Лекция
Сразу хочу сказать, что здесь никакой воды про генетические алгоритмы, и только нужная информация. Для того чтобы лучше понимать что такое генетические алгоритмы , настоятельно рекомендую прочитать все из категории Эволюционные алгоритмы.
Генети́ческий алгори́тм (англ. genetic algorithm) — это эвристический алгоритм поиска, используемый для решения задач оптимизации и моделирования путем случайного подбора, комбинирования и вариации искомых параметров с использованием механизмов, аналогичных естественному отбору в природе. Является разновидностью эволюционных вычислений, с помощью которых решаются оптимизационные задачи с использованием методов естественной эволюции, таких какнаследование, мутации, отбор и кроссинговер. Отличительной особенностью генетического алгоритма является акцент на использование оператора «скрещивания», который производит операцию рекомбинации решений-кандидатов, роль которой аналогична роли скрещивания в живой природе.
Первые работы по симуляции эволюции были проведены в 1954 году Нильсом Баричелли на компьютере установленном в Институте Продвинутых Исследований Принстонского университета. Его работа, опубликованная в том же году, привлекла широкое внимание общественности. С 1957 года, австралийский генетикАлекс Фразер опубликовал серию работ по симуляции искусственного отбора среди организмов с множественным контролем измеримых характеристик. Положенное начало позволило компьютерной симуляции эволюционных процессов и методам, описанным в книгах Фразера и Барнелла(1970) и Кросби (1973). , с 1960-х годов стать более распространенным видом деятельности среди биологов. Симуляции Фразера включали все важнейшие элементы современных генетических алгоритмов. Вдобавок к этому, Ганс-Иоахим Бремерманн в 1960-х опубликовал серию работ, которые также принимали подход использования популяции решений, подвергаемой рекомбинации, мутации и отбору, в проблемах оптимизации. Исследования Бремерманна также включали элементы современных генетических алгоритмов. Среди прочих пионеров следует отметить Ричарда Фридберга, Джорджа Фридмана и Майкла Конрада. Множество ранних работ были переизданы Давидом Б. Фогелем (1998).
Хотя Баричелли в своей работе 1963 года симулировал способности машины играть в простую игру, искусственная эволюция стала общепризнанным методом оптимизации после работы Инго Рехенберга и Ханса-Пауля Швефеля в 1960-х и начале 1970-х годов двадцатого века — группа Рехенсберга смогла решить сложные инженерные проблемы согласно стратегиям эволюции. [10][11][12] Другим подходом была техника эволюционного программирования Лоренса Дж. Фогеля, которая была предложена для создания искусственного интеллекта. Эволюционное программирование первоначально использовавшее конечные автоматы для предсказывания обстоятельств, и использовавшее разнообразие и отбор для оптимизации логики предсказания. генетические алгоритмы стали особенно популярны благодаря работе Джона Холланда в начале 70-х годов и его книге «Адаптация в естественных и искусственных системах» (1975)[13]. Его исследование основывалось на экспериментах с клеточными автоматами, проводившимися Холландом и на его трудах написанных в университете Мичигана. Холланд ввел формализованный подход для предсказывания качества следующего поколения, известный как Теорема схем. Исследования в области генетических алгоритмов оставались в основном теоретическими до середины 80-х годов, когда была наконец проведена Первая международная конференция по генетическим алгоритмам в Питтсбурге, Пенсильвания (США).
С ростом исследовательского интереса существенно выросла и вычислительная мощь настольных компьютеров, это позволило использовать новую вычислительную технику на практике. В конце 80-х, компания General Electric начала продажу первого в мире продукта, работавшего с использованием генетического алгоритма. Им стал набор промышленных вычислительных средств. В 1989, другая компания Axcelis, Inc. выпустила Evolver — первый в мире коммерческий продукт на генетическом алгоритме для настольных компьютеров. Журналист The New York Times в технологической сфере Джон Маркофф писал[14] об Evolver в 1990 году.
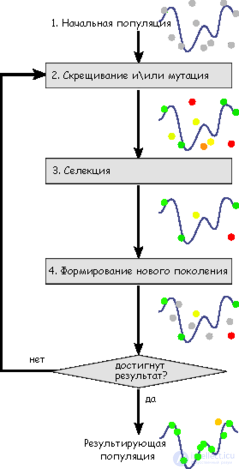
Задача формализуется таким образом, чтобы ее решение могло быть закодировано в виде вектора («генотипа») генов, где каждый ген может быть битом, числом или неким другим объектом. Об этом говорит сайт https://intellect.icu . В классических реализациях ГА предполагается, что генотип имеет фиксированную длину. Однако существуют вариации ГА, свободные от этого ограничения.
Некоторым, обычно случайным, образом создается множество генотипов начальной популяции. Они оцениваются с использованием «функции приспособленности», в результате чего с каждым генотипом ассоциируется определенное значение («приспособленность»), которое определяет насколько хорошо фенотип, им описываемый, решает поставленную задачу.
При выборе «функции приспособленности» (или fitness function в англоязычной литературе) важно следить, чтобы ее «рельеф» был «гладким».
Из полученного множества решений («поколения») с учетом значения «приспособленности» выбираются решения (обычно лучшие особи имеют большую вероятность быть выбранными), к которым применяются «генетические операторы» (в большинстве случаев «скрещивание» — crossover и «мутация» — mutation), результатом чего является получение новых решений. Для них также вычисляется значение приспособленности, и затем производится отбор («селекция») лучших решений в следующее поколение.
Этот набор действий повторяется итеративно, так моделируется «эволюционный процесс», продолжающийся несколько жизненных циклов (поколений), пока не будет выполнен критерий остановки алгоритма. Таким критерием может быть:
Генетические алгоритмы служат, главным образом, для поиска решений в многомерных пространствах поиска.
Таким образом, можно выделить следующие этапы генетического алгоритма:
Перед первым шагом нужно случайным образом создать начальную популяцию; даже если она окажется совершенно неконкурентоспособной, вероятно, что генетический алгоритм все равно достаточно быстро переведет ее в жизнеспособную популяцию. Таким образом, на первом шаге можно особенно не стараться сделать слишком уж приспособленных особей, достаточно, чтобы они соответствовали формату особей популяции, и на них можно было подсчитать функцию приспособленности (Fitness). Итогом первого шага является популяция H, состоящая из N особей.
Размножение в генетических алгоритмах обычно половое — чтобы произвести потомка, нужны несколько родителей, обычно два.
Размножение в разных алгоритмах определяется по-разному — оно, конечно, зависит от представления данных. Главное требование к размножению — чтобы потомок или потомки имели возможность унаследовать черты обоих родителей, «смешав» их каким-либо способом.
Почему особи для размножения обычно выбираются из всей популяции H, а не из выживших на первом шаге элементов H0 (хотя последний вариант тоже имеет право на существование)? Дело в том, что главный бич многих генетических алгоритмов — недостаток разнообразия (diversity) в особях. Достаточно быстро выделяется один-единственный генотип, который представляет собой локальный максимум, а затем все элементы популяции проигрывают ему отбор, и вся популяция «забивается» копиями этой особи. Есть разные способы борьбы с таким нежелательным эффектом; один из них — выбор для размножения не самых приспособленных, но вообще всех особей.
К мутациям относится все то же самое, что и к размножению: есть некоторая доля мутантов m, являющаяся параметром генетического алгоритма, и на шаге мутаций нужно выбрать mN особей, а затем изменить их в соответствии с заранее определенными операциями мутации.
На этапе отбора нужно из всей популяции выбрать определенную ее долю, которая останется «в живых» на этом этапе эволюции. Есть разные способы проводить отбор. Вероятность выживания особи h должна зависеть от значения функции приспособленности Fitness(h). Сама доля выживших s обычно является параметром генетического алгоритма, и ее просто задают заранее. По итогам отбора из N особей популяции H должны остаться sN особей, которые войдут в итоговую популяцию H'. Остальные особи погибают.
Существует несколько поводов для критики насчет использования генетического алгоритма по сравнению с другими методами оптимизации:
Имеется много скептиков относительно целесообразности применения генетических алгоритмов. Например, Стивен С. Скиена, профессор кафедры вычислительной техники университета Стоуни—Брук, известный исследователь алгоритмов, лауреат премии института IEEE, пишет[16]:
 |
Я лично никогда не сталкивался ни с одной задачей, для решения которой генетические алгоритмы оказались бы самым подходящим средством. Более того, я никогда не встречал никаких результатов вычислений, полученных посредством генетических алгоритмов, которые производили бы на меня положительное впечатление. |  |
Генетические алгоритмы применяются для решения следующих задач:
Поиск в одномерном пространстве, без скрещивания.
#include <cstdlib>
#include <ctime>
#include <algorithm>
#include <iostream>
#include <numeric>
int main()
{
srand((unsigned int)time(NULL));
const size_t N = 1000;
int a[N] = { 0 };
for ( ; ; )
{
//мутация в случайную сторону каждого элемента:
for (size_t i = 0; i < N; ++i)
a[i] += ((rand() % 2 == 1) ? 1 : -1);
//теперь выбираем лучших, отсортировав по возрастанию
std::sort(a, a + N);
//и тогда лучшие окажутся во второй половине массива.
//скопируем лучших в первую половину, куда они оставили потомство, а первые умерли:
std::copy(a + N / 2, a + N, a);
//теперь посмотрим на среднее состояние популяции. Как видим, оно все лучше и лучше.
std::cout << std::accumulate(a, a + N, 0) / N << std::endl;
}
}
Поиск в одномерном пространстве с вероятностью выживания, без скрещивания. (проверено на Delphi XE)
program Program1;
{$APPTYPE CONSOLE}
{$R *.res}
uses
System.Generics.Defaults,
System.Generics.Collections,
System.SysUtils;
const
N = 1000;
Nh = N div 2;
var
A: array [1..N] of Integer;
I, R, C, Points, BirthRate: Integer;
Iptr: ^Integer;
begin
Randomize;
// Частичная популяция
for I := 1 to N do
A[I] := Random(2);
repeat
// Мутация
for I := 1 to N do
A[I] := A[I] + (-Random(2) or 1);
// Отбор, лучшие в конце
TArray.Sort<Integer>(A, TComparer<Integer>.Default);
// Предустановка
Iptr := Addr(A[Nh + 1]);
Points := 0;
BirthRate := 0;
// Результаты скрещивания
for I := 1 to Nh do
begin
Inc(Points, Iptr^);
// Случайный успех скрещивания
R := Random(2);
Inc(BirthRate, r);
A[I] := Iptr^ * R;
Iptr^ := 0;
Iptr := Ptr(Integer(Iptr) + SizeOf(Integer));
end;
// Промежуточный итог
Inc(C);
until (Points / N >= 1) or (C = High(Integer));
Writeln(Format('Population %d (rate: %f) score: %f', [C, BirthRate / N, Points / N]));
end.
А как ты думаешь, при улучшении генетические алгоритмы, будет лучше нам? Надеюсь, что теперь ты понял что такое генетические алгоритмы и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Эволюционные алгоритмы

Комментарии