Лекция
Привет, Вы узнаете о том , что такое Паттерны индексирования Redis, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое Паттерны индексирования Redis , настоятельно рекомендую прочитать все из категории Redis DB Nosql.
Redis можно использовать бесчисленным количеством способов, однако, есть несколько паттернов, с помощью которых можно решать часто возникающие проблемы. Мы собрали коллекцию общих паттернов, которые мы считаем best practices для решения этих проблем. Эта коллекция не является исчерпывающей и не представляется как набор единственных способов использования Redis, но мы надеемся, она послужит отправной точкой для решения проблем с помощью Redis.
В этой статье рассмотрим способы выйти за рамки обычного доступа «ключ-значение» с Redis. Туда входят способы умного использования паттернов на ключах с использованием различных типов данных Redis, чтобы помочь не только в поиске данных, но и снизить сложность доступа;
Концептуально Redis – база данных, базирующаяся на парадигме «ключ/значение», когда каждая порция данных ассоциируется с неким ключом. Если вы хотите получить данные по чему-то кроме ключа, вам нужно будет реализовать индекс, который использует один из многих типов данных, доступных в Redis.
Индексирование в Redis довольно сильно отличается от того, что представлено в других базах данных, поэтому ваши собственные сценарии использования и данные определят лучшую стратегию для индексирования. В этой главе мы рассмотрим некоторые общие стратегии поиска данных помимо простого получения по «ключу/значению»:
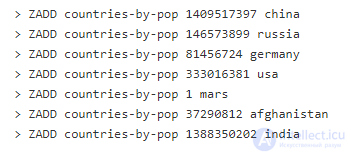
Сортированные множества (ZSETs) — стандартный тип данных в Redis, который представляет множество уникальных объектов (повторения не сохраняются), где каждый объект закреплен за числом (называемое «счет»), которое выступает как естественный механизм сортировки. И хотя объекты не могут повторяться, любые несколько объектов могут иметь одинаковый счет. При относительно невысокой временной сложности на добавление, удаление и получение диапазона значений (по рангу или счету) сортированные множества вполне пригодны для того, чтобы быть индексами. В качестве примера возьмем страны мира, ранжированные по населению:
Получить топ-5 стран будет просто:
А получение стран с населением между 10000000 и 1000000000:
Можно создать несколько индексов, чтобы продемонстрировать разные способы сортировки данных. В нашем примере мы могли бы использовать те же объекты, но вместо количества людей взять плотность населения, географические размеры, количество пользователей Интернет и т.д. Это создаст высокопроизводительные индексы для разных аспектов. Кроме того, деля имя объекта с данными о нем, хранящимися либо в Redis (в Hash, например), либо в другом хранилище данных, вторичный процесс мог бы получить дополнительную информацию о каждом элементе по мере необходимости.
Эта команда добавит нескольких животных к ключу animal-list. У каждый объекта счет 0. Выполнив команду ZRANGE с аргументами 0 и -1, увидим любопытный порядок:
Несмотря на то, что элементы были добавлены не в алфавитном порядке, они оказались возвращены отсортированными по алфавиту. Такой порядок является результатом двоичного сравнения строк, побайтового. Это значит, что ASCII-символы вернутся в алфавитном порядке. Это говорит о следующем:
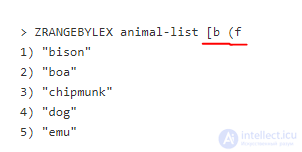
Redis также предоставляет некоторые продвинутые возможности для дальнейшего сужения лексикографического поиска. Например, мы хотим вернуть животных, начинающихся с b и заканчивающихся на e. Мы можем использовать следующую команду:
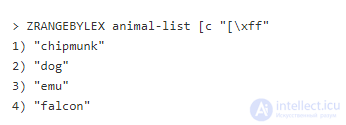
Аргумент (f может немного смутить. Это важный момент, потому что Redis не имеет никакого понятия о буквальном понимании букв алфавита. Это значит, что мы должны учитывать, что все начинающееся с e всегда будет стоять до всего начинающегося с f, независимо от последующих букв. Другое примечание заключается в том, что квадратная скобка указывает на поиск с включением, а круглая на поиск без включения. В нашем случае, если мы запрашиваем с b, это будет включено в список, тогда как f не появится в выборке. Если вам нужны все элементы до конца, используйте закодированный последний символ (255 или 0xFF):
Эту команду можно также ограничить, обеспечив тем самым постраничный вывод:
У Redis есть несколько команд, связанных с геопространственным индексированием (GEO команды), но, в отличие от других команд, у этих команд нет собственных типов данных. Эти команды на самом деле дополняют тип сортированного множества. Это достигается кодированием широты и долготы в счет (score) сортированного множества, используя алгоритм геохэша.
Добавить элементы к геоиндексу легко. Предположим, вы отслеживаете группу автомобилей, которые едут по дороге. Назовем это множество машин просто «cars». Скажем, что ваша особая машина может быть идентифицирована как объект «my-car» (мы используем термин «объект», потому что геоиндекс просто форма множества). Чтобы добавить машину ко множеству, мы можем выполнить команду:
Первый аргумент – множество, к которому добавляем, второй – широта, третий – долгота и четвертый – имя объекта.
Чтобы обновить местоположение машины, нужно просто выполнить команду снова с новыми координатами. Это работает, потому что геоиндекс – это просто множество, где повторяющиеся элементы непозволительны.
Добавим вторую машину к «cars». На этот раз ведет ее Володя:
Взглянув на координаты, вы можете сказать, что это машины довольно недалеко друг от друга, но насколько? Вы можете определить это командой GEODIST:
Это значит, что два транспортных средства примерно в 151 метре друг от друга. Можно посчитать также в других единицах измерения:
Это вернуло то же самое расстояние в футах. Вы также можете использовать мили (ml) или километры (km).
Сейчас давайте посмотрим, кто есть в радиусе определенной точки:
Это вернуло всех в радиусе 100 метров вокруг указанной точки. Можно также запросить всех в радиусе какого-либо объекта из множества:
Мы можем также включить дистанцию, добавив необязательный аргумент WITHDIST (это работает для GEORADIUS или GEORADIUSBYMEMBER):
Другой необязательный аргумент для GEORADIUS и GEORADIUSBYMEMBER – WITHCOORD, который возвращает координаты каждого объекта. WITHDIST и WITHCOORD можно использовать вместе или по отдельности:
Так как геопространственные индексы – это просто альтернатива сортированным множествам, можно пользоваться некоторыми операторами последних. Если мы хотим удалить «my-car» из множества «cars», можно использовать команду сортированного множества ZREM:
Redis предоставляет богатый набор инструментов для работы с геопространством, и в этом разделе мы рассмотрели только базовые из них.
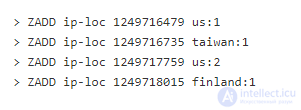
Нахождение фактического местоположения подключенного сервиса может быть очень полезным. Таблицы IP-геолокации, как правило, довольно велики и ими сложно эффективно управлять. Мы можем использовать сортированные множества, чтобы реализовать быстрые и эффективные сервисы IP-геолокации.
На IPv4 люди чаще всего ссылаются в десятичной нотации (74.1251.43.992, например). Однако сетевые сервисы видят этот же самый адрес как 32-битное число, причем каждый байт представляет одно из четырех чисел в десятичной форме. Пример выше будет 0x4A7D2B61 в шестнадцатеричном виде или 1249717090 в десятичном.
Наборы данных IP-геолокации широко доступны и обычно имеют форму простой таблицы с тремя колонками (начало, конец, местоположение). Начало и конец – десятичное представление IPv4. В Redis мы можем адаптировать сортированные множества под этот формат, потому что в диапазонах IP отсутствуют «дыры», следовательно, можно с уверенностью допустить, что конец одного диапазона – это начало другого.
Для простого примера добавим несколько диапазонов в сортированные множества:
Первый аргумент – ключ нашего множества, второй – десятичное предствление конца IP-диапазона, и последний – собственно, сам объект. Обратите внимание, что объект множества имеет число после двоеточия. Это просто для облегчения примера. В реальных IP-таблицах для каждого диапазона свои уникальные идентификаторы (и больше дополнительной информации, чем просто название страны).
Чтобы запросить таблицу к данному IP-адресу, мы можем использовать команду ZRANGEBYSCORE с несколькими дополнительными аргументами. Возьмем IP-адрес и конвертируем его в десятичный вид. Это можно сделать средствами вашего языка программирования. Для начала используем адрес из исходного примера 74.125.43.99 (1249717091). Если мы возьмем это число в качестве начало отсчета и не укажем максимум, а затем ограничим результат только до первого объекта, мы найдем его геоположение:
Первый аргумент – ключ нашего сортированного множества, второй – десятичное представление IP-адреса, третий (+inf) говорит Redis запрашивать без верхней границы, и последние три аргумента просто указывают, что мы хотим получить только самый первый результат.
До появления модулей полнотекстовый поиск был реализован с использованием собственных команд Redis. Модуль RedisSearch намного более производительный, чем этот паттерн, однако, в некоторых окружениях он недоступен. Кроме того, этот паттерн очень интересен и может быть обобщен для других рабочих нагрузок, в которых RedisSearch будет не идеален.
Допустим, у нас есть несколько текстовых документов, по которым нужно произвести поиск. Это может быть неочевидный use-case для Redis, так как он осуществляет доступ по ключам, но, с другой стороны, Redis может быть использован как совершенно новый полнотекстовый поисковый движок.
Сначала возьмем несколько примерных текстов в документах:

Разделим их на наборы слов, разделенных пробелом для простоты:
Обратите внимание, что мы помещаем каждую строку в свое собственное множество. Может показаться, что мы просто добавляем всю строку – SADD является вариативным и принимает сразу несколько элементов в качестве аргументов. Мы также перевели все слова в нижний регистр.
Затем нам нужно инвертировать этот индекс и показать, какое слово в каком документе содержится. Для этого мы сделаем множество для каждого слова и поместим имя документа в качестве объекта:
Для ясности мы разделили это на разные команды, но все команды обычно выполняются атомарно в блоке MULTI/EXEC.
Чтобы запросить наш крошечный полнотекстовый индекс, мы используем команду SINTER (пересечение множеств). Найти документы с «very» и «fast»:
В случае, когда нет документов, соответствующих запросу, мы получим пустой результат:
Для логичности лучше использовать SUNION вместо SINTER:
Удаление объекта из индекса немного сложнее. Сначала получим индексированные слова из документа, затем удалим идентификатор документа от каждого слова:
В Redis нет отдельного оператора, чтобы выполнить все эти шаги одной командой, поэтому сначала придется запрашивать командой SMEMBERS, затем последовательно удалять каждый объект при помощи SREM.
Конечно, это очень упрощенный полнотекстовый поиск. Можно сделать более продвинутый, используя сортированные множества вместо обычных. В этом случае, если в документе слово встречается больше одного раза, вы можете ранжировать его выше, чем документ, в котором оно встречается единожды. Описанные выше паттерны более-менее одинаковы, за исключением используемых типов множеств.
Единственный экземпляр (или шард) Redis очень жизнеспособный, но есть обстоятельства, когда вам может понадобиться индекс, распределенный по нескольким экземплярам. Например, чтобы повысить пропускную способность распараллеливанием индексов, размер которых превышает свободное пространство экземпляра. Скажем, вы хотите выполнить операцию над несколькими ключами. Эффективный способ разделить (партиционировать) эти ключи – обеспечить равномерное распределение ключей по каждой партиции, выполнять любые операции в каждой партиции параллельно и затем объединять результаты по окончанию.
Чтобы достичь равномерного распределения ключей, мы будем использовать некриптографический алгоритм хеширования. Подойдет любая быстрая функция хеширования, но мы используем известную CRC-32 для примера. В большинстве случаев эти алгоритмы возвращают результат в шестнадцатеричном виде (для «my-cool-document» CRC-32 выдаст F9FDB2C9). Шестнадцатеричное представление проще для машины, но это просто другое представление десятичных целых чисел, которое означает, что можно выполнять вычисления на этих значениях.
Далее нужно определить число партиций – это должно быть по крайней мере х2 от количества экземпляров. В дальнейшем это способствует масштабированию.
Допустим, у нас есть 3 экземпляра и 6 партиций. Вычислить партицию, на которую отправить документ, можно следующей операцией:

В Redis Enterprise вы можете контролировать, к какой партиции относится ключ, используя либо предопределенные регулярные выражения, либо оформив часть ключа фигурными скобками. Так для нашего примера мы можем установить ключ для документа следующим образом:
idx:my-cool-document{5}
Затем у нас есть другой документ, который выдает партицию с номером 3, следовательно, ключ будет выглядеть так:
idx:my-other-document{3}
Если у вас есть дополнительные вспомогательные ключи, с которыми вам нужно будет работать, и которые связаны с этим документом, вам нужно, чтобы они находились на той же партиции так, чтобы вы могли выполнять операции с обоими ключами одновременно, не сталкиваясь с кучей ошибок. Для этого вам надо добавить к ключу тот же самый номер партиции, что и у документа.
Отдаленно просматривая ваши данные, вы увидите, что ваш индекс довольно равномерно распределен по партициям. Вы можете распараллелить задачу, которую необходимо выполнить для каждой партиции. Когда у вас есть задача, которую нужно сделать через весь индекс, вашему приложению нужно будет выполнить ту же логику для каждой партиции, вернуть результат и объединить так, как требуется в приложении.
Данная статья про Паттерны индексирования Redis подтверждают значимость применения современных методик для изучения данных проблем. Надеюсь, что теперь ты понял что такое Паттерны индексирования Redis и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Redis DB Nosql


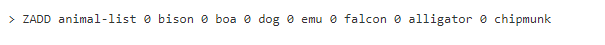


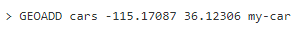
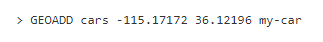
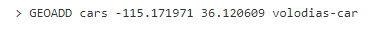


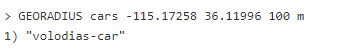







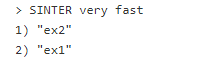



Комментарии
Оставить комментарий
Базы данных - Redis DB Nosql
Термины: Базы данных - Redis DB Nosql