Лекция
Привет, Вы узнаете о том , что такое внимание (машинное обучение), Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое внимание (машинное обучение), самовнимание , настоятельно рекомендую прочитать все из категории Модели нейросетей и методы исследований систем искусственного интеллекта.
В машинном обучении механизм внимания — это метод, определяющий важность каждого компонента в последовательности относительно других компонентов в этой последовательности. В обработке естественного языка важность представляется «мягкими» весами, присваиваемыми каждому слову в предложении. В более общем смысле, механизм внимания кодирует векторы, называемые векторными представлениями токенов , в последовательности фиксированной ширины, размер которой может варьироваться от десятков до миллионов токенов.
В отличие от «жестких» весов, которые вычисляются во время обратного прохода обучения, «мягкие» веса существуют только в прямом проходе и, следовательно, изменяются на каждом шаге входных данных. В более ранних разработках механизм внимания был реализован в системе языкового перевода на основе последовательной рекуррентной нейронной сети (RNN), но в более поздней разработке, а именно в системе Transformer , был удален более медленный последовательный RNN, и в большей степени использовалась более быстрая параллельная схема внимания.
Вдохновленный идеями о внимании у человека , механизм внимания был разработан для устранения недостатков использования информации из скрытых слоев рекуррентных нейронных сетей. Рекуррентные нейронные сети отдают предпочтение более свежей информации, содержащейся в словах в конце предложения, в то время как информация, расположенная в начале предложения, как правило, менее значима . Механизм внимания позволяет токену получать равный доступ к любой части предложения напрямую, а не только через предыдущее состояние.
| 1950-е – 1960-е годы | Психология и биология внимания. Эффект «коктейльной вечеринки» — фокусировка на содержании путем фильтрации фонового шума. Фильтровая модель внимания , парадигма частичного отчета и контроль саккад . |
| 1980-е годы | Сигма-пи единицы, нейронные сети более высокого порядка. |
| 1990-е годы | Быстрые контроллеры весов и динамические связи между нейронами, предвосхищающие механизмы ключ-значение в механизме внимания. |
| 1998 | Двусторонний фильтр был введен в обработку изображений. Он использует попарные матрицы сходства для распространения релевантности между элементами. |
| 2005 | Нелокальный означает расширенную фильтрацию на основе сходства в шумоподавлении изображений, используя ядра гауссова сходства в качестве фиксированных весов, подобных механизму внимания. |
| 2014 | seq2seq с RNN + Attention. Attention был введен для улучшения перевода кодировщика-декодера RNN, особенно для длинных предложений. См. раздел «Обзор».
Нейронные сети внимания представили механизм выбора признаков, основанный на обучении, с использованием когнитивной модуляции сверху вниз, демонстрируя, как весовые коэффициенты внимания могут выделять релевантные входные данные. |
| 2015 | Внимание было расширено на зрение для задач создания подписей к изображениям. |
| 2016 | В модели на основе RNN был интегрирован механизм самовнимания для учета внутрипоследовательных зависимостей.
самовнимание было исследовано в разложимых моделях внимания для вывода естественного языка и структурированных вложений предложений с самовниманием . |
| 2017 | Архитектура Transformer , представленная в исследовательской работе Attention is All You Need , формализовала масштабированное скалярное произведение самовнимания:
Сети отношений и преобразователи множеств применяют внимание к неупорядоченным множествам и реляционному рассуждению, обобщая модели парного взаимодействия. |
| 2018 | Нелокальные нейронные сети расширили возможности компьютерного зрения за счет улавливания долгосрочных зависимостей в пространстве и времени. Сети внимания графов применили механизмы внимания к данным, имеющим графовую структуру. |
| 2019–2020 | Эффективные трансформеры, включая Reformer , Linformer и Performer , представили масштабируемые приближения внимания для длинных последовательностей. |
| 2019+ | Сети Хопфилда были переосмыслены как ассоциативные системы внимания, основанные на памяти , а трансформеры зрения (ViT) достигли конкурентоспособных результатов в классификации изображений .
Трансформеры были использованы в различных научных областях, включая AlphaFold для сворачивания белков , CLIP для предварительной подготовки изображений и языка и модели плотной сегментации на основе внимания, такие как CCNet и DANet . |
Дополнительные исследования механизма внимания в глубоком обучении представлены в работах Niu et al. и Soydaner .
Главный прорыв произошел благодаря механизму самовнимания, при котором каждый элемент входной последовательности обращает внимание на все остальные, что позволяет модели улавливать глобальные зависимости. Эта идея была центральной для архитектуры Transformer , которая заменила рекуррентность механизмами внимания. В результате Transformer стали основой для таких моделей, как BERT , T5 и генеративных предварительно обученных трансформеров (GPT).
Современная эра машинного внимания получила новый импульс благодаря внедрению механизма внимания (рис. 1, оранжевый) в кодировщик-декодер.
|
|
|
| Обозначение | Описание |
|---|---|
| 100 | Максимальная длина предложения |
| 300 | Размер векторного представления (размерность слова) |
| 500 | Длина скрытого вектора |
| 9k, 10k | Размер словаря для входного и выходного языков соответственно. |
| x , Y | 9k и 10k 1-hot словарных векторов. x → x реализовано как таблица поиска, а не как векторное умножение. Y — это 1-hot максимизатор линейного слоя декодера D; то есть он берет argmax выходных данных линейного слоя D. |
| х | Вектор векторного представления слова длиной 300 слов. Векторы обычно предварительно рассчитываются на основе данных из других проектов, таких как GloVe или Word2Vec . |
| h | Скрытый вектор кодировщика длиной 500 символов. В каждый момент времени этот вектор суммирует все предшествующие ему слова. Конечный символ h можно рассматривать как вектор «предложения» или, как его называет Хинтон, вектор мысли . |
| s | Вектор скрытого состояния декодера длиной 500. |
| Е | Кодировщик на основе рекуррентной нейронной сети с 500 нейронами . 500 выходов. Количество входных сигналов: 800 – 300 от исходного векторного представления + 500 от рекуррентных связей. Кодировщик подает сигнал непосредственно в декодер только для его инициализации, но не после этого; поэтому эта прямая связь показана очень слабо. |
| D | 2-слойный декодер. Рекуррентный слой имеет 500 нейронов, а полносвязный линейный слой — 10 000 нейронов (размер целевого словаря). Только линейный слой имеет 5 миллионов (500 × 10 000) весов — примерно в 10 раз больше весов, чем рекуррентный слой. |
| score | 100-значный показатель выравнивания |
| w | Веса вектора внимания длиной 100. Это «мягкие» веса, которые изменяются во время прямого прохода, в отличие от «жестких» нейронных весов, которые изменяются во время фазы обучения. |
| А | Модуль внимания – это может быть скалярное произведение рекуррентных состояний или полносвязные слои типа «ключ-значение запроса». Выходные данные представляют собой вектор длиной 100 символов w. |
| H | 500×100. 100 скрытых векторов h объединены в матрицу. |
| с | Контекстный вектор длиной 500 = H * w. c представляет собой линейную комбинацию h векторов, взвешенных по w. |
На рисунке 2 показана внутренняя пошаговая работа блока внимания (А) на рисунке 1.

Рисунок 2. На диаграмме показано, как алгоритм внимания вычисляет корреляции слова «that» с другими словами в выражении «See that girl run». При правильном распределении весов, полученных в ходе обучения, сеть должна уметь идентифицировать слово «girl» как слово с высокой корреляцией. Некоторые важные моменты:
 .
.
При переводе между языками выравнивание — это процесс сопоставления слов исходного предложения со словами переведенного предложения. Нейронные сети, выполняющие дословный перевод без учета порядка слов, показывают наивысшие результаты вдоль (доминирующей) диагонали матрицы. Доминирование вне диагонали свидетельствует о более тонком механизме внимания.
Рассмотрим пример перевода фразы « Я люблю тебя» на французский язык. При первом проходе декодера 94% внимания приходится на первое английское слово «I» , поэтому сеть предлагает слово «je» . При втором проходе декодера 88% внимания приходится на третье английское слово «you» , поэтому предлагается слово «t'» . При последнем проходе 95% внимания приходится на второе английское слово «love» , поэтому предлагается слово «aime» .
В примере «Я люблю тебя» второе слово «любовь» выровнено с третьим словом «aime» . Объединение мягких векторных строк для слов «je» , «t'» и «aime» дает матрицу выравнивания :
| I | love | you | |
|---|---|---|---|
| je | 0,94 | 0,02 | 0,04 |
| t' | 0.11 | 0,01 | 0,88 |
| aime | 0,03 | 0,95 | 0,02 |
Иногда выравнивание может быть множественным по отношению к множественному. Например, английская фраза look it up соответствует cherchez-le . Таким образом, «мягкие» веса внимания работают лучше, чем «жесткие» веса внимания (установка одного веса внимания равным 1, а остальных — 0), поскольку мы хотим, чтобы модель создавала контекстный вектор, состоящий из взвешенной суммы скрытых векторов, а не «наилучший», поскольку наилучшего скрытого вектора может и не существовать.
Многие варианты механизма внимания используют мягкие веса, например:
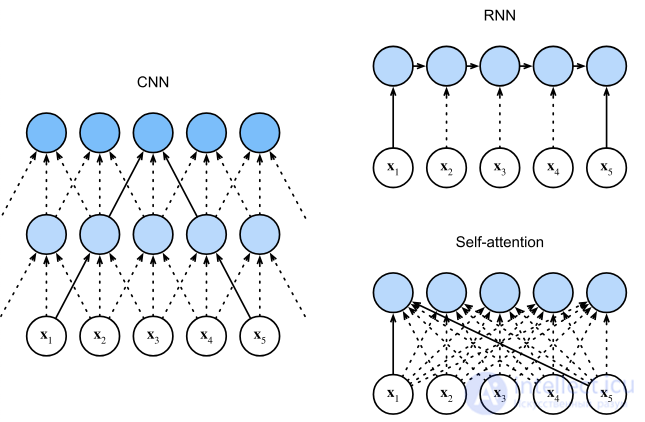
Сравнение потока данных в CNN, RNN и механизме самовнимания
Для сверточных нейронных сетей механизмы внимания можно различать по размерности, на которой они работают, а именно: пространственное внимание , внимание к каналам или их комбинации .
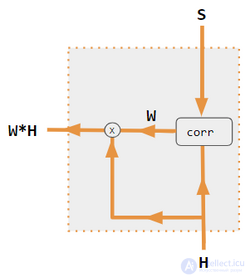
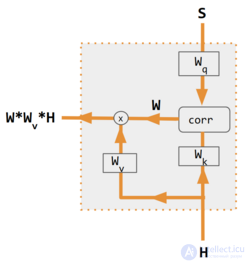
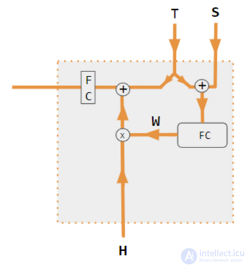
Эти варианты рекомбинируют входные данные со стороны кодировщика, чтобы перераспределить эти эффекты на каждый целевой выход. Часто коэффициенты перевзвешивания представляют собой матрицу скалярных произведений в корреляционном стиле. На рисунках ниже W — это матрица весов контекстного внимания, аналогичная формуле в разделе «Обзор» выше.
| 1. скалярное произведение кодировщика и декодера | 2. кодировщик-декодер QKV | 3. скалярное произведение только кодировщика | 4. QKV только с кодировщиком | 5. Учебное пособие по PyTorch |
|---|---|---|---|---|
|
|

|

|
|
Размер матрицы внимания пропорционален квадрату количества входных токенов. Поэтому, когда входные данные длинные, вычисление матрицы внимания требует большого объема памяти графического процессора . Flash attention — это реализация, которая уменьшает потребность в памяти и повышает эффективность без ущерба для точности. Она достигает этого за счет разделения вычисления внимания на более мелкие блоки, которые помещаются в более быструю встроенную память графического процессора, уменьшая необходимость хранения больших промежуточных матриц и, таким образом, снижая использование памяти при одновременном повышении вычислительной эффективности.
FlexAttention — это ядро внимания, разработанное Meta , которое позволяет пользователям изменять оценки внимания перед softmax и динамически выбирать оптимальный алгоритм внимания.
Механизм внимания широко используется в обработке естественного языка, компьютерном зрении и распознавании речи. В НЛП он улучшает понимание контекста в таких задачах, как ответы на вопросы и составление резюме. В компьютерном зрении визуальное внимание помогает моделям фокусироваться на релевантных областях изображения, улучшая обнаружение объектов и создание подписей к изображениям.
Начиная с оригинальной статьи о трансформерах зрения (ViT), визуализация оценок внимания в виде тепловой карты (называемой картами значимости или картами внимания) стала важным и стандартным способом анализа процесса принятия решений моделями ViT. Карты внимания можно вычислить относительно любого элемента внимания на любом слое, при этом более глубокие слои, как правило, показывают более семантически значимую визуализацию. Алгоритм Attention Rollout — это рекурсивный алгоритм для объединения оценок внимания по всем слоям путем вычисления скалярного произведения последовательных карт внимания.
Поскольку графические трансформеры обычно обучаются в режиме самообучения , карты внимания, как правило, не чувствительны к классу. Когда к базовой сети ViT подключается классификационный модуль, карты внимания, дискриминирующие класс (CDAM), объединяют карты внимания и градиенты относительно [CLS]токена класса. Некоторые методы интерпретируемости, чувствительные к классу, первоначально разработанные для сверточных нейронных сетей, также могут быть применены к ViT, например, GradCAM, который распространяет градиенты обратно на выходы конечного слоя внимания.
Использование внимания в качестве основы для объяснения трансформеров в языке и зрении не лишено споров. Хотя некоторые новаторские работы анализировали и формулировали показатели внимания как объяснения, более высокие показатели внимания не всегда коррелируют с большим влиянием на производительность модели.
Для матриц: и
и Масштабированное скалярное произведение, или механизм внимания QKV, определяется следующим образом:
Масштабированное скалярное произведение, или механизм внимания QKV, определяется следующим образом: где
где обозначает транспонирование , а функция softmax применяется независимо к каждой строке своего аргумента.
обозначает транспонирование , а функция softmax применяется независимо к каждой строке своего аргумента. содержит
содержит запросы, а матрицы
запросы, а матрицы совместно содержат неупорядоченное множество
совместно содержат неупорядоченное множество Пары ключ-значение. Об этом говорит сайт https://intellect.icu . Векторы значений в матрице.
Пары ключ-значение. Об этом говорит сайт https://intellect.icu . Векторы значений в матрице. Взвешиваются с использованием весов, полученных в результате операции softmax, так что строки -к-
Взвешиваются с использованием весов, полученных в результате операции softmax, так что строки -к- Выходная матрица ограничена выпуклой оболочкой точек в
Выходная матрица ограничена выпуклой оболочкой точек в задано строками.
задано строками.
Чтобы понять свойства инвариантности и эквивариантности перестановок внимания QKV, ] пусть и
и быть матрицами перестановок ; и
быть матрицами перестановок ; и произвольная матрица. Функция softmax является перестановочно-эквивариантной в том смысле, что:
произвольная матрица. Функция softmax является перестановочно-эквивариантной в том смысле, что: Учитывая, что транспонированная матрица перестановки также является ее обратной матрицей, следует, что:
Учитывая, что транспонированная матрица перестановки также является ее обратной матрицей, следует, что: что показывает, что механизм внимания QKV является эквивариантным по отношению к переупорядочиванию запросов (строки изи инвариантен к переупорядочиванию пар ключ-значение вЭти свойства наследуются при применении линейных преобразований к входным и выходным данным блоков внимания QKV. Например, простая функция самовнимания определяется следующим образом:
что показывает, что механизм внимания QKV является эквивариантным по отношению к переупорядочиванию запросов (строки изи инвариантен к переупорядочиванию пар ключ-значение вЭти свойства наследуются при применении линейных преобразований к входным и выходным данным блоков внимания QKV. Например, простая функция самовнимания определяется следующим образом: является ли перестановочная эквивариантность относительно перестановки строк входной матрицы
является ли перестановочная эквивариантность относительно перестановки строк входной матрицы Нетривиальным образом, поскольку каждая строка выходных данных является функцией всех строк входных данных. Аналогичные свойства справедливы и для многоголовочного механизма внимания , который определен ниже.
Нетривиальным образом, поскольку каждая строка выходных данных является функцией всех строк входных данных. Аналогичные свойства справедливы и для многоголовочного механизма внимания , который определен ниже.
Когда механизм внимания QKV используется в качестве базового элемента для авторегрессивного декодера, и когда во время обучения все входные и выходные матрицы имеютв строках используется вариант с маскированным вниманием: где маска,
где маска, является строго верхнетреугольной матрицей , имеющей нули на диагонали и ниже нее.
является строго верхнетреугольной матрицей , имеющей нули на диагонали и ниже нее. в каждом элементе выше диагонали. Выходные данные функции softmax, также в
в каждом элементе выше диагонали. Выходные данные функции softmax, также в В этом случае получается нижнетреугольная структура с нулями во всех элементах выше диагонали. Маскирование гарантирует, что для всех
В этом случае получается нижнетреугольная структура с нулями во всех элементах выше диагонали. Маскирование гарантирует, что для всех , ряд
, ряд Выходной сигнал внимания не зависит от строки
Выходной сигнал внимания не зависит от строки любой из трех входных матриц. Свойства инвариантности к перестановкам и эквивариантности стандартного механизма внимания QKV не выполняются для маскированного варианта.
любой из трех входных матриц. Свойства инвариантности к перестановкам и эквивариантности стандартного механизма внимания QKV не выполняются для маскированного варианта.
Многоголовочное внимание где каждая голова вычисляется с помощью механизма внимания QKV следующим образом:
где каждая голова вычисляется с помощью механизма внимания QKV следующим образом: и
и , и
, и являются матрицами параметров.
являются матрицами параметров.
Свойства перестановок (стандартного, немаскированного) механизма внимания QKV применимы и здесь. Для матриц перестановок, :
: Из чего мы также видим, что многоголовочное самовнимание:
Из чего мы также видим, что многоголовочное самовнимание: является эквивариантным относительно перестановки строк входной матрицы.
является эквивариантным относительно перестановки строк входной матрицы.
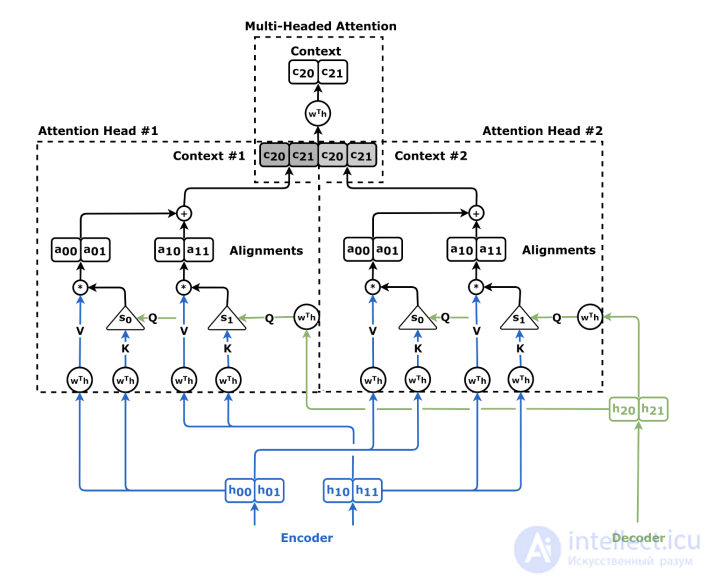
Декодер многоголового перекрестного внимания
 где
где и
и являются обучаемыми весовыми матрицами.
являются обучаемыми весовыми матрицами.
 где
где является обучаемой матрицей весов.
является обучаемой матрицей весов.
Механизм самовнимания по сути аналогичен механизму перекрестного внимания, за исключением того, что векторы запроса, ключа и значения берутся из одной и той же модели. И кодировщик, и декодер могут использовать механизм самовнимания, но с некоторыми незначительными различиями.
Для механизма самовнимания кодировщика можно начать с простого кодировщика без самовнимания, например, с «слоя встраивания», который просто преобразует каждое входное слово в вектор с помощью фиксированной таблицы поиска . Это дает последовательность скрытых векторов. Затем их можно применить к механизму внимания на основе скалярного произведения, чтобы получить
Затем их можно применить к механизму внимания на основе скалярного произведения, чтобы получить или, если говорить более кратко,
или, если говорить более кратко, Этот метод можно применять многократно для получения многослойного кодировщика. Это так называемое «самовнимание кодировщика», иногда именуемое «вниманием всех ко всем», поскольку вектор в каждой позиции может обращать внимание на каждый другой вектор.
Этот метод можно применять многократно для получения многослойного кодировщика. Это так называемое «самовнимание кодировщика», иногда именуемое «вниманием всех ко всем», поскольку вектор в каждой позиции может обращать внимание на каждый другой вектор.
Для механизма самовнимания декодера механизм внимания «все ко всем» не подходит, поскольку в процессе авторегрессивного декодирования декодер не может обращать внимание на будущие выходные данные, которые еще не были декодированы. Эту проблему можно решить путем принудительного изменения весовых коэффициентов внимания. для всех
для всех Этот механизм внимания называется «причинно-следственной маскировкой». Он называется «причинно-следственно замаскированным самовниманием».
Этот механизм внимания называется «причинно-следственной маскировкой». Он называется «причинно-следственно замаскированным самовниманием».
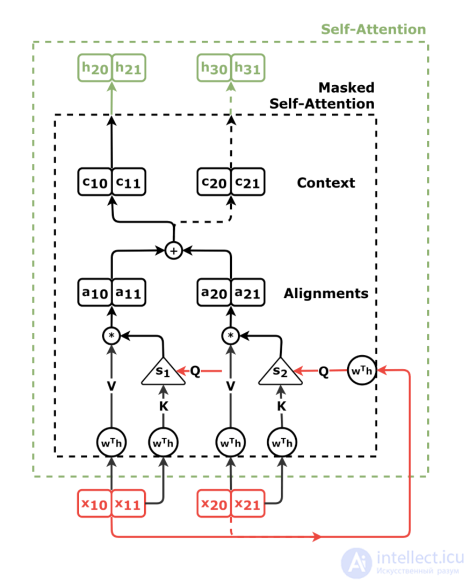
Декодер с механизмом самовнимания и причинно-следственной маскировкой, подробная схема
Исследование, описанное в статье про внимание (машинное обучение), подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое внимание (машинное обучение), самовнимание и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Модели нейросетей и методы исследований систем искусственного интеллекта
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.



Комментарии