Лекция
Это окончание невероятной информации про сайт.
...
содержимое запроса выполнено.
Сервер отвечает кодом ответа, обозначающим статус запроса, и отвечает ответом в форме:
200 ОК [заголовки ответов]
За ним следует один символ новой строки, а затем отправляется полезная нагрузка HTML-содержимого www.google.com. Затем сервер может либо закрыть соединение, либо, если заголовки, отправленные клиентом, запросили его, оставить соединение открытым для повторного использования для дальнейших запросов.
Если заголовки HTTP, отправленные веб-браузером, включали достаточно информации для веб-сервер а, чтобы определить, не изменилась ли версия файла, кэшированного веб-браузером, с момента последнего извлечения (т. Е. Если веб-браузер включил ETagзаголовок), он может вместо этого ответьте запросом в форме:
304 Не изменено [заголовки ответов]
и никакой полезной нагрузки, и вместо этого веб-браузер извлекает HTML из своего кеша.
После анализа HTML веб-браузер (и сервер) повторяет этот процесс для каждого ресурса (изображения, CSS, favicon.ico и т. Д.), На который ссылается HTML-страница, за исключением того, что вместо GET / HTTP/1.1запроса будет GET /$(URL relative to www.google.com) HTTP/1.1.
Если HTML ссылается на ресурс в другом домене www.google.com, веб-браузер возвращается к шагам, связанным с разрешением другого домена, и выполняет все шаги до этого момента для этого домена. В Hostзаголовке запроса будет указано соответствующее имя сервера, а не google.com.
Сервер HTTPD (HTTP Daemon) - это сервер, обрабатывающий запросы / ответы на стороне сервера. Наиболее распространенными серверами HTTPD являются Apache или nginx для Linux и IIS для Windows.
Сервер разбивает запрос на следующие параметры:

После того, как сервер предоставит браузеру ресурсы (HTML, CSS, JS, изображения и т. Д.), Он проходит следующий процесс:
Функциональность браузера заключается в том, чтобы представить выбранный вами веб-ресурс, запросив его с сервера и отобразив в окне браузера. Ресурс обычно представляет собой HTML-документ, но также может быть PDF-файлом, изображением или каким-либо другим типом содержимого. Расположение ресурса указывается пользователем с помощью URI (унифицированного идентификатора ресурса).
То, как браузер интерпретирует и отображает файлы HTML, указано в спецификациях HTML и CSS. Эти спецификации поддерживаются организацией W3C (Консорциум всемирной паутины), которая является организацией по стандартизации Интернета.
Пользовательские интерфейсы браузера имеют много общего друг с другом. Среди общих элементов пользовательского интерфейса:
Структура верхнего уровня браузера
Компоненты браузеров:
Механизм визуализации начинает получать содержимое запрошенного документа с сетевого уровня. Обычно это делается кусками по 8 КБ.
Основная задача парсера HTML - преобразовать разметку HTML в дерево синтаксического анализа.
Выходное дерево («дерево синтаксического анализа») представляет собой дерево элементов DOM и узлов атрибутов. DOM - это сокращение от Document Object Model. Это объектное представление HTML-документа и интерфейс элементов HTML для внешнего мира, например JavaScript. Корнем дерева является объект «Документ». До каких-либо манипуляций с помощью скриптов DOM имеет почти однозначное отношение к разметке.
Алгоритм разбора
HTML нельзя проанализировать с помощью обычных нисходящих или восходящих парсеров.
Причины:
Невозможно использовать обычные методы синтаксического анализа, браузер использует специальный синтаксический анализатор для анализа HTML. Алгоритм парсинга подробно описан в спецификации HTML5.
Алгоритм состоит из двух этапов: токенизации и построения дерева.
Действия после завершения разбора
Браузер начинает получать внешние ресурсы, связанные со страницей (CSS, изображения, файлы JavaScript и т. Д.).
На этом этапе браузер помечает документ как интерактивный и начинает анализировать сценарии, находящиеся в «отложенном» режиме: те, которые должны быть выполнены после анализа документа. Состояние документа устанавливается на «завершено», и запускается событие «загрузка».
Обратите внимание, что на странице HTML никогда не бывает ошибки «Недопустимый синтаксис». Браузеры исправляют любой недопустимый контент и продолжают.
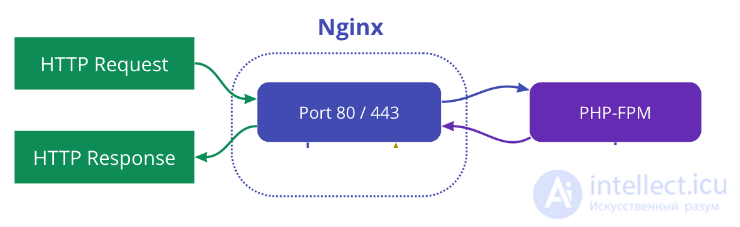
Если на сервер Nginx пришел HTTP-запрос , то Nginx станет передавать данный запрос на выполнение PHP-FPM, Nginx вернет результат полученный из PHP-FPM.
Выполнение PHP - это четырехэтапный процесс:
На следующем изображении показано визуальное представление основного процесса выполнения PHP.
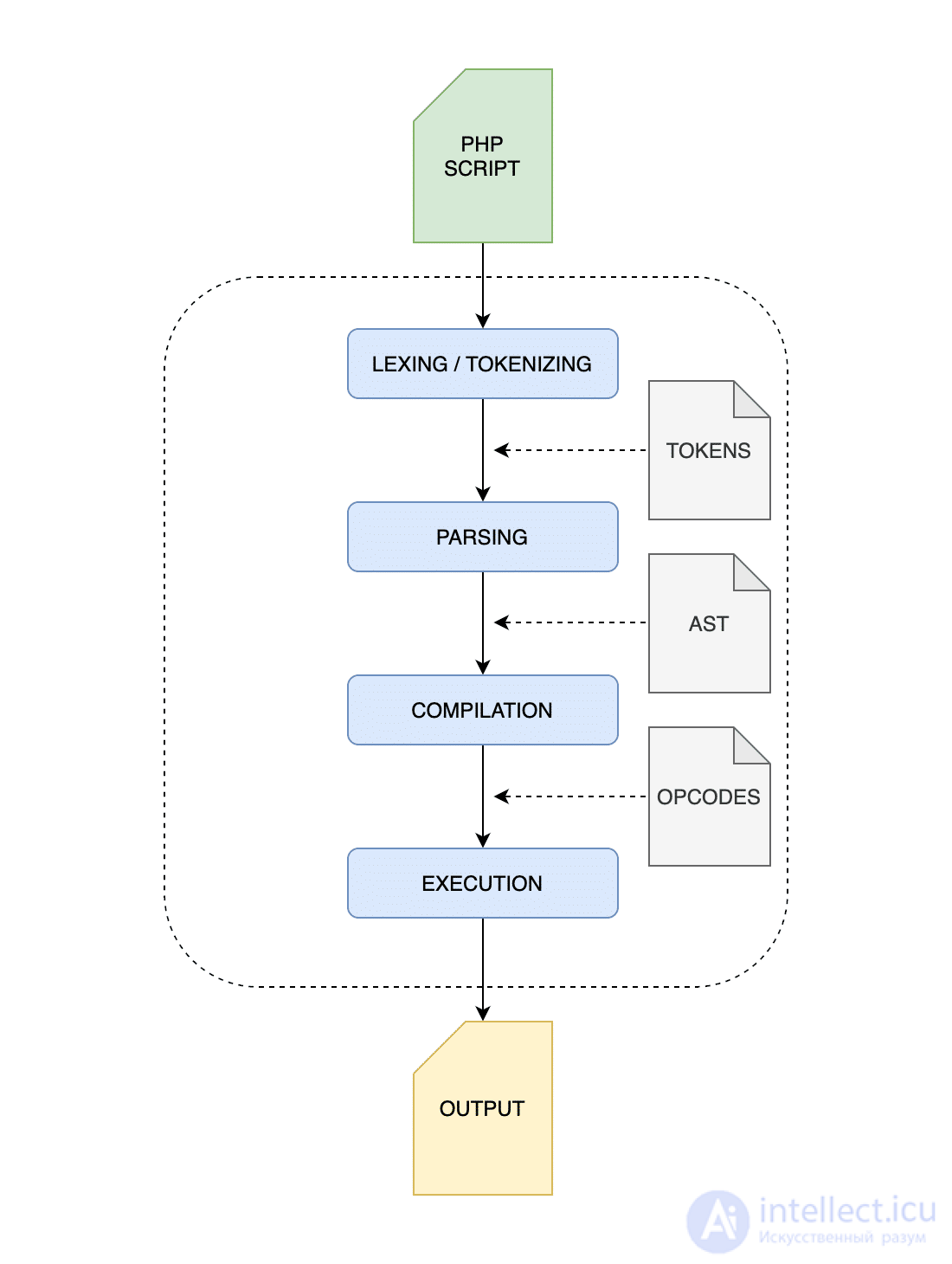
Базовый процесс выполнения PHP
Итак, как OPcache делает PHP быстрее? А что изменится в процессе выполнения с JIT?
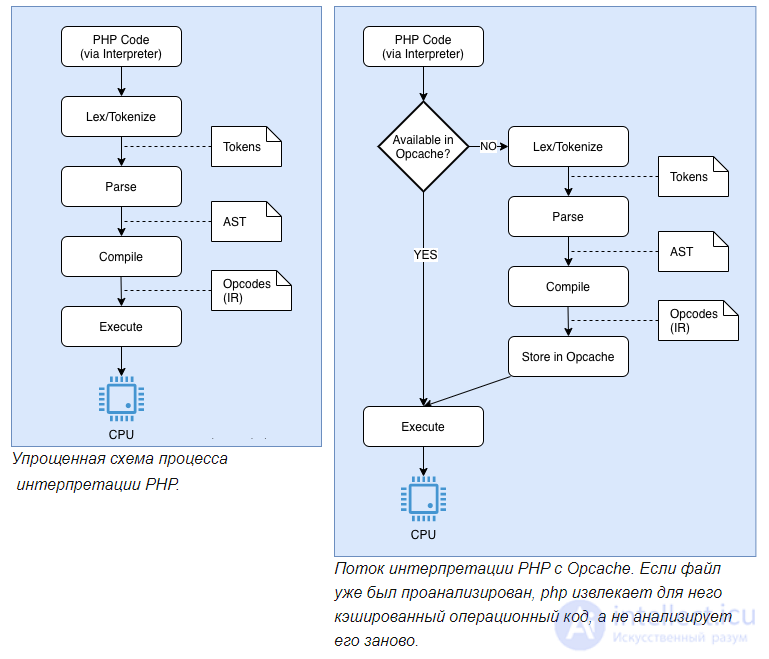
PHP - это интерпретируемый язык. Это означает, что при запуске сценария PHP интерпретатор анализирует, компилирует и выполняет код снова и снова при каждом запросе. Это может привести к потере ресурсов ЦП и дополнительному времени.
Здесь на помощь приходит расширение OPcache :
«OPcache повышает производительность PHP, сохраняя байт-код предварительно скомпилированного сценария в общей памяти, тем самым устраняя необходимость для PHP загружать и анализировать сценарии при каждом запросе».
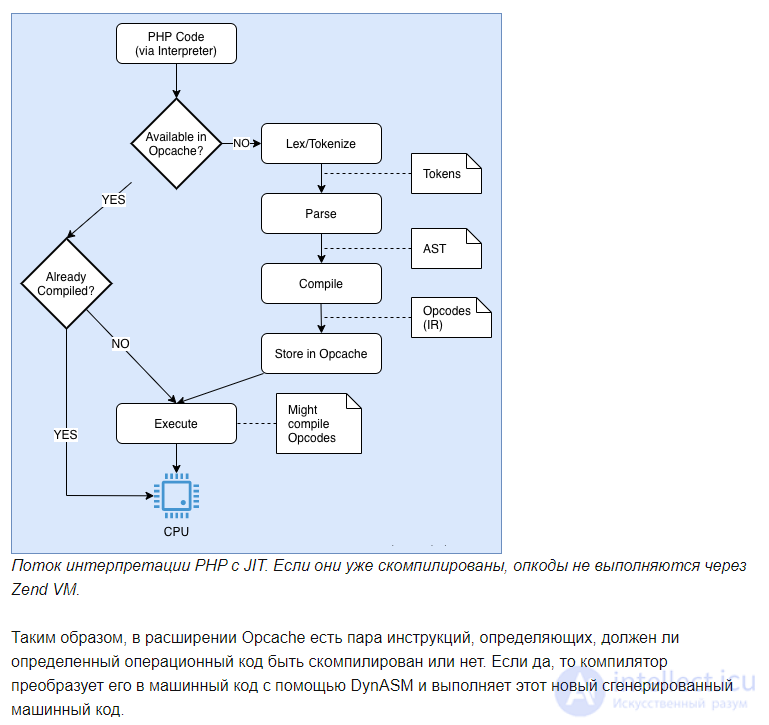
При включенном OPcache интерпретатор PHP проходит через упомянутый выше четырехэтапный процесс только при первом запуске скрипта. Поскольку байт-коды PHP хранятся в общей памяти, они сразу же доступны как низкоуровневое промежуточное представление и могут быть сразу выполнены на виртуальной машине Zend.
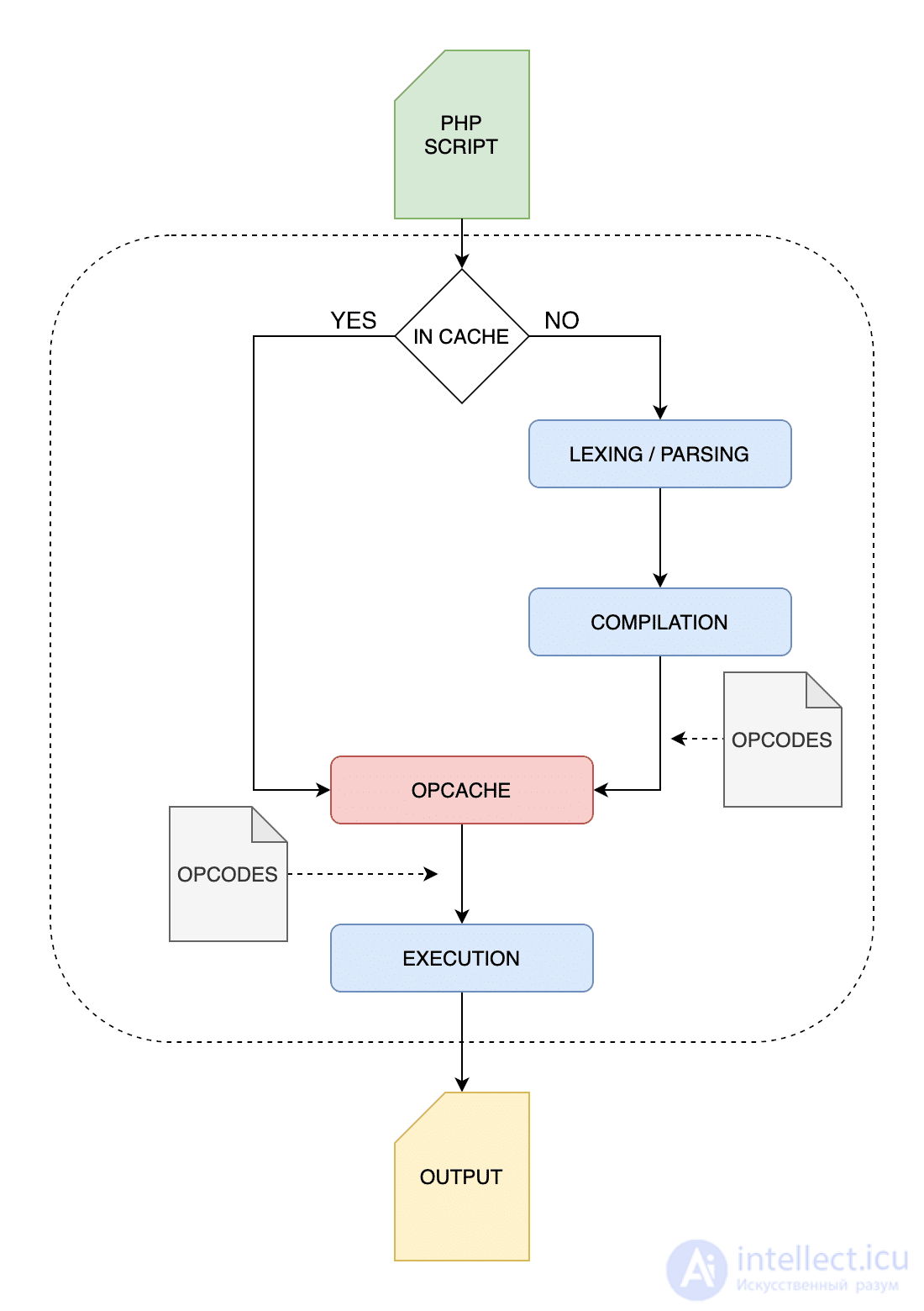
Процесс выполнения PHP с включенным OPcache
Начиная с PHP 5.5, расширение Zend OPcache доступно по умолчанию, и вы можете проверить, правильно ли оно настроено, просто вызвав phpinfo() из скрипта на вашем сервере или проверив файл php.ini
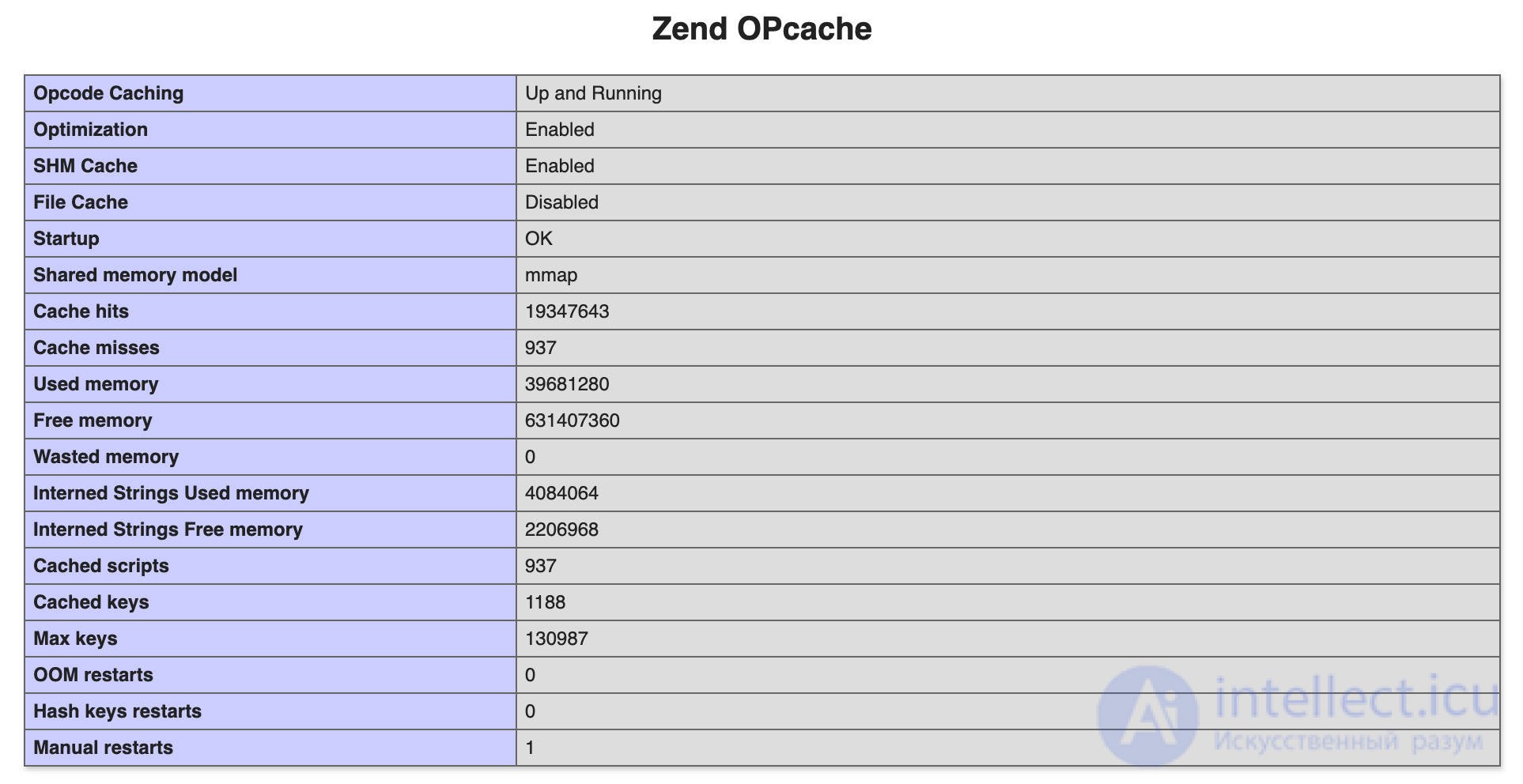
Раздел Zend OPcache на странице phpinfo
OPcache был недавно улучшен за счет реализации предварительной загрузки , новой функции OPcache, добавленной в PHP 7.4 . Предварительная загрузка предоставляет способ сохранить указанный набор сценариев в памяти OPcache « до запуска любого кода приложения. Тем не менее, это не приносит ощутимого улучшения производительности для типичных веб-приложений.
Вы можете узнать больше о предварительной загрузке во введении в PHP 7.4 .
Благодаря JIT PHP делает шаг вперед.
Даже если коды операций представляют собой низкоуровневое промежуточное представление, они все равно должны быть скомпилированы в машинный код. JIT «не вводит дополнительную форму IR (промежуточное представление)», но использует DynASM (динамический ассемблер для механизмов генерации кода) для генерации собственного кода непосредственно из байт-кода PHP.
Короче говоря, JIT переводит горячие части промежуточного кода в машинный код . В обход компиляции можно было бы значительно улучшить производительность и использование памяти.

Структура и логика работы элементарного веб-приложения (написанного на PHP, Java (Servlet) и C# (MVC)) с использованием шаблонизации

1. Какова основная функция веб-браузера?
2. Какой элемент используется для отправки запросов к серверу?
3. Какой процесс происходит при вводе URL в адресной строке браузера?
4. Что происходит после отправки HTTP-запроса на сервер?
5. Какой протокол обычно используется для передачи данных между браузером и сервером?
6. Какой ответ сервер отправляет браузеру после успешной обработки запроса?
7. Какую информацию содержит HTTP-заголовок?
8. Какой элемент веб-страницы отвечает за структуру и содержание?
9. Какой тип запроса используется для отправки данных на сервер?
10. Что такое кэширование в контексте браузера?
11. Какой компонент браузера отвечает за выполнение JavaScript-кода?
12. Какой из следующих элементов может быть частью URL?
13. Какой заголовок HTTP используется для определения типа содержимого?
14. Что такое статус код 404?
15. Какой метод используется для получения данных с сервера?
16. Что происходит, когда сервер не может обработать запрос?
17. Какой из следующих элементов определяет, как браузер должен отображать страницу?
18. Какой компонент отвечает за безопасность при передаче данных?
19. Какой элемент URL указывает на конкретный ресурс на сервере?
20. Какой из следующих процессов происходит после получения ответа от сервера?
А как ты думаешь, при улучшении сайт, будет лучше нам? Надеюсь, что теперь ты понял что такое сайт, веб-сервер, event loop, dns, работа сайта, как работает сайт и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Основы интернет и веб технологий
Часть 1 1.6. Работа сайта, браузера и сервера последовательность взаимодействия и назначение элементов
Часть 2 Что происходит на сервере? - 1.6. Работа сайта, браузера и
Комментарии
Оставить комментарий
Основы интернет и веб технологий
Термины: Основы интернет и веб технологий