Лекция
Это продолжение увлекательной статьи про средства анализа процессов .
...
метрики, которые используются, чтобы различать элементы XOR/AND-split/join: энтропия, количество типов событий, причинная связь и периодичность.
Энтропия определяет, как соотносятся два типа событий. Это необходимо, чтобы установить прямого наследника и предшественника типа события.
Количество типов событий позволяет различить элементы AND/XOR-split/join. Обратите внимание, что AND-split — это элемент разделения, и его прямые последователи выполняются одновременно. В ситуации XOR-split время выполнения следующего элемента наступает после времени (или совпадает со временем) выполнения элемента XOR-split (при условии отсутствия шума в протоколе).
Причинная связь используется, чтобы отличить параллельные события и продолжительность циклов, состоящих из двух событий. Периодичность помогает идентифицировать точки синхронизации.
Благодаря вероятностной природе, подобные алгоритмы устойчивы к шумам.
Первым, кто применил технологию Process Mining к бизнес-системам, использующим в качестве Workflow-системы IBM MQ Series, был Агравал (Agrawal ) [129]. Об этом говорит сайт https://intellect.icu . Предложенный им алгоритм предполагает, что протокол можно разбить на атомарные шаги. Извлеченная модель показывает зависимости между этими шагами, но не описывает семантики элементов разделитель/соединитель.
Данный подход требует цельную модель, имеющую начальную и конечную задачи. Это не является существенным ограничением, т. к. всегда можно предварительно добавить искусственную начальную и конечную задачи в начало и конец каждого экземпляра процесса. Данный алгоритм не обрабатывает дублируемые задачи и предполагает, что задача может появиться только один раз в экземпляре процесса. Поэтому для обработки циклов необходимо заново маркировать шаг процесса, преобразовав циклы в последовательности.
Как уже отмечалось, данный алгоритм нацелен на извлечение полной модели. Для этого он выполняет следующие шаги.
Шаг 1. Переименование повторяющихся меток в экземпляре процесса. Это позволяет корректно определить циклы.
Шаг 2. Построение графа зависимостей со всеми задачами, находящимися в протоколе. Здесь необходимо более детально рассмотреть, как устанавливается отношение зависимости. Алгоритм не только рассматривает появление задачи A рядом с B в одном и том же экземпляре процесса. Он рассматривает две задачи, которые могут также зависеть транзитивно во всем протоколе.
Так, если задача A следует за задачей C, а C за B, то B может зависеть от А, даже когда они никогда не появляются в том же самом экземпляре процесса.
Шаг 3. После построения графа отношения зависимости: удаление стрелки в обоих направлениях между двумя задачами; удаление строго связанных компонентов; применение транзитивного сокращения к подграфу (в главном графе), который представляет экземпляр процесса.
Шаг 4. Объединение перемаркированных задач в единый элемент.
Извлеченная модель имеет зависимости и булевы функции, ассоциированные с зависимостями. Эти булевы функции определяются, основываясь на других параметрах в протоколах. Для построения этих функций может использоваться классификационный алгоритм. В алгоритме шум обрабатывается сокращением дуг, которые появляются меньшее число раз, чем заданный порог.
Пинтер (Pinter) и Голани (Golani) в своих работах [130] развили подход Агравала. Главное отличие заключалось в том, что они рассматривают задачи, которые имеют начальное и конечное события. В этом случае обнаружение параллелизма становится более тривиальным.
Другое отличие заключается в том, что они рассматривают отдельные экземпляры процесса, чтобы установить отношения зависимости, в то время как Агравал и др. исследовали протокол как целое.
Хербст (Herbst) и Карагианнис (Karagiannis) предложили подход, который позволял обрабатывать дублирующиеся задачи [131, 132]. Они предложили три алгоритма: Merge-Seq, SplitSeq и SplitPar. Все три алгоритма могут извлекать модели с дублирующими задачами. Они извлекают модели процессов в два этапа.
На первом этапе строится стохастический граф деятельности (Stochastic Activity Graph, SAG), который описывает зависимости между задачами в протоколе потока работ. Этот граф имеет вероятности перехода, связанные с каждой зависимостью, но не имеет никакой информации об элементах AND/XOR-split/join. Вероятность перехода указывает возможность, что одна задача следует за другой. Поиск основан на метрике правдоподобия протокола — likelihood (LLH). Метрика LLH оценивает, насколько хорошо (правдободобно) модель отражает поведение, запечатленное в протоколе событий.
На втором этапе выполняется преобразование SAG в язык описания, используемый в системе бизнес-моделирования ADONIS (Adonis Definition Language, ADL). ADL — язык с блочной структурой для описания модели Workflow. Преобразование SAG в ADL необходимо для создания хорошо формализованной Workflow-модели.
MergeSeq и SplitSeq [132] хорошо работают для извлечения последовательных моделей процесса. SplitPar [131] может также извлекать параллельные модели процесса.
Алгоритм MergeSeq строит SAG снизу вверх. Он начинает с графа, который имеет ветвь для каждого уникального случая процесса в протоколе и последовательно применяется к узлам в графе.
Алгоритм SplitSeq строит граф сверху вниз. Он начинает с графа, который моделирует поведение в протоколе, но не содержит никаких дублированных задач. Алгоритм применяет набор операций разделения к узлам в SAG.
Алгоритм SplitPar можно рассматривать как расширение SplitSeq. Он также является нисходящим. Однако из-за того, что он предназначается для извлечения параллельных процессов, операции деления выполняются на уровне экземпляра процесса вместо SAG.
Основные понятия
В случаях, когда процессы имеют слишком сложную структуру, чтобы быть представленными одним графом, целесообразно использовать подход, основанный на кластеризации, т. е. разбиении модели на части. Существует несколько разных подходов к такому разбиению, одним из них является дизъюнктивная Workflow-схема, предложенная Греко и др. [133, 134]. Кластеризация в ней производится путем поиска таких переходов в модели, допущение об обязательном срабатывании (не срабатывании) которых позволит сделать вывод о недостижимости значительной части модели, что позволит убрать ее из рассмотрения (т. е. поделить модель на части).
Метод построен на формальной модели, описывающей процессы и протоколы. В данной модели набор различных задач, из которых состоит процесс P , и набор различных возможных последовательностей, в которых они должны выполняться, чаще всего моделируется посредством подходящего размеченного графа.
Граф управления потоком процесса P — это набор CF(P) = 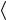 A, E, a0 , F
A, E, a0 , F , где
, где
A — ограниченный набор задач, E ( A − F) × ( A −{a0}) — отношение порядка среди задач, a0 A — начальная задача, F A — набор конечных задач.
Любой связанный подграф I = 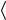 AI , EI
AI , EI  графа управления потоком, такой что a0 AI и AI F ≠ , соответствует одному из возможных экземпляров (instance) процесса P .
графа управления потоком, такой что a0 AI и AI F ≠ , соответствует одному из возможных экземпляров (instance) процесса P .
Для того чтобы промоделировать ограничения на возможные экземпляры процесса, описание процесса часто обогащается локальными или глобальны-
ми ограничениями, например, такими как: задача должна (не должна) прямо (непрямо) следовать за выполнением набора других задач.
Определим понятие локальные ограничения с помощью трех функций

Семантика ограничений выглядит следующим образом: выполнение задачи a может начаться не ранее, чем, как минимум, IN (a) предшествующих задач были выполнены.
Типовые конструкции:
если IN (a) = InDegree(a) , то a называется AND -соединением, так так она может быть выполнена только после того, как все ее предшественники были выполнены;
если IN (a) =1 , то a называется OR -соединением, так так она может быть выполнена, как только любая из предшествующих ей задач завершит свое выполнение.
Сразу же после завершения задача a должна активировать подмножество исходящих дуг, мощность (cardinality) которого находится в пределах
OUTmin (a) и OUTmax (a) .
Если OUTmax (a) = OutDegree(a) , то a является полным ветвлением, а если к тому же OUTmin (a) = OUTmax (a) , то a является детерминированным ветвлением ( AND -разделение), так как она активирует все последующие задачи. Наконец, если OUTmax (a) =1 , то a является исключающим ветвлением ( XOR -разделением), так как она активирует только одну из исходящих дуг.
Глобальные ограничения существенно разнообразнее локальных, и их представление сильно зависит от конкретной области применения, к которой относится моделируемый процесс. Таким образом, они часто представляются с использованием сложных формализмов, основанных на подходящей логике и связанной с ней семантике.
Простым, но достаточно выразительным способом описания глобальных ограничений является представление глобального ограничения в виде пары
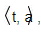 , где t и a — непересекающиеся наборы задач. Запись означает, что
, где t и a — непересекающиеся наборы задач. Запись означает, что
задачи из набора a не могут быть (или должны) быть выполнены, до того как будут выполнены все задачи из набора t .

Проблема построения модели.
Пусть AP — набор идентификаторов задач процесса P . Допустим, что фактическая Workflow-схема WS(P) для процесса P неизвестна, тогда проблема заключается в определении правильной схемы из множества Workflow-схем, для которых AP является набором узлов. Для того чтобы формализовать данную проблему, предварительно необходимо дать определения ряду других понятий и записей.
Workflow-следом s для набора AP называется строка из множества A*P , представляющая последовательность задач. Пусть s — след, тогда под обозначением s[i] будем понимать i -задачу в последовательности s , а под обозначением length(s) будем понимать длину s . Множество всех задач в s
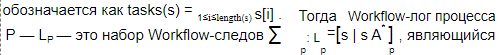
единственным источником информации для выявления схемы WS(P) .
Чтобы придать проблеме выявления WS(P) более конкретную форму, нужно определить, какой язык будет использоваться для описания глобальных ограничений в CG (P) , таким образом, проблема зависит от синтаксиса. Вследствие этого, чтобы разработать общий подход, удобнее будет использовать альтернативный, не зависящий от синтаксиса, способ описания глобальных ограничений. Для решения данной проблемы заменим целевую схему WS(P) набором альтернативных схем, которые не имеют глобальных ограничений, однако прямо моделируют различные варианты выполнения, предписываемые глобальными ограничениями. Основная идея заключается в том, чтобы сначала получить из Workflow-лога начальную Workflow-схему, глобальные ограничения которой не учитываются, а затем пошагово детализировать ее в набор специфических схем, каждая из которых моделирует класс следов, имеющих те же характеристики, что и глобальные ограничения.
Пример: допустим имеется глобальное ограничение, означающее, что задача c не может быть выполнена после завершения выполнения a и b , подходящее уточнение начальной схемы будет состоять из двух схем: в первой можно достичь одновременно a и b , но не c , а во второй c является достижимой, а a и b нет. При таком подходе набор ограничений представляется в виде различных вариантов выполнения, часто встречающихся в логе. В результате Workflow-схема рассматривается как объединение нескольких схем более простых вариантов протекания потоков без глобальных ограничений.

При условии, что известен LP , целью является выявление дизъюнктивной Workflow-схемы WS , наиболее "близкой" к некоторой "идеальной "схеме WS(P) , которая является полным отражением реального потока. Данное утверждение можно формализовать путем введения критериев полноты и правильности, которые будут служить ограничением для Workflow-схем, позволяющим принимать во внимание исключительно следы из лога. Очевидно, что предварительно нужно определить механизмы для принятия решения, может ли рассматриваемый след из множества LP быть выведен из реального протекания потока WS .
Пусть s — Workflow-след из множества LP , WS — дизъюнктивная Workflow-схема и подграф I =  Ai , Ei
Ai , Ei  — экземплярWS . Тогда будем говорить, что s совместим с WS через I , что обозначается как I |=I WS , если t
— экземплярWS . Тогда будем говорить, что s совместим с WS через I , что обозначается как I |=I WS , если t
является топологической сортировкой I , т. е. t — упорядочивание задач в Ai , такое что для каждой (a, b) EI , i < j , где s[i] = a , а s[ j] = b . Кроме того, будем говорить, что s совместим с WS , что обозначается как s|=WS , если существует I , такой что I |=I WS .
Пусть WS — дизъюнктивная Workflow-схема, а LP — лог процесса P , тогда:
правильность:

т. е. процент экземпляров процесса P , не имеющих соответствующих им следов в логе;
полнота:

т. е. процент следов, имеющих какой-либо совместимый с ними след в логе.
Пусть имеются два вещественных числа α и σ , причем 0 < α <1 и 0 < σ <1 (обычно α близко к 0, а σ — к 1), тогда будем говорить, что:

С учетом введенных понятий переформулируем задачу. Теперь она заключается в том, чтобы выявить дизъюнктивную схему WS для некоторого процесса P , которая будет α -правильной и σ -полной для заданных α и σ . Однако очевидно, что всегда существует тривиальная схема, удовлетворяющая данным условиям, она состоит из объединения протеканий процесса, каждое из которых моделирует соответствующий ему след из LP . Однако подобная модель не будет представлять большой ценности, т. к. ее размер будет WS = L , где L = {s | s L} . Учитывая это, определим ограничение
на набор подсхем в WS .
Пусть LP — Workflow-лог процесса P , α и σ — вещественные числа, m — натуральное число. Задача точного выявления процесса, обозначаемая как EPD(P, σ, α, m) , состоит из поиска α -правильной и σ -полной дизъюнктив-
ной Workflow-схемы WS , такой что WS ≤ m .
Задача точного выявления процесса может быть решена за полиномиальное время только для тривиальных случаев m =1 или для больших m (кроме случая, когда P принадлежит классу NP ).
Теорема 1. Имеет ли EPD(P, σ, α, m) решение, можно определить за полиномиальное время, зависящее от размера LP , если m ≤1, или m ≥| L | , в противном случае задача NP -полная [134].
Переформулируем постановку задачи выявления процесса таким образом, чтобы она всегда имела решение.
Пусть LP — Workflow-лог процесса P , σ — вещественное число, m — натуральное число. Задача минимального выявления процесса, обозначаемая как MPD(P, σ, m) , состоит из поиска σ -полной дизъюнктивной Workflow-
схемы WS , такой что WS ≤ m , и значение soundness(WS ) минимально.
Задача теперь решаема, т. к. можно пожертвовать правильностью в пользу получения результата. Тем не менее она все еще трудноразрешима. Будем считать что числа, характеризующие правильность, соответствующим образом дискретизированы и являются положительными целыми числами, чтобы можно было представить MPD как оптимизационную задачу класса NP .
Теорема 2. EPD(P, σ, m) — оптимизационная задача класса NP , множество возможных решений которой не пустое [134].
Теперь можно перейти к проблеме PD(P, σ, α, m) , которая заключается в поиске подходящей аппроксимации, т. е. σ -полной Workflow-схемы WS , где
WS ≤ m , являющейся настолько правильной, насколько это возможно.
Чтобы выявить Workflow-схему процесса P (проблема PD(P, σ, α, m) ), ис-
пользуется идея многократной пошаговой оптимизации схемы путем выявления глобальных ограничений, которые затем используются для того, чтобы провести различными вариантами выполнения, начиная с основной дизъюнк-
тивной схемы WS , которая отвечает только за зависимости между задачами в P .
Описание алгоритма
Алгоритм Process Discovery (листинг 15.1) получает WS , используя метод иерархической кластеризации, начинающийся с выявления графа управления потоком CFσ , с помощью процедуры minePrecedences. Каждая Workflow-
схема WSij , которая в конечном счете добавляется в WS , имеет номер i — количество необходимых шагов оптимизации, а номер j используется для различения схем на одном уровне оптимизации. L(WSij ) — набор следов в кластере, определяемом WSij . Следует также отметить, что начальная схема
WS01 , содержащая все следы из набора LP , вставляется в WS , а на шаге 3 модель оптимизируется выявлением локальных ограничений.
Листинг 15.1. Алгоритм Process Discovery
Вход: Проблема PD(P, σ, m), натуральное число maxFeatures
Выход: Модель процесса
Алгоритм: выполнить последовательность шагов:

Функция refineWorkflow выглядит следующим образом:

Алгоритм является "жадной" эвристикой, на каждом шаге он выбирает схему
WSij WS для оптимизации функцией refineWorkflow исходя из того, какую из них наиболее выгодно оптимизировать.
Чтобы применить методы кластеризации (k-means алгоритм), процедура refineWorkflow транслирует лог L(WSij ) в реляционную информацию с помощью процедур identifyRelevantFeatures и project. Если устанавливается наличие более чем одной релевантной особенности, то вычисляются класте-
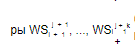
(где j — максимальный индекс схем, уже добавленных в WS на уровне i +1 ) с помощью применения k-means алгоритма к следам
L(WSij ) , далее кластеры добавляются в дизъюнктивную Workflow-схему WS . В конце для каждой схемы, добавленной в WS , чтобы определить локальные ограничения, вызывается процедура mineLocalConstraints.
Алгоритм сходится не более чем за m шагов и использует следующее свойство процедуры refineWorkflow: на каждом шаге оптимизации значение правильности уменьшается, т. е. алгоритм подходит ближе к оптимальному решению.

Основная идея алгоритма заключается в том, что число новых схем k , добавляемых на каждом шаге оптимизации, фиксируется. k может находиться в интервале от минимум 2, что потребует нескольких шагов вычислений, до неограниченной величины, при которой результат будет возвращен всего через 1 шаг. Второй случай не всегда эффективнее, так так алгоритм кластеризации может работать медленнее с большим набором классов, теряя преимущество меньшего количества итераций. Весомым доводом в пользу небольшого значения k : представление различных схем может быть оптимизировано путем сохранения древовидной структуры и хранения для каждого узла только его отличий от схемы родительского узла. Древовидное представление релевантно не только из-за уменьшения объема необходимой памяти, но и еще потому, что оно дает больше представления о свойствах моделируемых Workflow-следов и дает удобное описание глобальных ограничений.

Используя данную запись, можно описывать сложные взаимосвязи между задачами.

Параллельные задачи и строгие предшествования являются базовыми блоками, из которых строится процесс управления потоком. σ -управление потоком ( σ -control flow) процесса P — это граф CFσ (P) =  ∑ p, E
∑ p, E , содержащий дугу (a, b) в E для каждой пары узлов a и b , таких что или a σb , или
, содержащий дугу (a, b) в E для каждой пары узлов a и b , таких что или a σb , или
{a} →σ {b} , и не существует набора задач {h1,..., hm} , где a σh1 , hi σhi +1 для 1 ≤ i < m и hm σb .
Наконец, набор σ -локальных ограничений, обозначаемый как CLσ , может быть получен, используя процесс управления потоком:
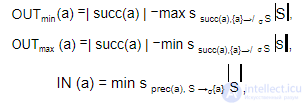
где succ(a) ={b | (a, b) Eσ} и prec(a) ={b | (b, a) Eσ} , а A →/ σ B означает, что A →σ B не выполняется.
Ключевым моментом алгоритма кластеризации Workflow-следов является
формализация процедур identifyRelevantFeatures и project.

Выявление дискриминантных правил выполняется при помощи алгоритма (листинг 15.2). На каждом k -м шаге в Lk сохраняются все последовательности σ -частоты, размер которых k . Конкретнее, на шагах 5—9 набор потенциальных последовательностей M , который сохраняется в Lk +1 , получается путем объединения тех Lk , которые имеют отношения предшествования в L2 . Также шаг 7 предотвращает вычисление не минимальных неожиданных правил. Таким образом, только последовательности σ -частоты в M включаются в Lk +1 (шаг 11), тогда как остальные определяют неожиданные правила (шаг 12). Процесс повторяется пока не найдены какие-либо другие часто встречающиеся следы. Правильность алгоритма определяется следующей теоремой.
Теорема 4. В алгоритме из листинга 15.2 до его завершения (шаг 16) множество R должно содержать точно все последовательности задачи σ -частоты, множество F должно содержать точно все минимальные дискриминантные правила.
Листинг 15.2. Алгоритм IdentifyRelevantFeatures
Вход: Набор логов L , порог σ , натуральное число maxFeatures, граф CFσ
Выход: Набор минимальных "неожиданных" правил


Следует отметить, что алгоритм IdentifyRelevantFeatures не прямо выдает F , а вызывает процедуру mostDiscriminantFeatures, целью которой является поиск подходящего подмножества, которое лучше дискриминирует следы в логе.

Следует отметить, что самый дискриминантный k -набор особенностей может быть вычислен за полиномиальное время путем рассмотрения всех возможных комбинаций особенностей R , содержащих k элементов. Минимальное k , для которого наиболее дискриминантный k -набор особенностей S покрывает все логи, т. е. w(S, L) = L , называется размерностью L , тогда как S — наиболее дискриминантным набором особенностей.
Теорема 5. Пусть L — набор следов, n — размер L (сумма размеров всех следов в L ), и F — набор особенностей. Тогда задача вычисления наиболее дискриминантного набора особенностей является NP -сложной [134].
Учитывая присущую проблеме сложность, перейдем к вычислению подходящей аппроксимации. Точнее, процедура mostDiscriminantFeatures, являющаяся имплементацией алгоритма поиска релевантных особенностей, вычисляет набор F ' дискриминантных правил с помощью эвристики, "жадно" выбирая особенность φ , покрывающую максимальный набор следов, среди
которых S ' не покрыты предыдущими выборками.
Проецирование следов. Набор релевантных особенностей F может быть использован для представления каждого следа s точкой в векторном пространстве  обозначаемой s
обозначаемой s
Процедура project использует данный способ, переводя (maps) следы в пространство R F , в котором k-means алгоритм может работать.
α-алгоритм
Основная идея алгоритма
Ван дер Аалст и др. [135—140] разработали α -алгоритм. Его главное отличие от других — то, что авторы доказывают, к какому классу моделей их подход будет гарантированно работать.
Они предполагают, что протокол должен быть без шума и должен быть дополнен отношением потоков. Так, если в исходной модели задача A может
|
быть выполнена только до задачи B (то есть B следует за |
A ), по крайней |
мере один экземпляр процесса в протоколе указывает на это поведение. Их подход доказывается в работе для класса структурированных сетей Workflow (SWF-сети) без коротких петель и неявных мест (см. более подробно [135]). α -алгоритм работает, основываясь на бинарных отношениях в протоколе. Есть четыре отношения: следствие, причина, параллельность и несвязанность. Две задачи A и B имеют отношение следования, если они появляются друг за другом в протоколе. Это отношение — основное отношение, из которого происходят другие отношения. Две задачи A и B имеют причинное отношение, если A следует за B , но B не следует за A . Если B также следует за A , то задачи имеют параллельное отношение. Когда A и B не вовлечены в перечисленные отношения, говорят, что они являются несвязанными.
Обратите внимание, что все отношения зависимости выведены на основании локальной информации в протоколе. Поэтому α -алгоритм не может обрабатывать нелокальный "не свободный выбор". Кроме того, из-за того что α -ал- горитм работает, основываясь на наборах, он не может извлекать модели с дублируемыми задачами.
Сети Петри
Сеть Петри — это набор N = (P,T, F) , где P — конечное множество пози-
ций, T — конечное множество переходов, таких что P ∩T = , F (P ×T) (T × P) — набор ориентированных дуг.
Размеченная сеть Петри — это пара (N, s) , где N = (P,T, F) — сеть Петри, а s — функция, задающая разметку сети s P → N .
Разметка сети — это набор натуральных чисел (вектор), сопоставленных элементам множества P . Каждое число обозначает количество маркеров, сопоставленных данной позиции в текущей разметке.
Пусть N = (P,T, F) — сеть Петри. Элементы множества P T называются
узлами, или вершинами сети. Вершина x является входной вершиной, для другой вершины y тогда и только тогда, когда есть ориентированная дуга от
|
x к |
y (т. е. (x, y) F , или xFy ). Вершина x |
является исходящей вершиной |
|
|
для другой вершины y тогда и только тогда, когда yFx . |
|||
|
Для |
каждой |
вершины x P T существует |
множество входных вершин |
|
N |
|
|
N |
|
• x = {y | yFx} |
и множество исходящих вершин x • = {y | xFy} (индекс N |
||
может быть опущен, если из контекста ясно, о какой сети Петри идет речь).
Графически сеть Петри изображается в виде двудольного ориентированного графа, в котором позиции изображаются в виде кружочков, а переходы — в виде прямоугольников. Разметка сети Петри изображается в виде точек внутри кружочков, соответствующих позициям. Количество точек внутри кружка соответствует числу маркеров, сопоставленных данной позиции в текущей разметке.
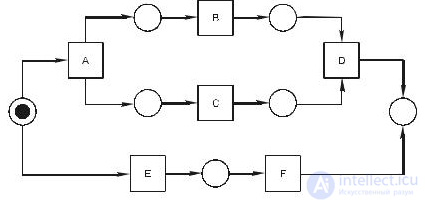
Рис. 15.11. Пример сети из позиций и переходов
На рис. 15.11 изображена сеть Петри, состоящая из 7 позиций и 6 переходов. Переход A имеет одну входную и две выходные позиции, такой переход называется AND -разделением, а переход D , имеющий две входные и одну выходную позиции, называется AND -соединением.
Динамическое поведение размеченной сети Петри определяется правилом срабатывания.
Пусть N = ((P,T, F), s) — размеченная сеть Петри. Переход t T считается возбужденным тогда и только тогда, когда •t ≤ s , что обозначается как
(N, s) t . Переход , являющийся возбужденным при текущей разметке ,
t s
может сработать, что приведет к изменению разметки: s ' = s − •t + t • . Про-
цесс срабатывания обозначается как (N, s) t ( N, s t t ) .
При маркировке, изображенной на рис. 15.11, два перехода A и E возбуждены, однако только один из них может сработать. Если сработает A , то из входной позиции маркер будет удален, а на выходные позиции маркеры будут добавлены. В получившейся разметке переходы B и C будут возбуждены, причем они могут сработать параллельно (т. к. у них нет общих входных позиций).
Пусть N = ((P,T, F), s) — размеченная сеть Петри. Разметка s называется
достижимой от начальной разметки s0 тогда и только тогда, когда сущест-
вует последовательность возбужденных переходов, срабатывание которых приведет к изменению разметки s0 к s . Множество достижимых от ( N, s0 )
разметок обозначается как N s .
, 0
Изображенная на рис. 15.11 размеченная сеть Петри имеет 6 достижимых разметок. Иногда удобно знать последовательность переходов, которые должны сработать для того, чтобы получилась некоторая искомая разметка. Далее используются следующие обозначения для таких последовательностей. Пусть A — некоторый алфавит идентификаторов, последовательность длиной n из натуральных чисел до числа n N над алфавитом A является функцией σ :{0,..., n −1} → A . Последовательность длиной 0 называется пустой последовательностью и обозначается как ε . Для повышения читабельности непустая последовательность может записываться только из значений функции. Например, последовательность σ ={(0, a),(1,b),(2,b)} при a, b A
записывается как aab . Множество всех последовательностей произвольной длины из символов алфавита A обозначается A* .
|
Пусть A — множество, ai A i N , |
* |
— последователь- |
|
σ = a0a1...an−1 A |
||
|
ность элементов A длиной n , тогда: |
|
|
1.a σ тогда и только тогда, когда a {a0a1...an−1} .
2.first(σ) = a0 , если n ≥1 .
3.last(σ) = an−1 , если n ≥1 .
Пусть ( N, s0 ) , где N = (P,T, F) — размеченная сеть Петри. Последовательность σ T* называется последовательностью срабатываний сети ( N, s0 )
тогда и только тогда, когда для некоторого натурального числа n N существуют разметки s1,..., sn и переходы t1,..., tn T , такие что σ = t1,..., tn , и для
каждого i [0, n) , (N, si ) ti+1 (N, si+1) , где si +1 = si − •ti +1 + ti +1 • (при n = 0
(N, si+1) , где si +1 = si − •ti +1 + ti +1 • (при n = 0
предполагается, что σ = ε , и что ε — последовательность срабатываний при ( N, s0 ) ). Последовательность σ называется возбужденной при разметке s0 ,
|
что обозначается как (N, s0 ) σ . Срабатывание последовательности σ при- |
||
|
|
|
|
|
ведет к разметке sn |
, что обозначается как ( N, s0 ) σ ( N , sn ) . |
|
|
|
|
|
|
Сеть N = (P,T, F) |
слабо связана тогда и только тогда, когда для любой | |
продолжение следует...
Часть 1 5 Средства анализа процессов - Process Mining
Часть 2 Метод построения дизъюнктивной Workflow-схемы - 5 Средства анализа процессов -
Часть 3 Методы на основе генетических алгоритмов - 5 Средства анализа процессов
Часть 4 ProM Import Framework - 5 Средства анализа процессов - Process

Комментарии
Оставить комментарий
Интеллектуальный анализ данных
Термины: Интеллектуальный анализ данных