Лекция
Автоматическое создание реалистичных высококачественных изображений из текстовых описаний было бы интересно и довольно полезно, так как имеет множество практических применений, но современные системы искусственного интеллекта все еще далеки от этой цели, так как это является довольно сложной задачей в области компьютерного зрения. Однако в последние годы были разработаны универсальные и мощные рекуррентные архитектуры нейронных сетей для изучения различных представлений текстовых признаков. Между тем, глубокие сверточные генеративные состязательные сети (англ. Generative Adversarial Nets, GANs) начали генерировать весьма убедительные изображения определенных категорий, таких как лица, обложки альбомов и интерьеры комнат. Образцы, генерируемые существующими подходами "текст-изображение", могут приблизительно отражать смысл данных описаний, но они не содержат необходимых деталей и ярких частей объекта. В данной статье рассмотрены формулировка и глубокая архитектура GAN, а также объединены достижения в генерации изображений по тексту.
Синтез изображений по тексту с использованием ИИ — это процесс, при котором нейронные сети преобразуют текстовое описание в визуальное изображение. Эта технология получила широкое развитие благодаря использованию глубокого обучения и больших наборов данных, состоящих из пар «текст-изображение». Основные шаги синтеза изображений из текста выглядят так:
1. Текстовое описание (ввод):
Пользователь вводит текст, например: "кот в шляпе сидит на лужайке возле дома". Этот текст описывает визуальные элементы, которые ИИ должен преобразовать в картинку.
2. Анализ текста (понимание контекста):
ИИ с помощью языковых моделей, таких как BERT, GPT, T5, разбирает текстовое описание. На этом этапе система определяет ключевые объекты (например, "кот", "шляпа", "лужайка"), их свойства (цвет, форма) и их взаимное расположение.
3. Генерация изображения (визуализация текста):
После анализа текста система использует одну из моделей для генерации изображений. Самые популярные подходы включают:
DALL·E и DALL·E 2: Разработанные OpenAI, эти модели используют трансформеры для генерации изображений по тексту. DALL·E 2, в частности, может создавать высококачественные и фотореалистичные изображения из описаний.
Stable Diffusion: Модель, которая работает по принципу диффузионных процессов, позволяя генерировать изображения высокого разрешения, начиная с шума и постепенно улучшая детали на основе текстового описания.
CLIP + VQGAN: Модель, в которой CLIP используется для сравнения текста и изображений, а VQGAN (генеративная состязательная сеть) создает само изображение. CLIP помогает улучшить соответствие между описанием и изображением.
4. Обучение на данных (запас знаний ИИ):
Модели обучаются на огромных наборах данных, состоящих из пар изображений и текстовых описаний. В ходе обучения ИИ "учится" сопоставлять объекты с их визуальными характеристиками и понимать, как они должны выглядеть на изображениях. Например, после анализа миллионов картинок и их текстовых подписей ИИ начинает "понимать", что такое "кот", что такое "шляпа" и как эти объекты могут выглядеть в разных контекстах.
5. Композиция изображения:
В процессе синтеза ИИ формирует композицию изображения на основе текстового описания. Он решает, где будут размещены объекты, как они будут взаимодействовать друг с другом и какие визуальные элементы будут ключевыми. Например, если текст описывает "зеленую лужайку перед домом", ИИ сначала определяет фон (лужайка) и добавляет на него другие объекты (дом, кот).
6. Постобработка и улучшение качества:
После начального этапа генерации изображение может подвергаться дополнительной обработке для повышения его четкости, реализма и визуального соответствия тексту. Некоторые модели используют GAN (Generative Adversarial Networks), где один блок создает изображение, а другой оценивает его качество, чтобы улучшить реализм результата.
Технологии:
CLIP (Contrastive Language-Image Pre-training): помогает улучшить соответствие между текстом и изображениями, сопоставляя текстовые и визуальные представления.
GAN (Generative Adversarial Networks): состязательные нейронные сети, одна из которых генерирует изображение, а другая оценивает его качество.
VQ-VAE и Diffusion Models: современные подходы для создания качественных изображений путем постепенного улучшения деталей на основе текстовых описаний.
Примеры использования:
Создание иллюстраций по описанию: можно сгенерировать изображения по текстовым запросам, что полезно в дизайне, маркетинге, разработке игр.
Визуализация идей: пользователи могут визуализировать свои идеи или концепты без необходимости вручную рисовать или моделировать их.
Артистические эксперименты: генеративные модели могут создавать уникальные, креативные изображения, которые сложно создать вручную.
Таким образом, синтез изображений по тексту с помощью ИИ позволяет автоматически и быстро создавать изображения на основе естественного языка, значительно расширяя возможности творчества и дизайна.
Генерация видео из текста с помощью генеративных ИИ использует сложные нейронные сети, обученные на огромных наборах данных с изображениями и видеороликами, чтобы создавать последовательности кадров на основе текстового описания. Вот основные этапы, как это работает:
1. Текстовое описание:
Пользователь вводит текстовое описание того, что он хочет видеть в видео. Например: "закат над горами с облаками, медленно движущимися на фоне".
2. Преобразование текста в визуальные концепции:
ИИ сначала анализирует текст и выделяет ключевые слова и объекты, которые можно визуализировать, используя языковые модели (например, GPT, BERT). Смысл текста разбивается на визуальные элементы (объекты, действия, сцены), которые затем переводятся в графические концепции.
3. Генерация начальных изображений (кадров):
Система использует модели вроде Stable Diffusion, DALL·E или VQ-VAE-2, которые на основе текстовых описаний создают изображения. Эти модели обучены на больших объемах изображений с подписями, что позволяет им "понимать", как визуализировать конкретные объекты, сцены или действия из текста.
4. Интерполяция кадров и анимация:
После генерации отдельных ключевых изображений ИИ создает плавные переходы между ними для формирования непрерывного видеоряда. Это делается с помощью методов интерполяции и анимации, при которых промежуточные кадры добавляются для создания ощущения движения.
5. Генерация движения:
Для более сложных действий ИИ может генерировать движение на основе информации о том, как различные объекты должны изменяться с течением времени (например, движение облаков, падение воды, перемещение людей).
Некоторые модели используют темпоральные нейронные сети или рекуррентные нейронные сети (например, LSTM или GRU), чтобы отслеживать изменения во времени и поддерживать плавность движений.
6. Постобработка и улучшение видео:
На последнем этапе добавляются дополнительные эффекты, например, корректировка освещения, цвета и четкости для улучшения качества видео. Это может делаться с помощью GAN (Generative Adversarial Networks), которые помогают улучшить реализм изображения.
Технологии:
В основе процесса лежат такие нейронные сети, как GAN, VQ-VAE (вариационные автокодировщики), Diffusion Models, а также рекуррентные нейронные сети для временной обработки.
На сегодняшний день (2025 год) такие технологии уже применяются для создания коротких анимаций или простых видео на основе текстовых запросов, хотя качество и сложность пока могут быть ограничены.
Сообщество глубокого обучения быстро совершенствует генеративные модели. Среди них можно выделить три перспективных типа: авторегрессионные модели (англ. Autoregressive model, AR-model), вариационные автокодировщики (англ. Variational Autoencoder, VAE) и генеративные состязательные сети. На данный момент самые качественные изображения генерируют сети GAN (фотореалистичные и разнообразные, с убедительными деталями в высоком разрешении). Поэтому в данной статье мы сосредоточимся на моделях GAN.
| Модель | Inception Score | FID | Разрешение генерируемой картинки | Реализация | Модификация (отличие от GAN) | Пример сгенерированной картинки | |
|---|---|---|---|---|---|---|---|
| COCO | Caltech-UCSD | ||||||
| Attribute2Image, 2015 | 14.30±0.10 | — | — | 64×64 | да | Генерация изображения как смесь переднего и заднего планов на основе многоуровневой генеративной модели. |

|
| GAN-INT-CLS, 2016 | 7.88±0.07 | 2.88±0.04 | 60.62 | 64×64 | да | Обучение на текстовых признаках, кодируемых гибридной сверточно-рекуррентной нейронной сетью. |

|
| StackGAN, 2017 | 8.45±0.03 | 3.70±0.04 | 74.05 | 256×256 | да | Генерация изображения происходит в два этапа, на первом этапе создается примитивная форма изображения и задаются цвета объектов, на втором исправляются дефекты предыдущего этапа и добавляются более мелкие детали. |

|
| FusedGAN, 2018 | — | 3.00±0.03 | — | 64×64 | нет | Генерация изображения в два этапа, на первом задаются признаки стиля, на втором генерируется изображение. |

|
| ChatPainter, 2018 | 9.74±0.02 | — | — | 256×256 | нет | В качестве дополнительных данных для обучения используется диалог описания изображения. |

|
| StackGAN++, 2018 | 8.30±0.10 | 3.84±0.06 | 81.59 | 256×256 | да | Генерация изображений разного масштаба из разных ветвей древовидной структуры, в которой несколько генераторов разделяют между собой большинство своих параметров. |

|
| HTIS, 2018 | 11.46±0.09 | — | — | 256×256 | нет | Генерация изображения разбивается на несколько шагов, сначала создается семантический макет из текста, затем этот макет преобразовывается в изображение. |

|
| AttnGAN, 2018 | 25.89±0.47 | 4.36±0.03 | 28.76 | 256×256 | да | Выделение слов для генерации областей картинки с помощью механизма внимания. |

|
| CVAE&GAN, 2018 | — | — | — | 256×256 | нет | Разделение переднего и заднего плана, сначала CVAE генерирует картинку в плохом качестве, после качество повышается с помощью GAN. |

|
| MMVR, 2018 | 8.30±0.78 | — | — | 256×256 | нет | Обучение на измененном описании картинки. |

|
| MirrorGAN, 2019 | 26.47±0.41 | 4.56±0.05 | — | 256×256 | да | Генерация изображения с использованием идеи обучения посредством переописания. |

|
| Obj-GAN, 2019 | 31.01±0.27 | — | 17.03 | 256×256 | да | Основной принцип генерации изображений заключается в распознавании и создании отдельных объектов из заданного текстового описания. |

|
| LayoutVAE, 2019 | — | — | — | 256×256 | нет | Генерация стохастических макетов сцен (англ. stochastic scene layouts) из заданного набора слов. |

|
| MCA-GAN, 2019 | — | — | — | 256×256 | нет | Генерация изображения с произвольных ракурсов, основывающаяся на семантическом отображении (англ. semantic mapping). |

|
Условная генерация изображений из визуальных атрибутов (англ. Conditional Image Generation from Visual Attributes, Attribute2Image ) моделирует изображение как смесь переднего и заднего планов и разрабатывает многоуровневую генеративную модель с выделенными скрытыми переменными (рис. 4), которые можно изучать от начала до конца с помощью вариационного автокодировщика (англ. Variational Autoencoder, VAE). Экспериментируя с естественными изображениями лиц и птиц на наборах данных Caltech-UCSD и LFW Attribute2Image демонстрирует, что способен генерировать реалистичные и разнообразные изображения размером 64x64 пикселя с распутанными скрытыми представлениями (англ. disentangled latent representations) — это состояние, в котором каждый фактор приобретается как каждый элемент скрытых переменных, то есть если в модели с обученными скрытыми представлениями смещение одной скрытой переменной при сохранении других фиксированными генерирует данные, показывающие, что изменяется только соответствующий фактор. (рис. 3). Таким образом, изученные генеративные модели показывают отличные количественные и визуальные результаты в задачах реконструкции и завершения изображения, обусловленного атрибутами.
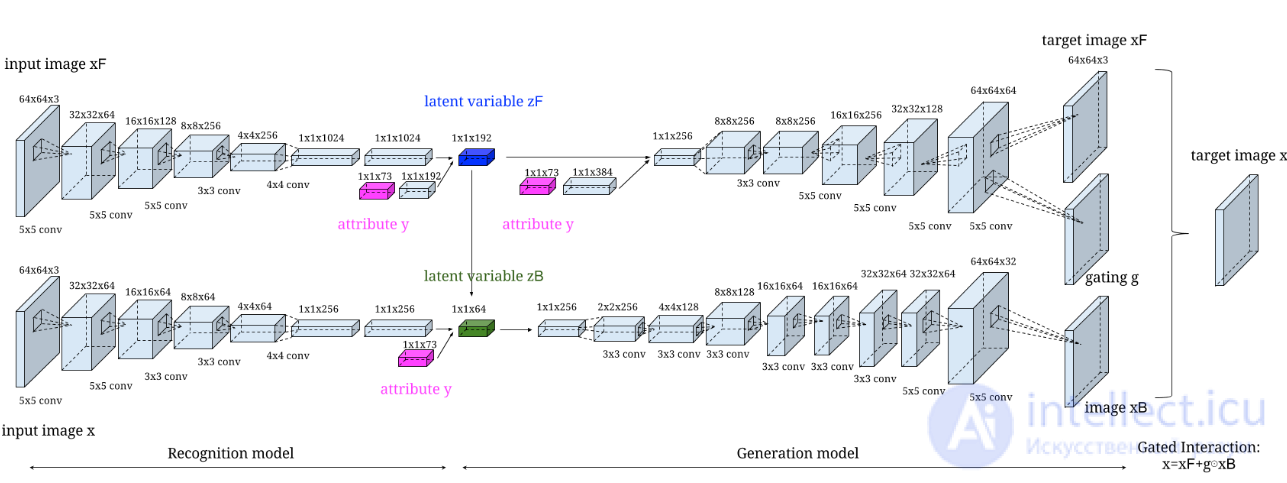
Рисунок 4. Архитектура Attribute2Image.
Глубокая сверточная генеративная состязательная сеть (англ. Deep Convolutional Generative Adversarial Network, DCGAN) — обусловлена текстовыми признаками, кодируемыми гибридной сверточно-рекуррентной нейронной сетью на уровне символов. DCGAN имеет эффективную архитектуру (рис. 1) и обучающую структуру, которая позволяет синтезировать изображения птиц и цветов из текстовых описаний.
Для обучения такой модели для птиц был использован набор данных Caltech-UCSD, а для цветов — Oxford-102. Наряду с этим было собрано по пять текстовых описаний на изображение, которые были использованы в качестве параметров оценки.
DCGAN во многих случаях может генерировать на основе текста визуально-правдоподобные изображения размером 64×64 пикселя, а также отличается тем, что сама модель является генеративной состязательней сетью, а не только использует ее для постобработки. Текстовые запросы кодируются с помощью текстового кодировщика φ, который позволяет получить векторное представление слов. Затем применяется концепция условной генеративной состязательной сети (англ. Conditional Generative Adversarial Network, CGAN). Таким образом, описание, внедренное в φ(t) сначала сжимается с помощью полностью связанного слоя до небольшого размера (на практике было использовано 128), затем применяется функция активации Leaky ReLU и результат конкатенируется с вектором шума z.
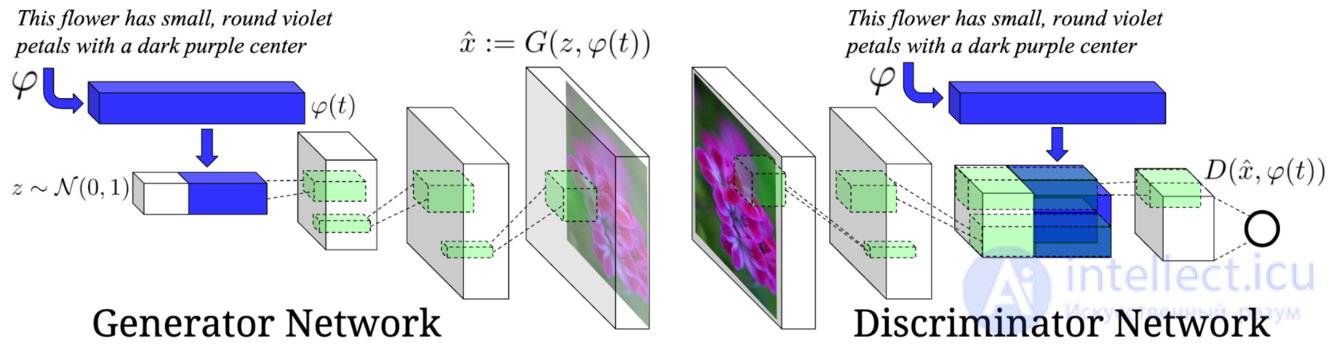
Рисунок 1. Архитектура DCGAN.
Как только модель научилась генерировать правдоподобные изображения (рис. 2), она должна также научиться согласовывать их с текстовым описанием, и было бы неплохо, если бы она научилась оценивать, соответствуют ли изображения заданному описанию или нет. Модель должна неявно разделять два источника ошибок: нереалистичные образы (для любого текста) и реалистичные образы неправильного класса, которые не соответствуют текстовым признакам. Алгоритм обучения GAN был модифицирован таким образом, чтобы разделять эти источники ошибок. В дополнение к реальным/поддельным входным данным в дискриминатор во время обучения был добавлен третий тип входных данных, состоящий из реальных изображений с несовпадающим текстовым описанием, на которых дискриминатор должен обучиться оценивать поддельные изображения.


Составные генеративные состязательные сети (англ. Stacked Generative Adversarial Networks, StackGAN ) служат для генерации фотореалистичных изображений размера 256x256, заданных текстовыми описаниями. В данной модели трудная задача генерации изображения разлагается на более мелкие подзадачи с помощью процесса эскиз-уточнения (англ. sketch-refinement process). Таким образом, Stage-I GAN рисует примитивную форму и цвета объекта на основе данного текстового описания, получая изображения Stage-I с низким разрешением (рис. 5). Stage-II GAN принимает результаты Stage-I и текстовые описания в качестве входных данных и генерирует изображения высокого разрешения с фотореалистичными деталями. Он способен исправлять дефекты в результатах этапа I и добавлять более мелкие детали в процессе уточнения (англ. refinement process). Чтобы улучшить разнообразие синтезированных изображений и стабилизировать обучение CGAN, вводится техника условно-когнитивной регуляции (англ. Conditioning Augmentation), которая способствует плавности в обусловливающем многообразии.
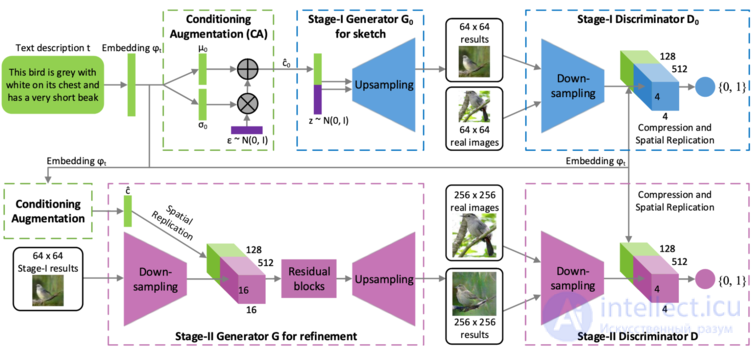
Вклад предлагаемого метода состоит в следующем:
Генератор Stage-II проектируется как сеть кодировщик-декодировщик с остаточными блоками. Что касается дискриминатора, его структура аналогична структуре дискриминатора Stage-I только с дополнительными блоками понижающей дискретизации, поскольку на этом этапе размер изображения больше.
| Набор данных | Inception Score |
|---|---|
| Caltech-UCSD | 3.70±0.04 |
| Oxford-102 | 3.20±0.01 |
| COCO | 8.45±0.03 |
Для проверки метода были проведены обширные количественные и качественные оценки. Результаты работы модели сравниваются с двумя современными методами синтеза текста в изображение — GAN-INT-CLS и GAWWN (рис. 6).


Для улучшения генерации изображений по описанию и получения контролируемой выборки, некоторые модели разделяют процесс генерации на несколько этапов. Например, в модели Attribute2Image раздельная генерации фона и переднего плана позволила получить контролируемую выборку (фиксируя фон и меняя основную сцену, и наоборот). В свою очередь модель FusedGAN может выполнять контролируемую выборку различных изображений с очень высокой точностью, что так же достигается путем разбиения процесса генерации изображений на этапы. В данной модели в отличие от StackGAN, где несколько этапов GAN обучаются отдельно с полным контролем помеченных промежуточных изображений, FusedGAN имеет одноступенчатый конвейер со встроенным StackGAN.
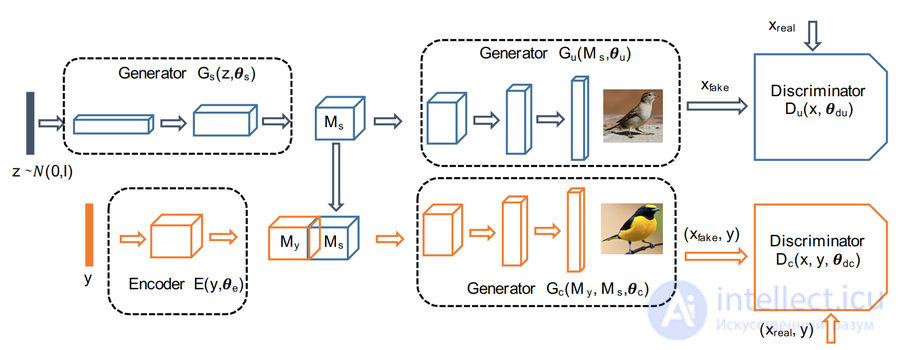
Контролируемая выборка относится к процессу выборки изображений путем изменения таких факторов как стиль, фон и другие детали. Например, можно генерировать разные изображения, оставляя постоянным фон, или генерировать изображения в различных стилях, сохраняя остальной контекст неизменным. Основное преимущество данной модели состоит в том, что для обучения она может использовать полу-размеченные данные. Это означает, что помимо размеченных данных (изображение и его описание) для генерации изображений, модель может использовать изображения без текстового описания. Модель состоит из двух взаимосвязанных этапов (рис. 19):
Мs выступает в роли шаблона подавая дополнительные признаки на второй шаг генерации. Вследствие чего изображения сгенерированных птиц не только соответствуют описанию, но также сохраняют информацию о стиле. Поэтому вместо того, чтобы учиться с нуля, Gc строится поверх Мs, добавляя к нему стили с помощью текстового описания. Следует отметить, что в модели отсутствует явная иерархия, поэтому оба этапа могут обучаться одновременно, используя альтернативный метод оптимизации.

Рисунок 20. Сравнение FusedGAN с другими моделями
Для оценки качества генерируемых изображений с помощью FusedGAN, были отобраны 30 тысяч изображений и посчитано inception scores, используя предварительно обученную модель на тестовом наборе Caltech-UCSD. Данные сравнения приведены в таблице.
| Модель | Inception Score |
|---|---|
| GAN-INT-CLS | 2.88±0.04 |
| StackGAN-I | 2.95±0.02 |
| FusedGAN | 3.00±0.03 |
В предыдущих и последующих моделях для создания изображений используются текстовые описания. Однако они могут быть недостаточно информативными, чтобы охватить все представленные изображения, и модели будет недостаточно данных для того чтобы сопоставить объекты на изображениях со словами в описании. Поэтому в качестве дополнительных данных в модели ChatPainter предлагается использовать диалоги, которые дополнительно описывают сцены (пример рис. 16). Это приводит к значительному улучшению Inception score и качества генерируемых изображений в наборе данных MS COCO (Microsoft COCO dataset). Для создания нового набора данных с диалогами, были объединены описания представленные в наборе данных MS COCO, с данными из Visual Dialog dataset (VisDial) .
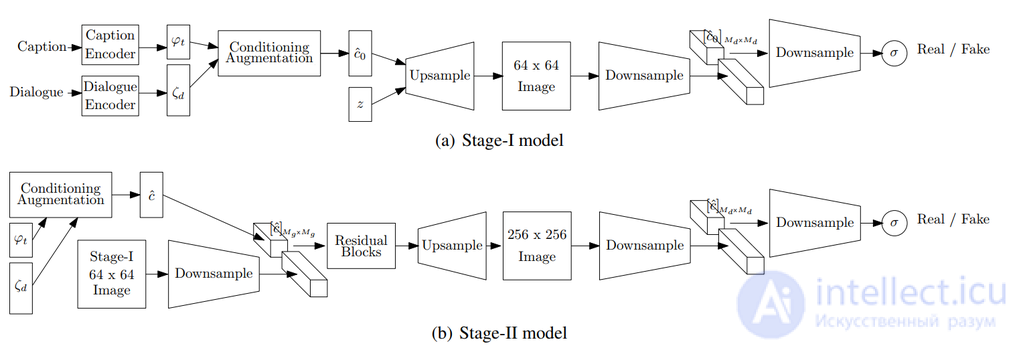
Рисунок 15. Архитектура ChatPainter:
Данная архитектура (рис. 15) опирается на модель StackGAN. StackGAN генерирует изображение в два этапа: на первом этапе генерируется грубое изображение 64×64, а на втором генерируется уже улучшенное изображение 256×256.
Формирование вектора текстовых описаний ϕt происходит путем кодирования подписей с помощью предварительно обученного кодировщика . Для генерации диалоговых вложений ζd используется два метода:
Затем выходы описаний и диалогов объединяются и передаются в качестве входных данных в модуль аугментации данных (англ. Conditioning Augmentation, CA). Модуль CA нужен для получения скрытых условных переменных, которые передаются на вход генератору. Архитектура блоков (рис. 15) upsample, downsample и residual blocks сохраняется такой же, как и у исходного StackGAN
Результаты тестирования и сравнение модели ChatPainter с другими приведены в таблице. Из нее видно, что модель ChatPainter, которая получает дополнительную диалоговую информацию, имеет более высокий Inception score , в отличии от модели StackGAN. Кроме того, рекурсивная версия ChatPainter получилась лучше, чем нерекурсивная версия. Вероятно, это связано с тем, что в нерекурсивной версии кодировщик не обучается на длинных предложениях сворачивая весь диалог в одну строку.
| Модель | Inception Score |
|---|---|
| StackGAN | 8.45±0.03 |
| ChatPainter (non-recurrent) | 9.43±0.04 |
| ChatPainter (recurrent) | 9.74±0.02 |
| AttnGAN | 25.89±0.47 |
Хотя генерирующие состязательные сети (GAN) показали замечательный успех в различных задачах, они все еще сталкиваются с проблемами при создании изображений высокого качества. Поэтому в данном разделе, во-первых, предлагается двухэтапная генеративная состязательная сетевая архитектура StackGAN-v1[12] для синтеза текста в изображение. Stage-I по-прежнему рисует примитивную форму и цвета сцены на основе заданного текстового описания, что дает изображения с низким разрешением. Stage-II все также принимает результаты этапа I и текстовое описание в качестве входных данных и генерирует изображения высокого разрешения с фотореалистичными деталями. Во-вторых, усовершенствованная многоэтапная генеративно-состязательная сетевая архитектура StackGAN-v2 предлагается как для условных, так и для безусловных генеративных задач. StackGAN-v2 состоит из нескольких генераторов и нескольких дискриминаторов, организованных в древовидную структуру (рис. 7); изображения в нескольких масштабах, соответствующие одной и той же сцене, генерируются из разных ветвей дерева. StackGAN-v2 демонстрирует более стабильное поведение при обучении, чем StackGAN-v1, за счет совместной аппроксимации нескольких распределений.
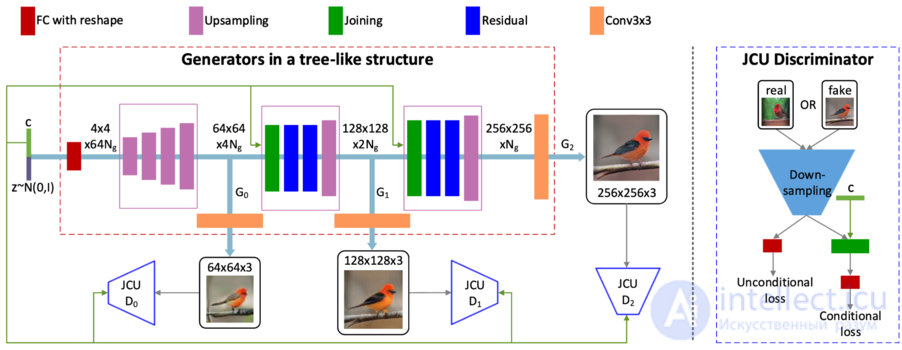
Рисунок 7.[12] Архитектура StackGAN++.
Несмотря на успех, GAN, как известно, сложно обучить. Тренировочный процесс обычно нестабилен и чувствителен к выбору гиперпараметров. При обучении GAN генерировать изображения с высоким разрешением (например, 256x256), вероятность того, что распределение изображений и распределение моделей будет совместно использовать один и тот же носитель в многомерном пространстве, очень мала. Более того, обычным явлением сбоя при обучении GAN является схлопывание мод распределения (англ. mode collapse), когда многие из сгенерированных выборок содержат одинаковый цвет или узор текстуры.
Предлагается продвинутая многоэтапная генеративно-состязательная сетевая архитектура StackGAN-v2 как для условных, так и для безусловных генеративных задач. StackGAN-v2 имеет несколько генераторов, которые разделяют между собой большинство своих параметров в древовидной структуре. Входные данные сети можно рассматривать как корень дерева, а изображения разного масштаба генерируются из разных ветвей дерева. Конечная цель генератора на самой глубокой ветви — создание фотореалистичных изображений с высоким разрешением. Генераторы в промежуточных ветвях имеют прогрессивную цель создания изображений от малых до больших для достижения конечной цели. Вся сеть совместно обучается аппроксимировать различные, но сильно взаимосвязанные распределения изображений в разных ветвях. Кроме того, используется регуляризация согласованности цвета (англ. color-consistency regularization), чтобы генераторы могли генерировать более согласованные образцы для разных масштабов.
| Набор данных | StackGAN-v1 | StackGAN-v2 |
|---|---|---|
| Caltech-UCSD | 3.70±0.04 | 4.04±0.05 |
| Oxford-102 | 3.20±0.01 | 3.26±0.01 |
| MS COCO | 8.45±0.03 | 8.30±0.10 |
На основе этих генеративных моделей также изучалась условная генерация изображений. В большинстве методов используются простые условные переменные, такие как атрибуты или метки классов. Существуют также работы с изображениями для создания изображений, включая редактирование фотографий, перенос области и сверхвысокое разрешение. Однако методы сверхвысокого разрешения могут добавлять только ограниченное количество деталей к изображениям с низким разрешением и не могут исправить большие дефекты.
Введен термин регуляризации согласованности цвета, чтобы образцы, сгенерированные с одного и того же входа на разных генераторах, были более согласованными по цвету и, таким образом, улучшили качество сгенерированных изображений (рис. 8).

Примеры результата работы для тестовых наборов Oxford-102 (крайние левые четыре столбца) и COCO (крайние правые четыре столбца).[12].
В данном разделе предлагается новый иерархический подход к синтезу текста (Hierarchical Text-to-Image Synthesis, HTIS[13]) в изображение путем определения семантического макета. Вместо того, чтобы изучать прямое отображение текста в изображение, алгоритм разбивает процесс генерации на несколько шагов, на которых он сначала создает семантический макет из текста с помощью генератора макета и преобразует макет в изображение с помощью генератора изображений (рис. 9). Предлагаемый генератор компоновки постепенно создает семантическую компоновку от грубого к точному, генерируя ограничивающие рамки (англ. bounding box) объекта и уточняя каждую рамку, оценивая формы объектов внутри нее. Генератор изображений синтезирует изображение, обусловленное предполагаемым семантическим макетом, что обеспечивает полезную семантическую структуру изображения, совпадающего с текстовым описанием.

Модель не только генерирует семантически более значимые изображения, но также позволяет автоматически аннотировать генерируемые изображения. Созданные изображения и процесс генерации под управлением пользователя путем изменения сгенерированного макета сцены.
Возможности предложенной модели были продемонстрированы на сложном наборе данных MS COCO. Оказывается, модель может существенно улучшить качество изображения, интерпретируемость вывода и семантическое выравнивание вводимого текста по сравнению с существующими подходами.
| Модель | Inception Score |
|---|---|
| StackGAN | 8.45±0.03 |
| Рассматриваемая модель | 11.46±0.09 |
Создание изображения из общего предложения «люди, едущие на слонах, идущих по реке» требует множества рассуждений о различных визуальных концепциях, таких как категория объекта (люди и слоны), пространственные конфигурации объектов (верховая езда), контекст сцены (прогулка по реке) и т. д., что намного сложнее, чем создание одного большого объекта, как в более простых наборах данных. Существующие подходы не привели к успеху в создании разумных изображений для таких сложных текстовых описаний из-за сложности обучения прямому преобразованию текста в пиксель из обычных изображений.
Поэтому вместо того, чтобы изучать прямое отображение текста в изображение, был предложен альтернативный подход, который строит семантический макет как промежуточное представление между текстом и изображением. Семантический макет определяет структуру сцены на основе экземпляров объектов и предоставляет детальную информацию о сцене, такую как количество объектов, категорию объекта, расположение, размер, форму и выдает довольно неплохой результат (рис. 10).

Сравнение HTIS[13].
Общепринятый подход заключается в кодировании всего текстового описания в глобальное векторное пространство предложений (англ. global sentence vector). Такой подход демонстрирует ряд впечатляющих результатов, но у него есть главные недостатки: отсутствие четкой детализации на уровне слов и невозможность генерации изображений высокого разрешения. Эта проблема становится еще более серьезной при генерации сложных кадров, таких как в наборе данных COCO.
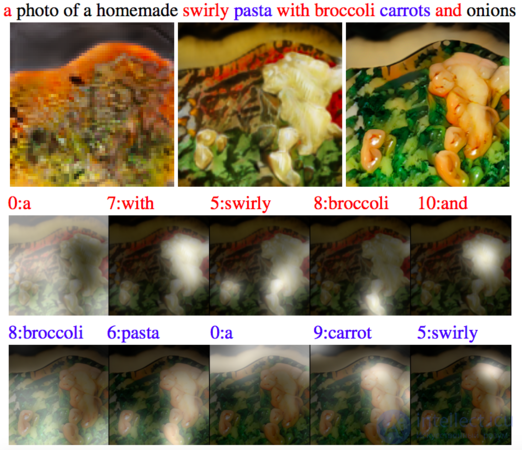
В качестве решения данной проблемы была предложена[14] новая генеративно-состязательная нейросеть с вниманием (англ. Attentional Generative Adversarial Network, AttnGAN), которая относится к вниманию как к фактору обучения, что позволяет выделять слова для генерации фрагментов изображения.
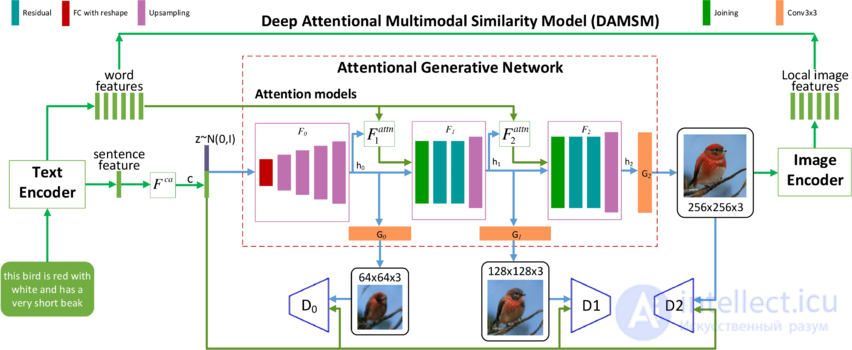
Рисунок 11.[14] Архитектура AttnGAN.
Модель состоит из нескольких взаимодействующих нейросетей (рис. 11):
Благодаря модификациям нейросеть AttnGAN показывает значительно лучшие результаты, чем традиционные системы GAN. В частности, максимальный из известных показателей Inception Score для существующих нейросетей улучшен на 14,14% (с 3,82 до 4,36) на наборе данных Caltech-UCSD и улучшен на целых 170,25% (с 9,58 до 25,89)[15] на более сложном наборе данных COCO.


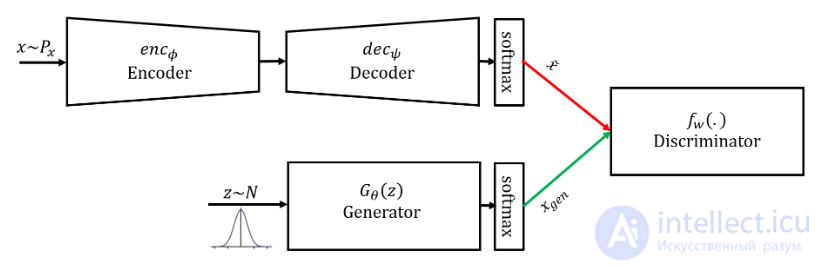
Большинство существующих методов генерации изображения по тексту нацелены на создание целостных изображений, которые не разделяют передний и задний план изображений, в результате чего объекты искажаются фоном. Более того, они обычно игнорируют взаимодополняемость различных видов генеративных моделей. Данное решение[16] предлагает контекстно-зависимый подход к генерации изображения, который разделяет фон и передний план. Для этого используется взаимодополняющая связка вариационного автокодировщика и генеративно-состязательной нейросети.
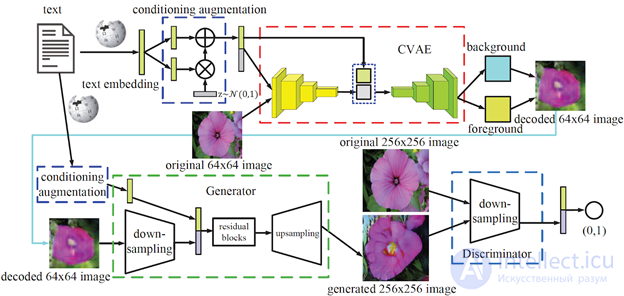
VAE имеет более стабильный выход чем GAN без схлопывания мод распределения (англ. mode collapse), это можно использовать для достоверной подборки распределения и выявления разнообразия исходного изображения. Однако он не подходит для генерации изображений высокого качества, т. к. генерируемые VAE изображения легко размываются. Чтобы исправить данный недостаток архитектура включает два компонента (рис. 13):
Полученные результаты проверки (рис.14) на 2 наборах данных (Caltech-UCSD и Oxford-102) эмпирически подтверждают эффективность предложенного метода.

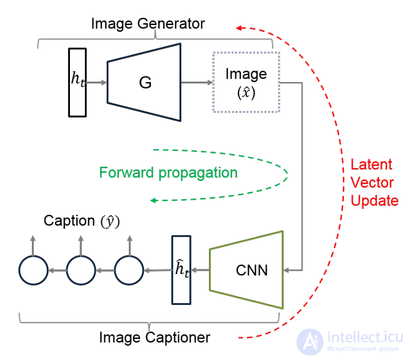
Модель мультимодальной векторной сети (англ. Multi-Modal Vector Representation, MMVR), впервые предложенная в статье[17], способна создавать изображения по описанию и генерировать описание исходя из предоставленного изображения. Она включает несколько модификаций для улучшения генерации изображений и описаний, а именно: вводится функция потерь на основе метрики N-грамм, которая обобщает описание относительно изображения; так же для генерации вместо одного используется несколько семантически сходных предложений, что так же улучшает создаваемые изображения.
Модель может быть разделена на два взаимозависимых модуля (рис. 17):
Прямое распространение (англ. forward pass) инициируется путем передачи случайного скрытого вектора (англ. latent vector) ht в генератор изображений (G), который генерирует изображение x^. Затем по сгенерированной картинке генератор описаний создает подпись. Для определения ошибки между сгенерированным описанием y^ и исходным описанием y используется перекрестная энтропия на уровне слов. Она используется для итеративного обновления ht (заодно и x^), оставляя при этом все остальные компоненты фиксированными. С каждой итерацией y^ приближается к y, и сгенерированное изображение на каждом шаге x^ является временным представлением конечного изображения. Для улучшения реалистичности изображения используется кодировщик шумоподавления (англ. Denoising Autoencoder, DAE)[20] — в правило обновления добавляется ошибка восстановления изображения (англ. reconstruction error), вычисляемая как разница между ht и ht^.
Обучение начинается с генерации случайного 4096-мерного вектора ht, который передается в модель для последующего итеративного обновления. Процесс завершается после 200 итераций, и полученное изображение считается репрезентативным для данного описания.
| Модель | Inception Score |
|---|---|
| Plug and Play Generative Networks (PPGN)[20] | 6.71±0.45 |
| MMVR | 7.22±0.81 |
| MMVR (Nc=5) | 8.30±0.78 |
MMVR (Nc) — модификация MMVR с несколькими текстовыми описаниями на изображение, где Nc — количество описаний.
| Модель | Inception Score (Caltech-UCSD) | Inception Score (COCO) |
|---|---|---|
| GAN-INT-CLS | 2.88±0.04 | 7.88±0.07 |
| GAWWN | 3.70±0.04 | − |
| StackGAN | 3.62±0.07 | 8.45±0.03 |
| StackGAN++ | 3.82±0.06 | − |
| PPGN[20] | − | 9.58±0.21 |
| AttnGAN | 4.36±0.03 | 25.89±0.47 |
| MirrorGAN | 4.56±0.05 | 26.47±0.41 |
Генерация изображения из заданного текстового описания преследует две главные цели: реалистичность и семантическое постоянство. Несмотря на то, что существует значительный прогресс в создании визуально реалистичных изображений высокого качества посредством генеративных состязательных сетей, обеспечение вышепоставленных целей все еще является довольно сложной задачей. Для осуществления попытки их реализации рассмотрим text-to-image-to-text фреймворк с вниманием, сохраняющий семантику, под названием MirrorGAN[21]. Данный фреймворк, который из текстового описания генерирует изображение, использует идею обучения с помощью переописания (англ. redescription) и состоит из трех модулей:
STEM создает встраивания на уровне слов и предложений, GLAM имеет каскадную архитектуру создания результирующих изображений от грубых до детализированных, используя как внимание к локальным словам, так и к глобальным предложениям, чтобы прогрессивно совершенствовать семантическое постоянство и разнообразие у сгенерированных изображений, а STREAM стремится к восстановлению текстового описания созданного изображения, которое семантически схоже с заданным описанием.
Если изображение, сгенерированное с помощью T2I (text-to-image), семантически соответствует заданному описанию, его текстовое описание, созданное посредством I2T (image-to-text) должно семантически совпадать с заданным.
Чтобы обучать модель сквозным методом, будем использовать две состязательные функции потерь:
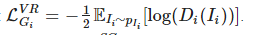
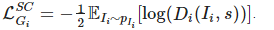
Где Ii — сгенерированное на этапе i изображение, взятое из распределения pIi. Вдобавок, для эффективного использования двойного регулирования T2I и I2T, применим текстово-семантическую реконструированную функцию потерь, основанную на перекрестной энтропии: 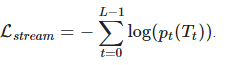
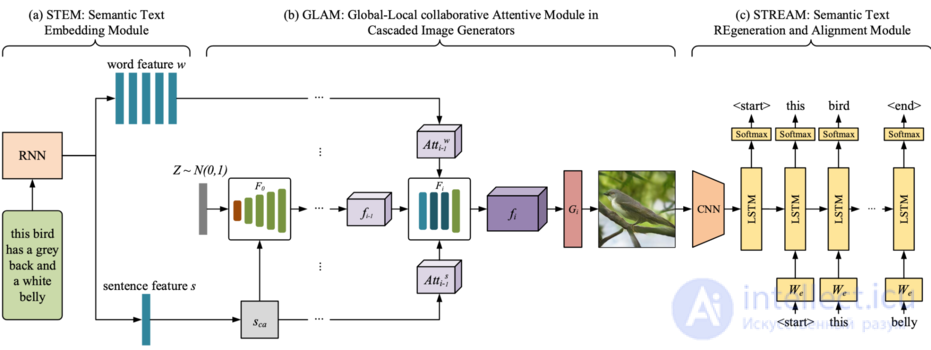
MirrorGan представляет собой зеркальную структуру, объединяя T2I и I2T. Чтобы сконструировать многоэтапный каскадный генератор, все три сети генерации изображений (STEM, GLAM и STREAM) необходимо объединить. В качестве архитектуры STREAM будем использовать довольно распространенный фреймворк создания текстового описания изображения (англ. image captioning framework), базирующийся на кодировании и декодировании. Кодировщик изображений — это сверточная нейронная сеть, предварительно обученная на ImageNet[22], а декодировщик — это рекуррентная нейронная сеть. Предварительное обучение STREAM помогло MirrorGAN достичь более стабильного процесса обучения и более быстрой сходимости, в то время, как их совместная оптимизация довольно нестабильна, занимает много места и долго работает. Структура кодировщик-декодировщик и соответствующие ей параметры фиксированы во время обучения других модулей MirrorGAN.
Обучая Gi, градиенты из Lstream обратно распространяются через STREAM в Gi, веса сетей которых остаются фиксированными. Финальная целевая функция генератора выглядит так:
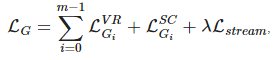
где λ — вес потери для обработки участия состязательной потери (англ. adversarial loss) и потери текстово-семантической реконструкции (англ. text-semantic reconstruction loss). Для наилучшего качества генерации можно поставить коэффициент λ=20.
Показатель Inception Score был использован для измерения как объективности, так и разнообразия сгенерированных изображений. R-precision был использован для вычисления визуально-семантической схожести между сгенерированными изображениями и их соответствующими текстовыми описаниями.

Рисунок 22.[21] Сравнение MirrorGAN, AttnGAN и других генеративных состязательных сетей.
Генерация текста представляет особый интерес во многих приложениях нейролингвистического программирования (англ. neuro-linguistic programming, NLP), таких как машинный перевод, моделирование языка и обобщение текста. Генеративные состязательные сети достигли замечательного успеха в создании высококачественных изображений в компьютерном зрении, и в последнее время они также вызвали большой интерес со стороны сообщества NLP. Однако достижение подобного успеха в NLP было бы более сложным из-за дискретности текста. В данной статье[23] вводится метод, использующий дистилляцию знаний (перенос знаний, усвоенных большой моделью (учителем), на меньшую модель (ученика)) для эффективного оперирования настройками сети.
TextKD-GAN представляет из себя решение для основного узкого места использования генеративных состязательных сетей для генерации текста с дистилляцией знаний — методом, переносящим знания смягченного вывода модели (учителя) в меньшую модель (ученика). Решение основано на автокодировщике (учителе), чтобы получить гладкое представление настоящего текста. Это представление затем подается в дискриминатор TextKD-GAN вместо обычного one-hot представления. Генератор (студент) пытается изучить многообразие смягченного гладкого представления автокодировщика. TextKD-GAN, в конечном итоге, будет превосходить обычный генератор текста на основе генеративных состязательных сетей, который не нуждается в предварительном обучении.
В общепринятом текстовом распознавании, реальные и сгенерированные входные данные дискриминатора будут иметь разные типы (one-hot и softmax). Один из способов избежать этой проблемы состоит в получении непрерывно гладкого представление слов, а не one-hot представления, и обучении дискриминатора различать их. На рисунке 27 проиллюстрирована модель, в которой используется стандартный автокодировщик (учитель), чтобы заменить one-hot представление выходом, перестроенным softmax-функцией, который является представлением, дающим меньшую дисперсию градиентов. Как видно, вместо one-hot представления реальных слов смягченный преобразованный выход автокодировщика подается на вход дискриминатору. Эта техника значительно усложняет распознавание для самого дискриминатора. Генератор с softmax выходом пытается имитировать распределение выходного сигнала автокодировщика вместо обычного one-hot представления.
Обучение автокодировщика и TextKD-GAN происходит одновременно. Чтобы добиться этого, необходимо раздробить целевую функцию на три члена:
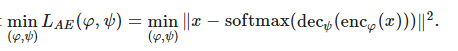
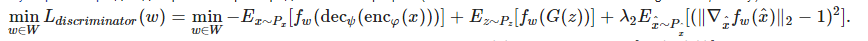
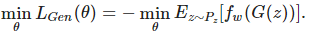
Эти функции потерь обучаются поочередно, чтобы оптимизировать различные части модели. В члене штрафа градиента необходимо посчитать норму градиента случайных выборок 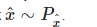
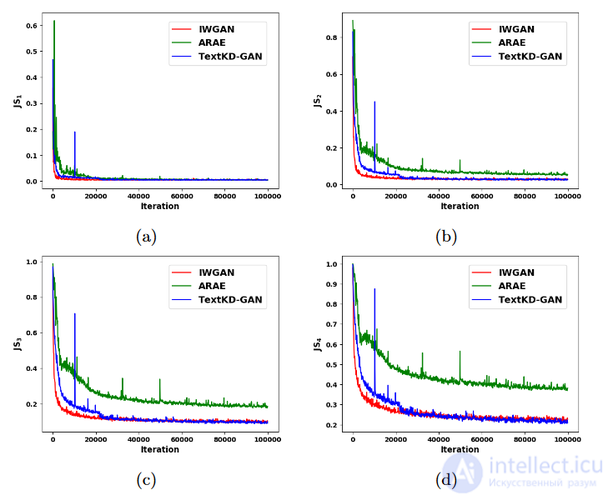
Объектно-управляемая генеративная состязательная сеть с вниманием (англ. Object-Driven Attentive Generative Adversarial Network, Obj-GAN) позволяет создавать изображения по описанию с учетом объектной компоновки. Объектно-управляемый генератор изображений, создает изображения на основе двухэтапной генерации. Сначала создается макет по наиболее значимым словам в текстовом описании, после этого генерируется изображение с полученной компоновкой объектов. А для сопоставления синтезируемых объектов с текстовым описанием и сгенерированным макетом, предлагается[25] новый объектный дискриминатор, основывающийся на Fast R-CNN[26]. В результате модификаций Obj-GAN значительно превосходит по производительности другие модели на наборе данных COCO, увеличивая показатель Inception score на 11% и уменьшая показатель FID (Fréchet inception distance) на 27%.
| Модель | Inception Score | FID |
|---|---|---|
| Obj-GAN (pred box & pred shp) | 27.32±0.40 | 24.70 |
| Obj-GAN (gt box & pred shp) | 28.22±0.35 | 22.67 |
| Obj-GAN (gt box & gt shp) | 31.01±0.27 | 17.03 |
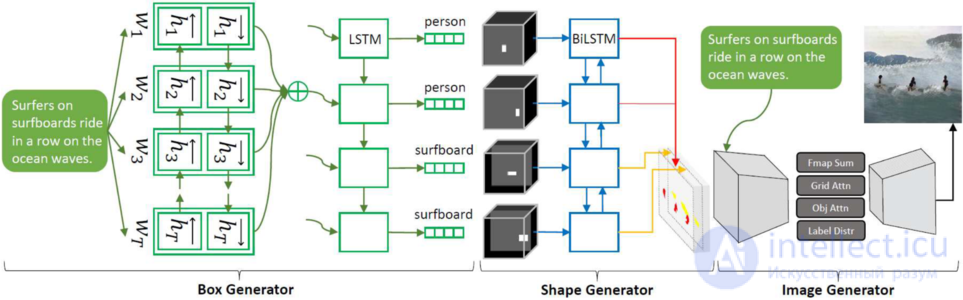
Основная цель Obj-GAN — генерация качественных изображений с семантически значимым макетом и реалистичными объектами. Obj-GAN состоит из пары генератора изображений с вниманием, управляемый объектами, и пообъектного дискриминатора (англ. object-wise discriminator). Генератор изображений в качестве входных данных принимает текстовое описание и предварительно сгенерированный семантический макет (англ. semantic layout), по которым создает изображение с помощью процесса, заключающегося в поэтапном улучшении качества результирующего изображения. На каждом этапе генератор синтезирует фрагмент изображений внутри ограничивающей рамки (англ. bounding box), фокусируясь на наиболее релевантных объекту словах.
Говоря более конкретно, он, с использованием управляемого объектами слоя внимания, оперирует метками класса, запрашивая слова в предложениях, чтобы сформировать вектор контекстов, и впоследствии синтезирует фрагмент изображения при условиях метки и вектора контекстов. Пообъектный дискриминатор проверяет каждую ограничивающую рамку, чтобы удостовериться в том, что сгенерированный объект действительно может быть сопоставлен с заранее сгенерированным макетом. Чтобы вычислить все потери при распознавании для всех заданных ограничивающих рамок одновременно и эффективно, дискриминатор представляет из себя быструю сверточную нейронную сеть на основе регионов (англ. Fast Region-based Convolutional Neural Network, Fast R-CNN) с двоичной функцией потерь перекрестной энтропии для каждой рамки.
Рассмотрим архитектуру Obj-GAN. Первым этапом, генеративная состязательная сеть принимает текстовое предложение и генерирует семантический макет — последовательность объектов специфицированных соответствующими ограничивающими рамками (наряду с метками классов) и фигурами. Генератор рамок (англ. box generator) и генератор фигур (англ. shape generator) работают соответствующим образом, сначала создавая последовательность ограничивающих рамок, а затем — фигуру для каждой. Поскольку большинству рамок сопоставлены слова из данного текстового предложения, модель seq2seq с вниманием охватывает это соответствие. Далее конструируется Gshape, базированный на двунаправленной сверточной долгой краткосрочной памяти (англ. bidirectional convolutional long short-term memory, LSTM). Обучение Gshape основывается на фреймворке генеративной состязательной сети, в которой потеря восприятия используется для ограничения генерируемых фигур и стабилизирования обучения.


Модели, используемые для создания макетов сцен из текстовых описаний по большей части игнорируют возможные визуальные вариации внутри структуры, описываемой самим текстом.
Макетный вариационный автокодировщик (англ. Layout variational autoencoder, LayoutVAE) — фреймворк, базирующийся на вариационном автокодировщике для генерации стохастических макетов сцен (англ. stochastic scene layouts) — это программная платформа моделирования, позволяющая генерировать либо полные макеты изображений с заданным набором меток, либо макеты меток для существующего изображения с новой заданной меткой.
Рассмотрим задачу генерации сцен с описанием набора меток. Этот набор всего лишь предоставляет множество меток, присутствующих в данном изображении (без дополнительного описания взаимосвязи), заставляя модель изучать пространственные и подсчитываемые отношения (англ. spatial and count relationships) на основе визуальных данных.
Касательно вышеописанной задачи предлагаются следующие решения:
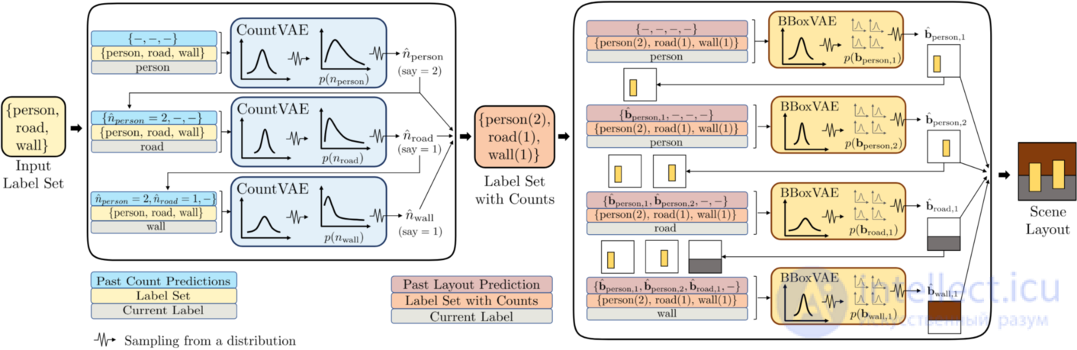
Рисунок 25.[27] Архитектура LayoutVAE.
В статье[27] были предложены фреймворки и структуры моделей, взаимодействующие с LayoutVE, такие как: PNP-Net — фреймворк вариационного автокодировщика для создания изображения из текстовой программы, которая полностью ее описывает (помимо того, что это стохастическая модель для генерации, она была протестирована на синтетических наборах данных с малым числом классов); LayoutGAN — модель, основанная на генеративных состязательных сетях, создающая макеты графических элементов (прямоугольники, треугольники, и так далее); фреймворк, базирующийся на вариационном автокодировщике, который кодирует объект и информацию о макете 3D-сцен в помещении в скрытом коде; и так далее...
Обучение генеративных моделей необходимо, чтобы предсказать разнообразные, но правдоподобные наборы ограничивающих рамок (англ. bounding boxes) bk,i=[xk,i,yk,i,wk,i,hk,i], учитывая набор меток в качестве входных данных. Рамки в наборе представлены верхними левыми координатами, шириной и высотой i-й ограничивающей рамки категории k. LayoutVAE декомпозируется на модель для предсказания количества для каждой заданной метки — CountVAE — и модель для предсказания местоположения и размера каждого объекта — BBoxVAE.
Имея набор меток L и количество объектов в категории {nm:m∈L}, BBoxVAE предсказывает распределение координат для ограничивающих рамок авторегрессионно. Мы следуем тому же предопределенному порядку меток, что и в CountVAE, в пространстве меток, и упорядочиваем ограничивающие рамки слева направо для каждой метки; сначала все ограничивающие рамки предсказываются для заданной метки, а уже потом происходит переход к следующей метке.

Преобразование изображений перекрестным видом (англ. cross-view image translation) проблематично, поскольку оно оперирует изображениями со значительно отличающимися ракурсами и тяжелыми деформациями. В статье[28] о выборочной генеративной состязательной сети с мультиканальным вниманием (англ. Multi-Channel Attention Selection GAN, MCA-GAN) рассматривается подход, позволяющий делать возможным генерацию изображения, максимально приближенной к реальной, с произвольных ракурсах, основывающийся на семантическом отображении (англ. semantic mapping). Работа сети происходит в два этапа:
Обширные эксперименты на наборах данных Dayton, CVUSA[29] и Ego2Top[30] показывают, что данная модель способна генерировать значительно более качественные результаты, чем другие современные методы.
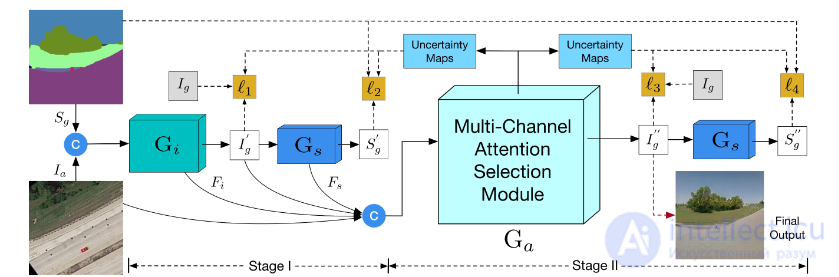
На рисунке 29 проиллюстрирована структура сети. Первый этап, как было описано выше, состоит из каскадной семантически-управляемой генерацинной подсети, использующая изображения в одном представлении и условные семантические отображения в другом представлении в качестве входных данных и преобразующая эти изображения в другом представлении. Результирующие изображения далее подаются на вход семантическому генератору для восстановления исходного семантического отображения, формируя цикл генерации. Второй этап заключается в том, что грубый синтез (англ. coarse synthesis) и отображения глубоких характеристик объединяются и подаются на вход в модуль мультиканального выделения внимания, направленный на получение более детализированного синтеза (англ. fine-grained synthesis) из большего пространства генерации и создание отображений неопределенности (англ. uncertainty maps) для управления множественными потерями оптимизации (англ. optimization losses). Модуль мультиканального выделения внимания в свою очередь состоит из многомасштабного пространственного пулинга (англ. multiscale spatial pooling) и компоненты мультиканального выделения внимания (англ. multichannel attention selection component).
Поскольку между изначальным ракурсом и результирующим существует объемная деформация объекта и/или сцены, одномасштабная характеристика (англ. single-scale feature) вряд ли сможет захватить всю необходимую информацию о пространстве для детализированной генерации. Многомасштабный пространственный пулинг оперирует же другими значениями размера ядра и шага для выполнения глобального среднего пулинга (англ. global average pooling) на одних и тех же входных характеристиках, тем самым получая многомасштабные характеристики с отличающимися рецептивными полями (англ. receptive fields) для восприятия различных пространственных контекстов. Механизм мультиканального внимания позволяет осуществлять выполнение пространственного и временного отбора (англ. spatial and temporal selection), чтобы синтезировать конечный детализированный результат.
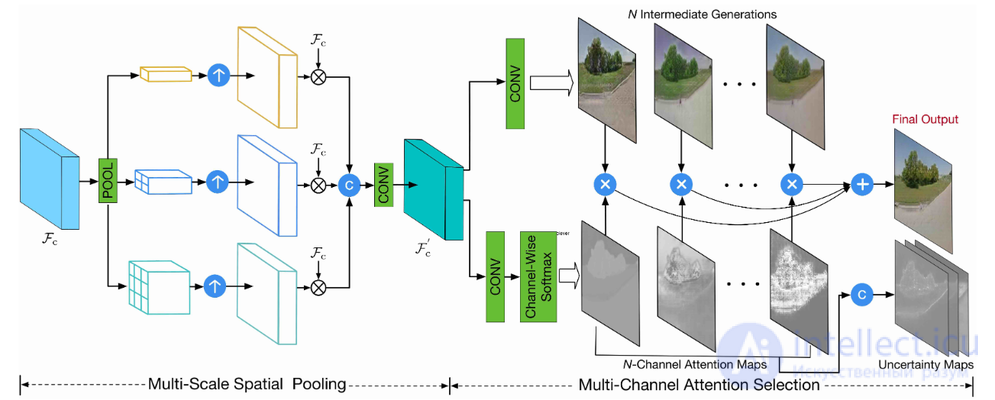

Рисунок 31 Преобразование изображения перекрестным видом.



Комментарии
Оставить комментарий
Нейронные сети
Термины: Нейронные сети