Лекция
Привет, Вы узнаете о том , что такое redis временные последовательности, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое redis временные последовательности, redis фильтр блума, счётчик redis , паттерн подсчёта битов redis , redis hyperloglog, redis lua-скрипты , настоятельно рекомендую прочитать все из категории Базы данных - Redis DB Nosql.
Данная статья содержит следующие темы:
Данные временных последовательностей, или данные с естественным временным порядком, могут быть смоделированы в Redis несколькими способами в зависимости от самих данных и желаемого вами способа доступа к ним. Мы рассмотрим несколько таких паттернов:
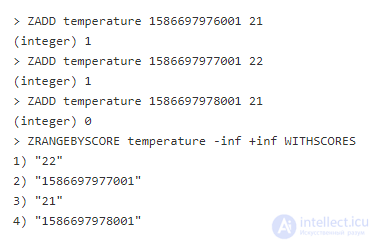
Временные последовательности на сортированных множествах (zsets) – типичный способ моделирования временной последовательности в Redis. Сортированные множества состоят из уникальных объектов, счета (scores) которых хранятся под одним ключом. Использование этого типа данных для сортированных множеств означает, что счет ведет себя как своего рода указатель времени (зачастую это отметка времени с точностью до миллисекунды), а элемент – записываемые данные. Единственная выгода заключается в том, что, поскольку это форма множества, допускаются только уникальные элементы, и попытка записать временные последовательности с одинаковыми значениями лишь обновит счет. Чтобы проиллюстрировать эту проблему возьмем следующий пример периодической записи температуры:
| Временная метка | Температура, C |
|---|---|
| 1686697976001 | 21 |
| 1686697977001 | 22 |
| 1686697978001 | 21 |
Если просто добавить их в сортированное множество, используя ZADD, можно потерять некоторые значения:
АНТИ-ПАТТЕРН
Обратите внимание, что третий вызов ZADD возвращает 0, что говорит о том, что новый элемент не был добавлен ко множеству. Затем в ZRANGEBYSCORE мы видим, что в сортированном множестве лишь две записи. Почему? Потому что первая и третья делят один и тот же объект, и мы просто обновили счет у этого объекта. Есть несколько способов обхода этой проблемы. Один из них – включить какие-то случайные данные с достаточным разбросом, обеспечив тем самым уникальность.
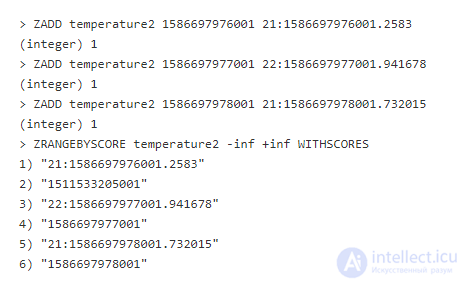
Для начала создадим псевдослучайное вещественное число от 0 до 1 не включительно, затем добавим его к нашей временной метке. В нашем примере мы оставим его в десятичной форме для читабельности (в реальности разумней будет просто конвертировать в 8-байтовую строку для экономии пространства).
Как видите, все ZADD вернули 1, обозначая успешное добавление, и ZRANGEBYSCORE вернул все значения. Это рабочий метод, однако, это не очень эффективно из-за траты байтов для обеспечения уникальности, что добавляет накладных расходов хранилищу. В большинстве случаев уникальность будет просто отметаться вашим приложением. Следует отметить, что добавление уникальности не потребуется, если ваши данные будут уже уникальными (например, данные, включающие UUID).
С этим методом у вас есть доступ ко всем методам сортированных множеств для анализа и управления:
ZINTERSTORE и ZUNIONSTORE операции, работающие с несколькими ключами. При работе с разделяемым окружением нужно быть осторожным, проверять, что ваш новый ключ окажется в том же сегменте, иначе эти команды приведут к ошибке.
Другой способ работы с временными последовательностями – использование лексикографических свойств сортированных множеств, чтобы хранить временную метку и значение. Если вы еще не знакомы с этим, то самое время прочитать этот раздел.
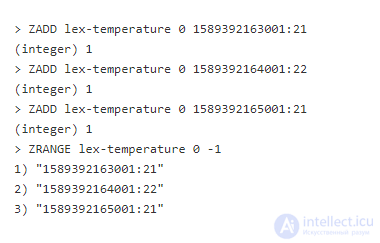
При этом методе мы храним все с тем же самым счетом и кодируем сначала временную метку, затем добавляем значение в качестве элемента. Возьмем пример:
В этих трех вызовах ZADD временная метка отделена от значения двоеточием, и мы можем увидеть, что каждый раз возвращается 1, что означает, что все три были добавлены. В ZRANGE мы видим сохраненный порядок. Почему? В сортированных множествах, если счет одинаков, результаты с тем же счетом упорядочены бинарной сортировкой. Так как временные метки в данный период имеют то же количество цифр, все будут отсортированы правильно (если ваши временные метки находятся до 2002 или после 2285, вам понадобятся еще цифры для заполнения).
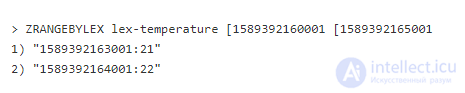
Чтобы получить диапазон значений из этого типа, используйте команду ZRANGEBYLEX:
Второй аргумент имеет префикс (, указывающий на исключительность значения (включительность обозначается [). На практике такой формат делает включительность и исключительность нерелевантной, так как за временной меткой всегда будут следовать дополнительные данные. Об этом говорит сайт https://intellect.icu . Третий аргумент + указывает на неограниченность верхней границы.
Попытаемся получить дату между 1689392160001 и 1689392165001 включительно:
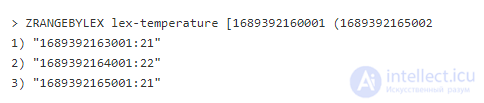
Почему данные по временной метке 1689392165001 не попали в выборку, несмотря на включительный префикс? Хочется верить, что Redis как-то понимает, что это временная метка. На деле же Redis просто видит бинарную сортировку. В бинарной сортировке 1689392165001:21 больше, чем 1689392165001 включительно или исключительно. Корректный способ включить это в верхнюю границу – добавить 1 миллисекунду к нужной верхней границе и использовать исключительность:
У временных последовательностей с лексикографически сортированными множествами есть похожий набор полезных команд, как у временных последовательностей с просто сортированными множествами:
ZINTERSTORE и ZUNIONSTORE можно использовать на лексикографически сортированных множествах, однако есть риск потери данных, поскольку дублирующиеся комбинации временных меток и значений не будут дублироваться в возвращаемом результате.
Вы можете задаться вопросом, зачем выбирать сортированные множества с временными метками вместо кодирования лексикографически сортированных множеств. Как правило лучше работать с лексикографически сортированными множествами для временных последовательностей – если значения не будут всегда уникальными, временные метки будут более эффективны.
Redis может эффективно хранить временные последовательности в битовых полях. Для этого нужно сначала выбрать произвольную точку отсчета и числовой формат. Возьмем пример с измерением температуры.
Предположим, мы хотим брать температуру каждую минуту, и точкой отсчета мы сделаем полночь каждого дня. Мы измеряем температуру в помещении в градусах Цельсия. Можно структурировать данные следующим образом:
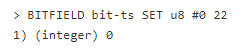
За день наберется данных примерно на 1.44 кб. Записать температуру можно командой BITFIELD:
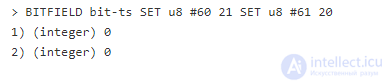
В этом случае по ключу bit-ts в беззнаковое 8-битное число (u8) в полночь (#0) записывается значение температуры 22.
Битовые поля не ограничены беззнаковыми 8-битными значениями. Обратите внимание на знак решетки перед смещением (offset). Он означает, что будет происходить выравнивание по выбранному типу. Например, если вы укажете "#79" – это будет означать 79й байт, «79» – 79й бит (см. справку по BITFIELD).
Смещение может быть выровнено по типу сохраненного числа, начиная от 0. Например, если мы хотим записать 1 a.m, учитывая нулевые слоты, мы используем смещение #59 или смещение #719 для полудня.
Пример также показывает, что BITFIELD вариативен, т.е. можно работать с несколькими значениями в одном вызове.
Добавим еще несколько значений:
И теперь извлечем:
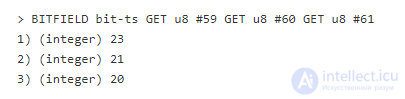
Сигнатура битовой подкоманды GET похожа на сигнатуру SET с той лишь разницей, что она не принимает третьим аргументом значение. Нормально, когда мы знаем все индексы, которые надо получить, но иногда нам нужен диапазон значений, и обозначать каждый байт по отдельности будет слишком напряжно. Мы можем использовать команду GETRANGE. В нормальной ситуации она используется для получения байтов из строки, но BITFIELDы – просто другой способ адресации тех же данных.
Команда вернула байты с 59 по 61 в шестнадцатеричном виде (23, 21 и 20 в десятичной. Клиентские языки обрабатывают двоичные данные лучше, чем «redis-cli», и обычно могут получить специфичный для языка массив байтов.
В нашем примере мы использовали байты 0, 59-61 и 719. Что будет, если мы запросим байты, которые еще не заданы?
Redis отдает незаданные байты как 0. Это может вызвать затруднения при работе с данными временных последовательностей – логике приложения нужно отличать 0 и неустановленное значение. Возможны округления и пропуски значений 0, особенно при использовании целых чисел со знаком, поскольку это может быть допустимым значением в середине вашего диапазона.
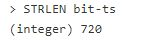
Реальная длина временной последовательности на самом деле зависит от последнего байта. В примере последний сохраненный байт – 719, поэтому длина данных 720 байтов.
Временные последовательности основанные на BITFIELD – мощный и компактный паттерн для хранения числовых или двоичных данных. Однако, это решение не покрывает всех вариантов использования, и его использование должно быть тщательно обдумано на соответствие вашим потребностям.
Создать ограничитель пропускной способности с Redis легко, благодаря наличию команд INCR и EXPIRE. Идея в том, что вы хотите ограничивать запросы к определенному сервису в заданный промежуток времени. Допустим, у нас есть сервис, в котором пользователи идентифицируются по ключу API. В сервисе действует ограничение на 20 запросов в минуту. Для реализации этого мы хотим создавать каждую минуту ключ Redis на ключ API. Чтобы не захламлять базу данных, время действия ключа устанавливаем также в 1 минуту.
Ключ API – zA21X31, жирный шрифт – лимит достигнут:

Ключ составляется из ключа API и номера минуты через двоеточие. Так как время действия ключей всегда истекает, нам достаточно использовать только номера минут – с наступлением нового часа можно быть уверенным, что других 59 ключей уже нет (они истекли 59 минут назад).
Рассмотрим, как это работает:
Два ключевых момента:
Худший сценарий – если по какой-то очень странной и маловероятной причине сервер Redis умирает между INCR и EXPIRE. При восстановлении данных либо из AOF, либо из in-memory реплики, INCR не будет восстановлен, так как транзакция не была выполнена.
При использовании этого паттерна возможна ситуация, когда у одного пользователя окажется два ключа: один, который используется в настоящий момент, и другой, время действия которого истекает в эту минуту. Тем не менее паттерн очень эффективен.
Фильтр Блума – интересная вероятностная структура данных, которую можно использовать, чтобы проверить, не был ли элемент добавлен ранее. Здесь намеренно такая формулировка.
Вероятностность в том, что может быть только ложноположительное срабатывание, но не ложноотрицательное. Фильтр Блума предоставляет намного более компактный и быстрый способ проверить наличие, чем сохранять все элементы во множество и вызовать SISMEMBER.
Фильтр Блума работает, пропуская элемент через функцию быстрого хэширования, отбирая из него биты и устанавливая их в 1 и 0 через определенный интервал в битовом поле. Чтобы проверить наличие в фильтре, отбираются одинаковые биты. У многих элементов могут быть биты, которые перекрываются, но, так как хэш-функция создает уникальные идентификаторы, если один бит из хэша все еще равен 0, тогда мы знаем, что он не был добавлен ранее.
Фильтр используется в Redis много лет как клиентская библиотека, которая использует GETBIT и SETBIT для работы с битовыми полями. К счастью, с версии Redis 4.0 доступен модуль ReBloom, который избавляет от создания собственной реализацию фильтра Блума.
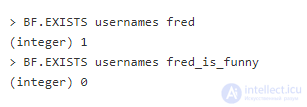
Хороший вариант использования для этого фильтра – проверка, было ли уже использовано имя пользователя. На малых размерах данных проблем нет, но по мере роста сервиса запросы к базе данных могут дорого стоить. Это легко исправить с ReBloom.
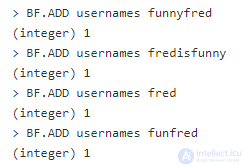
Добавим несколько имен для теста:
Теперь протестируем фильтр Блума:
Как и ожидалось, fred_is_funny вернул 0. Это означает, что такое имя не было использовано. Хотя нельзя сказать наверняка, поскольку биты могут просто перекрыться между несколькими элементами. В основном шанс ложноположительного срабатывания низкий, но не равен 0. По мере заполнения фильтра Блума шанс возрастает, но можно настроить частоту ошибок и начальный размер (по умолчанию 0.01 и 100 соответственно).
Счетчик в Redis можно реализовать несколькими способами. Наиболее очевидный – INCR со товарищи (INCRBY, INCRBYFLOAT, HINCRBY, HINCRBYFLOAT, ZINCRBY), применение которым можно найти, просто прочтя документацию. Менее очевидные – использование BITCOUNT и PFADD.
BITCOUNT считает число битов, установленных в 1 в битовом поле по ключу. Это можно использовать для подсчета серии активностей в течение произвольного периода времени (наподобие паттерну временных последовательностей на битовых полях). Процесс заключается в выборе момента времени, и каждый бит представляет единицу периода. Каждый раз, когда в течение этого периода совершается действие, запускаем SETBIT на расстоянии в 1 единицу от последней точки.

Вычислить, в какие минуты с 12:00 по 12:30 происходила активность, можно так:
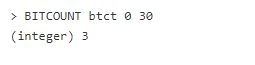
В целом, этот паттерн отвечает на вопрос “Как часто?”, а не “Сколько раз?”. Например, пользователь мог быть активным 20 раз в течение одной минуты, но это засчитается как 1.
Реальным преимуществом этого шаблона является то, что он обеспечивает минимально возможный счет в течение определенного периода времени, поскольку биты являются самыми элементарными строительными блоками хранения. Это буквально наименьшее (несжатое) хранилище для подсчета.
Подсчет уникальных элементов может оказаться непростым. Обычно это означает сохранение каждого уникального элемента, а затем вызов этой информации каким-то образом. В Redis это можно сделать, используя множество и одну команду, однако, и занимаемый объем, и временная сложность этого будут очень велики. HyperLogLog предоставляет вероятностную альтернативу.
HyperLogLog внутренне похож на фильтр Блума, также подает элементы через некриптографическую хэш-функцию и устанавливает биты в битовом поле. Но, в отличие от фильтра Блума, HyperLogLog хранит счетчик элементов, который инкрементируется, когда добавляется новый элемент, не добавленный ранее. Это дает низкий уровень ошибок при подсчете уникальных элементов в множестве. HyperLogLog встроен прямо в Redis.
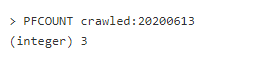
Существует 3 команды HyperLogLog в Redis: PFADD, PFCOUNT и PFMERGE. Допустим, мы создаем веб-сканер и хотим подсчитывать количество уникальных URL страниц, просмотренных в течение дня. Для каждой страницы запустим следующую команду:
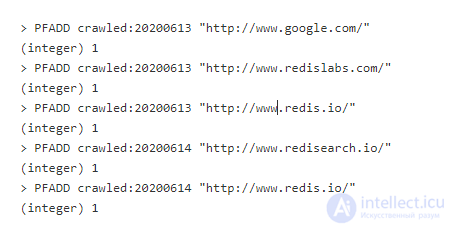
Каждый ключ выше индексируется по дням. Посмотреть, сколько страниц было просмотрено 13.06.2020, можно так:
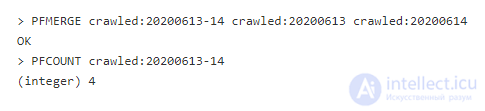
Для просмотра количества страниц за 13.06.2020 и 14.06.2020, используем команду PFMERGE, чтобы создать новый ключ со значением, объединяющим два счетчика. Обратите внимание, что, так как www.redis.io хранится в обоих множествах, подсчитан он будет единожды:
Это операция может работать с несколькими ключами, поэтому будьте осторожны в разделенном окружении, дабы ключи оказались на одном шарде.
Redis может делать изумительные вещи просто из «redis-cli» и еще больше между Redis и вашим языком программирования. Но иногда может потребоваться поведение, которого нельзя получить в клиент-серверной архитектуре из-за вопросов эффективности или безопасности – логику нужно выполнить в слое базы данных. В таких случаях на помощь приходит Lua. Lua работает в Redis как скриптовый язык. С ним можно выполнять код в Redis, без затрат на транспорт до и от клиента.
Тестовый пример – добавление значения к хэш-полю. В то время как Redis может легко добавлять значение к строковому ключу при помощи APPEND, нет команды для добавления значения к хэш-полю. Можно попытаться получить это, извлекая значение клиентом, добавляя новую строку к значению и сбросывая хэш-поля, но это плохая идея. Так как это неатомарно, есть вероятность, что пока вы добавляете значение, другой клиент может изменить его раньше, и тогда вы перезапишете новое значение.
| # | Клиент 1 | Клиент 2 |
|---|---|---|
| 1 |
[возвращается «hello»] |
|
| 2 | [добавляет «world» к «hello»] |
|
| 3 |
|
|
| 4 |
|
Как можно видеть на строке 2, обновление будет утеряно. Можно использовать Lua-скрипты, чтобы обойти эту проблему и убрать расходы на отправку/получение значений с клиента.
В любом текстовом редакторе создадим скрипт и назовем это happened.lua:

В первой строке создаем локальную переменную original, в которую сохраним текущее значение ключа хэша из первого переданного аргумента, а поле является первым неключевым аргументом. Важно понимать, что Lua-скрипты во время выполнения делают различия между ключами и неключевыми аргументами.
На второй строке вызывается HSET для того же ключа и поля, затем объединяем оригинальное значение со вторым неключевым аргументом. Это возвращается обратно в Redis, поэтому мы сохраним оригинальное возвращаемое значение HSET.
Непосредственное выполнение Lua-скриптов командой EVAL может быть запутанным и неэффективным. В Redis есть встроенный кэш скриптов, который позволяет предзагрузить скрипт, затем обратиться к нему по SHA1-хэшу из основного скрипта. Загрузить этот скрипт из командной строки можно с помощью «cat» и «redis-cli». Обратите внимание, если ваш скрипт будет отличаться хотя бы на один символ, у него будет совсем другой хэш. 
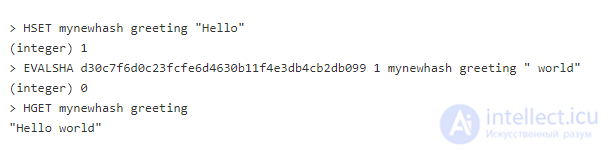
Сейчас можно использовать EVALSHA, чтобы вызвать скрипт и сделать добавление:
Первый аргумент команды EVALSHA – хэш скрипта, созданного SCRIPT LOAD. Второй аргумент – количество ключей. В нашем случае ключ один. Третий аргумент – ключ, над которым выполняем действие. И наконец четвертый – значение, которое добавляем к полю.
Поскольку добавление происходит внутри Lua-скрипта, сценарий выше прервется, так как Lua-скрипты выполняются синхронно и атомарно.
Хоть Lua может быть очень полезным при решении проблем, использовать его нужно осторожно. Скрипт блокирует сервер и может привести к не отвечающей базе данных. В ситуациях с шардингом скрипты пытаются сохранить все операции на одном сервере, чтобы избежать перекрестных ошибок.
Данная статья про redis временные последовательности подтверждают значимость применения современных методик для изучения данных проблем. Надеюсь, что теперь ты понял что такое redis временные последовательности, redis фильтр блума, счётчик redis , паттерн подсчёта битов redis , redis hyperloglog, redis lua-скрипты и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных - Redis DB Nosql






Комментарии