Лекция
Привет, Вы узнаете о том , что такое модели вычислений, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое модели вычислений , настоятельно рекомендую прочитать все из категории Стили и методы программирования.
Из материалов предыдущего раздела видно, что подходы к решению программистских задач при использовании различных языков отличаются друг от друга. Иногда эти различия непринципиальны и сводятся лишь к текстовому представлению программы, а иногда они довольно существенны. Если различия непринципиальны, то мы говорим, что языки имеют сходную модель вычислений.
Модель вычислений языка не обязательно совпадает с моделью вычислений, заложенной в оборудование. Эти модели расходятся, если сама машина имеет традиционную архитектуру. Более того, даже машины другой архитектуры программно моделируются на машинах традиционной архитектуры. В дальнейшем мы будем пользоваться термином традиционные языки, понимая под этим языки, модель вычислений которых унаследована от традиционной архитектуры машин. Архитектура, впервые использованная Конрадом фон Цузе 1 еще на рубеже 30-40-х гг. XX в., в несколько модифицированной форме до сих пор принята почти для всех вычислительных машин.
В этой архитектуре вычислительной системы имеются следующие три элемента:
Эти элементы обладают следующими особенностями.
Значение в ячейке, с точки зрения процессора, является последовательностью битов фиксированной длины без каких бы то ни было ограничений.
Из однородности памяти следует, что команды и данные (перерабатываемые значения) располагаются в единой общей памяти и одинаково адресуются.
Такую архитектуру будем называть традиционной.
Традиционная архитектура машины конкретизируется для соответствующей среды применения. В частности, она всегда дополняется устройствами ввода и вывода данных.
На рис. 2.1 показано взаимодействие устройств традиционной машины.
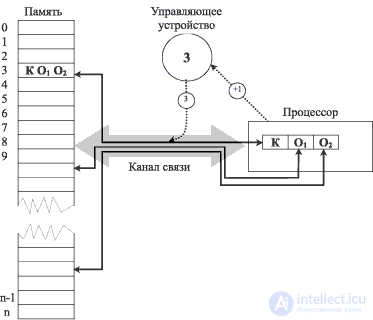
В команде КО1О2 К — код операции, O1 и O2 — адреса операндов. Команда размещена по адресу 3. Сплошными стрелками отмечена передача информации по каналу. Пунктирные стрелки обозначают действия, которые осуществляются непосредственно до исполнения команды (запрос кода команды по адресу 3) и после нее (указание на необходимость запроса команды, следующей в памяти за исполняемой).
Традиционная архитектура ЭВМ сформировалась в условиях ненадежности физических элементов. В частности, по этой причине выбран довольно примитивный способ управления: переход к следующей команде или к команде по принудительно задаваемому адресу. А в дальнейшем, несмотря на появление качественно новой элементной базы, стремительный рост производства машин такого типа препятствовал смене архитектуры.
Есть причина, из-за которой увеличение эффективности традиционных машин принципиально ограничено. Повышение быстродействия процессора как активного элемента оборудования приводит к росту скорости счета лишь в пределах, определяемых скоростью канала связи между процессором и памятью: если она невысока, то процессор будет простаивать, ожидая очередной команды, операндов или окончания выполнения присваивания 3. Темпы роста скорости процессора выше, чем у канала связи.
На эти принципиально непреодолимые ограничения классической модели вычислений указал Бэкус еще в середине семидесятых годов (Тьюринговская лекция Бэкуса [ 35 ] ), назвав канал связи памяти с процессором узким местом (буквально bottleneck ) традиционной модели.
Традиционная архитектура машин менее всего связана с конкретным классом решаемых задач. Она скорее связана с двумя наиболее распространенными и наиболее низкоуровневыми стилями программирования: структурным и автоматным программированием.
Под стилем программирования мы понимаем внутренне концептуально согласованную совокупность средств, базирующуюся на некоторой логике построения программ. Теоретические исследования последних десятилетий показали, что различным классам задач и методов соответствуют различные логики построения программ, и эти логики несовместимы друг с другом. Логики (и, соответственно, стили программирования) дают самую общую оболочку, не зависящую от конкретных предметных областей и даже от конкретных методов. Как только мы уясняем себе особенности методов, стили начинают конкретизироваться далее. Так, известный Вам (поскольку именно он преподается в качестве единственно существующего во всех современных учебных пособиях по началам программирования) структурный стиль конкретизируется в циклический либо рекурсивный варианты (ипостаси).
Для разных стилей логики построения несовместимы, поэтому прежде чем обсуждать стили в системе, мы познакомимся с примерами реализации различных стилей. Но еще до этого целесообразно рассмотреть другие архитектуры машин.
После того, как выяснилось, что традиционная архитектура препятствует повышению производительности, она стала изменяться. Ниже приведены самые распространенные ее модификации:
Полезность подобных модификаций очевидна. Но кэширование, прочие изменения классической канонической модели, и дажемногопроцессорность, - это лишь полумеры, позволяющие расширить, но никак не ликвидировать узкое место.
Внимание!
Важным следствием традиционной структуры компьютера является следующее: в машинной программе все действия и условия локальны.
Для повышения эффективности в оборудовании порой отказываются от принципа однородности памяти. Упомянем две архитектурные модификации традиционной машины.
В некоторых (в первую очередь специализированных) машинах предусмотрено явное выделение в памяти областей данных и областей команд. В обычном режиме выполнения программ процессору не разрешается записывать что-либо в область команд, в результате повышается надежность программ. Для записи чего-либо в область команд нужно аппаратно включить соответствующий режим 4.
Но разделение между командами и данными достаточно грубое. Полезно рассмотреть архитектуру, в которой предлагается так называемоетегирование. Смысл его заключается в том, что в ячейках (основной памяти) выделены специальные разряды, именуемые тегом, которые указывают тип хранимого в остальной части значения (см. рис. 2.2).

Тегирование, реализованное аппаратно, дает следующие преимущества.
В языковых терминах тегирование выражается как динамическая (определяемая при выполнении программы) типизация данных. В этом отношении тегирование в аппаратуре лет на десять опередило первые экспериментальные попытки динамической типизации в языках программирования. Сейчас динамическая типизация, с логической точки зрения полностью аналогичная тегированию, является одним из инструментов объектно-ориентированного программирования.
В языке C тегированное данное соответствует описанию структуры, подобному этому:
struct tagged
{
int type_tag;
union
{
int x;
float y;
}
}
В языке Pascal тегированная ячейка может быть представлена следующей вариантной структурой:
record case tag : Boolean of true: (i :integer); false: (r :real) end;
Тегирование великолепно сочетается со структурным программированием, и поэтому практически всегда используется вместе с модификацией адресации и структуры памяти, называемой стековой архитектурой. При реализации языков высокого уровня на современных системах программирования практически всегда создается структура контекстов.
В стековой архитектуре машины уже физическая память организована как структурированный стек контекстов (см. рис. 2.3).
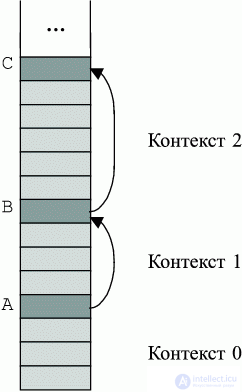
Стек растет вниз. Нынешний контекст назван Контекст 0. Самая нижняя единица в стеке - текущий результат. Стек структурирован как стекстеков. Каждый подстек включает данные для блока программы. Таким образом, каждый из подстеков задает контекст для вычислений в соответствующем блоке. В начале каждого подстека находится его маркер, который содержит всю необходимую служебную информацию о подстеке, в частности ссылку на предыдущий маркер.
Для абстрактного вычислителя со стеком в начале обработки каждой конструкции нужно запомнить в стеке текущий экземпляр состояния контекста. Далее можно выполнять обычные действия по вычислению конструкции.
Стековая архитектура была воплощена в системах команд машин серий Barroughs и Эльбрус. Они прекрасно зарекомендовали себя как машины для сложных ответственных вычислений, но не выдержали конкуренции с армадой PC, задавивших их числом и дешевизной.
Есть и противоположное направление развития аппаратуры. В машинах с так называемой RISC-архитектурой машинные команды исключительно просты, но в полупостоянной части оперативной памяти заложены подпрограммы для команд `нормального' или даже `высокого' уровня, так что в принципе RISC-процессор может в зависимости от режима эмулировать5 машины разной архитектуры. Например, такая система была использована в машинах знаменитой серии Power PC - Power Mac, которые могли выступать для пользователя и программиста и как PC, и как Macintosh. Эта серия потерпела коммерческую неудачу скорее из-за ошибок в продвижении на рынок, чем из-за отсутствия реальных достоинств.
Крутой подумал. Ему понравилось. Он решил когда-нибудь на досуге подумать еще раз. Русский анекдот
Исторический экскурс
Во время Великой французской революции в связи с введением метрической системы мер, да и для улучшения качества артиллерии и флота, возникла необходимость быстро и качественно пересчитать множество таблиц: артиллерийские, навигационные, астрономические, геодезические и т. п.
Решение этой задачи (вдохновителем и организатором работ был выдающийся математик и администратор Л. Карно) было гениально с точки зрения концептуальной и организационной проработки. Вначале с помощью методов интерполяции все функции были заменены их кусочно-полиномиальными приближениями, не имеющими разрывов (современный термин - сплайн). Полиномы могут вычисляться методом конечных разностей, поэтому алгоритм вычисления полинома был распределен на сложения, вычитания и небольшое число умножений наконстанты. Для организации таких вычислений было использовано две параллельно работающие роты грамотных солдат под руководством математиков. Одни и те же расчеты проводились ротами независимо. Каждый солдат получал аргументы от двух указанных ему товарищей, складывал либо вычитал их (действие было предопределено заранее и не менялось). Самые грамотные солдаты получали аргумент от одного товарища и умножали его на заданную константу. По команде результаты действий передавались далее. Математики-надзиратели проверяли полученные результаты на правдоподобие и пересчитывали их выборочно. В случаях расхождения результатов рот счет производился заново. Таким образом таблицы были пересчитаны практически без ошибок, с минимальными затратами, высокой точностью и в кратчайшее время. В результате артиллерийские таблицы французской армии оставались лучшими более пяти лет, до тех пор, пока русские артиллеристы под руководством гр. Аракчеева не посчитали их еще лучше 6.
Так что в том первом историческом случае, когда значительный объем вычислений был индустриализирован, была весьма квалифицированно выбрана модель вычислений.
Именно этим примером руководствовался при создании первой программно-управляемой механической вычислительной машины Чарльз Бэббидж, поскольку на механических элементах невозможно было добиться приемлемой скорости без распараллеливания вычислений. Быстродействующие, но ненадежные элементы первых ЭВМ практически вынудили отказаться от параллельной модели вычислений и перейти к более примитивной последовательной модели. Все преподавание и математическое обеспечение стало развиваться с ориентацией на последовательные вычисления. И когда появилась возможность электронной реализации параллельных вычислений, к ней оказались не готовы ни математики, ни программисты.
Прежде всего, можно просто иметь несколько процессоров. Многопроцессорность может быть использована несколькими способами.
Прямое развитие данной идеи наталкивается также на массу тонких вопросов синхронизации. Простейший и наиболее очевидный из конфликтов синхронизации - попытка одновременной записи результатов нескольких команд в одну ячейку памяти, поэтому присваивания становятся тормозом на пути программирования.
Рассмотрим теперь те архитектуры, где до известной степени ликвидируется централизованное управление и появляется возможность глубокого распараллеливания вычислений.
Здесь стоит обратить внимание на два взаимосвязанных момента. Во-первых, часто нет нужды в хранении промежуточных результатов счета и, как следствие, потребность в пассивной памяти существенно снижается. Во-вторых, ликвидируется примитивное устройство управления, а его роль принимают на себя элементы оборудования, отвечающие за выяснение готовности команд к выполнению. Это - одна из схем, которая подчиняет управление потокам данных (data flow). Такие схемы противопоставляются управляющим потокам (control flow) традиционных вычислений.
Рассмотрим гипотетическую схему машины, управляемой потоком данных. Каждая команда имеет ссылку на те команды, от которых она зависит ( предпосылки команды). Если выполнены все предпосылки, команда имеет право выполниться. Например, рассмотрим следующую схему.
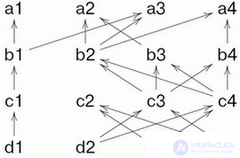
На схеме вершины означают команды. Каждая команда зависит не более чем от двух, но зависеть от нее может сколько угодно других.
Представленная идея неоднократно воплощалась в оборудовании (так называемые машины потоков данных). Но каждый раз узким местом для подобных машин оказывалось несоответствие стиля программ, требуемого для них, тем стилям, к которым привыкли программисты. Как следствие, в каждом из таких процессоров делались грубые системные ошибки, приводившие к затруднениям в программировании, а также к понижению скорости и гибкости вычислений. Тем не менее поскольку скорость света очень скоро поставит предел механическому увеличению пропускной способности каналов, к подобным схемам придется вернуться на другом уровне.
Конечно же, при реализации идеи возникают сложности. Пару из них демонстрирует следующий поток.
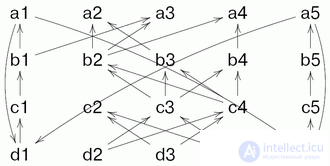
В потоке имеются два цикла, подготавливающие данные друг для друга. Возникает вопрос, а если один из циклов вторично подошел к точке, где требуются данные из другого, не устарели ли уже имеющиеся данные и не нужно ли подождать, пока они обновятся? Далее, здесь видно, что инициализацию потока данных часто необходимо выделять в самостоятельный блок, поскольку формально вычислениеобоих циклов просто не сможет начаться.
Машины потоков данных уже несколько десятилетий используются на практике, так называемые суперЭВМ считают вычислительные задачи колоссальной трудоемкости (например, метеорологические). В подобных задачах, как правило, вычисление может быть записано в матричной алгебре, и новые матрицы строка за строкой вычисляются по старым. Таким образом, можно организовать конвейер, когда элементы целого вектора данных параллельно считаются по элементам предшествующего вектора, а переход к следующему происходит, когда все новые элементы посчитаны (так что вопрос о старении данных решается радикально: все, что использовалось для предыдущего вектора, по умолчанию считается устаревшим для следующего). Особенно хорошо конвейер работает, когда подпрограммы вычисления для каждого из элементов массива практически не изменяются (конечно же, для разных элементов они могут быть разные), посколькуинициализация процесса занимает много времени и сил. Конвейер с 1024 процессорами увеличивает производительность вычислений для некоторых реальных задач примерно в 300 раз, и для многих приблизительно в 100 раз. Первой серийной суперЭВМ, успешно применившейконвейерную организацию, стала система машин Cray.
Одной из особенностей машин потоков данных является повышение активности памяти, в которой размещаются команды и их операнды. Поэтому пути можно пойти еще дальше, сделав всю память активной. Во избежание полной анархии, память обычно имеет общее устройство управления, задающее одну команду (или несколько команд, в зависимости от какого-то быстро проверяемого условия), которую выполняют все ячейки ( ассоциативная память ). История реализации этой идеи аналогична истории машин потоков данных: аппаратные предпосылки есть, но эффективных способов программирования нет.
Несмотря на очевидные преимущества для отдельных классов задач других моделей вычислений и на очевидную неэффективность классической модели вычислений, не происходит переход к другим, более перспективным с точки зрения ускорения счета, моделям. Почему? Это очень непростой вопрос, связанный как со сложившимися традициями, так и с огромным грузом накопленного программного обеспечения. В частности, другие модели вычислений, очевидно, не универсальны, ориентированы на некоторые классы задач, а иллюзия универсальности, основанная на примитивно истолкованной теореме об универсальном алгоритме, сопутствует традиционной модели вычислений. Но, пожалуй, более всего консерватизм обусловлен тем, что сегодняшняя армия программистов воспитана на традиционной модели, и она уже не в состоянии перестроиться.
Уже в машине потоков данных мы видим, что приказ выполнить следующую команду может быть заменен на разрешение ее выполнить. Таким образом, в программировании имеется возможность перехода от повелительного наклонения к изъявительному. Реализация идеи внедрения изъявительного наклонения в языки программирования возможна по следующим направлениям:
Способ передачи данных и активизации вычислений в коммутационной системе может рассматриваться как одна из реализаций потока данных в системе функций. В частности, если граф не имеет циклов, то коммутационная система становится формой представления нерекурсивной системы функций. Если граф коммутационной системы содержит циклы, то он может быть интерпретирован как рекурсивная система функций. Такая система может быть теоретически представлена как бесконечный ациклический граф.
В случае наиболее распространенной классической логики и языка исчисления предикатов либо некоторого его расширения на систему аксиом можно смотреть как на описание предметной области (либо, что то же самое, на задание соотношений между данными). Вычислительные действия в подобной системе активизируются по запросам, целью которых является вывод некоторой формулы (что для классической логики и элементарных формул соответствует выводу истинности либо ложности некоторого факта; такой вывод уже не назовешь проверкой, поскольку он не является элементарной операцией). Программиста в такой системе обычно интересует не способ вывода, а лишь его осуществимость.
Все описанное выше если и может быть сегодня реализовано в оборудовании, то крайне ущербным и частным способом. Но еще в 60-е гг. ХХ века стало видно, что программное обеспечение настолько сильно экранирует физическую структуру компьютера, что для всех пользователей и большинства программистов компьютер вместе с базовым программным обеспечением является единой системой. В связи с этим все чаще говорят о системе программирования как о машине. Например, реализация языка Java определяется через Java-машину, в терминах которой понимаются все вычисления. Достаточно часто такая программная машина, реализующая некоторую модель вычислений, служила основой для аппаратной реализации ключевых особенностей данной модели. Например, Алгол-машина легла в основу компьютеров со стековой архитектурой и тегированием.
Выводы из данной статьи про модели вычислений указывают на необходимость использования современных методов для оптимизации любых систем. Надеюсь, что теперь ты понял что такое модели вычислений и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Стили и методы программирования
Комментарии
Оставить комментарий
Стили и методы программирования
Термины: Стили и методы программирования