Лекция
Привет, Вы узнаете о том , что такое redis, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое redis , настоятельно рекомендую прочитать все из категории Redis DB Nosql.
Redis (от англ. remote dictionary server) — резидентная система управления базами данных класса NoSQL с открытым исходным кодом, работающая со структурами данных типа «ключ — значение». Используется как для баз данных, так и для реализации кэшей, брокеров сообщений.
В этом посте мы собираемся указать на некоторые основные различия между Redis и базой данных MySQL, а также на то, как их лучше всего использовать на практике.
Ориентирована на достижение максимальной производительности на атомарных операциях (заявляется о приблизительно 100 тыс. SET- и GET-запросов в секунду на Linux-сервере начального уровня ). Написана на Си, интерфейсы доступа созданы для большинства основных языков программирования.
В период 2010—2013 годов разработка системы спонсировалась компанией VMware , с мая 2013 года, после реорганизаций в федерации EMC — VMware, проект передан в Pivotal . С июня 2015 года основной спонсор проекта — компания Redis Labs, специально основанная для коммерциализации Redis, в нее же перешел основной разработчик продукта — Сальваторе Санфилиппо.
Redis — достаточно популярный инструмент, который из коробки поддерживает большое количество различных типов данных и методов работы с ними. Во многих проектах он используется в качестве кэшируещего слоя, но его возможности намного шире. Про некоторые интересные кейсы использования этой in-memory key-value базы данных я расскажу на примерах. Надеюсь, вам они будут полезны, и вы сможете применить что-то в своих проектах.
MySQL - самая популярная система управления реляционными базами данных с открытым исходным кодом, которая была выпущена в 1995 году, а позже была приобретена и обслуживается Oracle.
Redis или RE-dis - это проект структуры данных в памяти с открытым исходным кодом, реализующий распределенную базу данных ключ-значение в памяти с дополнительной надежностью. Он создан и поддерживается Redis Labs с первым выпуском в 2009 году. Он поддерживает структуры данных, такие как строки, хэши, списки, наборы и отсортированные наборы с запросами диапазона, растровыми изображениями, гиперлогами и геопространственными индексами с запросами радиуса.
| Redis | MySQL storage engine = MEMORY | |
|---|---|---|
| Первичная модель базы данных | Резидентное (в ОЗУ) Хранилище ключей и значений | Реляционная СУБД |
| Схема данных | Schema free | поддержанный |
| SQL | Не поддерживается | Поддерживается |
| Триггеры | Нет | да |
| Способы подключения | RESP - протокол сериализации REdis | Собственный собственный API ADO.NET JDBC ODBC |
| Методы разбиения | Шардинг | Горизонтальное разделение, сегментирование с помощью MySQL Cluster или MySQL Fabric |
| Концепции согласованности | Сильная согласованность в конечном итоге с CRDT Согласованность в конечном итоге |
Немедленная последовательность Immediate Consistency |
| Концепции транзакций | Оптимистическая блокировка, атомарное выполнение блоков команд и скриптов | ACID |
| Контроль доступа | Простой контроль доступа на основе пароля | Пользователи с детальной концепцией авторизации |
| мониторинг переполнения памяти, сохранение не в ОЗУ а на диск | да | нет? кроме InnoDB on RAMdisk |
| срок жизни ключа | кэш-хранилище, со скроком жизни кэша "из коробки" | срок жизни мужно реальзовать через эвенты |
Redis лучше подходит для :
MySQL работает лучше, когда вам нужно :
Самым большим преимуществом Redis является его хранилище данных ключ-значение в памяти. Он чрезвычайно быстр и гибок и включает встроенные структуры данных (например, списки, хэши, наборы, отсортированные наборы, растровые изображения, Hyperloglog и геопространственные индексы), которые могут выполнять некоторые операции с данными более эффективно, чем реляционные базы данных, такие как MySQL.
С другой стороны, Redis может очень хорошо дополнять и расширять другие базы данных в вашей экосистеме. Таким образом, по сравнению с MySQL, Redis действует не как замена, а как приспособление к недостаткам традиционной архитектуры MySQL:
Рекомендуется использовать Redis в качестве внешнего слоя базы данных между MySQL и приложением следующим образом:
Таким образом, Redis помогает вам быстрее получать доступ к вашим данным, быстро собирая данные от ваших пользователей.
Рассмотрим следующие варианты использования:
Хранит базу данных в оперативной памяти, снабжена механизмами снимков и журналирования для обеспечения постоянного хранения (на дисках, твердотельных накопителях). Также предоставляет операции для реализации механизма обмена сообщениями в шаблоне «издатель-подписчик»: с его помощью приложения могут создавать каналы, подписываться на них и помещать в каналы сообщения, которые будут получены всеми подписчиками (как IRC-чат). Поддерживает репликацию данных с основных узлов на несколько подчиненных (англ. master — slave replication). Также поддерживает транзакции и пакетную обработку команд (выполнение пакета команд, получение пакета результатов).
Работает на большинстве POSIX-систем, таких как Linux, *BSD, Mac OS X без каких-либо дополнений, компания-спонсор проекта поддерживает систему на Linux и Mac OS X. Официальной поддержки для сборок Windows нет, но доступны некоторые опции, позволяющие обеспечить работу Redis на этой системе , сообщается о работах Microsoft по переносу Redis на Windows.
В версии 2.6.0 добавлена поддержка Lua, позволяющего выполнять запросы на сервере. Lua позволяет атомарно совершить произвольную обработку данных на сервере и предназначена для использования в случае, когда нельзя достичь того же результата с использованием стандартных команд.
Среди языков программирования, имеющих библиотеки для работы с Redis — Си, C++, C#, Clojure, Лисп, Erlang, Java, JavaScript, Haskell, Lua, Perl, PHP, Python, Ruby, Scala, Go, Tcl, Rust, Swift, Nim.
Все данные Redis хранит в виде словаря, в котором ключи связаны со своими значениями. Одно из ключевых отличий Redis от других хранилищ данных заключается в том, что значения этих ключей не ограничиваются строками. Поддерживаются следующие абстрактные типы данных: строки, списки, множества, хеш-таблицы, упорядоченные множества.
Тип данных значения определяет, какие операции (команды) доступны для него; поддерживаются такие высокоуровневые операции, как объединение и разность наборов, сортировка наборов.
Восстановление данных проводится двумя разными способами. Первый — это механизм снимков, в котором данные асинхронно переносятся из оперативной памяти в файл формата RDB (расширение дампов Redis). Второй способ (с версии 1.1) — журнал упреждающей записи, доступный только для дозаписи, в котором хранятся все операции, изменявшие данные в памяти.
Система поддерживает репликацию с ведущих узлов на ведомые. Данные с любого сервера Redis могут реплицироваться произвольное количество раз. Все данные, которые попадают на один узел Redis (ведущий, англ. master), будут попадать также на другие узлы (ведомые, англ. slave). Для конфигурирования ведомых узлов можно изменить опцию slaveof или аналогичную по написанию команду (узлы, запущенные без подобных опций, являются ведущими узлами).
Репликация помогает защитить данные, копируя их на другие сервера. Репликация также может быть использована для увеличения производительности, так как запросы на чтение могут обслуживаться ведомыми узлами (горизонтальное масштабирование по чтению, но не по записи). Узлы-реплики могут ответить слегка устаревшими данными, но для многих приложений это приемлемо.
Система репликации Redis сама по себе не поддерживает автоматическую отказоустойчивость: если ведущий узел выходит из строя, необходимо вручную выбрать нового ведущего среди ведомых узлов; но имеется система Redis Sentinel, обеспечивающая мониторинг и автоматическое переключение.
Redis Sentinel — специализированная система управления узлами Redis, выполняющая следующие задачи:
Redis Sentinel входит в состав Redis начиная с версии 2.6 (Sentinel 1 — устарел). Начиная с версии Redis 2.8 поставляется текущая версия — Sentinel 2.
Sentinel не рекомендуется использовать в единственном экземпляре, кластер Sentinel-узлов поддерживает кворум, благодаря чему сохраняет работоспособность даже при переменном составе и временном отсутствии некоторых из них
Буду работать с сырыми redis командами, чтобы не завязываться на какую-либо конкретную библиотеку, предоставляющую обертку над этими командами. Об этом говорит сайт https://intellect.icu . Код буду писать на PHP с использованием ext-redis, но он здесь для наглядности, использовать представленные подходы можно в связке с любым другим языком программирования.
Давайте начнем с самого простого, один из самых популярных кейсов использования Redis — кэширование данных. Будет полезно для тех, кто не работал с Redis. Для тех, кто уже давно пользуется этим инструментом — можно смело переходить к следующему кейсу. Для того, чтобы снизить нагрузку на БД, иметь возможность запрашивать часто используемые данные максимально быстро, используется кэш. Redis — это in-memory хранилище, то есть данные хранятся в оперативной памяти. Еще это key-value хранилище, где доступ к данным по их ключу имеет сложность O(1) — поэтому данные мы получаем очень быстро.
Получение данных из хранилища выглядит следующим образом:
public function getValueFromCache(string $key)
{
return $this->getRedis()->rawCommand('GET', $key);
}
Но для того, чтобы данные из кэша получить, их нужно сначала туда положить. Простой пример записи:
public function setValueToCache(string $key, $value)
{
$this->getRedis()->rawCommand('SET', $key, $value);
}
Таким образом, мы запишем данные в Redis и сможем их считать по тому же самому ключу в любой нужный нам момент. Но если мы будем все время писать в Redis, данные в нем будут занимать все больше и больше места в оперативной памяти. Нам нужно удалять нерелевантные данные, контролировать это вручную достаточно проблематично, поэтому пускай redis занимается этим самостоятельно. Добавим к нашему ключу TTL (время жизни ключа):
public function setValueToCache(string $key, $value, int $ttl = 3600)
{
$this->getRedis()->rawCommand('SET', $key, $value, 'EX', $ttl);
}
По истечении времени ttl (в секундах) данные по этому ключу будут автоматически удалены.
Как говорят, в программировании существует две самых сложных вещи: придумывание названий переменных и инвалидация кэша. Для того, чтобы принудительно удалить значение из Redis по ключу, достаточно выполнить следующую команду:
public function dropValueFromCache(string $key)
{
$this->getRedis()->rawCommand('DEL', $key);
}
Также редис позволяет получить массив значений по списку ключей:
public function getValuesFromCache(array $keys)
{
return $this->getRedis()->rawCommand('MGET', ...$keys);
}
И соответственно массовое удаление данных по массиву ключей:
public function dropValuesFromCache(array $keys)
{
$this->getRedis()->rawCommand('MDEL', ...$keys);
}
Используя имеющиеся в Redis структуры данных, мы можем запросто реализовать стандартные очереди FIFO или LIFO. Для этого используем структуру List и методы по работе с ней. Работа с очередями состоит из двух основных действий: отправить задачу в очередь, и взять задачу из очереди. Отправлять задачи в очередь мы можем из любой части системы. Получением задачи из очереди и ее обработкой обычно занимается выделенный процесс, который называется консьюмером (consumer).
Итак, для того, чтобы отправить нашу задачу в очередь, нам достаточно использовать следующий метод:
public function pushToQueue(string $queueName, $payload)
{
$this->getRedis()->rawCommand('RPUSH', $queueName, serialize($payload));
}
Тем самым мы добавим в конец листа с названием $queueName некий $payload, который может представлять из себя JSON для инициализации нужной нам бизнес логики (например данные по денежной транзакции, данные для инициализации отправки письма пользователю, etc.). Если же в нашем хранилище не существует листа с именем $queueName, он будет автоматически создан, и туда попадет первый элемент $payload.
Со стороны консьюмера нам необходимо обеспечить получение задач из очереди, это реализуется простой командой чтения из листа. Для реализации FIFO очереди мы используем чтение с обратной записи стороны (в нашем случае мы писали через RPUSH), то есть читать будем через LPOP:
public function popFromQueue(string $queueName)
{
return $this->getRedis()->rawCommand('LPOP', $queueName);
}
Для реализации LIFO очереди, нам нужно будет читать лист с той же стороны, с которой мы в него пишем, то есть через RPOP.

Тем самым мы вычитываем по одному сообщению из очереди. В случае если листа не существует (он пустой), то мы получим NULL. Каркас консьюмера мог бы выглядеть так:
class Consumer {
private string $queueName;
public function __construct(string $queueName)
{
$this->queueName = $queueName;
}
public function run()
{
while (true) { //Вычитываем в бесконечном цикле нашу очередь
$payload = $this->popFromQueue();
if ($payload === null) { //Если мы получили NULL, значит очередь пустая, сделаем небольшую паузу в ожидании новых сообщений
sleep(1);
continue;
}
//Если очередь не пустая и мы получили $payload, то запускаем обработку этого $payload
$this->process($payload);
}
}
private function popFromQueue()
{
return $this->getRedis()->rawCommand('LPOP', $this->queueName);
}
}
Для того, чтобы получить информацию о глубине очереди (сколько значений хранится в нашем листе), можем воспользоваться следующей командой:
public function getQueueLength(string $queueName)
{
return $this->getRedis()->rawCommand('LLEN', $queueName);
}
Мы рассмотрели базовую реализацию простых очередей, но Redis позволяет строить более сложные очереди. Например, мы хотим знать о времени последней активности наших пользователей на сайте. Нам не важно знать это с точностью вплоть до секунды, приемлемая погрешность — 3 минуты. Мы можем обновлять поле last_visit пользователя при каждом запросе на наш бэкенд от этого пользователя. Но если этих пользователей большое количество в онлайне — 10,000 или 100,000? А если у нас еще и SPA, которое отправляет много асинхронных запросов? Если на каждый такой запрос обновлять поле в бд, мы получим большое количество тупых запросов к нашей БД. Эту задачу можно решать разными способами, один из вариантов — это сделать некую отложенную очередь, в рамках которой мы будем схлопывать одинаковые задачи в одну в определенном промежутке времени. Здесь на помощь нам придет такая структура, как Sorted SET. Это взвешенное множество, каждый элемент которого имеет свой вес (score). А что если в качестве score мы будем использовать timestamp добавления элемента в этот sorted set? Тогда мы сможем организовать очередь, в которой можно будет откладывать некоторые события на определенное время. Для этого используем следующую функцию:
public function pushToDelayedQueue(string $queueName, $payload, int $delay = 180)
{
$this->getRedis()->rawCommand('ZADD', $queueName, 'NX', time() + $delay, serialize($payload))
}
В такой схеме идентификатор пользователя, зашедшего на сайт, попадет в очередь $queueName и будет висеть там в течение 180 секунд. Все другие запросы в рамках этого времени будут также отправляться в эту очередь, но они не будут туда добавлены, так как идентификатор этого пользователя уже существует в этой очереди и продублирован он не будет (за это отвечает параметр 'NX'). Так мы отсекаем всю лишнюю нагрузку и каждый пользователь будет генерить не более одного запроса в 3 минуты на обновление поля last_visit.
Теперь возникает вопрос о том, как читать эту очередь. Если методы LPOP и RPOP для листа читают значение и удаляют его из листа атомарно (это значит, что одно и тоже значение не может быть взято несколькими консьюмерами), то sorted set такого метода из коробки не имеет. Мы можем сделать чтение и удаление элемента только двумя последовательными командами. Но мы можем выполнить эти команды атомарно, используя простой LUA скрипт!
public function popFromDelayedQueue(string $queueName)
{
$command = 'eval "
local val = redis.call(\'ZRANGEBYSCORE\', KEYS , 0, ARGV , \'LIMIT\', 0, 1)
if val then
redis.call(\'ZREM\', KEYS , val)
end
return val"
';
return $this->getRedis()->rawCommand($command, 1, $queueName, time());
}
В этом LUA скрипте мы пытаемся получить первое значение с весом в диапазоне от 0 до текущего timestamp в переменную val с помощью команды ZRANGEBYSCORE, если нам удалось получить это значение, то удаляем его из sorted set командой ZREM и возвращаем само значение val. Все эти операции выполняются атомарно. Таким образом мы можем вычитывать нашу очередь в консьюмере, аналогично с примером очереди построенной на структуре LIST.
Я рассказал про несколько базовых паттернов очередей, реализованных в нашей системе. На текущий момент у нас в продакшене существуют более сложные механизмы построения очередей — линейных, составных, шардированных. При этом Redis позволяет все это делать при помощи смекалки и готовых круто работающих структур из коробки, без сложного программирования.
Mutex (блокировка) — это механизм синхронизации доступа к shared ресурсу нескольких процессов, тем самым гарантируя, что только один процесс будет взаимодействовать с этим ресурсом в единицу времени. Этот механизм часто применяется в биллинге и других системах, где важно соблюдать потоковую безопасность (thread safety).
Для реализации mutex на базе Redis прекрасно подойдет стандартный метод SET с дополнительными параметрами:
public function lock(string $key, string $hash, int $ttl = 10): bool
{
return (bool)$this->getRedis()->rawCommand('SET', $key, $hash, 'NX', 'EX', $ttl);
}
где параметрами для установки mutex являются:
Основное отличие от метода SET, используемого в механизме кэширования — это параметр NX, который говорит Redis о том, что значение, которое уже хранится в Redis по ключу $key, не будет записано повторно. В результате, если в Redis нет значения по ключу $key, туда произведется запись и в ответе мы получим 'OK', если значение по ключу уже есть в Redis, оно не будет туда добавлено (обновлено) и в ответе мы получим NULL. Результат метода lock(): bool, где true – блокировка поставлена, false – уже есть активная блокировка, создать новую невозможно.
Чаще всего, когда мы пишем код, который пытается работать с shared ресурсом, который заблокирован, мы хотим дождаться его разблокировки и продолжить работу с этим ресурсом. Для этого можем реализовать простой метод для ожидания освободившегося ресурса:
public function tryLock(string $key, string $hash, int $timeout, int $ttl = 10): bool
{
$startTime = microtime(true);
while (!this->lock($key, $hash, $ttl)) {
if ((microtime(true) - $startTime) > $timeout) {
return false; // не удалось взять shared ресурс под блокировку за указанный $timeout
}
usleep(500 * 1000) //ждем 500 миллисекунд до следующей попытки поставить блокировку
}
return true; //блокировка успешно поставлена
}
Мы разобрались как ставить блокировку, теперь нам нужно научиться ее снимать. Для того, чтобы гарантировать снятие блокировки тем процессом, который ее установил, нам понадобится перед удалением значения из хранилища Redis, сверить хранимый хэш по этому ключу. Для того, чтобы сделать это атомарно, воспользуемся LUA скриптом:
public function releaseLock(string $key, string $hash): bool
{
$command = 'eval "
if redis.call("GET",KEYS )==ARGV then
return redis.call("DEL",KEYS )
else
return 0
end"
';
return (bool) $this->getRedis()->rawCommand($command, 1, $key, $hash);
}
Здесь мы пытаемся найти с помощью команды GET значение по ключу $key, если оно равно значению $hash, то удаляем его при помощи команды DEL, которая вернет нам количество удаленных ключей, если же значения по ключу $key не существует, или оно не равно значению $hash, то мы возвращаем 0, что значит блокировку снять не удалось. Базовый пример использования mutex:
class Billing {
public function charge(int $userId, int $amount)
{
$mutexName = sprintf('billing_%d', $userId);
$hash = sha1(sprintf('billing_%d_%d'), $userId, mt_rand()); //генерим некий хэш запущенного потока
if (!$this->tryLock($mutexName, $hash, 10)) { //пытаемся поставить блокировку в течение 10 секунд
throw new Exception('Не получилось поставить lock, shared ресурс занят');
}
//lock получен, процессим бизнес-логику
$this->doSomeLogick();
//освобождаем shared ресурс, снимаем блокировку
$this->releaseLock($mutexName, $hash);
}
}
Достаточно частая задача, когда мы хотим ограничить количество запросов к нашему апи. Например на один API endpoint от одного аккаунта мы хотим принимать не более 100 запросов в минуту. Эта задача легко решается с помощью нашего любимого Redis:
public function isLimitReached(string $method, int $userId, int $limit): bool
{
$currentTime = time();
$timeWindow = $currentTime - ($currentTime % 60); //Так как наш rate limit имеет ограничение 100 запросов в минуту,
//то округляем текущий timestamp до начала минуты — это будет частью нашего ключа, //по которому мы будем считать количество запросов
$key = sprintf('api_%s_%d_%d', $method, $userId, $timeWindow); //генерируем ключ для счетчика, соответственно каждую минуту он будет меняться исходя из $timeWindow
$count = $this->getRedis()->rawCommand('INCR', $key); //метод INCR увеличивает значение по указанному ключу, и возвращает новое значение.
//Если ключа не существует, он будут инициализирован со значением 0 и после этого увеличен
$this->getRedis()->rawCommand('EXPIRE', $key, 60); // Обновляем TTL нашему ключу, выставляя его в минуту, для того, чтобы не накапливать не актуальные данные
if ($count > $limit) { //limit достигнут
return true;
}
return false;
}
Таким простым методом мы можем лимитировать количество запросов к нашему API, базовый каркас нашего контроллера мог бы выглядеть следующим образом:
class FooController {
public function actionBar()
{
if ($this->isLimitReached(__METHOD__, $this->getUserId(), 100)) {
throw new Exception('API method max limit reached');
}
$this->doSomeLogick();
}
}
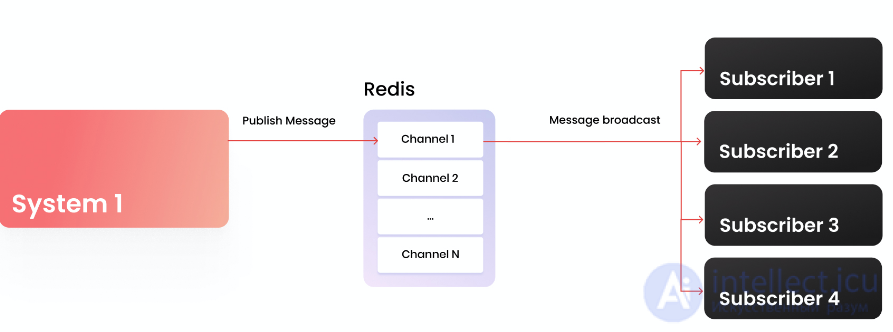
Pub/sub — интересный механизм, который позволяет, с одной стороны, подписаться на канал и получать сообщения из него, с другой стороны — отправлять в этот канал сообщение, которое будет получено всеми подписчиками. Наверное у многих, кто работал с вебсокетами, возникла аналогия с этим механизмом, они действительно очень похожи. Механизм pub/sub не гарантирует доставки сообщений, он не гарантирует консистентности, поэтому не стоит его использовать в системах, для которых важны эти критерии. Однако рассмотрим этот механизм на практическом примере. Предположим, что у нас есть большое количество демонизированных команд, которыми мы хотим централизованно управлять. При инициализации нашей команды мы подписываемся на канал, через который будем получать сообщения с инструкциями. С другой стороны у нас есть управляющий скрипт, который отправляет сообщения с инструкциям в указанный канал. К сожалению, стандартный PHP работает в одном блокирующем потоке; для того, чтобы реализовать задуманное, используем ReactPHP и реализованный под него клиент Redis.
Подписка на канал:
class FooDaemon {
private $throttleParam = 10;
public function run()
{
$loop = React\EventLoop\Factory::create(); //инициализируем event-loop ReactPHP
$redisClient = $this->getRedis($loop); //инициализируем клиента Redis для ReactPHP
$redisClient->subscribe(__CLASS__); // подписываемся на нужный нам канал в Redis, в нашем примере название канала соответствует названию класса
$redisClient->on('message', static function($channel, $payload) { //слушаем события message, при возникновении такого события, получаем channel и payload
switch (true) { // Здесь может быть любая логика обработки сообщений, в качестве примера пускай будет так:
case \is_int($payload): //Если к нам пришло число – обновим параметр $throttleParam на полученное значение
$this->throttleParam = $payload;
break;
case $payload === 'exit': //Если к нам пришла команда 'exit' – завершим выполнение скрипта
exit;
default: //Если пришло что-то другое, то просто залогируем это
$this->log($payload);
break;
}
});
$loop->addPeriodicTimer(0, function() {
$this->doSomeLogick(); // Здесь в бесконечном цикле может выполняться какая-то логика, например чтение задач из очереди и их процессинг
});
$loop->run(); //Запускаем наш event-loop
}
}
Отправка сообщения в канал — более простое действие, мы можем сделать это абсолютно из любого места системы одной командой:
public function publishMessage($channel, $message)
{
$this->getRedis()->publish($channel, $message);
}
В результате такой отправки сообщения в канал, все клиенты, которые подписаны на данный канал, получат это сообщение.
Мы рассмотрели 5 примеров использования Redis на практике, надеюсь что каждый найдет для себя что-то интересное. В нашем стэке технологий Redis занимает важное место, мы любим этот инструмент за его скорость и гибкость.
Данная статья про redis подтверждают значимость применения современных методик для изучения данных проблем. Надеюсь, что теперь ты понял что такое redis и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Redis DB Nosql
Комментарии
Оставить комментарий
Redis DB Nosql
Термины: Redis DB Nosql