особи;
IV — остановиться и вернуть наиболее соответствующих задаче особей;
V — создать следующую популяцию, используя элитизм и генетические операторы


Каждая особь в популяции представлена матрицей причинности (в ProM используется термин эвристическая сеть). Табл. 15.5 иллюстрирует матрицу причинности для модели процесса, изображенного на рис. 15.17.

Рис. 15.17. Модель в виде сети Петри
Задачи из одного подмножества входного/выходного множеств находятся в XOR -отношении между собой, а задачи из разных входных/выходных подмножеств находятся в AND -отношении между собой.
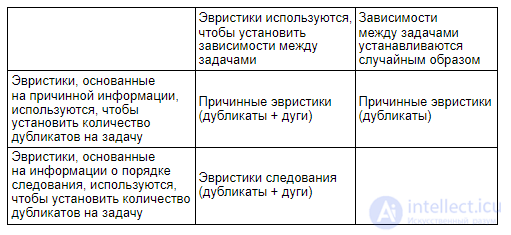
В алгоритме существуют несколько вариантов получения начальной популяции (табл. 15.6) и использования генетических операторов.
Т а б л и ц а 1 5 . 6 . Возможные варианты получения начальной популяции
Мера соответствия является комбинацией различных метрик. В целом, для того чтобы получить модель, адекватно отображающую дублируемые задачи, используются следующие принципы:
модель штрафуется за большое количество одновременно возбужденных переходов (как уже было отмечено ранее, неправильное распознавание дублируемых задач приводит к примыканию к одному переходу большого количества входных и выходных позиций);
модель штрафуется за количество дублируемых задач с общими входными и выходными задачами (тоже чтобы не получалось больших узлов).
Сравнение эффективности алгоритмов Process Mining
Так как за редким исключением алгоритмы Process Mining являются эвристическими, оценим их эффективность, исходя из теоретических соображений о том, какие типовые конструкции они могут выявлять, и основных принципов их работы. Сравнение описанных ранее алгоритмов приведено в табл. 15.7.
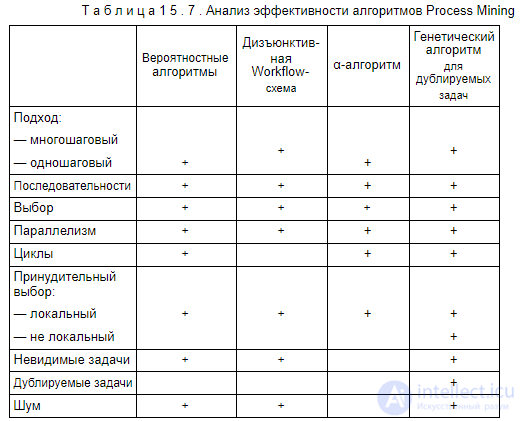
Как видно из таблицы, только генетический алгоритм может распознавать все типовые конструкции и, в особенности, дублируемые задачи.
Как уже было отмечено, из всех алгоритмов Process Mining только генетический алгоритм для выявления дублируемых задач может распознавать все типовые конструкции. Остальные алгоритмы Process Mining на это не способны, что резко ограничивает область их применения, фактически они подходят только для очень узкого класса реальных задач.
К сожалению, генетический алгоритм тоже нельзя считать эффективным, т. к. у него есть другой недостаток, нехарактерный для остальных алгоритмов Process Mining, предназначенных для выявления перспективы управления потоком: его выполнение занимает очень большое время, что фактически сводит на нет все его преимущества.
Проблема больших временных затрат возникает вследствие того, что одной из основных метрик, используемой для вычисления меры соответствия и вычисляемой генетическим алгоритмом на каждом шаге, является процент правильно завершенных следов в логе. Это означает, что алгоритм как бы "проверяет" на каждом шаге свои результаты, "прокручивая" все имеющиеся в логе следы, через каждую особь (модель) в популяции. Хотя такой подход позволяет адекватно оценить меру соответствия модели логу, это также вызывает как минимум прямую зависимость между размером лога и временем выполнения алгоритма, что делает нецелесообразным его использование для серьезных задач из реальной жизни.
Данный раздел посвящен описанию использованных в работе сторонних программных средств. Подобными программными средствами являются ProM Framework (который был использован для построения моделей и анализа логов), а также ProM Import Framework (который послужил базой для реализации конвертера логов игрового сервера).
ProM Framework — это набор программных средств, направленных на решение основных задач Process Mining, т. е. получение и анализ информации о бизнес-процессах из лог-файлов. Данный набор средств является кроссплатформенным приложением, написанным на языке Java. Он состоит из базовой части, предоставляющей пользователю единую среду и графический интерфейс, и набора различных алгоритмов, реализованных в виде подклю-
чаемых модулей (plug-in). На данный момент ProM Framework содержит более чем 190 встроенных подключаемых модулей и поддерживает добавление дополнительных пользовательских модулей.
ProM Framework разработан в Техническом университете Эйндховен и является свободно распространяемым приложением с открытым кодом.
Основная концепция организации ProM Framework заключается в том, что каждый подключаемый модуль реализует только свою специфическую задачу, а среда отвечает за их взаимодействие между собой.
Для реализации этой концепции в ProM Framework используется единый MXML-формат внутренней организации лог-файлов, а также автоматическое подключение/отключение подключаемых модулей, которое опирается на информацию о входных/выходных данных каждого подключаемого модуля и то, какие объекты для обработки открыты в графическом интерфейсе в данный момент времени.
ProM поддерживает следующие типы подключаемых модулей:
подключаемые модули для импортирования (import plug-ins) — позволяют использовать во время работы ранее созданные в других средствах модели, а также подключать их к уже открытым в среде логам;
подключаемые модули для выявления (mining plug-ins) — реализуют алгоритмы извлечения информации из лог-файлов и представления ее в виде различных моделей;
подключаемые модули для экспортирования (export plug-ins) — позволяют сохранять полученные на фазах извлечения и анализа информации модели, а также производить операции над логами;
подключаемые модули для анализа (analysis plug-ins) — позволяют анализировать открытые в среде лог-файлы и модели;
подключаемые модули для преобразования (conversion plug-ins) — позволяют преобразовывать созданные модели из одного формата в другой.
Кроме того, ProM Framework содержит набор лог-фильтров, предназначенных для очистки логов от ненужной или не актуальной для конкретной задачи информации.
Также в связке с ProM Framework распространяется отдельное приложение ProM Import Framework, предназначенное для преобразования лог-файлов различных форматов к используемому в ProM Framework единому формату MXML.
ProM Framework предоставляет пользователю полноценный многооконный графический интерфейс, позволяющий одновременно:
открывать, просматривать и редактировать лог-файлы;
импортировать, просматривать, сохранять модели;
управлять выполнением алгоритмов;
и т. д.
Наличие возможности добавления дополнительных подключаемых модулей, полноценный графический интерфейс и удобный MXML-формат делают ProM Framework удобной платформой для реализации и тестирования алгоритмов Process Mining. Также следует отметить наличие подробной справочной документации о создании пользовательских подключаемых модулей к ProM, что существенно упрощает их разработку.
Существенным минусом ProM является весьма ограниченная документация по использованию встроенных подключаемых модулей, что несколько затрудняет их применение. Также стоит отметить отсутствие полноценного интерфейса командной строки, что делает применение ProM в автоматизированном режиме мало возможным, однако данный недостаток не актуален для этой работы.
На сегодняшний день ProM уже содержит более 200 подключаемых модулей, реализующих множество алгоритмов, предназначенных для решения задач Process Mining. Имеющейся функциональности более чем достаточно для всестороннего анализа бизнес-процессов, что делает данное приложение
продолжение следует...
Часть 1 5 Средства анализа процессов - Process Mining
Часть 2 Метод построения дизъюнктивной Workflow-схемы - 5 Средства анализа процессов -
Часть 3 Методы на основе генетических алгоритмов - 5 Средства анализа процессов
Часть 4 ProM Import Framework - 5 Средства анализа процессов - Process
Комментарии
Оставить комментарий
Интеллектуальный анализ данных
Термины: Интеллектуальный анализ данных