Лекция
Это окончание невероятной информации про история искусственного интеллекта.
...
медицине, научных исследований и национальных органов , в том числе Института медицины ,Американского колледжа врачей , в Национальный научный фонд , Национальные институты здравоохранения и Национальной медицинской библиотеки (NLM), и оказали большое влияние на развитие медицина, вычислительной техники и биомедицинской информатики на национальном и международном уровне . Его интересы включают в себя широкий круг вопросов , связанных с интегрированными системами медицинского поддержки принятия решений и их реализации, биомедицинской информатики и медицинского образования и профессиональной подготовки, а также в Интернете в медицине.
В марте 2007 года он стал основателем Декан университета Аризоны 'ов колледжа медицины - Phoenix кампуса. Он ушел в отставку с этой позиции в мае 2008 года и в январе 2009 года перенес свою основную академическую встречу в Университете штата Аризона , где он стал профессором биомедицинской информатики. Он утверждал , вторичное назначение в качестве профессора основных медицинских наук и медицины в Университете штата Аризона медицинский колледж (Phoenix Campus). В ноябре 2009 года он перенес свой академический дом на неполный рабочий день назначения на должность профессора в Школе биомедицинской информатики, Университет Техаса Научного центра здоровья в Техасский медицинский центр в Хьюстоне, где он жил до ноября 2011 года С тех пор он вернулся в Нью - Йорке , где он по- прежнему в качестве адъюнкт - профессор биомедицинской информатики в Колумбийском университете .
В июле 2009 года Shortliffe занимает позицию президента и главного исполнительного директора Американской ассоциации медицинской информатики , организации ,которую он помог сформировать в период между 1988 и 1990 годами , когда он был президентом симпозиума по вопросам компьютерных технологий в медицинской помощи. В конце 2011 года он объявил о своем намерении уйти в отставку с этой позиции в 2012 году

Пол Дж Werbos (родился в 1947 году) является ученым самым известным за его 1974 Гарвардского университета кандидатской диссертации, которая впервые описал процесс обучения искусственных нейронных сетей за счет обратного распространения ошибок. Тезис, и некоторую дополнительную информацию, можно найти в его книге, Корни обратного распространения ( ISBN 0-471-59897-6 ). Он также был пионером рецидивирующих нейронных сетей .
Werbos был одним из первых трех двухгодичных президентов Международного нейросети общества (Inns). Он был удостоен премии IEEE нейронной сети Pioneer для открытия обратного распространения и других основных рамок обучения нейросети , таких как Adaptive динамического программирования .
Werbos также написал на квантовой механике и других областях физики. Он также имеет интерес в больших вопросах , касающихся сознания, основы физики и человеческого потенциала. Роджер Пенроуз обсуждает некоторые из этих идей в своей книге Тени Разума .
Он работал в качестве директора по программам в Национального научного фонда в течение нескольких лет до 2015 года.

Дэвид Румельхарт (англ. David Everett Rumelhart; 1942 — 2011) — американский ученый, сделавший значительный вклад в изучение человеческого сознания и во многом определивший ряд направлений развития когнитивной науки в 1970-е годы XX века. Научная работа Румельхарта связана с такими направлениями как искусственный интеллект, математическая психология, параллельные вычислительные процессы. Наибольшей научный резонанс получили его работы, связанные с исследованием научения и памяти в семантических нейронных сетях. Представитель коннекционистского подхода в когнитивной науке.
В 1963 году получил степень бакалавра в Университете Южной Дакоты. В 1967 — докторская степень (PhD) в Стэнфордском университете. С 1967 до 1987 преподавал на психологическом факультете Калифорнийского университета, затем перешел в Стэнфордский университет. В 1991 году избран в Национальную академию наук США.
После проявления симптомов болезни Пика в 1998 году, оставил научную деятельность в Стэнфорде и переехал жить к своему брату в Анн Арбор, штат Мичиган. Ушел из жизни 13 марта 2011 года в Челси, штат Мичиган, в возрасте 68 лет

Джуда Перл (англ. Judea Pearl, ивр. יהודה פרל, род. 1936) — американский и израильский ученый, автор математического аппарата байесовских сетей, создатель математической и алгоритмической базы вероятностного вывода, автор алгоритма распространения доверия для графических вероятностных моделей, do-исчисления и исчисления противофактических условных (англ. counterfactual conditional).
В 2011 году Перл стал лауреатом Премии Тьюринга за «фундаментальный вклад в искусственный интеллект посредством разработки исчисления для проведения вероятностных и причинно-следственных рассуждений».
Книга Перла «Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference» (1988) занимает 7-е место в базе CiteSeerX по количеству цитирований (5222 фактов по состоянию на май 2012 года).
1980-1990 годы - развитие нейронных сетей и машинного обучения. В это время были созданы новые методы машинного обучения, включая нейронные сети и генетические алгоритмы. Это привело к значительному улучшению способностей искусственного интеллекта в области распознавания образов, обработки естественного языка и прогнозирования.
Изначально появился механицизм и возможность посмотреть не только на мир как механизм, но и на человек. К этому приложил руку Декарт, который предположил, что животное - это автомат, а человек - чуть больше, чем автомат, но по большей части все равно автомат. Очевидно, что большего полета фантази в те времена можно было не ждать, ибо создать машину такого уровня сложности, как человек не представлялось возможным по техническим причинам.
История же вычислительной техники упиралась в необходимость делать массовые точные расчеты, успехи механики, электричество и т.д. Хотя иногда механические вычислительные машины создавались еще в XVII веке (в том числе и такими монстрами как Паскаль и Лейбниц), только в XX веке начали возникать машины, принятые называть компьютер. Одновременно с этим и закладывались теоретические основы исследований искусственного интеллекта (ИИ). Важной вехой стало появление идеи "машины Тьюринга" - простой машины из бесконечной ленты и механизма, который может изменять символ на ячейке ленты, менять состояние и двигаться к соседней ячейке. Конкретная операция зависит от состояния и символа в ячейке.
Тьюринг показал, что каждая рекурсивно вычислимая функция может быть вычислена на такой машине за конечное время. А из этого следовало, что при наличии необходимой программы, достаточной памяти в машине и определенного времени можно вычислить любую управляемую правилами функцию, в том числе и решить тест Тьюринга, что означало бы создание искусственного интеллекта! Осталось только найти нужную функцию... Сначала все шло к тому, что такую функцию вот-вот найдут: с середины 50-х до середины 70-х был сделано очень многон в области ИИ: компьютеры научились вести простые беседы, играть в шахматы, решать сложные алгебраические задачи и доказывать теоремы. Компьютеры росли в мощностях, удваивая свои мощности каждые два года (см. закон Мура), в 1958 году Розенблатт разрабатывает персептрон, а столпы ИИ предсказывают построение коммунизма ИИ к 1980 году... Но потом произошло затишье. Прирост мощности компьютеров не снизился (до сих пор не снизился), а "ИИ" не сильно от этого умнел. Всякие сложные действия требовали кучу времени, да и местами крайне мало напоминали работу мозга. Нужно создать огромные базы данных, научить ИИ усваивать новую информацию в базу данных, разобраться с проблемой поиска информации из этой каши (а иначе как будешь говорить о тенденциях французской мысли и кризисе контркультуры битников с "судьей"?)
В 1972 году Х.Л. Дрейфус публикует книгу, где разоблачил успехи ИИ, а в 1980 Серль добил это все своей критикой, а также мысленным экспериментом "Китайская комната", показав, что даже если машина и будет шикарнейшим образом выдавать правильные реакции, то это не сделает ее сознательным.
Таким образом, Серль выдвинул теорию сильного ИИ (что ИИ можно создать и оно будет вполне себе сознательным и интеллектом) и теорию слабого ИИ (что нельзя создать такую программу, которая будет идентична человеческому разуму).
Мы больше не мечтаем создать исскуственный разум, имитацию человека . для более адекватных понятий были введены термины Сильного и слабого ИИ.
Методы слабого ИИ решают отлично в конкретном ограниченном кроге задач, без упоминания что это является частью искучтвенного разума, прохождения теста Тьюринга, Это дает преимущество что нет разочарований от поставленных целенй и круга решаемых задач слабого интеллекта, т к слабый ИИ не преследует целью создания искусственного человесческого разума.
Область ИИ, которой уже более полувека, наконец-то достигла некоторых из своих самых старых целей. Его начали успешно использовать во всей технологической отрасли, хотя и несколько за кадром. Часть успеха была достигнута за счет увеличения мощности компьютеров, а часть была достигнута за счет сосредоточения внимания на конкретных изолированных проблемах и их решения с соблюдением самых высоких стандартов научной ответственности. Тем не менее, репутация ИИ, по крайней мере, в деловом мире, была далеко не идеальной.Внутри области было мало единого мнения о причинах того, что ИИ не смог осуществить мечту об интеллекте на уровне человека, которая захватила воображение мира в 1960-х годах. Вместе все эти факторы помогли разделить ИИ на конкурирующие подобласти, сосредоточенные на конкретных проблемах или подходах, иногда даже под новыми именами, которые маскировали запятнанную родословную «искусственного интеллекта». ИИ был и более осторожным, и более успешным, чем когда-либо.
2000-2010 годы - развитие ИИ в коммерческих и научных приложениях. В это время ИИ начал широко применяться в коммерческих и научных приложениях, таких как поисковые системы, рекомендательные системы, голосовые помощники и многое другое. Также начали развиваться более сложные технологии, такие как глубокое обучение и обработка больших данных.
Сильный и слабый искусственные интеллекты — гипотеза в философии искусственного интеллекта, согласно которой некоторые формы искусственного интеллекта могут действительно обосновывать и решать проблемы . Теория сильногоискусственного интеллекта предполагает, что компьютеры могут приобрести способность мыслить и осознавать себя, хотя и не обязательно их мыслительный процесс будет подобен человеческому. Теория слабого искусственного интеллекта отвергает такую возможность.
Термин «сильный ИИ» был введен в 1980 году Джоном Серлом (в работе, описывающей мысленный эксперимент «Китайская комната»), впервые охарактеризовавшим его следующим образом:
Соответствующим образом запрограммированный компьютер с нужными входами и выходами и будет разумом, в том смысле, в котором человеческий разум — это разум.
— «Разумы, мозги и программы»
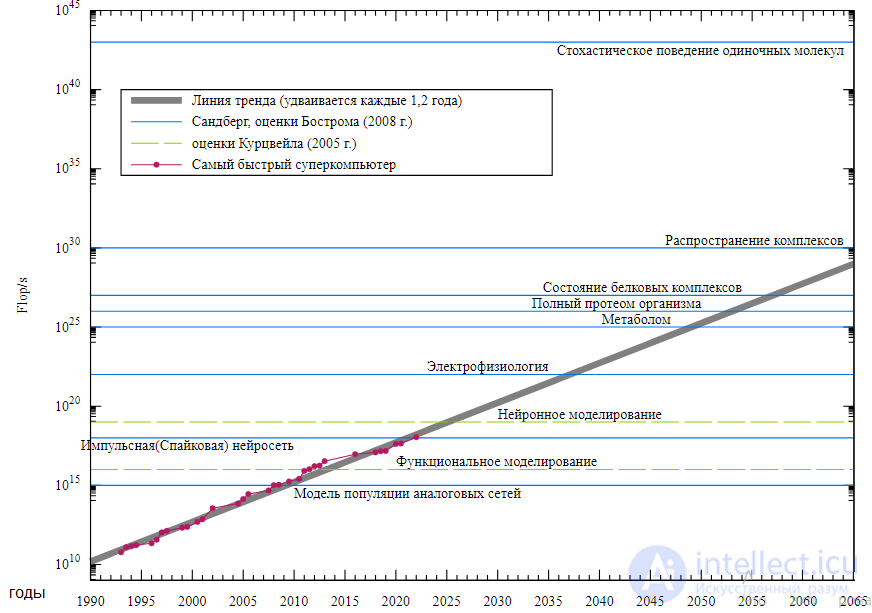
Предлагалось много определений интеллекта (такие, например, как возможность пройти тест Тьюринга), но на настоящий момент нет определения, которое бы удовлетворило всех. Тем не менее, среди исследователей искусственного интеллекта есть общая договоренность о том, что Сильный ИИ обладает следующими свойствами:
Ведутся работы для создания машин, имеющих все эти способности, и предполагается, что Сильный ИИ будет иметь либо их все, либо большую часть из них.
Существуют и другие аспекты интеллекта человека, которые также лежат в основе создания Сильного ИИ:
Ни одно из этих свойств не является необходимым для создания сильного ИИ. Например, неизвестно, необходимо ли воспринимать машине окружающую среду в той же мере, как человеку. Также неизвестно, являются ли эти навыки достаточными для создания интеллекта: если будет создана машина с устройством, которое сможет эмулировать нейронную структуру, подобную мозгу, получит ли она возможность формировать представление о знаниях или пользоваться человеческой речью. Возможно также, что некоторые из этих способностей, такие, например, как сопереживание, возникнут у машины естественным путем, если она достигнет реального интеллекта.
Тест Тьюринга сыграл определенную роль в развитии искусственного интеллекта, в том числе и критика самого теста. Здесь можно провести
аналогию с авиацией. Хорошими летательными аппаратами, по логике теста Тьюринга, должны считаться такие, которые неотличимы от птиц до такой
степени, что даже птицы принимают их за своих. Развитие авиации началось тогда, когда конструкторы перестали копировать птиц, а занялись
аэродинамикой, материаловедением и теорией прочности. Робототехника стала индустрией после того, как перестала копировать анатомию человека.
Аналогично, субъекты искусственного интеллекта получили право на жизнь после того, как прекратились попытки построить системы ИИ,
думающие и действующие подобно людям, а начали строить системы, действующие и думающие рационально, т.е. достигающие наилучшего
результата.
2010-настоящее время - продвижение ИИ в различных сферах жизни. Современные технологии искусственного интеллекта широко применяются в различных областях жизни, таких как медицина, автомобильная промышленность, финансы, образование и другие. Также появляются новые направления в развитии ИИ, такие как автономные транспортные средства, робототехника и квантовый ИИ.
В первые десятилетия 21 века доступ к большим объемам данных (известным как « большие данные »), более дешевые и быстрые компьютеры и передовые методы машинного обучения успешно применялись для решения многих проблем во всей экономике. Фактически, Глобальный институт McKinsey подсчитал в своей знаменитой статье «Большие данные: следующий рубеж инноваций, конкуренции и производительности», что «к 2009 году почти все сектора экономики США имели в среднем не менее 200 терабайт хранимых данных». .
К 2016 году рынок продуктов, оборудования и программного обеспечения, связанных с ИИ, достиг более 8 миллиардов долларов, и New York Times сообщила, что интерес к ИИ достиг «безумия». Применение больших данных стало распространяться и на другие области, такие как обучающие модели в экологии и для различных приложений в экономике . Достижения в области глубокого обучения (особенно глубоких сверточных нейронных сетей и рекуррентных нейронных сетей ) привели к прогрессу и исследованиям в области обработки изображений и видео, анализа текста и даже распознавания речи.
Глубокое обучение — это ветвь машинного обучения, которая моделирует абстракции высокого уровня в данных с использованием глубокого графа со многими слоями обработки. Согласно универсальной теореме аппроксимации , нейронная сеть не нуждается в глубине, чтобы иметь возможность аппроксимировать произвольные непрерывные функции. Тем не менее, есть много проблем, характерных для неглубоких сетей (таких как переобучение ), которых помогают избежать глубокие сети. Таким образом, глубокие нейронные сети способны реалистично генерировать гораздо более сложные модели по сравнению с их неглубокими аналогами.
Однако у глубокого обучения есть свои проблемы. Распространенной проблемой для рекуррентных нейронных сетей является проблема исчезающего градиента , когда градиенты, передаваемые между слоями, постепенно уменьшаются и буквально исчезают по мере округления до нуля. Для решения этой проблемы было разработано много методов, таких как блоки долговременной кратковременной памяти .
Современные архитектуры глубоких нейронных сетей иногда могут даже конкурировать с человеческой точностью в таких областях, как компьютерное зрение, особенно в таких вещах, как база данных MNIST и распознавание дорожных знаков.
Механизмы обработки языка, основанные на интеллектуальных поисковых системах, могут легко обыграть людей в ответах на общие вопросы (например, IBM Watson ), а недавние разработки в области глубокого обучения дали поразительные результаты в конкуренции с людьми в таких вещах, как Go и Doom (которые, будучи шутер от первого лица вызвал споры).
Большие данные — это совокупность данных, которые не могут быть собраны, управляемы и обработаны с помощью обычных программных инструментов в течение определенного периода времени. Это огромное количество возможностей для принятия решений, понимания и оптимизации процессов, которые требуют новых моделей обработки. В эпоху больших данных, написанной Виктором Мейером Шонбергом и Кеннетом Куком , большие данные означают, что вместо случайного анализа (выборочного опроса) для анализа используются все данные. Характеристики 5V больших данных (предложенные IBM): объем , скорость , разнообразие , ценность , достоверность .. Стратегическое значение технологии больших данных заключается не в том, чтобы овладеть огромным объемом данных, а в том, чтобы специализироваться на этих значимых данных. Другими словами, если большие данные уподобить отрасли, ключом к получению прибыльности в этой отрасли является увеличение «возможностей обработки » данных и реализация « добавленной стоимости » данных посредством « обработки ».
Общий интеллект — это способность решать любую проблему, а не находить решение конкретной проблемы. Искусственный общий интеллект (или «AGI») — это программа, которая может применять интеллект для решения самых разных задач почти так же, как люди. [Общий искусственный интеллект также называют «сильным ИИ», или синтетическим интеллектом , в отличие от « слабого ИИ » или «узкого ИИ». (Академические источники резервируют «сильный ИИ» для обозначения машин, способных испытывать сознание.)
Базовые модели , представляющие собой большие модели искусственного интеллекта, обученные на огромном количестве неразмеченных данных, которые можно адаптировать к широкому кругу последующих задач, начали разрабатывать в 2018 году. Такие модели, как GPT -3 , выпущенные OpenAI в 2020 году, и Gato , выпущенные DeepMind в 2022 году были названы важными вехами на пути к общему искусственному интеллекту.
В заключение, эта статья об история искусственного интеллекта подчеркивает важность того что вы тут, расширяете ваше сознание, знания, навыки и умения. Надеюсь, что теперь ты понял что такое история искусственного интеллекта и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Искусственный интеллект. Основы и история. Цели.
Часть 1 История искусственного интеллекта - Основные этапы
Часть 2 Биография - История искусственного интеллекта - Основные этапы
Часть 3 4 этап Краткое возвращение 1980-1984 - История искусственного интеллекта -
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.
Комментарии
Оставить комментарий
Искусственный интеллект. Основы и история. Цели.
Термины: Искусственный интеллект. Основы и история. Цели.