Лекция
Привет, Вы узнаете о том , что такое transformer, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое transformer, трансформер , настоятельно рекомендую прочитать все из категории Нейронные сети.
Трансфо́рмер (англ. Transformer) — архитектура глубоких нейронных сетей, представленная в 2017 году исследователями из Google Brain.
По аналогии с рекуррентными нейронными сетями (РНС) трансформер ы предназначены для обработки последовательностей, таких как текст на естественном языке, и решения таких задач как машинный перевод и автоматическое реферирование. В отличие от РНС, трансформеры не требуют обработки последовательностей по порядку. Например, если входные данные — это текст, то трансформеру не требуется обрабатывать конец текста после обработки его начала. Благодаря этому трансформеры распараллеливаются легче чем РНС и могут быть быстрее обучены.
Архитектура трансформера состоит из кодировщика и декодировщика. Кодировщик получает на вход векторизованую последовательность с позиционной информацией. Декодировщик получает на вход часть этой последовательности и выход кодировщика. Кодировщик и декодировщик состоят из слоев. Слои кодировщика последовательно передают результат следующему слою в качестве его входа. Слои декодировщика последовательно передают результат следующему слою вместе с результатом кодировщика в качестве его входа.
Каждый кодировщик состоит из механизма самовнимания (вход из предыдущего слоя) и нейронной сети с прямой связью (вход из механизма самовнимания). Каждый декодировщик состоит из механизма самовнимания (вход из предыдущего слоя), механизма внимания к результатам кодирования (вход из механизма самовнимания и кодировщика) и нейронной сети с прямой связью (вход из механизма внимания).


Каждый механизм внимания параметризован матрицами весов запросов  , весов ключей
, весов ключей  , весов значений
, весов значений  . Для вычисления внимания входного вектора 𝑋 к вектору 𝑌 , вычисляются вектора
. Для вычисления внимания входного вектора 𝑋 к вектору 𝑌 , вычисляются вектора  ,
,  ,
,  . Эти вектора используются для вычисления результата внимания по формуле:
. Эти вектора используются для вычисления результата внимания по формуле:

До трансформаторов в закрытые рекуррентные нейронные сети были добавлены предшественники механизма внимания , такие как LSTM и закрытые рекуррентные единицы (GRU), которые обрабатывали наборы данных последовательно. Зависимость от предыдущих вычислений токенов не позволила им распараллелить механизм внимания. В 1992 году быстрый контроллер веса был предложен в качестве альтернативы рекуррентным нейронным сетям, способным обучаться «внутренним прожекторам внимания». Теоретически информация от одного токена может распространяться сколь угодно далеко вниз по последовательности, но на практике проблема исчезающего градиента оставляет состояние модели в конце длинного предложения без точной, извлекаемой информации о предыдущих токенах.
Производительность старых моделей была улучшена за счет добавления механизма внимания, который позволял модели получать доступ к любой предыдущей точке последовательности. Уровень внимания взвешивает все предыдущие состояния в соответствии с изученной мерой релевантности, предоставляя соответствующую информацию об удаленных токенах. Это оказалось особенно полезным при языковом переводе , где отдаленный контекст может иметь решающее значение для значения слова в предложении. Вектор состояния стал доступен только после того, как было обработано последнее английское слово во время, например, перевода его с французского с помощью модели LSTM. Хотя теоретически такой вектор сохраняет информацию обо всем исходном предложении, на практике информация сохраняется плохо. Если добавлен механизм внимания, декодеру предоставляется доступ к векторам состояния каждого входного слова, а не только последнего, и он может узнать веса внимания, которые определяют, сколько внимания уделять каждому входному вектору состояния. Дополнение моделей seq2seq механизмом внимания было впервые реализовано в контексте машинного перевода Богданау, Чо и Бенджио в 2014 году.
В 2016 году высокораспараллеливаемое разлагаемое внимание было успешно объединено с сетью прямой связи . Это указывало на то, что механизмы внимания сами по себе являются мощными и что последовательная рекуррентная обработка данных не является необходимой для достижения повышения качества рекуррентных нейронных сетей с вниманием. В 2017 году Васвани и др. также предложил заменить рекуррентные нейронные сети самообслуживанием и начал попытки оценить эту идею. Трансформаторы, используя механизм внимания, обрабатывая все токены одновременно, вычисляли «мягкие» веса между ними в последовательных слоях. Поскольку механизм внимания использует информацию только о других токенах из нижних уровней, ее можно вычислять для всех токенов параллельно, что приводит к повышению скорости обучения.
Простая архитектура трансформатора с трудом сходилась. В оригинальной статье авторы рекомендовали использовать прогрев скорости обучения. То есть скорость обучения должна линейно увеличиваться от 0 до максимального значения для первой части обучения (обычно рекомендуется составлять 2% от общего количества шагов обучения), а затем снова снижаться.
В статье 2020 года было обнаружено, что использование нормализации слоев до (а не после) слоев многоголового внимания и прямой связи стабилизирует обучение, не требуя повышения скорости обучения.
Модель GT 3 объединяет CWTE, SWTE и TTE с использованием самоадаптивного слоя вентилей, что обеспечивает эффективное и действенное объединение трех типов функций для сквозного текстового прогнозирования фондового рынка.
Трансформаторы обычно проходят самостоятельное обучение, включающее предварительную подготовку без присмотра с последующей контролируемой точной настройкой . Предварительное обучение обычно выполняется на большем наборе данных, чем точная настройка, из-за ограниченной доступности помеченных обучающих данных. Задачи по предварительному обучению и тонкой настройке обычно включают в себя:
В статье «Трансформатор Т5» документировано большое количество предтренировочных задач. Некоторые примеры:
Thank you <X> me to your party <Y> week.-> <X> for inviting <Y> last <Z>где <Z>означает «конец вывода».translate English to German: That is good.-> Das ist gut..The course is jumping well. ): -> not acceptable.Модель преобразователя реализована в стандартных средах глубокого обучения , таких как TensorFlow и PyTorch .
Transformers — это библиотека, созданная Hugging Face , которая предоставляет архитектуры на основе трансформаторов и предварительно обученные модели.

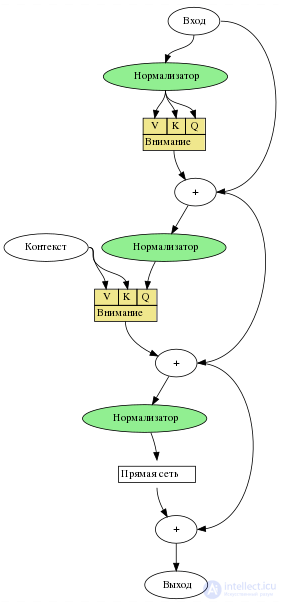
Иллюстрация основных компонентов модели трансформатора из оригинальной статьи, где нормализация слоев выполнялась после многоголового внимания. В статье 2020 года было обнаружено, что размещение нормализации слоя перед многонаправленным вниманием (а не после него) улучшает стабильность обучения .
Все трансформаторы имеют одинаковые первичные компоненты:
Слои преобразователя могут быть одного из двух типов: кодировщика и декодера . В оригинальной статье использовались оба они, тогда как более поздние модели включали только один из них. BERT — пример модели только для кодировщика; GPT — это модели только для декодера.
Входной текст анализируется на токены с помощью токенизатора, чаще всего токенизатора , кодирующего пару байтов , и каждый токен преобразуется в вектор путем поиска в таблице встраивания слов . Затем к встраиванию слова добавляется позиционная информация токена.
Как и более ранние модели seq2seq , исходная модель преобразователя использовала архитектуру кодер-декодер . Кодер состоит из слоев кодирования, которые итеративно обрабатывают входные токены один уровень за другим, а декодер состоит из слоев декодирования, которые итеративно обрабатывают выходные данные кодера, а также выходные токены декодера.
Функция каждого уровня кодера заключается в создании контекстуализированных представлений токенов, где каждое представление соответствует токену, который «смешивает» информацию из других входных токенов посредством механизма самообслуживания. Каждый уровень декодера содержит два подуровня внимания: (1) перекрестное внимание для включения выходных данных кодера (контекстуализированные входные представления токенов) и (2) самовнимание для «смешивания» информации между входными токенами в декодер (т. е. токены, сгенерированные на данный момент во время вывода)
И уровни кодера, и декодера имеют нейронную сеть прямого распространения для дополнительной обработки выходных данных и содержат остаточные соединения и этапы нормализации слоев.
Строительные блоки трансформатора представляют собой масштабированные единицы внимания со скалярным произведением . Для каждой единицы внимания модель преобразователя изучает три весовые матрицы: веса запроса , ключевые веса и веса значений . За каждый токен  , представление входного токенаИкся
, представление входного токенаИкся умножается на каждую из трех весовых матриц для получения вектора запроса с
умножается на каждую из трех весовых матриц для получения вектора запроса с , ключевой векторкя"="ИксяВтК
, ключевой векторкя"="ИксяВтК и вектор значений В
и вектор значений В . Веса внимания рассчитываются с использованием запроса и ключевых векторов: вес внимания
. Веса внимания рассчитываются с использованием запроса и ключевых векторов: вес внимания  из токена жетон
из токена жетон  является скалярным произведением междудя
является скалярным произведением междудя икдж
икдж . Веса внимания делятся на квадратный корень из размерности ключевых векторов:дк
. Веса внимания делятся на квадратный корень из размерности ключевых векторов:дк , который стабилизирует градиенты во время тренировки, и прошел через softmax , который нормализует веса. Дело в том, что и разные матрицы, позволяет вниманию быть несимметричным: если токенязанимается жетономдж(т.е.
, который стабилизирует градиенты во время тренировки, и прошел через softmax , который нормализует веса. Дело в том, что и разные матрицы, позволяет вниманию быть несимметричным: если токенязанимается жетономдж(т.е.  большой), это не обязательно означает, что токен займусь жетономя(т.е.
большой), это не обязательно означает, что токен займусь жетономя(т.е.  может быть небольшим). Об этом говорит сайт https://intellect.icu . Выход блока внимания для токенаяпредставляет собой взвешенную сумму векторов значений всех токенов, взвешенных по , внимание от токена к каждому токену.
может быть небольшим). Об этом говорит сайт https://intellect.icu . Выход блока внимания для токенаяпредставляет собой взвешенную сумму векторов значений всех токенов, взвешенных по , внимание от токена к каждому токену.
Вычисление внимания для всех токенов можно выразить как одно большое матричное вычисление с использованием функции softmax , которая полезна для обучения благодаря оптимизации вычислительных матричных операций, позволяющей быстро вычислять матричные операции. Матрицы  ,
,  и
и  определяются как матрицы, в которыхяэти строки являются векторами ,
определяются как матрицы, в которыхяэти строки являются векторами ,  , и
, и  соответственно. Тогда мы можем представить внимание как
соответственно. Тогда мы можем представить внимание как

где softmax отсчитывается по горизонтальной оси.
Один набор  матрицы называются головкой внимания , и каждый слой в модели преобразователя имеет несколько голов внимания. В то время как каждая голова внимания обслуживает токены, которые имеют отношение к каждому токену, несколько голов внимания позволяют модели делать это для разных определений «релевантности». Кроме того, поле влияния, представляющее релевантность, может постепенно расширяться на последующих уровнях. Многие преобразователи внимания кодируют отношения релевантности, значимые для людей. Например, некоторые головы внимания могут сосредоточиться в основном на следующем слове, тогда как другие в основном переключаются с глаголов на их прямые объекты. Вычисления для каждой головки внимания могут выполняться параллельно , что обеспечивает быструю обработку. Выходные данные слоя внимания объединяются для передачи в слои нейронной сети прямой связи .
матрицы называются головкой внимания , и каждый слой в модели преобразователя имеет несколько голов внимания. В то время как каждая голова внимания обслуживает токены, которые имеют отношение к каждому токену, несколько голов внимания позволяют модели делать это для разных определений «релевантности». Кроме того, поле влияния, представляющее релевантность, может постепенно расширяться на последующих уровнях. Многие преобразователи внимания кодируют отношения релевантности, значимые для людей. Например, некоторые головы внимания могут сосредоточиться в основном на следующем слове, тогда как другие в основном переключаются с глаголов на их прямые объекты. Вычисления для каждой головки внимания могут выполняться параллельно , что обеспечивает быструю обработку. Выходные данные слоя внимания объединяются для передачи в слои нейронной сети прямой связи .
Конкретно, пусть множественные головы внимания индексируютсяя, тогда мы имеем

где матрица  представляет собой конкатенацию вложений слов и матриц
представляет собой конкатенацию вложений слов и матриц  являются «проекционными матрицами», принадлежащими голове индивидуального внимания , и
являются «проекционными матрицами», принадлежащими голове индивидуального внимания , и  — это окончательная проекционная матрица, принадлежащая всей многоголовой голове внимания.
— это окончательная проекционная матрица, принадлежащая всей многоголовой голове внимания.
Возможно, потребуется вырезать связи внимания между некоторыми парами слов. Например, декодер позиции токенат не должен иметь доступа к позиции токена
не должен иметь доступа к позиции токена  . Это можно сделать до этапа softmax, добавив матрицу маски.М то есть
. Это можно сделать до этапа softmax, добавив матрицу маски.М то есть  в записях, где необходимо отключить ссылку внимания, и0 в других местах:
в записях, где необходимо отключить ссылку внимания, и0 в других местах:

Например, в авторегрессионном моделировании используется следующая матрица маски:

На словах это означает, что каждый токен может обращать внимание на себя и каждый токен до него, но не на любой после него.
Каждый кодер состоит из двух основных компонентов: механизма самообслуживания и нейронной сети прямой связи. Механизм самообслуживания принимает входные кодировки от предыдущего кодировщика и взвешивает их соответствие друг другу для создания выходных кодировок. Нейронная сеть с прямой связью дополнительно обрабатывает каждое выходное кодирование индивидуально. Эти выходные кодировки затем передаются следующему кодировщику в качестве входных данных, а также декодерам.
Первый кодер принимает в качестве входных данных позиционную информацию и вложения входной последовательности, а не кодировки. Информация о положении необходима преобразователю для использования порядка последовательности, поскольку никакая другая часть преобразователя не использует ее.
Кодер является двунаправленным. Внимание может быть обращено на токены до и после текущего токена. Токены используются вместо слов для учета многозначности .

Схема синусоидального позиционного кодирования с параметрами 
Позиционное кодирование — это векторное представление фиксированного размера, которое инкапсулирует относительные позиции токенов в целевой последовательности: оно предоставляет модели преобразователя информацию о том, где находятся слова во входной последовательности.
Позиционное кодирование определяется как функция типа  , где
, где  является положительным четным целым числом . Полное позиционное кодирование, определенное в оригинальной статье, задается уравнением:
является положительным четным целым числом . Полное позиционное кодирование, определенное в оригинальной статье, задается уравнением:

где  .
.
Здесь,  это свободный параметр, который должен быть значительно больше самого большого
это свободный параметр, который должен быть значительно больше самого большого  это будет введено в функцию позиционного кодирования. В оригинальной статье авторы выбрали
это будет введено в функцию позиционного кодирования. В оригинальной статье авторы выбрали  .
.
Функция имеет более простую форму, если ее записать как сложную функцию типаж: 

где  .
.
Основная причина, по которой авторы выбрали ее в качестве функции позиционного кодирования, заключается в том, что она позволяет выполнять сдвиги как линейные преобразования:

где  это расстояние, на которое человек хочет переместиться. Это позволяет преобразователю принимать любую закодированную позицию и находить кодировку позиции на n шагов вперед или на n шагов назад путем умножения матрицы.
это расстояние, на которое человек хочет переместиться. Это позволяет преобразователю принимать любую закодированную позицию и находить кодировку позиции на n шагов вперед или на n шагов назад путем умножения матрицы.
Взяв линейную сумму, любую свертку также можно реализовать как линейные преобразования:

для любых константсдж . Это позволяет преобразователю принять любую закодированную позицию и найти линейную сумму закодированных местоположений своих соседей. Эта сумма закодированных позиций, когда она подается в механизм внимания, будет создавать веса внимания для своих соседей, очень похоже на то, что происходит в языковой модели сверточной нейронной сети . По словам автора, «мы предположили, что это позволит модели легко научиться следить за относительным положением».
. Это позволяет преобразователю принять любую закодированную позицию и найти линейную сумму закодированных местоположений своих соседей. Эта сумма закодированных позиций, когда она подается в механизм внимания, будет создавать веса внимания для своих соседей, очень похоже на то, что происходит в языковой модели сверточной нейронной сети . По словам автора, «мы предположили, что это позволит модели легко научиться следить за относительным положением».
В типичных реализациях все операции выполняются над действительными числами, а не над комплексными числами, но поскольку комплексное умножение можно реализовать как умножение реальной матрицы 2 на 2 , это всего лишь разница в обозначениях.
Каждый декодер состоит из трех основных компонентов: механизма самоконтроля, механизма внимания к кодировкам и нейронной сети прямой связи. Декодер функционирует аналогично кодировщику, но в него вставлен дополнительный механизм внимания, который вместо этого извлекает соответствующую информацию из кодировок, сгенерированных кодировщиками. Этот механизм также можно назвать вниманием кодера-декодера .
Как и первый кодер, первый декодер принимает в качестве входных данных позиционную информацию и внедрения выходной последовательности, а не кодировки. Преобразователь не должен использовать текущий или будущий выходной сигнал для прогнозирования выходного сигнала, поэтому выходная последовательность должна быть частично замаскирована, чтобы предотвратить обратный поток информации. Это позволяет создавать авторегрессионный текст. Для всех голов внимания внимание не может быть сосредоточено на следующих токенах. За последним декодером следует окончательное линейное преобразование и слой softmax для получения выходных вероятностей по словарю.
Все члены серии OpenAI GPT имеют архитектуру только для декодера.
В больших языковых моделях терминология несколько отличается от терминологии, использованной в оригинальной статье Transformer:
Здесь «авторегрессия» означает, что в головку внимания вставляется маска, чтобы обнулить все внимание от одного токена до всех следующих за ним токенов, как описано в разделе «Маскированное внимание».
Обычно языковые модели на основе Transformer делятся на два типа: причинные (или «авторегрессивные») и маскированные. Серия GPT предназначена только для причинно-следственных связей и декодера. BERT маскируется и используется только кодировщиком. Серия T5 представляет собой кодер-декодер с полным кодером и авторегрессионным декодером.
Оригинальный трансформатор использует функцию активации ReLU . Были разработаны и другие функции активации, такие как SwiGLU
Трансформаторы могут использовать другие методы позиционного кодирования, кроме синусоидального.
RoPE (вращательное позиционное встраивание) лучше всего объясняется при рассмотрении списка двумерных векторов  . Теперь выберите угол𝜃
. Теперь выберите угол𝜃 . Тогда кодировка RoPE
. Тогда кодировка RoPE

Эквивалентно, если мы запишем двумерные векторы как комплексные числаям"="Иксм(1)+яИксм(2) , то кодирование RoPE — это просто умножение на угол:
, то кодирование RoPE — это просто умножение на угол:

Для списка  -мерные векторы, кодер RoPE определяется последовательностью углов
-мерные векторы, кодер RoPE определяется последовательностью углов  . Затем к каждой паре координат применяется кодировка RoPE.
. Затем к каждой паре координат применяется кодировка RoPE.
Преимущество RoPE заключается в том, что скалярное произведение между двумя векторами зависит только от их относительного местоположения:

для любого целого числа .
ALiBi (Внимание с линейными смещениями) не является заменой позиционного энкодера оригинального трансформатора. Вместо этого это дополнительный позиционный энкодер, который напрямую подключается к механизму внимания. В частности, механизм внимания ALiBi

Здесь,с является действительным числом («скаляром»), и
является действительным числом («скаляром»), и  - матрица линейного смещения, определяемая формулой
- матрица линейного смещения, определяемая формулой

другими словами,  .
.
ALiBi позволяет выполнять предварительное обучение в коротких контекстных окнах, а затем выполнять точную настройку в более длинных контекстных окнах. Поскольку он напрямую подключается к механизму внимания, его можно комбинировать с любым позиционным энкодером, который подключается в «низ» всей сети (именно там находится синусоидальный энкодер на оригинальном трансформаторе, а также RoPE и многие другие, расположены).
Кодирование относительного положения похоже на ALiBi, но более общее:

где является матрицей Теплица , т. е.  в любое времяя−
в любое времяя−  .
.
FlashAttention — это алгоритм, который эффективно реализует механизм внимания преобразователя на графическом процессоре. Он выполняет умножение матриц в блоках , так что каждый блок помещается в кэш графического процессора, и за счет тщательного управления блоками минимизирует копирование данных между кэшами графического процессора (поскольку перемещение данных происходит медленно).
Улучшенная версия FlashAttention-2, была разработана для удовлетворения растущего спроса на языковые модели, способные обрабатывать контексты большей длины. Он предлагает улучшения в разделении работы и параллелизме, что позволяет ему достигать производительности до 230 терафлопс/с на графических процессорах A100 ( FP16 / BF16 ), что в 2 раза превышает скорость исходного FlashAttention.
Ключевые достижения в FlashAttention-2 включают сокращение количества FLOP, не относящихся к matmul, улучшенный параллелизм по измерению длины последовательности, лучшее разделение работы между деформациями графического процессора, а также добавленную поддержку размеров головки до 256, а также внимания к множественным запросам (MQA) и группировки. запрос внимания (GQA).
Тесты показали, что FlashAttention-2 работает до 2 раз быстрее, чем FlashAttention, и до 9 раз быстрее, чем стандартная реализация внимания в PyTorch. Будущие разработки включают оптимизацию для нового оборудования, такого как графические процессоры H100 , и новых типов данных, таких как FP8.
Многозапросное внимание изменяет механизм многоголового внимания. Хотя обычно
с вниманием к множественным запросам есть только одинВтК,ВтВ , таким образом:
, таким образом:

Это нейтрально влияет на качество модели и скорость обучения, но увеличивает скорость вывода.
Трансформаторы используются в больших языковых моделях для генерации авторегрессионных последовательностей: генерации потока текста по одному токену за раз. Однако в большинстве случаев декодирование языковых моделей ограничено памятью, а это означает, что у нас есть свободная вычислительная мощность. Спекулятивное декодирование [ использует эту резервную вычислительную мощность путем параллельного вычисления нескольких токенов. Подобно спекулятивному выполнению в процессорах, будущие токены вычисляются одновременно, предполагая значение предыдущих токенов, а затем отбрасываются, если оказывается, что предположение было неверным.
В частности, рассмотрим модель преобразователя, такую как GPT-3, с размером контекстного окна 512. Чтобы сгенерировать все контекстное окно авторегрессионно с жадным декодированием, его необходимо запустить 512 раз, каждый раз генерируя токен.  . Однако, если бы у нас было какое-то обоснованное предположение о значениях этих токенов, мы могли бы проверить их все параллельно, за один прогон модели, проверив, что каждый
. Однако, если бы у нас было какое-то обоснованное предположение о значениях этих токенов, мы могли бы проверить их все параллельно, за один прогон модели, проверив, что каждый  действительно является токеном с наибольшей логарифмической вероятностью в -ый вывод.
действительно является токеном с наибольшей логарифмической вероятностью в -ый вывод.
При спекулятивном декодировании меньшая модель или какая-либо другая простая эвристика используется для генерации нескольких спекулятивных токенов, которые впоследствии проверяются более крупной моделью. Например, предположим, что небольшая модель сгенерировала четыре спекулятивных токена:  . Эти токены проходят через более крупную модель, и только
. Эти токены проходят через более крупную модель, и только  и
и  принимаются. Тот же запуск большой модели уже сгенерировал новый токен.
принимаются. Тот же запуск большой модели уже сгенерировал новый токен.  заменить
заменить  , иИкс4~
, иИкс4~ полностью отбрасывается. Затем процесс повторяется (начиная с 4-го токена), пока не будут сгенерированы все токены.
полностью отбрасывается. Затем процесс повторяется (начиная с 4-го токена), пока не будут сгенерированы все токены.
Для нежадного декодирования применяются аналогичные идеи, за исключением того, что спекулятивные токены принимаются или отклоняются стохастически, таким образом, чтобы гарантировать, что окончательное распределение выходных данных будет таким же, как если бы спекулятивное декодирование не использовалось.
Обучение архитектуры на основе трансформатора может быть дорогостоящим, особенно для длинных входных сигналов. Альтернативные архитектуры включают Reformer (который снижает вычислительную нагрузку от  к
к  ) или такие модели, как ETC/BigBird (которые могут свести его к
) или такие модели, как ETC/BigBird (которые могут свести его к  ) где длина последовательности. Это делается с использованием локально-зависимого хеширования и обратимых слоев.
) где длина последовательности. Это делается с использованием локально-зависимого хеширования и обратимых слоев.
Обычные преобразователи требуют размера памяти, квадратичного по размеру контекстного окна. Трансформаторы без внимания сводят эту зависимость к линейной, сохраняя при этом преимущества преобразователя за счет привязки ключа к значению.
Long Range Arena (2020) — стандартный тест для сравнения поведения архитектур трансформаторов при длинных входных сигналах.
Внимание к случайным функциям (2021) использует случайные функции Фурье :

гд  являются независимыми выборками из нормального распределения
являются независимыми выборками из нормального распределения  . Такой выбор параметров удовлетворяет
. Такой выбор параметров удовлетворяет  , или
, или

Следовательно, однонаправленное внимание с одним запросом можно записать как

где  . Аналогично для множественных запросов и многонаправленного внимания.
. Аналогично для множественных запросов и многонаправленного внимания.
Это приближение можно вычислить за линейное время, поскольку мы можем вычислить матрицу  сначала, затем умножьте его на запрос. По сути, нам удалось получить более точную версию
сначала, затем умножьте его на запрос. По сути, нам удалось получить более точную версию

Performer (2022) использует то же случайное внимание к функциям, но сначала независимо выбираются из нормального распределения , затем они обрабатываются по Граму-Шмидту .
Трансформеры также можно использовать/адаптировать для модальностей (ввода или вывода), помимо текста, обычно путем поиска способа «токенизации» модальности.
Трансформаторы зрения адаптируют преобразователь к компьютерному зрению, разбивая входные изображения на серии патчей, превращая их в векторы и обрабатывая их как токены в стандартном преобразователе.
Conformer и более поздний Whisper следуют той же схеме распознавания речи , сначала превращая речевой сигнал в спектрограмму , которая затем обрабатывается как изображение, т.е. разбивается на серию фрагментов, превращается в векторы и обрабатывается как жетоны в стандартном трансформере.
Воспринимающие , Эндрю Джегл и др. (2021) могут учиться на больших объемах разнородных данных.
Что касается вывода изображений , Пиблс и др. представили диффузионный преобразователь (DiT), который облегчает использование архитектуры преобразователя для создания изображений на основе диффузии . Кроме того, Google выпустила генератор изображений, ориентированный на трансформатор, под названием «Muse», основанный на технологии параллельного декодирования и генеративного преобразователя в масках. (Трансформеры играли менее центральную роль в предшествующих технологиях создания изображений, хотя и по-прежнему значительную. )
Трансформатор добился больших успехов в обработке естественного языка (НЛП), например, в задачах машинного перевода и прогнозирования временных рядов . Многие большие языковые модели , такие как GPT-2 , GPT-3 , GPT-4 , Claude , BERT , XLNet, RoBERTa и ChatGPT, демонстрируют способность преобразователей выполнять широкий спектр таких задач, связанных с НЛП, и имеют потенциал для поиска реальные приложения. Они могут включать в себя:
Помимо приложений НЛП, он также добился успеха в других областях, таких как компьютерное зрение или приложения для сворачивания белков (такие как AlphaFold ).
В качестве наглядного примера можно привести Ithaca — преобразователь только для энкодера с тремя выходными головками. В качестве входных данных принимается древнегреческая надпись в виде последовательности символов, но с неразборчивыми символами, замененными на «-». Его три выходные головки соответственно выводят распределения вероятностей по греческим символам, местоположению надписи и дате надписи.
Исследование, описанное в статье про transformer, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое transformer, трансформер и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Нейронные сети

Комментарии