Привет, Вы узнаете о том , что такое восприятие звуков у животных, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
восприятие звуков у животных , настоятельно рекомендую прочитать все из категории Сравнительная психология и Зоопсихология.
Мы привыкли считать, что основной «канал», через который звук попадает в мозг — это уши. Практически все животные, с которыми мы сталкиваемся в повседневной жизни или видим в зоопарках, реагируют на наше присутствие поворотом ушей — коты, собаки, слоны или фенеки.
Есть и звери, у которых ушей нет. Это не делает их глухими. Диапазон звуков, которые могут воспринимать некоторые животные, сильно отличается от «человеческого». Обо всем этом продолжим говорить под катом.
Если нет ушей у животных, то как они ощущают звуки?
Кузнечики, как и сверчки, в качестве аудиоканала используют передние лапки, на которых находится чувствительная мембрана. Этот «сенсор» может воспринять звуковые волны с амплитудой равной диаметру атома водорода. Кузнечики некоторых видов способны почувствовать минимальные изменения окружающей обстановки, в том числе и сейсмическую активность, и перебраться в безопасное для себя место задолго до землетрясений.
У рыб тоже нет ушей в привычном понимании (наверняка, если бы они были, то обтекаемая форма тела была бы сильно нарушена). Но слух у этих водных обитателей прекрасный: рыбы чувствуют колебания звука с помощью мелких отверстий, которые идут вдоль всего тела от головы до хвоста. Все звуковые волны, которые ловят эти рецепторы, преобразуются в импульсы, далее они поступают на плавательный пузырь. Этот орган, выступающий в качестве усилителя звука, передает его во внутреннее ухо (которое по строению очень схоже с человеческим), а дальше сигнал обрабатывается мозгом.
А киты вообще получают аудиоинформацию через горло, а затем через специальный канал, ведущий к внутреннему уху. Хотя, согласно альтернативной версии, у китов есть слуховое отверстие, которое открывается позади глаза.
У крокодила уши есть, но их не видно, так как его ушная раковина закрывается перепонкой во время погружения в воду. Сами слуховые отверстия снаружи защищены костным выступом. Среднее ухо у крокодилов представлено только одной костью — стремечком, оно и проводит звук ко внутреннему уху. Некоторые ученые считают, что крокодилы прекрасно слышат под водой, хотя, вероятно, они просто воспринимают колебания воды своими осязательными рецепторами.
Муравьи в восприятии звука немного похожи на кузнечиков: у них есть специальные сенсоры на лапках и усиках, которые улавливают изменения вибраций. При этом муравьи чувствуют вибрации не только в воздухе, но и через поверхности — деревья, листья и т.д. Органы слуха муравья не нуждаются в раковинах, как, например, человеческое ухо, так как муравьям нет необходимости улавливать пролетающие по воздуху звуковые волны. Для восприятия аудиоинформации у муравьев есть так называемые сколопидии, похожие на струны органы, натянутые между скелетом насекомого и мембраной. Эта система превращает колебания и вибрации в нервные импульсы.
Как они слышат животные музыку
Признайтесь, те, у кого дома есть кот или собака, хотя бы раз в жизни пытались оценить реакцию своего питомца на звучание той или иной композиции или фильма. Ученые всерьез задумались над вопросом о том, как воспринимают музыку животные и точно сошлись в одном: они, как и мы, могут разделять музыку на ту, которая им нравится и на ту, которая им неприятна.
Зоопсихологи обращают внимание на то, что более точного ответа получить просто невозможно, потому что даже люди воспринимают музыку по-разному. Диапазон восприятия звука у животных другой, и не стоит забывать об эмоциях и ассоциациях, которые вызывает та или иная музыка. (Мы уже писали о том, как музыка работает с человеческими эмоциями).
Ветеринар Чарльз Сноудон (Charles Snowdon) утверждает, что животные слышат музыку не так, как мы. Слух у питомцев гораздо острее нашего, и диапазон восприятия звуков у собак и кошек шире, чем у человека. Поэтому животные не «различают» (в привычном нам понимании) рок, регги или хип-хоп. Для них человеческая музыка — это целый океан звуков и шумов, не всегда приятных — и не всегда слышимых самим человеком.
Но вот американский композитор Дэвид Теи (David Teie) сочинил расслабляющую музыку для кошек. Газета Washington Post сразу же провела эксперимент ( https://www.washingtonpost.com/video/entertainment/listen-this-music-is-scientifically-proved-to-appeal-to-cats/2015/10/15/31ec6f54-6e9b-11e5-91eb-27ad15c2b723_video.html и проверила, как животные реагируют на такую музыку.
В своих «кошачьих» сочинениях Теи, например, сэмплирует звук малого барабана и ускоряет его до частоты кошачьего урчания. Как считает сам композитор, если просто записать что-то, похожее на мурлыканье, то пушистая аудитория быстро теряет интерес. Поэтому Теи пытается «пощекотать им мозги», чтобы кошки подумали: «Не знаю, что это, но мне это определенно нравится!».
Композитор изучил осциллограммы кошачьего урчания и выяснил, что каждый отдельный звук состоит из двух: сдвоенные удары, похожие на учащенное сердцебиение. Человек их не слышит, но кошки слышат.
Затем поверх «мурлыкающих» была наложена «партия мяукающих котят» в очень высоком диапазоне. Теи сыграл две ноты на скрипке, а затем на компьютере транспонировал их на две октавы вверх. Кстати, виолончель в «музыке для кошек» дает возможность наслаждаться такими произведениями и людям, но сначала надо привыкнуть к фоновому урчанию.
Виолончелист Теи пишет музыку для кошек с 2003 года, таким необычным способом он хочет сформулировать свою Универсальную теорию музыки, в соответствии с которой, музыка, минуя сознание, затрагивает глубинные эмоции, используя для этого звуки, которые окружают плод в утробе матери, когда мозг еще не сформировался.
Эта музыка, по его мнению, одинаково действует и для людей, и для животных. Как считает Теи, нет никакого случайного совпадения в том, что музыка, которую человек считает расслабляющей, совпадает по темпу с пульсом его матери в состоянии покоя, а звуковой спектр скрипки — самого популярного классического инструмента — совпадает со спектром женского голоса. Он даже провел эксперимент на обезьянах и опубликовал подробный отчет.
Так Дэвид Теи, спустя несколько лет, записал первый альбом расслабляющей музыки для кошек, эффективность которого проверял на животных в котокафе «Кошки и усики». До сих пор неясно, какие эмоции вызывает эта музыка в кошках, но промо-ролик для котомузыки вышел очень трогательный.
Поэтому теперь, уходя из дома, стоит включать своим питомцам не Guns N’ Roses — лучше воспользоваться изобретением Дэвида Теи и не травмировать мохнатые уши.
Многие люди замечали, что собаки, слыша какую-либо музыку, могут подвывать, скулить и выть. Эксперименты показывают, что слушая одну и ту же музыку через усилитель с колонками или в наушниках, собаки одинаково реагируют на нее. Скорее всего, музыка нравиться животному, если оно не проявляет агрессию и сидит спокойно. А используя наушники можно порадовать своего домашнего питомца, когда окружающие не хотят слушать громкую музыку. Для этого лучше использовать накладные облегченные наушники закрытого типа. Хорошо, если есть возможность телескопической регулировки оголовья
В отличие от человека, животные не воспринимают музыкальную композицию как что-то целое и единое. Они слышат определенные звуки, которые, зачастую, приятны для их слуха. Также у животных развито чувство ритма, что способствует их дрессировке. Под определенную музыку они способны воспроизводить движения, отработанные на тренировках. Поскольку собаки могут слышать высокочастотные звуки, при их дрессировке применяются специальные свистки.
Воздействие музыки на животных не всегда положительное. Тяжелая агрессивная музыка у куриц вызывает приступ истерии, а у коров снижает удои. Слоны вообще не терпят такую музыку и могут покинуть свой дом. Современная музыка может вызвать у животных приступ паники и невроза. Забавный случай произошел с собакой лондонского органиста на репетиции хора. Собака громко рычала на хористов, которые фальшивили, чем заслужила внимание известного композитора Эдуарда Уильяма Эдгара. Он посвятил замечательной собаке одну из энигма-вариаций.
Классификация звуков домашних кошек с использованием особенностей, полученных из глубоких нейронных сетей
Домашняя кошка ( Feliscatus ) - одно из самых привлекательных домашних животных в мире, и она издает загадочные звуки в зависимости от своего настроения и ситуации. В этой статье мы имеем дело с автоматической классификацией кошачьих звуков с помощью машинного обучения. Подход машинного обучения для классификации требует данных с пометкой классов, поэтому наша работа начинается с создания небольшого набора данных с именем CatSound.по 10 категориям. Наряду с исходным набором данных мы увеличиваем объем данных с помощью различных методов увеличения аудиоданных, чтобы помочь нашей задаче классификации. В этом исследовании мы используем два типа изученных функций из глубоких нейронных сетей; один из предварительно обученной сверточной нейронной сети (CNN) на музыкальных данных путем передачи обучения, а другой из неконтролируемой сверточной сети глубоких убеждений, которая (CDBN) обучается исключительно на собранном наборе звуков кошек. В дополнение к обычному GAP мы предлагаем эффективный метод объединения под названием FDAP для изучения ряда важных функций. В FDAP измерение частоты грубо делится, а затем в каждом делении применяется среднее объединение. Для классификации мы использовали пять различных алгоритмов машинного обучения и их множество. Мы сравниваем характеристики классификации по следующим факторам: объем данных, увеличенный за счет увеличения, изученные функции из предварительно обученной CNN или неконтролируемой CDBN, обычного GAP или FDAP и алгоритмов машинного обучения, используемых для классификации. Как и ожидалось, предлагаемые функции FDAP с большим объемом данных, увеличенным за счет дополнения в сочетании с ансамблевым подходом, дали наилучшую точность. Более того, как изученные функции из предварительно обученного CNN, так и неконтролируемого CDBN дают хорошие результаты в эксперименте. Таким образом, с комбинацией всех этих положительных факторов мы получили лучший результат: 91,13% по точности, 0,91 по шкале f1 и 0,995 по шкале площади под кривой (AUC). изученные функции из предварительно обученной CNN или неконтролируемой CDBN, обычного GAP или FDAP, а также алгоритмов машинного обучения, используемых для классификации. Как и ожидалось, предлагаемые функции FDAP с большим объемом данных, увеличенным за счет дополнения в сочетании с ансамблевым подходом, дали наилучшую точность. Более того, как изученные функции из предварительно обученного CNN, так и неконтролируемого CDBN дают хорошие результаты в эксперименте. Таким образом, с комбинацией всех этих положительных факторов мы получили лучший результат: 91,13% по точности, 0,91 по шкале f1 и 0,995 по шкале площади под кривой (AUC). изученные функции из предварительно обученной CNN или неконтролируемой CDBN, обычного GAP или FDAP, а также алгоритмов машинного обучения, используемых для классификации. Как и ожидалось, предлагаемые функции FDAP с большим объемом данных, увеличенным за счет дополнения в сочетании с ансамблевым подходом, дали наилучшую точность. Более того, как изученные функции из предварительно обученного CNN, так и неконтролируемого CDBN дают хорошие результаты в эксперименте. Таким образом, с комбинацией всех этих положительных факторов мы получили лучший результат: 91,13% по точности, 0,91 по шкале f1 и 0,995 по шкале площади под кривой (AUC). Предлагаемые функции FDAP с большим объемом данных, увеличенных за счет дополнения в сочетании с ансамблевым подходом, дали лучшую точность. Более того, как изученные функции из предварительно обученного CNN, так и неконтролируемого CDBN дают хорошие результаты в эксперименте. Таким образом, с комбинацией всех этих положительных факторов мы получили лучший результат: 91,13% по точности, 0,91 по шкале f1 и 0,995 по шкале площади под кривой (AUC). Предлагаемые функции FDAP с большим объемом данных, увеличенных за счет дополнения в сочетании с ансамблевым подходом, дали лучшую точность. Более того, как изученные функции из предварительно обученного CNN, так и неконтролируемого CDBN дают хорошие результаты в эксперименте. Таким образом, с комбинацией всех этих положительных факторов мы получили лучший результат: 91,13% по точности, 0,91 по шкале f1 и 0,995 по шкале площади под кривой (AUC).
1. Введение
Системы звукообразования и восприятия животных эволюционировали, чтобы помочь им выжить в окружающей среде. С эволюционной точки зрения намеренные звуки, издаваемые животными, должны отличаться от случайных звуков окружающей среды. Некоторые животные обладают особыми сенсорными способностями, такими как зрение, зрение, чувство и осведомленность о естественных изменениях по сравнению с людьми. Звуки животных могут быть полезны для людей с точки зрения безопасности, предсказания стихийных бедствий и интимного общения, если мы сможем их правильно распознать.
В последние годы машинное обучение на основе данных для акустического сигнала представляет большой интерес для исследователей, и были проведены некоторые исследования по классификации звуков животных [ 1 , 2 ] и идентификации популяций животных на основе их звуковых характеристик [ 3 ]. Звуковая классификация морских млекопитающих и ее влияние на морскую жизнь изучались в [ 4 , 5 ]. Несколько исследований [ 6 , 7 , 8 , 9 , 10 , 11 , 12 ] были сосредоточены на идентификации, классификации звука птиц и связанных с этим проблемах. В исследовании [ 13] провел классификацию видов насекомых на основе их звуковых сигналов. Предсказание необычного звукового поведения животных во время землетрясения и стихийного бедствия было изучено с использованием методов машинного обучения в [ 14 ]. Недавно возможность переноса обучения по музыкальным особенностям для идентификации птичьего звука с использованием скрытых марковских моделей (HMM) была исследована в [ 15 ].
Домашние животные - близкие друзья человека со времен человеческой эволюции, и они передают свои сообщения, издавая некоторые идентичные звуки. Большинство домашних животных проводят все свое время на периферии человека, поэтому важен тщательный анализ домашних животных. Домашняя кошка - одно из самых любимых домашних животных в мире, и согласно отчету Live Science (2013), общая популяция составляет около 88,3 миллиона человек. Поведенческий анализ домашней кошки хорошо объясняется в [ 16 , 17 ].
Попытка распознавания звуков окружающей среды с использованием HMM [ 18 ] показывает классификацию 15 классов различных звуков окружающей среды. Среди 15 классов также есть звуки животных (крик птиц, лай собак и мяуканье кошек), которые демонстрируют лучшую точность распознавания звука с использованием универсального моделирования, основанного на кластеризации GMM, а не простого HMM и сбалансированного универсального моделирования. Классификация звуков домашних кошек с использованием трансферного обучения [ 19 ] является первым шагом к классификации звуков кошек с ограниченными данными. Классификация кошачьих звуков - это попытка лучше общаться с домашней кошкой и, следовательно, возможно, лучше понять их намерения.
Эта статья является расширением [ 19 ], в которой особое внимание уделяется работе с небольшими наборами данных для автоматической классификации звуков домашних кошек с использованием алгоритмов машинного обучения. Подходы, основанные на данных, требуют данных с пометкой классов, поэтому наша работа начинается с создания небольшого набора данных о звуках кошек. Наша цель - создать систему классификации домашних кошек общего назначения, не зависящую от таких факторов, как биоразнообразие, видовые и возрастные вариации, поэтому мы стараемся включать множество звуков кошек в разных настроениях. Поскольку набора собранных данных недостаточно, мы увеличиваем объем данных с помощью различных методов увеличения звука. Как в [ 20], усиление звука выполняется путем случайного выбора методов увеличения в соответствующих диапазонах значений параметров, как описано более подробно в Разделе 3.1 .
Поскольку мало известно о том, какие звуковые функции эффективны для нашей цели, вместо функций, созданных вручную, мы используем два типа изученных функций из глубоких нейронных сетей: сверточную нейронную сеть (CNN) и сверточную сеть глубоких убеждений (CDBN). Функции CNN получены из предварительно обученной сети на музыкальных данных путем передачи обучения. Между тем, неконтролируемые сетевые функции CDBN извлекаются из сети, обученной исключительно на собранном наборе звуков кошек без меток классов. Мы сравниваем две сети с их изученными особенностями с точки зрения эффективности классификации звуков кошек.
Мы пытаемся классифицировать кошачьи звуки, используя пять различных алгоритмов машинного обучения, и, наконец, объединяем их прогнозы, чтобы сделать производительность более надежной. Каждый из этих пяти алгоритмов эффективен для задач классификации и требует меньше размеченных данных для обучения из-за небольшого количества параметров. Звуки кошек в каждом классе имеют разную природу, которая в основном различается по частотным диапазонам. Чтобы сделать нашу классификацию более эффективной, мы также модифицируем обычное объединение глобального среднего значения для уменьшения размерности и называем его объединением среднего значения частотного разделения (FDAP). FDAP сначала делит каждую карту характеристик на разные полосы частот и берет среднее значение в каждой полосе.
Для классификации мы используем пять различных алгоритмов машинного обучения и их множество. Мы сравниваем характеристики классификации по следующим факторам: объем данных, увеличенный за счет дополнения, изученные функции из предварительно обученной CNN или неконтролируемой CDBN, обычного глобального среднего пула (GAP) или FDAP, пяти различных алгоритмов машинного обучения и их совокупности. Как мы и ожидали, функции FDAP с данными, увеличенными с помощью дополнения, обеспечивают лучшую точность в ансамблевом подходе. Кроме того, как изученные функции из предварительно обученного CNN, так и неконтролируемого CDBN дают успешные результаты в эксперименте. Таким образом, мы получили с комбинацией всех этих положительных факторов лучший результат 91,13% по точности, 0,91 по шкале f1 и 0,995 по шкале площади под кривой (AUC).
Эта статья организована в следующем порядке. Раздел 2 описывает подготовку набора звуковых данных домашней кошки. Раздел 3 представляет собой обзор предварительной обработки данных, извлечения сетевых характеристик CNN и CDBN и классификации извлеченных функций. Результаты с обсуждением включены в раздел 4 . Наконец, заключение и будущие работы упомянуты в разделе 5 .
2. Набор звуковых данных Cat
Слух - второе по важности чувство человека после зрения для распознавания любого животного. Автоматическое распознавание звука кошки с использованием машинного обучения на основе данных требует большого количества помеченных данных для успешного обучения. Собрать звуки домашних кошек - сложная задача. Задача Kaggle ( https://www.kaggle.com ) Audio Cats and Dogs предоставляет 274 аудиофайла со звуками кошек, но в них нет категорий звуков. Поскольку для домашней кошки нет большого набора звуковых данных, мы собрали их в основном из источников онлайн-видео на YouTube ( https://www.youtube.com/ ) и Flicker ( https://www.flickr.com/ ).
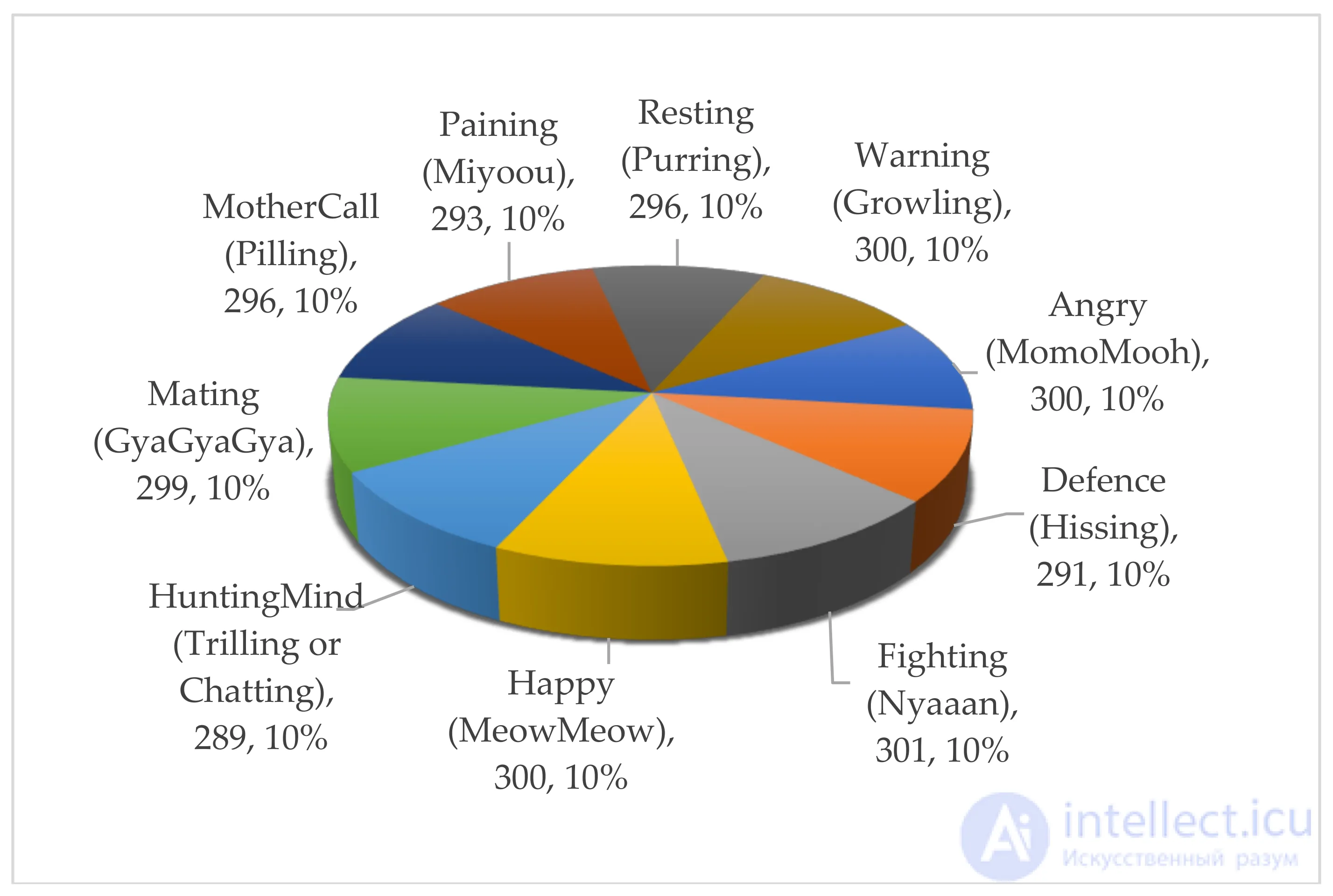
Круговая диаграмма на рисунке 1 иллюстрирует набор данных о звуках кошек, названный набором данных CatSound , где каждый класс назван в соответствии со звуком кошек в различных ситуациях. Количество звуковых файлов кошек в каждом классе составляет около 300, что составляет около десяти процентов от общего количества файлов данных, так что наш набор данных CatSound сбалансирован. Общая продолжительность набора данных CatSound составляет более 3 часов для всех звуков в 10 классах, что означает, что средняя продолжительность звука составляет около 4 секунд.
Рисунок 1. Сбалансированное представление набора данных звука кошки. Каждый класс в наборе данных назван в соответствии с настроением или положением кошки, когда она издает звук. Слова звукоподражания в скобках - это имитация кошачьих звуков в каждом классе. Цифры указывают количество кошачьих звуков, а числа с процентами - соответствующую часть каждого размера класса в наборе данных.
Правильная категоризация собранных звуков была еще одной большой проблемой, потому что некоторые звуки в одной категории очень похожи на другие в разных категориях. Кроме того, кошки часто издают разные звуки с небольшой разницей во времени. Например, рассерженный кот может почти одновременно издавать звуки « рычание », « шипение » или « ньяан ». Семантическое объяснение звуков домашних кошек в [ 21 , 22 ] помогло нам разделить различные звуки на соответствующие классы.
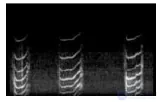
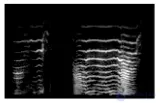
Некоторые аудиофайлы в нашем наборе данных были разделены на несколько сегментов разной длины, каждый из которых имеет одну и ту же семантическую категорию таким же образом, как в [ 23 ] для поиска музыкальной информации. Например, звук кошки в нормальном настроении (« мяу-мяу »), защита (« шипение »), котенок, зовущий свою мать (« пиллинг »), и кошки, испытывающие боль (« миеу »), могут быть семантически правильными. , даже в короткие сроки. С другой стороны, кошка издает звуки в состоянии покоя (« мурлыканье »), предупреждения (« рычание »), совокупления (« гей-гей-гей »), драки (« ньяан »), злости (« момо-му »), и хочу-охотиться ("трель или болтовня ») обычно более значимы, если их анализировать за более длительный период времени. Даже по некоторым классам кошачьих звуков данные могут иметь разную длину, поскольку биоразнообразие сильно различается в зависимости от географического положения, вида кошки и возраста. Представления формы волны 10 выборок из каждого класса визуализированы на рисунке 2 . Графическое изображение помогает читателю понять характер, амплитуду и продолжительность звуков.
Рис. 2. Визуализация формы волны 10 выборок данных, взятых из каждого класса набора данных CatSound.
3. Метод классификации
В этом разделе рассматриваются увеличение и предварительная обработка данных, обучение с передачей, объединение среднего частотного разделения и извлечение функций из нашего набора данных. В этом разделе также обсуждаются различные классификаторы и методы ансамбля, которые используются в нашей работе.
3.1. Увеличение и предварительная обработка данных
Поскольку набор данных CatSound слишком мал для обучения алгоритмов машинного обучения, необходимо увеличить размер данных, используя надлежащее увеличение данных. В эксперименте мы выполнили аудио-аугментацию, как описано в [ 20 ], используя случайный выбор методов аугментации с их параметрами в соответствующих диапазонах. Методы увеличения включают изменение скорости (диапазон от 0,9 до 1), смещение высоты тона (диапазон от -4 до 4), сжатие динамического диапазона (диапазон от 0,5 до 1,1), добавление шума (диапазон от 0,1 до 0,5) и сдвиг по времени (20% в вперед или назад). Обратите внимание, что каждый параметр следует выбирать в умеренном диапазоне, иначе звук может быть резко изменен и классифицирован иначе, чем исходный звук.
В эксперименте используются три вида расширенных наборов данных, а именно 1x_Aug, 2x_Aug и 3x_Aug, а также один исходный набор данных о звуках кошек. Набор данных 1x_Aug содержит исходные данные и их расширенный клон. Точно так же набор данных 2x_Aug и 3x_Aug состоит из исходного аудиофайла и его дополнительных расширенных клонов с удвоенным и утроенным размером соответственно. Об этом говорит сайт https://intellect.icu . Эти четыре набора данных (один исходный и три дополненных) подготовлены для ввода предварительно обученной CNN и неконтролируемой CDBN для извлечения признаков.
Предварительная обработка данных для каждой из двух нейронных сетей для извлечения признаков различается из-за разницы в структуре. Первым шагом нашей обработки входного сигнала является заполнение нулями, чтобы создать полноразмерный звук, который может генерировать спектрограмму mel фиксированного размера. Роль заполнения нулями в сигнале временной области заключается в увеличении разрешения по частоте и создании полных периодов в сигнале, которые устраняют спектральную утечку. Дискретные звуковые сигналы кошачьего звука с частотой 16 кГц представлены в виде спектрограммы mel как вход для обеих сетей. Для CNN спектрограммы mel извлекаются из каждого набора данных о звуках кошек с использованием метода Капре [ 24].]. Вход в CNN имеет один канал, 96-мелкие ячейки и 1813 временных кадров. В случае CDBN мел-спектрограмма с 96-мелкими ячейками и 155 временными кадрами подготавливается для ввода после отбеливания. Процедуры предварительной обработки для сетей CNN и CDBN показаны на рисунке 3 .
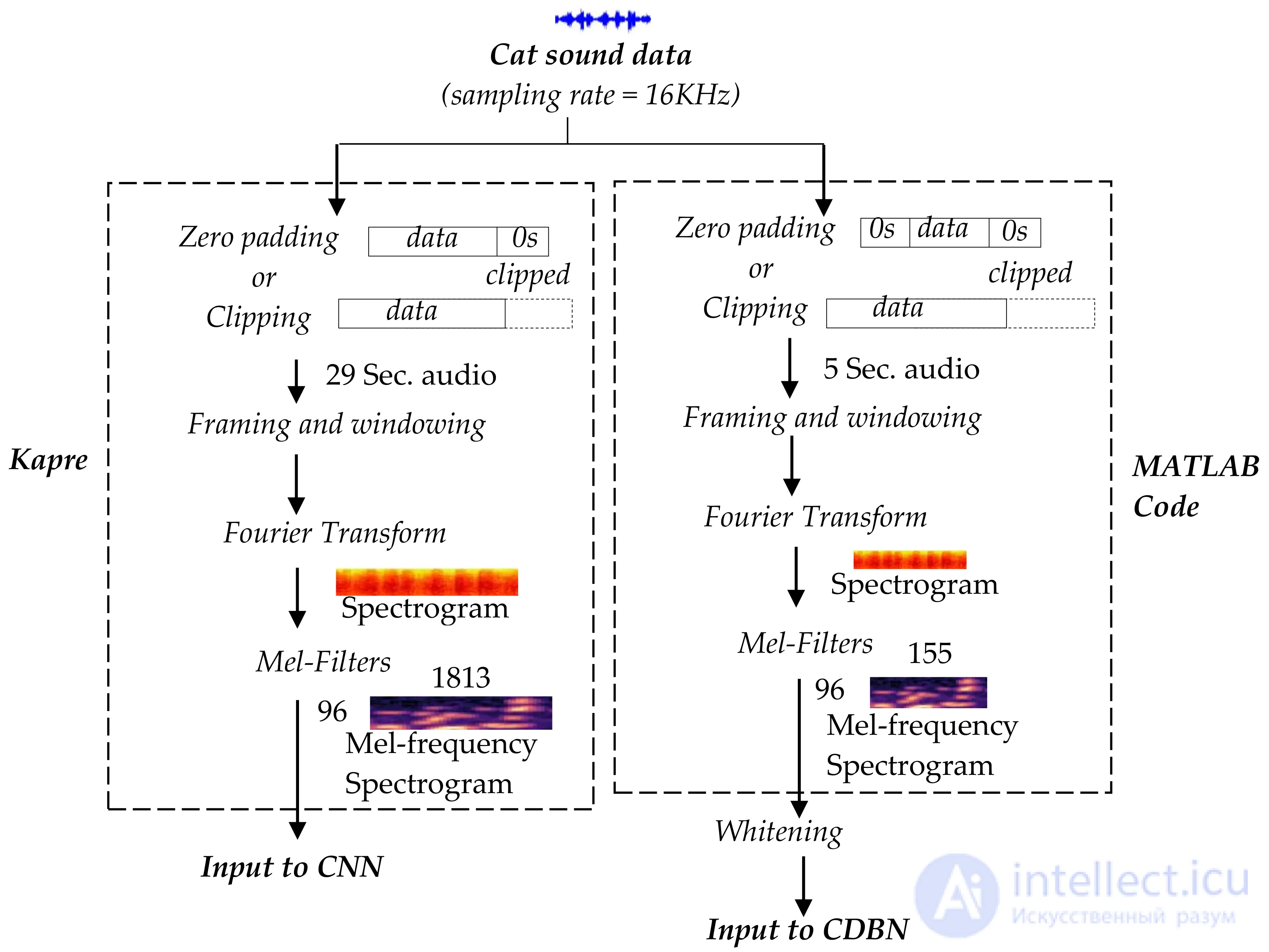
Рисунок 3. Предварительная обработка входных данных для сверточной нейронной сети (CNN) ( слева ) и сверточной сети глубоких убеждений (CDBN) ( справа ). Для входных данных CNN вся предварительная обработка выполняется с использованием Kepre, а короткие аудиоданные дополняются нулями только с правой стороны. Код MATLAB используется для предварительной обработки ввода CDBN, а короткие аудиоданные дополняются нулями с обеих сторон. Наконец, в конце проводится отбеливание.
3.2. Объединение средних значений частотного деления
Обычные слои GAP векторизуют карты характеристик сверточной сети, как описано в [ 25 ]. GAP - это метод уменьшения размерности, который сокращает трехмерный тензор до одного вектора признаков, беря среднее значение каждой карты признаков. Например, если тензор имеет размерность H × W × C , то GAP уменьшает размер до 1 × 1 × C , где H , W , C - высота, ширина и канал тензора соответственно. Одним из основных преимуществ использования GAP является уменьшение параметров сети, поскольку нет параметров для оптимизации.
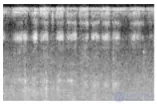
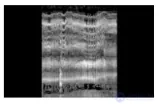
В этой работе мы использовали объединение средних частот с частотным разделением, которое является модифицированной версией GAP. Это выделение признаков для конкретной области, где мы сначала разделяем карту признаков на низкочастотные и высокочастотные полосы, а затем применяем GAP в каждой полосе. Это эффективный способ работы с данными с изменяющейся частотой, такими как звуки кошки, в которых частотные компоненты в определенной полосе активны для определенных классов звуков. Спектрограмма логарифмической мощности и спектрограмма mel образцов данных, взятых из каждого класса набора данных CatSound , как показано на рисунках 4 и 5., указывают на то, что активность кошачьего звука в частотных диапазонах различается в зависимости от класса звука. Следовательно, если функции правильно сегментированы в нескольких частотных диапазонах, мы можем ожидать лучших характеристик классификации. Однако трудно определить точные точки отсечки для разделения карт функций на полосы частот, поэтому мы перекрываем частотное разделение, как перекрывающиеся окна кратковременного преобразования Фурье (STFT). Характеристики берутся путем перекрытия небольшой части (одиночного бина) соседних частотных составляющих. Может быть много альтернативных способов разделения карт характеристик сетей на полосы частот. Мы разделяем карты функций в соответствии с количеством доступных частотных компонентов в каждом слое, и, следовательно, карта функций более высокого уровня имеет относительно меньшее количество разделов.
Рисунок 4. Образец на рисунке 2 преобразован в логарифмическую спектрограмму мощности.
Рисунок 5. Образец на рисунке 2 преобразован в мел-спектрограмму.
3.3. Трансферное обучение CNN
Передача обучения - это процесс преобразования любых полученных знаний из одного или нескольких исходных доменов в целевой домен, чтобы цель могла обобщить свои возможности прогнозирования для решения аналогичных проблем. Ключевым преимуществом трансферного обучения является повышение производительности при небольшом количестве помеченных наборов обучающих данных. Это возможно, если у исходной и целевой сети схожие задачи. Недавнее исследование трансфертного обучения при обнаружении начала музыки [ 26 ] показывает, что различие в исходных и целевых наборах данных может привести к невозможности захвата релевантной информации при использовании трансферного обучения. Техника трансферного обучения успешно применялась и исследовалась в различных областях исследований, таких как классификация изображений [ 27 , 28], обнаружение акустических событий [ 29 , 30 ], обработка речи и языка [ 31 ] и классификация музыки [ 32 , 33 ].
Однако в этой работе нет полезной альтернативы для компенсации недостатка данных, кроме трансферного обучения. Поэтому предварительно обученная CNN с набором данных «Миллион песен» [ 34 ] принимается в качестве средства извлечения признаков, и мы проверяем эффективность изученного признака из музыки для классификации звука кошки. Особенности из сети [ 33] путем передачи обучения показывает хорошие результаты в классификации музыки и регрессии. Хотя звуки кошек имеют некоторые отличия от записанной в студии музыки с точки зрения изменения частоты, отношения сигнал / шум, резкого изменения силы и частого прерывания звуков окружающей среды, но некоторые последующие исследования показывают тесную связь музыки с животными. звук. В западной классической музыке композиторы и музыканты обычно по-разному используют пение птиц [ 15 , 35 , 36 ] [ 37 ]. Кроме того, звуки домашних животных и диких животных также прямо или косвенно включены в песни [ 36 ] для создания фоновых шумов в концертных залах [ 35 ]. Обзорное исследование [ 38] иллюстрирует тесную связь между человеческими языками, (человеческой) музыкой и вокализацией животных. В заключение отметим, что диверсифицированная музыка в наборе данных из миллионов песен имеет некоторую связь со звуком кошки, и это может быть одним из решений проблемы отсутствия данных в классификации звуков кошек, если выполняется переносное обучение. Следовательно, мы используем предварительно обученную CNN в качестве исходной сети для передачи обучения.
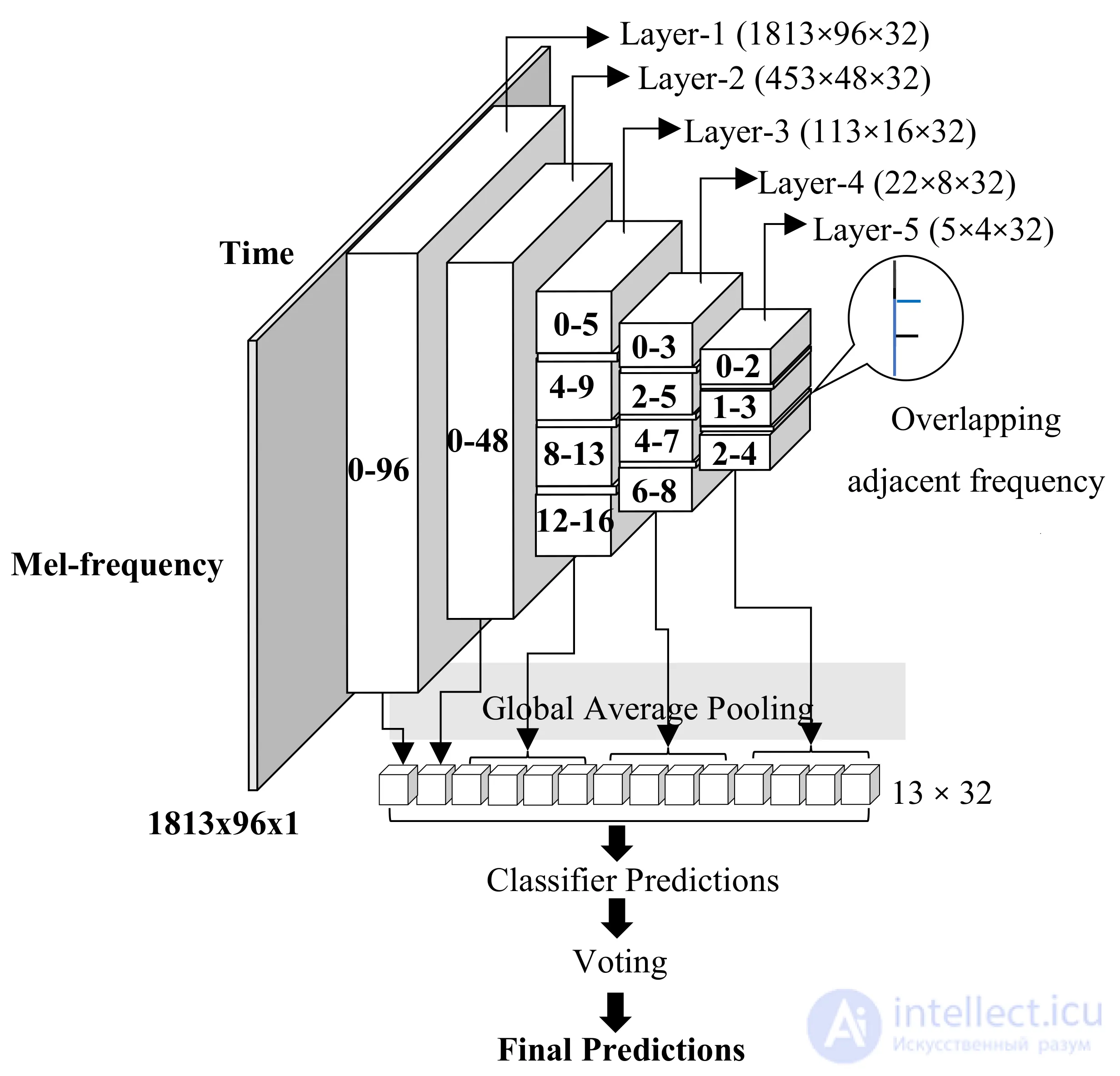
Мы извлекли функции из этой предварительно обученной сети как для исходного, так и для расширенного набора данных с помощью Keras ( https://keras.io/). Большие размеры извлеченных объектов в каждом слое уменьшаются до вектора с помощью метода FDAP, а затем объединяются. Все эксперименты проводились с графическим процессором NVIDIA GeForce GTX 1080 Ti. Мы столкнулись с проблемой памяти при извлечении признаков из первых двух слоев, и, следовательно, мы неизбежно использовали обычное объединение глобального среднего значения в этих двух слоях. Чтобы применить FDAP к третьему и четвертому слою, карты характеристик делятся поровну на четыре полосы. Но карты характеристик пятого слоя разделены на две перекрывающиеся полосы, потому что есть только небольшое количество интервалов в измерении частоты mel. В каждом бэнде 32 функции, и все они объединены, чтобы создать входной вектор для пяти классификаторов. Извлечение и классификация признаков с использованием предварительно обученной архитектуры CNN показано наРисунок 6 . Результаты экспериментов показывают, что, несмотря на то, что звук кошки и музыка сильно различаются, звуковые сигналы обладают схожими характеристиками, поэтому переносное обучение полезно.
Рисунок 6. Трансферное обучение CNN и классификация по извлеченным признакам. С первого по пятый уровень количество сегментов для объединения средних значений с частотным разделением (FDAP) на каждом уровне составляет 1, 1, 4, 4 и 3 соответственно. Параметры каждого уровня представлены как ( время × частота × канал ). Каждый сегмент создает 1 × 32-мерный вектор признаков, а объединенный вектор признаков подается в различные классификаторы и голосование за прогнозируемую вероятность окончательного результата ансамбля.
3.4. Извлечение функций CDBN
Сверточно-ограниченные машины Больцмана (CRBM) [ 39 , 40 ] являются строительным блоком CDBN, а CRBM является расширением RBM [ 41 ] до сверточной настройки. CDBN - это неконтролируемая иерархическая генеративная модель для извлечения признаков из немаркированных визуальных данных [ 42 ] или акустического сигнала [ 43 ] с использованием послойного жадного восходящего подхода. Вдохновленные этими исследованиями, мы построили пятиуровневую архитектуру CDBN, как показано на рисунке 7.. Спектральное отбеливание в частотной области выполняется на спектрограмме mel фиксированного размера перед подачей в CRBM, и извлеченные признаки из каждого слоя являются входными данными для соответствующего более высокого уровня сети. Используются фильтры различных размеров, а именно [3 × 7], [3 × 3], [3 × 3], [3 × 3] и [3 × 3] с фиксированным размером пула [2 × 2]. для пяти последовательных уровней CDBN, соответственно, где размер обозначается как [элементы разрешения по частоте × кадры].
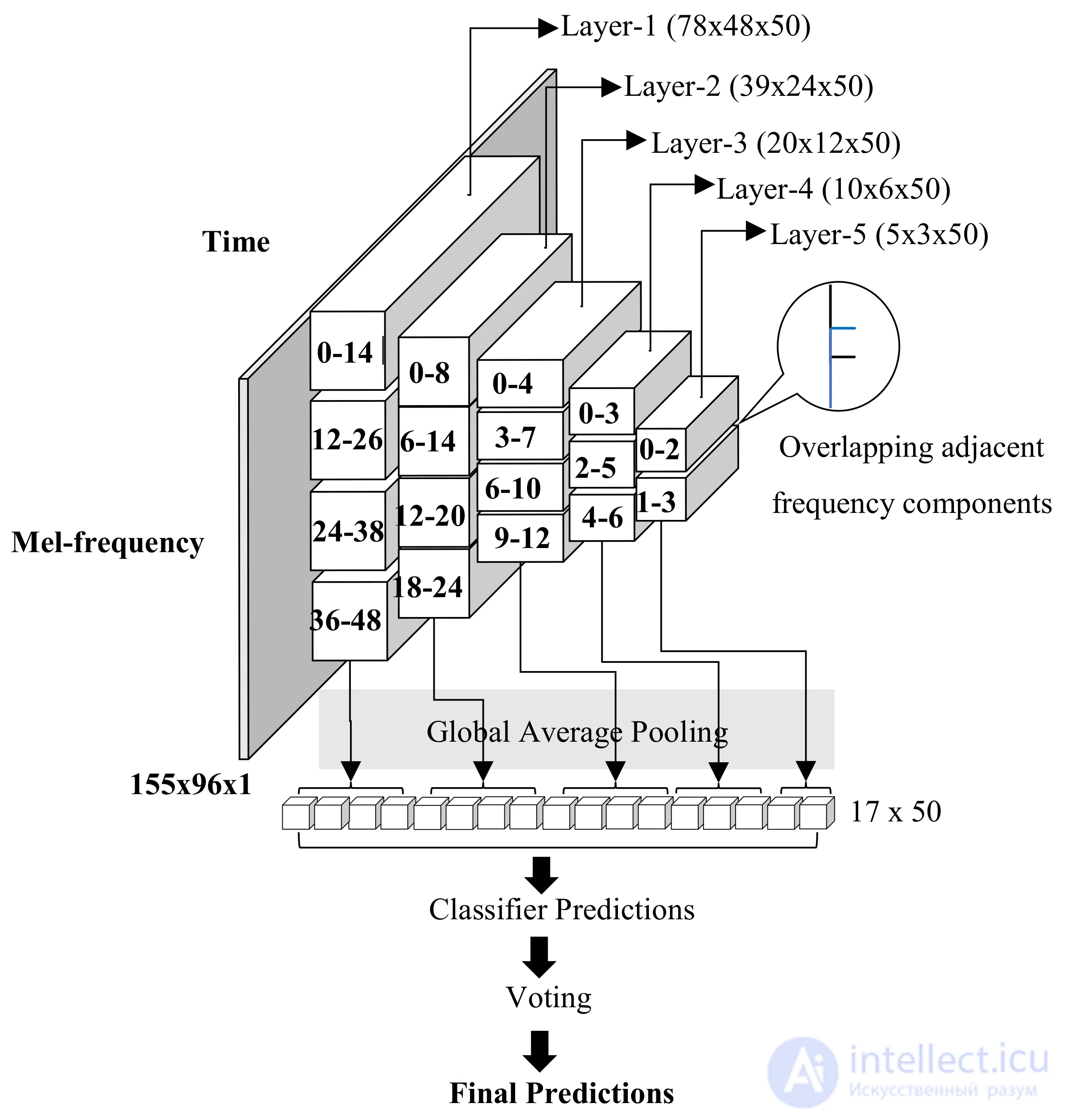
Рисунок 7. Обзор извлечения признаков из сети CDBN и классификации. Объекты из каждого слоя извлекаются с помощью FDAP с перекрытием, показанным в каждом сегментированном блоке функций. Параметры каждого уровня представлены как ( время × частота × канал ). Объединенный вектор признаков подается в различные классификаторы и голосование за прогнозируемую вероятность окончательного результата ансамбля.
CDBN обучается исключительно на звуковых данных кошек, и характеристики каждого слоя сохраняются для дальнейшей классификации. Карта признаков каждого слоя разделяется для FDAP, а затем векторы признаков объединяются для подачи в классификаторы. Функции CDBN разделены по частотному диапазону с перекрытием. Первые три уровня разделены на четыре равные полосы, а характеристики четвертого и пятого уровней разделены на три и две полосы соответственно. Объединение 50 объектов из каждой полосы слоев приводит к созданию вектора признаков размером 1 × 850. Этот вектор признаков является входными данными для пяти классификаторов, и результаты прогнозов объединяются с равным приоритетом, чтобы получить окончательные прогнозы путем голосования. Изученные возможности CDBN показаны в таблице 1 .
Таблица 1. Визуализация узнаваемой функции первого канала предлагаемой сети CDBN на каждом уровне. Форма волны того же образца данных представлена на рисунке 2 .
3.5. Классификация звуков кошек
Мы выбрали пять классификаторов, представленных в библиотеке python sklearn ( http://scikit-learn.org ), чтобы классифицировать звуки кошек с использованием изученной функции предварительно обученного CNN и неконтролируемого CDBN. Эти алгоритмы машинного обучения являются мощными и могут хорошо работать даже с ограниченным количеством классов, помеченных данными. Здесь мы даем краткое введение в классификаторы, используемые в этой работе. Классификатор случайного леса (RF) [ 44 ] использует схему голосования большинством ( Bagging [ 45 ] или Boosting [ 46 ]), чтобы сделать окончательный прогноз на основе заранее заданного количества деревьев решений. K-ближайший сосед (KNN) [ 47] классификатор находит класс, к которому принадлежит неизвестный объект, используя большинство голосов k- ближайших соседей. Чрезвычайно рандомизированные деревья (или Extra Tree) [ 48 ] классификатор пытается случайным образом найти оптимальную точку отсечения для всего заданного объекта. Линейный дискриминантный анализ (LDA) [ 49 ] является расширением идеи дискриминантного анализа Фишера [ 50 ] для ситуаций любого числа классов и использует устройства матричной алгебры для его вычисления. LDA - это тип байесовских классификаторов, который требует предположения о равных матрицах дисперсии-ковариации классов. Машина опорных векторов [ 51] (SVM) классификатор с радиальной базисной функцией (RBF) используется в этом исследовании для нелинейной классификации извлеченных нами признаков. Сравнительные результаты этих классификаторов упомянуты в разделе 4 .
Ансамбль - это хорошо известный метод машинного обучения, который объединяет возможности прогнозирования нескольких классификаторов, а затем классифицирует новые точки данных, принимая (взвешенное) голосование за их прогнозы, как экспериментально доказано в [ 52 ] для целей классификации звука. Был разработан ряд недавних алгоритмов, таких как упаковка, ведро моделей, наложение и повышение. Метод ансамбля объединяет несколько методов машинного обучения в одну модель прогнозирования, чтобы уменьшить дисперсию (упаковка), смещение (повышение) или улучшить прогнозы (суммирование) [ 53 ]. В этом эксперименте мы выбираем простейшее большинство голосов с равным приоритетом для ансамбля наших пяти классификаторов.
4. Результаты
Для оценки производительности, точности использовались показатели F1 [ 54 ] и площади под кривой рабочих характеристик приемника (ROC-AUC) [ 55 ]. Под точностью понимается процент правильно классифицированных выборок неизвестных данных, а F1 -score вычисляет гармоническое среднее между точностью и отзывом [ 56 ]. Показатель ROC-AUC измеряется по каждому классификатору на кривой рабочих характеристик приемника (ROC) [ 55 ]. Кривая ROC используется для визуализации и анализа производительности каждого классификатора в соответствии с различными порогами принятия решения, связанными с ним. Матрица путаницы показывает точные характеристики для разных классов.
В эксперименте мы использовали 10-кратную проверку [ 57 ] для оценки характеристик в соответствии с различными конфигурациями экспериментальной установки. Затем мы сравнили характеристики по следующим факторам: объем данных, увеличенный за счет дополнения, изученные функции из предварительно обученной CNN или неконтролируемой CDBN, обычного GAP или FDAP, пяти различных алгоритмов машинного обучения и их совокупности.
Результаты оценки показывают, что влияние дополнения на набор данных, метод FDAP и большинство голосов на прогнозы классификатора повышает общую производительность и снижает вероятность путаницы, как мы и ожидали. В таблице 2 показаны наиболее эффективные результаты различных классификаторов с использованием двух типов изученных функций с набором данных 3x_Aug.
Таблица 2. Лучшие характеристики различных классификаторов для функций CNN и CDBN, извлеченных из набора данных 3x_Aug с помощью FDAP. Жирными числами отмечен наивысший балл алгоритма (ов) за изученные функции из сети.
Таблица 2. Лучшие характеристики различных классификаторов для функций CNN и CDBN, извлеченных из набора данных 3x_Aug с помощью FDAP. Жирными числами отмечен наивысший балл алгоритма (ов) за изученные функции из сети.
| Классификаторы |
Точность (%) |
F1-Score |
Оценка AUC |
| CNN (± SD) |
CDBN (± SD) |
CNN |
CDBN |
CNN |
CDBN |
| RF |
84,64 (0,02) |
86,32 (0,03) |
0,85 |
0,86 |
0,988 |
0,988 |
| KNN |
81,60 (0,02) |
80,32 (0,02) |
0,82 |
0,80 |
0,898 |
0,890 |
| Дополнительные деревья |
83,80 (0,03) |
84,29 (0,03) |
0,84 |
0,84 |
0,987 |
0,985 |
| LDA |
78,48 (0,02) |
81,84 (0,03) |
0,78 |
0,82 |
0,975 |
0,979 |
| SVM |
87,43 (0,03) |
90,88 (0,04) |
0,87 |
0,91 |
0,992 |
0,994 |
| Ансамбль |
90,80 |
91,13 |
0,91 |
0,91 |
0,994 |
0,995 |
Обратите внимание, что изученные функции из предварительно обученного CNN с музыкой дали сопоставимые результаты с таковыми из неконтролируемого CDBN, который обучается исключительно на звуковых данных кошки. Классификатор SVM также демонстрирует хорошую производительность для функций CDBN, но оценка AUC не превышает оценку классификатора ансамбля.
Результаты ансамблевого классификатора с дополнением или без него, а также реализации GAP или FDAP представлены в таблице 3 . Обратите внимание, что производительность классификаторов постоянно улучшалась за счет увеличения объема обучающих данных с дополнением, независимо от нейронных сетей, которые используются для извлечения признаков. Кроме того, FDAP обеспечивает лучшие характеристики по сравнению с обычным GAP во всех сравнениях, что доказывает, что FDAP более эффективен для классификации кошачьих звуков. Среднее увеличение точности прогнозирования для набора данных звука кошки с использованием FDAP в CNN составляет 7,37 и 10,05 в CDBN, когда для обучения используется набор данных 3x_Aug.
Таблица 3. Точность, F1-оценка и площадь под кривой ROC для сравнения CNN и CDBN с использованием ансамблевого классификатора на исходных и дополненных наборах данных. Преимущество FDAP по сравнению с GAP на карте характеристик каждого слоя двух сетей, использующих различные наборы данных, обозначено «GAP» и «FDAP» в конце соответствующего набора данных. Жирными числами отмечены наиболее эффективные алгоритмы для набора данных с использованием FDAP в изученной функции сети.
.
| Cat Sound Dataset |
Accuracy (%) |
F1-Score |
AUC Score |
| CNN |
CDBN |
CNN |
CDBN |
CNN |
CDBN |
| Original_GAP * |
70.71 |
76.09 |
0.690 |
0.760 |
0.958 |
0.963 |
| Original_FDAP # |
79.12 |
82.15 |
0.780 |
0.820 |
0.974 |
0.982 |
| 1x_Aug_GAP |
80.61 |
76.39 |
0.810 |
0.760 |
0.977 |
0.970 |
| 1x_Aug_FDAP |
86.51 |
87.52 |
0.860 |
0.880 |
0.989 |
0.989 |
| 2x_Aug_GAP |
81.89 |
76.60 |
0.820 |
0.760 |
0.982 |
0.969 |
| 2x_Aug_FDAP |
89.31 |
87.96 |
0.890 |
0.880 |
0.993 |
0.991 |
| 3x_Aug_GAP |
83.04 |
79.49 |
0.830 |
0.790 |
0.985 |
0.977 |
| 3x_Aug_FDAP |
90.80 |
91.13 |
0.910 |
0.910 |
0.994 |
0.995 |
В таблице 4 показана матрица неточностей нашего лучшего классификатора ансамбля с использованием функции обучения CDBN с набором данных 3x_Aug. Мы изучили преимущества использования метода FDAP по сравнению с обычным GAP с помощью этой матрицы неточностей. Недиагональные числа представляют количество кошачьих звуков в каждом классе, которые неправильно классифицируются классификатором ансамбля. Проанализировав каждую матрицу неточностей пяти классификаторов и классификатора ансамбля, мы можем прийти к некоторым выводам. Обороны ( « Шипение ») и HuntingMind ( « трель или в чат ») звуки легко отличить от других звуков кошки , по крайней мере в нашем CatSound наборе данных, так что эти классы являются относительно менее запутанными. С другой стороны, Хэппи (« мяу-мяу») И Paining (« miyoou ») имеют некоторое сходство в звуковых характеристиках, так что все классификаторы считают эти классы более запутанными. Точно так же предупреждение (« рычание ») легко спутать с «Спариванием» (« гей-гей-гей »).
Таблица 4. Матрица неточностей лучшего классификатора ансамбля для набора данных 3x_Aug с использованием функций CDBN с GAP и FDAP. Первое число представляет количество сбитых с толку кошачьих звуков при использовании GAP, а второе - при использовании FDAP, что показано как формат GAP / FDAP.
| Сердитый |
Защита |
Борьба |
Счастливый |
Охотничий разум |
Спаривание |
Звонок матери |
Боль |
Отдыхает |
Предупреждение |
| Сердитый |
83 * / 94 # |
2 / - |
2 / - |
- / - |
- / - |
2/1 |
1 / - |
4/1 |
- / - |
7/4 |
| Защита |
1 / - |
92/97 |
- / - |
- / - |
4/1 |
1/3 |
1 / - |
- / - |
- / - |
1 / - |
| Борьба |
1/1 |
2 / - |
84/90 |
1 / - |
7/5 |
1/1 |
- / 2 |
3/1 |
- / - |
1/1 |
| Счастливый |
4/2 |
4/2 |
3 / - |
74/90 |
5/1 |
1 / - |
1/1 |
1/1 |
- / - |
- / - |
| Охотничий разум |
1 / - |
4 / - |
4/1 |
- / - |
78/96 |
6/1 |
- / - |
- / - |
2 / - |
6/2 |
| Спаривание |
2/2 |
- / - |
2/1 |
- / 2 |
7/3 |
76/85 |
1 / - |
2/2 |
2 / - |
8/5 |
| MotherCall |
1 / - |
- / - |
2 / - |
4/2 |
4/2 |
3/1 |
78/94 |
4 / - |
5/2 |
- / - |
| Боль |
7/5 |
1 / - |
3/1 |
8/4 |
1/2 |
1 / - |
4/3 |
75/85 |
- / - |
- / - |
| Отдыхает |
- / - |
3/3 |
1 / - |
- / - |
6/3 |
4 / - |
1 / - |
- / - |
78/92 |
7/1 |
| Предупреждение |
5/2 |
5/2 |
2 / - |
1/2 |
4/2 |
5/2 |
- / - |
1/1 |
2/1 |
76/89 |
* Количество кошачьих звуков попадает в тот же или другой класс с помощью GAP; # Количество кошачьих звуков попадает в тот же или другой класс с использованием FDAP.
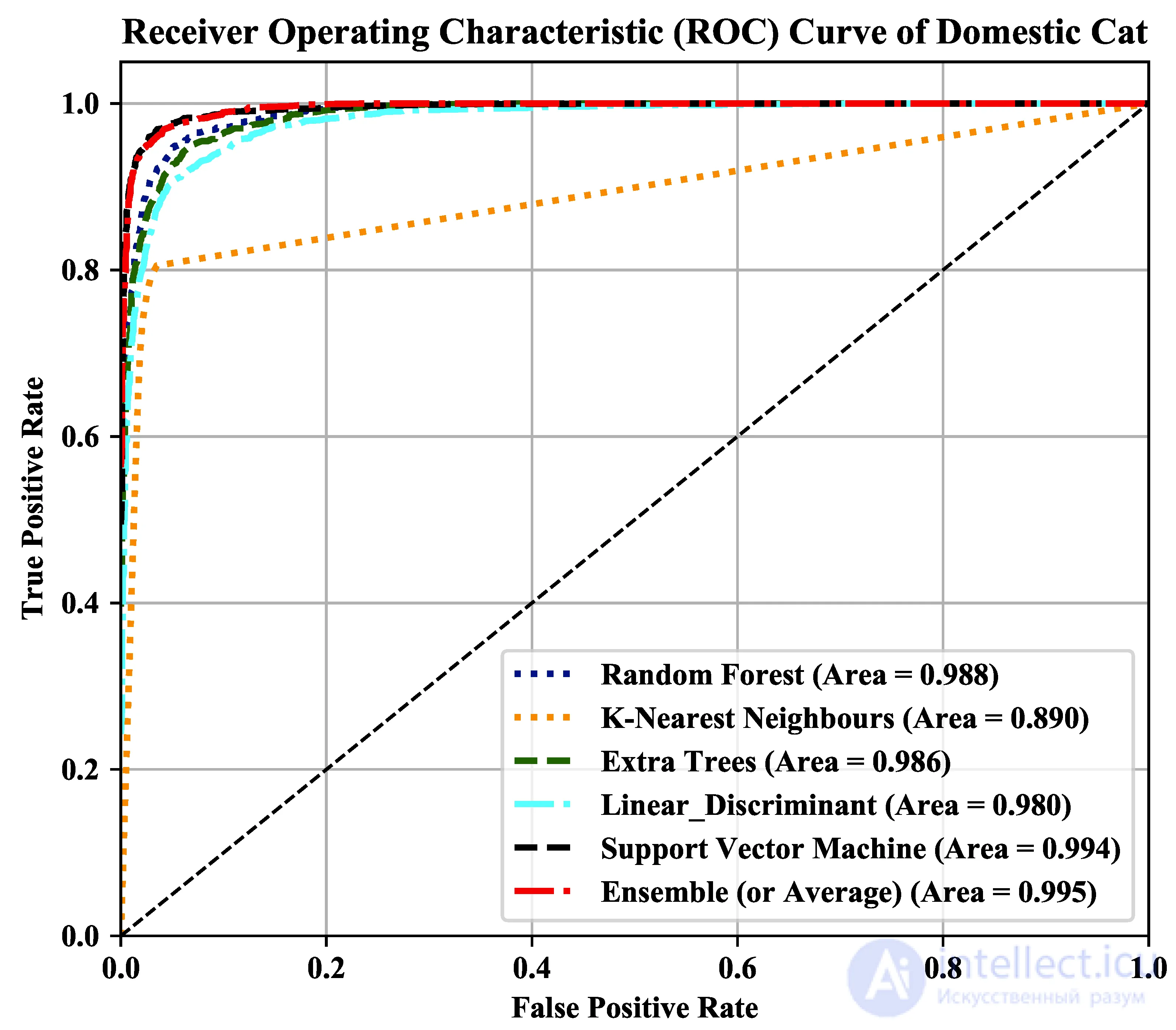
Кривые ROC пяти классификаторов и классификатора ансамбля и соответствующие им оценки ROC-AUC показаны на рисунке 8 . Можно заметить, что классификатор ансамбля обеспечивает наиболее близкую к идеальному классификатору производительность, даже несмотря на то, что SVM показывает аналогичную производительность.
Рисунок 8. Кривые ROC различных классификаторов с наборами данных 3x_Aug с использованием функций CDBN. Каждая кривая представлена уникальным цветом, а соответствующий показатель AUC указан в скобках.
5. Обсуждение
Функции неконтролируемой CDBN приводят к большей точности классификации, чем функции из предварительно обученной CNN, за исключением случая 2x_Aug_FADP, как показано в таблице 2.. Причин может быть несколько. Во-первых, функции CDBN обучаются исключительно на звуках кошек, в то время как функции из CNN получаются из предварительно обученной сети с музыкальными данными. Тем не менее, мы можем сделать вывод, что трансферное обучение все еще действует, даже если исходная и целевая задачи немного отличаются. Другая причина заключается в том, что метод FDAP был применен к последним трем уровням CNN, тогда как он использовался на всех уровнях CDBN. В заключение, улучшение производительности CNN с использованием FDAP относительно выше, чем у CDBN. В будущем есть надежда улучшить производительность, если FDAP будет применяться ко всем слоям.
Функции CDBN могут работать лучше, если доступно больше обучающих данных. В случае сравнения классификаторов классификатор SVM предсказывает более точно, чем другие классификаторы, но для этого требуется относительно больше времени на обучение. Как упоминалось ранее, ансамблевый классификатор обеспечивает наилучшую точность во всех разнообразных конфигурациях постановки эксперимента.
Выводы
Классификация звуков домашних кошек - это попытка улучшить взаимодействие между домашним животным и человеком. Подход к обоснованной классификации, основанный на данных, требует большого количества данных с маркировкой классов. В этой работе сначала мы создали небольшой набор данных о звуках кошек с 10 категориями и визуализировали характеристики звука с точки зрения временного и частотного представления. Мы надеемся, что этот набор данных может вдохновить других исследователей на изучение аналогичной задачи. Мы расширили возможности этого небольшого набора данных, выбрав различные методы увеличения звука. Кроме того, мы изменили традиционную концепцию глобального среднего пула (GAP) и использовали объединение среднего значения с частотным разделением (FDAP) для лучшего изучения и использования изученных функций глубоких нейронных сетей.
В этом исследовании экспериментально изучается эффект увеличения данных и FDAP. Еще один способ преодолеть ограниченную доступность больших аннотированных данных для классификации звуков кошек - это трансферное обучение. Мы обнаружили, что даже несмотря на то, что исходная сеть CNN обучается с использованием музыкальных данных, по-прежнему полезно извлекать изученные функции из небольшого набора звуковых данных кошек с использованием трансферного обучения. Неконтролируемая архитектура CDBN - еще один способ извлечь изученную функцию. Функции неконтролируемой сети CDBN, обученной исключительно на звуковых данных кошек, работают немного лучше, чем функции из CNN, обученной с музыкальными данными. Наш метод FDAP был применен ограниченно только к последним трем уровням CNN, поэтому есть возможность улучшения производительности в будущем. Мы также сравнили характеристики пяти различных классификаторов и их совокупности. Наконец, мы можем заключить, что увеличение данных, голосование большинством за ансамбль и FDAP - это способы повысить эффективность классификации для набора данных звука маленькой кошки.
Очевидно, что наша работа тоже недалеко от ограничений. Доминирующим ограничением может быть отсутствие участия экспертов в маркировке звуковых данных кошки, отклонения в предварительно обученных CNN и CDBN, отсутствие данных и перенос обучения в двух разных наборах данных.
В будущем есть возможность улучшить результаты, если будет доступен большой размеченный набор данных для сквозного обучения сети. Различные схемы разделения карт признаков в слоях глубокой нейронной сети, возможно, могут повысить эффективность классификации. Кроме того, для точной маркировки данных лучше посоветоваться со специалистами по кошачьему звуку. Здесь мы использовали предварительно обученный CNN с музыкальными данными, который несколько отличается от звука кошки. Если бы существовала какая-либо предварительно обученная сеть со звуком животного, похожим на звук кошки, трансферное обучение могло бы дать лучшие результаты классификации. Анализ звукового сигнала кошки с использованием другого типа алгоритма машинного обучения, такого как машина экстремального обучения (ELM) или многоядерный ELM (MKELM) [ 58], являются возможными методами для проведения более сравнительного исследования в будущем.
Вау!! 😲 Ты еще не читал? Это зря!
- ансамбль нейросетей
- глубокое обучение
- восприятие
- ощущения
Данная статья про восприятие звуков у животных подтверждают значимость применения современных методик для изучения данных проблем. Надеюсь, что теперь ты понял что такое восприятие звуков у животных
и для чего все это нужно, а если не понял, или есть замечания,
то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Сравнительная психология и Зоопсихология














































Комментарии
Оставить комментарий
Сравнительная психология и Зоопсихология
Термины: Сравнительная психология и Зоопсихология