Лекция
Привет, Вы узнаете о том , что такое переход от данных к конечному автомату, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое переход от данных к конечному автомату , настоятельно рекомендую прочитать все из категории Стили и методы программирования.
Таблицы переходов и состояний представляют собой метод программирования не только для задач, которые сводятся к конечным автоматам. При обсуждении XML/XSL-подхода к задаче стандартизованного представления таблиц переходов были указаны возможности применения методики оперирования со структурными представлениями данных и программ для более широкого класса алгоритмов.
Однако мы пока не решали задачи, когда представление алгоритма зависит от входных данных. Она классифицирована для автоматов как задача динамического порождения автомата (см. параграф 9.3, пункт 3). Конечно же, под таким углом зрения можно рассматривать трансляцию: текстовый файл на входном языке есть часть данных, генерирующая план обработки другой части данных, которая предъявляется при решении конкретной задачи. Вторая задача подобного типа, для которой разработаны методы, — это задача специализации универсальной программы. Она также может рассматриваться как уточнение общего плана, исходя из частичного знания обрабатываемых данных. Упомянутые случаи характеризуются тем, что представление алгоритма, зависящее от части входных данных, строится из заранее определенных заготовок. Например, для трансляции такими заготовками являются алгоритмы выполнения абстрактно-синтаксического представления программы.
В данном разделе показан иной метод построения алгоритма, зависящего от входных данных. Его идея в том, чтобы составить такоепредставление алгоритма, которое допускает непосредственную интерпретацию. Естественный путь демонстрации метода — взять за основу известный класс алгоритмов, конкретный представитель которого выбирается, исходя из знания о входных данных.
Обратимся к задаче, которая для каждого конкретного случая решается с помощью конечного автомата специального вида (как и всегда, выбор конкретного представления существенно влияет на сложность и другие характеристики программы, автоматическое применение ранее использованных представлений в других задачах не рекомендуется).
Пусть требуется подсчитать, сколько раз каждое из вводимых слов встречается в некотором большом файле (теперь слово — это любая последовательность символов). 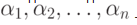 — вводимые слова;
— вводимые слова; 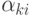 — слово. Напечатать:
— слово. Напечатать:
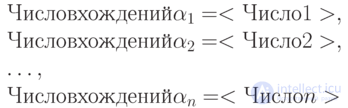
Где <Число k> — полное число вхождений слова 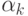 в файл с учетом возможного перекрытия слов (например, в строке *МАМАМА{} два вхождения слова МАМА ).
в файл с учетом возможного перекрытия слов (например, в строке *МАМАМА{} два вхождения слова МАМА ).
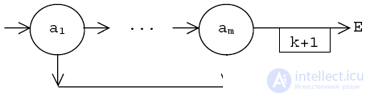
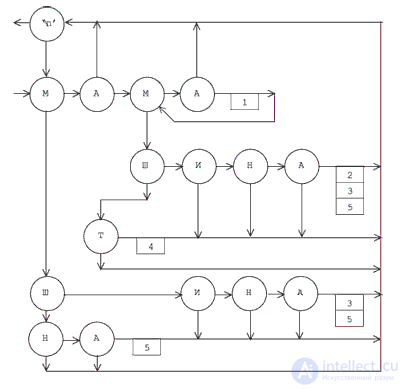
Для заданных заранее слов легко построить граф, каждая вершина которого представляет символы внутри слов. Его вершины помечены символом. Из такой вершины исходят две дуги: первая указывает на вершину, к которой следует переходить, когда очередной читаемый символ совпадает с пометкой вершины, а вторая — на ту, которая должна стать преемником данной в случае несовпадения. Легко видеть, что это одна из форм представления конечного автомата, каждое состояние которого кодирует множество всех вершин, связанных дугами второго вида, а состояния-преемники определяются дугами первого вида исходного графа. Для того, чтобы этот автомат работал (решал поставленную задачу), нужно снабдить его действиями, которые сводятся к увеличению счетчиков, соответствующих найденным словам, а также определить начальное и конечное состояния. Мы не будем переделывать исходный граф, поскольку такая его форма удобнее для интерпретации.
Если дуги первого вида изображать стрелками, исходящими в горизонтальном направлении, дуги второго вида — вертикальными стрелками, а действия со счетчиками — соответствующими пометками при дугах, то, например, для множества слов

может быть построен граф, показанный на рис. 12.1.
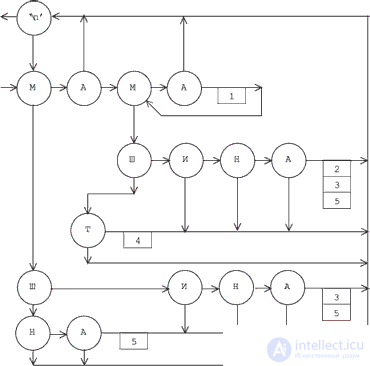
Для нашего примера граф-автомат представляется следующей таблицей (переход 111, указывающий за пределы таблицы, использован для обозначения завершения просмотра файла):
Программа интерпретации графа проста, и для данной задачи нет смысла применять транслирующий вариант реализации оперирования с таблицей. Операторы Current_Reaction(); и Final_Reaction(); использованы для обозначения действий со счетчиками, например, тех, которые приведены в комментариях.

В этом интерпретаторе структура данных не содержит описаний действий — они только идентифицируются значениями соответствующих полей таблицы. Важно, что здесь достигается универсальность, независимость от таблицы для всех вариантов ввода слов.
Несложно решение также когда вместо таблицы-массива используется списочная структура. Об этом говорит сайт https://intellect.icu . По существу ничто, кроме доступа к данным, который можно строго локализовать в соответствующих процедурах, не изменится. Выполните это решение самостоятельно. В то же время решение разработки текстового представления таблицы с числовой разметкой было бы во всех отношениях опрометчивым. Оно сложнее и не дает никаких преимуществ даже в тех случаях, когда процесс построения автомата отделен от его использования во времени. По тем же причинам вариант с XML не имеет никаких преимуществ. Другое дело, если речь пойдет об оперировании со списком слов (а не с таблицей!). Этот список целесообразно редактировать, запуская программу построения графа с помощью соответствующего обработчика списка слов и затем вызывая интерпретатор для работы с файлом. Рациональность такого подхода нужно оценить на этапе анализа жизненного цикла конструируемой программной системы.
Для обоих удовлетворительных решений требуется разработка алгоритма построения автомата по заданному набору слов. Если используется таблица-массив, то результатом такого построения должен быть заполненный массив. При списочной организации таблицы нужно составить соответствующий список. Для решения задачи могут быть построены различные автоматы, но эффективность дальнейшего их использования будет различна. Следовательно, можно ставить задачу оптимизации: выбор такого автомата из множества автоматов, который справляется с подсчетом вхождений за наиболее короткое время.
Построение графа автомата, достаточного для решения задачи, но не обязательно оптимального, можно реализовать, используя следующее рекуррентное описание алгоритма.
Если множество слов пустое, то граф задается структурой:
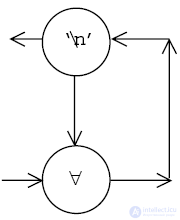
Вершина, содержащая \n, объявляется выходной для графа в целом (есть горизонтальная исходящая из нее дуга, которая никуда не ведет). Она обозначается далее E. На данном этапе входной вершиной является та, которая пропускает все символы (по определению у нее нет вертикальной исходящей дуги).
Пусть граф G определяет автомат, распознающий некоторое множество слов 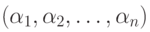 , и пусть есть слово
, и пусть есть слово 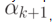 , которое нужно добавить к этому множеству. Добавление слова достигается с помощью следующих шагов:
, которое нужно добавить к этому множеству. Добавление слова достигается с помощью следующих шагов:
по слову 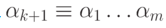 строится список вида
строится список вида
который рассматривается как заготовка для пополнения графа G
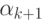 есть собственная часть какого-либо слова, то склейка заготовки с графом сводится к добавлению пометки k+1 у соответствующей горизонтальной дуги; в противном случае перейти к следующим пунктам;
есть собственная часть какого-либо слова, то склейка заготовки с графом сводится к добавлению пометки k+1 у соответствующей горизонтальной дуги; в противном случае перейти к следующим пунктам;для каждого слова  из
из 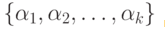 ищутся такие
ищутся такие 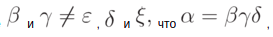 и
и 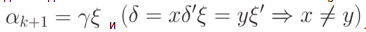 . В графе G есть фрагменты, отвечающие за распознавание
. В графе G есть фрагменты, отвечающие за распознавание 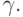 Следовательно, надо склеить заготовку с каждым из таких фрагментов, т. е. вставить вертикальную дугу от последнего вертикального преемника вершины x x1,...,i к остатку заготовки:
Следовательно, надо склеить заготовку с каждым из таких фрагментов, т. е. вставить вертикальную дугу от последнего вертикального преемника вершины x x1,...,i к остатку заготовки:
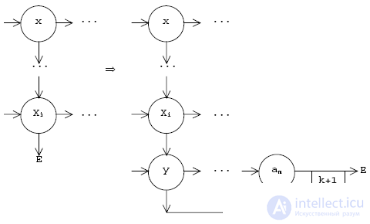
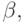
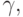
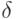 и
и 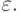
Улучшение данного алгоритма возможно, в частности, за счет стандартного приема оптимизации задач, обрабатывающих сложно структурированную взаимосвязанную информацию. Этот прием состоит в упорядочении данных. Слова можно расположить таким образом, что будет минимизировано число проверок в каждом (вертикальном) состоянии автомата. Другая идея улучшения алгоритма — в некоторых случаях, когда линейные участки распознавания оказываются относительно независимыми, вычислить локально оптимальные последовательности и распознавать сразу их вхождения. Такое агрегирование данных также является стандартным приемом. Наконец, чуть-чуть повысит эффективность размножение выходной вершины графа. Подобные модификации алгоритма предлагается выполнить самостоятельно.
Только что решенная задача, разумеется, является модельной. На практике подобные задачи приходится решать в основном в частных случаях (например, игнорируются пересечения слов, вместо подсчета числа вхождений может потребоваться другая обработка). Дополнительные условия существенно влияют на выбор подхода, но применение метода динамически порождаемого автомата — это хорошее решение с точки зрения эффективности, наглядности и автономности.
Логически подобные задачи возникают в случае предварительного планирования действий по сложной структуре данных, и они, как правило, еще сложнее, хотя часто подход к их решению упрощается тем, что требуется найти приемлемый, а не оптимальный, пландействий. Тут такой прием динамического порождения и последующей интерпретации еще более ценен.
Анализ предложенной двухэтапной схемы (построение автомата и его применение), показывает, что естественный метод реализации первого этапа — алгоритм, который на концептуальном уровне следует отнести либо к стилю сентенциального программирования, либо к рекурсивному варианту структурного. В качестве языка его реализации примерно одинаково адекватны LISP, Рефал и Prolog. В то же время адекватный стиль реализации второго этапа — автоматное программирование. Таким образом, разделение стилей требует в идеале применения двуязычной системы программирования. К сожалению, сугубо технические трудности сопряжения двух языков (упомянем только одну из них: согласование представлений данных) часто приводят к тому, что разработчики предпочитают моделирование стиля. И это порою прагматически обоснованное решение, особенно если систему не придется развивать дальше. Но если это потребуется, лучше один раз преодолеть технические трудности1, зато в дальнейшем работать концептуально продуманно. Хорошим примером здесь является система Autocad, языком для преобразования планов в которой служит расширение языка LISP.
Полезно сравнить, как решалась бы наша задача при использовании стилей, отличных от автоматного программирования. При сопоставлении вариантов, предложенных выше для подсчета длин слов, показано, что стиль структурного программирования плохо подходит для этой задачи: как минимум, он приводит к избыточным вычислениям.
Если обратиться к сентенциальному программированию, то для решения в этом стиле нужно отказаться от соглашения об обработке потока, заменив его описанием структуры перерабатываемых данных, и в терминах такой структуры формулировать задание, как мы и сделали в программе 10.2.1. Такой стиль целесообразен для задач, работающих с более сложными структурами данных, и только в том случае, когда появившиеся структуры данных естественно обрабатываются крупномасштабными операциями распознавания, характерными для данного стиля, а действия естественно представляются как операции замены.
Функциональный стиль совсем уж далек от исходной постановки задачи. Этот стиль плохо сочетается с понятиями состояния, перехода и действия. Поэтому при разработке сентенциальных и функциональных систем программирования нужна специальная забота не только о поддержке стиля, но и о том, каким образом будет достигаться подключение к программе модулей, написанных в иных стилях. Впрочем, это же можно сказать вообще о любых системах программирования.
Убийственно для представления "живых" таблиц переходов объектами то, что, хотя число объектов и их связи могут изменяться динамически, новые действия в них уже не вставишь, поскольку весь конечный набор допустимых действий определяется статически при описании типов объектов в программе.
На языке С++/C# структура, которая представляет граф, подобный только что описанному, может быть изображена следующим образом:

Особенность данной интерпретации таблицы в том, что она соответствует автоматам Мура: действия ассоциируются с вершинами, а не с дугами, с состояниями, а не с переходами. Вершина, которой сопоставлено действие, не требует чтения очередного символа и его анализа. Вместо символьных пометок вершины-действия содержат числовые номера, идентифицирующие соответствующие счетчики (размеченноеобъединение использовано для того, чтобы отразить это соглашение).
Выводы из данной статьи про переход от данных к конечному автомату указывают на необходимость использования современных методов для оптимизации любых систем. Надеюсь, что теперь ты понял что такое переход от данных к конечному автомату и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Стили и методы программирования


Комментарии