Привет, Вы узнаете о том , что такое две ветви компьютерной эволюции последовательная обработка символов по заданной программе, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
две ветви компьютерной эволюции последовательная обработка символов по заданной программе, параллельное распознавание образов по обучающим ам , настоятельно рекомендую прочитать все из категории Искусственный интеллект. Основы и история. Цели..
Две ветви компьютерной эволюции
Две базовые архитектуры компьютеров — последовательная обработка символов по заданной программе и параллельное распознавание образов по обучающим примерам — появились практически одновременно.
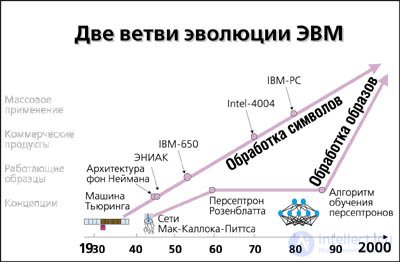
— Концептуально они оформились в 30-40-х годах. Первая — в теоретической работе Тьюринга 1936 г., предложившего гипотетическую машину для формализации понятия вычислимой функции, и затем уже в практической плоскости — в так и не законченном отчете фон Неймана 1945 г. на 101 странице, обобщившего уроки создания первой ЭВМ ENIAC и предложившего методологию конструирования машин с запоминаемыми программами (ENIAC программировался штекерами). Фон Нейман, кстати, использовал не только идеи Тьюринга. Так, в качестве базовых элементов ЭВМ фон Нейман предложил модифицированные формальные нейроны (!) Мак-Каллока и Питтса — основателей нейросетевой архитектуры. В статье, опубликованной в 1943 г., они доказали, что сети из таких пороговых элементов способны решать тот же класс задач, что и машина Тьюринга.
Однако дальнейшая судьба этих вычислительных парадигм напоминает скорее перипетии многочисленных историй про принцев и нищих. Вторая мировая подтолкнула работы по созданию суперкалькулятора.
— Одной из главных задач Лаборатории баллистических исследований Министерства обороны США был расчет баллистических траекторий и составление корректировочных таблиц. Каждая такая таблица содержала более 2 тысяч траекторий, и лаборатория не справлялась с объемом вычислений, несмотря на свой раздувшийся штат: около ста квалифицированных математиков, усиленных несколькими сотнями подсобных вычислителей, окончивших трехмесячные подготовительные курсы. Под давлением этих обстоятельств в 1943 г. армия заключила контракт с Высшим техническим училищем Пенсильванского университета на 400 тысяч долларов для создания первого электронного компьютера ENIAC. Руководили проектом Джон Мочли и Прес Экерт (последнему в день подписания контракта исполнилось 24 года). ENIAC был построен уже после войны. Он потреблял 130 кВт, содержал 18 тысяч ламп, работающих с тактовой частотой 100 кГц, и мог выполнять 300 операций умножения в секунду.
В дальнейшем компьютеры стали широко использоваться и в бизнесе, но именно в этом своем качестве — вычислительных машин. Компьютеры стремительно развивались, идя по пути, начертанному фон Нейманом.
— Первые серийные коммерческие компьютеры IBM-650 появились в 1954 г. (за 15 лет их было продано 1,5 тысячи штук). В том же году был изобретен кремниевый транзистор. В 1961 г. появился его полевой аналог, используемый в микросхемах, а в 1962-м началось массовое производство микросхем. В 1970 г. фирма Intel выпустила свой первый микропроцессор, дав старт микропроцессорной революции 70-х. Всего через четыре года появился первый персональный компьютер Altair по весьма доступной цене 397 долларов, правда, еще в виде набора деталей, подобно тому, как тогда продавались комплекты для радиолюбителей. А в 1977-м появился уже полнофункциональный user-friendly Apple-2. В 1981 г. на рынок PC наконец вышли компьютерные гиганты в лице IBM. В 90-х годах типичный пользователь уже имеет на своем рабочем столе аналог суперкомпьютера Cray-1.
Что касается нейросетевой архитектуры, то, несмотря на многочисленные реверансы в сторону нейронных сетей со стороны классиков кибернетики, их влияние на промышленные разработки вплоть до недавнего времени было минимальным. Хотя в конце 50-х — начале 60-х с этим направлением связывали большие надежды, в основном благодаря Фрэнку Розенблатту, разработавшему первое обучаемое нейросетевое устройство для распознавания образов, персептрон (от английского perception — восприятие).
— Персептрон был впервые смоделирован в 1958 году, причем его обучение требовало около получаса машинного времени на одной из самых мощных в то время ЭВМ IBM-704. Аппаратный вариант — Mark I Perceptron — был построен в 1960 г. и предназначался для распознавания зрительных образов. Его рецепторное поле состояло из матрицы фотоприемников 20x20, и он успешно справлялся с решением ряда задач — мог, например, различать транспаранты некоторых букв.
Тогда же возникли первые коммерческие нейрокомпьютинговые компании. Энтузиазм того героического периода «бури и натиска» был так велик, что многие, увлекшись, предсказывали появление думающих машин в самом ближайшем будущем. Эти пророчества раздувались прессой до совсем уже неприличных масштабов, что, естественно, отталкивало серьезных ученых. Об этом говорит сайт https://intellect.icu . В 1969 году бывший однокашник Розенблатта по Высшей научной школе в Бронксе Марвин Минский, сам в свое время отдавший дань конструированию нейрокомпьютеров, решил положить этому конец, выпустив вместе с южноафриканским математиком Пейпертом книгу «Персептроны». В этой роковой для нейрокомпьютинга книге была строго доказана принципиальная, как тогда казалось, ограниченность персептронов. Утверждалось, что им доступен лишь очень узкий круг задач. В действительности критика относилась лишь к персептрону с одним слоем обучающихся нейронов. Но для многослойных нейронных сетей алгоритм обучения, предложенный Розенблаттом, не годился. Холодный душ критики, умерив пыл энтузиастов, затормозил развитие нейрокомпьютинга на многие годы. Исследования в этом направлении были свернуты вплоть до 1983 года, когда они, наконец, получили финансирование от Агентства перспективных военных исследований США (DARPA). Этот факт стал сигналом к началу нового нейросетевого бума.
Интерес широкой научной общественности к нейросетям пробудился после теоретической работы физика Джона Хопфилда (1982 г.), предложившего модель ассоциативной памяти в нейронных ансамблях. Холфилд и его многочисленные последователи обогатили теорию нейросетей многими идеями из арсенала физики, такими как коллективные взаимодействия нейронов, энергия сети, температура обучения и т. д. Однако настоящий бум практического применения нейросетей начался после публикации в 1986 году Дэвидом Румельхартом с соавторами метода обучения многослойного персептрона, названного ими методом обратного распространения ошибки (error back-propagation). Ограничения персептронов, о которых писали Минский и Пейперт, оказались преодолимыми, а возможности вычислительной техники — достаточными для решения широкого круга прикладных задач. В 90-х годах производительность последовательных компьютеров возросла настолько, что это позволило моделировать с их помощью работу параллельных нейронных сетей с числом нейронов от нескольких сотен до десятков тысяч. Такие эмуляторы нейросетей способны решать многие интересные с практической точки зрения задачи. В свою очередь, нейросетевые программные комплексы станут тем носителем, который выведет на технологическую орбиту настоящее параллельное нейросетевое hardware.
Две парадигмы вычислений
Еще на заре компьютерной эры — до появления первых ЭВМ — были намечены два принципиально разных подхода к обработке информации: последовательная обработка символов и параллельное распознавание образов. В контексте данной статьи как символы, так и образы — это «слова», которыми оперируют вычислительные машины, их отличие — лишь в размерности. Информационная емкость образа может на многие порядки превосходить число бит, которыми описываются символы. Но это чисто количественное различие имеет далеко идущие качественные последствия в силу экспоненциально быстрого возрастания сложности обработки данных с ростом их разрядности.
Так, можно строго описать все возможные операции над относительно короткими символами. Значит, можно сделать устройство — процессор -, предсказуемым образом обрабатывающее любой поступивший на вход символ — команду или данные. Если теперь удастся свеТак, можно строго описать все возможные операции над относительно короткими символами. Значит, можно сделать устройство — процессор -, предсказуемым образом обрабатывающее любой поступивший на вход символ — команду или данные. Если теперь удастся свести сложную задачу к перечисленным базовым операциям такого процессора — написать алгоритм ее решения, — то можно поручить ее выполнение компьютеру, избавляясь тем самым от утомительной рутинной работы. Оказывается, что любой сколь угодно сложный алгоритм можно запрограммировать на элементарно простых процессорах. [2]
Описать же все операции над многобитными образами принципиально невозможно, ибо длина описания растет экспоненциально. Следовательно, любой «процессор образов» всегда специализирован — задание на его разработку представлено заведомо неполной таблицей преобразований образов, как правило, содержащей ничтожную часть возможных сочетаний входов-выходов. Во всех остальных ситуациях его поведение не специфицировано. Процессор должен «додумать» свое поведение, обобщить имеющиеся обучающие примеры таким образом, чтобы и на тех примерах, которые не встречались в процессе обучения, его поведение было бы «в приемлемой степени аналогичным».
Таким образом, различие между последовательными и параллельными вычислениями гораздо глубже, чем просто большая или меньшая продолжительность вычислений. За этим различием стоят совершенно разные методологии, способы постановки и решения информационных задач. Осталось добавить, что первым путем идут знакомые нам фон-неймановские компьютеры, а второй путь, вслед за естественными нейронными ансамблями мозга, выбран нейрокомпьютингом.
Чтобы вписать нейрокомпьютинг в общую картину эволюции вычислительных машин, рассмотрим эти две парадигмы в историческом контексте. Давно известен факт «встречной направленности» биологической и компьютерной эволюций. Человек сначала научается распознавать зрительные образы и двигаться, затем говорить, считать, и наконец, самое сложное, — приобретает способность логически мыслить абстрактными категориями. Компьютеры же, наоборот, сначала освоили логику и счет, потом научились играть в игры и лишь с большим трудом подходят к проблемам распознавания речи, обработки сенсорных образов и ориентации в пространстве. Чем объясняется такое различие?
Последовательная обработка символов
Первые ЭВМ обязаны своим появлением не только гению ученых, но и в не меньшей степени давлению обстоятельств. Вторая мировая война потребовала решения сложных вычислительных задач. Нужны были суперкалькуляторы, какими и стали первые ЭВМ.
При тогдашней дороговизне hardware выбор последовательной архитектуры, принципы которой были сформулированы в знаменитом отчете фон Неймана 1945 года, был, пожалуй, единственно возможным. И этот выбор на несколько десятилетий определил основное занятие ЭВМ: решение формализованных задач. Разделение труда между компьютером и человеком закрепилось по формуле: «человек программирует алгоритмы — компьютер их исполняет».
Тем временем прогресс полупроводниковых интегральных технологий обеспечил несколько десятилетий экспоненциального роста производительности фон-неймановских компьютеров, в основном за счет увеличения тактовой частоты, и в меньшей степени — за счет использования параллелизма. Если тактовая частота растет обратно пропорционально размеру вентилей на чипе, то есть пропорционально корню квадратному числа элементов, то число входов-выходов — всего лишь как корень пятой степени. Этот факт отражен в эмпирическом законе Рента: число вентилей в процессоре пропорционально примерно 5-й степени от числа его входов-выходов (Д. Ферри, Л. Эйкерс, Э. Гринич, «Электроника ультрабольших интегральных схем», М.: «Мир», 1991). Поэтому кардинальное увеличение разрядности процессоров при сохранении существующих ныне схемотехнических принципов невозможно. Обработка действительно сложной — образной -информации должна базироваться на принципиально иных подходах. Поэтому-то мы и не имеем пока систем искусственного зрения, хоть как-то сопоставимых по своим возможностям с их природными прототипами.
Параллельная обработка образов
Распознавание сенсорной информации и выработка адекватной реакции на внешние воздействия — вот главная эволюционная задача биологических компьютеров, от простейших нервных систем моллюсков до мозга человека. Не выполнение внешних алгоритмов, а выработка собственных в процессе обучения. Обучение представляет собой процесс самоорганизации распределенной вычислительной среды — нейронных ансамблей. В распределенных нейронных сетях происходит параллельная обработка информации, сопровождающаяся постоянным обучением, направляемым результатами этой обработки.
Лишь постепенно в ходе эволюции биологические нейронные сети научились осуществлять достаточно длинные логические цепочки — эмулировать логическое мышление. Распознавание же образов вовсе не предполагает логического обоснования. Как правило, каждый мужчина легко различит мелькнувшую в толпе симпатичную девушку. Но кто из них рискнет предложить алгоритм оценки женской красоты? Да и существует ли вообще такой алгоритм? Кто формализует эту задачу, и кому это вообще нужно? Эволюция не решает формализованных задач, не рассуждает, она лишь отбраковывает неверные решения. Элиминация ошибок — основа любого обучения, и в эволюции, и в мозге, и в нейрокомпьютерах.
Но зададимся, наконец, вопросом: как именно работают нейрокомпьютеры? Устройство мозга слишком сложно. Искусственные нейросети проще — они «пародируют» работу мозга, как и положено любым научным моделям сложных систем. Главное, что объединяет мозг и нейрокомпьютеры, — нацеленность на обработку образов. Оставим в стороне биологические прототипы и сосредоточимся на базовых принципах распределенной обработки данных.
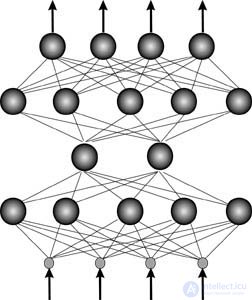
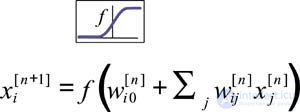
Коннекционизм
Отличительной чертой нейросетей является глобальность связей. Базовые элементы искусственных нейросетей — формальные нейроны — изначально нацелены на работу с векторной информацией. Каждый нейрон нейросети, как правило, связан со всеми нейронами предыдущего слоя обработки данных (см. рис.).
Специализация же связей возникает лишь на этапе их настройки — обучения на конкретных данных. Архитектура процессора или, что то же самое, алгоритм решения конкретной задачи проявляется, подобно фотоснимку, по мере обучения.
Каждый формальный нейрон производит простейшую операцию — взвешивает значения своих входов со своими же локально хранимыми синаптическими весами и производит над их суммой нелинейное преобразование:
Нелинейность выходной функции активации принципиальна. Если бы нейроны были линейными элементами, то любая последовательность нейронов также производила бы линейное преобразование, и вся нейросеть была бы эквивалентна одному слою нейронов. Нелинейность разрушает линейную суперпозицию и приводит к тому, что возможности нейросети существенно выше возможностей отдельных нейронов. [
Выводы из данной статьи про две ветви компьютерной эволюции последовательная обработка символов по заданной программе указывают на необходимость использования современных методов для оптимизации любых систем. Надеюсь, что теперь ты понял что такое две ветви компьютерной эволюции последовательная обработка символов по заданной программе, параллельное распознавание образов по обучающим ам
и для чего все это нужно, а если не понял, или есть замечания,
то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Искусственный интеллект. Основы и история. Цели.
Комментарии
Оставить комментарий
Искусственный интеллект. Основы и история. Цели.
Термины: Искусственный интеллект. Основы и история. Цели.