Лекция
Привет, Вы узнаете о том , что такое защита сайта от сканирования, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое защита сайта от сканирования, защита от интенсивных запросов, много запросов, защита от парсинга , настоятельно рекомендую прочитать все из категории Информационная безопасность, Вредоносное ПО и защита информации.
В этой статье я хочу рассмотреть несколько известных методов защиты контента сайта от автоматического парсинга. Kаждый из них обладает своими достоинствами и недостатками, поэтому выбирать нужно исходя из конкретной ситуации. Кроме этого, ни один из этих методов не является панацеей и практически для каждого есть свои пути обхода, которые я тоже упомяну.
Есть разные техники обнаружения веб-ботов в сетевом трафике, начиная от лимитирования частоты запросов к узлу, черных списков IP-адресов, анализа значения HTTP-заголовка User-Agent, снятия отпечатков устройства — и заканчивая внедрением CAPTCHA, и поведенческим анализом сетевой активности с помощью машинного обучения.
Что такое парсинг ? Парсингом сайта называется комплекс мер по извлечению данных с сайта. Впоследствии скопированный контент может использоваться для разных целей, например для продвижения иных сайтов или аналитики.
Для каких целей применяется парсинг сайтов?
Парсинг сайтов применяется для целей разного характера. Например:
Копирование статей для размещения на конкурентных сайтах;
Еще роботы используются для создания трудностей в аналитике при обработке данных. К примеру, боты могут сканировать сайт, добавлять товары в корзины и так далее. В результате аналитика данных сильно затрудняется, системы подсказок работают не верно, а в базе накапливаются ненужные данные. В большинстве стран никаких законов в отношении парсинга нет. Но на разных территориях встречаются разные законы в отношении копирования контента. Например, если сайт принадлежит компании, которая зарегистрирована как юридическое лицо в штатах, то есть ряд законов, используя которые можно защититься от парсинга контента.
Например:
Самым простым и распространенным способом определения попыток парсинга сайта является анализ частоты и периодичности запросов к серверу. Если с какого-то IP адреса запросы идут слишком часто или их слишком много, то этот адрес блокируется и чтобы его разблокировать часто предлагается ввести каптчу.
Самое главное в этом способе защиты — найти границу между естественной частотой и количеством запросов и попытками скрейпинга чтобы не заблокировать ни в чем не винных пользователей. Обычно это определяется посредством анализа поведения нормальных пользователей сайта.
Примером использования этого метода может служить Google, который контроллирует количество запросов с определенного адреса и выдает соответствующее предупреждение с блокировкой IP адреса и предложением ввести каптчу.
Есть сервисы (вроде distilnetworks.com), которые позволяют автоматизировать процесс отслеживания подозрительной активности на вашем сайте и даже сами включают проверку пользователя с помощью каптчи.
Обход этой защиты осуществляется посредством использования нескольких прокси-серверов, скрывающих реальный IP-адрес парсера. Например сервисы типа BestProxyAndVPN предоставляют недорогие прокси, а сервис SwitchProxy хоть и дороже, но специально предназначен для автоматических парсеров и позволяет выдержать большие нагрузки.
В этом способе защиты доступ к данным осуществляется только авторизованным пользователям. Это позволяет легче контролировать поведение пользователей и блокировать подозрительные аккаунты вне зависимости от того, с какого IP адреса работает клиент.
Примером может служить Facebook, активно контролирующий действия пользователей и блокирующий подозрительных.
Эта защита обходится путем создания (в том числе автоматического) множества учетных записей (есть даже сервисы, которые торгуют готовыми учетными записями для известных социальных сетей, например buyaccs.com и bulkaccounts.com). Cущественным усложнением автоматического создания учетных записей может являться необходимость верификации аккаунта посредством телефона с проверкой его уникальности (так называемые, PVA -Phone Verified Account). Но, в принципе, это тоже обходится путем покупки множества одноразовых SIM-карт.
Это тоже распространенный метод защиты данных о парсинга. Здесь пользователю для доступа к данным сайта предлагается ввести капчу (CAPTCHA). Существенным недостатком этого способа можно считать неудобство пользователя в необходимости ввода капчи. Поэтому этот метод лучше всего применим в системах, где доступ к данным осуществляется отдельными запросами и не очень не часто.
Примером использования каптчи для защиты от автоматического создания запросов могут служить сервисы проверки позиции сайта в поисковой выдаче (например http://smallseotools.com/keyword-position/).
Обходится каптча посредством программ и сервисов по ее распознаванию. Они делятся на две основные категории: автоматическое распознавание без участия человека (OCR, например программа GSA Captcha Breaker) и распознавания с помощью человека (когда где-то в Индии сидят люди и в режиме онлайн обрабатывают запросы на распознание картинок, напримером может служить сервис Bypass CAPTCHA). Человеческое распознание обычно более эфективно, но оплата в данном случае происходит за каждую каптчу, а не один раз, как при покупке программы.
Здесь в запросе к серверу браузер отсылает специальный код (или несколько кодов), которые сформированы сложной логикой написанной на JavsScript. При этом, часто код этой логики обфусцирован и размещен в одном или нескольких подгружаемых JavaScript-файлах.
Типичным примером использования данного метода защиты от парсинга является Facebook.
Обходится это посредством использования для парсинга реальных браузеров (например, с помощью библиотек Selenium или Mechanize). Но это дает данному методу дополнителое преимущество: исполняя JavaScript парсер будет проявлять себя в аналитике посещаемости сайта (например Google Analytics), что позволит вебмастеру сразу заметить неладное.
Один из эффективных способов защиты от автоматического парсинга — это частое изменение структуры страницы. Это может касаться не только изменение названий идентификаторов и классов, но даже и иерархии элементов. Это сильно усложняет написание парсера, но с другой стороны усложняет и код самой системы.
С другой стороны, эти изменения могут делаться в ручном режиме где-то раз в месяц (или несколько месяцев). Это тоже существенно испортит жизнь парсерам.
Чтобы обойти такую защиту требуется создание более гибкого и «умного» парсера или же (если изменения делаются не часто) просто ручное исправление парсера, когда эти изменения произошли.
Это позволяет сделать парсинг большого количества данных очень медленным и поэтому нецелесообразным. При этом, ограничения неоходимо выбирать исходя из нужд типичного пользователя, что бы не снизить общее удобство пользования сайтом.
Обходится это посредством доступа к сайту с разных IP адресов или учетных записей (симуляция многих пользователей).
Данный способ защиты контента позволяет усложнить автоматический сбор данных, при этом сохранив визуальный доступ к ним со стороны обычного пользователя. Часто на картинки заменяются адреса электронной почты и телефоны, но некоторые сайты умудряются заменять картинками даже случайные буквы в тексте. Хотя ничто не мешает полностью выводить содержимое сайта в виде графики (будь то Flash или HTML 5), однако при этом может существенно пострадать его индексируемость поисковиками.
Минус этого способа не только в том, что не весь контент будт индексироваться поисковиками, но и в том, что исключается возможность пользователю скопировать данные в буфер обмена.
Обходится такая защита сложно, скорее всего нужно применять автоматическое или ручное распознавание картинок, как и в случае капчи.
Хаотичные интенсивные запросы сильно нагружают сервера и транспортные каналы, существенно замедляя работу сайта. С помощью сканирования злоумышленники копируют содержимое сайтов и выявляют слабые стороны в их защите, нанося при этом значительный ущерб. Кроме того, запросы к сайту, производящиеся в процессе сканирования, также отрицательно влияют на производительность. Чаще всего проблема медленной работы сайтов касается крупных порталов с высокой посещаемостью. Но она может коснуться и небольших сайтов, так как даже при малой посещаемости сайт может подвергаться высокой нагрузке. Высокая нагрузка создается различными роботами, постоянно сканирующими сайты. При этом работа сайта может сильно замедлиться, или он вообще может оказаться недоступным.
Сканирование сайта производится программами, сторонними сайтами или вручную. При этом создается большое количество запросов в короткий промежуток времени. Сканирование сайта чаще всего используют для поиска в нем уязвимостей или копирования содержимого сайта.
Достаточно эффективной мерой защиты сайта от сканирования будет разграничение прав доступа к ресурсам сайта. Информацию о структуре сайта поможет скрыть модуль apache mod_rewriteизменяющий ссылки. А сделать неэффективным сканирование ссылок и, одновременно, снизить нагрузку поможет установка временной задержки между частыми запросами исходящими от одного пользователя. Для поддержания эффективной защиты от сканирования и хаотичных интенсивных запросов необходим регулярный аудит вэб-ресурсов.
Хаотичные интенсивные запросы – это случайные или злонамеренные многочисленные запросы в короткий промежуток времени на страницы сайта со стороны пользователей или роботов. К примеру случайных интенсивных запросов относится частое обновление страницы. К злонамеренным многочисленным запросам относится спам на страницы сайта со стороны пользователей или DoS атаки. К хаотичным интенсивным запросам так же относится способ подбора паролей методом перебора. Подобрать пароль можно как вручную, так и при помощи специальных программ. Вручную пароль подбирается лишь в тех случаях, когда известны его возможные варианты. В других случаях используются специальные программы, осуществляющие автоматический подбор пары логина и пароля, т.е. программы для брутфорса.
К эффективным методам защиты сайта от хаотичных интенсивных запросов относятся: установка временной задержки между запросами в определенный промежуток времени, создание черного и белого списков, установка для поисковых систем временной задержки между запросами страниц сайта в файле robots.txt и установка периода обновления страниц в файле sitemap.xml.
Мной был реализован один из методов по защите сайта от сканирования и хаотичных интенсивных запросов, который заключается в подсчете количества запросов в определенный промежуток времени и установке временной задержки при превышении установленного порога. В частности этот метод делает неэффективным или даже бесполезным способ взлома пароля путем перебора, потому что затраченное на перебор время будет слишком велико. Готовый php скрипт под капотом.
В настоящее время на практике используются различные подходы к защите любой компьютерной информации, в том числе и информации, располагаемой на Интернет-ресурсе. Данные подходы могут быть определены следующими характеристиками:
— наличием формализованных требований, как к набору, так и к параметрам всех механизмов защиты, которые регламентируются большинством современных требований к обеспечению общей компьютерной безопасности (иначе говоря, требованиями, определяющими, что именно должно быть предусмотрено разработчиками);
— наличием реальных механизмов защиты, которые реализуются в процессе защиты любой компьютерной информации. К таким механизмам защиты, прежде всего, относя встроенные в операционную систему средства защиты, по той простой причине, что в большинстве своем используемые на веб-сервере скрипты пользуются встроенными в операционную систему механизмами защиты или же наследуют используемые в них методы. Именно на базе этих механизмов и используемых в них методов определяется общий уровень защиты всего веб-сервера;
— существующей статистикой различных угроз безопасности компьютерной информации. В частности, это данные об уже осуществленных успешных атаках на какие-либо информационные ресурсы. Ведение данной статистики призвано помочь определить, насколько эффективны предпринятые меры защиты, а также дать оценку уровню выдвигаемых требований к созданию защиты на веб-сервере.
Как уже упоминалось, наиболее эффективным методом для противодействия сканированию сайта, а также всем видам хаотичных интенсивных запросов, является установка некоторой временной задержки между запросами, исходящими от одного и того же пользователя. При идентификации пользователя основной упор следует делать на его IP-адрес, по той причине, что файлы cookie могут быть легко удалены. Конечно же, IP-адрес пользователя также может быть изменен, к примеру, при помощи прокси-сервера или же с помощью переподключения, в случае, если IP-адрес у пользователя динамический, правда, такая операция может занять довольно много времени, что в свою очередь сведет на нет все старания злоумышленника.
Данный метод защиты сайта следует реализовать путем написания php-скрипта. Об этом говорит сайт https://intellect.icu . Использование такого рода скрипта поможет защитить содержимое сайта от сканирования проводимого при помощи программ-краулеров и, одновременно, поможет существенно замедлить проведение сканирования сайта «вручную». Кроме того, использование подобного скрипта обеспечит прекрасную защищенность абсолютно всех страниц сайта от различных видов хаотичных интенсивных запросов, что в свою очередь даст возможность снизить нагрузку на оборудование веб-сервера.
Разрабатываемый скрипт должен иметь возможность настройки. В частности необходимо заранее предусмотреть возможность изменения части параметров скрипта. Иначе говоря, в скрипте должно быть:
— наличие возможности настройки времени блокировки IP-адреса пользователя;
— наличие возможности задать интервал времени, в который будет проверяться активность пользователя, иначе говоря, время, в течение которого будет вестись учет количества запросов, поступивших от одного определенного пользователя;
— наличие возможности установки количества запросов, которые один пользователь сможет отправить на страницы сайта в течение заданного временного интервала;
— наличие возможности создания списка «всегда разрешенных IP-адресов». IP-адреса, внесенные в данный список, никогда не будут заблокированы;
— наличие возможности создания списка «всегда запрещенных IP-адресов», т.е. скрипт всегда будет блокировать IP-адреса, которые внесены в данный список.
Преимуществами создания и использования подобного php-скрипта можно считать:
— существенное снижение количества запросов, отправляемых к серверу баз данных;
— существенную экономию входящего и исходящего трафика на веб-сервере;
— наличие удобной и гибкой настройки наиболее важных параметров работы скрипта;
— возможность существенного снижения нагрузки на веб-сервер со стороны пользователей;
— копирование всей информации, размещенной на сайте, будет сильно затруднено или даже невозможно в случае, если страниц на данном ресурсе доста-точно много.
Логика работы разрабатываемой системы защиты сайта, создаваемой в виде php-скрипта, приведена на рисунке:
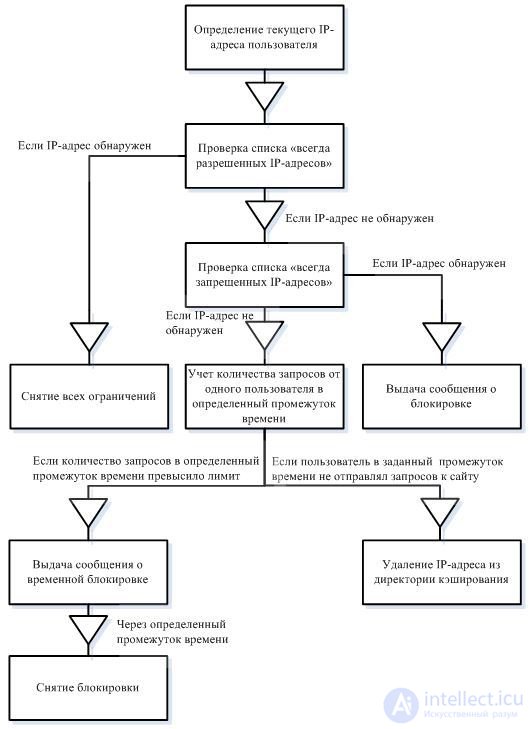
В процессе разработки скрипта важным моментом является выбор способа хранения получаемой информации. В нашем случае, это IP-адреса текущих пользователей. Данная информация может храниться либо в базе данных, либо на жестком диске. Для того чтоб ускорить работу разрабатываемого скрипта, а также сделать его более устойчивым, для хранения IP-адресов текущих пользователей мы будем использовать директории кэширования.
В одну из таких директорий скрипт будет помещать на хранение IP-адреса активных, на данный момент пользователей, эта директория будет носить название active. А в другую директорию мы будем вносить файлы, название которых будет включать IP-адреса временно заблокированных пользователей (директория block).
Кроме IP-адреса, в процессе работы скрипта, также понадобиться информация об активности пользователя. Для этого в название файла, содержащего IP-адрес пользователя, мы также будем вносить точное системное время, когда он проявил «первую», в заданный промежуток времени, активность, т.е. первый раз за определенный (заранее установленный) промежуток времени отправил запрос к странице сайта. В случае, если пользователь в заданный интервал времени превысил заранее определенное в скрипте количество отправленных запросов к страницам сайта, скрипт удалит файл, содержащий его IP-адрес из директории активных пользователей. После чего запишет новый файл (название которого будет содержать IP-адрес только что заблокированного пользователя) в директорию, содержащую заблокированные IP-адреса. Таким образом, в директориях кэширования (active и block) будут временно сохраняться файлы с такими названиями как: 127.0.0.1_12222222 и тому подобные.
В имени файла, до нижнего слеша, будет содержаться IP-адрес активного пользователя, а после нижнего слеша в имя файла будет вноситься точное системное время, в которое он проявил активность (т.е. отправил запрос к страницам ресурса или же был заблокирован).
Отдельно следует отметить тот момент, что для директорий кэширования, т.е. папок active и block, обязательно нужно выставить права доступа владельца файла или 777. Иначе говоря, атрибуты данных папок, указанные на сервере, должны давать скрипту право на запись, право на чтение, а также право на выполнение. Права доступа 777 обязательно должны быть установлены для всех групп пользователей.
К тому же следует предусмотреть отдельное исключение на случай, если администратор сайта этого не сделает. Ведь в подобной ситуации работа скрипта будет невозможна, а значит,
защита сайта от сканирования и хаотичных интенсивных запросов окажется, как минимум, несостоятельной. Иначе говоря, в процессе работы скрипта обязательно должно проверяться наличие или же отсутствие возможности произведения чтения, а также записи в какую-либо из директорий кэширования.
Информацию о текущих пользователях (в частности, об их IP-адресах) мы будем брать из суперглобального массива $_SERVER[]. Данный массив создается веб-сервером. В нем содержатся значения разнообразных переменных окружения. Для работы с IP-адресами пользователей нам понадобиться использовать такие переменные окружения, содержащиеся в суперглобальном массиве $_SERVER[]:
— $_SERVER['HTTP_X_FORWARDED_FOR'];
— $_SERVER['HTTP_CLIENT_IP'];
— $_SERVER['HTTP_X_CLUSTER_CLIENT_IP'];
— $_SERVER['HTTP_PROXY_USER'];
— $_SERVER['REMOTE_ADDR'].
Переменная окружения $_SERVER['HTTP_X_FORWARDED_FOR'] дает нам возможность определить IP-адрес клиента, если он использует для работы прокси-сервер. Переменная окружения $_SERVER['HTTP_CLIENT_IP'] дает возможность получить IP-адрес клиента, если он не использует прокси-сервер, для работы в Интернете. Переменная окружения $_SERVER['HTTP_X_CLUSTER_CLIENT_IP'] дает возможность получить IP-адрес клиента, в случае, если на сайте не используется криптографический протокол SSL, обеспечивающий безопасное соединение между сервером и клиентом. Переменная окружения $_SERVER['HTTP_PROXY_USER'] дает возможность определить IP-адрес клиента, который использует в работе прокси-сервер.
Переменная окружения $_SERVER['REMOTE_ADDR'] дает возможность получить IP-адрес удаленного пользователя. Во время тестирования на локальной машине данный IP-адрес будет равен 127.0.0.1. В то же время в сети данная переменная вернет либо IP-адрес клиента, либо IP-адрес последнего используемого пользователем прокси-сервера (при помощи которого данный клиент попал на веб-сервер). Таким образом, используя одновременно множество различных переменных окружения из массива $_SERVER[] (все используемые переменные приведены выше), у нас будет возможность определить реальный IP-адрес пользователя, даже в том случае, если он попытается его «замаскировать» при помощи какого-либо прокси-сервера.
Для устойчивой работы скрипта на любой из страниц сайта, вне зависимости от ее уровня вложенности, будем использовать возможность приведения к абсолютному виду путей к директориям кэширования (active и block). Использование такого подхода даст нам возможность запускать скрипт с любой страницы сайта и при этом не опасаться того, что изначально указанные в скрипте относительные пути к директориям кэширования на какой-то из страниц окажутся неверными.
Как уже упоминалось, разрабатываемый скрипт должен иметь возможность настройки. В частности необходимо заранее предусмотреть возможность изменения части параметров скрипта (времени блокировки IP-адреса пользователя, интервала времени, за который будет учитываться количество запросов отправляемых к страницам ресурса, а также количества разрешенных запросов в данный интервал времени). Данные параметры изначально в скрипте будут задаваться при помощи констант.
В частности, подобными константами в скрипте будут указаны такие пара-метры:
— время блокировки IP-адреса пользователя указываемое в секундах (const blockSeconds);
— интервал времени, в который будут учитываться запросы от одного пользователя к страницам сайта. Данный интервал также будет указываться в секундах (const intervalSeconds);
— количество запросов к страницам веб-сайта, которые сможет отправить один пользователь за заданный временной промежуток (const intervalTimes).
Отдельно в скрипте следует определить такие массива, содержащие строчные данные:
— массив значений тех IP-адресов, которые внесены в «список всегда разрешенных IP-адресов» (объявление массива public static $alwaysActive = array(‘’));
— массив значений тех IP-адресов, которые внесены в «список всегда запрещенных IP-адресов» (объявление массива public static $alwaysBlock = array(‘’)).
Для правильной работы скрипта, а также для его отладки необходимо предусмотреть наличие в скрипте нескольких флагов. Отметим, что использование подобных флагов также поможет в процессе защиты содержимого сайта от сканирования и различных хаотичных интенсивных запросов. К таким флагам можно отнести:
— флаг возможности подключения всегда активных пользователей (const isAlwaysActive);
— флаг возможности подключения всегда заблокированных пользователей (const isAlwaysBlock).
Разработанный скрипт содержит один класс TBlockIp. Данный класс включает такие методы:
— checkIp(). Данный метод реализовывает возможность произведения проверки IP-адреса пользователя на его блокировку или же на активность. При этом пропускаются IP-адреса, внесенные в список «всегда разрешенных IP-адресов», а IP-адреса внесенные в список «всегда запрещенных IP-адресов» наоборот блокируются. В случае, если пользовательский IP-адрес не найден в массиве возможных IP-адресов – скрипт создаст идентификатор нового активного IP-адреса;
— _getIp(). Данный метод дает возможность получить текущий IP-адрес пользователя, выбираемый из всех возможных IP-адресов (фильтрация производиться до выявления нужного IP-адреса клиента). Метод возвращает полученный IP-адрес.
В конечном счете разработанный скрипт может считаться эффективным инструментом, который поможет оказывать противодействие процессу сканирования сайта, а также станет мерой пресечения для всех видов хаотичных интенсивных запросов. В разработанном скрипте имеется установка некоторой временной задержки между запросами, исходящими от одного и того же пользователя. При идентификации пользователя основной упор делается на его IP-адрес. Причина этого проста – дело в том, что файлы cookie могут быть легко удалены с компьютера злоумышленника, а значит строить защиту ресурса с их использованием нельзя.
Конечно же, IP-адрес пользователя также может быть изменен, к примеру, при помощи прокси-сервера. Для того чтоб исключить подобную возможность для злоумышленника, в скрипте используются переменные окружения, которые в свою очередь помогают выявить реальный IP-адрес пользователя. Именно этот IP-адрес, в случае превышения пользователем установленного лимита запросов к страницам сайта в определенный промежуток времени, окажется заблокированным. Разработанный скрипт выполняет все возложенные на него функции, связанные с защитой сайта от сканирования, а также от хаотичных интенсивных запросов.
Просмотр и последующее тестирование написанного кода являются одним из важнейших этапов разработки php-скриптов. Данный этап разработчики, занимающиеся программированием для Web, нередко упускают. Дело в том, что очень просто можно два или три раза запустить написанный скрипт и отметить, что он работает нормально. В то же время это является распространенной ошибкой. Ведь созданный скрипт необходимо подвергнуть тщательному анализу или же тестированию.
Главным отличием разрабатываемых php-скриптов от прикладных программ является то, что с Web-приложениями будет работать чрезвычайно широкий круг людей. В подобной ситуации не следует рассчитывать на то, что пользователи будут в совершенстве разбираться в использовании различных Web-приложений. Пользователей нельзя снабдить огромным руководством или же кратким справочником. Именно поэтому разрабатываемые Web-приложения обязательно должны быть не только самодокументируемыми, но и самоочевидными. При внедрении разработанного php-скрипта необходимо учесть всевозможные способы его использования, а также протестировать его поведение в различных ситуациях.
Опытному пользователю или программисту нередко сложно понять проблемы, которые возникают у неискушенных пользователей. Одним из способов решения проблемы будет найти тестеров, которые и будут представлять действия типовых пользователей. В прошлом использовался следующий подход – сначала на рынок выпускалась бета-версия разработанного Web-приложения. После того, как большинство ошибок, предположительно, было исправлено, данное приложение публиковали для небольшого количества пользователей, которые, соответственно, создадут небольшую интенсивность входящего трафика. После проведения такого рода теста разработчики получают массу различных комбинаций данных и вариантов использования разработанной системы, о которых ее разработчики даже и не догадывались [13, стр. 394].
Созданный php-скрипт должен делать именно то, для чего, собственно говоря, он и был создан. Применительно к разработанному и созданному в данной работе php-скрипту можно сказать так: если пользователь сможет отправить за определенный промежуток времени (по умолчанию 15 секунд) больше заданного количества запросов (по умолчанию – 3 запроса) к страницам сайта и скрипт не заблокирует его IP-адрес, значит, в работу написанного Web-приложения закралась ошибка. В целом, тестирование представляет собой деятельность, которая направлена на выявление подобного рода несоответствий, существующих между ожидаемым поведением написанного php-скрипта и действительным его поведением. За счет выявления несоответствия в поведении скрипта, а также его некорректного поведения еще во время разработки, у разработчика есть возможность существенно снизить вероятность того, что с такого рода поведением скрипта столкнется и пользователь. Проводить тестирование программы (в нашем случае, написанного php-скрипта) можно как вручную, так и при помощи специализированных онлайнсервисов.
При тестировании написанного php-скрипта вручную, нам необходимо проверить выполняет ли скрипт возложенные на него задачи. В частности, ограничивает ли количество запросов к страницам сайта, исходящим от одного и того же пользователя, в случае, если их частота превышает допустимый предел в определенный промежуток времени. Для проверки работоспособности скрипта нам, прежде всего, необходимо внедрить его в код сайта. Для этого можно воспользоваться такой языковой конструкцией:
include «block/index.php»;
При таком включении скрипт должен быть расположен в папке block. Следует учесть, что в случае, если система управления содержимым сайта использует для страниц создание, так называемых Friendly URL, т.е. веб-адресов, которые удобны для восприятия человеком (в данном случае имеется ввиду создание каких-либо многоуровневых структур, например, /news/sport/2003/10/), или же загружает страницы с адресом отличным от корня папки (например, /news/sport.php), возникнет необходимость правильного указания адреса к скрипту. В подобной ситуации вполне может быть указан абсолютный путь к скрипту.
Само по себе тестирование написанного php-скрипта будет заключаться в отправке запросов к страницам сайта. В процессе тестирования нам нужно проверить: пропускает ли созданный скрипт заданное максимальное количество запросов (по умолчанию – 3 запроса) в определенный промежуток времени (по умолчанию – 15 секунд). Прежде всего, нам необходимо проверить как скрипт справляется со своей основной функцией, т.е. непосредственной блокировкой интенсивных запросов на страницы сайта, исходящих от одного и того же пользователя. Проверка количества запросов, которые могут быть отправлены к страницам сайта, показала, что на протяжении отведенных пятнадцати секунд отправить к страницам сайта более трех запросов нет возможности. В частности, если пользователь отправляет больше трех запросов, то получает сообщение о временной блокировке, приведенное на рисунке:
Таким образом, тестирование показало, что скрипт работает именно так, как предполагалось: блокирует пользователя на определенное время (по умолчанию – на одну минуту) в случае, если в определенный интервал времени количество запросов от одного пользователя превышает заданный показатель (по умолчанию – 3 запроса). Следующим этапом тестирования будет проверка, работоспособности отдельных функций написанного php-скрипта. В частности, нужно проверить, как будет работать скрипт если IP-адрес тестирующего пользователя будет добавлен в список «всегда разрешенных IP-адресов». Также нужно проверить, как будет вести себя скрипт, если IP-адрес тестирующего пользователя будет добавлен в список «всегда запрещенных IP-адресов».
После добавления IP-адреса тестирующего пользователя в список «всегда разрешенных IP-адресов» ограничение на количество отправляемых к страницам сайта запросов оказалось снятым, и переходить по ссылкам (или обновлять страницу) можно было неограниченное количество раз. Иначе говоря, функция, которую должен выполнять список «всегда разрешенных IP-адресов» правильно работает. После добавления IP-адреса тестирующего пользователя в список «всегда запрещенных IP-адресов» отправить хотя бы один запрос к странице сайта не удалось. Вместо содержимого веб-ресурса в браузере появляется сообщение о блокировке, приведенное на рисунке:
Другими словами, функция, которую должен выполнять список «всегда запрещенных IP-адресов» работает правильно. Данная функция полностью блокирует пользователя, IP-адрес которого внесен в список «всегда запрещенных IP-адресов». Таким образом, функции разграничения доступа, которые реализованы при помощи наличия списка «всегда разрешенных IP-адресов», а также наличия списка «всегда запрещенных IP-адресов» работают верно и скрипт ведет себя именно так, как изначально предполагалось. Иначе говоря, скрипт предоставляет неограниченный доступ к страницам сайта для тех пользователей, IP-адреса которых внесены в список «всегда разрешенных IP-адресов» и полностью запрещает доступ тем пользователям, чьи IP-адреса обнаруживаются в списке «всегда запрещенных IP-адресов». Тестирование написанного php-скрипта вручную показало, что все функции скрипта, а значит и сам скрипт, работают правильно, т.е. именно так как изначально задумано.
Тестирование написанного php-скрипта, при помощи онлайнсервисов, даст возможность узнать, точное количество трафика необходимого для загрузки страниц сайта, а также поможет точно установить «пропускную способность» написанного php-скрипта для запросов, которые будут отправляться различными автоматическими сервисами или же программами. Последний параметр очень важен, ведь одной из задач скрипта является защита сайта от сканирования при помощи программ-краулеров. Такого рода тестирование не только поможет сделать вывод об необходимом количестве трафика и процессорного времени, но и о том, доступна ли будет информация представленная на сайте для программных средств, запрашивающих страницы в автоматическом режиме. Для начала оценим среднее время загрузки страниц сайта, при разных скоростях соединения. Также оценим и размер загружаемых пользователем страниц. Для проведения такого рода тестирования воспользуемся онлайн-сервисом, расположенным по адресу analyze.websiteoptimization.com. Размеры загружаемых страниц, определенные сервисом, приведены на рисунке:

С учетом того, что тестируемый нами сайт состоит лишь из одной страницы, размер которой составляет 1511 байт, она загрузиться за 0,51 секунды (при скорости соединения 56 К) или за 0,21 секунды (при скорости соединения пользователя 1,44 Mbps). Скорость загрузки страниц при разной скорости соединения пользователя приведена на рисунке:
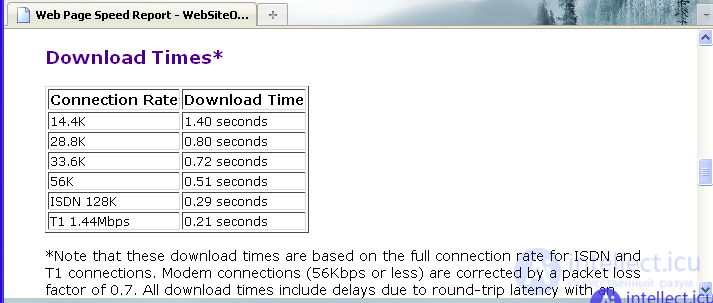
Как видно из приведенной на рисунке информации, даже при самой низкой скорости соединения (14,4 К) страница сайта грузится довольно быстро – за 1,4 секунды. В то же время, если скорость соединения пользователя довольно высока (в частности, 1,44 Mbps), то страница будет загружена буквально моментально (за 0,21 секунды). Отметим, что низкая скорость загрузки на данном ресурсе корректируется на коэффициент потери пакетов (этот коэффициент равен 0,7). Также учитывается и время задержки равное в среднем 0,2 секунды на загрузку одной страницы. Именно эти параметры и объясняют, почему существенный рост скорости соединения не приводит к столь же существенному сокращению времени загрузки страницы. Отметим, что данный сервис кроме оценки основных параметров загрузки страниц сайта также предоставляет общие результаты анализа сайта и, конечно же, рекомендации направленные на улучшение всех параметров загрузки страниц сайта. Результаты анализа и рекомендации сервиса приведены на рисунке:

Как видно из рисунка, все показатели тестируемого сайта по всем анализируемым параметрам находятся в пределах нормы. В частности, сервис констатирует, что количество страниц сайта, объектов на них, а также размеры этих страниц и объектов находятся в допустимых пределах. Исходя из полученных данных оптимизация тестируемому сайту не требуется, ведь сайт соответствует нормам по всем анализируемым параметрам. Иначе говоря, объемы загружаемой с сайта информации (или страниц сайта) довольно малы и позволяют экономить ресурсы как веб-сервера, так и пользователя. Т.е. разработанный скрипт не нагружает сайт и, фактически, его присутствие не заметно. Что подчеркивает проведенное тестирование. Проверку скорости загрузки страниц сайта, а также их доступности для других скриптов можно выполнить при помощи такого онлайн-сервиса как www.pr-cy.ru. Результат теста, сделанного при помощи данного онлайн-сервиса, приведен на рисунке:

Как видно, из полученных данных при средней скорости загрузки 30,31 Кб/сек, время загрузки страницы составляет 0,05 секунды. В то же время при средней скорости 37,89 Кб/сек, время загрузки страницы составляет уже 0,04 секунды. В то же время, тестирование показало, что разработанный в данной работе скрипт блокирует больше трех запросов к страницам сайта, исходящих от одного IP-адреса и тем самым снижает излишнюю нагрузку и весьма усложняет попытки или вовсе делает невозможным подбор пароля к сайту.
Проведенные тесты показали, что разработанный php-скрипт отлично справляется с изначально возложенными на него функциями по защите сайта от сканирования, а также от хаотичных интенсивных запросов и попыток брутфорса, исходящих от одного пользователя. В частности, тестирование сайта вручную показало, что скрипт блокирует запросы к страницам сайта, исходящие с одного IP-адреса, в случае, если количество этих запросов в заданный интервал времени превышает заранее отведенный лимит. Кроме того, данное тестирование показало, что все функции скрипта работают отлично, в частности функции по работе со списками «всегда разрешенных IP-адресов» и «всегда запрещенных IP-адресов». Иначе говоря, разработанный скрипт предоставляет неограниченный доступ ко всем страницам сайта для тех пользователей, IP-адреса которых внесены в список «всегда разрешенных IP-адресов» и полностью запрещает доступ тем пользователям, чьи IP-адреса обнаруживаются в списке «всегда запрещенных IP-адресов».
Тестирование сайта, в который внедрен разработанный php-скрипт, показало, что все показатели тестируемого сайта по всем анализируемым параметрам находятся в пределах нормы. В частности, сервис констатирует, что количество страниц сайта, объектов на них, а также размеры этих страниц и объектов находятся в допустимых пределах. Исходя из полученных данных оптимизация тестируемому сайту не требуется, ведь сайт соответствует нормам по всем анализируемым параметрам. Иначе говоря, объемы загружаемой с сайта информации (или страниц сайта) довольно малы и позволяют экономить ресурсы как веб-сервера, так и пользователя. Ранее скрипт использовался на сайтах по изучению английского языка и английских слов, но позднее были предприняты более серьезные меры защиты. Однако, на первых порах, данный скрипт существенно снижал нагрузку на недорогой хостинг и позволял крутить сайты с посещаемостью 7000+ хостов в сутки.
Кроме того, тестирование сайта показало, что скорость загрузки страниц тестируемого сайта довольно высока. Также, скрипт заблокировал проведение тестирования сайта, когда количество запросов отправленных с IP-адреса данного онлайн-сервиса превысило допустимый в разработанном скрипте предел (максимальное количество запросов с одного IP-адреса, установленное в скрипте, равно трем запросам за 15 секунд).
Другими словами, защита сайта от сканирования и хаотичных интенсивных запросов работает именно так, как и предусматривалось изначально. Другими словами, если количество запросов, исходящих с одного IP-адреса (в случае, если IP-адрес пользователя не находится в списке «всегда разрешенных IP-адресов» или же в списке «всегда запрещенных IP-адресов»), превышает допустимый лимит в определенный интервал времени, то IP-адрес пользователя будет временно заблокирован вне зависимости от того, отправлялись запросы при помощи браузера, программы и использовался ли при отправке запросов прокси-сервер (для маскировки реального IP-адреса пользователя).
| Признак | Описание |
|---|---|
| vec_len | Количество запросов в сессии |
| vec_len_pages | Количество запросов в сессии в страницах (URI заканчивается на .htm, .html, .php, .asp, .aspx, .jsp) |
| vec_len_static_request | Количество запросов в сессии в статических страницах |
| vec_len_sec | Время сессии в секундах |
| vec_len_unique_uri | Количество запросов в сессии, содержащих уникальный URI |
| vec_headers_cnt | Количество заголовков в сессии |
| vec_has_cookie | Есть ли заголовок Сookie |
| vec_has_referer | Есть ли заголовок Referer |
| vec_avg_time_page | Среднее время на страницу в сессии |
| vec_avg_time_request | Среднее время на запрос в сессии |
| vec_avh_headers | Среднее количество заголовков в сессии |
после получения таких ботов остается отсеить только орошие боты - разница и будет в ввиде плохих ботов
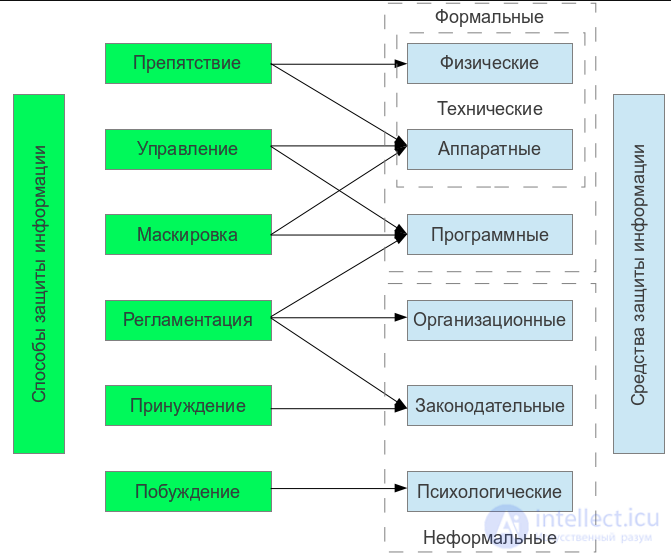
Таким образом способы защиты от парсинга и вооще любой информации можно классифицировать следующем образом
Прочтение данной статьи про защита сайта от сканирования позволяет сделать вывод о значимости данной информации для обеспечения качества и оптимальности процессов. Надеюсь, что теперь ты понял что такое защита сайта от сканирования, защита от интенсивных запросов, много запросов, защита от парсинга и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Информационная безопасность, Вредоносное ПО и защита информации

Комментарии