Лекция
Привет, Вы узнаете о том , что такое cron, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое cron, supervisor, redis , настоятельно рекомендую прочитать все из категории Операционная система LINUX.
Очереди сообщений в архитектуре распределенных систем часто используются при дроблении большой системы на компоненты, поскольку они являются простым и в то же время масштабируемым инструментом, позволяющим «подружить» независимые системы и научить
их работать совместно.
К их задачам относится предоставление возможности обмена сообщениями различным подсистемам при обеспечении маршрутизации, масштабирования и гарантированной доставки .
Очередь сообщений позволяет обеспечить асинхронное выполнение участков программы. Это позволяет:
Принцип системы очередей можно реализовать на MySQL и PHP, однако простота и наличие готовых решений позволяют сделать это быстрее.
Для PHP существует разные системы управления очередями задач.
Supervisor — простой и достаточно мощный инструмент для контроля процессов. С правильной настройкой он способен обеспечить бесперебойную работу вашего веб-сервиса.
Supervisor — это система клиент/сервер, при помощи которой пользователь (администратор) может контролировать подключенные процессы в системах типа UNIX. Инструмент создает процессы в виде под-процессов от своего имени, поэтому имеет полный контроль над ними.
Также присутствует поддержка автоматического перезапуска задачи при возникновении ошибки и запуск одной очереди несколькими воркерами для более быстрого выполнения очереди.
Supervisor – система клиент/сервер, при помощи которой пользователь (администратор) может контролировать подключенные процессы в системах типа UNIX.
Инструмент создает процессы в виде подпроцессов от своего имени, поэтому имеет полный контроль над ними. Схема работы системы управления Supervisor представлена на рис. 2 .
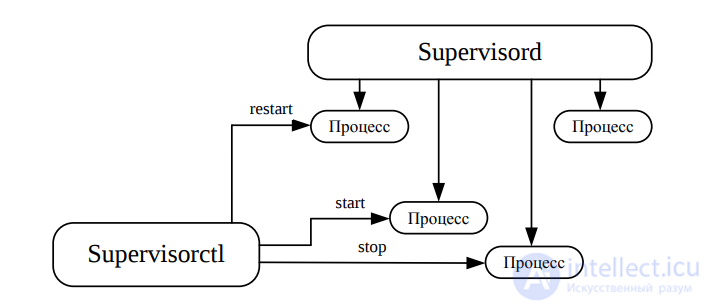
Рис. 2. Схема работы Supervisor
Supervisor состоит из серверной части под названием supervisord, которая создает и управляет всеми процессами, и системного/веб-интерфейса supervisorctl для управления и мониторинга supervisord. Supervisor также включает пользовательский веб-интерфейс supervisorctl, который включается при помощи файла конфигурации. Для этого нужно изменить секцию [inet_http_server], вписав туда верные имя пользователя и пароль.
Supervisor состоит из серверной части под названием supervisord, которая создает и управляет всеми процессами, и системного/веб-интерфейса supervisorctl для управления и мониторинга supervisord.
Процесс установки supervisord в Debian предельно прост. Нужно выполнить команду:
apt-get install supervisor
# Установка supervisor, необходимо иметь права root
После установки, supervisor нужно сконфигурировать и добавить программы/процессы, которыми он будет управлять. Файл конфигурации по умолчанию находится в /etc/supervisor/supervisord.conf (для Ubuntu, Debian) или /etc/supervisord.conf для других систем(FreeBSD и т.д.).
Для добавления нового процесса (воркера) нужно дополнить файл аналогичным кодом:
[program:worker] command=/usr/bin/php /var/www/site/public_html/artisan queue:work stdout_logfile=/var/log/worker.log autostart=true autorestart=true user=www-data stopsignal=KILL numprocs=1
пример запуска одновремено 1-0 потоков для обработки очереди
[program:laravel-worker]
process_name=%(program_name)s_%(process_num)02d
command=php /var/www/app/artisan queue:work database --sleep=3 --tries=3
autostart=true
autorestart=true
user=username
numprocs=10
redirect_stderr=true
stderr_events_enabled=true
stderr_logfile=/var/www/app/storage/logs/worker.error.log
stdout_logfile=/var/www/app/storage/logs/worker.log
# Создание воркера для управления процессом PHP
.
В случае, когда требуется запуск сразу нескольких инстансов одного и того же процесса, конфигурация будет иметь вид:
[program:worker] command=/usr/bin/php /var/www/site/public_html/artisan queue:work process_name=%(program_name)s_%(process_num)02d numprocs=10 stdout_logfile=/var/log/worker.log autostart=true autorestart=true user=www-data stopsignal=KILL
# Создание 10 копий процесса
В этом случае добавляется строчка process_name=%(program_name)s_%(process_num)02d, которая задает имена всех копий процесса, в нашем случае worker_00, worker_01 и т.д.
После добавления новых процессов/воркеров не забывайте перезагружать supervisor:
/etc/init.d/supervisor restart
# Перезапуск супервизора
Supervisor также включает пользовательский веб-интерфейс supervisorctl, который включается при помощи файла конфигурации. Об этом говорит сайт https://intellect.icu . Для этого нужно изменить секцию [inet_http_server], вписав туда верные имя пользователя и пароль:
[inet_http_server] port=127.0.0.1:9001 ;username=some_user_name ;password=some_password
# Включение веб-консоли supervisorctl на 9001-м сокете
Теперь всеми доступными процессами можно управлять через браузер. Помните, что после изменения конфига supervisor и/или supervisorctl нужно обновить.
В supervisor есть встроенный механизм мониторинга событий, при помощи которого система может оповещать об ошибках:
[eventlistener:memmon] command=memmon -a 200MB -m error@intellect.icu events=TICK_60
# Если процесс потребляет более 200 МБ памяти, memmon перезапускает его и отправляет уведомление на почту, проверка каждые 60 секунд
При помощи ивентов и собственного скрипта на Pyton можно произвести проверку буквально любого аспекта нужного процесса.
Теперь можно использвать supervisorctl для управления программой.
Перечитываем конфиги:
worker: available
Добавляем его в supervisord:
worker: added process group
Проверяем статус:
worker RUNNING pid 32284, uptime 0:00:40
Останавливаем:
worker: stopped
Удаляем:
worker: removed process group
Cron – планировщик задач, автоматически запускающий определенные задания с указанной периодичностью [14]. Удобен при выполнении, например, скрипта, очищающего кэш скриптов или отсылающего уведомления зарегистрированным пользователям сайта.
Редактировать файл crontab можно с помощью интерфейса панели управления и используя специальный инструмент с таким же названием – crontab. Конфигурационный файл состоит из строк. Каждая строка описывает программу, которая будет запущена по расписанию .
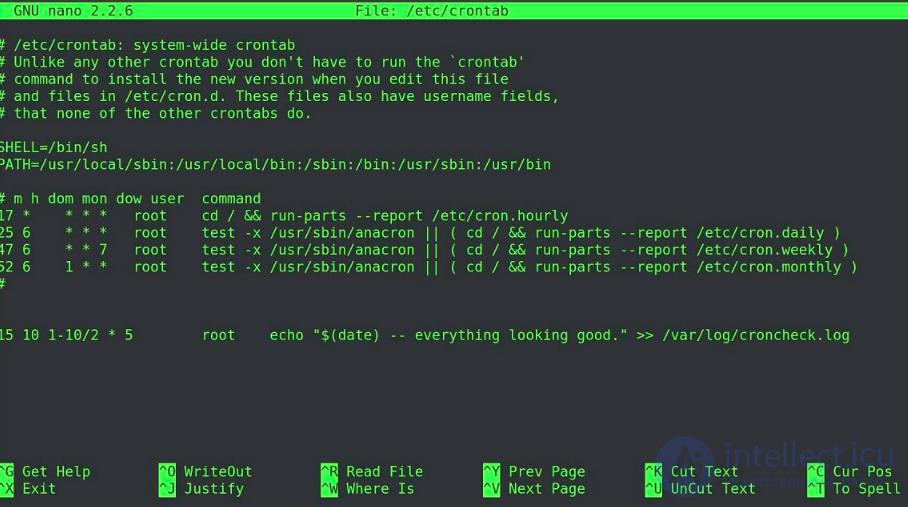
В каждой строке шесть полей.
Поля имеют назначение:
1) минуты (0–59);
2) часы (0–23);
3) день месяца (1–31);
4) месяц в году (1–12);
5) день недели (0–6);
6) программа, которая будет запущена.
Сравнение популярных систем управления очередями задач представлено в табл. 2 [16].
Redis — достаточно популярный инструмент, который из коробки поддерживает большое количество различных типов данных и методов работы с ними. Во многих проектах он используется в качестве кэшируещего слоя, но его возможности намного шире. Мы в ManyChat очень любим Redis и активно используем его в нашем продукте для решения огромного количества задач. Про некоторые интересные кейсы использования этой in-memory key-value базы данных я расскажу на примерах. Надеюсь, вам они будут полезны, и вы сможете применить что-то в своих проектах.
Redis может использоваться для:
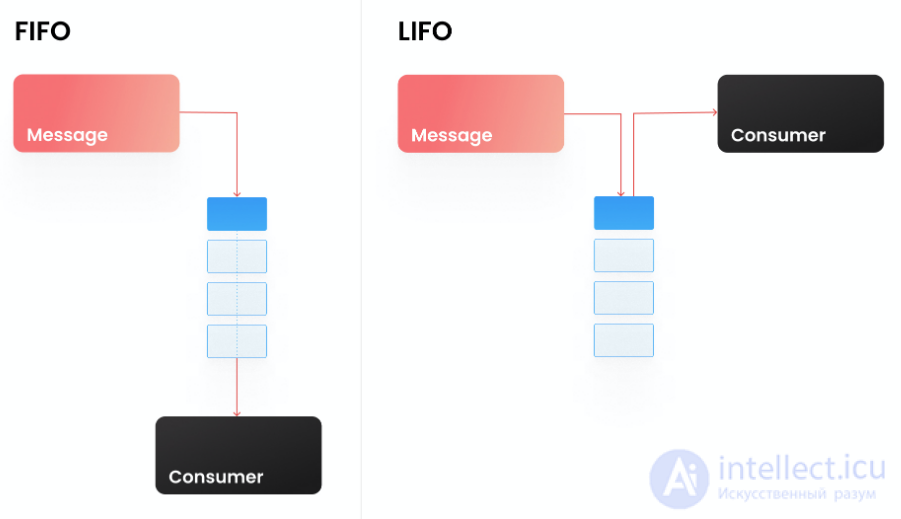
Используя имеющиеся в Redis структуры данных, мы можем запросто реализовать стандартные очереди FIFO или LIFO. Для этого используем структуру List и методы по работе с ней. Работа с очередями состоит из двух основных действий: отправить задачу в очередь, и взять задачу из очереди. Отправлять задачи в очередь мы можем из любой части системы. Получением задачи из очереди и ее обработкой обычно занимается выделенный процесс, который называется консьюмером (consumer).
Итак, для того, чтобы отправить нашу задачу в очередь, нам достаточно использовать следующий метод:
Тем самым мы добавим в конец листа с названием $queueName некий $payload, который может представлять из себя JSON для инициализации нужной нам бизнес логики (например данные по денежной транзакции, данные для инициализации отправки письма пользователю, etc.). Если же в нашем хранилище не существует листа с именем $queueName, он будет автоматически создан, и туда попадет первый элемент $payload.
Со стороны консьюмера нам необходимо обеспечить получение задач из очереди, это реализуется простой командой чтения из листа. Для реализации FIFO очереди мы используем чтение с обратной записи стороны (в нашем случае мы писали через RPUSH), то есть читать будем через LPOP:
Для реализации LIFO очереди, нам нужно будет читать лист с той же стороны, с которой мы в него пишем, то есть через RPOP.
Тем самым мы вычитываем по одному сообщению из очереди. В случае если листа не существует (он пустой), то мы получим NULL. Каркас консьюмера мог бы выглядеть так:
Для того, чтобы получить информацию о глубине очереди (сколько значений хранится в нашем листе), можем воспользоваться следующей командой:
Мы рассмотрели базовую реализацию простых очередей, но Redis позволяет строить более сложные очереди. Например, мы хотим знать о времени последней активности наших пользователей на сайте. Нам не важно знать это с точностью вплоть до секунды, приемлемая погрешность — 3 минуты. Мы можем обновлять поле last_visit пользователя при каждом запросе на наш бэкенд от этого пользователя. Но если этих пользователей большое количество в онлайне — 10,000 или 100,000? А если у нас еще и SPA, которое отправляет много асинхронных запросов? Если на каждый такой запрос обновлять поле в бд, мы получим большое количество тупых запросов к нашей БД. Эту задачу можно решать разными способами, один из вариантов — это сделать некую отложенную очередь, в рамках которой мы будем схлопывать одинаковые задачи в одну в определенном промежутке времени. Здесь на помощь нам придет такая структура, как Sorted SET. Это взвешенное множество, каждый элемент которого имеет свой вес (score). А что если в качестве score мы будем использовать timestamp добавления элемента в этот sorted set? Тогда мы сможем организовать очередь, в которой можно будет откладывать некоторые события на определенное время. Для этого используем следующую функцию:
В такой схеме идентификатор пользователя, зашедшего на сайт, попадет в очередь $queueName и будет висеть там в течение 180 секунд. Все другие запросы в рамках этого времени будут также отправляться в эту очередь, но они не будут туда добавлены, так как идентификатор этого пользователя уже существует в этой очереди и продублирован он не будет (за это отвечает параметр 'NX'). Так мы отсекаем всю лишнюю нагрузку и каждый пользователь будет генерить не более одного запроса в 3 минуты на обновление поля last_visit.
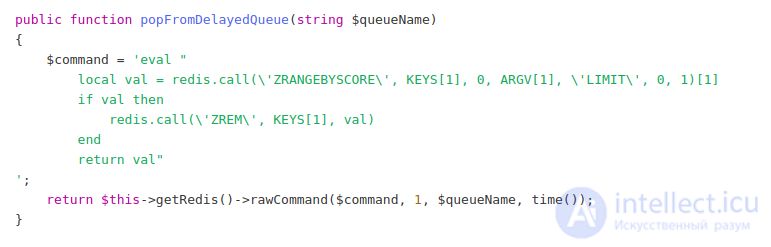
Теперь возникает вопрос о том, как читать эту очередь. Если методы LPOP и RPOP для листа читают значение и удаляют его из листа атомарно (это значит, что одно и тоже значение не может быть взято несколькими консьюмерами), то sorted set такого метода из коробки не имеет. Мы можем сделать чтение и удаление элемента только двумя последовательными командами. Но мы можем выполнить эти команды атомарно, используя простой LUA скрипт!
В этом LUA скрипте мы пытаемся получить первое значение с весом в диапазоне от 0 до текущего timestamp в переменную val с помощью команды ZRANGEBYSCORE, если нам удалось получить это значение, то удаляем его из sorted set командой ZREM и возвращаем само значение val. Все эти операции выполняются атомарно. Таким образом мы можем вычитывать нашу очередь в консьюмере, аналогично с примером очереди построенной на структуре LIST.
Я рассказал про несколько базовых паттернов очередей, реализованных в нашей системе. На текущий момент у нас в продакшене существуют более сложные механизмы построения очередей — линейных, составных, шардированных. При этом Redis позволяет все это делать при помощи смекалки и готовых круто работающих структур из коробки, без сложного программирования.
Прежде всего, я делю записи на количество фрагментов (например, 5 фрагментов.
Он разделит миллионы элементов на несколько фрагментов по сотнни тысяч тыс. элементов в каждом).
Затем можно отправить команду в очереди, которые я создаю мгновенно для фрагментов, и выполнить обработчик очереди для этой очереди только один раз, используя --once параметр. Чтобы лучше понимать, вот код
$chunkId = 0;
foreach($chunks as $chunk){
// Adding chunk to queue
Artisan::queue('process:items',[
'items' => $chunk,
])->onQueue('processChunk'.$chunkId);
// Executing queue worker only once
exec('php artisan queue:work --queue=processChunk'.$chunkId.' --once > storage/logs/process.log &');
$chunkId++;
}
Таблица 2. Cравнение популярных систем управления очередями задач
| Система | Требует установки |
Начало выполнения – |
авто перезапуск |
накопление команд в очереди |
управление количеством параллельных патоков |
Сложность настройки |
| Cron | нет | нет | нет | нет | нет | 2 |
| Supervisor | да | да | да | нет | да | 3 |
|
да | да | нет | да | ? | 5 |
Представленные результаты и исследования подтверждают, что применение искусственного интеллекта в области cron имеет потенциал для революции в различных связанных с данной темой сферах. Надеюсь, что теперь ты понял что такое cron, supervisor, redis и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Операционная система LINUX





Комментарии