Лекция
Привет, Вы узнаете о том , что такое генерация с дополненным поиском, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое генерация с дополненным поиском, rag , настоятельно рекомендую прочитать все из категории Подходы и направления создания Искусственного интеллекта.
генерация с дополненным поиском ( RAG ) — это метод, позволяющий крупным языковым моделям (LLM) извлекать и включать новую информацию. С помощью RAG LLM не отвечают на запросы пользователей, пока не обратятся к указанному набору документов. Эти документы дополняют информацию из уже имеющихся обучающих данных LLM . Это позволяет LLM использовать специфичную для предметной области и/или обновленную информацию, которая отсутствует в обучающих данных. Например, это помогает чат-ботам на основе LLM получать доступ к внутренним данным компании или генерировать ответы на основе авторитетных источников.
RAG улучшает большие языковые модели (LLM), включая поиск информации перед генерацией ответов. В отличие от традиционных LLM, которые полагаются на статические данные обучения, RAG извлекает соответствующий текст из баз данных, загруженных документов или веб-источников. По данным Ars Technica , «RAG — это способ улучшить производительность LLM, по сути, путем объединения процесса LLM с веб-поиском или другим процессом поиска документов, чтобы помочь LLM придерживаться фактов». Этот метод помогает уменьшить галлюцинации ИИ , из-за которых чат-боты описывают несуществующие политики или рекомендуют несуществующие судебные дела юристам, ищущим цитаты для подтверждения своих аргументов.
RAG также снижает необходимость в переобучении LLM на основе новых данных, что позволяет экономить вычислительные и финансовые затраты. Помимо повышения эффективности, RAG также позволяет LLM включать источники в свои ответы, чтобы пользователи могли проверять цитируемые источники. Это обеспечивает большую прозрачность, поскольку пользователи могут перепроверять полученный контент для обеспечения точности и релевантности.
Термин RAG был впервые введен в исследовательской статье 2020 года из Meta .
LLM могут предоставлять неверную информацию. Например, когда Google впервые продемонстрировал свой инструмент LLM « Google Bard », LLM предоставил неверную информацию о космическом телескопе Джеймса Уэбба . Эта ошибка привела к падению стоимости акций компании на 100 миллиардов долларов . RAG используется для предотвращения этих ошибок, но не решает всех проблем. Например, LLM могут генерировать дезинформацию, даже используя фактически верные источники, если они неверно истолковывают контекст. MIT Technology Review приводит пример ответа, сгенерированного ИИ: «В Соединенных Штатах был один президент-мусульманин, Барак Хусейн Обама». Модель извлекла это из академической книги с риторическим названием « Барак Хусейн Обама: первый президент-мусульманин Америки?». LLM не «знал» и не «понимал» контекст заголовка, что привело к ложному утверждению
LLM с RAG запрограммированы на приоритизацию новой информации. Этот метод называется «заполнением подсказок». Без заполнения подсказок входные данные LLM генерируются пользователем; при использовании заполнения подсказок к этим данным добавляется дополнительный релевантный контекст, направляющий реакцию модели. Такой подход предоставляет LLM ключевую информацию с самого начала подсказки, побуждая его отдавать приоритет предоставленным данным перед уже имеющимися знаниями, полученными в ходе обучения.
Генерация с дополненным поиском (RAG) улучшает большие языковые модели (LLM) за счет включения механизма информационного поиска , который позволяет моделям получать доступ к дополнительным данным за пределами их исходного обучающего набора и использовать их. AWS утверждает: «RAG позволяет LLM извлекать релевантную информацию из внешних источников данных для генерации более точных и контекстно релевантных ответов» («индексация»). Такой подход снижает зависимость от статических наборов данных, которые могут быстро устареть. Когда пользователь отправляет запрос, RAG использует средство извлечения документов для поиска релевантного контента из доступных источников, прежде чем включить извлеченную информацию в ответ модели («извлечение»). Ars Technica отмечает, что «когда становится доступной новая информация, вместо того, чтобы переобучать модель, все, что требуется, — это дополнить внешнюю базу знаний модели обновленной информацией» («дополнение»). Благодаря динамической интеграции соответствующих данных RAG позволяет магистрам права генерировать более информированные и контекстно обоснованные ответы («генерация»). IBM утверждает, что «на этапе генерации магистра права использует дополненную подсказку и внутреннее представление своих обучающих данных для синтеза интересного ответа, адаптированного для пользователя в данный момент».
Как правило, данные, на которые необходимо ссылаться, преобразуются в LLM- внедрения – числовые представления в форме большого векторного пространства. RAG можно использовать для неструктурированных (обычно текстовых), полуструктурированных или структурированных данных (например, графов знаний ). Эти вложения затем сохраняются в векторной базе данных для обеспечения возможности поиска документов
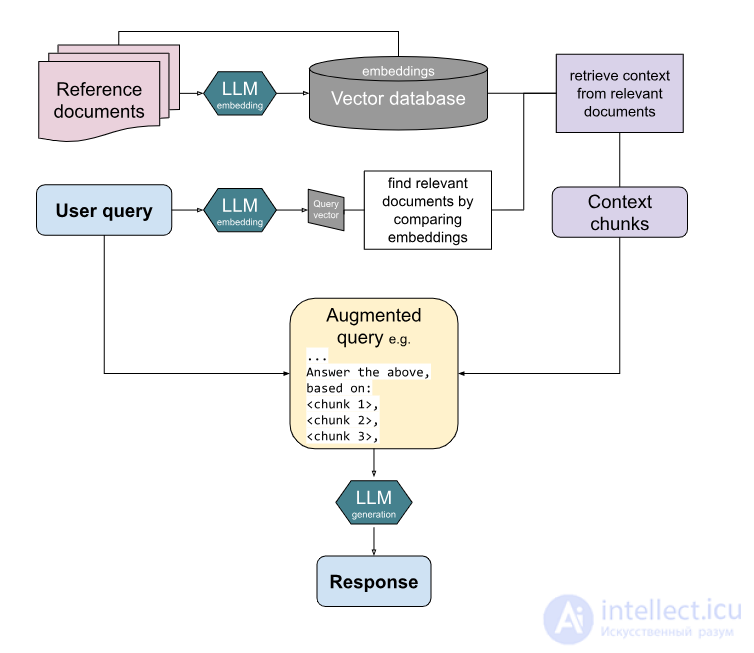
Обзор процесса RAG, объединяющего внешние документы и вводимые пользователем данные в приглашение LLM для получения адаптированного результата
При получении запроса пользователя сначала вызывается средство извлечения документов, чтобы выбрать наиболее релевантные документы, которые будут использованы для дополнения запроса. Об этом говорит сайт https://intellect.icu . Это сравнение можно выполнить с помощью различных методов, которые частично зависят от типа используемого индексирования.
Модель передает эту соответствующую извлеченную информацию в LLM посредством оперативного проектирования исходного запроса пользователя. Более новые реализации (по состоянию на 2023 год ) также могут включать специальные модули расширения с такими возможностями, как расширение запросов на несколько доменов и использование памяти и самосовершенствования для обучения на основе предыдущих извлечений.
Наконец, LLM может генерировать выходные данные на основе как запроса, так и извлеченных документов. Некоторые модели включают дополнительные шаги для улучшения выходных данных, такие как повторное ранжирование извлеченной информации, выбор контекста и тонкая настройка .
Усовершенствования базового процесса, описанного выше, могут применяться на разных этапах потока RAG.
Эти методы ориентированы на кодирование текста в виде плотных или разреженных векторов. Разреженные векторы , кодирующие идентичность слова, обычно имеют длину, равную словарному запасу , и содержат в основном нули. Плотные векторы , кодирующие значение, более компактны и содержат меньше нулей. Различные усовершенствования могут улучшить способ вычисления сходства в векторных хранилищах (базах данных).
Эти методы направлены на повышение качества поиска документов в векторных базах данных:

Перепроектировав языковую модель с учетом ретривера, сеть в 25 раз меньшего размера может достичь уровня сложности, сопоставимого с гораздо более крупными аналогами. Поскольку обучение происходит с нуля, этот метод (Retro) влечет за собой высокие затраты на тренировочные прогоны, которых избегала исходная схема RAG. Гипотеза заключается в том, что, предоставляя знания о предметной области во время обучения, Retro меньше фокусируется на предметной области и может использовать свои меньшие весовые ресурсы только для семантики языка. Перепроектированная языковая модель представлена здесь.
Было сообщено, что Retro невоспроизводим, поэтому были внесены изменения, чтобы сделать его таковым. Более воспроизводимая версия называется Retro++ и включает контекстный RAG.
Разделение данных на фрагменты предполагает использование различных стратегий для разбиения данных на векторы, чтобы извлекатель мог найти в них детали.
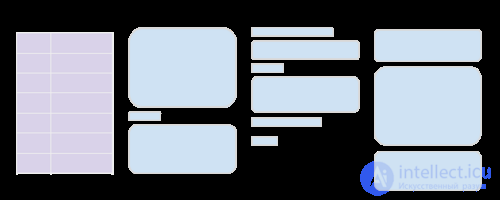
Три типа стратегий фрагментации:
Вместо использования документов в качестве источника для векторизации и извлечения данных можно использовать графы знаний . Можно начать с набора документов, книг или других текстовых массивов и преобразовать их в граф знаний, используя один из множества методов, включая языковые модели. После создания графа знаний подграфы можно векторизовать, сохранить в векторной базе данных и использовать для извлечения данных, как в обычном RAG. Преимущество заключается в том, что графы имеют более узнаваемую структуру, чем строки текста, и эта структура может помочь извлечь больше релевантных фактов для генерации. Иногда этот подход называют GraphRAG.
Иногда при поиске по векторным базам данных могут отсутствовать ключевые факты, необходимые для ответа на вопрос пользователя. Один из способов решения этой проблемы — выполнить традиционный текстовый поиск, добавить полученные результаты к фрагментам текста, связанным с полученными векторами, и передать полученный гибридный текст в языковую модель для генерации.
Системы RAG обычно оцениваются с помощью бенчмарков, разработанных для проверки извлекаемости , точности извлечения и качества генерации. Среди популярных наборов данных — BEIR, набор задач поиска информации в различных предметных областях, а также Natural Questions или Google QA для проверки качества данных в открытых областях.
RAG не является полным решением проблемы галлюцинаций у лиц с ограниченной жизнедеятельностью. Согласно Ars Technica , «это не прямое решение, поскольку в ответ на воздействие LLM все еще могут возникать галлюцинации, связанные с исходным материалом».
Хотя RAG повышает точность больших языковых моделей (LLM), он не устраняет всех проблем. Одно из ограничений заключается в том, что RAG, хотя и снижает потребность в частом переобучении модели, не устраняет ее полностью. Кроме того, LLM могут испытывать трудности с распознаванием случаев, когда им не хватает информации для предоставления надежного ответа. Без специального обучения модели могут генерировать ответы, даже если они должны указывать на неопределенность. По данным IBM , эта проблема может возникнуть, когда модель не способна оценить собственные ограничения знаний.
Системы RAG могут извлекать фактически верные, но вводящие в заблуждение источники, что приводит к ошибкам в интерпретации. В некоторых случаях LLM может извлекать утверждения из источника, не учитывая его контекст, что приводит к неверному выводу. Кроме того, при столкновении с противоречивой информацией модели RAG могут испытывать трудности в определении того, какой источник является точным. Наихудшим результатом этого ограничения является то, что модель может объединять данные из нескольких источников, выдавая ответы, которые объединяют устаревшую и актуальную информацию вводящим в заблуждение образом. Согласно MIT Technology Review , эти проблемы возникают из-за того, что системы RAG могут неправильно интерпретировать извлекаемые ими данные.
Поскольку системы RAG являются расширением традиционных поисковых систем , области их применения пересекаются. Системы RAG применяются в таких областях, как обслуживание клиентов , анализ медицинской информации , юридические исследования , образование , научные исследования, финансовый анализ , оценка данных журналов и все другие приложения, где поиск информации имеет значение.
Исследование, описанное в статье про генерация с дополненным поиском, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое генерация с дополненным поиском, rag и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Подходы и направления создания Искусственного интеллекта
Комментарии
Оставить комментарий
Подходы и направления создания Искусственного интеллекта
Термины: Подходы и направления создания Искусственного интеллекта